في نهاية المقال ، سنشارك معك قائمة بالمواد الأكثر إثارة للاهتمام حول هذا الموضوع.

نهج جديد
يعد التعلم المعزز متعدد العوامل مجالًا متناميًا وثريًا للبحث. ومع ذلك ، فإن الاستخدام المستمر للخوارزميات أحادية العامل في سياقات متعددة العوامل يضعنا في موقف صعب. التعلم معقد لأسباب عديدة ، خاصة بسبب:
- عدم الاستقرار بين وكلاء مستقلين ؛
- النمو الأسي لمساحات الأفعال والدول.
لقد وجد الباحثون العديد من الطرق للحد من آثار هذه العوامل. تندرج معظم هذه الأساليب تحت مفهوم "التخطيط المركزي مع التنفيذ اللامركزي".
التخطيط المركزي
كل وكيل لديه وصول مباشر إلى الملاحظات المحلية. يمكن أن تكون هذه الملاحظات متنوعة للغاية: صور البيئة ، والمواقف المتعلقة ببعض المعالم أو حتى المواضع بالنسبة للعوامل الأخرى. بالإضافة إلى ذلك ، أثناء التدريب ، تتم إدارة جميع العملاء بواسطة وحدة مركزية أو ناقد.
على الرغم من أن كل وكيل لديه معلومات محلية وسياسات محلية للتدريب فقط ، فهناك كيان يراقب نظام الوكلاء بأكمله ويخبرهم بكيفية تحديث السياسات. وبالتالي ، يتم تقليل تأثير عدم الثبات. يتم تدريب جميع العملاء باستخدام الوحدة مع المعلومات العالمية.
التنفيذ اللامركزي
أثناء الاختبار ، تتم إزالة الوحدة المركزية ، ويبقى الوكلاء مع سياساتهم وبياناتهم المحلية. هذا يقلل من الضرر الناجم عن المساحات المتزايدة من الإجراءات والدول ، حيث لا يتم دراسة السياسات الإجمالية مطلقًا. بدلاً من ذلك ، نأمل أن يكون هناك معلومات كافية في الوحدة المركزية لدفع سياسة التعلم المحلية بحيث تكون مثالية للنظام بأكمله بمجرد أن يحين وقت الاختبار.
Openai
قدم باحثون من OpenAI ، جامعة كاليفورنيا في بيركلي وجامعة ماكجيل ، نهجًا جديدًا للإعدادات متعددة الوكلاء باستخدام تدرج السياسة الحتمية المتعددة العوامل . مستوحى من نظيره الوكيل الوحيد لـ DDPG ، يستخدم هذا النهج التدريب من نوع "الممثل الناقد" ويظهر نتائج واعدة للغاية.
هندسة معمارية
تفترض هذه المقالة أنك معتاد على إصدار الوكيل المفرد لـ MADDPG: تدرجات السياسة الحتمية العميقة أو DDPG. لتحديث ذاكرتك ، يمكنك قراءة المقالة الرائعة لكريس يون .
كل عامل لديه مساحة مراقبة ومساحة عمل مستمرة. يحتوي كل وكيل أيضًا على ثلاثة مكونات:
- , ;
- ;
- , - Q-.
بينما يفحص الناقد القيم Q المشتركة لوظيفة ما بمرور الوقت ، يرسل تقريبًا مناسبًا من قيم Q إلى الممثل للمساعدة في التعلم. في القسم التالي ، سنفحص هذا التفاعل بمزيد من التفصيل.
تذكر أن الناقد يمكن أن يكون شبكة مشتركة بين جميع وكلاء N. وبعبارة أخرى ، بدلاً من تدريب شبكات N التي تقيم نفس القيمة ، ما عليك سوى تدريب شبكة واحدة واستخدامها للمساعدة في تدريب جميع الوكلاء الآخرين. وينطبق الشيء نفسه على شبكات الممثلين إذا كان الوكلاء متجانسون.
