لم أكتب أي مقالات لفترة طويلة ، وأعتقد أنه حان الوقت للكتابة هناك عن كيفية الاستفادة من المعرفة في علم البيانات ، التي تم الحصول عليها أثناء تدريب التخصص المعروف من Yandex و MIPT "التعلم الآلي وتحليل البيانات". صحيح ، في الإنصاف ، تجدر الإشارة إلى أن المعرفة لم يتم الحصول عليها بالكامل - لم يكتمل التخصص :) ومع ذلك ، من الممكن بالفعل حل مشاكل العمل الحقيقية البسيطة. أم أنها ضرورية؟ سيتم الرد على هذا السؤال في فقرتين فقط.
لذا ، سأخبر اليوم في هذا المقال عزيزي القارئ عن تجربتي الأولى في المشاركة في مسابقة مفتوحة. أود أن أشير على الفور إلى أن هدفي من المسابقة لم يكن الحصول على أي جوائز. كانت الرغبة الوحيدة هي تجربة يدي في العالم الحقيقي :) نعم ، بالإضافة إلى أنه حدث أن موضوع المسابقة عمليًا لم يتقاطع مع مادة الدورات التي تم اجتيازها. أضاف هذا بعض التعقيدات ، ولكن مع ذلك أصبحت المنافسة أكثر إثارة للاهتمام وقيمة الخبرة المكتسبة من هناك.
حسب التقاليد ، سأقوم بتعيين من قد يكون مهتمًا بالمقال. أولاً ، إذا كنت قد أكملت بالفعل أول دورتين من التخصص أعلاه ، وترغب في تجربة يدك في المشكلات العملية ، لكنك خجول وقلق من أن ذلك قد لا ينجح وسيُضحك عليك ، إلخ. بعد قراءة المقال آمل أن تبدد هذه المخاوف. ثانيًا ، ربما تحل مشكلة مماثلة ولا تعرف مطلقًا من أين تدخل. وإليك نموذج بسيط جاهز ، كما تقول معلمات البيانات الحقيقية ، خط الأساس :)
سيكون من المفيد هنا تحديد الخطوط العريضة لخطة البحث ، لكننا سنستطرد قليلاً ونحاول الإجابة عن السؤال من الفقرة الأولى - ما إذا كان المبتدئ في كتابة البيانات يحتاج إلى تجربة يده في مثل هذه المسابقات. تختلف الآراء حول هذه النقطة. أنا شخصياً رأيي ضروري! اسمحوا لي أن أشرح لماذا. هناك أسباب كثيرة ، لن أسرد كل شيء ، وسأشير إلى أهمها. أولاً ، تساعد مثل هذه المسابقات على تعزيز المعرفة النظرية في الممارسة. ثانيًا ، في ممارستي ، دائمًا تقريبًا ، الخبرة المكتسبة في ظروف قريبة من القتال ، تحفز بشدة على المزيد من المآثر. ثالثًا ، وهذا هو الشيء الأكثر أهمية - أثناء المنافسة لديك فرصة للتواصل مع المشاركين الآخرين في محادثات خاصة ، ليس عليك حتى التواصل ، يمكنك فقط قراءة ما يكتب عنه الناس وهذا غالبًا ما يؤدي إلى أفكار مثيرة للاهتمام حولما هي التغييرات الأخرى التي يجب إجراؤها في الدراسة ؛ و ب) يمنح الثقة للتحقق من صحة أفكارهم ، خاصةً إذا تم التعبير عنها في الدردشة. يجب التعامل مع هذه المزايا بحكمة معينة ، حتى لا يكون هناك شعور بالكلية ...
الآن قليلا عن كيف قررت المشاركة. علمت بالمسابقة قبل أيام قليلة من بدئها. الفكرة الأولى هي "حسنًا ، لو كنت قد علمت بالمسابقة قبل شهر ، لكنت أعدت نفسي ، لكني كنت سأدرس بعض المواد الإضافية التي يمكن أن تكون مفيدة لإجراء البحث ، وإلا فقد لا أفي بالموعد النهائي بدون تحضير ... الفكرة "في الواقع ، ما قد لا ينجح إذا لم يكن الهدف الحصول على جائزة ، ولكن المشاركة ، خاصة وأن المشاركين في 95٪ من الحالات يتحدثون اللغة الروسية ، بالإضافة إلى وجود محادثات خاصة للمناقشة ، سيكون هناك نوع من الندوات عبر الإنترنت من المنظمين. في النهاية ، سيكون من الممكن رؤية خبراء بيانات حية من جميع الخطوط والأحجام ... ". كما خمنت ، فازت الفكرة الثانية ، ولم تذهب سدى - فقط بضعة أيام من العمل الشاق وحصلت على تجربة قيمة ، وإن كانت بسيطة ،لكنها مهمة تجارية تمامًا. لذلك ، إذا كنت في طريقك لقهر مرتفعات علم البيانات ورأيت المنافسة القادمة ، نعم بلغتك الأم ، مع دعم في الدردشة ولديك وقت فراغ - لا تتردد لفترة طويلة - حاول وقد تأتي القوة معك! على الجانب الإيجابي ، ننتقل إلى المهمة وخطة البحث.
مطابقة الأسماء
لن نعذب أنفسنا ونتوصل إلى وصف للمشكلة ، لكننا سنقدم النص الأصلي من الموقع الإلكتروني لمنظم المسابقة.
مهمة
عند البحث عن عملاء جدد ، يتعين على SIBUR معالجة المعلومات الخاصة بملايين الشركات الجديدة من مصادر مختلفة. في الوقت نفسه ، قد تحتوي أسماء الشركات على تهجئات مختلفة ، أو تحتوي على اختصارات أو أخطاء ، وتكون تابعة لشركات معروفة بالفعل لـ SIBUR.
لمعالجة المعلومات حول العملاء المحتملين بشكل أكثر كفاءة ، يحتاج SIBUR إلى معرفة ما إذا كان الاسمان مرتبطين (أي ينتميان إلى نفس الشركة أو الشركات التابعة).
في هذه الحالة ، سيكون SIBUR قادرًا على استخدام المعلومات المعروفة بالفعل عن الشركة نفسها أو حول الشركات التابعة ، وليس لتكرار المكالمات إلى الشركة أو عدم إضاعة الوقت في الشركات غير ذات الصلة أو الشركات التابعة للمنافسين.
يحتوي نموذج التدريب على أزواج من الأسماء من مصادر مختلفة (بما في ذلك الأسماء المخصصة) والترميز.
تم الحصول على الترميز جزئيًا يدويًا ، وجزئيًا - بطريقة حسابية. بالإضافة إلى ذلك ، قد يحتوي الترميز على أخطاء. ستقوم ببناء نموذج ثنائي يتنبأ بما إذا كان هناك اسمان مرتبطان أم لا. المقياس المستخدم في هذه المهمة هو F1.
في هذه المهمة ، من الممكن بل ومن الضروري استخدام مصادر البيانات المفتوحة لإثراء مجموعة البيانات أو العثور على معلومات إضافية مهمة لتحديد الشركات التابعة.
معلومات إضافية حول المهمة
اكشف لي لمزيد من المعلومات
, . , : , , Sibur Digital, , Sibur international GMBH , “ International GMBH” .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source , . — . .
, - – . , , - , , , .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
, , , .. crowdsource
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source
open source , . — . .
, - – . , , - , , , .
البيانات
train.csv - تدريب مجموعة
test.csv - مجموعة اختبار
sample_submission.csv - مثال للحل في الصحيحين شكل
baseline.ipynb التسمية - كود
baseline_submission.csv - الأساسية الحل
الرجاء ملاحظة أن منظمي المسابقة اعتنى جيل الشباب ونشر الحل الأساسي لهذه المشكلة، مما يعطي جودة f1 تبلغ حوالي 0.1. هذه هي المرة الأولى التي أشارك فيها في المسابقات وأول مرة أرى هذا :)
لذا ، بعد أن تعرفت على المهمة نفسها ومتطلبات حلها ، دعنا ننتقل إلى خطة الحل.
خطة حل المشكلات
إعداد الأدوات الفنية
لنقم بتحميل المكتبات
لنكتب وظائف مساعدة
معالجة البيانات
… -. !
50 & Drop it smart.
دعونا نحسب مسافة Levenshtein
احسب مسافة Levenshtein التي تم تطبيعها
تصور الميزات
قارن الكلمات في النص لكل زوج وقم بإنشاء مجموعة كبيرة من الميزات
قارن الكلمات من النص بكلمات من أسماء أفضل 50 علامة تجارية مملوكة في صناعات البتروكيماويات والبناء. دعنا نحصل على المجموعة الكبيرة الثانية من الميزات. الثانية CHIT
إعداد البيانات لتغذية النموذج
إعداد النموذج وتدريبه
نتائج المسابقة
مصادر المعلومات
الآن بعد أن تعرفنا على خطة البحث ، دعنا ننتقل إلى تنفيذها.
