في حديثي ، شاركت تجربتي في استخدام Alembic ، وهي أداة مثبتة جيدًا لإدارة الهجرات. لماذا تختار Alembic ، وكيفية تحضير عمليات الترحيل معها ، وكيفية تشغيلها (تلقائيًا أو يدويًا) ، وكيفية حل مشكلات التغييرات التي لا رجعة فيها ، ولماذا تختبر عمليات الترحيل ، وما هي المشكلات التي يمكن اكتشافها عن طريق الاختبارات وكيفية تنفيذها - لقد حاولت الإجابة على كل هذه الأسئلة. في الوقت نفسه ، شاركت العديد من حيل الحياة التي ستجعل العمل مع الهجرات في ألمبيك أمرًا سهلاً وممتعًا.
منذ يوم التقرير ، تم تحديث الكود على GitHub قليلاً ، وهناك المزيد من الأمثلة. إذا كنت تريد رؤية الكود تمامًا كما يظهر في الشرائح ، فإليك رابطًا لالتزام من ذلك الوقت.
- مرحبا! اسمي الكسندر اعمل في Edadil. اليوم أريد أن أخبرك كيف نعيش مع الهجرات وكيف يمكنك التعايش معها. ربما سيساعدك هذا على العيش بشكل أسهل.
ما هي الهجرات؟
قبل أن نبدأ ، يجدر بنا الحديث عن ماهية الهجرات بشكل عام. على سبيل المثال ، لديك تطبيق وقمت بإنشاء زوج من الأجهزة اللوحية بحيث تعمل ، تذهب إليهم. ثم تطرح إصدارًا جديدًا ، حيث تغير شيء ما - فقد تغيرت اللوحة الأولى ، والثانية لم تتغير ، والثالثة لم تكن موجودة من قبل ، لكنها ظهرت.

ثم يظهر إصدار جديد من التطبيق ، حيث يتم حذف بعض اللوحات ، ولا يحدث شيء للباقي. ما هذا؟ يمكننا القول أن هذه هي الحالة التي يمكن وصفها بالهجرة. عندما ننتقل من حالة إلى أخرى ، فهذه ترقية ، عندما نريد الرجوع إلى إصدار سابق.
ما هي الهجرات؟

من ناحية أخرى ، هذا هو الرمز الذي يغير حالة قاعدة البيانات. من ناحية أخرى ، هذه هي العملية التي نبدأها.

ما الخصائص التي يجب أن تمتلكها الهجرات؟ من المهم أن تكون الحالات التي ننتقل بينها في إصدارات التطبيق ذرية. على سبيل المثال ، إذا أردنا أن يكون لدينا جدولين ، ولكن يظهر واحد فقط ، فقد يؤدي ذلك إلى عواقب غير جيدة للغاية في الإنتاج.
من المهم أن نتمكن من التراجع عن التغييرات التي أجريناها ، لأنه إذا قمت بطرح إصدار جديد ، فلن ينطلق ولا يمكنك التراجع ، فعادة ما ينتهي كل شيء بشكل سيء.
من المهم أيضًا أن يتم ترتيب الإصدارات بحيث يمكنك ربطها بالطريقة التي يتم بها لفها.
أدوات
كيف يمكننا تنفيذ هذه الهجرات؟
الفكرة الأولى التي تتبادر إلى الذهن: حسنًا ، الترحيل هو SQL ، فلماذا لا تأخذ ملفات SQL مع الاستعلامات وتنشئها. هناك العديد من الوحدات النمطية التي يمكن أن تجعل حياتنا أسهل.

إذا نظرنا إلى ما يجري في الداخل ، فهناك بالفعل طلبان. يمكن أن يكون إنشاء جدول أو تغيير أو أي شيء آخر. في ملف downgrade_v1.sql ، نقوم بإلغاء كل شيء.

لماذا لا تفعل هذا؟ في المقام الأول لأنك تحتاج إلى القيام بذلك بيديك. لا تنس أن تكتب ابدأ ، ثم أدخل تغييراتك. عندما تكتب رمزًا ، ستحتاج إلى تذكر كل التبعيات وماذا تفعل بأي ترتيب. هذه وظيفة روتينية إلى حد ما وصعبة وتستغرق وقتًا طويلاً.
ليس لديك حماية ضد تشغيل الملف الخطأ عن طريق الخطأ. تحتاج إلى تشغيل جميع الملفات يدويًا. إذا كان لديك 15 هجرة فهذا ليس بالأمر السهل. ستحتاج إلى استدعاء بعض psql 15 مرة ، فلن يكون الأمر رائعًا.
الأهم من ذلك ، أنك لا تعرف أبدًا حالة قاعدة البيانات الخاصة بك. تحتاج إلى تدوين في مكان ما - على قطعة من الورق ، في مكان آخر - الملفات التي قمت بتنزيلها والتي لم تقم بتنزيلها. لا يبدو جيدًا أيضًا.

هناك وحدة yoyo-migrations . يدعم قواعد البيانات الأكثر شيوعًا ويستخدم الاستعلامات الأولية.

إذا نظرنا إلى ما يقدمه لنا ، يبدو الأمر هكذا. نرى نفس SQL. يوجد بالفعل كود Python على اليمين يستورد مكتبة yoyo.

وبالتالي ، يمكننا بالفعل بدء عمليات الترحيل تلقائيًا تمامًا. بعبارة أخرى ، هناك أمر ينشئ ويضيف ترحيلًا جديدًا إلى السلسلة حيث يمكننا كتابة كود SQL الخاص بنا. باستخدام الأوامر ، يمكنك تطبيق واحد أو أكثر من عمليات الترحيل ، ويمكنك التراجع ، وهذه خطوة للأمام بالفعل.

الميزة الإضافية هي أنك لم تعد بحاجة إلى الكتابة على قطعة من الورق ما هي الطلبات التي قمت بتنفيذها على قاعدة البيانات ، والملفات التي قمت بتشغيلها والملفات التي تحتاج إلى الرجوع إليها إذا حدث شيء ما. لديك نوع من الحماية المضمونة: لن تتمكن بعد الآن من تشغيل ترحيل مصمم لشيء آخر ، للانتقال بين حالتين أخريين من قاعدة البيانات. إضافة كبيرة جدًا: يقوم هذا الشيء بكل عملية ترحيل في معاملة منفصلة. هذا يعطي أيضا مثل هذه الضمانات.

