يعمل LightGBM على توسيع خوارزمية Gradient Boosting عن طريق إضافة نوع من التحديد التلقائي للكائن بالإضافة إلى التركيز على أمثلة التعزيز باستخدام التدرجات الكبيرة. يمكن أن يؤدي ذلك إلى تسريع كبير في التعلم وتحسين الأداء التنبئي. وهكذا ، أصبح LightGBM الخوارزمية الفعلية لمسابقات التعلم الآلي عند العمل مع البيانات المجدولة لمشاكل النمذجة التنبؤية للانحدار والتصنيف. سيوضح لك هذا البرنامج التعليمي كيفية تصميم مجموعات آلة معزز بالتدرج الخفيف من أجل التصنيف والانحدار. بعد الانتهاء من هذا البرنامج التعليمي ، ستعرف:
- آلة تعزيز التدرج الخفيف (LightGBM) هي تطبيق فعال مفتوح المصدر لمجموعة تعزيز التدرج العشوائي.
- كيفية تطوير مجموعات LightGBM للتصنيف والانحدار باستخدام scikit-Learn API.
- كيفية التحقيق في تأثير المعلمات الفائقة لنموذج LightGBM على أدائه.

يتكون هذا البرنامج التعليمي من ثلاثة أجزاء.
- خوارزمية LightBLM.
- Scikit-Learn API لـ LightGBM.
- مجموعة LightGBM للتصنيف.
- فرقة LightGBM للانحدار. - معلمات تشعبية LightGBM.
- دراسة عدد الأشجار.
- استكشاف عمق الشجرة.
- دراسة معدل التعلم.
- بحث عن نوع التعزيز.
خوارزمية LightBLM
ينتمي تعزيز التدرج إلى فئة من خوارزميات التعلم الآلي للمجموعة والتي يمكن استخدامها لمشاكل التصنيف أو نمذجة الانحدار التنبئي.
الفرق مبنية من نماذج شجرة القرار. تتم إضافة الأشجار واحدة تلو الأخرى إلى المجموعة ويتم تدريبها على تصحيح أخطاء التنبؤ التي ارتكبتها النماذج السابقة. هذا نوع من نماذج التعلم الآلي للمجموعة يسمى التعزيز.
يتم تدريب النماذج باستخدام أي دالة خسارة تعسفية قابلة للتفاضل وخوارزمية تحسين نزول التدرج. يعطي هذا الطريقة اسمها "تعزيز التدرج" لأن التدرج اللوني يتم تصغيره إلى أدنى حد أثناء تدريب النموذج ، مثل الشبكة العصبية. لمزيد من المعلومات حول تعزيز التدرج ، راجع البرنامج التعليمي:"مقدمة لطيفة لخوارزمية تعزيز التدرج ML . "
LightGBM هو تطبيق مفتوح المصدر لتعزيز التدرج مصمم ليكون فعالاً وربما أكثر كفاءة من التطبيقات الأخرى.
على هذا النحو ، يعد LightGBM مشروعًا مفتوح المصدر ومكتبة برامج وخوارزمية تعلم الآلة. أي أن المشروع مشابه جدًا لتقنية Extreme Gradient Boosting أو XGBoost .
تم وصف LightGBM بواسطة Golin ، K. ، et al. لمزيد من المعلومات ، راجع مقالة عام 2017 بعنوان "LightGBM: شجرة قرارات فعالة للغاية لتعزيز التدرج" . يقدم التنفيذ فكرتين رئيسيتين: GOSS و EFB.
أخذ عينات التدرج أحادي الاتجاه (GOSS) هو تعديل لتعزيز التدرج الذي يركز على تلك البرامج التعليمية التي تؤدي إلى تدرج أكبر ، والذي بدوره يسرع التعلم ويقلل من التعقيد الحسابي للطريقة.
مع GOSS ، نستبعد جزءًا كبيرًا من مثيلات البيانات ذات التدرجات الصغيرة ونستخدم فقط باقي مثيلات البيانات لتقدير اكتساب المعلومات. نجادل أنه نظرًا لأن مثيلات البيانات ذات التدرجات الكبيرة تلعب دورًا أكثر أهمية في اكتساب المعلومات الحاسوبية ، يمكن لـ GOSS الحصول على تقدير دقيق إلى حد ما للحصول على المعلومات باستخدام حجم بيانات أصغر بكثير.
