سأخبرك في هذه المقالة عن وظائف BigQuery الرئيسية وأعرض إمكانياتها مع أمثلة محددة. يمكنك كتابة استفسارات أساسية وتجربتها على البيانات التجريبية.
ما هي لغة الاستعلامات البنيوية ولغاتها
SQL (لغة الاستعلام الهيكلية) هي لغة استعلام منظمة للعمل مع قواعد البيانات. بفضل مساعدتها ، يمكنك تلقي كميات كبيرة من البيانات وإضافتها إلى قاعدة البيانات وتعديلها. يدعم Google BigQuery لهجتين: معيار SQL و SQL القديم.
تعتمد اللهجة التي تختارها على تفضيلاتك ، لكن Google توصي باستخدام معيار SQL نظرًا لعدد من المزايا:
- المرونة والوظائف عند العمل مع الحقول المتداخلة والمتكررة.
- دعم لغات DML و DDL ، والتي تسمح لك بتغيير البيانات في الجداول ، وكذلك التعامل مع الجداول وطرق العرض في GBQ.
- تعتبر معالجة كميات كبيرة من البيانات أسرع من Legasy SQL.
- دعم لجميع تحديثات BigQuery الحالية والمستقبلية.
يمكنك معرفة المزيد عن الاختلاف بين اللهجات في المساعدة .
بشكل افتراضي ، تعمل طلبات بحث Google BigQuery مقابل Legacy SQL.
هناك عدة طرق للتبديل إلى معيار SQL:
- في واجهة BigQuery ، في نافذة تعديل الاستعلام ، حدد "إظهار الخيارات" وألغ تحديد المربع بجوار الخيار "استخدام لغة SQL القديمة"

- أضف السطر #standardSQL قبل الاستعلام وابدأ الاستعلام في سطر جديد

من أين نبدأ
حتى تتمكن من ممارسة تشغيل الاستعلامات بالتوازي مع قراءة المقالة ، فقد أعددت جدولًا يحتوي على بيانات توضيحية لك . قم بتحميل البيانات من جدول البيانات إلى مشروع Google BigQuery.
إذا لم يكن لديك بالفعل مشروع GBQ ، فقم بإنشاء واحد. للقيام بذلك ، تحتاج إلى حساب فوترة نشط في Google Cloud Platform . ستحتاج إلى ربط البطاقة ، ولكن بدون علمك لن يتم خصم أموالك منها ، إلى جانب ذلك ، عند التسجيل ، ستتلقى 300 دولار لمدة 12 شهرًا ، يمكنك إنفاقها على تخزين البيانات ومعالجتها.
ميزات Google BigQuery
أكثر مجموعات الوظائف شيوعًا عند إنشاء الاستعلامات هي وظيفة التجميع ووظيفة التاريخ ووظيفة السلسلة ووظيفة النافذة. الآن المزيد عن كل منهم.
وظيفة التجميع
تسمح لك وظائف التجميع بالحصول على قيم موجزة عبر الجدول بأكمله. على سبيل المثال ، احسب متوسط الشيك أو إجمالي الدخل الشهري أو قم بتمييز شريحة المستخدمين الذين أجروا أقصى عدد من عمليات الشراء.
فيما يلي الميزات الأكثر شيوعًا من هذا القسم:
| لغة SQL القديمة | معيار SQL | ماذا تفعل الوظيفة |
|---|---|---|
| AVG (حقل) | AVG ([DISTINCT] (حقل)) | إرجاع متوسط عمود الحقل. في SQL القياسي ، عند إضافة جملة DISTINCT ، يتم حساب المتوسط فقط للصفوف ذات القيم الفريدة (غير المكررة) من عمود الحقل |
| MAX (حقل) | MAX (حقل) | تُرجع القيمة القصوى من عمود الحقل |
| MIN (حقل) | MIN (حقل) | تُرجع الحد الأدنى للقيمة من عمود الحقل |
| SUM (حقل) | SUM (حقل) | تُرجع مجموع القيم من عمود الحقل |
| COUNT (حقل) | COUNT (حقل) | ترجع عدد الصفوف في حقل العمود |
| EXACT_COUNT_DISTINCT (حقل) | COUNT ([DISTINCT] (حقل)) | تُرجع هذه الدالة عدد الصفوف الفريدة في عمود الحقل |
يمكنك العثور على قائمة بجميع الوظائف في التعليمات: Legacy SQL و Standard SQL .
