أنا أعمل حاليًا في ManyChat. في الواقع ، هذه شركة ناشئة - جديدة وطموحة وسريعة النمو. وعندما دخلت للتو إلى الشركة ، نشأ السؤال الكلاسيكي: "ما الذي يجب على شركة ناشئة أن تأخذها الآن من سوق قواعد البيانات ونظام إدارة قواعد البيانات؟"
في هذه المقالة ، بناءً على حديثي في مهرجان RIT ++ 2020 عبر الإنترنت ، سأجيب على هذا السؤال. نسخة الفيديو من التقرير متاحة على موقع يوتيوب .
قواعد البيانات المعروفة لعام 2020
إنه عام 2020 ، نظرت حولي ورأيت ثلاثة أنواع من قواعد البيانات.
النوع الأول هو قواعد بيانات OLTP الكلاسيكية : PostgreSQL و SQL Server و Oracle و MySQL. لقد تم كتابتها منذ وقت طويل ، لكنها لا تزال ذات صلة لأنها مألوفة لمجتمع المطورين.
النوع الثاني - قواعد من "صفر" . لقد حاولوا الابتعاد عن الأنماط الكلاسيكية عن طريق الابتعاد عن SQL والهياكل التقليدية و ACID ، عن طريق إضافة التجزئة المضمنة وغيرها من الميزات الجذابة. على سبيل المثال ، هذه هي Cassandra أو MongoDB أو Redis أو Tarantool. أرادت كل هذه الحلول أن تقدم للسوق شيئًا جديدًا بشكل أساسي واحتلت مكانته ، لأنه في بعض المهام تبين أنها مريحة للغاية. سيتم الإشارة إلى هذه القواعد بواسطة المصطلح الشامل NOSQL.
لقد انتهى عدد "الصفر" ، وقد اعتادوا على قواعد بيانات NOSQL ، والعالم ، من وجهة نظري ، قد اتخذ الخطوة التالية - إلى قواعد البيانات المُدارة . قواعد البيانات هذه لها نفس النواة مثل قواعد بيانات OLTP الكلاسيكية أو قواعد بيانات NoSQL الجديدة. لكنهم لا يحتاجون إلى DBA و DevOps وهم يعملون على الأجهزة المدارة في السحاب. بالنسبة للمطور ، هذه "مجرد قاعدة" تعمل في مكان ما ، ولكن كيف يتم تثبيتها على الخادم ، ومن قام بتكوين الخادم ومن يقوم بتحديثه ، لا أحد يهتم.
أمثلة على هذه القواعد:
- AWS RDS عبارة عن غلاف مُدار عبر PostgreSQL / MySQL.
- DynamoDB هو نظير AWS لقاعدة بيانات قائمة على المستندات ، على غرار Redis و MongoDB.
- Amazon Redshift هي قاعدة تحليلات مُدارة.
في الأساس ، هذه قواعد قديمة ، لكنها نشأت في بيئة مُدارة ، دون الحاجة إلى العمل مع الأجهزة.
ملحوظة. تم أخذ الأمثلة لبيئة AWS ، لكن نظرائهم موجودون أيضًا في Microsoft Azure أو Google Cloud أو Yandex.Cloud.

اذن مالجديد؟ في عام 2020 ، لا شيء من هذا.
مفهوم Serverless
الجديد حقًا في السوق في عام 2020 هو حلول بدون خادم أو خادم.
سأحاول شرح ما يعنيه هذا باستخدام مثال خدمة عادية أو تطبيق خلفي.
لنشر تطبيق خلفي عادي ، نقوم بشراء أو تأجير خادم ، ونسخ الرمز إليه ، ونشر نقطة النهاية في الخارج ، ودفع الإيجار ، والكهرباء ، وخدمات مركز البيانات بانتظام. هذا هو التخطيط القياسي.
هل هناك أي طريقة أخرى؟ مع الخدمات بدون خادم ، يمكنك ذلك.
ما هو محور هذا النهج: لا يوجد خادم ، ولا يوجد حتى تأجير مثيل افتراضي في السحابة. لنشر الخدمة ، انسخ الكود (الوظائف) إلى المستودع وانشر نقطة النهاية في الخارج. ثم ندفع فقط مقابل كل استدعاء لهذه الوظيفة ، متجاهلين تمامًا الأجهزة التي يتم تنفيذها فيها.
سأحاول توضيح هذا النهج بالصور.
