في حين أن لغات مثل Python و R أصبحت أكثر شيوعًا في علوم البيانات ، يمكن أن تكون C و C ++ خيارات قوية لحل المشكلات في علوم البيانات بكفاءة. في هذه المقالة ، سنستخدم C99 و C ++ 11 لكتابة برنامج يعمل مع رباعي Anscombe ، والذي سأناقشه بعد ذلك.
لقد كتبت عن حافزي لتعلم اللغات باستمرار في مقال عن Python و GNU Octave يستحق القراءة. جميع البرامج مخصصة لسطر الأوامر ، وليست واجهة مستخدم رسومية (GUI). تتوفر أمثلة كاملة في مستودع polyglot_fit.
تحدي البرمجة
البرنامج الذي ستكتبه في هذه السلسلة:
- يقرأ البيانات من ملف CSV
- يقحم البيانات بخط مستقيم (أي f (x) = m ⋅ x + q).
- يكتب النتيجة إلى ملف صورة
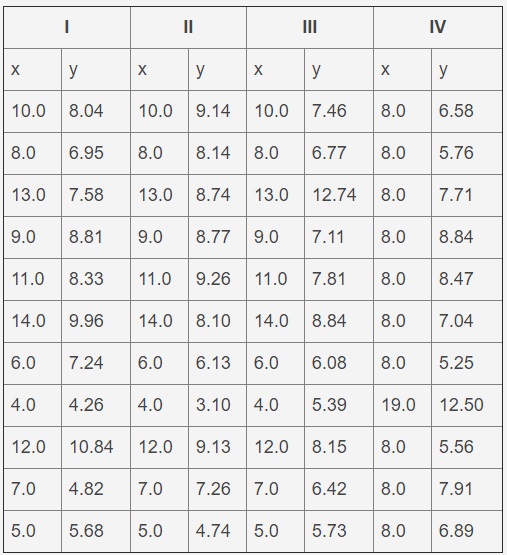
هذا هو التحدي المشترك الذي يواجهه العديد من علماء البيانات. مثال على البيانات هو المجموعة الأولى من الرباعية Anscombe ، المقدمة في الجدول أدناه. هذه مجموعة من البيانات التي تم إنشاؤها بشكل مصطنع والتي تعطي نفس النتائج عند تركيبها على خط مستقيم ، ولكن الرسوم البيانية الخاصة بهم مختلفة تمامًا. ملف البيانات هو ملف نصي بعلامات تبويب لفصل الأعمدة والعديد من الأسطر التي تشكل رأسًا. ستستخدم هذه المشكلة المجموعة الأولى فقط (أي أول عمودين).
أنسكومب الرباعية
الحل في ج
C هي لغة برمجة للأغراض العامة وهي واحدة من أكثر اللغات شيوعًا في الاستخدام اليوم (وفقًا لمؤشر TIOBE ، وتصنيفات لغة برمجة RedMonk ، ومؤشر شعبية لغة البرمجة ، وأبحاث GitHub ). إنها لغة قديمة (تم إنشاؤها حوالي عام 1973) وقد تم كتابة العديد من البرامج الناجحة فيها (على سبيل المثال ، Linux kernel و Git). هذه اللغة أيضًا قريبة قدر الإمكان من الأعمال الداخلية للكمبيوتر ، حيث يتم استخدامها لإدارة الذاكرة المباشرة. إنها لغة مترجمة ، لذلك يجب أن تترجم شفرة المصدر إلى رمز الجهاز من قبل المترجم . لهالمكتبة القياسية صغيرة وخفيفة الحجم ، لذلك تم تطوير مكتبات أخرى لتوفير الوظائف المفقودة.
هذه هي اللغة التي أستخدمها أكثر في سحق الأرقام ، ويرجع ذلك أساسًا إلى أدائها. أجد أنه ممل جدًا للاستخدام لأنه يتطلب الكثير من التعليمات البرمجية المتداخلة ، ولكنه مدعوم جيدًا في مجموعة متنوعة من البيئات. معيار C99 هو مراجعة حديثة تضيف بعض الميزات الأنيقة ويدعمها المترجمون بشكل جيد.
سأغطي المتطلبات الأساسية للبرمجة في C و C ++ حتى يتمكن كل من المستخدمين المبتدئين وذوي الخبرة من استخدام هذه اللغات.
التركيب
يتطلب تطوير C99 مترجم. عادة ما أستخدم Clang ، لكن GCC ، وهو مترجم آخر مفتوح المصدر كامل ، سيفعل . لتناسب البيانات ، قررت استخدام مكتبة غنو العلمية . للتآمر ، لم أجد أي مكتبة معقولة وبالتالي يعتمد هذا البرنامج على برنامج خارجي: Gnuplot . يستخدم المثال أيضًا بنية بيانات ديناميكية لتخزين البيانات ، والتي تم تعريفها في توزيع برامج Berkeley (BSD ).