دعونا نرى كيف تعمل الوظائف المدرجة مع مثال عرض بيانات. دعونا نحسب متوسط الدخل من المعاملات والمشتريات بأعلى وأقل مبلغ وإجمالي الدخل وعدد جميع المعاملات. للتحقق مما إذا كانت عمليات الشراء مكررة ، سنقوم أيضًا بحساب عدد المعاملات الفريدة. للقيام بذلك ، نكتب استعلامًا نشير فيه إلى اسم مشروع Google BigQuery ومجموعة البيانات والجدول.
#legasy SQL
SELECT
AVG(revenue) as average_revenue,
MAX(revenue) as max_revenue,
MIN(revenue) as min_revenue,
SUM(revenue) as whole_revenue,
COUNT(transactionId) as transactions,
EXACT_COUNT_DISTINCT(transactionId) as unique_transactions
FROM
[owox-analytics:t_kravchenko.Demo_data]# معيار SQL
SELECT
AVG(revenue) as average_revenue,
MAX(revenue) as max_revenue,
MIN(revenue) as min_revenue,
SUM(revenue) as whole_revenue,
COUNT(transactionId) as transactions,
COUNT(DISTINCT(transactionId)) as unique_transactions
FROM
`owox-analytics.t_kravchenko.Demo_data`نتيجة لذلك ، نحصل على النتائج التالية:
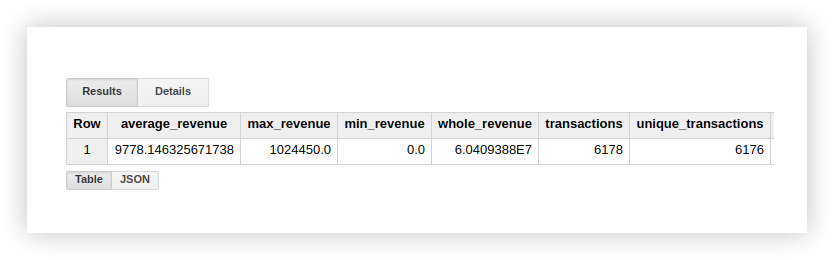
يمكنك التحقق من نتائج الحساب في الجدول الأصلي بالبيانات التجريبية باستخدام وظائف جداول بيانات Google القياسية (SUM و AVG وغيرها) أو الجداول المحورية.
كما ترى من لقطة الشاشة أعلاه ، يختلف عدد المعاملات والمعاملات الفريدة.
يشير هذا إلى وجود معاملتين في جدولنا مع معرّف معاملة مكرر:
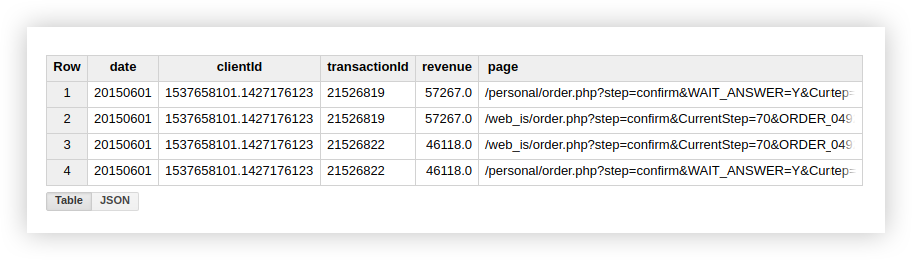
لذلك ، إذا كنت مهتمًا بمعاملات فريدة ، فاستخدم الوظيفة التي تحسب صفوفًا فريدة. بدلاً من ذلك ، يمكنك تجميع البيانات باستخدام عبارة GROUP BY للتخلص من التكرارات قبل استخدام وظيفة التجميع.
