المقدمة
تتكون بنية الشبكة العصبية التلافيفية (CNN) RetinaNet من 4 أجزاء رئيسية ، لكل منها غرضه الخاص:
أ) العمود الفقري - الشبكة الرئيسية (الأساسية) المستخدمة لاستخراج الميزات من صورة الإدخال. هذا الجزء من الشبكة متغير وقد يشمل تصنيف الشبكات العصبية مثل ResNet و VGG و EfficientNet وغيرها.
ب) Feature Pyramid Net (FPN) - شبكة عصبية تلافيفية ، مبنية على شكل هرم ، تعمل على الجمع بين مزايا الخرائط المميزة للمستويات الدنيا والعليا من الشبكة ، تتمتع الأولى بدقة عالية ، ولكن ذات دلالة منخفضة ، وتعميم القدرة ؛ على العكس ؛
ج) الشبكة الفرعية للتصنيف - شبكة فرعية تستخرج معلومات حول فئات الكائن من FPN ، وتحل مشكلة التصنيف ؛
د) شبكة الانحدار الفرعية - شبكة فرعية تستخرج معلومات حول إحداثيات الكائنات في الصورة من FPN ، وتحل مشكلة الانحدار.
في التين. يوضح الشكل 1 بنية RetinaNet مع الشبكة العصبية ResNet باعتبارها العمود الفقري.
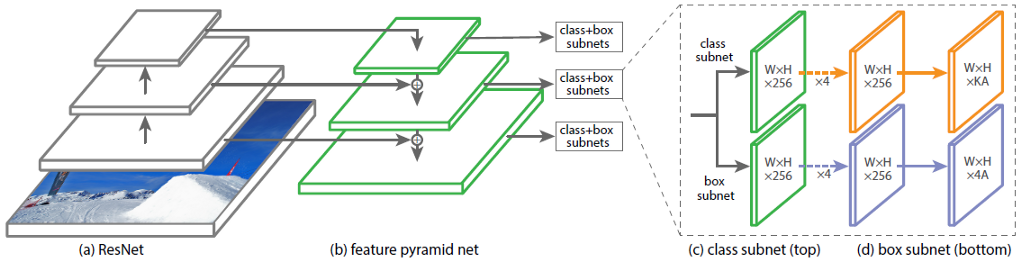
الشكل 1 - بنية RetinaNet مع العمود الفقري ResNet
دعونا نحلل بالتفصيل كل جزء من أجزاء RetinaNet الموضحة في الشكل. 1.
العمود الفقري هو جزء من شبكة RetinaNet
بالنظر إلى أن جزء بنية RetinaNet الذي يقبل صورة كمدخل ويسلط الضوء على الميزات المهمة متغير وأن المعلومات المستخرجة من هذا الجزء ستتم معالجتها في المراحل التالية ، من المهم اختيار شبكة أساسية مناسبة للحصول على أفضل النتائج.
أدت الأبحاث الحديثة حول تحسين CNN إلى تطوير نماذج التصنيف التي تتفوق على جميع البنى المطورة سابقًا بأفضل معدلات الدقة في مجموعة بيانات ImageNet مع تحسين الكفاءة بمقدار 10 مرات. تم تسمية هذه الشبكات EfficientNet-B (0-7). يتم عرض مؤشرات عائلة الشبكات الجديدة في الشكل. 2.
