ما هو الكلام البشري؟ هذه كلمات تسمح لك مجموعاتها بالتعبير عن هذه المعلومات أو تلك. السؤال الذي يطرح نفسه ، كيف نعرف متى تنتهي كلمة واحدة وتبدأ أخرى؟ السؤال غريب نوعًا ما ، سيظن الكثيرون ، لأنه منذ الولادة نسمع خطاب الناس من حولنا ، نتعلم التحدث والكتابة والقراءة. بالطبع ، تلعب العبء المتراكم للمعرفة اللغوية دورًا مهمًا ، ولكن بالإضافة إلى ذلك ، هناك شبكات عصبية في الدماغ تقسم تدفق الكلام إلى كلمات مكونة و / أو مقاطع. اليوم سنتعرف على دراسة قام فيها علماء من جامعة جنيف (سويسرا) بإنشاء نموذج للحاسوب العصبي لفك تشفير الكلام من خلال التنبؤ بالكلمات والمقاطع. ما هي العمليات الدماغية التي أصبحت أساس النموذج ، وما تعنيه الكلمة الكبيرة "التنبؤ" ،وما مدى فعالية النموذج الذي تم إنشاؤه؟ الإجابات على هذه الأسئلة تنتظرنا في تقرير العلماء. اذهب.
أساس البحث
بالنسبة لنا نحن البشر ، الكلام البشري مفهوم ومفهوم تمامًا (في أغلب الأحيان). ولكن بالنسبة للسيارة ، هذا مجرد دفق من المعلومات الصوتية ، وهي إشارة مستمرة يجب فك شفرتها قبل فهمها.
يعمل دماغ الإنسان بنفس الطريقة تقريبًا ، فهو يحدث بسرعة كبيرة وغير محسوسة بالنسبة لنا. يعتقد العلماء أن أساس هذا والعديد من عمليات الدماغ الأخرى هي بعض التذبذبات العصبية ، بالإضافة إلى مجموعاتها.
على وجه الخصوص ، يرتبط التعرف على الكلام بمزيج من تذبذبات ثيتا وجاما ، لأنه يسمح بالتنسيق الهرمي لتشفير الصوتيات في المقاطع دون معرفة مسبقة بمدتها وأصلها الزمني ، أي. معالجة المنبع * في الوقت الحقيقي.
* (bottom-up) — , .يعتمد التعرف الطبيعي على الكلام أيضًا بشكل كبير على الإشارات السياقية للتنبؤ بالمحتوى والهيكل الزمني لإشارة الكلام. أظهرت الدراسات السابقة أنه خلال إدراك الكلام المستمر ، فإن آلية التنبؤ هي التي تلعب دورًا مهمًا. ترتبط هذه العملية باهتزازات بيتا.
عنصر آخر مهم من التعرف على إشارات الكلام يمكن أن يسمى الترميز التنبئي ، عندما يولد الدماغ باستمرار ويحدث النموذج العقلي للبيئة. يُستخدم هذا النموذج لإنشاء تنبؤات باللمس تتم مقارنتها بإدخال اللمس الفعلي. تؤدي مقارنة الإشارة المتوقعة والفعلية إلى تحديد الأخطاء التي تعمل على تحديث ومراجعة النموذج العقلي.
وبعبارة أخرى ، يتعلم الدماغ دائمًا شيئًا جديدًا ، ويحدث باستمرار نموذج العالم المحيط. تعتبر هذه العملية حاسمة في معالجة إشارات الكلام.
يلاحظ العلماء أن العديد من الدراسات النظرية تدعم كلا النهجين التصاعدي والسفلي لمعالجة الكلام.
المعالجة من أعلى لأسفل * (من أعلى لأسفل ) - تحليل النظام إلى مكوناته للحصول على فكرة عن أنظمته الفرعية التركيبية باستخدام الهندسة العكسية.كان نموذج الحاسبات العصبية الذي تم تطويره سابقًا ، والذي يتضمن مزيجًا من شبكات ثيتا وشبكات الإثارة / المثبطة الواقعية ، قادرًا على معالجة الكلام مسبقًا حتى يمكن فك شفرته بشكل صحيح.
يمكن لنموذج آخر ، يعتمد فقط على الترميز التنبئي ، التعرف بدقة على عناصر الكلام الفردية (مثل الكلمات أو الجمل الكاملة إذا تم النظر إليها كعنصر كلام واحد).
لذلك ، عمل كلا النموذجين ، في اتجاهات مختلفة فقط. ركز أحدهما على الجانب الحقيقي لتحليل الكلام ، والآخر على التعرف على شرائح الكلام المعزولة (لا يتطلب التحليل).