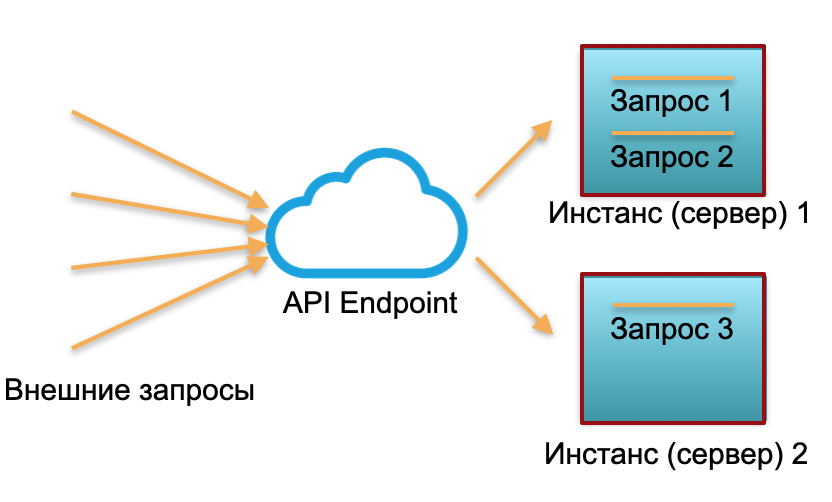
النشر الكلاسيكي . لدينا خدمة ذات حمولة معينة. نطرح حالتين: الخوادم المادية أو المثيلات في AWS. يتم إرسال الطلبات الخارجية إلى هذه المثيلات ومعالجتها هناك.
كما ترى في الصورة ، يتم استخدام الخوادم بشكل مختلف. أحدهما مستخدم بنسبة 100٪ ، وهناك طلبان ، والآخر 50٪ خاملاً جزئيًا. إذا لم تأت ثلاثة طلبات ، ولكن 30 ، فلن يتمكن النظام بأكمله من التعامل مع الحمل وسيبدأ في التباطؤ.

النشر بدون خادم... في بيئة بدون خادم ، لا تحتوي هذه الخدمة على مثيلات أو خوادم. هناك مجموعة من الموارد المحسّنة - حاويات Docker صغيرة معدة برمز الوظيفة المنشور. يتلقى النظام الطلبات الخارجية ولكل منها يقوم إطار العمل بدون خادم برفع حاوية صغيرة مع رمز: يعالج هذا الطلب المحدد ويقتل الحاوية.
طلب واحد - حاوية مرفوعة واحدة ، 1000 طلب - 1000 حاوية. والنشر على خوادم الحديد هو بالفعل عمل مقدم خدمة السحابة. إنه مخفي تمامًا بواسطة إطار عمل بدون خادم. في هذا المفهوم ، ندفع مقابل كل مكالمة. على سبيل المثال ، جاءت مكالمة واحدة في اليوم - دفعنا لمكالمة واحدة ، وصل مليون في الدقيقة - دفعنا مقابل مليون. أو في ثانية ، يحدث هذا أيضًا.
يعد مفهوم نشر وظيفة بدون خادم مناسبًا لخدمة عديمة الحالة. وإذا كنت بحاجة إلى خدمة (state) كاملة الحالة ، فقم بإضافة قاعدة بيانات إلى الخدمة. في هذه الحالة ، عندما يتعلق الأمر بالعمل مع state ، with state ، فإن كل دالة statefull تكتب وتقرأ من قاعدة البيانات. علاوة على ذلك ، من قاعدة بيانات لأي من الأنواع الثلاثة الموضحة في بداية المقال.
ما هو القيد المشترك لكل هذه القواعد؟ هذه هي تكاليف خدمة سحابية أو حديدية مستخدمة باستمرار (أو خوادم متعددة). لا يهم ما إذا كنا نستخدم قاعدة بيانات كلاسيكية أو نُدار ، سواء كان لدينا Devops ومسؤول أم لا ، ما زلنا ندفع على مدار الساعة طوال أيام الأسبوع مقابل إيجار الأجهزة والكهرباء ومركز البيانات. إذا كانت لدينا قاعدة كلاسيكية ، فإننا ندفع ثمن السيد والعبد. إذا كانت قاعدة مُقسمة محملة للغاية - فإننا ندفع مقابل 10 أو 20 أو 30 خادمًا ، وندفع باستمرار.
كان يُنظر سابقًا إلى وجود خوادم محجوزة بشكل دائم في هيكل التكلفة على أنه شر لا بد منه. تواجه قواعد البيانات العادية أيضًا صعوبات أخرى ، مثل القيود المفروضة على عدد الاتصالات وحدود القياس والإجماع الموزع جغرافيًا - يمكن حلها بطريقة ما في قواعد بيانات معينة ، ولكن ليس كلها مرة واحدة وليست مثالية.
قاعدة بيانات بدون خادم - نظرية
سؤال 2020: هل يمكن جعل قاعدة البيانات بلا خادم أيضًا؟ لقد سمع الجميع عن الواجهة الخلفية بدون خادم ... ولكن دعنا نحاول جعل قاعدة البيانات بلا خادم أيضًا؟
يبدو هذا غريبًا لأن قاعدة البيانات هي خدمة كاملة الحالة ، وليست مناسبة جدًا لبنية تحتية بدون خادم. في الوقت نفسه ، فإن حالة قاعدة البيانات كبيرة جدًا: غيغا بايت ، وتيرابايت ، وحتى بيتابايت في قواعد البيانات التحليلية. ليس من السهل رفعها في حاويات Docker خفيفة الوزن.