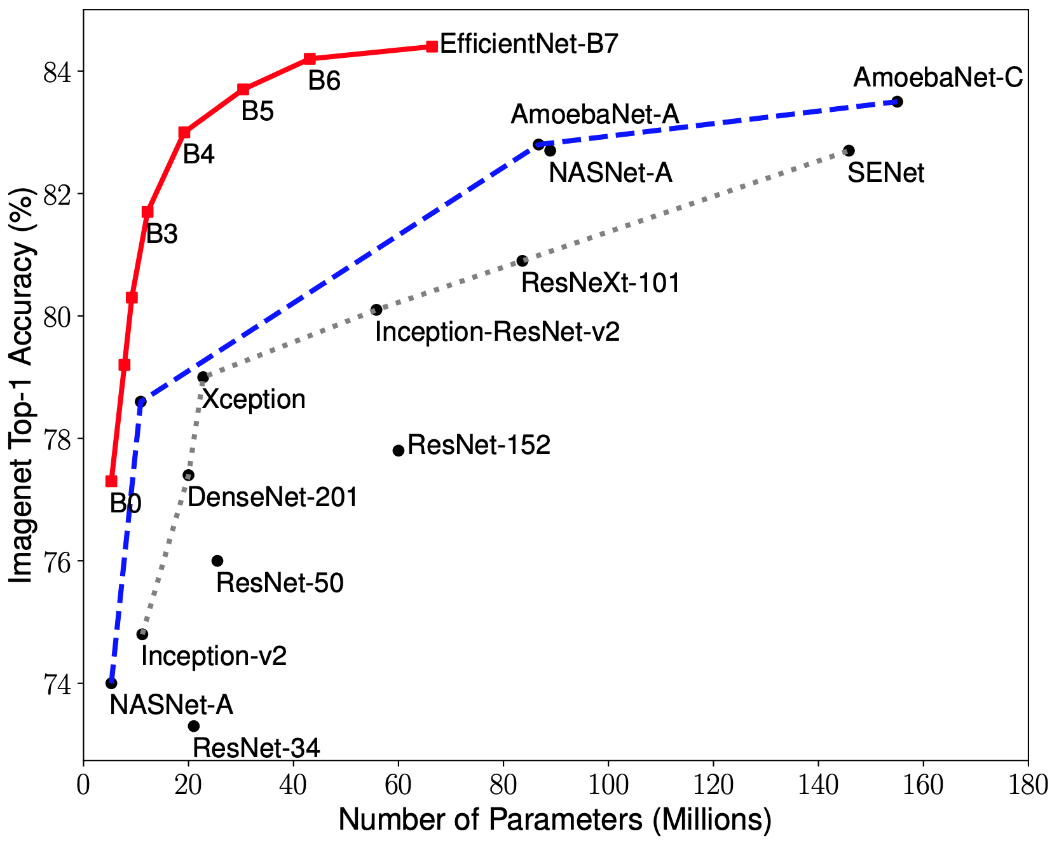
الشكل 2 - رسم بياني لاعتماد مؤشر الدقة الأعلى على عدد أوزان الشبكة لمختلف الهياكل
هرم العلامات
تتكون شبكة الهرم المميز من ثلاثة أجزاء رئيسية: المسار من الأسفل إلى الأعلى ، المسار من أعلى إلى أسفل ، والوصلات الجانبية.
المسار الصاعد هو نوع من "الهرم" الهرمي - سلسلة من الطبقات التلافيفية ذات البعد المتناقص ، في حالتنا - شبكة العمود الفقري. الطبقات العليا للشبكة التلافيفية لها معنى أكثر دلالة ، ولكن دقة أقل ، والأدنى منها ، على العكس (الشكل 3). يحتوي المسار من أسفل لأعلى على ثغرة في استخراج الميزات - فقدان المعلومات المهمة حول كائن ، على سبيل المثال ، بسبب ضجيج كائن صغير ولكنه مهم في الخلفية ، حيث أنه بحلول نهاية الشبكة ، يتم ضغط المعلومات وتعميمها بشكل كبير.
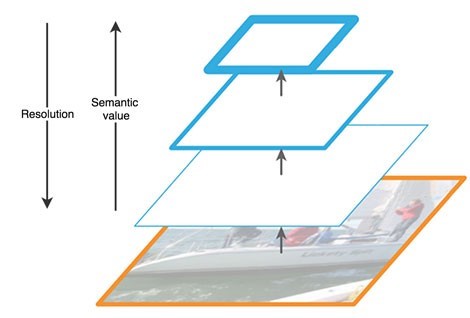
الشكل 3 - ملامح خرائط المعالم على مستويات مختلفة من الشبكة العصبية
المسار الهابط هو أيضا "هرم". خرائط المعالم للطبقة العليا من هذا الهرم لها حجم خرائط المعالم للطبقة العليا من أسفل الهرم ، ويتم مضاعفتها بأقرب طريقة مجاورة (الشكل 4) للأسفل.