ولكن ماذا لو دمجنا المبادئ الأساسية لهذه النماذج المختلفة جذريًا في نموذج واحد؟ وفقًا لمؤلفي الدراسة التي ندرسها ، سيؤدي ذلك إلى تحسين الأداء وزيادة الواقعية البيولوجية لنماذج معالجة الكلام في الكمبيوتر العصبي.
في عملهم ، قرر العلماء اختبار ما إذا كان نظام التعرف على الكلام القائم على التشفير التنبؤي يمكن أن يحصل على بعض الفائدة من عمليات التذبذبات العصبية.
قاموا بتطوير نموذج الكمبيوتر العصبي Precoss (من الترميز التنبئي والتذبذبات في الكلام ) ، استنادًا إلى بنية التشفير التنبؤية ، التي أضافوا إليها وظائف التذبذب ثيتا وجاما للتعامل مع الطبيعة المستمرة للكلام الطبيعي.
كان الغرض المحدد من هذا العمل هو العثور على إجابة للسؤال عما إذا كان مزيج من الترميز التنبئي والتذبذبات العصبية يمكن أن يكون مفيدًا لتحديد سريع للمكونات المقطعية للجمل الطبيعية. على وجه الخصوص ، تم النظر في الآليات التي يمكن من خلالها لموجات ثيتا أن تتفاعل مع مجرى المعلومات المنبع والمصب ، وتم تقييم تأثير هذا التفاعل على كفاءة عملية فك التشفير المقطع.
نماذج العمارة
تتمثل إحدى الوظائف المهمة للنموذج في أنه يجب أن يكون قادرًا على استخدام الإشارات / المعلومات الزمنية الموجودة في الكلام المستمر لتحديد حدود المقطع. اقترح العلماء أن النماذج التوليدية الداخلية ، بما في ذلك التنبؤات الزمنية ، يجب أن تستفيد من هذه الإشارات. لاستيعاب هذه الفرضية ، وكذلك العمليات المتكررة التي تحدث أثناء التعرف على الكلام ، تم استخدام نموذج التشفير التنبئي المستمر.
يفصل النموذج المطور بوضوح "ماذا" و "متى". "ماذا" - يشير إلى هوية المقطع المقطعي وتمثيله الطيفي (ليس مؤقتًا ، ولكن تسلسلًا منظمًا للمتجهات الطيفية) ؛ يشير "متى" إلى توقع توقيت ومدة المقاطع.