تُعد حزمة الميزات الحصرية ، أو EFB ، أسلوبًا للجمع بين الميزات المتفرقة (الخالية في الغالب) الحصرية للطرفين ، مثل متغيرات الإدخال الفئوية المشفرة بترميز أحادي. وبالتالي ، فهو نوع من اختيار الميزة التلقائي.
... نقوم بحزم ميزات حصرية متبادلة (أي أنها نادرًا ما تأخذ قيمًا غير صفرية في نفس الوقت) لتقليل عدد الميزات.
يمكن لهذين التغيرين معًا تسريع وقت تدريب الخوارزمية حتى 20 مرة. وبالتالي ، يمكن اعتبار LightGBM بمثابة أشجار قرار معززة بالتدرج (GBDT) مع إضافة GOSS و EFB.
نطلق على تطبيق GBDT الجديد لدينا GOSS و EFB LightGBM. تُظهر تجاربنا على العديد من مجموعات البيانات المتاحة للجمهور أن LightGBM يعمل على تسريع عملية تعلم GBDT التقليدي بأكثر من 20 مرة ، محققًا نفس الدقة تقريبًا.
Scikit-Learn API for LightGBM
يمكن تثبيت LightGBM كمكتبة قائمة بذاتها ويمكن تطوير نموذج LightGBM باستخدام واجهة برمجة تطبيقات scikit-Learn.
الخطوة الأولى هي تثبيت مكتبة LightGBM. في معظم الأنظمة الأساسية ، يمكن القيام بذلك باستخدام مدير حزمة النقطة ؛ على سبيل المثال:
sudo pip install lightgbmيمكنك التحقق من التثبيت والإصدار مثل هذا:
# check lightgbm version
import lightgbm
print(lightgbm.__version__)سيعرض البرنامج النصي إصدار LightGBM المثبت. يجب أن تكون نسختك هي نفسها أو أعلى. إذا لم يكن كذلك ، فقم بتحديث LightGBM. إذا كنت بحاجة إلى إرشادات محددة لبيئة التطوير الخاصة بك ، فراجع البرنامج التعليمي: دليل تثبيت LightGBM .
تحتوي مكتبة LightGBM على واجهة برمجة تطبيقات خاصة بها ، على الرغم من أننا نستخدم طريقة عبر فئات المجمع scikit-learn: LGBMRegressor و LGBMClassifier . سيسمح ذلك باستخدام مكتبة تعلم الآلة scikit-Learn بأكملها لإعداد البيانات وتقييم النموذج.
يعمل كلا النموذجين بنفس الطريقة ويستخدمان نفس الحجج للتأثير على كيفية إنشاء أشجار القرار وإضافتها إلى المجموعة. النموذج يستخدم العشوائية. هذا يعني أنه في كل مرة تعمل الخوارزمية على نفس البيانات ، فإنها تنشئ نموذجًا مختلفًا قليلاً.
عند استخدام خوارزميات التعلم الآلي مع خوارزمية التعلم العشوائية ، يوصى بتقييمها عن طريق حساب متوسط أدائها على عدة عمليات تشغيل أو تكرار التحقق المتبادل. عند ملاءمة النموذج النهائي ، قد يكون من المرغوب فيه إما زيادة عدد الأشجار حتى يتناقص تباين النموذج مع التقديرات المتكررة ، أو تدريب عدة نماذج نهائية ومتوسط تنبؤاتها. دعونا نلقي نظرة على تصميم مجموعة LightGBM لكل من التصنيف والانحدار.
مجموعة LightGBM للتصنيف
في هذا القسم ، سننظر في استخدام LightGBM لمهمة التصنيف. أولاً ، يمكننا استخدام الدالة make_classification () لإنشاء مشكلة تصنيف ثنائي تركيبي مع 1000 مثال و 20 ميزة إدخال. انظر المثال الكامل أدناه.
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# summarize the datasetيؤدي تشغيل المثال إلى إنشاء مجموعة بيانات ويلخص شكل مكونات الإدخال والإخراج.
(1000, 20) (1000,)يمكننا بعد ذلك تقييم خوارزمية LightGBM على مجموعة البيانات هذه. سنقوم بتقييم النموذج باستخدام التحقق المتقاطع من k-fold المتقاطع مع ثلاثة تكرارات و k يساوي 10. سنقوم بالإبلاغ عن المتوسط والانحراف المعياري لدقة النموذج على جميع التكرارات والطيات.
# evaluate lightgbm algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))تشغيل المثال يوضح دقة المتوسط والانحراف المعياري للنموذج.