العيوب واضحة. لا يزال لديك SQL خام. إذا كان لديك ، على سبيل المثال ، إنتاج كبير للبيانات مع منطق مترامي الأطراف في Python ، فلا يمكنك استخدامه ، لأن لديك SQL فقط.
أيضًا ، ستجد الكثير من الأعمال الروتينية التي لا يمكن أتمتتها. من الضروري تتبع جميع العلاقات بين الجداول - ما يمكن كتابته في مكان ما ، وما هو غير ممكن بعد. بشكل عام ، هناك عيوب واضحة.
الوحدة الأخرى التي تستحق الاهتمام ، والتي يتحدث عنها اليوم بأكمله ، هي Alembic .

لديها نفس الأشياء مثل yoyo ، وأكثر من ذلك بكثير. فهو لا يراقب عمليات الترحيل الخاصة بك ويعرف كيفية إنشائها فحسب ، بل يسمح لك أيضًا بكتابة منطق أعمال معقد للغاية ، وربط إنتاج البيانات بالكامل ، وأي وظائف في Python. اسحب البيانات ومعالجتها داخليًا إذا كنت تريد ذلك. إذا كنت لا تريد ذلك ، فلا داعي لذلك.
يمكنه كتابة رمز لك تلقائيًا في معظم الحالات. ليس دائمًا ، بالطبع ، ولكن يبدو أنه إضافة جيدة بعد أن اضطررت إلى الكتابة كثيرًا بيديك.
لديه الكثير من الأشياء الرائعة. على سبيل المثال ، لا يدعم SQLite بشكل كامل ALTER TABLE. ويتمتع Alembic بوظائف تسمح لك بتجاوز هذا بسهولة في سطرين ، ولن تفكر فيه حتى.
في الشرائح السابقة ، كانت هناك وحدة هجرات جانغو. هذه أيضًا وحدة جيدة جدًا للهجرات. مبدأه مشابه لـ Alembic في الوظيفة. الاختلاف الوحيد هو أنه خاص بإطار عمل معين ، بينما Alembic ليس كذلك.
SQLAlchemy
نظرًا لأن Alembic يعتمد على SQLAlchemy ، أقترح تشغيل بعض الشيء من خلال SQLAlchemy لتذكر أو معرفة ما هو عليه.

حتى الآن ، نظرنا في الاستفسارات الأولية. الاستعلامات الأولية ليست سيئة. هذا يمكن أن يكون جيدا جدا. عندما يكون لديك تطبيق محمّل بشكل كبير ، فربما يكون هذا هو بالضبط ما تحتاجه. لا داعي لإضاعة الوقت في تحويل بعض العناصر إلى نوع من الاستعلامات.
لا توجد مكتبات إضافية مطلوبة. أنت فقط تأخذ السائق وهذا كل شيء ، إنه يعمل. لكن على سبيل المثال ، إذا كتبت استعلامات معقدة ، فلن يكون الأمر بهذه السهولة: حسنًا ، يمكنك أن تأخذ ثابتًا ، تطرحه ، تكتب رمزًا كبيرًا متعدد الأسطر. ولكن إذا كان لديك 10-20 من هذه الطلبات ، فسيكون من الصعب جدًا قراءتها بالفعل. ثم لا يمكنك إعادة استخدامها بأي شكل من الأشكال. لديك الكثير من النصوص وبالطبع وظائف للعمل مع السلاسل والأوتار وكل ذلك ، لكن هذا لا يبدو جيدًا بالفعل. من الصعب قراءتها.
إذا كان لديك ، على سبيل المثال ، فئة تريد أيضًا أن يكون لديك فيها استعلامات وتركيبات معقدة ، فإن المسافة البادئة هي ألم شديد. إذا كنت ترغب في إجراء عملية ترحيل أولية ، فإن الطريقة الوحيدة لمعرفة مكان استخدام شيء ما هي باستخدام grep. وليس لديك أداة ديناميكية للاستعلامات الديناميكية أيضًا.
على سبيل المثال ، مهمة سهلة للغاية. لديك كيان يحتوي على 15 حقلاً في لوحة واحدة. تريد تقديم طلب التصحيح. يبدو أنه بسيط للغاية. حاول كتابة هذا على الاستفسارات الأولية. لن تبدو جميلة جدًا ، ومن غير المرجح أن تتم الموافقة على طلب السحب.

هناك بديل لهذا - منشئ الاستعلام. بالتأكيد لها عيوب لأنها تتيح لك تمثيل استفساراتك ككائنات في بايثون.
للراحة ، سيتعين عليك الدفع مقابل كل من وقت إنشاء الطلبات والذاكرة. لكن هناك إيجابيات. عندما تكتب تطبيقات كبيرة ومعقدة ، فإنك تحتاج إلى أفكار مجردة. يمكن لمنشئ الاستعلام أن يمنحك هذه الأفكار التجريدية. يمكن أن تتحلل هذه الاستعلامات ؛ سنرى كيف يتم ذلك بعد قليل. يمكن إعادة استخدامها أو توسيعها أو تغليفها بوظائف ستُطلق عليها بالفعل أسماء مألوفة مرتبطة بمنطق العمل.
من السهل جدًا إنشاء استعلامات ديناميكية. إذا كنت بحاجة إلى تغيير شيء ما ، فاكتب عملية ترحيل ، فالتحليل الإحصائي للرمز كافٍ. هذا مناسب جدا.
لماذا SQLAlchemy على أي حال؟ لماذا يستحق التوقف عند؟