إعداد الأدوات الفنية
تحميل المكتبات
في الواقع ، كل شيء بسيط هنا ، أولاً سنقوم بتثبيت المكتبات المفقودة
قم بتثبيت المكتبة لتحديد قائمة الدول ثم قم بإزالتها من النص
pip install pycountry
قم بتثبيت مكتبة لتحديد مسافة Levenshtein بين الكلمات من النص مع بعضها البعض ومع الكلمات من قوائم مختلفة
pip install strsimpy
سنقوم بتثبيت المكتبة التي من خلالها سنقوم بترجمة النص الروسي إلى اللاتينية
pip install cyrtranslit
اسحب المكتبات
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import pycountry
import re
from tqdm import tqdm
tqdm.pandas()
from strsimpy.levenshtein import Levenshtein
from strsimpy.normalized_levenshtein import NormalizedLevenshtein
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import seaborn as sns
sns.set()
sns.set_style("whitegrid")
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit
from scipy.sparse import csr_matrix
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report, f1_score
# import googletrans
# from googletrans import Translator
import cyrtranslitدعنا نكتب وظائف مساعدة
يعتبر تحديد الوظيفة في سطر واحد ممارسة جيدة بدلاً من نسخ جزء كبير من التعليمات البرمجية. سنفعل ذلك دائمًا تقريبًا.
لن أجادل في أن جودة الكود في الوظائف ممتازة. في بعض الأماكن ، يجب بالتأكيد تحسينها ، ولكن من أجل البحث عنها بسرعة ، ستكون دقة الحسابات فقط كافية.
لذا فإن الوظيفة الأولى تحول النص إلى أحرف صغيرة
الرمز
# convert text to lowercase
def lower_str(data,column):
data[column] = data[column].str.lower()تساعد الوظائف الأربع التالية في تصور مساحة الميزات قيد الدراسة وقدرتها على فصل الكائنات حسب تسميات الهدف - 0 أو 1.
الرمز
# statistic table for analyse float values (it needs to make histogramms and boxplots)
def data_statistics(data,analyse,title_print):
data0 = data[data['target']==0][analyse]
data1 = data[data['target']==1][analyse]
data_describe = pd.DataFrame()
data_describe['target_0'] = data0.describe()
data_describe['target_1'] = data1.describe()
data_describe = data_describe.T
if title_print == 'yes':
print ('\033[1m' + ' ',analyse,'\033[m')
elif title_print == 'no':
None
return data_describe
# histogramms for float values
def hist_fz(data,data_describe,analyse,size):
print ()
print ('\033[1m' + 'Information about',analyse,'\033[m')
print ()
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
min_data = data_describe['min'].min()
max_data = data_describe['max'].max()
data0_mean = data_describe.loc['target_0']['mean']
data0_median = data_describe.loc['target_0']['50%']
data0_min = data_describe.loc['target_0']['min']
data0_max = data_describe.loc['target_0']['max']
data0_count = data_describe.loc['target_0']['count']
data1_mean = data_describe.loc['target_1']['mean']
data1_median = data_describe.loc['target_1']['50%']
data1_min = data_describe.loc['target_1']['min']
data1_max = data_describe.loc['target_1']['max']
data1_count = data_describe.loc['target_1']['count']
print ('\033[4m' + 'Analyse'+ '\033[m','No duplicates')
figure(figsize=size)
sns.distplot(data_0,color='darkgreen',kde = False)
plt.scatter(data0_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data0_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data0_count,
' Min:', round(data0_min,2),
' Max:', round(data0_max,2),
' Mean:', round(data0_mean,2),
' Median:', round(data0_median,2))
print ()
print ('\033[4m' + 'Analyse'+ '\033[m','Duplicates')
figure(figsize=size)
sns.distplot(data_1,color='darkred',kde = False)
plt.scatter(data1_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data1_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data_1.count(),
' Min:', round(data1_min,2),
' Max:', round(data1_max,2),
' Mean:', round(data1_mean,2),
' Median:', round(data1_median,2))
# draw boxplot
def boxplot(data,analyse,size):
print ('\033[4m' + 'Analyse'+ '\033[m','All pairs')
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
figure(figsize=size)
sns.boxplot(x=analyse,y='target',data=data,orient='h',
showmeans=True,
meanprops={"marker":"o",
"markerfacecolor":"dimgray",
"markeredgecolor":"black",
"markersize":"14"},
palette=['palegreen', 'salmon'])
plt.ylabel('target', size=14)
plt.xlabel(analyse, size=14)
plt.show()
# draw graph for analyse two choosing features for predict traget label
def two_features(data,analyse1,analyse2,size):
fig = plt.subplots(figsize=size)
x0 = data[data['target']==0][analyse1]
y0 = data[data['target']==0][analyse2]
x1 = data[data['target']==1][analyse1]
y1 = data[data['target']==1][analyse2]
plt.scatter(x0,y0,c='green',marker='.')
plt.scatter(x1,y1,c='black',marker='+')
plt.xlabel(analyse1)
plt.ylabel(analyse2)
title = [analyse1,analyse2]
plt.title(title)
plt.show()تم تصميم الوظيفة الخامسة لإنشاء جدول التخمين والخطأ للخوارزمية ، المعروف باسم جدول التصريف.
بعبارة أخرى ، بعد تشكيل متجه التنبؤ ، نحتاج إلى مقارنة التنبؤ بالتسميات المستهدفة. يجب أن تكون نتيجة هذه المقارنة جدول تصريف لكل زوج من الشركات من عينة التدريب. في جدول الاقتران لكل زوج ، سيتم تحديد نتيجة مطابقة التنبؤ بالفصل من عينة التدريب. يتم قبول تصنيف المطابقة على النحو التالي: "إيجابي حقيقي" أو "إيجابي خطأ" أو "سلبي حقيقي" أو "سلبي خطأ". هذه البيانات مهمة جدًا لتحليل تشغيل الخوارزمية واتخاذ القرارات بشأن تحسين النموذج ومساحة الميزة.
الرمز
def contingency_table(X,features,probability_level,tridx,cvidx,model):
tr_predict_proba = model.predict_proba(X.iloc[tridx][features].values)
cv_predict_proba = model.predict_proba(X.iloc[cvidx][features].values)
tr_predict_target = (tr_predict_proba[:, 1] > probability_level).astype(np.int)
cv_predict_target = (cv_predict_proba[:, 1] > probability_level).astype(np.int)
X_tr = X.iloc[tridx]
X_cv = X.iloc[cvidx]
X_tr['predict_proba'] = tr_predict_proba[:,1]
X_cv['predict_proba'] = cv_predict_proba[:,1]
X_tr['predict_target'] = tr_predict_target
X_cv['predict_target'] = cv_predict_target
# make true positive column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false positive column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make true negative column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false negative column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
return X_tr,X_cvتم تصميم الوظيفة السادسة لتشكيل مصفوفة الاقتران. يجب عدم الخلط بينه وبين طاولة التوصيل. على الرغم من أن أحدهما يتبع الآخر. أنت نفسك سوف ترى كل شيء أبعد من ذلك
الرمز
def matrix_confusion(X):
list_matrix = ['True_Positive','False_Positive','True_Negative','False_Negative']
tr_pos = X[list_matrix].sum().loc['True_Positive']
f_pos = X[list_matrix].sum().loc['False_Positive']
tr_neg = X[list_matrix].sum().loc['True_Negative']
f_neg = X[list_matrix].sum().loc['False_Negative']
matrix_confusion = pd.DataFrame()
matrix_confusion['0_algorythm'] = np.array([tr_neg,f_neg]).T
matrix_confusion['1_algorythm'] = np.array([f_pos,tr_pos]).T
matrix_confusion = matrix_confusion.rename(index={0: '0_target', 1: '1_target'})
return matrix_confusionتم تصميم الوظيفة السابعة لتصور التقرير الخاص بتشغيل الخوارزمية ، والذي يتضمن مصفوفة الاقتران ، وقيم دقة المقاييس ، والتذكر ، f1
الرمز
def report_score(tr_matrix_confusion,
cv_matrix_confusion,
data,tridx,cvidx,
X_tr,X_cv):
# print some imporatant information
print ('\033[1m'+'Matrix confusion on train data'+'\033[m')
display(tr_matrix_confusion)
print ()
print(classification_report(data.iloc[tridx]["target"].values, X_tr['predict_target']))
print ('******************************************************')
print ()
print ()
print ('\033[1m'+'Matrix confusion on test(cv) data'+'\033[m')
display(cv_matrix_confusion)
print ()
print(classification_report(data.iloc[cvidx]["target"].values, X_cv['predict_target']))
print ('******************************************************')باستخدام الوظيفتين الثامنة والتاسعة ، سنقوم بتحليل فائدة الميزات للنموذج المستخدم من Light GBM من حيث قيمة المعامل "كسب المعلومات" لكل ميزة تم فحصها
الرمز
def table_gain_coef(model,features,start,stop):
data_gain = pd.DataFrame()
data_gain['Features'] = features
data_gain['Gain'] = model.booster_.feature_importance(importance_type='gain')
return data_gain.sort_values('Gain', ascending=False)[start:stop]
def gain_hist(df,size,start,stop):
fig, ax = plt.subplots(figsize=(size))
x = (df.sort_values('Gain', ascending=False)['Features'][start:stop])
y = (df.sort_values('Gain', ascending=False)['Gain'][start:stop])
plt.bar(x,y)
plt.xlabel('Features')
plt.ylabel('Gain')
plt.xticks(rotation=90)
plt.show()الوظيفة العاشرة مطلوبة لتشكيل مجموعة من عدد الكلمات المطابقة لكل زوج من الشركات.