ونتيجة لذلك ، تتخذ التنبؤات شكلين: بداية مقطع ، مشار إليه بواسطة وحدة ثيتا. ومدة المقطع ، مشار إليها بواسطة تذبذبات ثيتا الخارجية / الداخلية ، والتي تحدد مدة تسلسل الوحدة المتزامنة مع غاما (الرسم البياني أدناه).
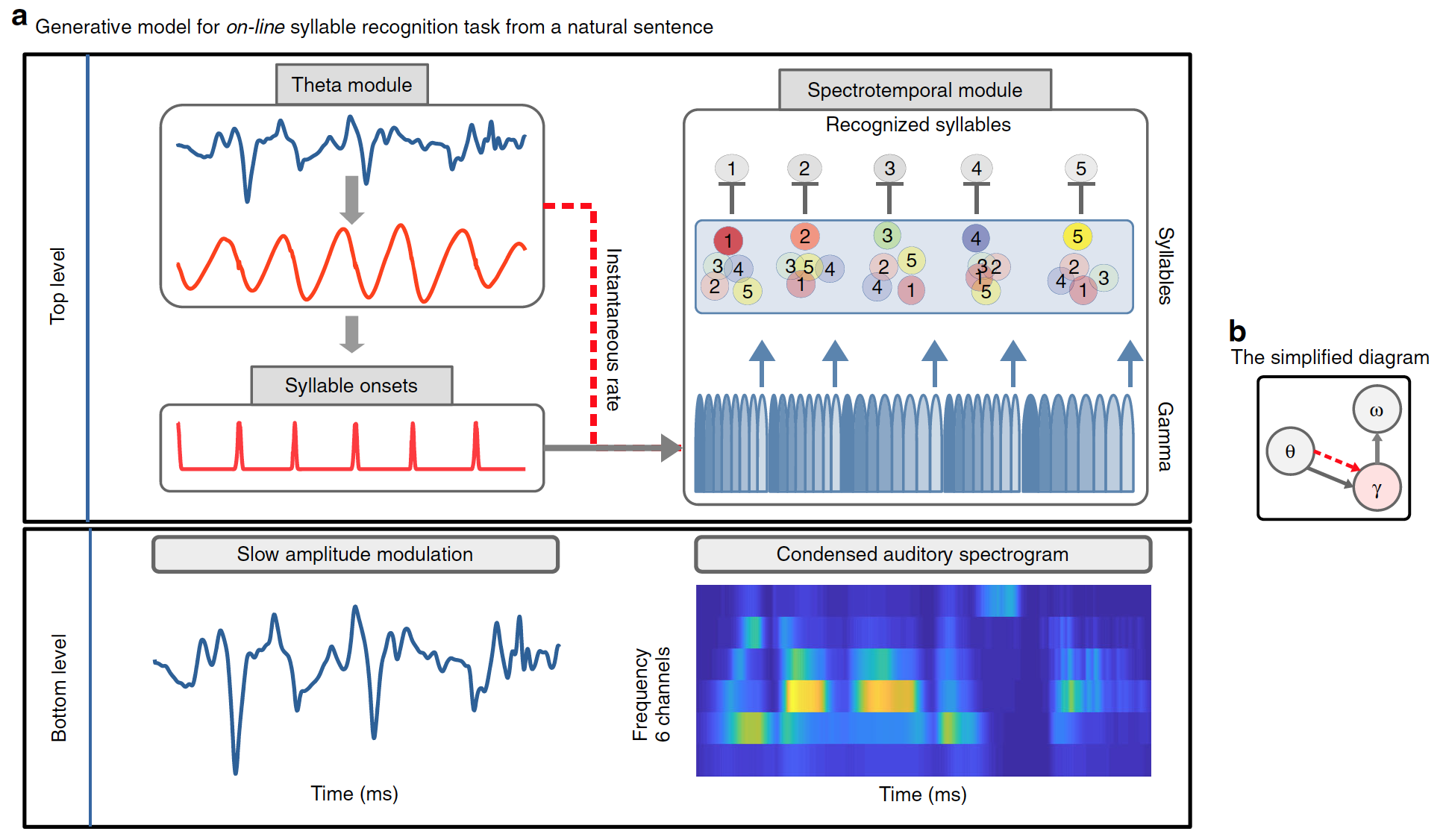
الصورة رقم 1
يستخرج Precoss إشارة المستشعر من التمثيلات الداخلية لمصدرها من خلال الإشارة إلى نموذج التوليد. في هذه الحالة ، يتوافق الإدخال باللمس مع التعديل البطيء للإشارة الكلامية والمخطط الطيفي السمعي ذي 6 قنوات للجملة الطبيعية الكاملة ، التي يولدها النموذج داخليًا من أربعة مكونات:
- تمايل ثيتا
- كتلة تعديل السعة البطيئة في وحدة ثيتا ؛
- مجموعة من وحدات المقاطع (عدد المقاطع الموجودة في الجملة التمهيدية الطبيعية ، أي من 4 إلى 25) ؛
- بنك من ثماني وحدات جاما في الوحدة الزمنية الطيفية.
تعمل وحدات المقاطع وتذبذبات جاما معًا على توليد تنبؤات تنازلية بشأن مخطط طيفي الإدخال. تمثل كل وحدة من وحدات جاما الثمانية مرحلة في مقطع ؛ يتم تنشيطها بالتسلسل ، ويتم تكرار تسلسل التنشيط بأكمله. لذلك ، ترتبط كل وحدة مقطع بتسلسل من ثمانية نواقل (واحد لكل وحدة جاما) مع ستة مكونات لكل منها (واحد لكل قناة تردد). يتم إنشاء مخطط الطيف الصوتي للمقطع الفردي عن طريق تنشيط وحدة المقطع المطابق طوال مدة المقطع.
في حين أن كتلة المقاطع تشفر نمطًا صوتيًا محددًا ، فإن كتل جاما تستخدم مؤقتًا التنبؤ الطيفي المناسب طوال مدة المقطع. يتم تقديم معلومات حول طول المقطع من خلال موجة ثيتا ، حيث تؤثر سرعته اللحظية على سرعة / مدة تسلسل غاما.
أخيرًا ، يجب حذف البيانات المتراكمة على المقطع المقصود قبل معالجة المقطع التالي. للقيام بذلك ، تقوم كتلة غاما الأخيرة (الثامنة) ، التي تشفر الجزء الأخير من مقطع ، بإعادة تعيين جميع وحدات المقطع إلى مستوى تنشيط منخفض بشكل عام ، مما يسمح بجمع أدلة جديدة.