ملاحظة : قد تختلف نتائجك بسبب الطبيعة العشوائية للخوارزمية أو إجراء التقدير ، أو الاختلافات في الدقة العددية. جرب المثال عدة مرات وقارن النتيجة المتوسطة.
في هذه الحالة ، يمكننا أن نرى أن مجموعة LightGBM ذات المعلمات الفائقة الافتراضية تحقق دقة تصنيف تبلغ حوالي 92.5٪ في مجموعة بيانات الاختبار هذه.
Accuracy: 0.925 (0.031)يمكننا أيضًا استخدام نموذج LightGBM كنموذج نهائي والتنبؤ بالتصنيف. أولاً ، تناسب مجموعة LightGBM جميع البيانات المتاحة ، وثانيًا ، يمكنك استدعاء وظيفة التنبؤ () لعمل تنبؤات بشأن البيانات الجديدة. يوضح المثال أدناه هذا في مجموعة بيانات التصنيف الثنائي الخاصة بنا.
# make predictions using lightgbm for classification
from sklearn.datasets import make_classification
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]
yhat = model.predict([row])
print('Predicted Class: %d' % yhat[0])يؤدي تشغيل المثال إلى تدريب نموذج مجموعة LightGBM لمجموعة البيانات بأكملها ثم استخدامه للتنبؤ بصف جديد من البيانات ، كما لو تم استخدام النموذج في أحد التطبيقات.
Predicted Class: 1الآن بعد أن اعتدنا على استخدام LightGBM للتصنيف ، دعنا نلقي نظرة على واجهة برمجة تطبيقات الانحدار.
فرقة LightGBM للانحدار
في هذا القسم ، سننظر في استخدام LightGBM لمشكلة الانحدار. أولاً ، يمكننا استخدام وظيفة make_regression ()
لإنشاء مشكلة انحدار تركيبي مع 1000 مثال و 20 ميزة إدخال. انظر المثال الكامل أدناه.
# test regression dataset
from sklearn.datasets import make_regression
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# summarize the dataset
print(X.shape, y.shape)يؤدي تشغيل المثال إلى إنشاء مجموعة بيانات ويلخص مكونات الإدخال والإخراج.
(1000, 20) (1000,)ثانيًا ، يمكننا تقييم خوارزمية LightGBM على مجموعة البيانات هذه.
كما في القسم الأخير ، سنقوم بتقييم النموذج عن طريق التحقق المتقاطع من k-fold مع ثلاثة مكررات و k يساوي 10. سنقوم بالإبلاغ عن متوسط الخطأ المطلق (MAE) للنموذج عبر جميع التكرارات ومجموعات التحقق من الصحة. مكتبة scikit-Learn تجعل MAE سلبيًا بحيث يتم تكبيرها بدلاً من تصغيرها. هذا يعني أن MAEs السلبية الكبيرة أفضل وأن النموذج المثالي له MAE من 0. ويرد مثال كامل أدناه.
# evaluate lightgbm ensemble for regression
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# evaluate the model
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))تشغيل المثال يوضح المتوسط والانحراف المعياري للنموذج.
ملاحظة : قد تختلف نتائجك بسبب الطبيعة العشوائية للخوارزمية أو إجراء التقدير ، أو الاختلافات في الدقة العددية. ضع في اعتبارك تشغيل المثال عدة مرات ومقارنة متوسط النتيجة. في هذه الحالة ، نرى أن مجموعة LightGBM ذات المعلمات الفائقة الافتراضية تصل إلى MAE يبلغ حوالي 60.
MAE: -60.004 (2.887)يمكننا أيضًا استخدام نموذج LightGBM كنموذج نهائي والتنبؤ بالانحدار. أولاً ، يتم تدريب مجموعة LightGBM على جميع البيانات المتاحة ، ثم يمكن استدعاء وظيفة التنبؤ () للتنبؤ بالبيانات الجديدة. يوضح المثال أدناه هذا في مجموعة بيانات الانحدار الخاصة بنا.
# gradient lightgbm for making predictions for regression
from sklearn.datasets import make_regression
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.20543991,-0.97049844,-0.81403429,-0.23842689,-0.60704084,-0.48541492,0.53113006,2.01834338,-0.90745243,-1.85859731,-1.02334791,-0.6877744,0.60984819,-0.70630121,-1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,-0.11154792]
yhat = model.predict([row])
print('Prediction: %d' % yhat[0]) يؤدي تشغيل المثال إلى تدريب نموذج مجموعة LightGBM على مجموعة البيانات بأكملها ثم استخدامه للتنبؤ بصف جديد من البيانات ، كما لو كان يستخدم النموذج في تطبيق ما.
