ولكن ، نظرًا لأن الناس ليسوا أجهزة كمبيوتر ، فهم يبحثون عن شيء مثل " شيء من هذا القبيل كان من إيفانوف أو من إيفانوفسكي ... لا ، ليس هذا ، سابقًا ، حتى قبل ذلك ... ها هو! "
لكن هذا يهدد المطور بمشاكل رهيبة - بعد كل شيء ، بالنسبة لبحث FTS في PostgreSQL ، يتم استخدام أنواع "مكانية" من فهارس GIN و GiST ، والتي لا توفر "زلة" للبيانات الإضافية ، باستثناء متجه النص.
يبقى محزنًا فقط قراءة جميع السجلات حسب مطابقة البادئة (الآلاف منها!) وفرزها ، أو العكس ، انتقل إلى فهرس التاريخ وتصفيةجميع الإدخالات التي تم العثور عليها لمطابقة البادئة حتى نجد المدخلات المناسبة (متى سيكون هناك "هراء"؟ ..).
كلاهما غير ممتع للغاية لأداء الاستعلام. أو هل لا يزال بإمكانك التفكير في شيء للبحث السريع؟
أولاً ، دعنا ننشئ "نصوصنا حتى الآن":
CREATE TABLE corpus AS
SELECT
id
, dt
, str
FROM
(
SELECT
id::integer
, now()::date - (random() * 1e3)::integer dt -- - 3
, (random() * 1e2 + 1)::integer len -- "" 100
FROM
generate_series(1, 1e6) id -- 1M
) X
, LATERAL(
SELECT
string_agg(
CASE
WHEN random() < 1e-1 THEN ' ' -- 10%
ELSE chr((random() * 25 + ascii('a'))::integer)
END
, '') str
FROM
generate_series(1, len)
) Y;
نهج ساذج رقم 1: جوهر + btree
دعنا نحاول تدوير الفهرس لكل من FTS وللفرز حسب التاريخ - ماذا لو ساعدا:
CREATE INDEX ON corpus(dt);
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str));
سنبحث عن جميع المستندات التي تحتوي على كلمات تبدأ بـ
'abc...'
. ودعنا نتحقق أولاً من عدم وجود العديد من هذه المستندات ، ويتم استخدام فهرس FTS بشكل طبيعي:
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*');
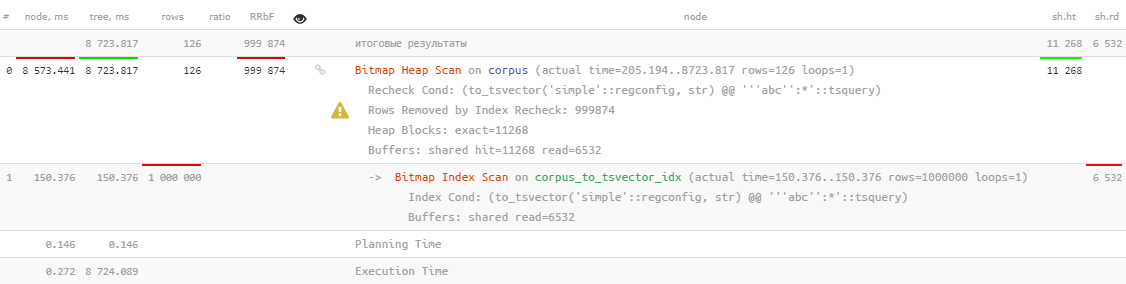
حسنًا ... تم استخدامه بالطبع ، لكنه يستغرق أكثر من 8 ثوانٍ ، ومن الواضح أنه ليس ما نود أن ننفقه في البحث في 126 سجلًا.
ربما إذا أضفت الفرز حسب التاريخ وبحثت فقط في آخر 10 سجلات - هل تتحسن؟
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt DESC
LIMIT 10;

لكن لا ، تمت إضافة الفرز فقط في الأعلى.
نهج ساذج رقم 2: btree_gist
ولكن هناك امتداد ممتاز
btree_gist
يسمح لك "بإزاحة" قيمة عددية إلى فهرس GiST ، مما يمكننا من استخدام فرز الفهرس
<->
على الفور باستخدام عامل تشغيل المسافة ، والذي يمكن استخدامه في عمليات بحث kNN :
CREATE EXTENSION btree_gist;
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str), dt);
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt <-> '2100-01-01'::date DESC -- ""
LIMIT 10;
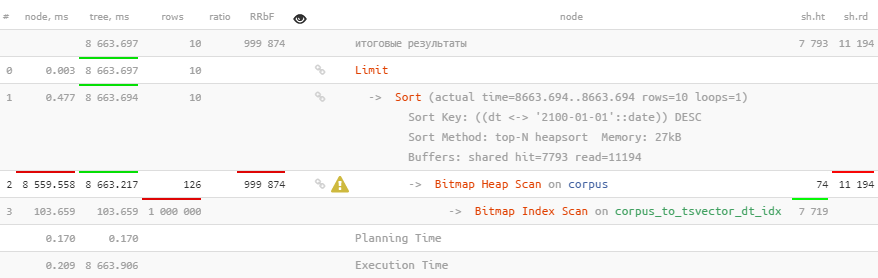
للأسف ، هذا لا يساعد على الإطلاق.
الهندسة للإنقاذ!
لكن من السابق لأوانه اليأس! دعونا نلقي نظرة على قائمة فئات عوامل تشغيل GiST المضمنة - عامل المسافة
<->
متاح فقط لـ "هندسي"
circle_ops, point_ops, poly_ops
، ومنذ PostgreSQL 13 - لـ
box_ops
.
لذلك دعونا نحاول ترجمة مهمتنا "إلى مستوى" - سنقوم بتعيين إحداثيات بعض النقاط إلى أزواجنا
(, )
المستخدمة للبحث بحيث تكون كلمات "البادئة" والتواريخ غير البعيدة أقرب ما يمكن:

نقسم النص إلى كلمات
بالطبع ، لن يكون بحثنا نصًا كاملاً ، بمعنى أنه لا يمكنك تعيين شرط لعدة كلمات في نفس الوقت. لكنها ستكون بالتأكيد بادئة!
لنقم بتكوين جدول قاموس مساعد:
CREATE TABLE corpus_kw AS
SELECT
id
, dt
, kw
FROM
corpus
, LATERAL (
SELECT
kw
FROM
regexp_split_to_table(lower(str), E'[^\\-a-z-0-9]+', 'i') kw
WHERE
length(kw) > 1
) T;
في مثالنا ، كان هناك 4.8 مليون "كلمة" لكل مليون "نص".
وضع الكلمات
لترجمة كلمة إلى "تنسيقها" ، دعنا نتخيل أن هذا رقم مكتوب بالتدوين الأساسي
2^16
(بعد كل شيء ، نريد أيضًا دعم أحرف UNICODE). سنقوم بتدوينها فقط بدءًا من الموضع السابع والأربعين الثابت:
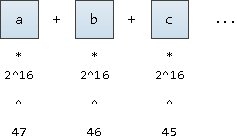
سيكون من الممكن البدء من المركز 63 ، وهذا سيعطينا قيمًا أقل قليلاً من القيم
1E+308
الحدية لـ
double precision
، ولكن بعد ذلك سيحدث تجاوز عند إنشاء الفهرس.
اتضح أنه سيتم ترتيب جميع الكلمات على محور الإحداثيات:

ALTER TABLE corpus_kw ADD COLUMN p point;
UPDATE
corpus_kw
SET
p = point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
);
CREATE INDEX ON corpus_kw USING gist(p);
نحن نشكل استعلام بحث
WITH src AS (
SELECT
point(
( --
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
SELECT
*
, src.ps <-> kw.p d
FROM
corpus_kw kw
, src
ORDER BY
d
LIMIT 10;

الآن لدينا
id
المستندات التي كنا نبحث عنها ، مرتبة بالترتيب الصحيح - واستغرق الأمر أقل من 2 مللي ثانية ، أسرع بـ 4000 مرة !
ذبابة صغيرة في المرهم
<->
لا يعرف المشغل أي شيء عن طلبنا على محورين ، لذلك توجد بياناتنا المطلوبة فقط في أحد الأحياء الصحيحة ، اعتمادًا على الفرز المطلوب حسب التاريخ:

حسنًا ، ما زلنا نرغب في تحديد المستندات النصية نفسها ، وليس كلماتها الرئيسية ، لذلك سنحتاج إلى فهرس منسي منذ زمن طويل:
CREATE UNIQUE INDEX ON corpus(id);
لننتهي من الطلب:
WITH src AS (
SELECT
point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
, dc AS (
SELECT
(
SELECT
dc
FROM
corpus dc
WHERE
id = kw.id
)
FROM
corpus_kw kw
, src
WHERE
p[0] >= ps[0] AND -- kw >= ...
p[1] <= ps[1] -- dt DESC
ORDER BY
src.ps <-> kw.p
LIMIT 10
)
SELECT
(dc).*
FROM
dc;

لقد أضافوا لنا القليل
InitPlan
بحساب ثابت x / y ، لكننا ظللنا في نفس 2 مللي ثانية !
يطير في المرهم # 2
لا شيء مجاني:
SELECT relname, pg_size_pretty(pg_total_relation_size(oid)) FROM pg_class WHERE relname LIKE 'corpus%';
corpus | 242 MB -- corpus_id_idx | 21 MB -- PK corpus_kw | 705 MB -- corpus_kw_p_idx | 403 MB -- GiST-
242 ميغابايت من "النصوص" أصبحت 1.1 جيجابايت من "فهرس البحث".
لكن بعد كل شيء ،
corpus_kw
التاريخ والكلمة نفسها تكمن في ، والتي لم نستخدمها في البحث ذاته ، لذلك دعونا نحذفها:
ALTER TABLE corpus_kw
DROP COLUMN kw
, DROP COLUMN dt;
VACUUM FULL corpus_kw;
corpus_kw | 641 MB -- id point
تافه - لكنها لطيفة. لم يساعد ذلك كثيرًا ، ولكن تم استرداد 10٪ من الحجم.