يمكن استخدام هذه الوظيفة أيضًا لتكوين مصفوفة من الكلمات غير المطابقة.
الرمز
def compair_metrics(data):
duplicate_count = []
duplicate_sum = []
for i in range(len(data)):
count=len(data[i])
duplicate_count.append(count)
if count <= 0:
duplicate_sum.append(0)
elif count > 0:
temp_sum = 0
for j in range(len(data[i])):
temp_sum +=len(data[i][j])
duplicate_sum.append(temp_sum)
return duplicate_count,duplicate_sum تقوم الوظيفة الحادية عشرة بترجمة النص الروسي إلى الأبجدية اللاتينية
الرمز
def transliterate(data):
text_transliterate = []
for i in range(data.shape[0]):
temp_list = list(data[i:i+1])
temp_str = ''.join(temp_list)
result = cyrtranslit.to_latin(temp_str,'ru')
text_transliterate.append(result)
.
, , , . , ,
<spoiler title="">
<source lang="python">def rename_agg_columns(id_client,data,rename):
columns = [id_client]
for lev_0 in data.columns.levels[0]:
if lev_0 != id_client:
for lev_1 in data.columns.levels[1][:-1]:
columns.append(rename % (lev_0, lev_1))
data.columns = columns
return datareturn text_transliterate
هناك حاجة إلى الدالتين الثالثة عشرة والرابعة عشرة لعرض وإنشاء جدول المسافة Levenshtein والمؤشرات المهمة الأخرى.
ما هو نوع الجدول ، وما هي المقاييس فيه وكيف يتم تشكيله؟ دعونا نلقي نظرة على كيفية تشكيل الجدول:
- الخطوة 1. دعنا نحدد البيانات التي سنحتاجها. معرف الزوج ، إنهاء النص - كلا العمودين ، قائمة أسماء الحيازة (أفضل 50 شركة للبتروكيماويات والبناء).
- الخطوة 2. في العمود 1 ، في كل زوج من كل كلمة ، نقيس مسافة Levenshtein إلى كل كلمة من قائمة أسماء الأسماء ، وكذلك طول كل كلمة ونسبة المسافة إلى الطول.
- 3. , 0.4, id , .
- 4. , 0.4, .
- 5. , ID , — . id ( id ). .
- الخطوة 6. الصق الجدول الناتج بجدول البحث.
ميزة مهمة:
الحساب يستغرق وقتًا طويلاً بسبب الكود المكتوب على عجل
الرمز
def dist_name_to_top_list_view(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
words1 = []
words2 = []
top_words = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist1
df['levenstein_dist_w2_top_w'] = dist2
df['length_w1_top_w'] = len(word1)
df['length_w2_top_w'] = len(word2)
df['length_top_w'] = len(top_word)
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
display(data)
print ('Words:', word1,word2,top_word)
print ('Levenstein distance:',dist1,dist2)
print ('Length of word:',len(word1),len(word2),len(top_word))
print ('Ratio (distance/length word):',ratio1,ratio2)
def dist_name_to_top_list_make(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
dist_w1 = []
dist_w2 = []
length_w1 = []
length_w2 = []
length_top_w = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
dist_w1.append(dist1)
dist_w2.append(dist2)
length_w1.append(float(len(word1)))
length_w2.append(float(len(word2)))
length_top_w.append(float(len(top_word)))
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist_w1
df['levenstein_dist_w2_top_w'] = dist_w2
df['length_w1_top_w'] = length_w1
df['length_w2_top_w'] = length_w2
df['length_top_w'] = length_top_w
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
return dataمعالجة البيانات
من واقع خبرتي الصغيرة ، فإن المعالجة المسبقة للبيانات بالمعنى الواسع لهذا التعبير هي التي تستغرق وقتًا أطول. دعنا نذهب بالترتيب.
تحميل البيانات
كل شيء بسيط للغاية هنا. لنقم بتحميل البيانات واستبدال اسم العمود بالتسمية الهدف "is_duplicate" بكلمة "target". هذا من أجل سهولة استخدام الوظائف - تمت كتابة بعضها في بحث سابق واستخدموا اسم العمود مع التسمية الهدف كـ "هدف".
الرمز
# DOWNLOAD DATA
text_train = pd.read_csv('train.csv')
text_test = pd.read_csv('test.csv')
# RENAME DATA
text_train = text_train.rename(columns={"is_duplicate": "target"})لنلق نظرة على البيانات
تم تحميل البيانات. دعونا نرى عدد العناصر في المجموع ومدى توازنها.
الرمز
# ANALYSE BALANCE OF DATA
target_1 = text_train[text_train['target']==1]['target'].count()
target_0 = text_train[text_train['target']==0]['target'].count()
print ('There are', text_train.shape[0], 'objects')
print ('There are', target_1, 'objects with target 1')
print ('There are', target_0, 'objects with target 0')
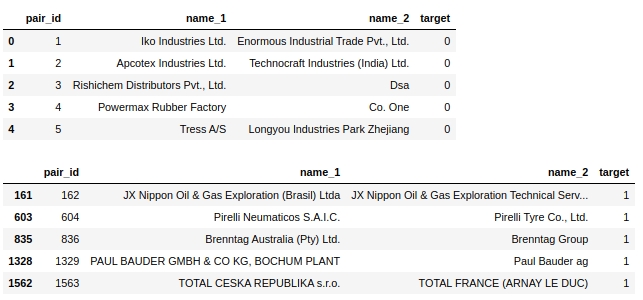
print ('Balance is', round(100*target_1/target_0,2),'%')الجدول №1 "ميزان العلامات"

هناك الكثير من الأشياء - ما يقرب من 500 ألف وهي غير متوازنة على الإطلاق. وهذا يعني أنه من بين ما يقرب من 500 ألف عنصر ، فإن أقل من 4 آلاف عنصر لها تسمية مستهدفة تبلغ 1 (أقل من 1٪) ،
دعونا نلقي نظرة على الجدول نفسه. لنلقِ نظرة على أول خمسة كائنات مسماة 0 وأول خمسة كائنات مسماة 1.
الرمز
display(text_train[text_train['target']==0].head(5))
display(text_train[text_train['target']==1].head(5))الجدول رقم 2 "الكائنات الخمسة الأولى من الفئة 0" ، الجدول رقم 3 "العناصر الخمسة الأولى من الفئة 1"
بعض الخطوات البسيطة تقترح نفسها على الفور: إحضار النص إلى سجل واحد ، وإزالة أي كلمات توقف ، مثل "ltd" ، وحذف البلدان وفي نفس الوقت أسماء المواقع الجغرافية شاء.
في الواقع ، يمكن حل شيء من هذا القبيل في هذه المهمة - تقوم ببعض المعالجة المسبقة ، وتأكد من أنها تعمل كما ينبغي ، وتشغل النموذج ، وتنظر إلى الجودة وتحلل بشكل انتقائي الكائنات التي يكون النموذج بها خطأ. هذه هي الطريقة التي أجريت بها بحثي. ولكن في المقالة نفسها ، يتم تقديم الحل النهائي ولا يتم فهم جودة الخوارزمية بعد كل معالجة مسبقة ، في نهاية المقالة سنجري تحليلًا نهائيًا. خلاف ذلك ، سيكون حجم المقالة لا يوصف :)
لنقم بعمل نسخ
بصراحة ، لا أعرف لماذا أفعل ذلك ، لكن لسبب ما أفعله دائمًا. سأفعلها هذه المرة أيضًا
الرمز
baseline_train = text_train.copy()
baseline_test = text_test.copy()دعنا نحول جميع الأحرف من نص إلى أحرف صغيرة
الرمز
# convert text to lowercase
columns = ['name_1','name_2']
for column in columns:
lower_str(baseline_train,column)
for column in columns:
lower_str(baseline_test,column)إزالة أسماء البلدان
وتجدر الإشارة إلى أن منظمي المسابقة زملاء عظماء! إلى جانب المهمة ، قدموا جهاز كمبيوتر محمول بخط أساس بسيط للغاية ، والذي تم توفيره ، بما في ذلك الكود أدناه.
الرمز
# drop any names of countries
countries = [country.name.lower() for country in pycountry.countries]
for country in tqdm(countries):
baseline_train.replace(re.compile(country), "", inplace=True)
baseline_test.replace(re.compile(country), "", inplace=True)إزالة العلامات والأحرف الخاصة
الرمز
# drop punctuation marks
baseline_train.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_test.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_train.replace(re.compile(r"[^\w\s]"), "", inplace=True)
baseline_test.replace(re.compile(r"[^\w\s]"), "", inplace=True)احذف الأرقام
أفسدت إزالة الأرقام من النص مباشرة على الجبهة ، في المحاولة الأولى ، جودة النموذج بشكل كبير. سأقدم الرمز هنا ، لكن في الحقيقة لم يتم استخدامه.