Prediction: 52الآن بعد أن أصبحنا على دراية باستخدام scikit-Learn API لتقييم وتطبيق مجموعات LightGBM ، فلنلقِ نظرة على إعداد النموذج.
معلمات LightGBM Hyperparameters
في هذا القسم ، سوف نلقي نظرة فاحصة على بعض المعلمات الفائقة المهمة لمجموعة LightGBM ، وتأثيرها على أداء النموذج. يحتوي LightGBM على الكثير من المعلمات الفائقة التي يجب النظر إليها ، وهنا ننظر إلى عدد الأشجار وعمقها ومعدل التعلم ونوع التعزيز. للحصول على نصائح عامة حول تعديل معلمات LightGBM الفوقية ، راجع الوثائق: ضبط معلمات LightGBM .
فحص عدد الأشجار
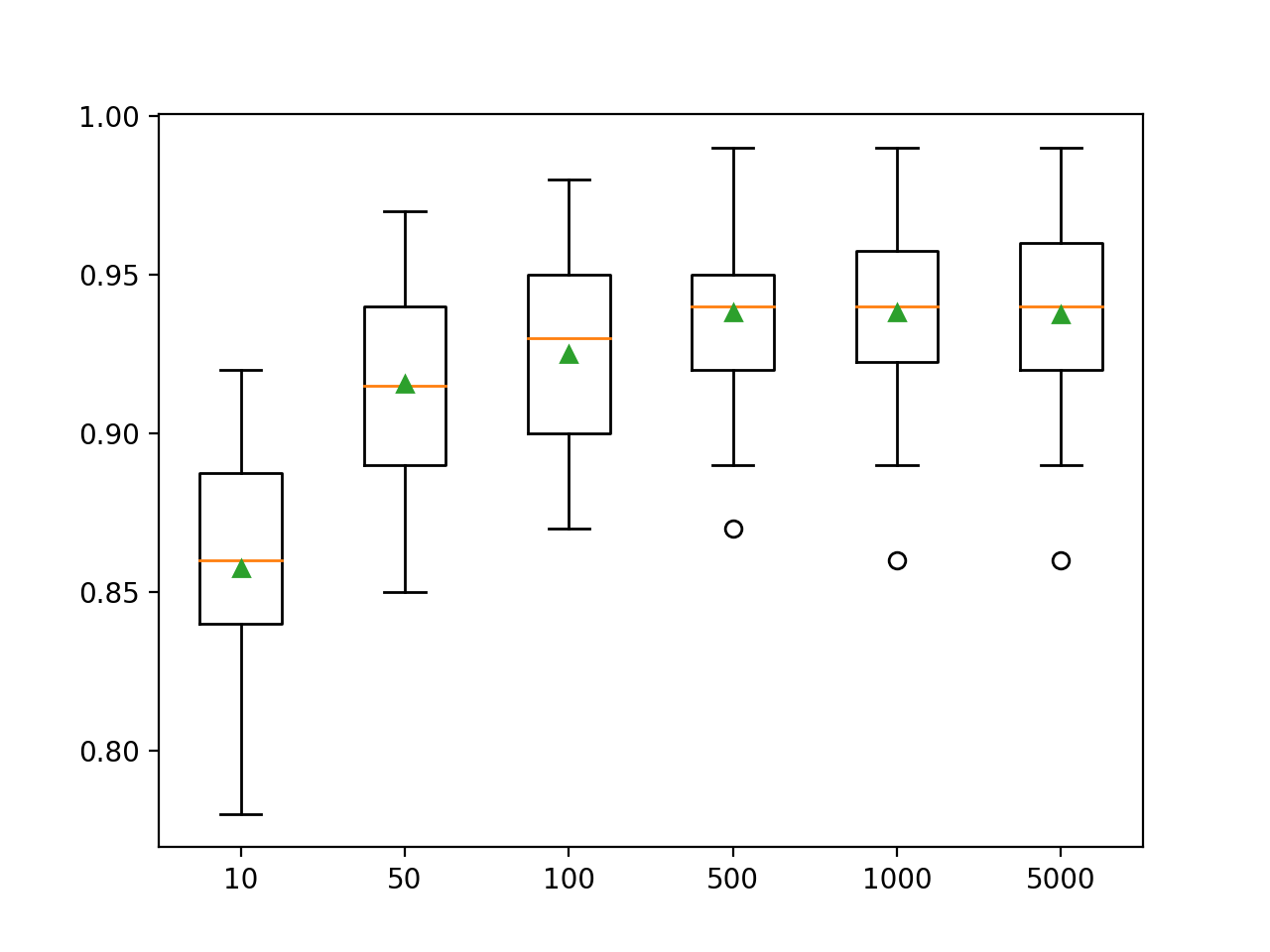
من المعلمات الفائقة الهامة لخوارزمية مجموعة LightGBM عدد أشجار القرار المستخدمة في المجموعة. تذكر أنه تمت إضافة أشجار القرار إلى النموذج بالتسلسل في محاولة لتصحيح وتحسين التنبؤات التي قدمتها الأشجار السابقة. تعمل القاعدة غالبًا: المزيد من الأشجار أفضل. يمكن تحديد عدد الأشجار باستخدام الوسيطة n_estimators ، والتي يتم تعيينها افتراضيًا على 100. يفحص المثال أدناه تأثير عدد الأشجار ، من 10 إلى 5000.