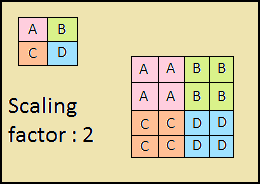
الشكل 4 - زيادة دقة الصورة عن طريق أقرب طريقة مجاورة
وهكذا ، في الشبكة من أعلى إلى أسفل ، يتم زيادة كل خريطة معلم للطبقة المتراكبة إلى حجم الخريطة الأساسية. بالإضافة إلى ذلك ، توجد اتصالات جانبية في FPN ، مما يعني أن الخرائط المميزة للطبقات المقابلة من أعلى إلى أسفل وأعلى من الأهرامات يتم إضافتها عنصرًا بعنصر ، ويتم طي الخرائط من الأسفل إلى الأعلى 1 * 1. تظهر هذه العملية بشكل تخطيطي في الشكل. 5.
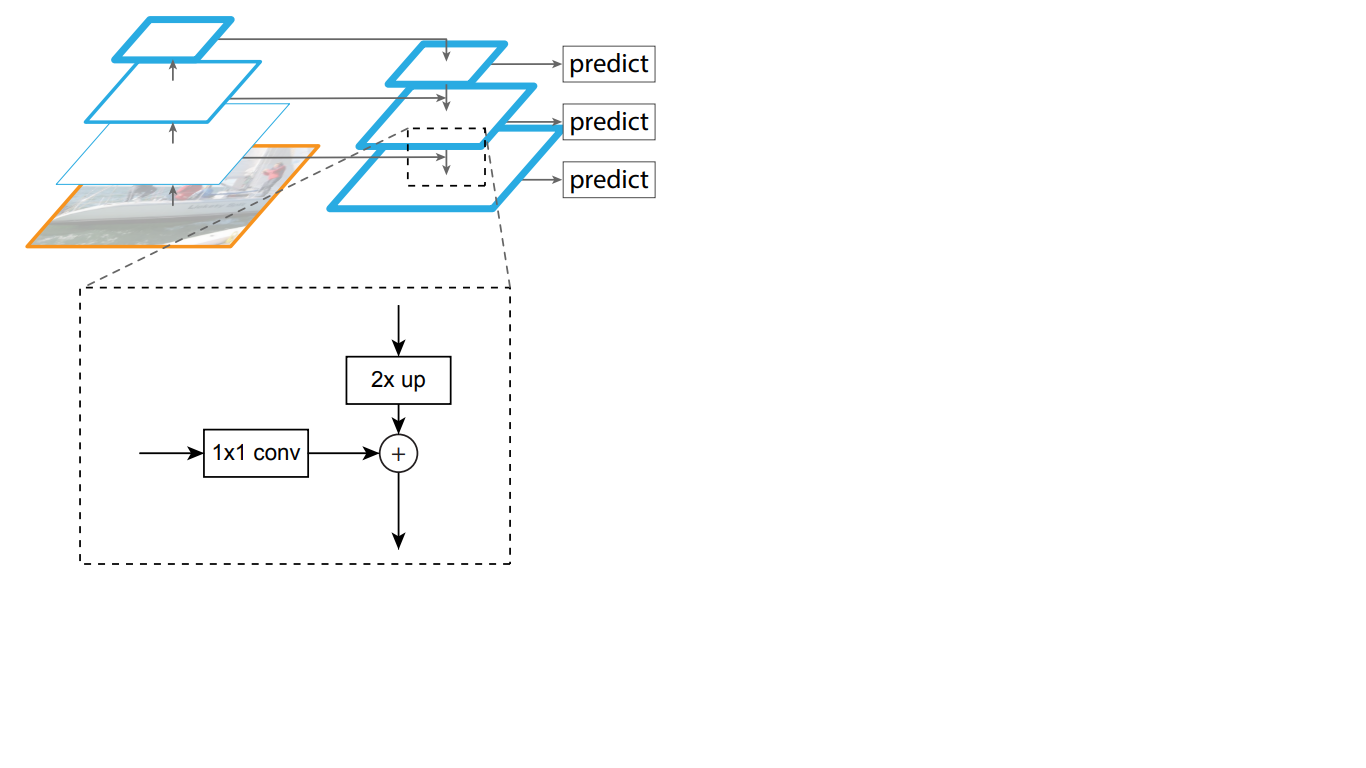
الشكل 5 - هيكل هرم العلامات
تحل الاتصالات الجانبية مشكلة توهين الإشارات المهمة في عملية المرور عبر الطبقات ، وتجمع بين المعلومات المهمة دلالة التي يتم تلقيها في نهاية الهرم الأول ومعلومات أكثر تفصيلاً تم الحصول عليها سابقًا.