وظائف للعمل مع التواريخ (وظيفة التاريخ)
تتيح لك هذه الوظائف معالجة التواريخ: تغيير تنسيقها ، وتحديد الجزء المطلوب (اليوم أو الشهر أو السنة) ، وتحويل التاريخ بفاصل زمني معين.
يمكن أن تكون مفيدة لك في الحالات التالية:
- عند إعداد تحليلات شاملة - لجلب التواريخ والأوقات من مصادر مختلفة إلى تنسيق واحد.
- عند إنشاء تقارير محدثة تلقائيًا أو إرسال رسائل بريدية. على سبيل المثال ، عندما تحتاج إلى بيانات لآخر ساعتين أو أسبوع أو شهر.
- عند إنشاء تقارير جماعية ، من الضروري الحصول على بيانات في سياق الأيام والأسابيع والشهور.
أكثر وظائف التاريخ شيوعًا:
| لغة SQL القديمة | معيار SQL | ماذا تفعل الوظيفة |
|---|---|---|
| التاريخ الحالي () | التاريخ الحالي () | إرجاع التاريخ الحالي بالتنسيق٪ YYYY-٪ MM-٪ DD |
| DATE (الطابع الزمني) | DATE (الطابع الزمني) | تحويل تاريخ من التنسيق٪ YYYY-٪ MM-٪ DD٪ H:٪ M:٪ S. بالتنسيق٪ YYYY-٪ MM-٪ DD |
| DATE_ADD (الطابع الزمني ، الفاصل الزمني ، الفاصل_الوحدات) | DATE_ADD(timestamp, INTERVAL interval interval_units) | timestamp, interval.interval_units.
Legacy SQL YEAR, MONTH, DAY, HOUR, MINUTE SECOND, Standard SQL — YEAR, QUARTER, MONTH, WEEK, DAY |
| DATE_ADD(timestamp, — interval, interval_units) | DATE_SUB(timestamp, INTERVAL interval interval_units) | timestamp, interval |
| DATEDIFF(timestamp1, timestamp2) | DATE_DIFF(timestamp1, timestamp2, date_part) | timestamp1 timestamp2.
Legacy SQL , Standard SQL — date_part (, , , , ) |
| DAY(timestamp) | EXTRACT(DAY FROM timestamp) | timestamp. 1 31 |
| MONTH(timestamp) | EXTRACT(MONTH FROM timestamp) | timestamp. 1 12 |
| YEAR(timestamp) | EXTRACT(YEAR FROM timestamp) | timestamp |
للحصول على قائمة من كافة الميزات، راجع تراث SQL و ستاندرد SQL مساعدة .
لنلقِ نظرة على عرض توضيحي للبيانات ، وكيف تعمل كل وظيفة من الوظائف المذكورة أعلاه. على سبيل المثال ، نحصل على التاريخ الحالي ، ونحضر التاريخ من الجدول الأصلي إلى التنسيق٪ YYYY-٪ MM-٪ DD ، اطرح وأضف يومًا واحدًا إليه. ثم نحسب الفرق بين التاريخ الحالي والتاريخ من الجدول الأصلي ونقسم التاريخ الحالي بشكل منفصل إلى السنة والشهر واليوم. للقيام بذلك ، يمكنك نسخ نماذج الاستعلامات أدناه واستبدال اسم المشروع ومجموعة البيانات وجدول البيانات باسمك.