من ناحية أخرى ، فإن جميع قواعد البيانات الحديثة تقريبًا عبارة عن قدر هائل من المنطق والمكونات: المعاملات ، ومفاوضات النزاهة ، والإجراءات ، والتبعيات العلائقية ، والكثير من المنطق. الكثير من منطق قاعدة البيانات هو حالة صغيرة إلى حد ما. يتم استخدام الجيجابايت والتيرابايت مباشرة بواسطة جزء صغير فقط من منطق قاعدة البيانات المرتبط بتنفيذ الاستعلامات مباشرة.
وفقًا لذلك ، الفكرة: إذا كان جزء من المنطق يسمح بالإعدام بدون حالة ، فلماذا لا يتم تقطيع القاعدة إلى أجزاء ذات حالة وعديمة الجنسية.
بدون خادم لحلول OLAP
دعونا نرى كيف يمكن أن تبدو قاعدة البيانات المقطوعة إلى أجزاء ذات حالة وعديمة الحالة مع أمثلة عملية.
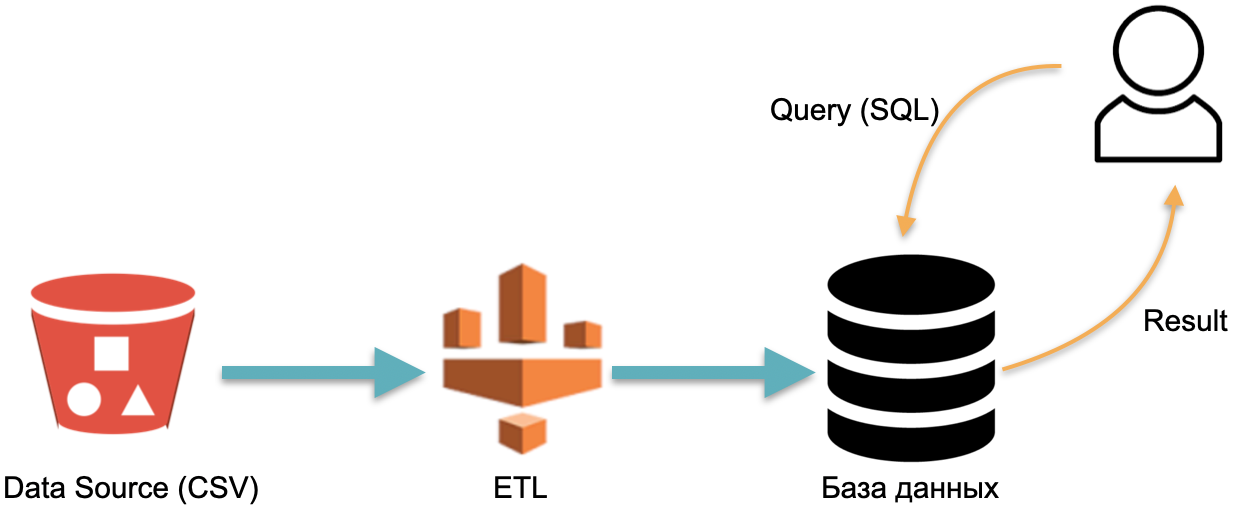
على سبيل المثال ، لدينا قاعدة بيانات تحليلية : بيانات خارجية (أسطوانة حمراء على اليسار) ، وعملية ETL تقوم بتحميل البيانات في قاعدة البيانات ، ومحلل يرسل استعلامات SQL إلى قاعدة البيانات. هذه هي الطريقة الكلاسيكية التي يعمل بها مستودع البيانات.
في هذا المخطط ، وفقًا للاتفاقية ، يتم تنفيذ ETL مرة واحدة. ثم عليك أن تدفع كل الوقت للخوادم التي تشغل قاعدة البيانات ببيانات مغمورة بـ ETL ، بحيث يكون لديك شيء لرمي الطلبات.
فكر في نهج بديل مطبق في AWS Athena Serverless. لا توجد أجهزة مخصصة بشكل دائم يتم تخزين البيانات التي تم تنزيلها عليها. بدلا من هذا:
- SQL- Athena. Athena SQL- (Metadata) , .
- , , ( ).
- SQL- , .
- , .
في هذه البنية ، ندفع فقط مقابل عملية تنفيذ الطلب. لا توجد طلبات - لا توجد تكاليف.