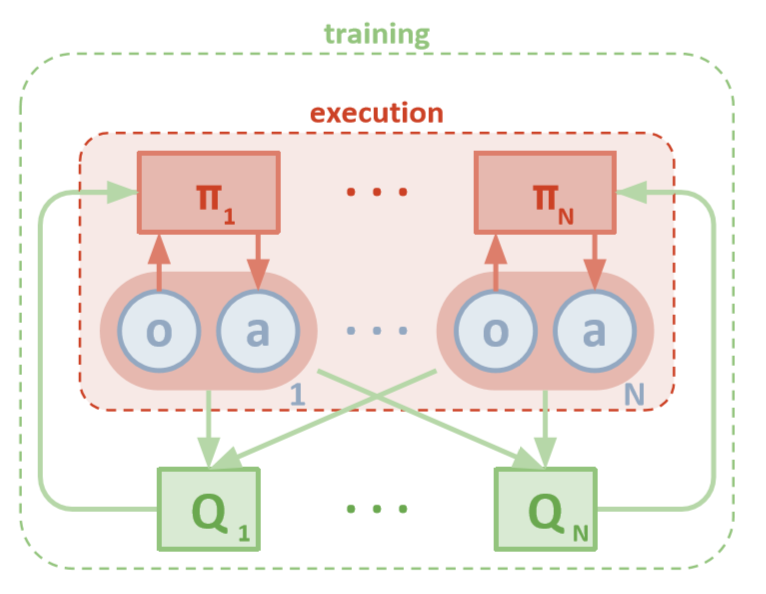
هندسة MADDPG (لوي ، 2018)
تدريب
أولاً ، تستخدم MADDPG تجربة إعادة التشغيل للتعلم الفعال خارج السياسة . في كل فترة زمنية ، يقوم الوكيل بتخزين الانتقال التالي:
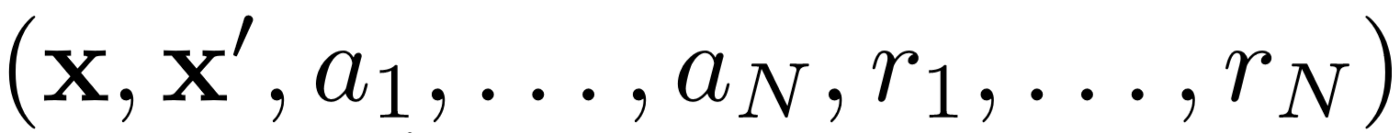
حيث نقوم بتخزين الحالة المشتركة ، والحالة المشتركة التالية ، والعمل المشترك ، وكل من المكافآت التي يتلقاها الوكيل. ثم نأخذ مجموعة من هذه التحولات من إعادة التجربة لتدريب وكيلنا.
تحديثات النقد
لتحديث الناقد المركزي للوكيل ، نستخدم خطأ TD lookahead:
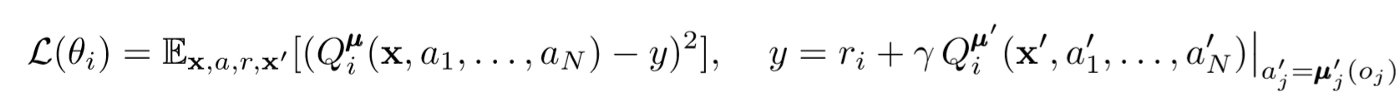
حيث μ هو ممثل. تذكر أن هذا ناقد مركزي ، مما يعني أنه يستخدم معلومات عامة لتحديث معلماته. الفكرة الأساسية هي أنه إذا كنت تعرف الإجراءات التي يتخذها جميع الوكلاء ، فستكون البيئة ثابتة حتى إذا تغيرت السياسة.
انتبه للجانب الأيمن من التعبير مع حساب قيمة Q. على الرغم من أننا لا نحفظ تعاوننا التالي أبدًا ، إلا أننا نستخدم كل ممثل مستهدف للوكيل لحساب الإجراء التالي أثناء التحديث لجعل التعلم أكثر استقرارًا. يتم تحديث معلمات الممثل المستهدف بشكل دوري لتتناسب مع تلك الخاصة بممثل الوكيل.
تحديثات الفاعل
على غرار DDPG للوكيل الواحد ، نستخدم تدرجًا محددًا للسياسة لتحديث كل معلمة للعامل الفاعل.
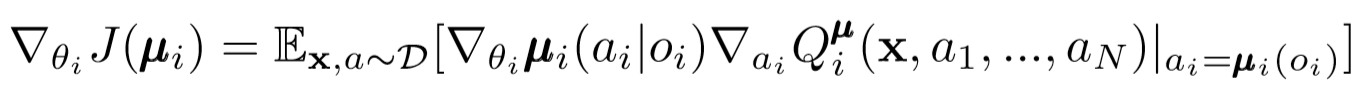
أين μ هو ممثل الوكيل.
