
اليوم سنتحدث عن موضوع يبدو بسيطًا مثل البيانات العلائقية والبيانات ذات الصلة.
على الرغم من بساطته ، إلا أنني لاحظت أنه في بعض الأحيان يشعر الناس بالارتباك حيالهم - قررت إصلاح ذلك من خلال كتابة شرح قصير وغير رسمي لما هم عليه ولماذا هناك حاجة إليه.
سنناقش ماهية النموذج العلائقي وجبر SQL والجبر العلائقي ذي الصلة. ثم ننتقل إلى أمثلة البيانات ذات الصلة من Wikidat ، ثم RDF و SPARQL ونقاش بسيط حول Datalog وتمثيل البيانات المنطقية. في النهاية ، الاستنتاجات - متى يتم تطبيق النموذج العلائقي ، وعندما يكون منطقيًا متماسكًا.
الغرض الرئيسي من المنشور هو وصف متى يكون من المنطقي التقديم ولماذا. نظرًا لوجود العديد من المفاهيم الصعبة التي تم تجميعها في مكان واحد ، سيكون من الممكن بالطبع كتابة كتاب لكل منها - ولكن مهمتنا اليوم هي إعطاء فكرة عن الموضوع وسنقوم بتحليله بشكل غير رسمي باستخدام أمثلة بسيطة.
إذا كانت لديك شكوك حول كيفية اختلاف أحدهما عن الثانية ولماذا تحتاج إلى بيانات مرتبطة (LinkedData) على الإطلاق ، فمرحبًا بك ضمن cat.

البيانات العلائقية
لنبدأ بتعريف موحد:
قاعدة البيانات العلائقية هي مجموعة من البيانات ذات علاقات محددة مسبقًا فيما بينها. يتم تنظيم هذه البيانات كمجموعة من الجداول تتكون من أعمدة وصفوف. تخزن الجداول معلومات حول الكائنات الممثلة في قاعدة البيانات.
عند التطبيق:
- نمذجة المجال الثابت
- يتغير مخطط البيانات بشكل طفيف أو تؤثر التغييرات على مجموعة كبيرة من السجلات على الفور
- الاستعلامات الأساسية - تصفية الفئات حسب الحقول الرئيسية للسجلات ، والتجميع ، وإنشاء التقارير والتحليلات بناءً على المؤشرات الإحصائية ، إلخ.
في هذه الحالة ، تكون وحدة النمذجة هي الجدول والعلاقات بين الجداول (مثل المفاتيح الخارجية). في الواقع ، يعد الجدول مسندًا بسمات ثابتة ، أي نحن نعلم دائمًا مدى صحة المسند الجدولي.
لنأخذ مفتاحًا خارجيًا كمثال على علاقات القيد: المفتاح "p (_ ، X ، _) → q (_ ، Y ، _)" ، الذي يضع قيودًا في النموذج X \ المجموعة الفرعية Y ، حيث X هي سمة من علاقة p ، و Y سمة العلاقة q.

الأهم من ذلك ، في عالم البيانات العلائقية ، لدينا كل شيء على شكل جدول! والعمليات تأخذ الجدول كمدخلات وترجع الجدول ، على سبيل المثال:

لغة البيانات العلائقية: SQL والجبر العلائقي
الجبر العلائقي (Codd algebra) هو في الأساس مجموعة من العمليات على الجداول التي تُرجع الجداول. هذا هو ، بالنسبة لك ، العنصر المركزي للنمذجة هو بالتحديد الجداول الثابتة وتحولاتها.
لغة SQL هي بنية فوقية توضيحية وتنفيذ ملموس لأفكار الجبر العلائقي.
مثال على استعلام بسيط والعوامل العلائقية المقابلة من الجبر.