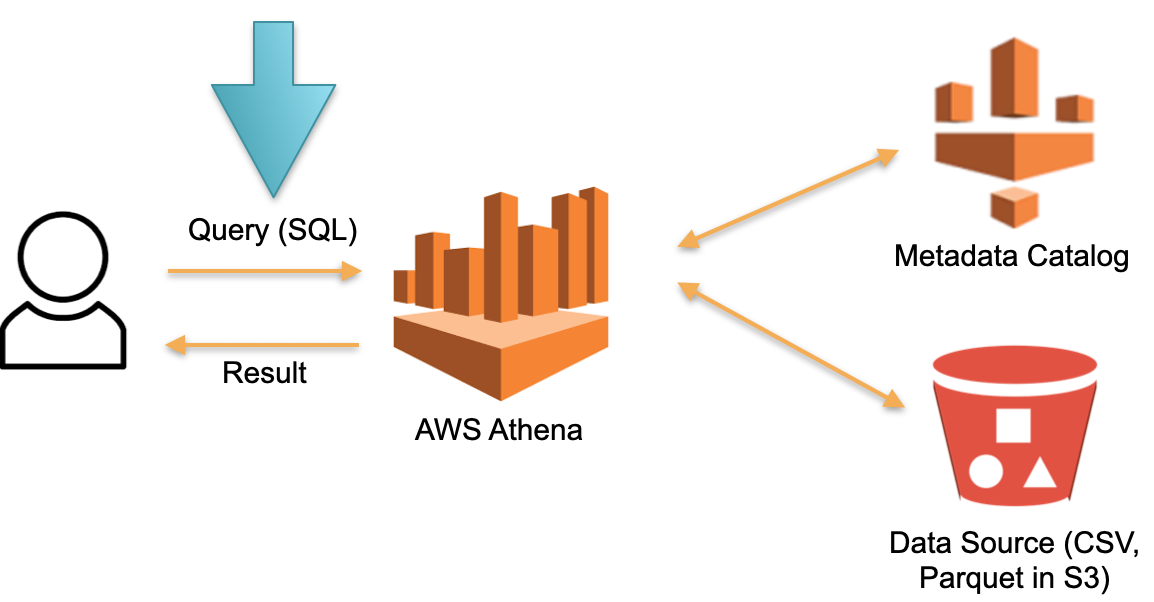
هذا نهج عملي ويتم تنفيذه ليس فقط في Athena Serverless ، ولكن أيضًا في Redshift Spectrum (على AWS).
يوضح مثال أثينا أن قاعدة البيانات Serverless تعمل على استعلامات حقيقية مع عشرات ومئات من تيرابايت من البيانات. سوف تتطلب مئات من التيرابايت المئات من الخوادم ، لكننا لسنا مضطرين لدفع ثمنها - نحن ندفع مقابل الطلبات. سرعة كل طلب بطيئة (جدًا) مقارنة بقواعد بيانات التحليلات المتخصصة مثل Vertica ، لكننا لا ندفع مقابل وقت التوقف عن العمل.
قاعدة البيانات هذه مفيدة للاستفسارات التحليلية المخصصة النادرة. على سبيل المثال ، عندما نقرر تلقائيًا اختبار فرضية على كمية هائلة من البيانات. أثينا مثالية لهذه الحالات. للاستفسارات المنتظمة ، مثل هذا النظام مكلف. في هذه الحالة ، قم بتخزين البيانات مؤقتًا في بعض الحلول المتخصصة.
بدون خادم لحلول OLTP
في المثال السابق ، تم اعتبار مهام OLAP (التحليلية). الآن دعونا نلقي نظرة على مهام OLTP.
تخيل إمكانية تطوير PostgreSQL أو MySQL. دعنا نطرح مثيلاً مُدارًا بشكل منتظم PostgreSQL أو MySQL على الحد الأدنى من الموارد. عندما يصل المزيد من الحمل إلى المثيل ، سنقوم بتوصيل النسخ المتماثلة الإضافية التي سنقوم بتوزيع جزء من حمل القراءة عليها. إذا لم تكن هناك طلبات ولا تحميل ، فسنوقف تشغيل النسخ المتماثلة. المثال الأول هو الرئيسي ، والباقي نسخ متماثلة.
يتم تنفيذ هذه الفكرة في قاعدة بيانات تسمى Aurora Serverless AWS. المبدأ بسيط: يتم قبول الطلبات الواردة من التطبيقات الخارجية بواسطة أسطول الوكيل. عند رؤية زيادة في الحمل ، فإنه يخصص موارد الحوسبة من الحد الأدنى من المثيلات المحسّنة مسبقًا - يكون الاتصال بأسرع ما يمكن. فصل الحالات هو نفسه.
داخل Aurora ، هناك مفهوم وحدة سعة Aurora ، ACU. هذا (شرطيًا) مثيل (خادم). يمكن أن تكون كل وحدة ACU محددة رئيسية أو تابعة. كل وحدة سعة لها ذاكرة الوصول العشوائي الخاصة بها والمعالج والحد الأدنى من القرص. وفقا لذلك ، سيد واحد ، يتم قراءة الباقي فقط النسخ المتماثلة.
عدد وحدات سعة Aurora قيد التشغيل قابل للتكوين. يمكن أن يكون الحد الأدنى للكمية واحدًا أو صفرًا (في هذه الحالة ، لا تعمل القاعدة في حالة عدم وجود طلبات).