# explore lightgbm number of trees effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
trees = [10, 50, 100, 500, 1000, 5000]
for n in trees:
models[str(n)] = LGBMClassifier(n_estimators=n)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()يؤدي تشغيل المثال أولاً إلى عرض متوسط الدقة لكل عدد من أشجار القرار.
ملاحظة : قد تختلف نتائجك بسبب الطبيعة العشوائية للخوارزمية أو إجراء التقدير ، أو الاختلافات في الدقة العددية. ضع في اعتبارك تشغيل المثال عدة مرات ومقارنة متوسط النتيجة.
هنا نرى أن الأداء يتحسن لمجموعة البيانات هذه إلى حوالي 500 شجرة ، وبعد ذلك يبدو أنه مستوي.
>10 0.857 (0.033)
>50 0.916 (0.032)
>100 0.925 (0.031)
>500 0.938 (0.026)
>1000 0.938 (0.028)
>5000 0.937 (0.028)يتم إنشاء مخطط مربع وشعيرات لتوزيع درجات الدقة لكل عدد مكون من الأشجار. هناك اتجاه عام نحو زيادة أداء النموذج وحجم المجموعة.
فحص عمق الشجرة
يعد تغيير عمق كل شجرة مضافة إلى المجموعة معلمة إضافية مهمة لتعزيز التدرج. يحدد عمق الشجرة مدى تخصص كل شجرة في مجموعة بيانات التدريب: إلى أي مدى يمكن أن تكون عامة أو مدربة. تُفضل الأشجار التي لا ينبغي أن تكون ضحلة جدًا وعامة (مثل AdaBoost ) وليست عميقة جدًا ومتخصصة (مثل تجميع bootstrap ).
عادةً ما يعمل التعزيز المتدرج جيدًا مع الأشجار ذات العمق المعتدل ، مع موازنة التدريب والعموم. يتم التحكم في عمق الشجرة بواسطة وسيطة max_depth، والقيمة الافتراضية هي قيمة غير محددة ، حيث أن الآلية الافتراضية لإدارة تعقيد الأشجار هي استخدام عدد محدود من العقد.