التثبيت على Fedora بسيط للغاية:
sudo dnf install clang gnuplot gsl gsl-develتعليقات التعليمات البرمجية
في C99 ، يتم تنسيق التعليقات عن طريق إضافة // إلى بداية السطر ، وسيتم تجاهل باقي السطر من قبل المترجم. يتم أيضًا تجاهل أي شيء بين / * و * /.
// .
/* */المكتبات المطلوبة
تتكون المكتبات من جزئين:
- ملف رأس يحتوي على وصف الوظائف
- ملف المصدر يحتوي على تعريفات الوظائف
يتم تضمين ملفات الرأس في التعليمات البرمجية المصدر ، ويرتبط رمز المصدر للمكتبات بالملف القابل للتنفيذ. وبالتالي فإن ملفات الرأس مطلوبة لهذا المثال:
// -
#include <stdio.h>
//
#include <stdlib.h>
//
#include <string.h>
// "" BSD
#include <sys/queue.h>
// GSL
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>الوظيفة الأساسية
في لغة C ، يجب أن يكون البرنامج داخل وظيفة خاصة تسمى main () :
int main(void) {
...
}هنا يمكنك ملاحظة اختلاف عن Python ، والذي تمت مناقشته في البرنامج التعليمي الأخير ، لأنه في حالة Python ، سيتم تنفيذ أي تعليمات برمجية في الملفات المصدر.
تحديد المتغيرات
في لغة C ، يجب التصريح عن المتغيرات قبل استخدامها ، ويجب أن ترتبط بنوع. كلما أردت استخدام متغير ، يجب أن تقرر البيانات التي تريد تخزينها فيه. يمكنك أيضًا الإشارة إلى ما إذا كنت ستستخدم المتغير كقيمة ثابتة ، وهو أمر غير مطلوب ، ولكن يمكن للمترجم الاستفادة من هذه المعلومات. مثال من برنامج fitting_C99.c في المستودع:
const char *input_file_name = "anscombe.csv";
const char *delimiter = "\t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;المصفوفات في C ليست ديناميكية بمعنى أنه يجب تحديد طولها مسبقًا (أي قبل التجميع):
int data_array[1024];نظرًا لأنك عادةً لا تعرف عدد نقاط البيانات الموجودة في الملف ، استخدم قائمة مرتبطة بشكل فردي . إنها بنية بيانات ديناميكية يمكن أن تنمو إلى أجل غير مسمى. لحسن الحظ يوفر BSD قوائم مرتبطة بشكل فردي . إليك مثال تعريف:
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
SLIST_INIT(&head);يحدد هذا المثال قائمة data_point ، تتكون من قيم منظمة تحتوي على قيم x و y . بناء الجملة معقد للغاية ، ولكنه بديهي ، وسيكون الوصف التفصيلي مطولًا للغاية.
اطبع
للطباعة على الجهاز الطرفي ، يمكنك استخدام وظيفة printf () ، التي تعمل مثل وظيفة printf () في Octave (الموضحة في المقالة الأولى):
printf("#### C99 ####\n");لا تضيف وظيفة printf () تلقائيًا سطرًا جديدًا في نهاية السطر المطبوع ، لذلك تحتاج إلى إضافته بنفسك. الوسيطة الأولى عبارة عن سلسلة ، والتي يمكن أن تحتوي على معلومات حول تنسيق الوسائط الأخرى التي يمكن تمريرها إلى الدالة ، على سبيل المثال:
printf("Slope: %f\n", slope);قراءة البيانات
الآن يأتي الجزء الصعب ... هناك العديد من المكتبات لتحليل ملفات CSV في C ، ولكن لم تثبت أي منها أنها مستقرة أو شائعة بما يكفي لتكون في مستودع حزمة Fedora. بدلاً من إضافة تبعية لهذا البرنامج التعليمي ، قررت كتابة هذا الجزء بنفسي. مرة أخرى ، سيكون من الصعب للغاية الخوض في التفاصيل ، لذلك سأشرح فقط الفكرة العامة. سيتم تجاهل بعض الأسطر في التعليمات البرمجية المصدر للإيجاز ، ولكن يمكنك العثور على مثال كامل في المستودع.
