
تتمثل إحدى مهام فحص التنظير الصوتي في إثبات صحة التسجيل الصوتي ومصداقيته - وبعبارة أخرى ، لتحديد علامات التحرير والتشويه والتغيير في التسجيل. كانت لدينا مهمة إجراء ذلك من أجل إثبات صحة السجلات - لتحديد عدم وجود أي تأثيرات على السجلات. ولكن كيف تحلل الآلاف وحتى مئات الآلاف من التسجيلات الصوتية؟
تأتي أساليب الذكاء الاصطناعي لإنقاذنا ، بالإضافة إلى أداة مساعدة للعمل مع الصوت ، والتي تحدثنا عنها في مقال على موقع NewTechAudit على الويب "معالجة الصوت باستخدام FFMPEG" .
كيف تظهر التغييرات في الصوت؟ كيف تميز بين ملف معدل وملف لم يتم لمسه؟
هناك العديد من هذه العلامات ، وأبسطها هو تحديد المعلومات الخاصة بتحرير ملف وتحليل تاريخ تعديله. يتم تنفيذ هذه الأساليب بسهولة عن طريق نظام التشغيل نفسه ، لذلك لن نتطرق إلى هذه الأساليب. ولكن يمكن إجراء التغييرات بواسطة مستخدم أكثر تأهيلاً يمكنه إخفاء أو تغيير المعلومات حول التحرير ، وفي هذه الحالة ، يتم استخدام طرق أكثر تعقيدًا ، على سبيل المثال:
- تحول ملامح
- تغيير المظهر الطيفي للصوت المسجل ؛
- ظهور فترات التوقف.
- واشياء أخرى عديدة.
ويتم تنفيذ جميع طرق السبر المعقدة هذه من قبل خبراء مدربين تدريباً خاصاً - أخصائيو التنظير الصوتي باستخدام برامج متخصصة مثل Praat و Speech Analyzer SIL و ELAN ، والتي يتم دفع معظمها وتتطلب مؤهلات عالية بما يكفي لاستخدام وتفسير النتائج.
يقوم الخبراء بتحليل الصوت باستخدام ملف تعريف طيفي ، أي من خلال تحليل معاملات cepstral. سنستخدم خبرة الخبراء ، وفي نفس الوقت نستخدم الكود الجاهز ، ونكيفه مع مهمتنا.
إذن هناك الكثير من التغييرات التي يمكن إجراؤها ، كيف نختار؟
من بين الأنواع المحتملة للتغييرات التي يمكن إجراؤها على الملفات الصوتية ، نحن مهتمون باستبعاد جزء من الصوت ، أو قطع جزء منه ثم استبدال الجزء الأصلي بقطعة من نفس المدة - ما يسمى بتغييرات القص / النسخ. تحرير الملفات من حيث تقليل الضوضاء وتغيير تردد النغمة وغيرها لا تحمل مخاطر إخفاء المعلومات.
وكيف سنتعرف على نفس القطع / النسخ؟ هل يجب مقارنتهم بشيء؟
الأمر بسيط للغاية - بمساعدة الأداة FFmpeg ، سنقتطع جزءًا من المدة العشوائية من الملف وفي مكان عشوائي ، وبعد ذلك سنقارن بين مخططات الطيف الصغيرة للملف الأصلي والملف "المقطوع".
كود لعرضها:
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
def make_spek(audio):
n_fft = 2048
y, sr = librosa.load(audio)
ft = np.abs(librosa.stft(y[:n_fft], hop_length = n_fft+1))
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max)
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(mel_spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time');
plt.title('Mel Spectrogram');
plt.colorbar(format='%+2.0f dB');
plt.show();
make_spek('./audio/original.wav')# './audio/original.wav' نقوم بإعداد مجموعة بيانات من المصدر ونقطع الملفات باستخدام أمر الأداة المساعدة FFmpeg:
ffmpeg -i oroginal.wav -ss STARTTIME -to ENDTIME -acodec copy cut.wav حيث STARTTIME و ENDTIME هما بداية ونهاية الجزء المقطوع. وباستخدام الأمر:
ffmpeg -iconcat:"part_0.wav|part_1.wav |part_2.wav" -codeccopyconcat.wavانضم إلى جزء الملف لإدخال part_1.wav مع الأجزاء الأصلية (لتغليف أوامر FFmpeg في بيثون ، راجع مقالتنا على FFmpeg).