دعونا نتعمق قليلاً في هذا التعبير عن التجديد. نأخذ التدرج النسبي لمعلمات الممثل باستخدام ناقد المركز. أهم شيء يجب الانتباه إليه هو أنه حتى لو كان لدى الممثل ملاحظات وأفعال محلية فقط ، أثناء التدريب ، نستخدم ناقدًا مركزيًا للحصول على معلومات حول مدى أمثلية أفعاله داخل النظام ككل. وهكذا ، يتم تقليل تأثير اللا ثابتية ، وتبقى سياسة التعلم في مساحة أقل من الدول!
استنتاجات السياسيين ومجموعات السياسيين
يمكننا اتخاذ خطوة أخرى بشأن قضية اللامركزية. في التحديثات السابقة ، افترضنا أن كل وكيل سيتعرف تلقائيًا على إجراءات الوكلاء الآخرين. ومع ذلك ، تقترح MADDPG استخلاص استنتاجات من سياسات الوكلاء الآخرين من أجل جعل التدريب أكثر استقلالية. في الواقع ، سيضيف كل وكيل شبكات N-1 لتقييم صلاحية السياسة لجميع الوكلاء الآخرين. نستخدم شبكة احتمالية لتعظيم الاحتمال اللوغاريتمي لاستنتاج الإجراء المرصود لعامل آخر.
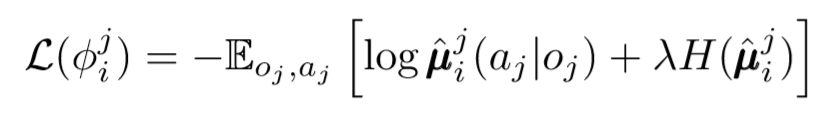
حيث نرى دالة الخسارة للعامل ith ، تقييم سياسات الوكيل jth باستخدام منظم الإنتروبيا. ونتيجة لذلك ، تصبح قيمة Q المستهدفة لدينا مختلفة قليلاً عندما نستبدل إجراءات الوكيل بإجراءاتنا المتوقعة!
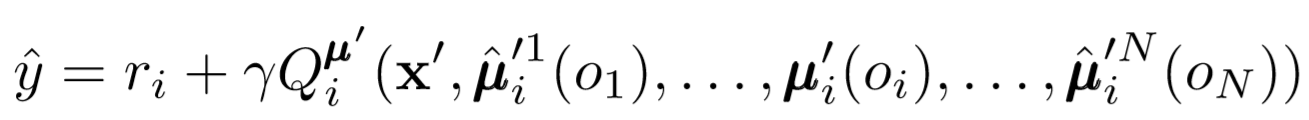
لذا ، ماذا انتهى بك؟ أزلنا الافتراض القائل بأن الوكلاء يعرفون سياسات بعضهم البعض. بدلاً من ذلك ، نحاول تدريب الوكلاء للتنبؤ بسياسات الوكلاء الآخرين بناءً على سلسلة من الملاحظات. في الواقع ، يتعلم كل وكيل بشكل مستقل ، حيث يتلقى معلومات عالمية من البيئة بدلاً من مجرد الحصول عليها بشكل افتراضي.
مجموعات من السياسيين
هناك مشكلة واحدة كبيرة في النهج أعلاه. في العديد من إعدادات الوكلاء المتعددين ، خاصة في الظروف التنافسية ، يمكن للوكلاء إنشاء سياسات يمكن أن تتراجع عن سلوك الوكلاء الآخرين. وهذا سيجعل السياسة هشة وغير مستقرة وعامة بشكل عام. للتعويض عن هذا النقص ، تقوم MADDPG بتدريب مجموعة من السياسات الفرعية K لكل وكيل. في كل خطوة زمنية ، يختار الوكيل عشوائيًا إحدى السياسات الفرعية لتحديد إجراء. ثم يفعل ذلك.
التدرج في السياسة يتغير قليلا. نحن نأخذ المتوسط فوق السياسة الفرعية K ، ونستخدم خط الانتظار المنتظر ، وننشر التحديثات باستخدام وظيفة Q-value.