لاحظ أيضًا أنه حتى هذه النقطة ، قمنا بإجراء التحويل مباشرة على الأعمدة التي تم إعطاؤها لنا. لنقم الآن بإنشاء أعمدة جديدة لكل معالجة مسبقة. سيكون هناك المزيد من الأعمدة ، ولكن إذا حدث فشل في مكان ما في مرحلة ما من المعالجة المسبقة - فلا بأس ، لست بحاجة إلى القيام بكل شيء من البداية ، لأنه سيكون لدينا أعمدة من كل مرحلة من مراحل المعالجة المسبقة.
كود الذي أفسد الجودة. يجب أن تكون أكثر حساسية
# # first: make dictionary of frequency every word
# list_words = baseline_train['name_1'].to_string(index=False).split() +\
# baseline_train['name_2'].to_string(index=False).split()
# freq_words = {}
# for w in list_words:
# freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame of frequency words
# df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
# df_freq.columns = ['word','frequency']
# df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
# df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
# df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
# # third: make drop list of digits
# string = df_freq_agg['word'].to_string(index=False)
# digits = [int(digit) for digit in string.split() if digit.isdigit()]
# digits = set(digits)
# digits = list(digits)
# # drop the digits
# baseline_train['name_1_no_digits'] =\
# baseline_train['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_train['name_2_no_digits'] =\
# baseline_train['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_1_no_digits'] =\
# baseline_test['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_2_no_digits'] =\
# baseline_test['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))دعنا نحذف ... قائمة كلمات التوقف الأولى. يدويا!
يُقترح الآن تعريف وإزالة كلمات التوقف من قائمة الكلمات في أسماء الشركات.
قمنا بتجميع القائمة بناءً على المراجعة اليدوية لعينة التدريب. منطقيا ، يجب تجميع هذه القائمة تلقائيًا باستخدام الأساليب التالية:
- أولاً ، استخدم أفضل 10 كلمات شائعة (2050100).
- ثانيًا ، استخدام مكتبات إيقاف الكلمات القياسية بلغات مختلفة. على سبيل المثال ، تعيينات الأشكال التنظيمية والقانونية للمنظمات بلغات مختلفة (LLC ، PJSC ، CJSC ، ltd ، gmbh ، inc ، إلخ.)
- ثالثًا ، من المنطقي تجميع قائمة بأسماء الأماكن بلغات مختلفة
سنعود إلى الخيار الأول لتجميع قائمة بأهم الكلمات التي تتكرر بشكل متكرر تلقائيًا ، ولكن في الوقت الحالي ننظر في المعالجة المسبقة اليدوية.
الرمز
# drop some stop-words
drop_list = ["ltd.", "co.", "inc.", "b.v.", "s.c.r.l.", "gmbh", "pvt.",
'retail','usa','asia','ceska republika','limited','tradig','llc','group',
'international','plc','retail','tire','mills','chemical','korea','brasil',
'holding','vietnam','tyre','venezuela','polska','americas','industrial','taiwan',
'europe','america','north','czech republic','retailers','retails',
'mexicana','corporation','corp','ltd','co','toronto','nederland','shanghai','gmb','pacific',
'industries','industrias',
'inc', 'ltda', '', '', '', '', '', '', '', '', 'ceska republika', 'ltda',
'sibur', 'enterprises', 'electronics', 'products', 'distribution', 'logistics', 'development',
'technologies', 'pvt', 'technologies', 'comercio', 'industria', 'trading', 'internacionais',
'bank', 'sports',
'express','east', 'west', 'south', 'north', 'factory', 'transportes', 'trade', 'banco',
'management', 'engineering', 'investments', 'enterprise', 'city', 'national', 'express', 'tech',
'auto', 'transporte', 'technology', 'and', 'central', 'american',
'logistica','global','exportacao', 'ceska republika', 'vancouver', 'deutschland',
'sro','rus','chemicals','private','distributors','tyres','industry','services','italia','beijing',
'','company','the','und']
baseline_train['name_1_non_stop_words'] =\
baseline_train['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_non_stop_words'] =\
baseline_train['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_non_stop_words'] =\
baseline_test['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_non_stop_words'] =\
baseline_test['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))دعنا نتحقق بشكل انتقائي من إزالة كلمات التوقف الخاصة بنا بالفعل من النص.
الرمز
baseline_train[baseline_train.name_1_non_stop_words.str.contains("factory")].head(3)الجدول 4 "فحص انتقائي للرمز لإزالة كلمات التوقف"

يبدو أن كل شيء يعمل. تمت إزالة جميع كلمات الإيقاف المفصولة بمسافة. ما أردناه. المضي قدما.
دعونا نترجم النص الروسي إلى الأبجدية اللاتينية
أستخدم وظيفتي المكتوبة ذاتيًا ومكتبة cyrtranslit لهذا الغرض. يبدو أنه يعمل. فحص يدويا.
الرمز
# transliteration to latin
baseline_train['name_1_transliterated'] = transliterate(baseline_train['name_1_non_stop_words'])
baseline_train['name_2_transliterated'] = transliterate(baseline_train['name_2_non_stop_words'])
baseline_test['name_1_transliterated'] = transliterate(baseline_test['name_1_non_stop_words'])
baseline_test['name_2_transliterated'] = transliterate(baseline_test['name_2_non_stop_words'])لنلق نظرة على زوج يحمل المعرف 353150. يحتوي العمود الثاني ("name_2") على كلمة "Michelin" ، بعد المعالجة المسبقة ، تمت كتابة الكلمة بالفعل مثل "mishlen" (انظر العمود "name_2_transliterated"). ليس صحيحًا تمامًا ، لكن من الواضح أنه أفضل.
الرمز
pair_id = 353150
baseline_train[baseline_train['pair_id']==353150]الجدول رقم 5 "التحقق الانتقائي من الرمز للترجمة الصوتية"

لنبدأ التجميع التلقائي لقائمة أفضل 50 كلمة الأكثر تكرارًا وإسقاطها بذكاء. أول شيت
عنوان صعب بعض الشيء. دعونا نلقي نظرة على ما سنفعله هنا.
أولاً ، سنجمع النص من العمودين الأول والثاني في مصفوفة واحدة ونحسب لكل كلمة فريدة عدد مرات حدوثها.
ثانيًا ، دعنا نختار أفضل 50 كلمة من هذه الكلمات. ويبدو أنه يمكنك حذفها ، لكن لا. قد تحتوي هذه الكلمات على أسماء المقتنيات ("total"، "knauf"، "shell"، ...) ، لكن هذه معلومات مهمة جدًا ولا يمكن فقدها ، حيث سنستخدمها أكثر. لذلك ، سنذهب لخدعة الغش (المحرمة). بادئ ذي بدء ، على أساس دراسة دقيقة وانتقائية لعينة التدريب ، سنقوم بتجميع قائمة بأسماء المقتنيات التي يتم مواجهتها بشكل متكرر. لن تكون القائمة كاملة ، وإلا فلن تكون عادلة على الإطلاق :) على الرغم من أننا لا نطارد جائزة ، فلماذا لا. ثم سنقارن بين مجموعة الكلمات الخمسين الأكثر تكرارا مع قائمة الأسماء المقتناة ونزيل من القائمة الكلمات التي تطابق أسماء المقتنيات.
اكتملت الآن قائمة كلمات الإيقاف الثانية. يمكنك إزالة الكلمات من النص.
لكن قبل ذلك ، أود أن أدرج ملاحظة صغيرة بشأن قائمة الغش في الأسماء. حقيقة أننا قمنا بتجميع قائمة بأسماء المقتنيات بناءً على الملاحظات جعلت حياتنا أسهل بكثير. لكن في الواقع ، كان بإمكاننا تجميع مثل هذه القائمة بطريقة مختلفة. على سبيل المثال ، يمكنك الحصول على تصنيفات أكبر الشركات في مجال البتروكيماويات والبناء والسيارات وغيرها من الصناعات ، والجمع بينها وأخذ أسماء المقتنيات من هناك. ولكن لأغراض بحثنا ، سنقتصر على نهج بسيط. هذا النهج محظور في المنافسة! علاوة على ذلك ، يتم فحص منظمي المسابقة وأعمال المرشحين للأماكن الحائزة على جوائز بحثًا عن التقنيات المحظورة. كن حذرا!
الرمز
list_top_companies = ['arlanxeo', 'basf', 'bayer', 'bdp', 'bosch', 'brenntag', 'contitech',
'daewoo', 'dow', 'dupont', 'evonik', 'exxon', 'exxonmobil', 'freudenberg',
'goodyear', 'goter', 'henkel', 'hp', 'hyundai', 'isover', 'itochu', 'kia', 'knauf',
'kraton', 'kumho', 'lusocopla', 'michelin', 'paul bauder', 'pirelli', 'ravago',
'rehau', 'reliance', 'sabic', 'sanyo', 'shell', 'sherwinwilliams', 'sojitz',
'soprema', 'steico', 'strabag', 'sumitomo', 'synthomer', 'synthos',
'total', 'trelleborg', 'trinseo', 'yokohama']
# drop top 50 common words (NAME 1 & NAME 2) exept names of top companies
# first: make dictionary of frequency every word
list_words = baseline_train['name_1_transliterated'].to_string(index=False).split() +\
baseline_train['name_2_transliterated'].to_string(index=False).split()
freq_words = {}
for w in list_words:
freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame
df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
df_freq.columns = ['word','frequency']
df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
drop_list = list(set(df_freq_agg[0:50]['word'].to_string(index=False).split()) - set(list_top_companies))
# # check list of top 50 common words
# print (drop_list)
# drop the top 50 words
baseline_train['name_1_finish'] =\
baseline_train['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_finish'] =\
baseline_train['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_finish'] =\
baseline_test['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_finish'] =\
baseline_test['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
هذا هو المكان الذي ننتهي فيه من المعالجة المسبقة للبيانات. لنبدأ في إنشاء ميزات جديدة وتقييمها بصريًا للقدرة على فصل الكائنات بمقدار 0 أو 1.