هذا سؤال ليس فقط عن الهجرة ولكن بشكل عام. لأنه عندما يكون لدينا Alembic ، يكون من المنطقي استخدام المكدس بأكمله مرة واحدة ، لأن SQLAlchemy لا يعمل فقط مع برامج التشغيل المتزامنة. وهذا يعني أن Django أداة رائعة جدًا ، ولكن يمكن استخدام Alchemy ، على سبيل المثال ، مع asyncpg و aiopg . يسمح لك Asyncpg بقراءة ، كما قال Selivanov ، مليون سطر في الثانية - قراءة من قاعدة البيانات ونقلها إلى Python. بالطبع ، مع SQLAlchemy سيكون هناك القليل ، سيكون هناك بعض النفقات العامة. لكن على اي حال.
يحتوي SQLAlchemy على عدد لا يُصدق من برامج التشغيل التي يعرف كيفية التعامل معها. هناك Oracle و PostgreSQL ، وكل شيء يناسب كل ذوق ولون. علاوة على ذلك ، لقد خرجوا بالفعل من الصندوق ، وإذا كنت بحاجة إلى شيء منفصل ، فهناك ، لقد بحثت مؤخرًا ، هناك حتى Elasticsearch. صحيح ، للقراءة فقط ، لكن - هل تفهم؟ - Elasticsearch في SQLAlchemy.
هناك وثائق جيدة جدا ، ومجتمع كبير. يوجد الكثير من المكتبات. والمهم بعد كل شيء أنه لا يملي عليك الأطر والمكتبات. عندما تقوم بمهمة ضيقة يجب القيام بها بشكل جيد ، يمكن أن تكون أداة.
إذن ما الذي تتكون منه؟
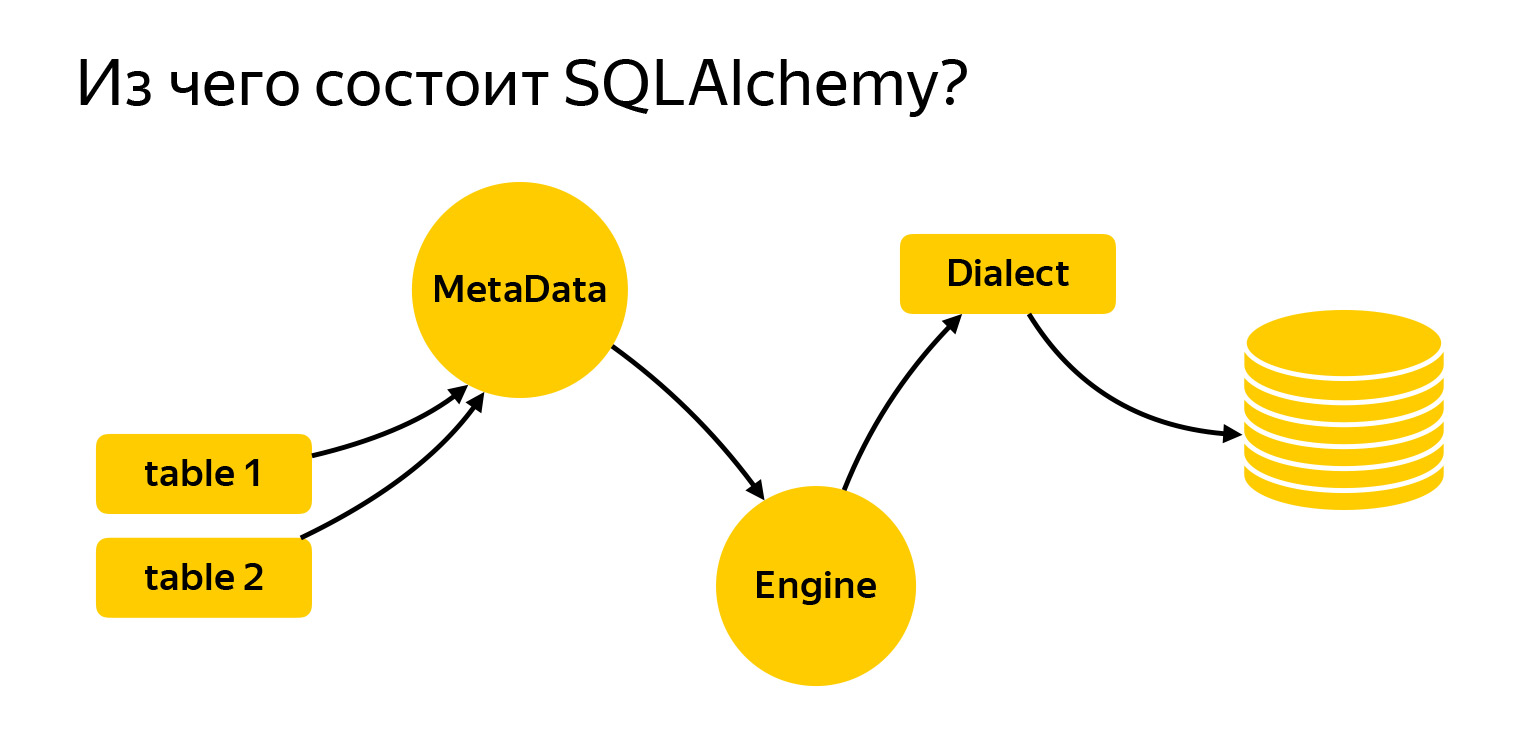
أحضرت هنا الكيانات الرئيسية التي سنعمل معها اليوم. هذه هي الجداول. لكتابة الطلبات ، يجب إخبار Alchemy بما هو عليه وما نعمل معه. التالي هو سجل MetaData. المحرك هو شيء يتصل بقاعدة البيانات ويتواصل معها من خلال اللهجة.
دعونا نلقي نظرة فاحصة على ما هو عليه.

MetaData هي نوع من الكائنات ، حاوية ، ستضيف إليها الجداول والفهارس ، وبشكل عام ، جميع الكيانات التي لديك. هذا كائن يعكس ، من ناحية ، كيف تريد أن ترى قاعدة البيانات ، بناءً على التعليمات البرمجية المكتوبة. من ناحية أخرى ، يمكن لـ MetaData الانتقال إلى قاعدة البيانات ، والحصول على لقطة لما هو موجود بالفعل ، وبناء نموذج الكائن نفسه.
أيضًا ، يحتوي كائن MetaData على ميزة واحدة مثيرة للاهتمام للغاية. يتيح لك تحديد قالب تسمية افتراضي للفهارس والقيود. هذا مهم جدًا عند كتابة عمليات الترحيل ، لأن كل قاعدة بيانات - سواء كانت PostgreSQL أو MySQL أو MariaDB - لها رؤيتها الخاصة بكيفية تسمية الفهارس.
بعض المطورين لديهم أيضًا رؤيتهم الخاصة. ويسمح لك SQLAlchemy بوضع معيار لكيفية عمله مرة واحدة وإلى الأبد. اضطررت إلى تطوير مشروع يحتاج إلى العمل مع كل من SQLite و PostgreSQL. كانت مريحة للغاية.

