
هناك العديد من الطرق لبناء كود التطبيق لمنع تعقيد المشروع من النمو بمرور الوقت. على سبيل المثال ، يسمح النهج الموجه للكائنات والعديد من الأنماط المرفقة ، إذا لم يتم الحفاظ على تعقيد المشروع على نفس المستوى ، فعلى الأقل إبقائه تحت السيطرة أثناء التطوير ، وإتاحة الكود للمبرمج الجديد في الفريق.
كيف يمكنك إدارة تعقيد مشروع تحويل ETL على Spark؟
انها ليست بهذه البساطة.
كيف تبدو في الحياة الحقيقية؟ يعرض العميل إنشاء تطبيق يجمع واجهة عرض. يبدو أنه من الضروري تنفيذ التعليمات البرمجية من خلال Spark SQL وحفظ النتيجة. أثناء التطوير ، اتضح أن بناء هذا السوق يتطلب 20 مصدر بيانات ، منها 15 متشابهة والبقية ليست كذلك. يجب الجمع بين هذه المصادر. ثم اتضح أنه بالنسبة لنصفهم ، تحتاج إلى كتابة إجراءات التجميع والتنظيف والتطبيع الخاصة بك.
ويبدأ العرض البسيط ، بعد الوصف التفصيلي ، في الظهور على
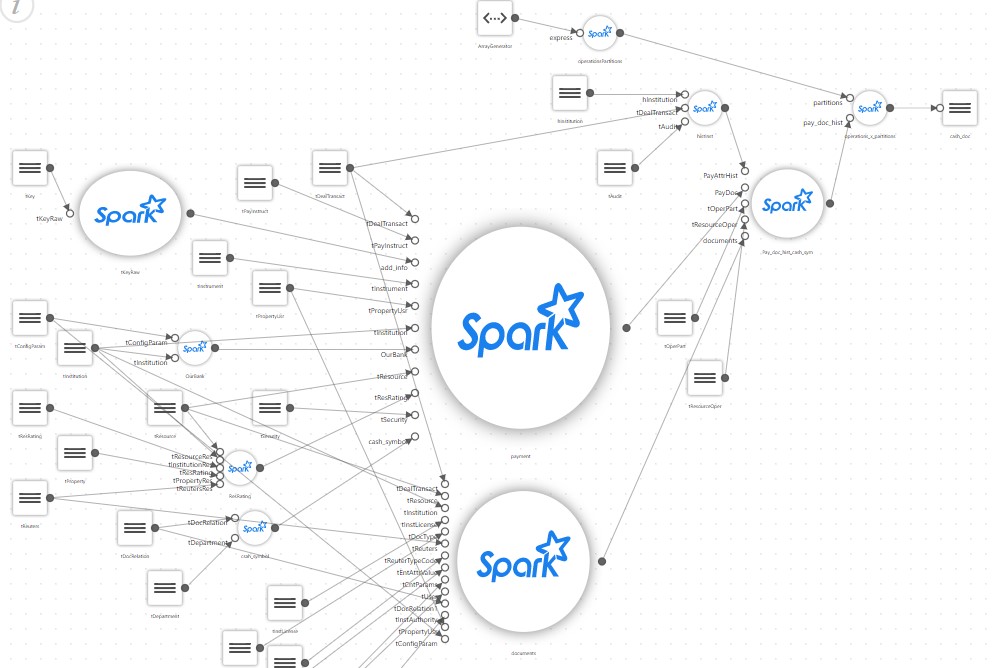
النحو التالي : ونتيجة لذلك ، فإن مشروعًا بسيطًا كان يجب أن يشغِّل نصًا برمجيًا SQL يجمع العرض على Spark يكتسب مُكوِّنًا خاصًا به ، وهو كتلة لقراءة عدد كبير من ملفات التكوين ، وفرع الخرائط الخاص به ، والمترجمين لبعض القواعد الخاصة إلخ
بحلول منتصف المشروع ، اتضح أن المؤلف فقط يمكنه دعم الكود الناتج. ويقضي معظم وقته في التفكير. في غضون ذلك ، يطلب العميل جمع المزيد من واجهات العرض ، مرة أخرى بناءً على مئات المصادر. في الوقت نفسه ، يجب أن نتذكر أن Spark بشكل عام ليست مناسبة جدًا لإنشاء أطر العمل الخاصة بك.