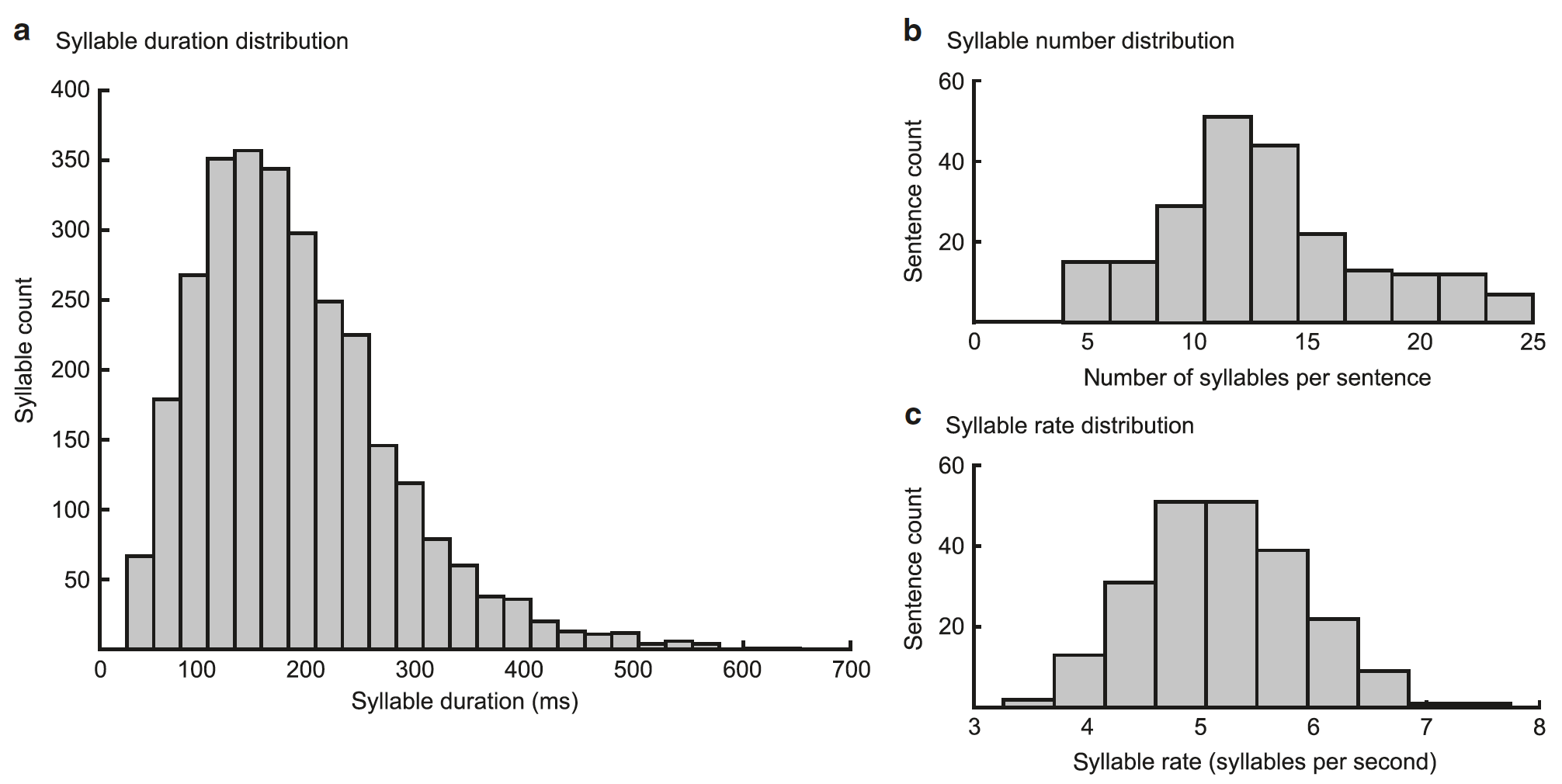
الصورة رقم 2
يعتمد أداء النموذج على ما إذا كان تسلسل غاما يتزامن مع بداية مقطع وما إذا كانت مدته تتطابق مع مدة مقطع (50-600 مللي ثانية ، متوسط = 182 مللي ثانية).
يتم توفير تقدير النموذج فيما يتعلق بتسلسل المقاطع من خلال وحدات المقاطع ، التي تولد مع وحدات جاما الأنماط الزمنية الطيفية المتوقعة (نتيجة تشغيل النموذج) ، والتي تتم مقارنتها مع مخطط طيفي الإدخال. يقوم النموذج بتحديث تقديراته حول المقطع الحالي لتقليل الفرق بين الرسم البياني الطيفي الذي تم إنشاؤه والفعلية. يزداد مستوى النشاط في تلك الوحدات ذات المقاطع التي يتوافق مطيافها مع المدخلات الحسية ، وينقص في وحدات أخرى. في الحالة المثالية ، يؤدي تقليل أخطاء التنبؤ في الوقت الفعلي إلى زيادة النشاط في وحدة مقطع منفصلة واحدة تتوافق مع مقطع الإدخال.