علاوة على ذلك ، تتم معالجة كل من الطبقات الناتجة في الهرم من أعلى لأسفل بواسطة شبكتين فرعيتين.
تصنيف الشبكات الفرعية والانحدار
الجزء الثالث من بنية RetinaNet هو شبكتان فرعيتان: التصنيف والانحدار (الشكل 6). كل من هذه الشبكات الفرعية تشكل عند الإخراج استجابة حول فئة الكائن وموقعه على الصورة. دعونا نفكر في كيفية عمل كل منهم.
الشكل 6 - الشبكات الفرعية RetinaNet
لا يختلف الفرق في مبادئ الكتل المدروسة (الشبكات الفرعية) حتى الطبقة الأخيرة. تتكون كل منها من 4 طبقات من الشبكات التلافيفية. يتم تشكيل 256 خريطة معالم في الطبقة. في الطبقة الخامسة ، يتغير عدد خرائط المعالم: تحتوي الشبكة الفرعية للانحدار على 4 * خرائط معالم ، والشبكة الفرعية للتصنيف لديها خرائط معالم K * A ، حيث A هو عدد إطارات الارتساء (وصف مفصل لإطارات الارتساء في القسم الفرعي التالي) ، K هو عدد فئات الكائنات.
في الطبقة الأخيرة ، السادسة ، يتم تحويل كل خريطة معالم إلى مجموعة من المتجهات. يحتوي نموذج الانحدار عند المخرج على كل صندوق إرساء متجهًا من 4 قيم تشير إلى إزاحة صندوق الحقيقة الأرضية بالنسبة إلى صندوق الإرساء. يحتوي نموذج التصنيف على متجه ساخن واحد للطول K عند الخرج لكل إطار مرساة ، حيث يتوافق الفهرس مع القيمة 1 مع رقم الفئة الذي خصصته الشبكة العصبية للكائن.
إطارات المرساة
في القسم الأخير ، تم استخدام مصطلح إطارات المرساة. صندوق الإرساء عبارة عن معلمة مفرطة من كاشفات الشبكات العصبية ، وهو مستطيل محدد مسبقًا فيما يتعلق بالشبكة.
لنفترض أن الشبكة لديها خريطة ميزات 3 * 3 عند الإخراج. في RetinaNet ، تحتوي كل خلية على 9 مربعات ربط ، لكل منها حجم ونسبة عرض إلى ارتفاع مختلفة (الشكل 7). أثناء التدريب ، تتطابق إطارات المرساة مع كل إطار هدف. إذا كانت قيمة IoU الخاصة بهم تحتوي على قيمة 0.5 ، فسيتم تعيين إطار الارتساء كهدف ، إذا كانت القيمة أقل من 0.4 ، فسيتم اعتبارها في الخلفية ، وفي حالات أخرى سيتم تجاهل إطار الارتساء للتدريب. يتم تدريب شبكة التصنيف نسبة إلى المهمة المعينة (فئة الكائن أو الخلفية) ، يتم تدريب شبكة الانحدار نسبة إلى إحداثيات إطار المرساة (من المهم ملاحظة أن الخطأ يتم حسابه بالنسبة لإطار الربط ، ولكن ليس الإطار الهدف).