على سبيل المثال ، تم تصميم Spark لجعل الكود يبدو مثل هذا (pseudocode):
park.sql(“select table1.field1 from table1, table2 where table1.id = table2.id”).write(...pathToDestTable)
بدلاً من ذلك ، عليك أن تفعل شيئًا كالتالي:
var Source1 = readSourceProps(“source1”) var sql = readSQL(“destTable”) writeSparkData(source1, sql)
بمعنى ، إخراج كتل من التعليمات البرمجية إلى إجراءات منفصلة ومحاولة كتابة شيء خاص بك ، عالمي ، يمكن تخصيصه بواسطة الإعدادات.
في الوقت نفسه ، يظل تعقيد المشروع على نفس المستوى بالطبع ، ولكن فقط لمؤلف المشروع ، ولفترة قصيرة فقط. سيستغرق أي مبرمج تمت دعوته وقتًا طويلاً لإتقانه ، والشيء الرئيسي هو أنه لن ينجح في جذب الأشخاص الذين يعرفون SQL فقط إلى المشروع.
هذا أمر مؤسف ، لأن Spark نفسها هي طريقة رائعة لتطوير تطبيقات ETL لأولئك الذين يعرفون SQL فقط.
وأثناء تطوير المشروع ، اتضح أن الشيء البسيط تحول إلى شيء معقد.
تخيل الآن مشروعًا حقيقيًا ، حيث يوجد العشرات ، أو حتى المئات ، من واجهات المحلات كما في الصورة ، ويستخدمون تقنيات مختلفة ، على سبيل المثال ، يمكن أن يعتمد بعضها على تحليل بيانات XML ، والبعض الآخر على تدفق البيانات.
أود بطريقة أو بأخرى الحفاظ على تعقيد المشروع عند مستوى مقبول. كيف يمكن القيام بذلك؟
قد يكون الحل هو استخدام أداة ونهج منخفض الكود ، عندما تقرر بيئة التطوير لك ، الأمر الذي يأخذ كل التعقيدات ، ويقدم نهجًا مناسبًا ، كما هو موضح ، على سبيل المثال ، في هذه المقالة .
توضح هذه المقالة مناهج وفوائد استخدام الأداة لحل هذه الأنواع من المشكلات. على وجه الخصوص ، تقدم Neoflex الحل الخاص بها Neoflex Datagram، والتي يتم استخدامها بنجاح من قبل عملاء مختلفين.
لكن ليس من الممكن دائمًا استخدام مثل هذا التطبيق.
ماذا أفعل؟
في هذه الحالة ، نستخدم أسلوبًا يُسمى تقليديًا Orc - Object Spark أو Orka ، كما تريد.
البيانات الأولية هي كما يلي:
هناك عميل يوفر مكان عمل حيث توجد مجموعة قياسية من الأدوات ، وهي: Hue لتطوير Python أو Scala code ، ومحررات Hue لتصحيح أخطاء SQL من خلال Hive أو Impala ، وأيضًا محرر سير العمل Oozie. هذا ليس كثيرًا ، ولكنه كافٍ تمامًا لحل المشكلات. من المستحيل إضافة شيء ما إلى البيئة ، من المستحيل تثبيت أي أدوات جديدة ، لأسباب مختلفة.
إذن كيف يمكنك تطوير تطبيقات ETL التي ، كالعادة ، ستنمو لتصبح مشروعًا كبيرًا ، حيث ستشارك المئات من جداول مصادر البيانات وعشرات الأسواق المستهدفة ، دون الغرق في التعقيد وعدم الكتابة كثيرًا؟
يتم استخدام عدد من الأحكام لحل المشكلة. إنهم ليسوا اختراعهم الخاص ، لكنهم يعتمدون بالكامل على بنية Spark نفسها.
- تتم جميع عمليات الوصل والحسابات والتحويلات المعقدة من خلال Spark SQL. يتحسن مُحسِّن Spark SQL مع كل إصدار ويعمل بشكل جيد للغاية. لذلك ، نعطي كل عمل حساب Spark SQL للمحسن. أي أن الكود الخاص بنا يعتمد على سلسلة SQL ، حيث تقوم الخطوة 1 بإعداد البيانات ، والخطوة 2 تنضم ، والخطوة 3 تحسب ، وهكذا.