يبدو كالتالي: تقوم باستيراد كائن MetaData من SQLAlchemy وعندما تقوم بإنشائه ، فإنك تحدد قوالب باستخدام معلمة naming_convention ، والتي تشير مفاتيحها إلى أنواع الفهارس والقيود: ix هو فهرس عادي ، uq فهرس فريد ، fk هو مفتاح خارجي ، pk هو المفتاح الأساسي.
في قيم معلمة naming_convention ، يمكنك تحديد قالب يتكون من نوع / قيد الفهرس (ix / uq / fk ، إلخ) واسم الجدول ، مفصولاً بشرطة سفلية. في بعض القوالب ، يمكنك أيضًا سرد كافة الأعمدة. على سبيل المثال ، ليس من الضروري القيام بذلك للمفتاح الأساسي ، يمكنك ببساطة تحديد اسم الجدول.
عندما تبدأ في إنشاء مشروع جديد ، فإنك تضيف إليه قوالب تسمية مرة واحدة وتنسى. منذ ذلك الحين ، تم إنشاء جميع عمليات الترحيل بنفس أسماء الفهرس والقيد.
هذا مهم لسبب آخر: عندما تقرر أن هذا الفهرس لم يعد مطلوبًا في نموذج الكائن الخاص بك وقمت بحذفه ، فإن Alembic سيعرف ما يطلق عليه وسيولد الترحيل بشكل صحيح. هذا بالفعل ضمان معين للموثوقية ، وأن كل شيء سيعمل كما ينبغي.
كيان آخر مهم للغاية لا بد أن تصادفه هو الجدول ، وهو كائن يصف ما يحتويه الجدول.

يحتوي الجدول على اسم وأعمدة تحتوي على أنواع بيانات ، ويشير بالضرورة إلى سجل MetaData ، لأن MetaData هو سجل لكل ما تصفه. وهناك أعمدة بأنواع البيانات.
بفضل ما وصفناه ، يمكن لـ SQLAlchemy الآن معرفة الكثير. إذا حددنا مفتاحًا خارجيًا هنا ، فستظل تعرف كيف ترتبط طاولاتنا ببعضها البعض. وستعرف الترتيب الذي يجب القيام به.

يحتوي SQLAlchemy أيضًا على محرك. هام: يمكن استخدام ما قلناه عن الاستعلامات بشكل منفصل ، ويمكن استخدام المحرك بشكل منفصل. ويمكنك استخدام كل شيء معًا ، لا أحد يمنعه. أي أن المحرك يعرف كيفية الاتصال مباشرة بالخادم ويمنحك نفس الواجهة بالضبط. لا ، بالطبع ، يحاول السائقون المختلفون الامتثال لـ DBAPI ، فهناك مثل هذا PEP في Python يقدم توصيات. لكن المحرك يمنحك نفس الواجهة تمامًا لجميع قواعد البيانات ، وهي مريحة للغاية.

آخر معلم رئيسي هو اللهجة. هذه هي الطريقة التي يتواصل بها المحرك مع قواعد البيانات المختلفة. هناك لغات مختلفة وأشخاص مختلفون ولهجة مختلفة هنا.
دعونا نرى ما هو كل هذا.

هذا هو الشكل الذي سيبدو عليه الإدخال العادي. إذا أردنا إضافة سطر جديد ، اللوحة التي وصفناها سابقًا ، والتي يوجد بها حقل معرف وحقل بريد إلكتروني ، نحدد هنا البريد الإلكتروني ، ونقوم بالإدراج ، ونستعيد على الفور كل ما قمنا بإدخاله.
ماذا لو أردنا إضافة الكثير من الخطوط؟ ليس هناك أى مشكلة.

يمكنك ببساطة نقل قائمة الإملاءات هنا. يبدو وكأنه رمز مثالي لقلم بسيط للغاية. تم إدخال البيانات ، واجتازت نوعًا من التحقق من الصحة ، وبعض مخطط JSON ، وتم إدخال كل شيء في قاعدة البيانات. سهل للغاية.
بعض الاستفسارات معقدة للغاية. في بعض الأحيان يمكن عرض الطلب بطباعة ، وأحيانًا يتعين عليك تجميعه. هذا ليس بالأمر الصعب. تتيح لك Alchemy القيام بكل هذا. في هذه الحالة ، قمنا بتجميع الطلب ، ويمكنك رؤية ما سينتقل بالفعل إلى قاعدة البيانات.

يبدو طلب البيانات بسيطًا جدًا. حرفيا سطرين ، يمكنك حتى الكتابة في واحد.

لنعد إلى سؤالنا حول كيفية كتابة طلب التصحيح لـ 15 حقلاً على سبيل المثال. هنا يجب أن تكتب فقط اسم الحقل ومفتاحه وقيمته. هذا كل ما هو مطلوب. لا توجد ملفات ، لا بناء سلسلة ، لا شيء على الإطلاق. تبدو مريحة.
ربما تكون أهم ميزة Alchemy التي أستخدمها يوميًا في عملي هي تحليل الاستعلام وتوسيعه.

لنفترض أنك تكتب واجهة في PostgreSQL ، يجب أن يقوم تطبيقك بطريقة ما بتفويض شخص ما وتمكينه من أداء CRUD. حسنًا ، ليس هناك الكثير لتتحلل.
عندما تكتب تطبيقًا معقدًا للغاية يستخدم إصدار البيانات ، ومجموعة من التجريدات المختلفة ، يمكن أن تتكون الاستعلامات التي ستنشئها من عدد كبير من الاستعلامات الفرعية. الاستعلامات الفرعية مرتبطة باستعلامات فرعية. هناك مهام مختلفة. وأحيانًا يساعد تحليل الاستعلام كثيرًا ، فهو يسمح بفصل كبير بين تصميم المنطق والكود.
لماذا يعمل مثل هذا؟ عند استدعاء طريقة users_table.select () ، على سبيل المثال ، تقوم بإرجاع كائن. عندما تستدعي طريقة أخرى على الكائن الناتج ، مثل حيث () ، فإنها تُرجع كائنًا جديدًا تمامًا. جميع كائنات الاستعلام غير قابلة للتغيير. لذلك ، يمكنك البناء على أي شيء تريده.
الهجرات من الإنبيق
لذلك ، تعاملنا مع SQLAlchemy والآن يمكننا أخيرًا كتابة هجرات Alembic.

الشروع في استخدام Alembic ليس بالأمر الصعب على الإطلاق ، خاصة إذا كنت قد وصفت جداولك بالفعل ، كما قلنا سابقًا ، وحددت كائن MetaData. ما عليك سوى تثبيت alembic ، واستدعاء alembic init alembic. alembic - اسم الوحدة ، هذا هو سطر الأوامر ، سيكون لديك. init هو أمر. الوسيطة الأخيرة هي المجلد المطلوب وضعه فيه.
عند استدعاء هذا الأمر ، سيكون لديك العديد من الملفات ، والتي سنلقي نظرة فاحصة عليها الآن.

سيكون هناك تكوين عام في alembic.ini. script_location هو المكان الذي تريده بالضبط. بعد ذلك ، سيكون هناك نموذج لأسماء عمليات الترحيل التي ستنشئها ، ومعلومات للاتصال بقاعدة البيانات.