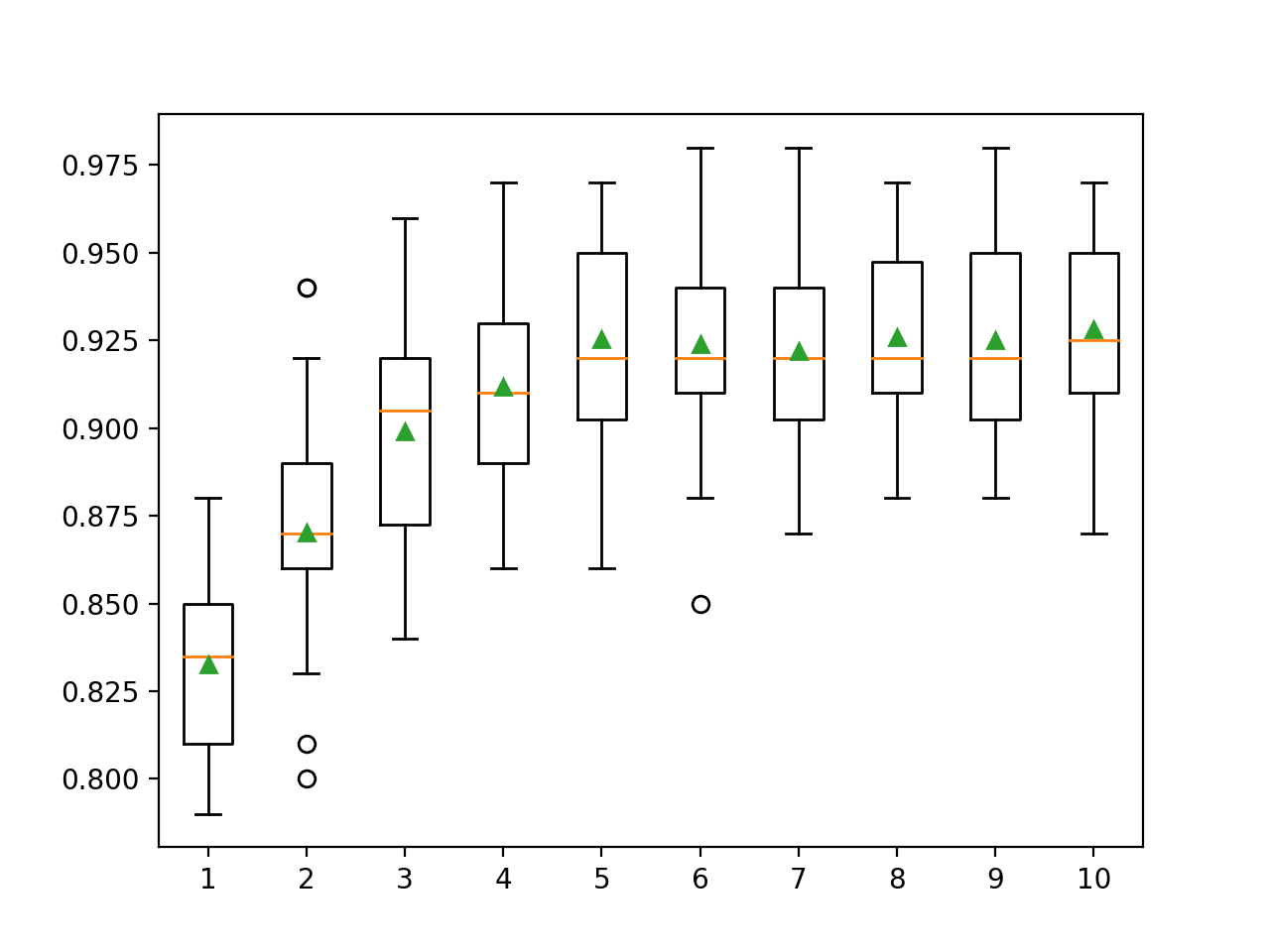
هناك طريقتان رئيسيتان للتحكم في تعقيد الشجرة: من خلال أقصى عمق للشجرة والحد الأقصى لعدد العقد الطرفية (الأوراق) للشجرة. نحن نفحص عدد الأوراق هنا ، لذلك نحتاج إلى زيادة العدد لدعم الأشجار الأعمق من خلال تحديد وسيطة num_leaves . أدناه نقوم بفحص أعماق الأشجار من 1 إلى 10 وتأثيرها على أداء النموذج.
# explore lightgbm tree depth effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in range(1,11):
models[str(i)] = LGBMClassifier(max_depth=i, num_leaves=2**i)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()يعرض تشغيل المثال أولاً متوسط الدقة لكل عمق شجرة مضبوط.
ملاحظة : قد تختلف نتائجك بسبب الطبيعة العشوائية للخوارزمية أو إجراء التقدير ، أو الاختلافات في الدقة العددية. ضع في اعتبارك تشغيل المثال عدة مرات ومقارنة متوسط النتيجة.
هنا يمكننا أن نرى أن الأداء يتحسن مع زيادة عمق الشجرة ، وربما يصل إلى 10 مستويات. سيكون من الممتع استكشاف أشجار أعمق.
>1 0.833 (0.028)
>2 0.870 (0.033)
>3 0.899 (0.032)
>4 0.912 (0.026)
>5 0.925 (0.031)
>6 0.924 (0.029)
>7 0.922 (0.027)
>8 0.926 (0.027)
>9 0.925 (0.028)
>10 0.928 (0.029)يتم إنشاء مخطط مستطيل وشعر طولي لتوزيع درجات الدقة لكل عمق شجرة تم تكوينه. هناك اتجاه عام لزيادة أداء النموذج بعمق شجرة يصل إلى خمسة مستويات ، وبعد ذلك يظل الأداء ثابتًا إلى حد ما.