- Spark, Spark SQL. (DataFrame) Spark SQL.
- Spark Directed Acicled Graph, , , , , 2, 2.
- Spark lazy, , , .
نتيجة لذلك ، يمكن جعل التطبيق بأكمله بسيطًا جدًا.
يكفي إنشاء ملف تكوين يتم فيه تحديد قائمة ذات مستوى واحد لمصادر البيانات. هذه القائمة المتسلسلة لمصادر البيانات هي الكائن الذي يصف منطق التطبيق بأكمله.
يحتوي كل مصدر بيانات على ارتباط إلى SQL. في SQL ، بالنسبة للمصدر الحالي ، يمكنك استخدام مصدر غير موجود في Hive ، ولكن تم وصفه في ملف التوصيف أعلى الملف الحالي.
على سبيل المثال ، المصدر 2 ، إذا تمت ترجمته إلى كود Spark ، فسيبدو شيئًا مثل هذا (الرمز الزائف):
var df = spark.sql(“select * from t1”); df.saveAsTempTable(“source2”);
وقد يبدو المصدر 3 بالفعل كما يلي:
var df = spark.sql(“select count(*) from source2”) df.saveAsTempTable(“source3”);
أي أن المصدر 3 يرى كل ما تم حسابه قبله.
وبالنسبة لتلك المصادر التي تعد واجهات عرض مستهدفة ، يجب عليك تحديد المعلمات لحفظ واجهة العرض المستهدفة هذه.
نتيجة لذلك ، يبدو ملف تكوين التطبيق كما يلي:
[{name: “source1”, sql: “select * from t1”}, {name: “source2”, sql: “select count(*) from source1”}, ... {name: “targetShowCase1”, sql: “...”, target: True, format: “PARQET”, path: “...”}]
ويظهر رمز التطبيق على النحو التالي:
List = readCfg(...) For each source in List: df = spark.sql(source.sql).saveAsTempTable(source.name) If(source.target == true) { df.write(“format”, source.format).save(source.path) }
هذا هو ، في الواقع ، التطبيق بأكمله. لا شيء آخر مطلوب سوى لحظة واحدة.
كيف يتم تصحيح كل هذا؟
بعد كل شيء ، الكود نفسه في هذه الحالة بسيط للغاية ، ما هو موجود لتصحيحه ، لكن منطق ما يتم فعله سيكون من الجيد التحقق منه. تصحيح الأخطاء بسيط للغاية - يجب أن تمر عبر جميع التطبيقات إلى المصدر الذي يتم التحقق منه. للقيام بذلك ، أضف معلمة إلى سير عمل Oozie تتيح لك إيقاف التطبيق عند مصدر البيانات المطلوب عن طريق طباعة مخططه ومحتوياته إلى السجل.
لقد أطلقنا على هذا النهج Object Spark بمعنى أن منطق التطبيق مفصول عن كود Spark وتخزينه في ملف تكوين واحد بسيط إلى حد ما ، وهو كائن وصف التطبيق.
يظل الرمز بسيطًا ، وبمجرد إنشائه ، يمكن تطوير واجهات المحلات المعقدة باستخدام المبرمجين الذين يعرفون لغة SQL فقط.
عملية التطوير بسيطة للغاية. في البداية ، يشارك مبرمج Spark ذو خبرة ، والذي يقوم بإنشاء كود عالمي ، ثم يتم تحرير ملف تكوين التطبيق عن طريق إضافة مصادر جديدة هناك.
ما يعطي هذا النهج:
- يمكنك إشراك مبرمجي SQL في التطوير ؛
- بالنظر إلى المعلمة في Oozie ، يصبح تصحيح أخطاء مثل هذا التطبيق أمرًا سهلاً وبسيطًا. هذا هو تصحيح أي خطوة وسيطة. سيعمل التطبيق على كل شيء إلى المصدر المطلوب ويحسبه ويتوقف ؛
- ( … ), , , , , . , Object Spark;
- , . . , , , XML JSON, -. , ;
- . , , , , .