نتائج المحاكاة
يتضمن النموذج المعروض أعلاه تذبذبات ثيتا ذات الدافع الفسيولوجي ، والتي يتم التحكم فيها من خلال تعديلات السعة البطيئة لإشارة الكلام ونقل المعلومات حول بداية ومدة المقطع إلى مكون غاما.
يوفر ارتباط ثيتا-جاما محاذاة مؤقتة للتنبؤات الداخلية التي تم إنشاؤها مع حدود المقاطع المكتشفة بواسطة بيانات الإدخال (الخيار A في الصورة رقم 3).
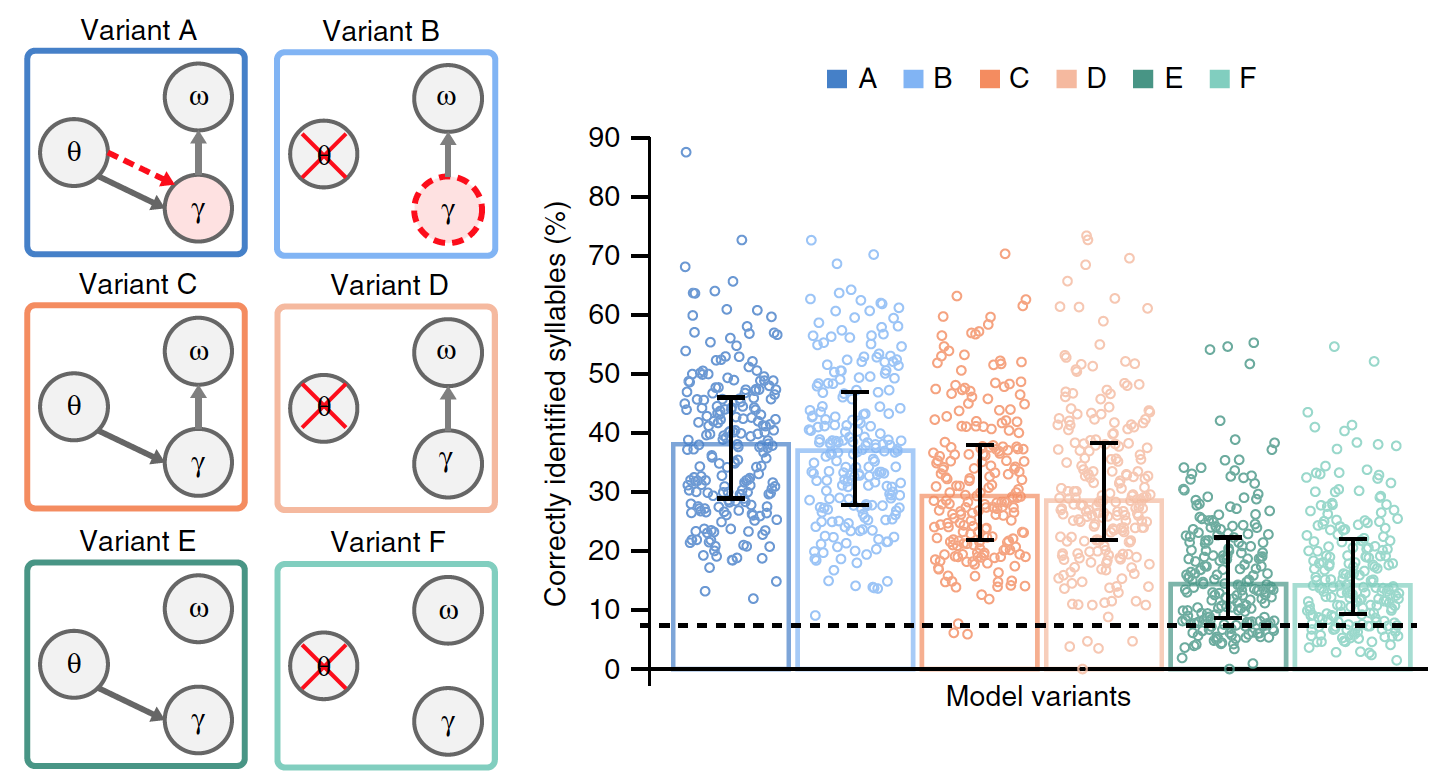
الصورة رقم 3
لتقييم مدى ملاءمة التزامن المقطعي بناءً على تعديل السعة البطيئة ، قمنا بمقارنة النموذج A مع المتغير B ، حيث لا يتم نمذجة نشاط ثيتا بواسطة التذبذبات ، ولكن ينشأ من التكرار الذاتي لتسلسل غاما.