عندما تتلقى القاعدة طلبات ، يقوم أسطول الوكيل برفع وحدات قدرة Aurora ، مما يزيد من الموارد الإنتاجية للنظام. تتيح القدرة على زيادة الموارد وتقليلها للنظام "التوفيق بين" الموارد: عرض تلقائيًا وحدات ACU فردية (استبدالها بأخرى جديدة) وإطلاق جميع التحديثات ذات الصلة بالموارد التي تمت إزالتها.
يمكن لقاعدة Aurora Serverless قياس حمل القراءة. لكن الوثائق لا تقول ذلك بشكل مباشر. قد يبدو الأمر وكأنهم قادرون على اكتساب ماجستير متعدد. لا يوجد سحر.
هذه القاعدة مناسبة تمامًا لعدم إنفاق الكثير من الأموال على أنظمة ذات وصول غير متوقع. على سبيل المثال ، عند إنشاء مواقع MVP أو مواقع تسويق بطاقات العمل ، لا نتوقع عادةً حملاً ثابتًا. وفقًا لذلك ، في حالة عدم الوصول ، لا ندفع مقابل الحالات. عندما ينشأ حمل بشكل غير متوقع ، على سبيل المثال ، بعد مؤتمر أو حملة إعلانية ، تزور حشود من الناس الموقع ويزداد الحمل بشكل كبير ، يتولى Aurora Serverless تلقائيًا هذا الحمل ويربط بسرعة الموارد المفقودة (ACU). ثم يستمر المؤتمر ، وينسى الجميع النموذج الأولي ، والخوادم (ACU) تنفد ، وتنخفض التكاليف إلى الصفر - إنه أمر مريح.
هذا الحل غير مناسب للأحمال العالية المستقرة لأنه لا يمكنه قياس حمل الكتابة. تحدث كل هذه الاتصالات وانفصال الموارد في لحظة ما يسمى بـ "نقطة القياس" - في الوقت الذي لا يتم فيه الاحتفاظ بقاعدة البيانات بواسطة المعاملة ، لا يتم الاحتفاظ بالجداول المؤقتة. على سبيل المثال ، خلال أسبوع ، قد لا تحدث نقطة القياس ، وتعمل القاعدة على نفس الموارد ولا يمكنها ببساطة التوسع أو التقلص.
لا يوجد سحر - هذا هو PostgreSQL العادي. لكن عملية إضافة السيارات وفصلها آلية جزئيًا.
Serverless حسب التصميم
Aurora Serverless هي قاعدة قديمة أعيد كتابتها للسحابة للاستفادة من المزايا الفردية لـ Serverless. والآن سأخبرك عن القاعدة ، التي تمت كتابتها في الأصل للسحابة ، للنهج بدون خادم - تصميم بدون خادم. تم تطويره على الفور دون افتراض أنه يعمل على خوادم فعلية.
هذه القاعدة تسمى ندفة الثلج. لديها ثلاث كتل رئيسية.
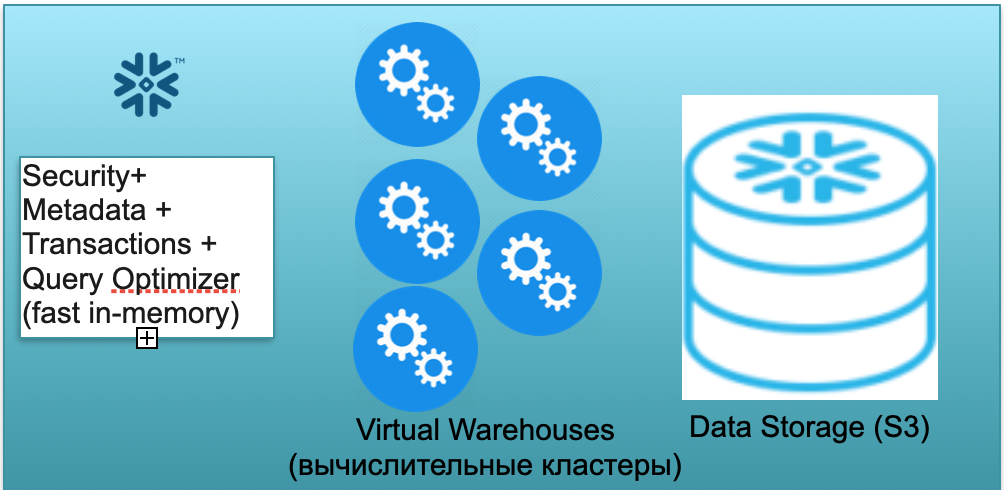
الأول هو كتلة من البيانات الوصفية. إنها خدمة سريعة في الذاكرة تعمل على حل المشكلات المتعلقة بالأمان والبيانات الوصفية والمعاملات وتحسين الاستعلام (في الرسم التوضيحي الموجود على اليسار).
الكتلة الثانية عبارة عن مجموعة من المجموعات الحسابية الافتراضية للحسابات (في الرسم التوضيحي - مجموعة من الدوائر الزرقاء).