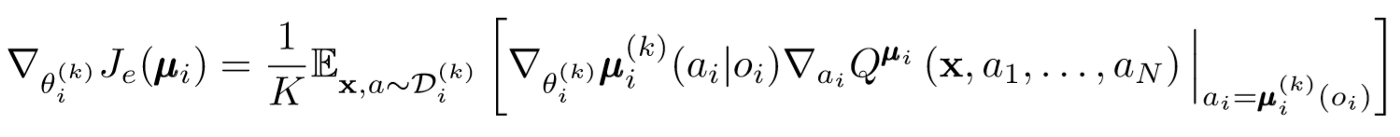
لنأخذ خطوة إلى الوراء
هذه هي الطريقة التي تبدو بها الخوارزمية بأكملها بعبارات عامة. الآن نحن بحاجة إلى العودة وإدراك ما فعلناه بالضبط وفهم سبب نجاحه بشكل حدسي. بشكل أساسي ، قمنا بما يلي:
- تم تحديد الفاعلين للوكلاء الذين يستخدمون الملاحظات المحلية فقط. بهذه الطريقة ، يمكن التحكم في التأثيرات السلبية لزيادة مساحات الدولة والعمل بشكل كبير.
- حدد ناقدًا مركزيًا لكل وكيل يستخدم المعلومات المشتركة. لذلك تمكنا من تقليل تأثير اللاستقلالية وساعدنا الممثل على أن يصبح الأمثل للنظام العالمي.
- شبكات استنتاجات محددة من سياسات تقييم سياسات وكلاء آخرين. وبهذه الطريقة ، تمكنا من الحد من الترابط بين العملاء وإلغاء الحاجة إلى وكلاء للحصول على معلومات مثالية.
- تم تحديد مجموعات السياسات للحد من تأثير وإمكانية إعادة التدريب على سياسات وكلاء آخرين.
يخدم كل مكون من مكونات الخوارزمية غرضًا محددًا ومميزًا. إن خوارزمية MADDPG قوية بسبب ما يلي: تم تصميم مكوناتها خصيصًا للتغلب على العقبات الخطيرة التي تواجه عادةً الأنظمة متعددة الوكلاء. بعد ذلك ، سنتحدث عن أداء الخوارزمية.
النتائج
تم اختبار MADDPG في العديد من البيئات. يمكن الاطلاع على نظرة عامة كاملة عن عمله في المقالة [1]. هنا سنتحدث فقط عن مهمة الاتصال التعاوني.
نظرة عامة على البيئة
هناك عاملان: المتكلم والمستمع. عند كل تكرار ، يستمع المستمع إلى نقطة ملونة على الخريطة للانتقال إليه ويستلم مكافأة تتناسب مع المسافة إلى تلك النقطة. لكن ها هو الصيد: المستمع يعرف فقط موقعه ولون نقاط النهاية. لا يعرف النقطة التي يجب أن ينتقل إليها. ومع ذلك ، يعرف المتحدث لون النقطة المطلوبة للتكرار الحالي. نتيجة لذلك ، يجب أن يتفاعل عاملان لحل هذه المشكلة.
مقارنة
لحل هذه المشكلة ، تناقض المقالة MADDPG والأساليب الحديثة أحادية العامل. ينظر إلى تحسينات كبيرة باستخدام MADDPG.
كما تبين أن الاستنتاجات من السياسات ، حتى لو لم يكن السياسيون مدربين بشكل مثالي ، حققت نفس النتائج التي يمكن تحقيقها باستخدام الملاحظة الحقيقية. علاوة على ذلك ، لم يكن هناك تباطؤ كبير في التقارب.
وأخيرًا ، أظهرت مجموعات السياسات نتائج واعدة للغاية. تستكشف الورقة [1] تأثير المجموعات في بيئة تنافسية وتوضح تحسينات كبيرة في الأداء على وكلاء السياسة الفردية.
خاتمة
هذا كل شئ. نظرنا هنا إلى نهج جديد لتعزيز التعلم متعدد الوكلاء. بالطبع ، هناك عدد لا حصر له من الطرق المتعلقة بـ MARL ، لكن MADDPG يوفر أساسًا متينًا للطرق التي تحل معظم المشاكل العالمية للأنظمة متعددة العوامل.
المصادر
[1] R. Lowe، Y. Wu، A. Tamar، J. Harb، P. Abbeel، I. Mordatch، Multi-Agent Actor-Critic For بيئة تعاونية-تنافسية مختلطة (2018).
قائمة المقالات المفيدة
- 3 مطبات لعلماء البيانات الطموحين
- خوارزمية AdaBoost
- كيف كان 2019 في الرياضيات وعلوم الكمبيوتر
- يواجه التعلم الآلي مشكلة في الرياضيات لم يتم حلها
- فهم نظرية بايز
- ابحث عن ملامح الوجه في جزء من الثانية باستخدام مجموعة من أشجار الانحدار
, , , . .