قم أولاً بفتح ملف الإدخال:
FILE* input_file = fopen(input_file_name, "r");ثم اقرأ سطر الملف سطرًا حتى يحدث خطأ أو حتى ينتهي الملف:
while (!ferror(input_file) && !feof(input_file)) {
size_t buffer_size = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}تعد وظيفة getline () إضافة حديثة لطيفة لمعيار POSIX.1-2008 . يمكنه قراءة سطر كامل في ملف والعناية بتخصيص الذاكرة اللازمة. يتم بعد ذلك تقسيم كل سطر إلى رموز مميزة باستخدام الدالة strtok () . بالنظر إلى الرمز المميز ، حدد الأعمدة التي تحتاجها:
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, "%lf", &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}أخيرًا ، مع تحديد قيم x و y ، أضف نقطة جديدة إلى القائمة:
struct data_point *datum = malloc(sizeof(struct data_point));
datum->x = x;
datum->y = y;
SLIST_INSERT_HEAD(&head, datum, entries);تقوم دالة malloc () بتخصيص (احتياطي) ديناميكيًا قدرًا من الذاكرة الدائمة لنقطة جديدة.
بيانات ملائمة
تقبل دالة الاستكمال الخطي لـ GSL gsl_fit_linear () المصفوفات العادية كمدخلات. لذلك ، نظرًا لأنه لا يمكنك معرفة حجم المصفوفات التي تم إنشاؤها مسبقًا ، يجب عليك تخصيص ذاكرة لها يدويًا:
const size_t entries_number = row - skip_header - 1;
double *x = malloc(sizeof(double) * entries_number);
double *y = malloc(sizeof(double) * entries_number);ثم انتقل من خلال القائمة لتخزين البيانات ذات الصلة في المصفوفات:
SLIST_FOREACH(datum, &head, entries) {
const double current_x = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}الآن بعد أن انتهيت من القائمة ، قم بتنظيف الطلب. قم دائمًا بتحرير الذاكرة التي تم تخصيصها يدويًا لمنع حدوث تسرب للذاكرة . تسريبات الذاكرة سيئة ، سيئة ، ومرة أخرى سيئة. في كل مرة لا يتم فيها تحرير الذاكرة ، يفقد جنوم الحديقة رأسه:
while (!SLIST_EMPTY(&head)) {
struct data_point *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}أخيرًا ، أخيرًا (!) ، يمكنك احتواء بياناتك:
gsl_fit_linear(x, 1, y, 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);رسم رسم بياني
لإنشاء رسم بياني ، يجب عليك استخدام برنامج خارجي. لذا احتفظ بوظيفة الملاءمة في ملف خارجي:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
fprintf(output_file, "%f\t%f\n", current_x, current_y);
}يبدو أمر تخطيط Gnuplot كما يلي:
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'النتائج
قبل تشغيل البرنامج ، تحتاج إلى تجميعه:
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99يخبر هذا الأمر المترجم باستخدام معيار C99 ، وقراءة ملف fitting_C99.c ، وتحميل مكتبات gsl و gslcblas ، وحفظ النتيجة في fitting_C99. الناتج الناتج في سطر الأوامر:
#### C99 ####
: 0.500091
: 3.000091
: 0.816421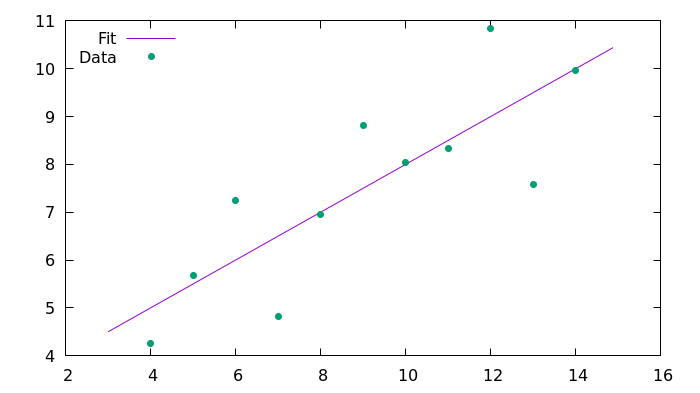
هنا هي الصورة الناتجة التي تم إنشاؤها باستخدام Gnuplot.
حل C ++ 11
C ++ هي لغة برمجة للأغراض العامة وهي أيضًا واحدة من أكثر اللغات الشائعة المستخدمة اليوم. تم إنشاؤه كخليفة للغة C (في عام 1983) مع التركيز على البرمجة الشيئية (OOP). تعتبر C ++ بشكل عام مجموعة شاملة من C ، لذلك يجب ترجمة برنامج C مع مترجم C ++. ليس هذا هو الحال دائمًا ، حيث توجد بعض حالات الحافة التي تتصرف فيها بشكل مختلف. في تجربتي ، يتطلب C ++ رمزًا أقل من اللوح الأساسي من C ، لكن بناءه أكثر تعقيدًا إذا كنت تريد تصميم الكائنات. معيار C ++ 11 هو مراجعة حديثة تضيف بعض الميزات الأنيقة التي يدعمها المترجمون بشكل أو بآخر.
نظرًا لأن C ++ متوافق تمامًا مع C ، فسوف أركز فقط على الاختلافات بين الاثنين. إذا لم أصف قسمًا في هذا الجزء ، فهذا يعني أنه هو نفسه الموجود في C.