الكتلة الثالثة هي نظام تخزين قائم على S3. S3 عبارة عن تخزين كائنات بدون أبعاد من AWS ، يشبه Dropbox عديم الأبعاد للأعمال.
دعونا نلقي نظرة على كيفية عمل Snowflake في ظل افتراض البداية الباردة. أي أن قاعدة البيانات موجودة ، ويتم تحميل البيانات فيها ، ولا توجد استفسارات عملية. وفقًا لذلك ، إذا لم تكن هناك استفسارات لقاعدة البيانات ، فسنكون قد رفعنا خدمة بيانات وصفية سريعة في الذاكرة (الكتلة الأولى). ولدينا تخزين S3 ، حيث يتم تخزين بيانات الجدول ، مقسمة إلى ما يسمى بأقسام صغيرة. من أجل التبسيط: إذا كان الجدول يحتوي على صفقات ، فإن العقود الصغيرة هي أيام الصفقات. كل يوم عبارة عن دفعة صغيرة منفصلة ، ملف منفصل. وعندما تعمل قاعدة البيانات في هذا الوضع ، فإنك تدفع فقط مقابل المساحة التي تشغلها البيانات. علاوة على ذلك ، فإن معدل كل مقعد منخفض للغاية (خاصة بالنظر إلى الضغط الكبير). تعمل خدمة البيانات الوصفية أيضًا بشكل مستمر ، ولكنها لا تحتاج إلى الكثير من الموارد لتحسين الاستعلامات ، ويمكن اعتبار الخدمة برامج تجريبية.
الآن دعنا نتخيل أن مستخدمًا جاء إلى قاعدة بياناتنا وألقى استعلام SQL. يتم إرسال استعلام SQL على الفور إلى خدمة البيانات الوصفية للمعالجة. وفقًا لذلك ، عند تلقي طلب ، تقوم هذه الخدمة بتحليل الطلب ، والبيانات المتاحة ، وسلطة المستخدم ، وإذا كان كل شيء على ما يرام ، فإنها تضع خطة معالجة الطلب.
بعد ذلك ، تبدأ الخدمة في إطلاق الكتلة الحسابية. الكتلة الحسابية هي مجموعة من الخوادم التي تقوم بعمليات حسابية. وهذا يعني أن هذه مجموعة يمكن أن تحتوي على خادم واحد وخادمين و 4 و 8 و 16 و 32 - بقدر ما تريد. أنت تطرح طلبًا ويبدأ إطلاق هذه المجموعة على الفور تحته. انها حقا تستغرق ثواني.
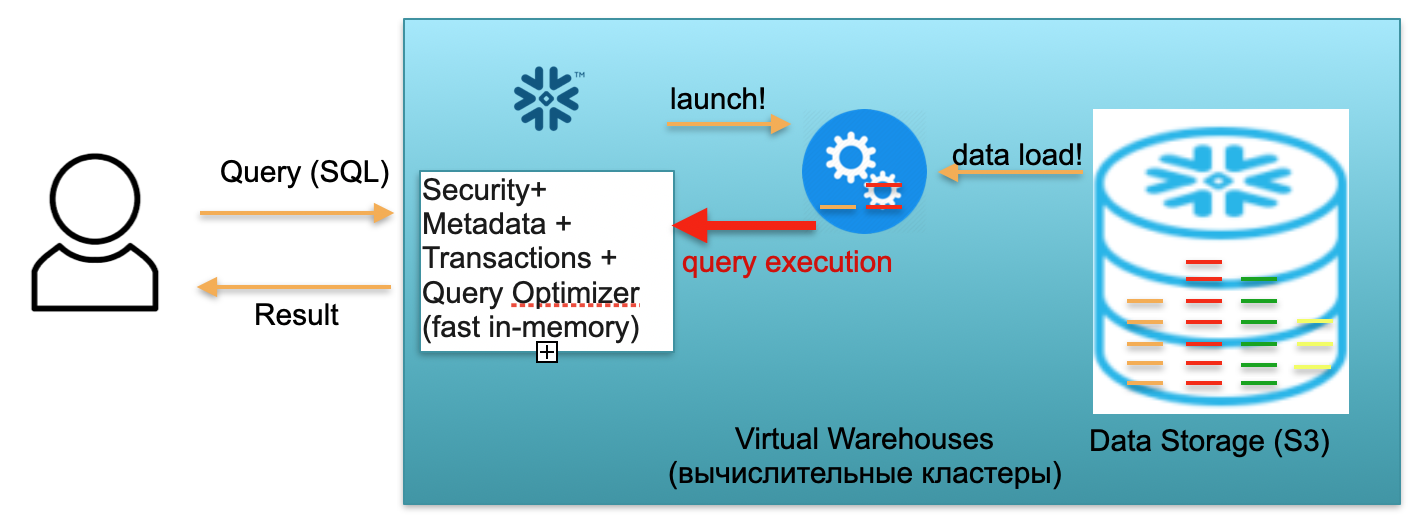
علاوة على ذلك ، بعد بدء الكتلة ، يتم نسخ الأجزاء الدقيقة إلى الكتلة من S3 ، والتي تكون ضرورية لمعالجة طلبك. أي ، تخيل أنه لتنفيذ استعلام SQL ، فإنك تحتاج إلى قسمين من جدول وآخر من الثاني. في هذه الحالة ، سيتم نسخ الأقسام الثلاثة الضرورية فقط إلى المجموعة ، ولن يتم نسخ جميع الجداول ككل. هذا هو السبب وبالتحديد لأن كل شيء يقع في إطار مركز بيانات واحد ومتصل بقنوات سريعة جدًا ، تتم عملية الضخ بأكملها بسرعة كبيرة: في ثوانٍ ، نادرًا جدًا - في دقائق ، إذا لم نتحدث عن بعض الطلبات الوحشية ... وفقًا لذلك ، يتم نسخ الأجزاء الدقيقة إلى مجموعة حسابية ، وعند الانتهاء ، يتم تنفيذ استعلام SQL على هذه المجموعة الحسابية. يمكن أن تكون نتيجة هذا الاستعلام سطرًا واحدًا أو عدة أسطر أو جدول - يتم إرسالها إلى المستخدم ،بحيث يمكن تنزيله أو عرضه في أداة BI الخاصة به أو استخدامه بطريقة أخرى.