#legasy SQL
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day,
DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day,
DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date,
DAY( CURRENT_DATE() ) AS the_day,
MONTH( CURRENT_DATE()) AS the_month,
YEAR( CURRENT_DATE()) AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data]
# معيار SQL
SELECT
today,
date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day,
DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day,
DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date,
EXTRACT(DAY FROM today ) AS the_day,
EXTRACT(MONTH FROM today ) AS the_month,
EXTRACT(YEAR FROM today ) AS the_year
FROM (
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD
FROM
`owox-analytics.t_kravchenko.Demo_data`)
بعد تقديم الطلب سيصلك التقرير التالي:
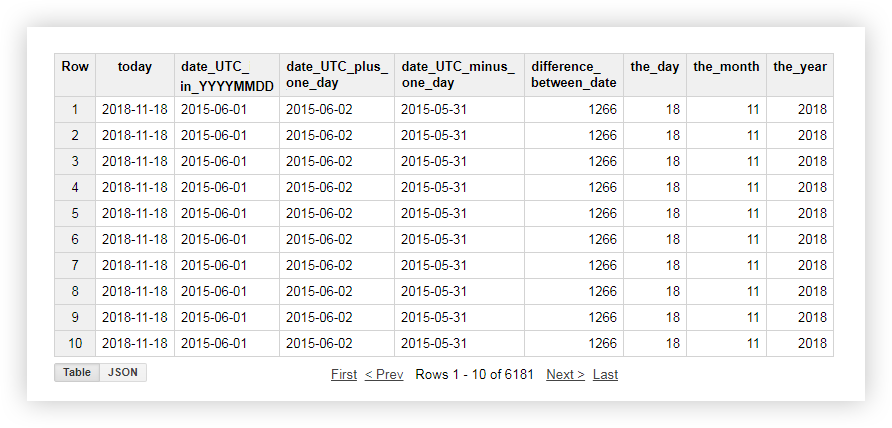
وظائف للعمل مع الأوتار (String function)
تتيح لك وظائف السلسلة تكوين سلسلة وتحديد واستبدال السلاسل الفرعية وحساب طول السلسلة والفهرس الترتيبي للسلسلة الفرعية في السلسلة الأصلية.
على سبيل المثال ، بمساعدتهم يمكنك:
- قم بعمل عوامل التصفية في التقرير بواسطة علامات UTM التي تم تمريرها إلى عنوان URL للصفحة.
- أحضر البيانات إلى تنسيق موحد إذا كانت أسماء المصادر والحملات مكتوبة في سجلات مختلفة.
- استبدل البيانات غير الصحيحة في التقرير ، على سبيل المثال ، إذا تم إرسال اسم الحملة بخطأ إملائي.
الوظائف الأكثر شيوعًا للعمل مع السلاسل:
| لغة SQL القديمة | معيار SQL | ماذا تفعل الوظيفة |
|---|---|---|
| CONCAT ('str1' ، 'str2') أو 'str1' + 'str2' | CONCAT ('str1'، 'str2') | يربط بين سلاسل متعددة "str1" و "str2" في سلسلة واحدة |
| "str1" يحتوي على "str2" | REGEXP_CONTAINS('str1', 'str2') 'str1' LIKE ‘%str2%’ | true 'str1' ‘str2’.
Standard SQL ‘str2’ re2 |
| LENGTH('str' ) | CHAR_LENGTH('str' )
CHARACTER_LENGTH('str' ) |
'str' ( ) |
| SUBSTR('str', index [, max_len]) | SUBSTR('str', index [, max_len]) | max_len, index 'str' |
| LOWER('str') | LOWER('str') | 'str' |
| UPPER(str) | UPPER(str) | 'str' |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | لعرض فهرس التواجد الأول للسلسلة 'str2' في السلسلة 'str1' ، وإلا - 0 |
| استبدال ('str1'، 'str2'، 'str3') | استبدال ('str1'، 'str2'، 'str3') | يستبدل في السلسلة "str1" السلسلة الفرعية "str2" بسلسلة فرعية "str3" |
مزيد من التفاصيل في التعليمات: Legacy SQL و Standard SQL .
دعونا نحلل كيفية استخدام الوظائف الموصوفة باستخدام مثال البيانات التجريبية. لنفترض أن لدينا 3 أعمدة منفصلة تحتوي على قيم اليوم والشهر والسنة:
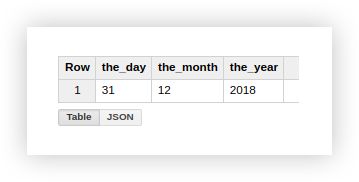
العمل مع تاريخ بهذا التنسيق ليس ملائمًا للغاية ، لذلك دعونا ندمجها في عمود واحد. للقيام بذلك ، استخدم استعلامات SQL أدناه ، ولا تنس تضمين اسم مشروعك ومجموعة البيانات وجدول Google BigQuery.