في النموذج B ، لم يعد يتم التحكم في مدة تسلسل غاما خارجيًا (بسبب العوامل الخارجية) من خلال تذبذبات ثيتا ، ولكن داخليًا (بسبب العوامل الداخلية) يستخدم معدل جاما المفضل ، والذي ، عندما يتكرر التسلسل ، يؤدي إلى تكوين إيقاع ثيتا داخلي. كما هو الحال في تذبذبات ثيتا ، فإن مدة تسلسل غاما لها معدل مفضل في نطاق ثيتا ، والتي يمكن أن تتكيف مع أطوال المقاطع المختلفة. في هذه الحالة ، من الممكن اختبار إيقاع ثيتا الناتج عن تكرار تسلسل غاما.
لإجراء تقييم أكثر دقة للتأثيرات المحددة لثيتا جاما لتركيب وإلقاء البيانات المتراكمة في وحدات مقطعية ، تم عمل إصدارات إضافية من النماذج السابقة A و B.
تميز الخياران C و D بغياب معدل إشعاع جاما المفضل. اختلف الخياران E و F بالإضافة إلى الخيارين C و D في غياب إعادة تعيين البيانات المتراكمة على المقاطع.
من بين جميع متغيرات النموذج ، فقط أ لديه علاقة ثيتا جاما الحقيقية ، حيث يتم تحديد نشاط جاما من خلال وحدة ثيتا ، بينما في النموذج ب يتم تعيين معدل جاما داخليًا.
كان من الضروري تحديد أي إصدار من النموذج هو الأكثر فاعلية ، والذي تم من أجله مقارنة نتائج عملهم في وجود بيانات إدخال مشتركة (جمل طبيعية). يوضح الرسم البياني في الصورة أعلاه متوسط أداء كل من النماذج.
كانت هناك اختلافات كبيرة بين الخيارات. بالمقارنة مع الطرازين A و B ، كان الأداء أقل بكثير في الطرازين E و F (23٪ في المتوسط) و C و D (15٪). هذا يشير إلى أن محو البيانات المتراكمة حول المقطع السابق قبل معالجة المقطع الجديد هو عامل حاسم في ترميز دفق المقطع في الكلام الطبيعي.
أظهرت مقارنة الخيارين A و B مع الخيارين C و D أن اتصال ثيتا-جاما ، سواء كان محفزًا (A) أو داخليًا (B) ، يحسن بشكل كبير أداء النموذج (بمتوسط 8.6٪).
بشكل عام ، أظهرت التجارب مع إصدارات مختلفة من النماذج أنها تعمل بشكل أفضل عندما يتم إعادة تعيين وحدات المقطع بعد كل تسلسل من وحدات غاما (بناءً على معلومات داخلية حول البنية الطيفية للمقطع) ، وعندما يتم تحديد معدل إشعاع غاما من خلال اقتران ثيتا غاما.
لذلك ، لا يعتمد أداء النموذج مع الجمل الطبيعية على الإشارة الدقيقة لبداية المقاطع عن طريق تذبذبات ثيتا المدفوعة بالمحفزات ، ولا على الآلية الدقيقة لعلاقة ثيتا-جاما.
كما يعترف العلماء أنفسهم ، هذا اكتشاف مدهش إلى حد ما. من ناحية أخرى ، فإن عدم وجود اختلافات في الأداء بين الارتباط بين الدافع التحفيزي والربط بين ثيتا وغاما يعكس حقيقة أن مدة المقاطع في الكلام الطبيعي قريبة جدًا من توقعات النموذج ، وفي هذه الحالة لن تكون هناك ميزة لإشارة ثيتا مدفوعة مباشرة ببيانات الإدخال.
لفهم مثل هذا التحول غير المتوقع للأحداث ، أجرى العلماء سلسلة أخرى من التجارب ، ولكن مع إشارات الكلام المضغوطة (x2 و x3). كما تظهر الدراسات السلوكية ، لا يتغير فهم الكلام المضغوط في x2 مرات عمليًا ، لكنه ينخفض بشكل ملحوظ عند الضغط عليه 3 مرات.
في هذه الحالة ، يمكن أن يكون اتصال ثيتا-جاما المحفز مفيدًا للغاية في تحليل المقاطع وفك تشفيرها. يتم عرض نتائج المحاكاة أدناه.

الصورة رقم 4
كما هو متوقع ، انخفض الأداء العام مع زيادة نسبة الضغط. لضغط X2 ، لا يوجد حتى الآن فرق كبير بين التحفيز والعلاقة بين ثيتا وغاما. ولكن في حالة ضغط X3 ، هناك فرق كبير. هذا يشير إلى أن تمايل ثيتا المدفوع بالمحفزات ، يقود ارتباط ثيتا-جاما ، كان أكثر فائدة لعملية تشفير المقطع من سرعة ثيتا التي تم ضبطها داخليًا.