توليد الميزات والتحليل
دعونا نحسب مسافة ليفينشتاين
دعنا نستخدم مكتبة strsimpy وفي كل زوج (بعد كل المعالجة المسبقة) نحسب مسافة Levenshtein من اسم الشركة من العمود الأول إلى اسم الشركة في العمود الثاني.
الرمز
# create feature with LEVENSTAIN DISTANCE
levenshtein = Levenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["levenstein"] = baseline_train.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)
baseline_test["levenstein"] = baseline_test.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)دعونا نحسب مسافة ليفينشتاين الطبيعية
كل شيء هو نفسه كما هو مذكور أعلاه ، فقط سنحسب المسافة الطبيعية.
رأس سبويلر
# create feature with NORMALIZATION LEVENSTAIN DISTANCE
normalized_levenshtein = NormalizedLevenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["norm_levenstein"] = baseline_train.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)
baseline_test["norm_levenstein"] = baseline_test.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)قمنا بالعد ، والآن نتخيل
تصور الميزات
دعونا نلقي نظرة على توزيع السمة "ليفنشتاين"
الرمز
data = baseline_train
analyse = 'levenstein'
size = (12,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)الرسوم البيانية # 1 "المدرج التكراري ومربع به شارب لتقييم أهمية الميزة"
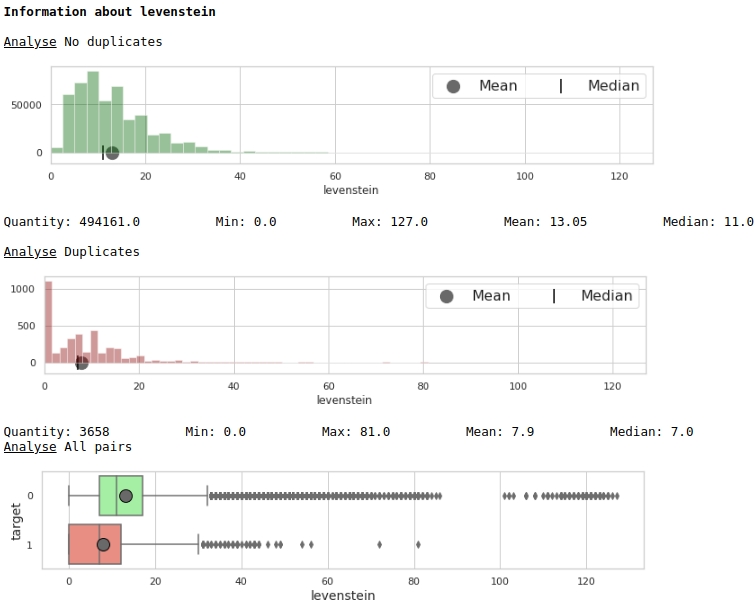
للوهلة الأولى ، يمكن للمقياس ترميز البيانات. من الواضح أنها ليست جيدة جدًا ، ولكن يمكن استخدامها.
دعونا نلقي نظرة على توزيع السمة "norm_levenstein"
رأس سبويلر
data = baseline_train
analyse = 'norm_levenstein'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)الرسوم البيانية №2 "رسم بياني ومربع به شارب لتقييم أهمية العلامة"

بالفعل أفضل. الآن ، دعنا نلقي نظرة على كيفية قيام الميزتين المدمجتين بتقسيم المساحة إلى كائنين 0 و 1.
الرمز
data = baseline_train
analyse1 = 'levenstein'
analyse2 = 'norm_levenstein'
size = (14,6)
two_features(data,analyse1,analyse2,size)الرسم البياني رقم 3 "مخطط مبعثر"
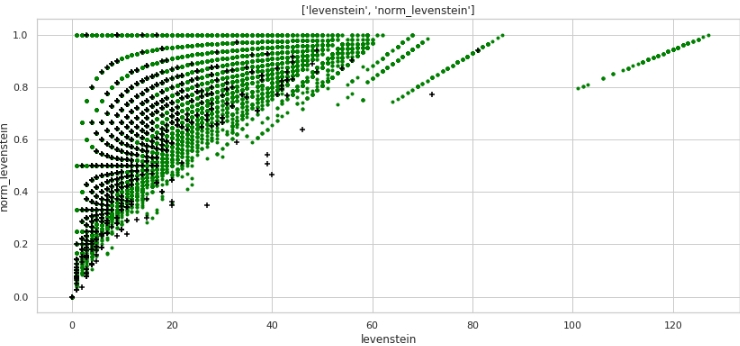
يتم الحصول على ترميز جيد جدًا. لذا فليس عبثًا أننا قمنا بمعالجة البيانات مسبقًا كثيرًا :)
الجميع يفهم ذلك أفقيًا - قيم المقياس "ليفنشتاين" ، وعموديًا - قيم المقياس "norm_levenstein" ، والنقطتان الخضراء والسوداء هما جسمان 0 و 1. تابع.
دعنا نقارن الكلمات في النص لكل زوج وننشئ مجموعة كبيرة من الميزات
أدناه سنقارن الكلمات في أسماء الشركات. لنقم بإنشاء الميزات التالية:
- قائمة بالكلمات المكررة في العمودين # 1 و # 2 من كل زوج
- قائمة الكلمات غير المكررة
بناءً على قوائم الكلمات هذه ، سننشئ الميزات التي سنقوم بإدخالها في النموذج المدرب:
- عدد الكلمات المكررة
- عدد الكلمات غير المكررة
- مجموع الأحرف والكلمات المكررة
- مجموع الأحرف ، وليس الكلمات المكررة
- متوسط طول الكلمات المكررة
- متوسط طول الكلمات غير المكررة
- نسبة عدد التكرارات إلى عدد التكرارات NOT
ربما لا يكون الرمز هنا ودودًا للغاية ، لأنه ، مرة أخرى ، تمت كتابته على عجل. لكنها تعمل ، لكنها ستذهب لإجراء بحث سريع.
الرمز
# make some information about duplicates and differences for TRAIN
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_train.shape[0]):
list1 = list(baseline_train[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_train[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TRAIN
baseline_train['duplicate'] = duplicates
baseline_train['difference'] = difference
baseline_train['duplicate_count'] = duplicate_count
baseline_train['duplicate_sum'] = duplicate_sum
baseline_train['duplicate_mean'] = baseline_train['duplicate_sum'] / baseline_train['duplicate_count']
baseline_train['duplicate_mean'] = baseline_train['duplicate_mean'].fillna(0)
baseline_train['dif_count'] = dif_count
baseline_train['dif_sum'] = dif_sum
baseline_train['dif_mean'] = baseline_train['dif_sum'] / baseline_train['dif_count']
baseline_train['dif_mean'] = baseline_train['dif_mean'].fillna(0)
baseline_train['ratio_duplicate/dif_count'] = baseline_train['duplicate_count'] / baseline_train['dif_count']
# make some information about duplicates and differences for TEST
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_test.shape[0]):
list1 = list(baseline_test[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_test[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TEST
baseline_test['duplicate'] = duplicates
baseline_test['difference'] = difference
baseline_test['duplicate_count'] = duplicate_count
baseline_test['duplicate_sum'] = duplicate_sum
baseline_test['duplicate_mean'] = baseline_test['duplicate_sum'] / baseline_test['duplicate_count']
baseline_test['duplicate_mean'] = baseline_test['duplicate_mean'].fillna(0)
baseline_test['dif_count'] = dif_count
baseline_test['dif_sum'] = dif_sum
baseline_test['dif_mean'] = baseline_test['dif_sum'] / baseline_test['dif_count']
baseline_test['dif_mean'] = baseline_test['dif_mean'].fillna(0)
baseline_test['ratio_duplicate/dif_count'] = baseline_test['duplicate_count'] / baseline_test['dif_count']
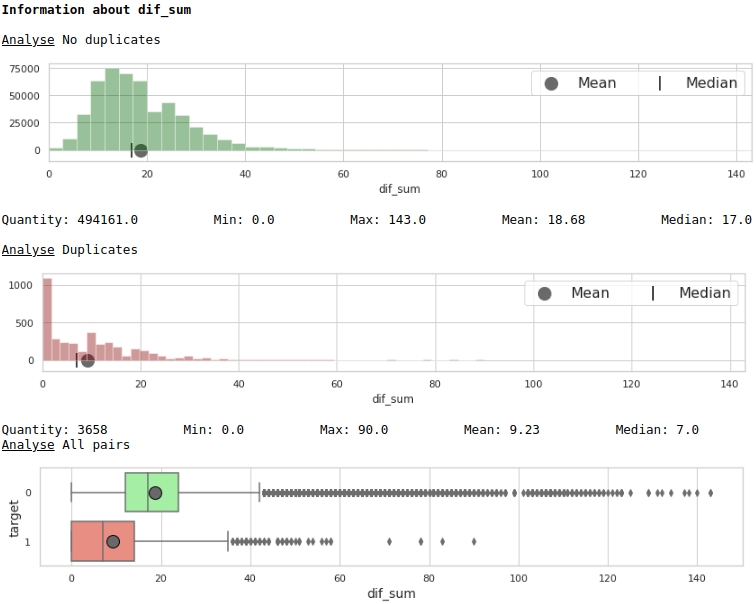
نتخيل بعض العلامات.