#legasy SQL
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1,
the_day+'-'+the_month+'-'+the_year AS mix_string2
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
mix_string1,
mix_string2
# معيار SQL
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
mix_string1
بعد تنفيذ الطلب ، سوف نتلقى التاريخ في عمود واحد:

غالبًا ، عند تحميل صفحة معينة على الموقع ، يحتوي عنوان URL على قيم المتغيرات التي حددها المستخدم. يمكن أن تكون هذه طريقة للدفع أو التسليم ، أو رقم معاملة ، أو فهرسًا لمتجر مادي حيث يريد العميل التقاط عنصر ، وما إلى ذلك. باستخدام استعلام SQL ، يمكنك استخراج هذه المعلمات من عنوان الصفحة.
دعنا نلقي نظرة على مثالين لكيفية ولماذا القيام بذلك.
مثال 1 . لنفترض أننا نريد معرفة عدد عمليات الشراء التي يلتقط فيها المستخدمون العناصر من المتاجر الفعلية. للقيام بذلك ، تحتاج إلى حساب عدد المعاملات المرسلة من الصفحات التي يحتوي عنوان URL الخاص بها على السلسلة الفرعية shop_id (فهرس المتجر الفعلي). نقوم بذلك باستخدام الاستعلامات التالية:
#legasy SQL
SELECT
COUNT(transactionId) AS transactions,
check
FROM (
SELECT
transactionId,
page CONTAINS 'shop_id' AS check
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
check
# معيار SQL
SELECT
COUNT(transactionId) AS transactions,
check1,
check2
FROM (
SELECT
transactionId,
REGEXP_CONTAINS( page, 'shop_id') AS check1,
page LIKE '%shop_id%' AS check2
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
check1,
check2
من الجدول الناتج ، نرى أنه تم إرسال 5502 معاملة من الصفحات التي تحتوي على معرّف المتجر (تحقق = صحيح):
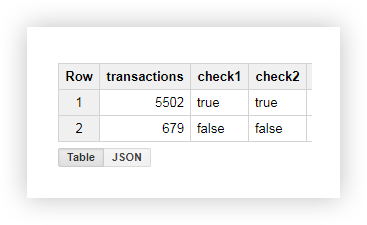
مثال 2 . لنفترض أنك قمت بتعيين delivery_id لكل طريقة تسليم واكتب قيمة هذه المعلمة في عنوان URL للصفحة. لمعرفة طريقة التسليم التي اختارها المستخدم ، حدد delivery_id في عمود منفصل.
نستخدم الاستعلامات التالية لهذا:
#legasy SQL
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
LENGTH(page_lower_case) AS page_length,
INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
[owox-analytics:t_kravchenko.Demo_data])))
ORDER BY
page_lower_case ASC
# معيار SQL
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
CHAR_LENGTH(page_lower_case) AS page_length,
STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
`owox-analytics.t_kravchenko.Demo_data`)))
ORDER BY
page_lower_case ASC
نتيجة لذلك ، حصلنا على الجدول التالي في Google BigQuery:

وظائف للعمل مع مجموعات فرعية من البيانات أو وظائف النافذة (وظيفة النافذة)
تشبه هذه الوظائف وظائف التجميع التي ناقشناها أعلاه. يتمثل الاختلاف الرئيسي بينهما في أن الحسابات لا يتم إجراؤها على مجموعة البيانات الكاملة المحددة باستخدام استعلام ، ولكن على جزء منها - مجموعة فرعية أو نافذة.
باستخدام وظائف النافذة ، يمكنك تجميع البيانات حسب المجموعات دون استخدام عامل التشغيل JOIN لدمج استعلامات متعددة. على سبيل المثال ، احسب متوسط الدخل عن طريق الحملات الإعلانية ، وعدد المعاملات حسب الجهاز. من خلال إضافة حقل آخر إلى التقرير ، يمكنك بسهولة معرفة ، على سبيل المثال ، حصة الإيرادات من حملة إعلانية في يوم الجمعة الأسود أو حصة المعاملات التي تمت من تطبيق الهاتف المحمول.