ويترتب على ذلك أنه يمكن معالجة الكلام الطبيعي باستخدام مولد ثيتا الداخلي نسبيًا ثابتًا نسبيًا. ولكن بالنسبة لإشارات الكلام المدخلة الأكثر تعقيدًا (على سبيل المثال ، عندما تتغير سرعة الكلام باستمرار) ، يلزم وجود مولد ثيتا المتحكم فيه والذي ينقل معلومات دقيقة عن المقاطع إلى مشفر جاما (بداية المقطع ومدة المقطع).
قدرة النموذج على التعرف على المقاطع بدقة في جملة الإدخال لا تأخذ في الاعتبار التعقيد المتغير لمختلف النماذج المقارنة. لذلك ، تم تقييم معيار معلومات بايزي (BIC) لكل نموذج. يحدد هذا المعيار كمًا التوافق بين دقة وتعقيد النموذج (الصورة رقم 5). أظهرت
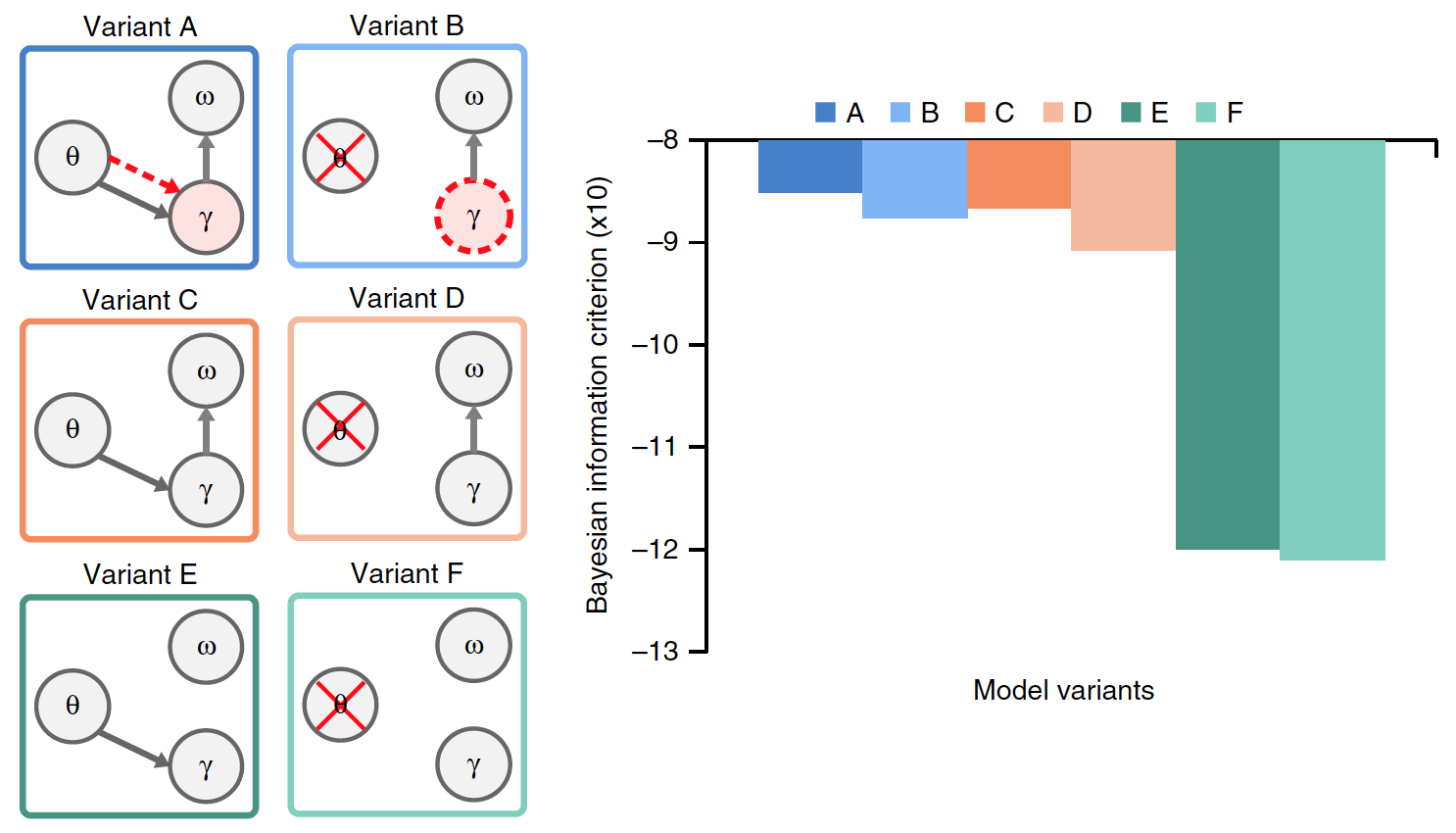
الصورة رقم 5
الخيار A أعلى قيم BIC. لم تتمكن المقارنات السابقة بين النموذج A والنموذج B من التمييز بدقة بين أدائهم. ومع ذلك ، وبفضل معيار BIC ، أصبح من الواضح أن الخيار A يوفر التعرف على المقطع بشكل أكثر ثقة من النموذج دون تذبذبات ثيتا المدفوعة بالمحفزات (النموذج B).