الرمز
data = baseline_train
analyse = 'dif_sum'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)الرسوم البيانية رقم 4 "رسم بياني ومربع به شارب لتقييم أهمية العلامة"
الرمز
data = baseline_train
analyse1 = 'duplicate_mean'
analyse2 = 'dif_mean'
size = (14,6)
two_features(data,analyse1,analyse2,size)رسم بياني №5 "مخطط مبعثر"
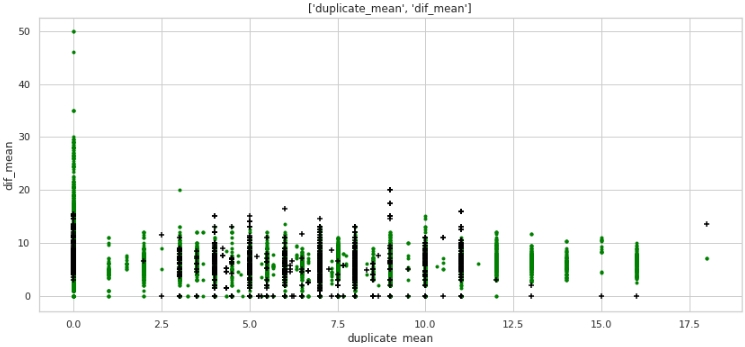
ما لا ، ولكن الترميز. انتبه إلى حقيقة أن الكثير من الشركات التي تحمل التصنيف المستهدف 1 ليس لديها أي نسخ مكررة في النص ، كما أن الكثير من الشركات التي تحتوي على نسخ مكررة في أسمائها ، في المتوسط أكثر من 12 كلمة ، تنتمي إلى شركات ذات تصنيف مستهدف 0.
دعونا نلقي نظرة على البيانات الجدولية ، وقم بإعداد استعلام في الحالة الأولى: لا يوجد أي تكرار في أسماء الشركات ، لكن الشركات هي نفسها.
الرمز
baseline_train[
baseline_train['duplicate_mean']==0][
baseline_train['target']==1].drop(
['duplicate', 'difference',
'name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated'],axis=1)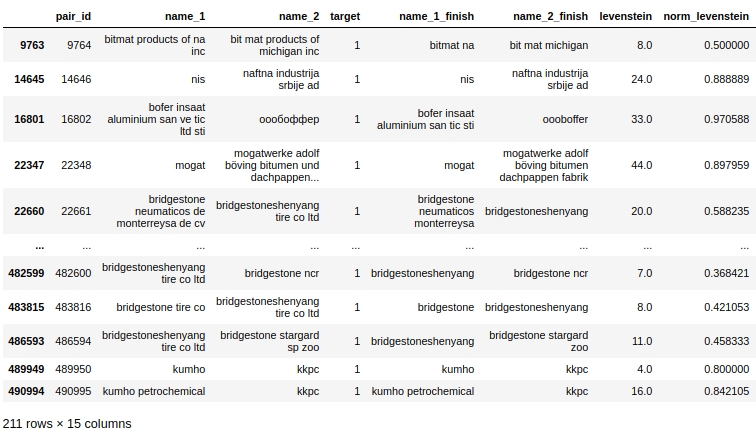
من الواضح أن هناك خطأ في النظام في معالجتنا. لم نأخذ في الاعتبار أن الكلمات يمكن تهجئتها ليس فقط بالأخطاء ، ولكن أيضًا ببساطة معًا أو ، على العكس من ذلك ، بشكل منفصل حيث لا يكون ذلك مطلوبًا. على سبيل المثال ، زوج # 9764. في العمود الأول "bitmat" في "bit mat" الثاني والآن هذه ليست مزدوجة ، لكن الشركة هي نفسها. أو مثال آخر ، زوج # 482600 'bridgestoneshenyang' و 'bridgestone'.
ما الذي يمكن عمله. أول ما خطر ببالي هو المقارنة ليس مباشرة على الجبهة ، ولكن باستخدام مقياس Levenshtein. ولكن هنا أيضًا ، ينتظرنا كمين: لن تكون المسافة بين "بريدجستونشينيانغ" و "بريدجستون" صغيرة. ربما سيأتي اللوم إلى الإنقاذ ، لكن مرة أخرى ليس من الواضح على الفور كيف يمكن أن تُزال أسماء الشركات. أو يمكنك استخدام معامل Tamimoto ، لكن دعنا نترك هذه اللحظة للرفاق الأكثر خبرة ونمضي قدمًا.
دعنا نقارن الكلمات من النص بكلمات من أسماء أفضل 50 علامة تجارية في مجال البتروكيماويات والبناء والصناعات الأخرى. دعنا نحصل على الكومة الكبيرة الثانية من الميزات. الشيت الثاني
في الواقع ، هناك مخالفتان لقواعد المشاركة في المسابقة:
- -, , «duplicate_name_company»
- -, . , .
كلا الأسلوبين محظوران بموجب قواعد المسابقة. يمكنك تجاوز الحظر. للقيام بذلك ، تحتاج إلى تجميع قائمة بأسماء الأسماء التي لا تستند يدويًا إلى عرض انتقائي لعينة التدريب ، ولكن تلقائيًا - من مصادر خارجية. ولكن بعد ذلك ، أولاً ، ستصبح قائمة المقتنيات كبيرة وستستغرق مقارنة الكلمات المقترحة في العمل الكثير من الوقت ، وثانيًا ، لا تزال هذه القائمة بحاجة إلى التجميع :) لذلك ، لأغراض بساطة البحث ، سوف نتحقق من مدى تحسن جودة النموذج مع هذه العلامات. استشراف المستقبل - الجودة تزداد بشكل مذهل!
في الطريقة الأولى ، يبدو كل شيء واضحًا ، لكن الطريقة الثانية تتطلب تفسيرات.
لذلك ، دعونا نحدد مسافة Levenshtein من كل كلمة في كل سطر من العمود الأول مع اسم الشركة لكل كلمة من قائمة أفضل شركات البتروكيماويات (وليس فقط).
إذا كانت نسبة مسافة Levenshtein إلى طول الكلمة أقل من أو تساوي 0.4 ، فإننا نحدد نسبة مسافة Levenshtein إلى الكلمة المحددة من قائمة أفضل الشركات لكل كلمة من العمود الثاني - اسم الشركة الثانية.
إذا تبين أن المعامل الثاني (نسبة المسافة إلى طول الكلمة من قائمة أفضل الشركات) أقل من أو يساوي 0.4 ، فإننا نصلح القيم التالية في الجدول:
- Levenshtein المسافة من كلمة من قائمة الشركات رقم 1 إلى كلمة واحدة في قائمة الشركات الكبرى
- Levenshtein المسافة من كلمة من قائمة الشركات رقم 2 إلى كلمة واحدة في قائمة الشركات الكبرى
- طول الكلمة من القائمة رقم 1
- طول الكلمة من القائمة رقم 2
- طول الكلمة من قائمة أفضل الشركات
- نسبة طول الكلمة من القائمة رقم 1 إلى المسافة
- نسبة طول الكلمة من القائمة رقم 2 إلى المسافة
يمكن أن يكون هناك أكثر من تطابق واحد في سطر واحد ، دعنا نختار الحد الأدنى منها (وظيفة التجميع).
أود أن ألفت انتباهك مرة أخرى إلى حقيقة أن الطريقة المقترحة لإنشاء الميزات كثيفة الاستخدام للموارد ، وفي حالة الحصول على قائمة من مصدر خارجي ، سيكون من الضروري إجراء تغيير في رمز تجميع المقاييس.