جنبًا إلى جنب مع كل وظيفة ، يجب كتابة تعبير OVER في الطلب ، والذي يحدد حدود النافذة. يحتوي OVER على 3 مكونات يمكنك العمل معها:
- PARTITION BY - يُعرّف السمة التي ستقسّم بيانات المصدر بواسطتها إلى مجموعات فرعية ، على سبيل المثال PARTITION BY clientId، DayTime.
- ORDER BY - يحدد ترتيب الصفوف في المجموعة الفرعية ، على سبيل المثال ORDER BY hour DESC.
- WINDOW FRAME - يسمح لك بمعالجة الصفوف داخل مجموعة فرعية وفقًا لخاصية محددة. على سبيل المثال ، يمكنك حساب مجموع ليس كل الأسطر في النافذة ، ولكن فقط الخمسة الأولى قبل السطر الحالي.
يلخص هذا الجدول وظائف النوافذ الأكثر استخدامًا:
| لغة SQL القديمة | معيار SQL | ماذا تفعل الوظيفة |
|---|---|---|
| AVG (حقل)
COUNT (حقل) COUNT (حقل DISTINCT) MAX () MIN () SUM () |
AVG ([DISTINCT] (حقل))
COUNT (حقل) COUNT ([DISTINCT] (حقل)) MAX (حقل) MIN (حقل) SUM (حقل) |
, , , field .
DISTINCT , () |
| 'str1' CONTAINS 'str2' | REGEXP_CONTAINS('str1', 'str2') 'str1' LIKE ‘%str2%’ | true 'str1' ‘str2’.
Standard SQL ‘str2’ re2 |
| DENSE_RANK() | DENSE_RANK() | |
| FIRST_VALUE(field) | FIRST_VALUE (field[{RESPECT | IGNORE} NULLS]) | field .
field . RESPECT IGNORE NULLS , NULL |
| LAST_VALUE(field) | LAST_VALUE (field [{RESPECT | IGNORE} NULLS]) | field .
field . RESPECT IGNORE NULLS , NULL |
| LAG(field) | LAG (field[, offset [, default_expression]]) | field .
Offset , . . Default_expression — , , |
| LEAD(field) | LEAD (field[, offset [, default_expression]]) | field .
Offset , . . Default_expression — , , |
يمكنك الاطلاع على قائمة بجميع الوظائف في التعليمات لـ Legacy SQL و Standard SQL: الوظائف التحليلية المجمعة ، وظائف التنقل .
مثال 1. لنفترض أننا نريد تحليل نشاط المشترين أثناء ساعات العمل وغير ساعات العمل. للقيام بذلك ، من الضروري تقسيم المعاملات إلى مجموعتين وحساب المقاييس التي نهتم بها:
- المجموعة 1 - المشتريات خلال ساعات العمل من 9:00 حتي 18:00.
- المجموعة 2 - المشتريات خارج ساعات العمل من 00:00 إلى 9:00 ومن 18:00 إلى 00:00.
بالإضافة إلى ساعات العمل وغير ساعات العمل ، هناك علامة أخرى لتكوين النافذة وهي معرف العميل ، أي أنه سيكون لدينا نافذتان لكل مستخدم:
| مجموعة فرعية (نافذة) | معرف العميل | النهار |
|---|---|---|
| 1 نافذة | معرف العميل 1 | وقت العمل |
| 2 نافذة | معرف العميل 2 | ساعات غير العمل |
| 3 نافذة | معرف العميل 3 | وقت العمل |
| 4 نافذة | معرف العميل 4 | ساعات غير العمل |
| نافذة N | معرف العميل N | وقت العمل |
| نافذة N + 1 | معرف العميل N + 1 | ساعات غير العمل |
دعونا نحسب متوسط الدخل ، والحد الأقصى ، والحد الأدنى ، والإجمالي ، وعدد المعاملات وعدد المعاملات الفريدة لكل مستخدم أثناء ساعات العمل وغير ساعات العمل على البيانات التجريبية. ستساعدنا الاستفسارات أدناه على القيام بذلك.