لمعرفة أكثر تفصيلا عن الفروق الدقيقة في الدراسة ، أوصي بالنظر في تقرير العلماء ومواد إضافية لها.
الخاتمة
تلخيص النتائج المذكورة أعلاه ، يمكننا القول أن نجاح النموذج يعتمد على عاملين رئيسيين. الأول والأهم هو إغراق البيانات المتراكمة بناءً على معلومات نموذجية حول محتوى المقطع (في هذه الحالة ، هيكله الطيفي). العامل الثاني هو العلاقة بين عمليات ثيتا وغاما ، والتي تضمن إدراج نشاط غاما في دورة ثيتا ، بما يتوافق مع المدة المتوقعة للمقطع.
في الأساس ، قام النموذج المطور بتقليد عمل الدماغ البشري. تم تعديل الصوت الذي يدخل النظام بواسطة موجة ثيتا تشبه نشاط الخلايا العصبية. هذا يسمح لك بتحديد حدود المقاطع. علاوة على ذلك ، تساعد موجات غاما الأسرع في ترميز المقطع. في هذه العملية ، يقترح النظام المتغيرات المحتملة للمقاطع ويصحح الاختيار إذا لزم الأمر. بالقفز بين المستويين الأول والثاني (ثيتا وجاما) ، يكتشف النظام الإصدار الصحيح من المقطع ، ومن ثم يبدأ في الأصفار لبدء العملية للمقطع التالي.
خلال الاختبارات العملية ، تم فك شفرات 2888 مقطعًا بنجاح (تم استخدام 220 جمل من الكلام الطبيعي ، الإنجليزية).
لم تجمع هذه الدراسة بين نظريتين متعارضتين فقط ، ووضعهما موضع التطبيق كنظام واحد ، بل جعلت من الممكن أيضًا فهم كيفية إدراك دماغنا لإشارات الكلام بشكل أفضل. يبدو لنا أننا ندرك الكلام "كما هو" ، أي بدون أي عمليات مساعدة معقدة. ومع ذلك ، وبالنظر إلى نتائج المحاكاة ، اتضح أن ثيتا العصبية وتذبذبات جاما تسمح لدماغنا بعمل تنبؤات صغيرة حول المقطع الذي نسمعه ، على أساس أي تصور للكلام يتكون.
من يقول أي شيء ، لكن الدماغ البشري يبدو أحيانًا أكثر غموضاً وغير مفهوم من الزوايا غير المكتشفة في الكون أو الأعماق اليائسة للمحيطات.
شكرا لاهتمامكم ، ابقوا فضوليين وأتمنى لكم أسبوع عمل جيد يا رفاق. :)
القليل من الدعاية
أشكركم على البقاء معنا. هل تحب مقالاتنا؟ هل تريد مشاهدة محتوى أكثر إثارة للاهتمام؟ ادعمنا عن طريق تقديم طلب أو التوصية لأصدقائك VPS القائم على السحابة للمطورين من $ 4.99 ، وهو نظير فريد من نوعه لخوادم مستوى الدخول التي اخترعناها لك: الحقيقة الكاملة حول VPS (KVM) E5-2697 v3 (6 نوى) 10GB DDR4 480GB SSD 1Gbps من $ 19 أو كيفية تقسيم الخادم بشكل صحيح؟ (تتوفر الخيارات مع RAID1 و RAID10 ، حتى 24 مركزًا وذاكرة DDR4 تصل إلى 40 جيجابايت).
Dell R730xd أرخص مرتين في مركز بيانات Equinix Tier IV في أمستردام؟ فقط لدينا 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV من 199 دولارًا في هولندا!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - من 99 دولار! اقرأ عن كيفية بناء البنية التحتية للبناء. الطبقة باستخدام خوادم Dell R730xd E5-2650 v4 بتكلفة 9000 يورو مقابل بنس واحد؟