يوجد أيضًا نموذج لعمليات الترحيل الجديدة. أنت تقول ، "أريد ترحيلًا جديدًا" ، وسيقوم Alembic بإنشائه وفقًا لقالب معين. يمكنك تخصيص كل هذا ، الأمر بسيط للغاية. تذهب إلى هذا الملف وتحرير كل ما تريد. جميع المتغيرات التي يمكن تحديدها هنا موجودة في الوثائق. هذا هو الجزء الاول. يوجد نوع من التعليقات في الأعلى بحيث يكون من الملائم رؤية ما يحدث هناك. ثم هناك مجموعة من المتغيرات التي يجب أن تكون في كل عملية ترحيل - مراجعة ، down_revision. سنعمل معهم اليوم. علاوة على ذلك - معلومات وصفية إضافية.

أهم الطرق هي الترقية والخفض. سيستبدل Alembic هنا أي اختلاف يجده كائن MetaData بين وصف المخطط الخاص بك وما هو موجود في قاعدة البيانات.

env.py هو الملف الأكثر إثارة للاهتمام في Alembic. يتحكم في تقدم الأوامر ويسمح لك بتخصيصها بنفسك. في هذا الملف تقوم بتوصيل كائن MetaData الخاص بك. كما قلت من قبل ، فإن كائن MetaData هو السجل لجميع الكيانات في قاعدة البيانات الخاصة بك.
أنت تقوم بتوصيل كائن MetaData هذا هنا. ومنذ ذلك الوقت ، أدرك Alembic أنهم هنا ، نماذجي ، ها هم ، لوحاتي. إنه يفهم ما يعمل معه. بعد ذلك ، يحتوي Alembic على رمز يستدعي Alembic إما غير متصل بالإنترنت أو عبر الإنترنت. سننظر الآن أيضًا في كل هذا.
هذا هو بالضبط الخط الذي تحتاج إليه لتوصيل MetaData في مشروعك. لا تقلق إذا لم يكن هناك شيء واضح تمامًا ، فقد جمعت كل شيء في مشروع ونشرته على GitHub . يمكنك استنساخها ورؤيتها ، تشعر بكل شيء.

ما هو وضع الاتصال بالإنترنت؟ في وضع الاتصال ، يتصل Alembic بقاعدة البيانات المحددة في المعلمة sqlalchemy.url في ملف alembic.ini ويبدأ تشغيل عمليات الترحيل.
لماذا ننظر إلى هذا الجزء من الكود على الإطلاق؟ يمكن تخصيص Alembic بمرونة كبيرة.
تخيل أن لديك تطبيقًا يحتاج إلى العيش في مخططات قواعد بيانات مختلفة. على سبيل المثال ، تريد تشغيل الكثير من مثيلات التطبيق في وقت واحد ، وكل واحدة تعيش في مخططها الخاص. يمكن أن تكون مريحة وضرورية.
لا يكلفك أي شيء على الإطلاق. بعد استدعاء طريقة Context.begin_transaction () ، يمكنك كتابة الأمر "SET search_path = SCHEMA" ، والذي سيخبر PostgreSQL باستخدام مخطط افتراضي مختلف. و هذا كل شيء. من الآن فصاعدًا ، يعيش التطبيق الخاص بك في نظام مختلف تمامًا ، حيث يتم الانتقال إلى مخطط مختلف. هذا سؤال ذو سطر واحد.

هناك أيضًا وضع غير متصل بالشبكة. لاحظ أن Alembic لا تستخدم المحرك هنا. يمكنك ببساطة تمرير رابط له هنا. يمكنك بالطبع نقل المحرك أيضًا ، لكنه لا يتصل بأي مكان. إنه يولد فقط استعلامات أولية يمكنك تنفيذها في مكان ما.

لذلك ، لديك Alembic وبعض MetaData مع الجداول. وتريد أخيرًا إنشاء هجرات لنفسك. أنت تنفذ هذا الأمر ، وهذا هو الأساس. سوف يذهب Alembic إلى قاعدة البيانات ويرى ما هو هناك. هل هناك تسميته الخاصة "alembic_versions" ، والتي ستخبرك بأن عمليات الترحيل قد تم طرحها بالفعل في قاعدة البيانات هذه؟ سوف نرى ما هي الجداول الموجودة هناك. سوف نرى ما هي البيانات التي تحتاجها في قاعدة البيانات. سيقوم بتحليل كل هذا ، وإنشاء ملف جديد ، بناءً على هذا القالب فقط ، وسيكون لديك ترحيل. بالطبع ، يجب أن تنظر بالتأكيد إلى ما تم إنشاؤه في الترحيل ، لأن Alembic لا ينتج دائمًا ما تريد. لكن في معظم الأحيان يعمل.

ماذا أنشأنا؟ كان هناك تسجيل المستخدمين. عندما أنشأنا الترحيل ، أشرت إلى الرسالة الأولية. ستتم تسمية الترحيل بـ initial.py مع بعض القوالب الأخرى التي تم تحديدها مسبقًا في alembic.ini.
هناك أيضًا معلومات حول المعرف الذي يحتوي عليه هذا الترحيل. down_revision = None - هذه هي الهجرة الأولى.
ستكون الشريحة التالية هي الجزء الأكثر أهمية: الترقية والرجوع إلى إصدار أقدم.

في الترقية ، نرى أن لدينا لوحة يتم إنشاؤها. في الرجوع إلى إصدار أقدم ، تتم إزالة هذه العلامة. يضيف Alembic ، افتراضيًا ، مثل هذه التعليقات على وجه التحديد بحيث يمكنك الذهاب إلى هناك وتعديلها وحذف هذه التعليقات على الأقل. وفقط في حالة مراجعة الترحيل ، تأكد من أن كل شيء يناسبك. هذه مسألة فريق واحد. لديك بالفعل هجرة.

بعد ذلك ، من المرجح أنك تريد تطبيق هذا الترحيل. لا يمكن أن يكون الأمر أسهل. ما عليك سوى أن تقول: رئيس ترقية الإنبيق. سوف يطبق كل شيء على الاطلاق.
إذا قلنا head ، فسيحاول التحديث إلى أحدث عملية ترحيل. إذا قمنا بتسمية عملية ترحيل معينة ، فسيتم تحديثها إليها.
هناك أيضًا أمر الرجوع إلى إصدار أقدم - في حال غيرت رأيك على سبيل المثال. كل هذا يتم في المعاملات ويعمل بكل بساطة.