#legasy SQL
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
# معيار SQL
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
دعونا نرى ما حدث نتيجة لذلك ، باستخدام مثال أحد المستخدمين مع معرف العميل = '102041117.1428132012 ′. في الجدول الأصلي لهذا المستخدم ، كانت لدينا البيانات التالية: من
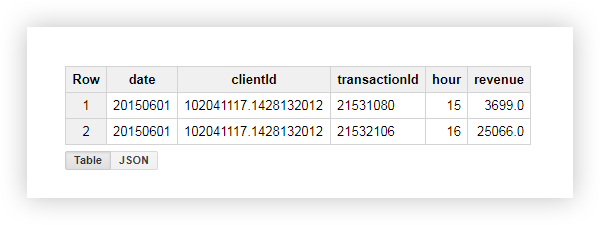
خلال تطبيق الاستعلام ، تلقينا تقريرًا يحتوي على متوسط الدخل ، والحد الأدنى ، والحد الأقصى ، وإجمالي الدخل من هذا المستخدم ، بالإضافة إلى عدد المعاملات. كما ترى في لقطة الشاشة أدناه ، أجرى المستخدم كلا المعاملتين خلال ساعات العمل:

مثال 2 . الآن دعنا نعقد المهمة قليلاً:
- دعنا نضع الأرقام التسلسلية لجميع المعاملات في النافذة ، اعتمادًا على وقت تنفيذها. تذكر أننا نحدد النافذة من قبل المستخدم ووقت العمل / غير وقت العمل.
- دعنا نعرض دخل المعاملة التالية / السابقة (بالنسبة إلى المعاملة الحالية) داخل النافذة.
- دعنا نعرض دخل المعاملات الأولى والأخيرة في النافذة.
لهذا نستخدم الاستعلامات التالية:
#legasy SQL
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
# معيار SQL
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
دعنا نتحقق من نتائج الحساب باستخدام مثال مستخدم مألوف لنا بالفعل مع clientId = '102041117.1428132012 ′:

من لقطة الشاشة أعلاه ، نرى ما يلي:
- كانت المعاملة الأولى في الساعة 15:00 والثانية في الساعة 16:00.
- بعد المعاملة الحالية الساعة 15:00 ، كانت هناك معاملة في الساعة 16:00 ، يبلغ دخلها 25066 (عمود الرصاص_الإيرادات).
- قبل إجراء المعاملة الحالية في الساعة 4:00 مساءً ، كانت هناك معاملة في الساعة 3:00 مساءً بإيرادات 3699 (عمود lag_revenue).
- كانت أول معاملة داخل النافذة عبارة عن معاملة في الساعة 15:00 ، يبلغ دخلها 3699 (العمود first_revenue_by_hour).
- يقوم الطلب بمعالجة البيانات سطرًا بسطر ، وبالتالي ، بالنسبة للمعاملة قيد النظر ، ستكون الأخيرة في النافذة والقيم في last_revenue_by_hour وأعمدة الإيرادات ستكون هي نفسها.
الاستنتاجات
في هذه المقالة ، قمنا بتغطية الوظائف الأكثر شيوعًا من الأقسام وظيفة التجميع ، وظيفة التاريخ ، وظيفة السلسلة ، وظيفة النافذة. ومع ذلك ، يحتوي Google BigQuery على العديد من الميزات المفيدة ، على سبيل المثال:
- وظائف الصب - تسمح لك بإرسال البيانات إلى تنسيق معين.
- وظائف أحرف البدل للجدول - تتيح لك الوصول إلى جداول متعددة من مجموعة بيانات.
- وظائف التعبير العادي - تسمح لك بوصف نموذج استعلام البحث وليس قيمته بالضبط.
اكتب في التعليقات إذا كان من المنطقي الكتابة عنها بنفس التفاصيل.