CREATE TABLE task AS
SELECT
id
, (random() * 100)::integer person -- 100
, least(trunc(-ln(random()) / ln(2)), 10)::integer priority -- 2
FROM
generate_series(1, 1e5) id; -- 100K
CREATE INDEX ON task(person, priority);
تتحول الكلمة "is" في SQL إلى
EXISTS
- إليك أبسط نسخة ولنبدأ:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

كل صور الخطط قابلة للنقر
حتى الآن ، كل شيء يبدو جيدًا ، لكن ...
EXISTS + IN
.. ثم جاءوا إلينا وطلبوا ألا يقتصر الأمر على
priority = 10
8 و 9 على أنهم "ممتازون" :
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority IN (10, 9, 8)
);

قرأوا 1.5 مرة أكثر ، وأثرت أيضًا على وقت التنفيذ.
أو + EXISTS
دعنا نحاول استخدام معرفتنا أنه
priority = 8
من المرجح أن تتوافق مع رقم قياسي بأكثر من 10:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

لاحظ أن PostgreSQL 12 ذكي بالفعل بما يكفي لإجراء
EXISTS
استعلامات فرعية لاحقة فقط لتلك "التي لم يتم العثور عليها" من قبل الاستعلامات السابقة بعد 100 بحث عن القيمة 8 - 13 فقط للقيمة 9 و 4 فقط للقيمة 10.
حالة + EXISTS + ...
في الإصدارات السابقة ، يمكن تحقيق نتيجة مماثلة من خلال "الإخفاء تحت CASE" في الاستعلامات التالية:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) THEN TRUE
ELSE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) THEN TRUE
ELSE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
)
END
END;
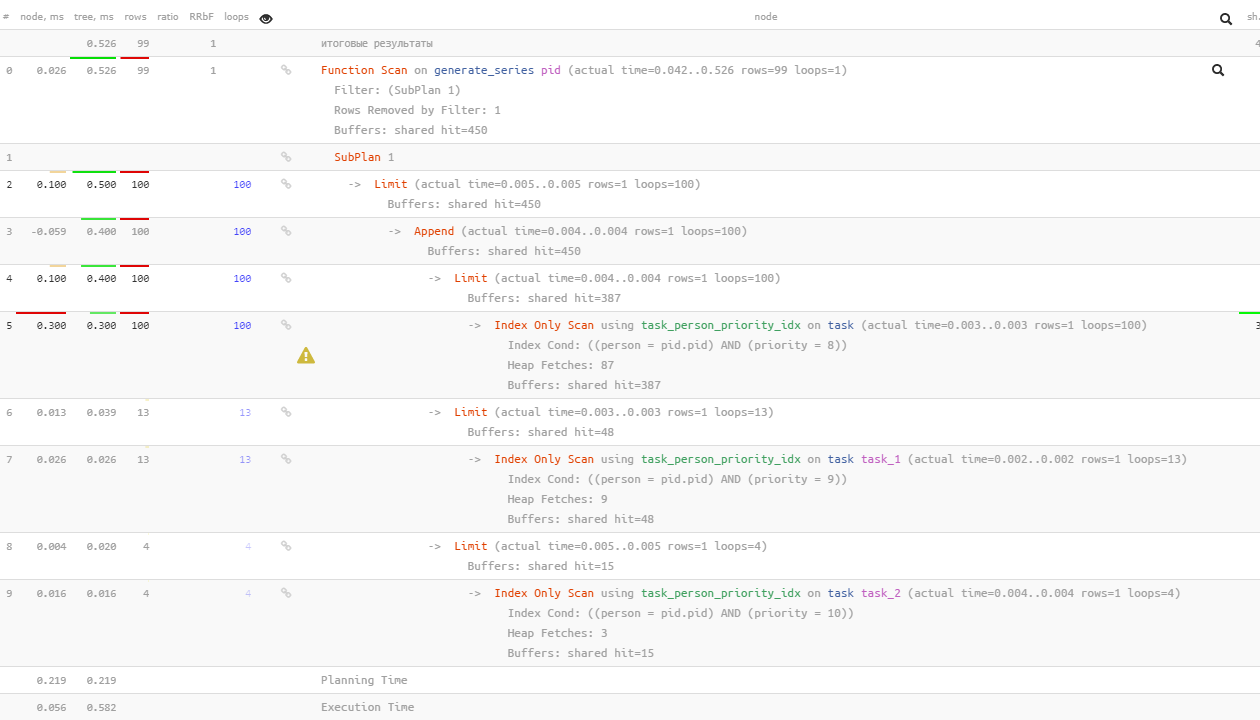
EXISTS + الاتحاد الكل + الحد
نفس الشيء ، ولكن يمكنك الحصول على أسرع قليلاً إذا استخدمت "الاختراق"
UNION ALL + LIMIT
:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
LIMIT 1
)
LIMIT 1
);
الفهارس الصحيحة هي مفتاح سلامة قاعدة البيانات
لننظر الآن إلى المشكلة من جانب مختلف تمامًا. إذا علمنا على وجه اليقين أن
task
عدد السجلات التي نريد العثور عليها أقل بعدة مرات من الباقي ، فسننشئ فهرسًا جزئيًا مناسبًا. في الوقت نفسه ، دعنا ننتقل مباشرة من تعداد "النقطة"
8, 9, 10
إلى
>= 8
:
CREATE INDEX ON task(person) WHERE priority >= 8;
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority >= 8
);

كان علي أن أقرأ مرتين أسرع و 1.5 مرة أقل!
لكن ، على الأرجح ، لطرح كل العناصر المناسبة دفعة
task
واحدة - هل سيكون أسرع؟ ..
SELECT DISTINCT
person
FROM
task
WHERE
priority >= 8;

بعيدًا عن ذلك دائمًا ، وبالتأكيد ليس في هذه الحالة - لأنه بدلاً من قراءة 100 من التسجيلات الأولى المتاحة ، علينا قراءة أكثر من 400!
ولكي لا تخمن أي خيارات الاستعلام ستكون أكثر فاعلية ، ولمعرفتها بثقة - استخدم expl.tensor.ru .