فيما يلي الملفات الأصلية للطباشير الطيفية التي تم قطعها من الصوت لمدة 0.2-2.5 ثانية ، والطباشير الطيفي للملفات التي تم قطعها من الصوت لمدة 0.2-2.5 ثانية ، ثم تم إدراجها في الأجزاء الصوتية ذات المدة المماثلة لهذا الملف الصوتي:
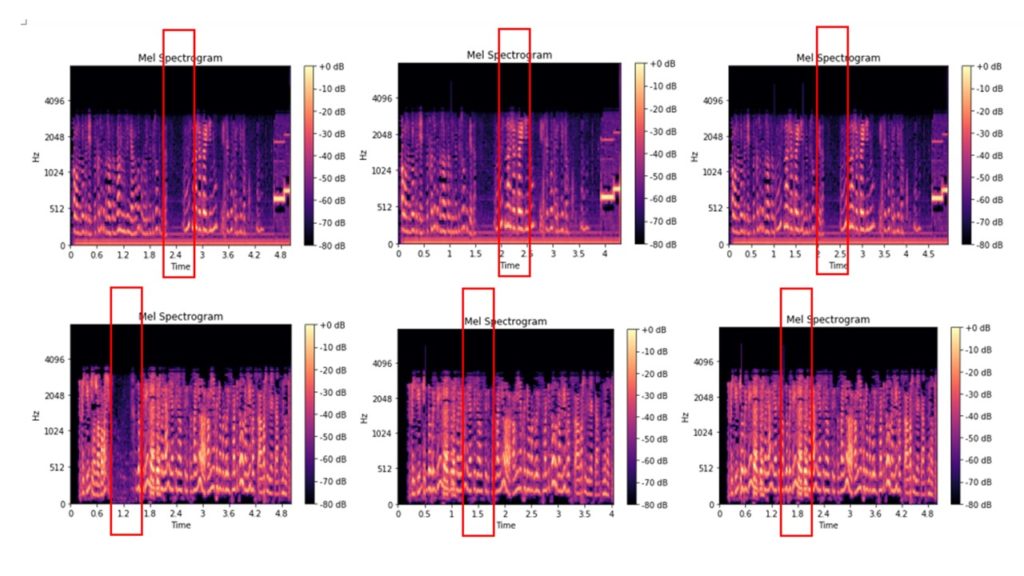
بعض يمكن تمييز الصور حتى بصريًا ، والبعض الآخر يبدو متماثلًا تقريبًا. نوزع الصور الناتجة في مجلدات ونستخدمها كبيانات إدخال لتدريب النموذج على تصنيف الصور. هيكل المجلد:
model.py #
/input/train/original/ #
/input/train/cut_copy/ # بالنسبة لنا ، لا فرق بين ما إذا كان ملف الصوت المعدل قد تم تكميله أو تقصيره - فنحن نقسم جميع النتائج إلى ملفات جيدة ، أي ملفات بدون تغييرات وسيئة. وهكذا ، فإننا نحل مشكلة التصنيف الثنائي الكلاسيكية. سنقوم بتصنيف استخدام الشبكات العصبية ، وسنأخذ الكود للعمل مع شبكة عصبية جاهزة من أمثلة العمل مع حزمة Keras.
#
from keras.models import Sequential
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
#
classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Flatten())
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 1, activation = 'sigmoid'))
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
#
from keras.preprocessing.image import ImageDataGenerator as img
train_datagen = img(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = img(rescale = 1./255)
training_set = train_datagen.flow_from_directory('input/train',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
test_set = test_datagen.flow_from_directory('input/test',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
classifier.fit_generator(
training_set,
steps_per_epoch = 8000,
epochs = 25,
validation_data = test_set,
validation_steps = 2000)علاوة على ذلك ، بعد تدريب النموذج ، نقوم بالتصنيف بمساعدته
import numpy as np
from keras.preprocessing import image
test_image = image.load_img('dataset/prediction/original_or_corrupt.jpg', target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
ifresult[0][0] == 1:
prediction = 'original'
else:
prediction = 'corrupt'عند الإخراج نحصل على تصنيف الملف الصوتي - "أصلي" / "فاسد" ، أي الملف دون تغيير والملفات التي تم إجراء التغييرات عليها.
أثبتنا مرة أخرى أن الأشياء المعقدة يمكن القيام بها ببساطة - لم نستخدم أصعب آلية لأساليب الذكاء الاصطناعي ، والحلول الجاهزة وفحصنا الصوت بحثًا عن التغييرات. حسنًا ، كنا خبراء من المحقق.