لا يمكن لكل استعلام SQL قراءة التجميعات من البيانات التي تم تحميلها مسبقًا فحسب ، بل يمكنه أيضًا تحميل / تشكيل بيانات جديدة في قاعدة البيانات. أي أنه يمكن أن يكون استعلامًا ، على سبيل المثال ، يُدرج سجلات جديدة في جدول آخر ، مما يؤدي إلى ظهور قسم جديد في المجموعة الحسابية ، والذي بدوره يتم تخزينه تلقائيًا في وحدة تخزين S3 واحدة.
السيناريو الموصوف أعلاه ، من وصول المستخدم إلى رفع الكتلة ، وتحميل البيانات ، وتنفيذ الاستعلامات ، والحصول على النتائج ، يتم دفعه بمعدل كل دقيقة من استخدام مجموعة الحوسبة الافتراضية المرتفعة ، المستودع الافتراضي. يختلف المعدل حسب منطقة AWS وحجم المجموعة ، ولكن في المتوسط يكون بضعة دولارات في الساعة. مجموعة من أربع سيارات هي ضعف تكلفة مجموعة من سيارتين ، وثماني سيارات هي ضعف تكلفة مجموعة من سيارتين. الخيارات المتاحة من 16 ، 32 سيارة ، حسب مدى تعقيد الطلبات. لكنك تدفع فقط مقابل الدقائق التي تعمل فيها المجموعة فعليًا ، لأنه عندما لا تكون هناك طلبات ، فأنت ترفع يديك نوعًا ما ، وبعد 5-10 دقائق من الانتظار (معلمة قابلة للتكوين) ستنطلق من تلقاء نفسها وتحرر الموارد وتصبح مجانية.
السيناريو حقيقي تمامًا ، عندما تطرح طلبًا ، تنبثق الكتلة ، نسبيًا ، في غضون دقيقة ، يتم احتساب دقيقة أخرى ، ثم خمس دقائق للإغلاق ، وينتهي بك الأمر بالدفع مقابل سبع دقائق من تشغيل هذه المجموعة ، وليس لشهور وسنوات.
وصف السيناريو الأول استخدام Snowflake في سيناريو مستخدم واحد. الآن دعنا نتخيل أن هناك العديد من المستخدمين ، وهو أقرب إلى سيناريو حقيقي.
لنفترض أن لدينا الكثير من المحللين وتقارير Tableau الذين يقصفون قاعدة بياناتنا باستمرار بالكثير من استعلامات SQL التحليلية البسيطة.
بالإضافة إلى ذلك ، دعنا نقول أن لدينا علماء بيانات بارعين يحاولون القيام بأشياء مروعة بالبيانات ، ويعملون على عشرات تيرابايت ، ويحللون مليارات وتريليونات من صفوف البيانات.
بالنسبة لنوعي الحمل الموصوفين أعلاه ، يسمح لك Snowflake برفع عدة مجموعات حسابية مستقلة ذات سعات مختلفة. علاوة على ذلك ، تعمل هذه المجموعات الحسابية بشكل مستقل ، ولكن مع بيانات متسقة مشتركة.
لعدد كبير من الاستفسارات الخفيفة ، يمكنك جمع 2-3 مجموعات صغيرة ، تقليديا في الحجم ، 2 آلة لكل منهما. يمكن تحقيق هذا السلوك ، من بين أمور أخرى ، باستخدام الإعدادات التلقائية. هذا هو ، كما تقول ، "ندفة الثلج ، ارفع كتلة صغيرة. إذا نما الحمل عليه أكثر من معلمة معينة ، فقم برفع نفس الثانية والثالثة. عندما يبدأ الحمل في التراجع - أطفئ الحمولات الزائدة ". وبغض النظر عن عدد المحللين الذين يأتون ويبدأون في الاطلاع على التقارير ، فإن كل شخص لديه موارد كافية.