حتى الآن ، كل ما قمنا بتغطيته هو الأشياء الكلاسيكية التي نعرفها من أي دورة تدريبية في قاعدة البيانات.
البيانات المرتبطة والرسوم البيانية المعرفية
دعنا نتخيل فقط ماذا سيحدث إذا كانت لدينا خصائص جديدة وهذا يحدث ، ربما في الوقت الفعلي؟ أي أن المجال ليس ثابتًا - ولكنه مرن وقابل للتوسيع ؟
في مثل هذه الحالة ، بالطبع ، يمكننا إضافة جداول وأعمدة إلى الجداول عن طريق إدخال قيم فارغة أو قيم افتراضية. ولكن بالإضافة إلى كونها غير مريحة من الناحية الفنية ، فهي أيضًا أداة غير مناسبة من وجهة نظر النمذجة.
تخيل أنك تجسد حياة الناس من جميع جوانبها الممكنة. حتى شخصان مختلفان سيكون لهما مجموعة مختلفة من الخصائص الرئيسية ، وهذا أمر طبيعي تمامًا!
ليس لديك قائمة ثابتة بكيفية وصف شخصية معينة ، فالكاتب ولاعب كرة القدم شخصان لهما العديد من الخصائص المهمة ، ولكن مع ذلك ، مختلفة.
لنبدأ بالكاتب دوغلاس آدامز - الخصائص الأعلى نموذجية جدًا لأي شخص - هنا وفي الأسفل نستخدم ويكي بيانات كمثال على LinkedData.
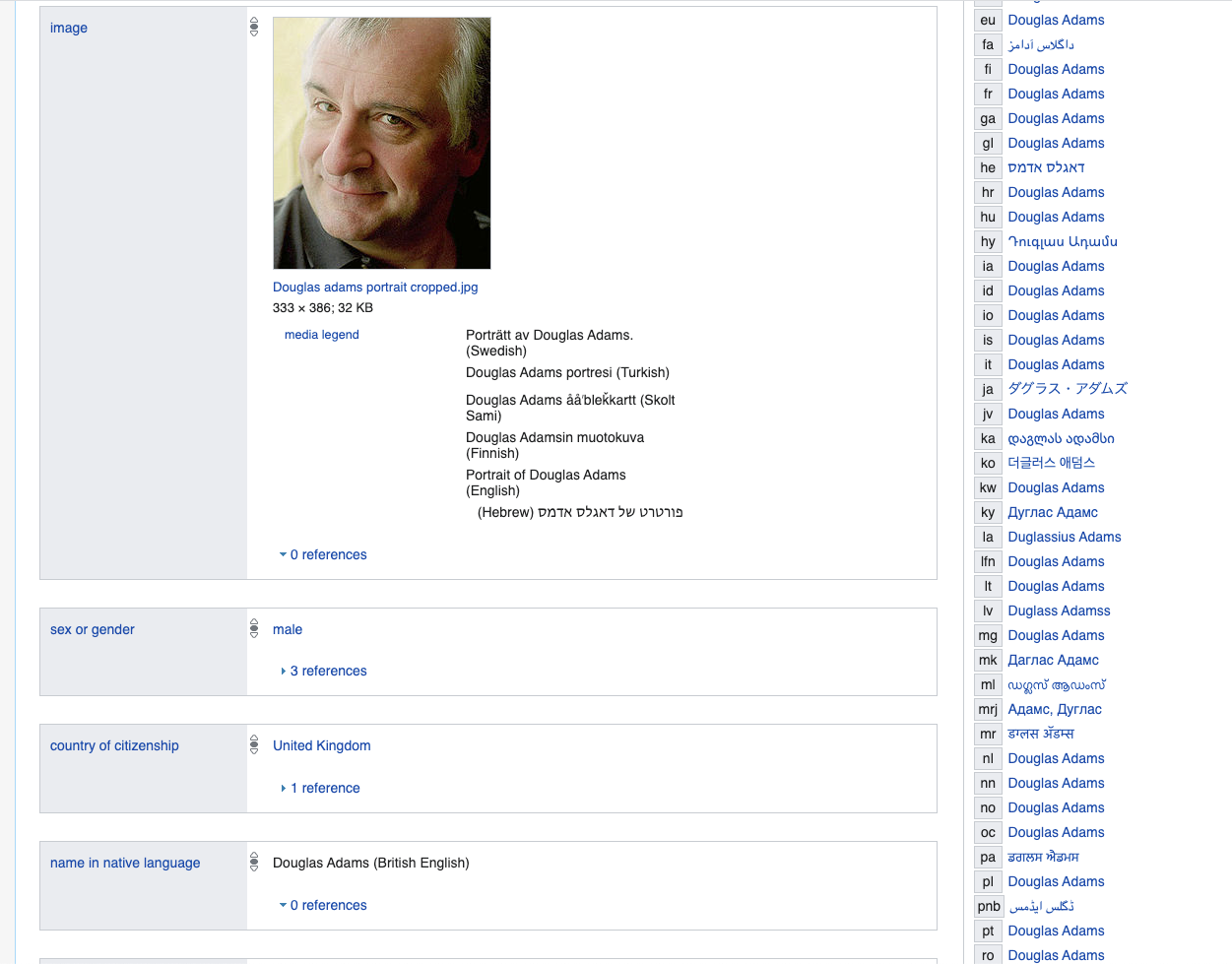
www.wikidata.org/wiki/Q42
لكن دعنا نتعمق أكثر قليلاً
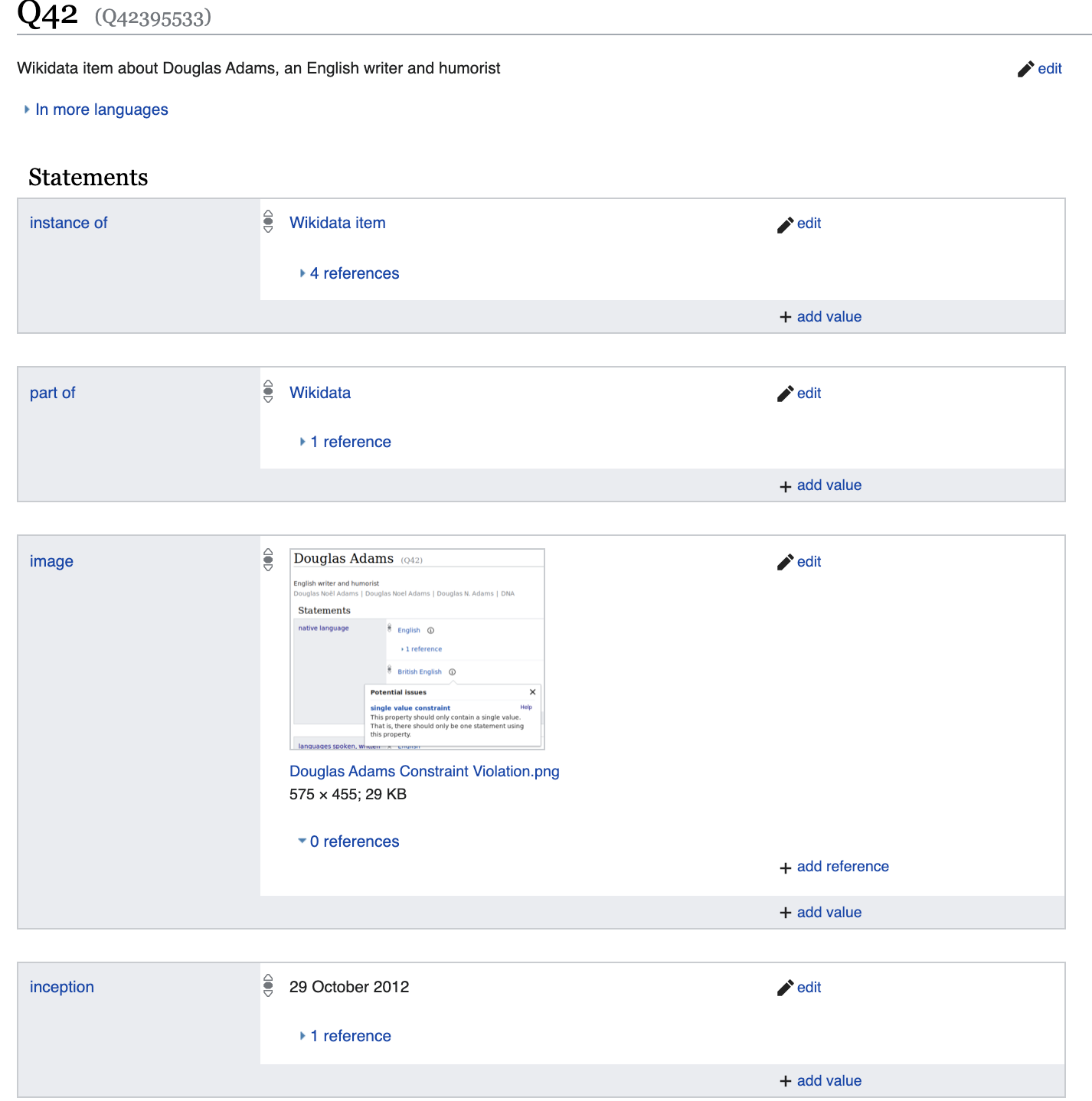
ونرى مجموعة من الخصائص التي ستختلف بشكل كبير ، على سبيل المثال ، دييغو مارادونا
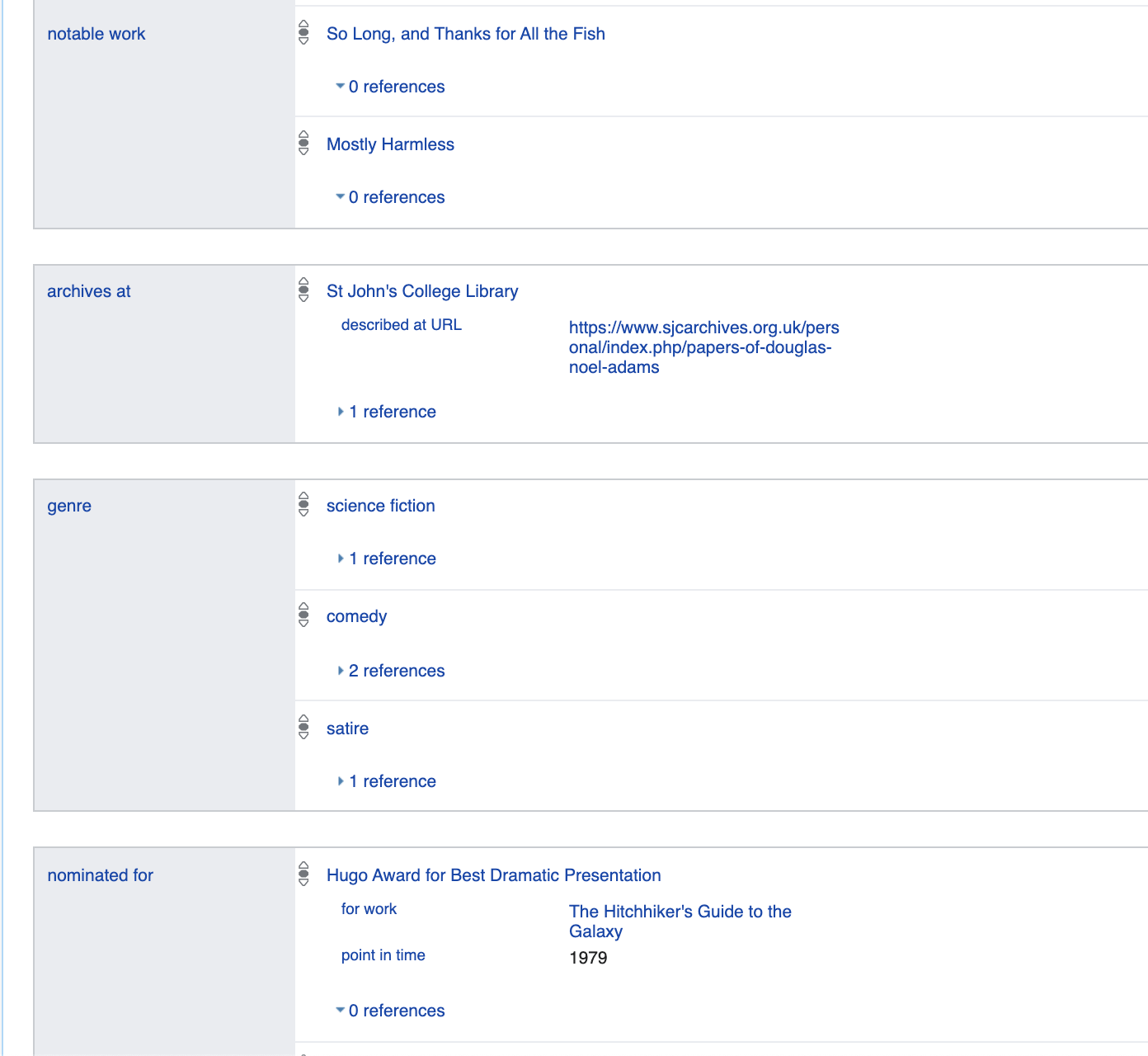
. على سبيل المثال ، الجنس: الذكر هو في