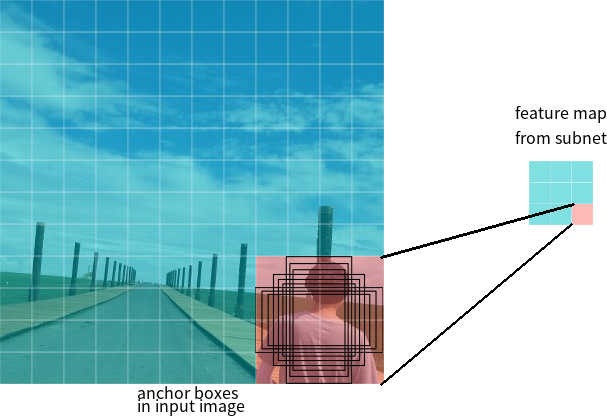
الشكل 7 - إطارات الربط لخلية واحدة من خريطة المعالم بحجم 3 * 3
وظائف الخسارة
خسائر RetinaNet مركبة ، وتتكون من قيمتين: خطأ الانحدار أو التوطين (يشار إليه باسم Lloc أدناه) وخطأ التصنيف (المشار إليه باسم Lcls أدناه). يمكن كتابة دالة الخسارة العامة على النحو التالي:
حيث λ هي معلمة مفرطة تتحكم في التوازن بين الخسارين.
دعونا نفكر بمزيد من التفصيل في حساب كل خسارة.
كما هو موضح سابقًا ، يتم تعيين مرساة لكل إطار هدف. لنشير إلى هذه الأزواج على أنها (Ai، Gi) i = 1، ... N ، حيث تمثل A نقطة الارتساء ، و G هي الإطار المستهدف ، و N هو عدد الأزواج المتطابقة.
لكل مرساة ، تتوقع شبكة الانحدار 4 أرقام ، والتي يمكن الإشارة إليها بـ Pi = (Pix ، Piy ، Piw ، Pih). يمثل الزوجان الأولان الفرق المتوقع بين إحداثيات مراكز المرساة Ai والإطار المستهدف Gi ، ويمثل الزوجان الأخيران الفرق المتوقع بين عرضهما وارتفاعهما. وفقًا لذلك ، لكل إطار هدف ، يتم حساب Ti على أنه الفرق بين المرساة والأطر المستهدفة:
حيث يتم تعريف smoothL1 (x) بالصيغة التالية:
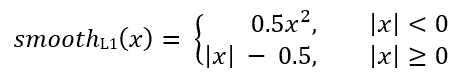
يتم حساب خسارة مشكلة تصنيف RetinaNet باستخدام وظيفة فقدان البؤرة.
حيث K هو عدد الفئات ، و yi هي القيمة المستهدفة للفئة ، و p هي احتمال التنبؤ بالفئة i ، و γ هي معلمة التركيز ، و α هي معامل التحيز. هذه الميزة هي ميزة متقدمة عبر الكون. يكمن الاختلاف في إضافة المعلمة γ∈ (0 ، + ∞) ، التي تحل مشكلة اختلال التوازن الطبقي. أثناء التدريب ، تكون معظم الكائنات التي تمت معالجتها بواسطة المصنف هي الخلفية ، وهي فئة منفصلة. لذلك ، قد تنشأ مشكلة عندما تتعلم الشبكة العصبية تحديد الخلفية بشكل أفضل من الأشياء الأخرى. أدت إضافة معلمة جديدة إلى حل هذه المشكلة عن طريق تقليل قيمة الخطأ للكائنات المصنفة بسهولة. يوضح الشكل 8 الرسوم البيانية للوظائف البؤرية والداخلية.