إذاً ، لديك هجرات ، أنت تعرف كيف تديرها. لديك تطبيق وأنت تسأل ، على سبيل المثال ، هذا السؤال: لدي CI ، والاختبارات قيد التشغيل ، ولا أعرف حتى ما إذا كنت أريد ، على سبيل المثال ، تشغيل عمليات الترحيل تلقائيًا؟ ربما من الأفضل أن تفعل ذلك بيديك؟
هناك وجهات نظر مختلفة هنا. ربما ، يجدر الالتزام بالقاعدة: إذا لم يكن لديك وصول سهل ، والقدرة على ركوب سيارة مع قاعدة بيانات ، فمن الأفضل بالطبع القيام بذلك تلقائيًا.
إذا كان لديك وصول ، فأنت تقوم بعمل خدمة تعمل في السحابة ، ويمكنك الذهاب إلى هناك من جهاز كمبيوتر محمول لديك دائمًا ، ثم يمكنك القيام بذلك بنفسك وبالتالي منح نفسك مزيدًا من التحكم.
بشكل عام ، هناك العديد من الأدوات للقيام بذلك تلقائيًا. على سبيل المثال ، في نفس Kubernetes. توجد حاويات init يمكنها القيام بذلك ويمكنك من خلالها تشغيل هذه الأوامر. يمكنك إضافة أمر تشغيل مباشرة إلى Docker للقيام بذلك.
ما عليك سوى التفكير: إذا قمت بتطبيق عمليات الترحيل تلقائيًا ، فأنت بحاجة إلى التفكير فيما يحدث ، على سبيل المثال ، إذا كنت تريد التراجع ، ولكن لا يمكنك ذلك. على سبيل المثال ، لديك لوحة بيانات سعة 500 جيجابايت من نوع ما. فكرت: حسنًا ، لم تعد هناك حاجة لهذه البيانات لمنطق الأعمال ، ربما يمكنك إسقاطها. أخذوها وأسقطوها. أو تغير نوع العمود الذي تغير مع فقدان البيانات. على سبيل المثال ، كان هناك خط طويل ، لكنه أصبح قصيرًا. أو شيء ما ذهب بعيدا. أو قمت بحذف عمود. لا يمكنك التراجع حتى لو كنت تريد ذلك.
في وقت من الأوقات ، قمت بتصنيع منتجات محلية ، يتم تثبيتها بواسطة ملف exe للأشخاص الموجودين مباشرة على الجهاز. بمجرد أن تفهم: نعم ، لقد كتبت الترحيل ، ودخل الإنتاج ، وقام الناس بالفعل بتثبيته. في السنوات الخمس المقبلة ، قد يعمل من أجلهم وفقًا لاتفاقية مستوى الخدمة ، وتريد تغيير شيء ما ، فقد يكون هناك شيء أفضل. في هذه اللحظة ، تفكر في كيفية التعامل مع التغييرات التي لا رجعة فيها.

لا يوجد علم الصواريخ هنا أيضًا. الفكرة هي أنه يمكنك تجنب استخدام هذه الأعمدة أو استخدام الجداول قدر الإمكان. توقف عن الاتصال بهم. يمكنك ، على سبيل المثال ، تعليم الحقول في ORM بمصمم خاص. سيقول في السجلات أنك يبدو أنك لا تريد لمس هذا الحقل ، لكنك ما زلت تشير إليه. ما عليك سوى إنشاء مهمة في الأعمال المتأخرة وحذفها يومًا ما.
أنت ، إذا كان هناك أي شيء ، سيكون لديك وقت للتراجع. وإذا سارت الأمور على ما يرام ، فستقوم بهذه المهمة بهدوء لاحقًا في وقت متأخر. قم بإجراء عملية ترحيل أخرى من شأنها حذف كل شيء بالفعل.
الآن لأهم سؤال: لماذا وكيف نختبر الهجرات؟

قلة من الأشخاص الذين سألتهم يفعلون ذلك. لكن من الأفضل القيام بذلك. وهذه قاعدة مكتوبة في الألم والدم والعرق. استخدام الهجرة في الإنتاج دائمًا محفوف بالمخاطر. أنت لا تعرف أبدا كيف يمكن أن تنتهي. حتى الترحيل الجيد جدًا على إنتاج يعمل بشكل طبيعي تمامًا ، عندما يكون لديك CI مهيأ ، يمكن أن يكون رعشة.
الحقيقة هي أنه عند اختبار عمليات الترحيل ، يمكنك حتى تنزيل ، على سبيل المثال ، مرحلة أو جزء من الإنتاج. يمكن أن يكون الإنتاج كبيرًا ، ولا يمكنك تنزيله بالكامل للاختبارات أو المهام الأخرى. قواعد التنمية ، كقاعدة عامة ، ليست في الواقع قواعد إنتاج. ليس لديهم الكثير مما كان يمكن أن يتراكم على مر السنين.

يمكن أن تكون هذه بيانات تالفة ، عندما نقوم بترحيل شيء ما ، أو برامج قديمة جلبت البيانات إلى حالة غير متناسقة. يمكن أن تكون أيضًا تبعيات ضمنية - إذا نسي شخص ما إضافة مفتاح خارجي. يعتقد أنها مرتبطة ببعضها البعض ، لكن زملائه ، على سبيل المثال ، لا يعرفون عنها. تسمى الحقول أيضًا بالصدفة ، وليس من الواضح عمومًا أنها متصلة.
ثم قرر أحدهم الدخول وإضافة نوع من الفهرس مباشرة إلى الإنتاج ، لأنه "يتباطأ الآن ، ولكن ماذا لو بدأ العمل بشكل أسرع؟" ربما أبالغ ، لكن الناس أحيانًا يغيرون شيئًا ما بشكل صحيح في قواعد البيانات.
هناك ، بالطبع ، أخطاء في الأدوات ، في ترحيل المخطط. لأكون صادقًا ، لم أجد هذا. كانت هناك عادة المشاكل الثلاثة الأولى. وربما المزيد من الأخطاء في الافتراضات حول كيفية نقل البيانات.
عندما يكون لديك نموذج كائن كبير جدًا ، قد يكون من الصعب وضع كل شيء في الاعتبار. من الصعب كتابة وثائق حديثة باستمرار. التوثيق الأحدث هو الكود الخاص بك ، ولا يحتوي دائمًا على منطق عمل مكتوب بالكامل: ماذا وكيف يجب أن يعمل ، من كان يدور في ذهنه.