الرمز
# create information about duplicate name of petrochemical companies from top list
list_top_companies = list_top_companies
dp_train = []
for i in list(baseline_train['duplicate']):
dp_train.append(''.join(list(set(i) & set(list_top_companies))))
dp_test = []
for i in list(baseline_test['duplicate']):
dp_test.append(''.join(list(set(i) & set(list_top_companies))))
baseline_train['duplicate_name_company'] = dp_train
baseline_test['duplicate_name_company'] = dp_test
# replace name duplicate to number
baseline_train['duplicate_name_company'] =\
baseline_train['duplicate_name_company'].replace('',0,regex=True)
baseline_train.loc[baseline_train['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
baseline_test['duplicate_name_company'] =\
baseline_test['duplicate_name_company'].replace('',0,regex=True)
baseline_test.loc[baseline_test['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
# create some important feature about similar words in the data and names of top companies for TRAIN
# (levenstein distance, length of word, ratio distance to length)
baseline_train = dist_name_to_top_list_make(baseline_train,
'name_1_finish','name_2_finish',list_top_companies)
# create some important feature about similar words in the data and names of top companies for TEST
# (levenstein distance, length of word, ratio distance to length)
baseline_test = dist_name_to_top_list_make(baseline_test,
'name_1_finish','name_2_finish',list_top_companies)
دعونا نلقي نظرة على فائدة الميزات من خلال منشور المخططات
الرمز
data = baseline_train
analyse = 'levenstein_dist_w1_top_w_min'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)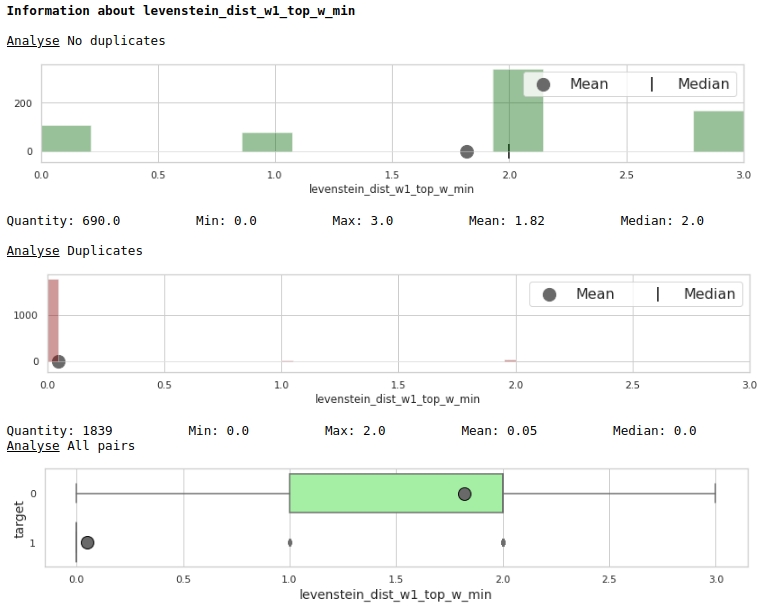
حسن جدا.
تجهيز البيانات لتقديمها إلى النموذج
لدينا جدول كبير ولا نحتاج كل البيانات للتحليل. لنلقِ نظرة على أسماء أعمدة الجدول.
الرمز
baseline_train.columns
دعنا نختار تلك الأعمدة التي سنقوم بتحليلها.
دعنا نصلح البذور لاستنساخ النتيجة.
الرمز
# fix some parameters
features = ['levenstein','norm_levenstein',
'duplicate_count','duplicate_sum','duplicate_mean',
'dif_count','dif_sum','dif_mean','ratio_duplicate/dif_count',
'duplicate_name_company',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min'
]
seed = 42قبل تدريب النموذج أخيرًا على جميع البيانات المتاحة وإرسال الحل للتحقق ، من المنطقي اختبار النموذج. للقيام بذلك ، قمنا بتقسيم عينة التدريب إلى تدريب مشروط واختبار مشروط. سنقوم بقياس الجودة عليها وإذا كان يناسبنا فسنرسل الحل للمنافسة.
الرمز
# provides train/test indices to split data in train/test sets
split = StratifiedShuffleSplit(n_splits=1, train_size=0.8, random_state=seed)
tridx, cvidx = list(split.split(baseline_train[features],
baseline_train["target"]))[0]
print ('Split baseline data train',baseline_train.shape[0])
print (' - new train data:',tridx.shape[0])
print (' - new test data:',cvidx.shape[0])إعداد النموذج وتدريبه
سوف نستخدم شجرة القرار من مكتبة Light GBM كنموذج.
ليس من المنطقي إنهاء الكثير من المعلمات. نحن ننظر إلى الكود.
الرمز
# learning Light GBM Classificier
seed = 50
params = {'n_estimators': 1,
'objective': 'binary',
'max_depth': 40,
'min_child_samples': 5,
'learning_rate': 1,
# 'reg_lambda': 0.75,
# 'subsample': 0.75,
# 'colsample_bytree': 0.4,
# 'min_split_gain': 0.02,
# 'min_child_weight': 40,
'random_state': seed}
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train.iloc[tridx][features].values,
baseline_train.iloc[tridx]["target"].values)تم ضبط النموذج وتدريبه. الآن دعونا نلقي نظرة على النتائج.
الرمز
# make predict proba and predict target
probability_level = 0.99
X = baseline_train
tridx = tridx
cvidx = cvidx
model = model
X_tr, X_cv = contingency_table(X,features,probability_level,tridx,cvidx,model)
train_matrix_confusion = matrix_confusion(X_tr)
cv_matrix_confusion = matrix_confusion(X_cv)
report_score(train_matrix_confusion,
cv_matrix_confusion,
baseline_train,
tridx,cvidx,
X_tr,X_cv)
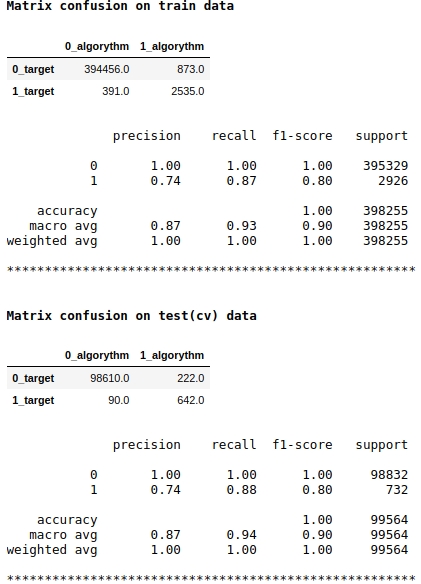
لاحظ أننا نستخدم مقياس الجودة f1 كنقطة نموذج. هذا يعني أنه من المنطقي تنظيم مستوى احتمال تخصيص كائن للفئة 1 أو 0. لقد اخترنا المستوى 0.99 ، أي إذا كان الاحتمال يساوي أو أعلى من 0.99 ، فسيتم تخصيص الكائن للفئة 1 ، أقل من 0.99 - للفئة 0. هذه نقطة مهمة - يمكنك تحسين السرعة بشكل كبير هذه خدعة بسيطة صعبة.
يبدو أن الجودة ليست سيئة. في عينة اختبار مشروط ، ارتكبت الخوارزمية أخطاء عند تحديد 222 كائنًا من الفئة 0 وعلى 90 كائنًا تنتمي إلى الفئة 0 ، ارتكبت خطأً وخصصتها للفئة 1 (انظر ارتباك المصفوفة في بيانات الاختبار (السيرة الذاتية)).
دعونا نرى العلامات الأكثر أهمية والتي لم تكن كذلك.
الرمز
start = 0
stop = 50
size = (12,6)
tg = table_gain_coef(model,features,start,stop)
gain_hist(tg,size,start,stop)
display(tg)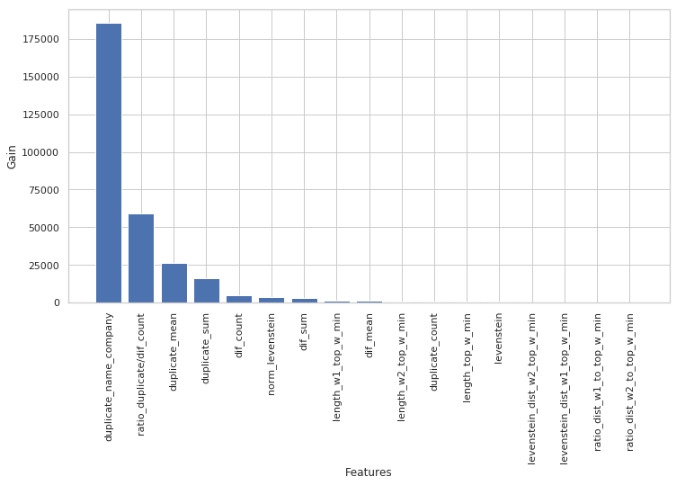
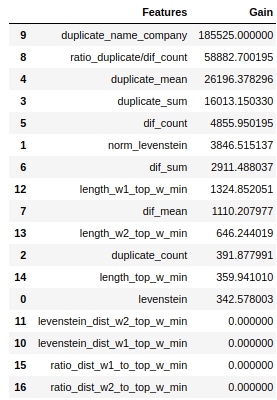
لاحظ أننا استخدمنا معلمة "كسب" ، وليس معلمة "تقسيم" لتقييم أهمية الميزات. هذا مهم لأنه في إصدار مبسط للغاية ، تعني المعلمة الأولى مساهمة الميزة في تقليل الانتروبيا ، وتشير الثانية إلى عدد المرات التي تم فيها استخدام الميزة لتمييز الفضاء.