في الوقت نفسه ، إذا كان المحللون نائمين ولا أحد ينظر إلى التقارير ، يمكن أن تخرج المجموعات تمامًا ، وتتوقف عن الدفع مقابلها.
في الوقت نفسه ، للاستعلامات الكثيفة (من علماء البيانات) ، يمكنك إنشاء مجموعة كبيرة جدًا لكل 32 جهازًا شرطيًا. ستتم محاسبة هذه المجموعة أيضًا فقط للدقائق والساعات التي يتم فيها تشغيل طلبك العملاق هناك.
تسمح الميزة الموضحة أعلاه بالتقسيم إلى مجموعات ليس فقط 2 ، ولكن أيضًا المزيد من أنواع الحمل (ETL ، المراقبة ، تجسيد التقارير ، ...).
دعونا نلخص ندفة الثلج. تجمع القاعدة بين فكرة جميلة وتنفيذ عملي. في ManyChat ، نستخدم Snowflake لتحليل جميع البيانات التي لدينا. ليس لدينا ثلاث مجموعات ، كما في المثال ، ولكن من 5 إلى 9 ، بأحجام مختلفة. لدينا 16 آلة مشروطة ، 2 آلة ، وهناك أيضًا آلة واحدة صغيرة جدًا لبعض المهام. لقد قاموا بتوزيع الحمل بنجاح ويسمحون لنا بتوفير الكثير.
تقوم القاعدة بقياس عبء عمل القراءة والكتابة بنجاح. هذا فرق كبير واختراق كبير بالمقارنة مع نفس "Aurora" ، التي سحبت عبء القراءة فقط. يسمح Snowflake لهذه المجموعات الحسابية بتوسيع نطاق أعباء العمل وكتابتها. هذا ، كما ذكرت ، نستخدم العديد من المجموعات في ManyChat ، تستخدم المجموعات الصغيرة والصغيرة جدًا بشكل أساسي لـ ETL ، لتحميل البيانات. ويعيش المحللون بالفعل في مجموعات متوسطة الحجم لا تتأثر مطلقًا بحمل ETL ، لذا فهم يعملون بسرعة كبيرة.
وفقًا لذلك ، القاعدة مناسبة تمامًا لمهام OLAP. في الوقت نفسه ، للأسف ، لا يمكن تطبيقه بعد على أعباء عمل OLTP. أولاً ، هذه القاعدة عمودية ، مع كل العواقب المترتبة على ذلك. ثانيًا ، النهج نفسه ، عند كل طلب ، إذا لزم الأمر ، تقوم بجمع مجموعة حسابية وتسكبها بالبيانات ، لسوء الحظ ، بالنسبة لأحمال عمل OLTP ، فإنها لا تزال غير سريعة بما يكفي. يعد انتظار ثوانٍ لمهام OLAP أمرًا طبيعيًا ، ولكن بالنسبة لمهام OLTP ، فهو غير مقبول ، وسيكون 100 مللي ثانية أفضل ، بل وأفضل - 10 مللي ثانية.
النتيجة
قاعدة البيانات بدون خادم ممكنة عن طريق فصل قاعدة البيانات إلى أجزاء عديمة الحالة وذات حالة. يجب أن تكون قد لاحظت أنه في جميع الأمثلة المقدمة ، الجزء ذو الحالة هو ، نسبيًا ، تخزين الأجزاء الدقيقة في S3 ، و Stateless هو مُحسِّن ، يعمل مع البيانات الوصفية ، ويتعامل مع مشكلات الأمان التي يمكن طرحها على أنها خفيفة الوزن مستقلة خدمات عديمي الجنسية.
يمكن أيضًا اعتبار تنفيذ استعلامات SQL بمثابة خدمات الحالة الخفيفة التي يمكن أن تظهر في وضع بدون خادم ، مثل مجموعات حساب Snowflake ، وتنزيل البيانات التي تحتاجها فقط ، وتنفيذ الاستعلام ، و "الخروج".
قواعد البيانات على مستوى الإنتاج بدون خادم متاحة بالفعل للاستخدام ، فهي تعمل. قواعد البيانات بدون خادم جاهزة بالفعل للتعامل مع مهام OLAP. لسوء الحظ ، يتم استخدامها لمهام OLTP ... مع الفروق الدقيقة ، نظرًا لوجود قيود. من ناحية ، هذا ناقص. لكن من ناحية أخرى ، هذه فرصة. ربما سيجد بعض القراء طريقة لجعل قاعدة OLTP بلا خوادم تمامًا ، دون قيود Aurora.
آمل أن تكون قد وجدت ذلك ممتعًا. Serverless هو المستقبل :)