ماذا يمكننا التحقق؟ على الأقل حقيقة أن الهجرة تبدأ. هذا رائع بالفعل. وأنه لا توجد أخطاء مطبعية غبية في الكود. يمكننا التحقق من وجود طريقة صالحة للرجوع إلى إصدار أقدم () ، وأن طريقة الرجوع إلى إصدار أقدم () تحذف جميع أنواع البيانات التي تم إنشاؤها بواسطة SQLAlchemy.
تقوم SQLAlchemy بالعديد من الأشياء الجميلة. على سبيل المثال ، عندما تصف جدولًا وتحدد نوع عمود التعداد ، فإن SQLAlchemy ستنشئ تلقائيًا نوع البيانات لهذا التعداد في PostgreSQL. ولكن لن يتم إنشاء الكود المطلوب لإزالة نوع البيانات هذا في طريقة الرجوع إلى إصدار أقدم () تلقائيًا.
يجب أن تتذكر وتحقق هذا: عندما تريد التراجع عن الترحيل وإعادة تطبيقه ، فإن محاولة إنشاء نوع بيانات موجود في طريقة الترقية () ستؤدي إلى استثناء. والأهم من ذلك ، إذا غيرت عملية الترحيل أي بيانات ، فستحتاج إلى التحقق من أن البيانات تتغير بشكل صحيح في الترقية. ومن المهم جدًا التحقق من أنها تتراجع بشكل صحيح في الرجوع إلى إصدار سابق دون آثار جانبية.

قبل الانتقال إلى الاختبارات نفسها ، دعونا نرى أفضل طريقة للتحضير لكتابتها. لقد رأيت العديد من الطرق لذلك. ينشئ بعض الأشخاص قاعدة ، وألواح ، ثم يكتبون أداة تنظف كل شيء ، ويستخدمون نوعًا من تركيبات التطبيق التلقائي . لكن الطريقة المثالية التي ستحميك بنسبة 100٪ وستجري اختبارات في مساحة معزولة تمامًا هي إنشاء قاعدة بيانات منفصلة.
هناك وحدة sqlalchemy_utils رائعة يمكنها إنشاء وحذف قواعد البيانات. في PostgreSQL ، يتحقق أيضًا: إذا نام أحد العملاء ولم ينفصل ، فلن يتعطل بسبب الخطأ القائل "شخص ما يستخدم قاعدة البيانات ، لا يمكنني فعل أي شيء بها ، ولا يمكنني حذفها". بدلاً من ذلك ، سيرى بهدوء من الذي اتصل بهم ، ويفصل هؤلاء العملاء ويحذف القاعدة بهدوء.
لا يعد إنشاء قاعدة بيانات وتطبيق الترحيل على كل اختبار عملية سريعة دائمًا. يمكن حل ذلك على النحو التالي: تدعم PostgreSQL إنشاء قواعد بيانات جديدة من قالب ، بحيث يمكنك تقسيم إعداد قاعدة البيانات إلى مبادتين.
يتم تشغيل الأداة الأولى مرة واحدة لتشغيل جميع الاختبارات (النطاق = جلسة) ، وإنشاء قاعدة بيانات وتطبيق عمليات الترحيل عليها. تقوم الأداة الثانية (النطاق = الوظيفة) بإنشاء قواعد مباشرة لكل اختبار بناءً على القاعدة من المباراة الأولى.
يعد إنشاء قاعدة بيانات من قالب سريعًا جدًا ويوفر الوقت عند تطبيق عمليات الترحيل لكل اختبار.

إذا كنا نتحدث فقط عن كيفية إنشاء قاعدة بيانات بشكل مؤقت ، فيمكننا كتابة مثل هذا التثبيت. ماذا يحدث هنا؟ سنقوم بإنشاء اسم عشوائي. نضيف ، فقط في حالة ، إلى نهاية pytest ، بحيث عندما نذهب إلى المضيف المحلي لأنفسنا من خلال بعض Postico ، يمكننا فهم ما تم إنشاؤه بواسطة الاختبارات وما لم يتم إنشاؤه.
ثم ننشئ من الرابط معلومات حول الاتصال بقاعدة البيانات ، والتي أظهرها الشخص ، واحدة جديدة ، بالفعل مع قاعدة بيانات جديدة. نقوم بإنشائه وإرساله إلى الاختبارات. بعد أن يعمل الشخص مع قاعدة البيانات هذه ، نقوم بحذفها.

يمكننا أيضًا تجهيز المحرك للاتصال بقاعدة البيانات هذه. وهذا يعني ، في هذه المباراة ، نشير إلى التركيبات السابقة المستخدمة كتبعية. نقوم بإنشاء محرك وإرساله للاختبارات.

إذن ما هي الاختبارات التي يمكننا كتابتها؟ الاختبار الأول هو مجرد اختراع رائع من زميلي. منذ ظهوره ، أعتقد أنني نسيت مشاكل الهجرة.
هذا اختبار بسيط للغاية. يمكنك إضافته إلى مشروعك مرة واحدة. إنه موجود في المشروع على جيثب... يمكنك فقط سحبها إليك ، وإضافة ونسيان ، ربما ، حوالي 80 بالمائة من المشاكل.
إنه يفعل شيئًا بسيطًا للغاية: فهو يحصل على قائمة بجميع عمليات الترحيل ويبدأ في تكرارها. ترقية المكالمات ، الرجوع إلى إصدار أقدم ، الترقية.

على سبيل المثال ، لدينا خمس هجرات. دعونا نرى كيف يعمل. ها هي الهجرة الأولى. لقد حققناها. التراجع عن الترحيل الأول ، قم بتشغيله مرة أخرى. ماذا حدث هنا؟ في الواقع ، رأينا هنا أن شخصًا ما طبق طريقة الرجوع إلى إصدار أقدم () بشكل صحيح ، لأنه لم يكن من الممكن إنشاء جداول مرتين ، على سبيل المثال.
نرى أنه إذا قام شخص ما بإنشاء بعض أنواع البيانات ، فإنه يقوم أيضًا بحذفها ، لأنه لا توجد أخطاء إملائية وعمومًا يعمل بطريقة ما.
ثم ينتقل الاختبار. يأخذ الترحيل الثاني ، يركض إليه على الفور ، يتراجع خطوة واحدة ، ويركض للأمام مرة أخرى. وهذا يحدث في عدد المرات التي تحدث فيها الهجرات.
الغرض من هذا الاختبار هو العثور على الأخطاء الأساسية والمشاكل عند تغيير بنية البيانات.
يبدأ السلم على قاعدة فارغة وعادة ما يكون سريعًا جدًا. أي أن هذا الاختبار يتعلق أكثر بهيكل البيانات. لا يتعلق الأمر بتغيير البيانات في عمليات الترحيل. لكن بشكل عام ، يمكن أن تنقذ حياتك جيدًا.
إذا كنت تريد إصلاحًا سريعًا ، فهذا هو. هذه القاعدة. كقاعدة عامة: أدخله في مشروعك ، وسيصبح الأمر أسهل بالنسبة لك.