التركيب
التبعيات لـ C ++ هي نفسها على سبيل المثال C. في Fedora ، قم بتشغيل الأمر التالي:
sudo dnf install clang gnuplot gsl gsl-develالمكتبات المطلوبة
تعمل المكتبات كما هو الحال في لغة C ، لكن توجيهات التضمين مختلفة قليلاً:
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
extern "C" {
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
}بما أن مكتبات GSL مكتوبة بلغة C ، فيجب إعلام المترجم بهذه الميزة.
تحديد المتغيرات
يدعم C ++ أنواع بيانات (فئات) أكثر من C ، على سبيل المثال ، نوع السلسلة ، الذي يحتوي على العديد من الميزات أكثر من نظيره C. قم بتحديث تعريفات المتغيرات الخاصة بك وفقًا لذلك:
const std::string input_file_name("anscombe.csv");بالنسبة للكائنات المنظمة مثل السلاسل ، يمكنك تحديد متغير بدون استخدام علامة = .
اطبع
يمكنك استخدام وظيفة printf () ، ولكن من الشائع استخدام cout . استخدم عامل << لتحديد السلسلة (أو الكائنات) التي تريد طباعتها باستخدام cout :
std::cout << "#### C++11 ####" << std::endl;
...
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;قراءة البيانات
الدائرة هي نفسها كما كانت من قبل. يتم فتح الملف وقراءته سطرًا بسطر ، ولكن باستخدام بنية مختلفة:
std::ifstream input_file(input_file_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}يتم استرداد الرموز المميزة للسلسلة بواسطة نفس الوظيفة كما في المثال C99. استخدم متجهين بدلاً من صفائف C القياسية . المتجهات هي امتداد لمصفوفات C في مكتبة C ++ القياسية لإدارة الذاكرة ديناميكيًا بدون استدعاء malloc () :
std::vector<double> x;
std::vector<double> y;
// x y
x.emplace_back(value);
y.emplace_back(value);بيانات ملائمة
لتناسب البيانات في C ++ ، لا داعي للقلق بشأن القوائم ، نظرًا لأن المتجهات مضمونة أن يكون لها ذاكرة تسلسلية. يمكنك تمرير المؤشرات مباشرة إلى المخازن المؤقتة المتجهة إلى وظائف الملاءمة:
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;رسم رسم بياني
يتم التخطيط بنفس الطريقة كما كان من قبل. اكتب إلى الملف:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
output_file << current_x << "\t" << current_y << std::endl;
}
output_file.close();ثم استخدم Gnuplot لرسم الرسم البياني.
النتائج
قبل تشغيل البرنامج ، يجب أن يتم ترجمته باستخدام أمر مشابه:
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11الناتج الناتج في سطر الأوامر:
#### C++11 ####
: 0.500091
: 3.00009
: 0.816421وهنا الصورة الناتجة ، التي تم إنشاؤها باستخدام Gnuplot.
خاتمة
تقدم هذه المقالة أمثلة لتركيب البيانات ورسمها في C99 و C ++ 11. نظرًا لأن C ++ متوافق إلى حد كبير مع C ، فإن هذه المقالة تستخدم أوجه التشابه لكتابة مثال ثان. في بعض الجوانب ، يعد C ++ أسهل في الاستخدام ، لأنه يخفف جزئيًا من عبء إدارة الذاكرة الصريحة ، ولكن بناء الجملة أكثر تعقيدًا ، لأنه يقدم القدرة على كتابة فئات لـ OOP. ومع ذلك ، يمكنك أيضًا الكتابة بلغة C باستخدام تقنيات OOP ، نظرًا لأن OOP هو نمط برمجة ، يمكن استخدامه بأي لغة. هناك بعض الأمثلة الرائعة لـ OOP في C ، مثل مكتبات GObject و Jansson .
أفضل استخدام C99 للعمل مع الأرقام بسبب تركيبها الأبسط ودعمها الأوسع. حتى وقت قريب ، لم يكن C ++ 11 مدعومًا على نطاق واسع وحاولت تجنب الحواف الخشنة في الإصدارات السابقة. بالنسبة إلى البرامج الأكثر تعقيدًا ، قد يكون C ++ خيارًا جيدًا.
هل تستخدم C أو C ++ ل Data Science؟ شارك تجربتك في التعليقات.

تعرف على تفاصيل كيفية الحصول على مهنة رفيعة المستوى من الصفر أو المستوى الأعلى في المهارات والراتب من خلال الحصول على دورات SkillFactory المدفوعة عبر الإنترنت:
- دورة تعلم الآلة (12 أسبوعًا)
- تدريب مهنة علوم البيانات من الصفر (12 شهرًا)
- مهنة التحليلات مع أي مستوى بداية (9 أشهر)
- بايثون لدورة تطوير الويب (9 شهور)