الأساس انعكاس للحقيقة المنطقية: ص 21 (س 42 ، س 6581097).
حيث p21 → هذا هو Gender_identity / 2 - مسند ثنائي
Q42 → Douglas Adams
Q6581097 → ذكر
وهكذا ، يتم تقديم جميع البيانات إما كمسندات أحادية ، على سبيل المثال is_dead (Q42) ، أو كـ ثنائي p21 (Q42، Q6581097)
في الواقع ، هذا نموذج آخر لنموذج النمذجة - منطق الترتيب الأول ، ولكن على المسندات أحادية وثنائية.
وهنا من السهل جدًا إضافة بيانات جديدة: كل ما لم تتم الإشارة إليه في شكل مسند على الأشياء خاطئ ، وهذا ما يُعرف في الأدبيات باسم افتراض العالم المغلق .
علاوة على ذلك ، يسمح هذا التنسيق بنمذجة وصفية طبيعية تمامًا
https://www.wikidata.org/wiki/Q42395533
هناك العديد من الاستفسارات الأساسية للتخزين والكتابة لهذه البيانات - دعنا نلقي نظرة على الخيارات الشائعة.
RDF ولغة SPARQL Query
RDF هي لغة رسمية لوصف البيانات ذات الصلة لمعالجة الاستعلام اللاحقة ، أي أنها تنسيق يمكن قراءته آليًا.
في الواقع ، بالنسبة له ، المفتاح هو مفهوم الثلاثي:

وهنا مثال على تسجيل البيانات في هذا النموذج (تحدد البادئات مكان تكمن "أوصاف" هذه المسندات)

يتيح لك تنسيق التسجيل هذا تمثيل البيانات المتعلقة بالأشياء بيانياً - على سبيل المثال ، يمكنك كتابة معلومات حول مدينة برلين.

بالنسبة إلى تنسيق RDF ، قاموا بإنشاء لغة استعلام SPARQL: والتي تصف بشكل أساسي القيود المفروضة على المسندات المنطقية وتحدد المتغير الذي يجب استخراجه من التعبير المنطقي:

ما نريد العثور عليه في الواقع هو قيمة المتغير؟ البلد ، مثل أن يكون member_of صحيحًا بالنسبة إلى member_of (؟ Country ، q458) و q458 هو معرف الاتحاد الأوروبي.
في الكود الحقيقي ، قد يبدو كالتالي:
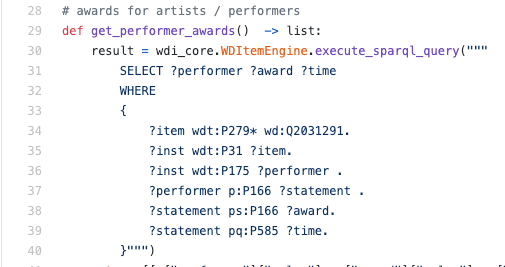
المجموع: RDF هو تنسيق لتمثيل البيانات في شكل ثلاثيات (المسندات الثنائية) وسباركل هي لغة استعلام منطقية لثلاثيات.
لغة استعلام Datalog ومشتقاتها
أيضًا ، لكتابة استعلامات إلى RDF (وليس فقط لها ، المزيد عن ذلك لاحقًا) ، يمكنك استخدام Datalog - لغة تعريفية (غالبًا) تمثل مجموعة فرعية من Prolog (غالبًا).
في ذلك ، تبدو الاستعلامات
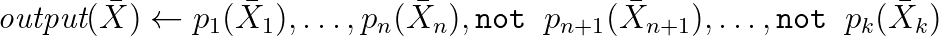
على النحو التالي : غالبًا ما يتم توسيع بناء الجملة بمساعدة المجموعات والأشياء الأخرى المهمة عمليًا. في الواقع ، هذه قواعد استنتاج مأخوذة من المنطق ، وبمساعدتهم يمكنك نمذجة استدلال الخصائص الجديدة وكتابة استعلامات إلى RDF. ما يلي هو مثال حقيقي للعمل مع WikiData بناءً على إحدى اللهجات

ميزة أخرى مهمة للغات الاستعلام المنطقية القائمة على Datalog هي أن RDF بالنسبة لهم هو مجرد تنسيق لتسجيل الحقائق (البيانات) للمنطق الثنائي. يمكنهم أيضًا التعامل مع أي تأكيد منطقي آخر - وليس بالضرورة ثنائيًا.
الاستنتاجات
أولاً ، البيانات العلائقية مناسبة تمامًا لنمذجة المجالات الثابتة ، حيث يتغير المخطط بشكل غير متكرر أو التغييرات لا تتعلق فقط بسجلات فردية ، ولكن بمقاطع كاملة.
ثانيًا ، اللغات العلائقية مناسبة تمامًا لمهام النمذجة حيث تحتاج إلى استخراج الجداول الفرعية وتحويل ودمج الجداول الموجودة - هذه ليست أداة مثالية عندما يذهب جزء كبير من العمل إلى مستوى التعديل و / أو الاستدلال على سجل معين.
ثالثًا ، إذا كان مجال النمذجة مجالًا شاملاً ، وحتى متغيرًا ، حيث حتى سجلات نفس الفئة مختلفة بشكل لافت للنظر ، فإن البيانات المتماسكة تكون مناسبة تمامًا.
رابعًا ، التمثيل القياسي هو RDF ومن المنطقي تجربته أولاً. من خلال ربط قواعد البيانات اللازمة به واستخدام لغات تشبه لغة SPARQ ، يمكنك استخراج البيانات اللازمة.
خامسًا ، إذا أصبحت النمذجة باستخدام التوائم الثلاثية مرهقة ومربكة ، يمكنك اعتبار التمثيل المنطقي للبيانات وكتالوج البيانات كلغة استعلام.