هذا الاختبار يبدو مثل هذا. نحصل على جميع المراجعات ، وننشئ ملف التكوين Alembic. هذا ما رأيناه من قبل ، ملف alembic.ini ، ها هي وظيفة get_alembic_config ، تقرأ هذا الملف ، وتضيف قاعدتنا المؤقتة إليه ، لأننا حددنا المسار إلى القاعدة هناك. وبعد ذلك يمكننا استخدام أوامر Alembic.
يمكن أيضًا استيراد الأمر المنفذ سابقًا - رأس ترقية الإنبيق - بأمان. لسوء الحظ ، لا تناسب هذه الشريحة جميع الواردات ، لكن خذ كلامي على عاتقها. انها فقط من ترقية استيراد alembic.com. تقوم بترجمة التكوين هناك ، وإخبار المكان الذي يجب أن تذهب إليه من خلال الترقية. ثم قل: الرجوع إلى إصدار سابق.
مع الرجوع إلى إصدار أقدم ، يتم إرجاع الترحيل إلى down_revision ، أي إلى المراجعة السابقة ، أو إلى "-1".
"-1" طريقة بديلة لإخبار Alembic بالتراجع عن الترحيل الحالي. إنها وثيقة الصلة عندما يبدأ الترحيل الأول ، down_revision الخاص به هو None ، في حين أن Alembic API لا تسمح بتمرير أي شيء لأمر الرجوع إلى إصدار أقدم.
ثم يتم تشغيل أمر الترقية مرة أخرى.
الآن دعنا نتحدث عن كيفية اختبار عمليات الترحيل مع البيانات.

عمليات ترحيل البيانات هي نوع من الأشياء التي تبدو بسيطة جدًا في العادة ، ولكنها مؤلمة للغاية. يبدو أن كتابة بعض التحديد والإدراج وأخذ البيانات من جدول واحد ونقلها إلى تنسيق مختلف قليلاً - ما الذي يمكن أن يكون أبسط؟
يبقى أن يقال عن هذا الاختبار ، على عكس الاختبار السابق ، أنه مكلف للغاية لتطويره. عندما قمت بهجرات كبيرة ، استغرق الأمر في بعض الأحيان ست ساعات للنظر في جميع الثوابت ، لا بأس في وصف كل شيء. لكن عندما كنت أقوم بالفعل بتدوير هذه الهجرات ، كنت هادئًا.

كيف يعمل هذا الاختبار؟ الفكرة هي أننا نطبق جميع عمليات الترحيل على التي نريد اختبارها الآن. ندرج في قاعدة البيانات مجموعة من البيانات التي ستتغير. يمكننا التفكير في إدخال بيانات إضافية قد تتغير ضمنيًا. ثم نقوم بالترقية. نتحقق من أن البيانات قد تم تغييرها بشكل صحيح ، وننفذ عملية الرجوع إلى إصدار أقدم ، ونتحقق من تغيير البيانات بشكل صحيح.

يبدو الرمز مثل هذا. أي أن هناك أيضًا معلمات عن طريق المراجعة ، وهناك مجموعة من المعلمات. نقبل محركنا هنا ، ونقبل الترحيل الذي نريد بدء الاختبار به.
ثم rev_head ، وهو ما نريد اختباره. ثم ثلاث نداءات. هذه هي عمليات الاسترجاعات التي نحددها في مكان ما ، وسيتم استدعاؤها بعد إجراء شيء ما. يمكننا التحقق مما يحدث هناك.
أين يمكنني رؤية مثال؟
لقد جمعت كل ذلك في مثال على GitHub . لا يوجد بالفعل الكثير من التعليمات البرمجية ، ولكن من الصعب جدًا إضافتها إلى الشريحة. حاولت أن أتحمل أبسط. يمكنك الانتقال إلى GitHub ومعرفة كيفية عمله في المشروع نفسه ، وستكون هذه أسهل طريقة.
ما الذي يستحق الانتباه إليه أيضًا؟ أثناء بدء التشغيل ، يبحث Alembic عن ملف تكوين alembic.ini في المجلد الذي تم تشغيله فيه. بالطبع ، يمكنك تحديد المسار باستخدام متغير البيئة ALEMBIC_CONFIG ، لكن هذا ليس مناسبًا وواضحًا دائمًا.
مشكلة أخرى: يتم تحديد معلومات الاتصال بقاعدة البيانات في alembic.ini ، ولكن غالبًا ما تحتاج إلى أن تكون قادرًا على العمل مع عدة قواعد بيانات بدورها. على سبيل المثال ، قم بطرح عمليات الترحيل على المرحلة ثم للحث. بشكل عام ، يمكنك تحديد معلومات الاتصال في متغير البيئة SQLALCHEMY_URL ، ولكن هذا ليس واضحًا جدًا للمستخدمين النهائيين لبرنامجك.
سيكون استخدام الأداة المساعدة $ -db $ project أكثر سهولة للمستخدمين النهائيين من استخدام alembic.
عندما تنظر إلى الأمثلة الموجودة في المشروع ، ألق نظرة على الأداة المساعدة staff-db. هذا غلاف رفيع حول Alembic وطريقة أخرى لتخصيص Alembic من أجلك. بشكل افتراضي ، يبحث عن ملف alembic.ini في المشروع بالنسبة لموقعه. من أي مجلد يسميها المستخدمون ، ستجد هي نفسها ملف التكوين. أيضًا ، يضيف staff-db وسيطة --db-url ، والتي يمكنك من خلالها تحديد معلومات للاتصال بقاعدة البيانات. والأهم من ذلك ، يمكنك مشاهدته من خلال تمرير خيار المساعدة المقبول عمومًا. بعد كل شيء ، اسم الأداة بديهية.
تبدأ جميع أوامر المشروع القابلة للتنفيذ باسم الوحدة النمطية "للموظفين": staff-api ، التي تدير REST API ، و staff-db ، التي تدير الحالة الأساسية. من خلال فهم هذا النمط ، سيكتب العميل اسم البرنامج الخاص بك وسيكون قادرًا على رؤية جميع الأدوات المساعدة المتاحة بالضغط على مفتاح TAB ، حتى لو نسي الاسم الكامل. لدي كل شيء ، شكرا.