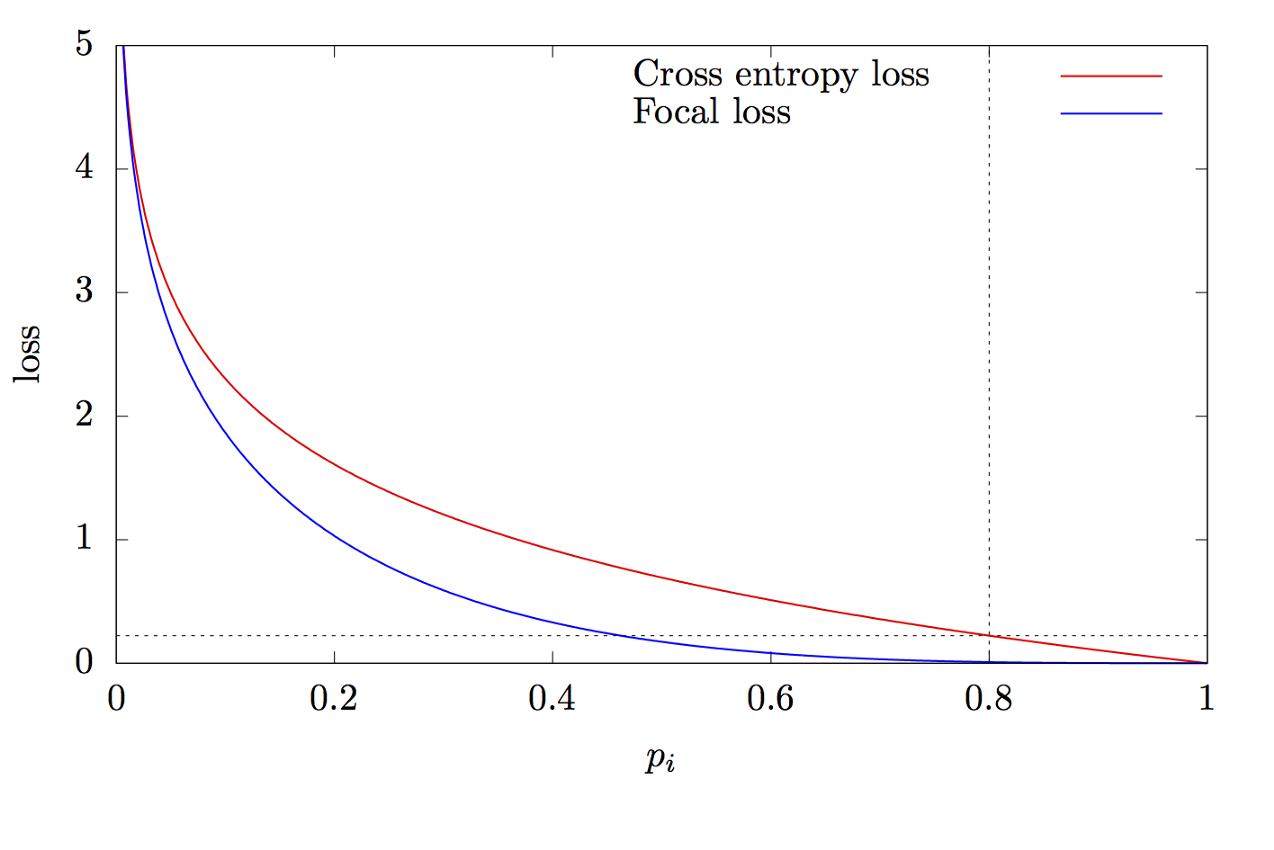
الشكل 8 - الرسوم البيانية للوظائف البؤرية وعبر الإنتروبيا
شكرا لقراءة هذا المقال!
قائمة المصادر:
- Tan M., Le Q. V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 2019. URL: arxiv.org/abs/1905.11946
- Zeng N. RetinaNet Explained and Demystified [ ]. 2018 URL: blog.zenggyu.com/en/post/2018-12-05/retinanet-explained-and-demystified
- Review: RetinaNet — Focal Loss (Object Detection) [ ]. 2019 URL: towardsdatascience.com/review-retinanet-focal-loss-object-detection-38fba6afabe4
- Tsung-Yi Lin Focal Loss for Dense Object Detection. 2017. URL: arxiv.org/abs/1708.02002
- The intuition behind RetinaNet [ ]. 2018 URL: medium.com/@14prakash/the-intuition-behind-retinanet-eb636755607d