تعلم معدل البحث
يتحكم معدل التعلم في مقدار مساهمة كل نموذج في توقع المجموعة. قد تتطلب السرعات المنخفضة مزيدًا من أشجار القرار في المجموعة. يمكن التحكم في معدل التعلم باستخدام وسيطة Learning_rate ، وهي 0.1 افتراضيًا. فيما يلي يفحص معدل التعلم ويقارن تأثير القيم من 0.0001 إلى 1.0
# explore lightgbm learning rate effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
rates = [0.0001, 0.001, 0.01, 0.1, 1.0]
for r in rates:
key = '%.4f' % r
models[key] = LGBMClassifier(learning_rate=r)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()يعرض تشغيل المثال أولاً متوسط الدقة لكل معدل تعلم تم تكوينه.
ملاحظة : قد تختلف نتائجك بسبب الطبيعة العشوائية للخوارزمية أو إجراء التقدير ، أو الاختلافات في الدقة العددية. ضع في اعتبارك تشغيل المثال عدة مرات ومقارنة المتوسط.
نرى هنا أن معدل التعلم العالي يؤدي إلى أداء أفضل لمجموعة البيانات هذه. نتوقع أن إضافة المزيد من الأشجار إلى المجموعة للحصول على معدل تعليمي أقل سيحسن الأداء بشكل أكبر.
>0.0001 0.800 (0.038)
>0.0010 0.811 (0.035)
>0.0100 0.859 (0.035)
>0.1000 0.925 (0.031)
>1.0000 0.928 (0.025)يتم إنشاء مربع شارب لتوزيع درجات الدقة لكل معدل تعلم تم تكوينه. هناك اتجاه عام لزيادة أداء النموذج مع زيادة معدل التعلم حتى 1.0

تعزيز البحث النوعي
الشيء المميز في LightGBM هو أنه يدعم عددًا من خوارزميات التعزيز تسمى أنواع التعزيز. يتم تحديد نوع التحسين باستخدام وسيطة boosting_type ويأخذ سلسلة لتحديد النوع. القيم الممكنة:
- 'gbdt' : شجرة القرار المعزز بالتدرج (GDBT) ؛
- "dart" : تم إدخال مفهوم التسرب في MART ، نحصل على DART ؛
- "goss" : إحضار متدرج أحادي الاتجاه (GOSS).
الافتراضي هو GDBT ، خوارزمية تعزيز التدرج الكلاسيكي.
تم وصف DART في مقال عام 2015 بعنوان " DART: المتسربين يلتقون بأشجار الانحدار المضافة المتعددة " ، وكما يوحي الاسم ، يضيف مفهوم التسرب من التعلم العميق إلى خوارزمية أشجار الانحدار المضافة المتعددة (MART) ، تمهيدًا لتدرج تعزيز أشجار القرار.
تُعرف هذه الخوارزمية بالعديد من الأسماء ، بما في ذلك Gradient TreeBoost ، و Boosted Trees ، وأشجار وأشجار الانحدار المضافة المتعددة (MART). نستخدم الاسم الأخير للإشارة إلى الخوارزمية.
يتم تقديم GOSS مع العمل على LightGBM ومكتبة lightbgm. يهدف هذا الأسلوب إلى استخدام تلك الحالات فقط التي تؤدي إلى تدرج خطأ كبير لتحديث النموذج وإزالة المثيلات المتبقية.
... نستبعد جزءًا كبيرًا من مثيلات البيانات ذات التدرجات الصغيرة ونستخدم الباقي فقط لتقدير الزيادة في المعلومات.