للوهلة الأولى ، الميزة التي كنا نقوم بها لفترة طويلة جدًا ، "levenstein_dist_w1_top_w_min" ، تبين أنها ليست مفيدة على الإطلاق - مساهمتها هي 0. ولكن هذا فقط للوهلة الأولى. إنه ببساطة مكرر بالكامل تقريبًا في المعنى مع سمة "Dupate_name_company". إذا حذفت "Dupate_name_company" وتركت "levenstein_dist_w1_top_w_min" ، فإن الميزة الثانية ستحل محل الأولى ولن تتغير الجودة. التحقق!
بشكل عام ، تعد هذه العلامة أمرًا مفيدًا ، خاصةً عندما يكون لديك مئات الميزات ونموذج به مجموعة من الأجراس والصفارات و 5000 تكرار.يمكنك إزالة الميزات على دفعات ومشاهدة كيف تنمو الجودة من هذا الإجراء غير الماكرة. في حالتنا ، لن تؤثر إزالة الميزات على الجودة.
دعنا نلقي نظرة على طاولة رفيقه. بادئ ذي بدء ، دعونا نلقي نظرة على الكائنات "إيجابية خطأ" ، أي تلك التي حددتها خوارزميتنا لتكون متطابقة وخصصتها للفئة 1 ، لكنها في الواقع تنتمي إلى الفئة 0.
الرمز
X_cv[X_cv['False_Positive']==1][0:50].drop(['name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated', 'duplicate', 'difference',
'levenstein',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min',
'True_Positive','True_Negative','False_Negative'],axis=1)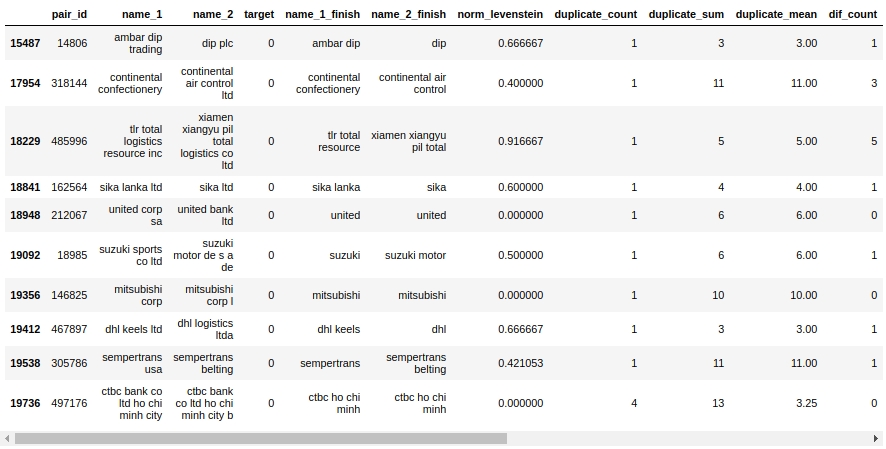
بلى. هنا ، لن يحدد الشخص على الفور 0 أو 1. على سبيل المثال ، الزوج # 146825 "mitsubishi corp" و "mitsubishi corp l". تقول العيون أنه نفس الشيء ، لكن العينة تقول إنها شركات مختلفة. لمن تصدق؟
دعنا نقول فقط أنه يمكنك الضغط على الفور - لقد ضغطنا للخارج. سنترك باقي العمل للرفاق ذوي الخبرة :)
لنقم بتحميل البيانات إلى موقع المنظم على شبكة الإنترنت ومعرفة تقييم جودة العمل.
نتائج المسابقة
الرمز
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train[features].values,
baseline_train["target"].values)
sample_sub = pd.read_csv('sample_submission.csv', index_col="pair_id")
sample_sub['is_duplicate'] = (model.predict_proba(
baseline_test[features].values)[:, 1] > probability_level).astype(np.int)
sample_sub.to_csv('baseline_submission.csv')
لذلك ، صيامنا ، مع الأخذ في الاعتبار الطريقة المحظورة: 0.5999
بدونها ، كانت الجودة في مكان ما بين 0.3 و 0.4. نحتاج إلى إعادة تشغيل النموذج من أجل الدقة ، لكنني كسول قليلاً :)
لنلخص التجربة بشكل أفضل.
أولاً ، كما ترى ، لدينا رمز قابل للتكرار تمامًا وبنية ملف مناسبة إلى حد ما. نظرًا لخبرتي القليلة ، في وقت من الأوقات حصلت على الكثير من المطبات على وجه التحديد لأنني كنت أقوم بملء العمل على عجل ، فقط للحصول على بعض السرعة الممتعة أو أقل. نتيجة لذلك ، تبين أن الملف أصبح مخيفًا بعد أسبوع من فتحه - لا يوجد شيء واضح. لذلك ، رسالتي هي - اكتب الكود على الفور واجعل الملف قابلاً للقراءة ، بحيث يمكنك في غضون عام العودة إلى البيانات ، وإلقاء نظرة على الهيكل أولاً ، وفهم الخطوات التي تم اتخاذها ، ثم حتى يمكن تفكيك كل خطوة بسهولة. بالطبع ، إذا كنت مبتدئًا ، ففي المحاولة الأولى ، لن يكون الملف جميلًا ، وسوف ينكسر الكود ، وستكون هناك عكازات ، ولكن إذا قمت بإعادة كتابة الكود بشكل دوري أثناء عملية البحث ،ثم بحلول 5-7 مرات إعادة الكتابة ، سوف تفاجأ بنفسك بمدى نظافة الكود وربما تجد أخطاء وتحسن السرعة. لا تنسى الوظائف ، فهي تجعل من السهل جدًا قراءة الملف.
ثانيًا ، بعد كل معالجة للبيانات ، تحقق مما إذا كان كل شيء سار على النحو المنشود. للقيام بذلك ، يجب أن تكون قادرًا على تصفية الجداول في الباندا. هناك الكثير من التصفية في هذا العمل ، استخدمه للصحة :)
ثالثًا ، دائمًا ، وبصراحة دائمًا ، في مهام التصنيف ، قم بتكوين جدول ومصفوفة تصريف. من الجدول ، يمكنك بسهولة العثور على الكائنات الخاطئة في الخوارزمية. بادئ ذي بدء ، حاول ملاحظة تلك الأخطاء التي تسمى أخطاء النظام ، فهي تتطلب جهدًا أقل لإصلاحها ، ولكنها تعطي نتائج أكثر. بعد ذلك ، بمجرد فرز أخطاء النظام ، انتقل إلى الحالات الخاصة. من خلال مصفوفة الأخطاء ، سترى أين ترتكب الخوارزمية المزيد من الأخطاء: في الصنف 0 أو 1. من هنا سوف تحفر الأخطاء. على سبيل المثال ، لاحظت أن شجرتى تحدد الفئات 1 جيدًا ، ولكنها ترتكب الكثير من الأخطاء في الفئة 0 ، أي أن الشجرة غالبًا "تقول" أن هذا الكائن من الفئة 1 ، بينما في الحقيقة هو 0. افترضت أنه قد يكون كذلك يرتبط بمستوى احتمال تصنيف كائن كـ 0 أو 1. تم تثبيت مستوي عند 0.9.أدت الزيادة في مستوى احتمالية تخصيص كائن للفئة 1 إلى 0.99 إلى جعل اختيار الكائنات من الفئة 1 أكثر صرامة وفويلا - أعطت سرعتنا زيادة كبيرة.
مرة أخرى ، سألاحظ أن الغرض من المشاركة في المسابقة لم يكن الفوز بجائزة ، ولكن اكتساب الخبرة. بالنظر إلى أنه قبل بدء المسابقة ، لم يكن لدي أي فكرة عن كيفية التعامل مع النصوص في التعلم الآلي ، ونتيجة لذلك ، حصلت في غضون أيام قليلة على نموذج بسيط ، ولكنه لا يزال يعمل ، ثم يمكننا القول إن الهدف قد تحقق. أيضًا ، بالنسبة لأي ساموراي مبتدئ في عالم علم البيانات ، أعتقد أنه من المهم اكتساب الخبرة ، وليس الحصول على جائزة ، أو بالأحرى ، الخبرة هي الجائزة. لذلك لا تخافوا من المشاركة في المسابقات ، انطلقوا ، الجميع سمور!
في وقت نشر المقال ، لم تنته المنافسة بعد. بناءً على نتائج إتمام المسابقة ، في التعليقات على المقالة ، سأكتب عن السرعة القصوى العادلة ، حول الأساليب والميزات التي تعمل على تحسين جودة النموذج.
وأنت قارئ عزيز ، إذا كانت لديك أفكار حول كيفية زيادة السرعة الآن ، فاكتب في التعليقات. اعمل عملا صالحا :)
مصادر المعلومات والمواد المساعدة
- "Github with Data and Jupyter Notebook"
- "منصة مسابقة SIBUR CHALLENGE 2020"
- "موقع منظم مسابقة SIBUR CHALLENGE 2020"
- "مقال جيد عن حبري" أساسيات معالجة اللغة الطبيعية للنص ""
- "مقال جيد آخر عن حبري" مقارنة سلسلة ضبابية: افهمني إذا استطعت ""
- "منشور من مجلة APNI"
- "مقال عن معامل تانيموتو" تشابه السلسلة "غير مستخدم هنا"