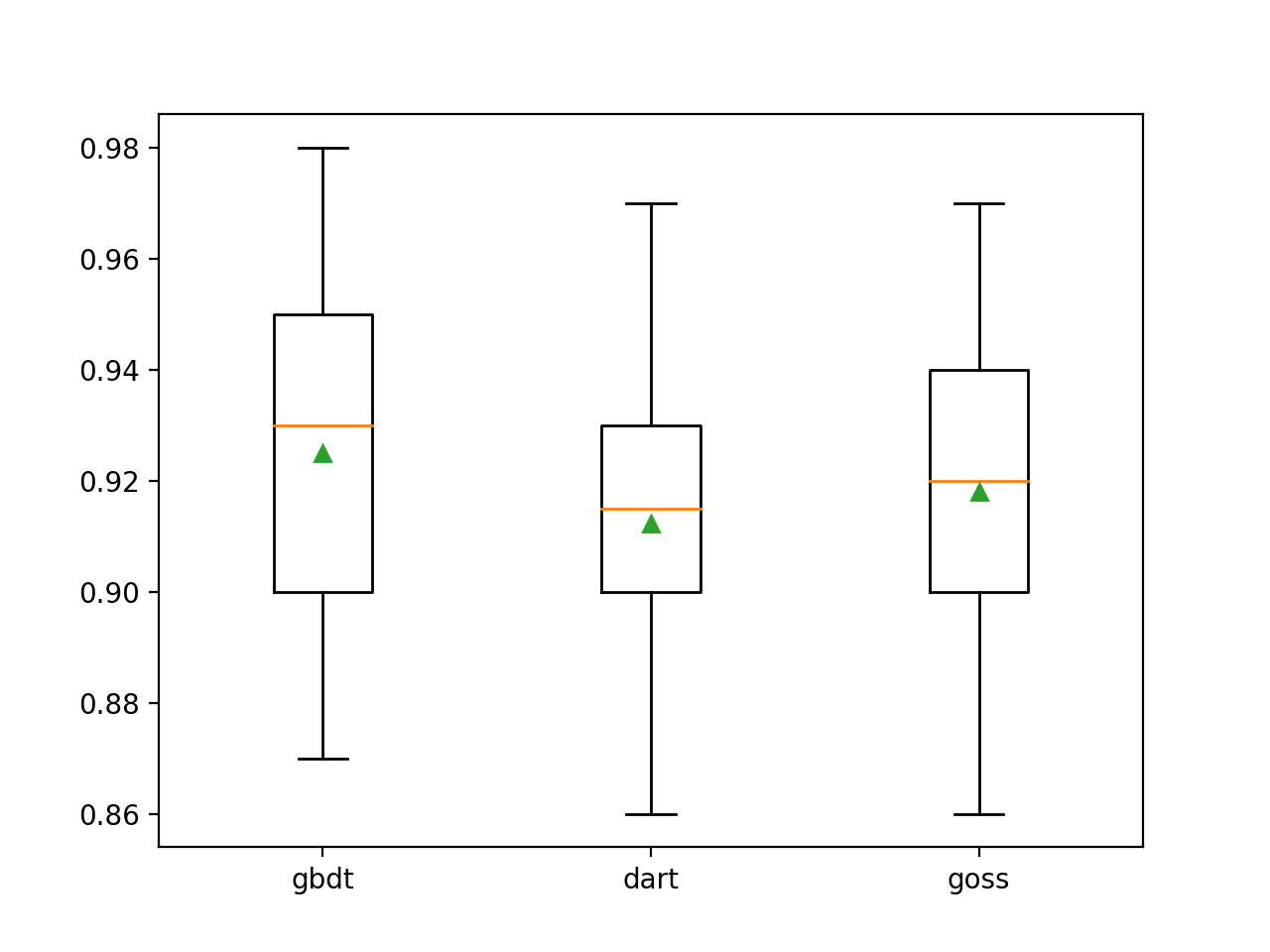
أدناه LightGBM تم تدريبه على مجموعة بيانات تصنيف اصطناعية بثلاث طرق تعزيز رئيسية.
# explore lightgbm boosting type effect on performance
from numpy import arange
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
types = ['gbdt', 'dart', 'goss']
for t in types:
models[t] = LGBMClassifier(boosting_type=t)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()يعرض تشغيل المثال أولاً متوسط الدقة لكل نوع تعزيز تم تكوينه.
ملاحظة : قد تختلف نتائجك بسبب الطبيعة العشوائية للخوارزمية أو إجراء التقدير ، أو الاختلافات في الدقة العددية. ضع في اعتبارك تشغيل المثال عدة مرات ومقارنة المتوسط.
يمكننا أن نرى أن طريقة التعزيز الافتراضية تعمل بشكل أفضل من الطريقتين المقيَّمتين الأخريين.
>gbdt 0.925 (0.031)
>dart 0.912 (0.028)
>goss 0.918 (0.027)يتم إنشاء مخطط مربع وشعر لتوزيع درجات الدقة لكل طريقة تضخيم تم تكوينها ، مما يسمح بإجراء مقارنة مباشرة للطرق.

المزيد من الدورات