
يمكن اعتبار هذا المنشور بمثابة إعادة صياغة لمواد الاستعادة من خلال التعلم العميق لأصدقائي أو المبتدئين. لقد كتبت أكثر من 10 منشورات تتعلق بأساليب استعادة الصور باستخدام التعلم العميق. حان الوقت الآن لإلقاء نظرة عامة سريعة على ما تعلمه قراء هذه المقالات ، وكذلك لكتابة مقدمة سريعة للمبتدئين الذين يرغبون في الاستمتاع معنا.
المصطلح

الشكل: 1. مثال على صورة إدخال تالفة (على اليسار) ونتيجة استعادة (على اليمين). صورة مأخوذة من صفحة Github للمؤلف يحدد
الإدخال التالف الموضح في الشكل 1 عادةً: أ) وحدات بكسل أو ثقوب غير صالحة أو مفقودة مثل وحدات البكسل الموجودة في المناطق المراد ملؤها ؛ ب) صحيح ، متبقي ، وحدات بكسل حقيقية يمكننا استخدامها لملء البيكسلات المفقودة. لاحظ أنه يمكننا أخذ وحدات البكسل الصحيحة وملء الفراغات المرتبطة بها.
المقدمة
أسهل طريقة لملء الأجزاء المفقودة هي النسخ واللصق. الفكرة الأساسية هي البحث أولاً للعثور على شرائح الصور الأكثر تشابهًا من وحدات البكسل المتبقية ، أو العثور عليها في مجموعة بيانات كبيرة بها ملايين الصور ، ثم إدخال الشرائح مباشرةً في الأجزاء المفقودة. ومع ذلك ، يمكن أن تستغرق خوارزمية البحث وقتًا طويلاً وتتضمن مقاييس قياس المسافة التي يتم إنشاؤها يدويًا. لا يزال تعميم الخوارزمية وكفاءتها بحاجة إلى التحسين.
من خلال مناهج التعلم العميق في عصر البيانات الضخمة ، لدينا مناهج تعتمد على البيانات لاستعادة التعلم العميق ، وباستخدام هذه الأساليب ، نقوم بإنشاء وحدات بكسل متساقطة مع تناسق جيد وتركيبات دقيقة. دعنا نلقي نظرة على 10 مناهج تعلم عميق معروفة لاستعادة الصورة. أنا متأكد من أنك تستطيع فهم المقالات الأخرى عندما تفهم هذه 10. فلنبدأ.
مشفر السياق (أول خوارزمية استعادة قائمة على GAN ، 2016)

الشكل: 2. معمارية شبكة المشفر السياقي (CE).
إن برنامج ترميز السياق (CE ، 2016) [1] هو أول تنفيذ لاستعادة قائمة على GAN. يغطي هذا العمل المفاهيم الأساسية المفيدة لمهام الاستعادة. يرتبط مفهوم "السياق" بفهم الصورة على هذا النحو ، وجوهر فكرة المشفر هو طبقات متصلة بالكامل بواسطة القنوات (تظهر الطبقة الوسطى من الشبكة في الشكل 2). على غرار الطبقة القياسية المتصلة بالكامل ، فإن النقطة الرئيسية هي أن جميع مواقع العناصر في الطبقة السابقة ستساهم في كل موقع عنصر في الطبقة الحالية. لذلك تتعلم الشبكة العلاقة بين جميع ترتيبات العناصر وتحصل على تمثيل دلالي أعمق للصورة بأكملها. يعتبر CE خطًا أساسيًا ، يمكنك قراءة المزيد عنه في رسالتي [ هنا ].
MSNPS ( )

. 3. ( CE) (VGG-19).
(MSNPS ، 2016) [3] يمكن اعتباره نسخة موسعة من CE [1]. استخدم مؤلفو هذه المقالة CE المعدلة للتنبؤ بالأجزاء المفقودة في صورة وشبكة نسيج لتزيين التنبؤ لتحسين جودة الأجزاء المفقودة من النموذج المملوء. فكرة شبكة النسيج مأخوذة من مهمة نقل النمط. أردنا تصميم وحدات البكسل الموجودة الأكثر تشابهًا مع وحدات البكسل التي تم إنشاؤها لتحسين تفاصيل النسيج المحلي. أود أن أقول إن هذا العمل هو نسخة مبكرة من هيكل شبكة من مرحلتين من الخشنة إلى الدقيقة. شبكة المحتوى الأولى (أي هنا CE) مسؤولة عن إعادة بناء / توقع الأجزاء المفقودة ، والشبكة الثانية (أي شبكة النسيج) مسؤولة عن تحسين الأجزاء المعبأة.
بالإضافة إلى خسارة إعادة بناء البكسل النموذجية (أي خسارة L1) وخسارة الخصومة القياسية ، يلعب مفهوم فقدان النسيج المقترح في هذه المقالة دورًا مهمًا في العمل اللاحق على استعادة الصورة. في الواقع ، يرتبط فقدان النسيج بفقدان الإدراك الحسي وفقدان الأسلوب ، والذي يستخدم على نطاق واسع في العديد من مهام إنشاء الصور مثل نقل النمط العصبي. لمعرفة المزيد حول هذه المقالة ، يمكنك الرجوع إلى رسالتي السابقة [ هنا ].
GLCIC (علامة فارقة في استعادة التعلم العميق ، 2017)
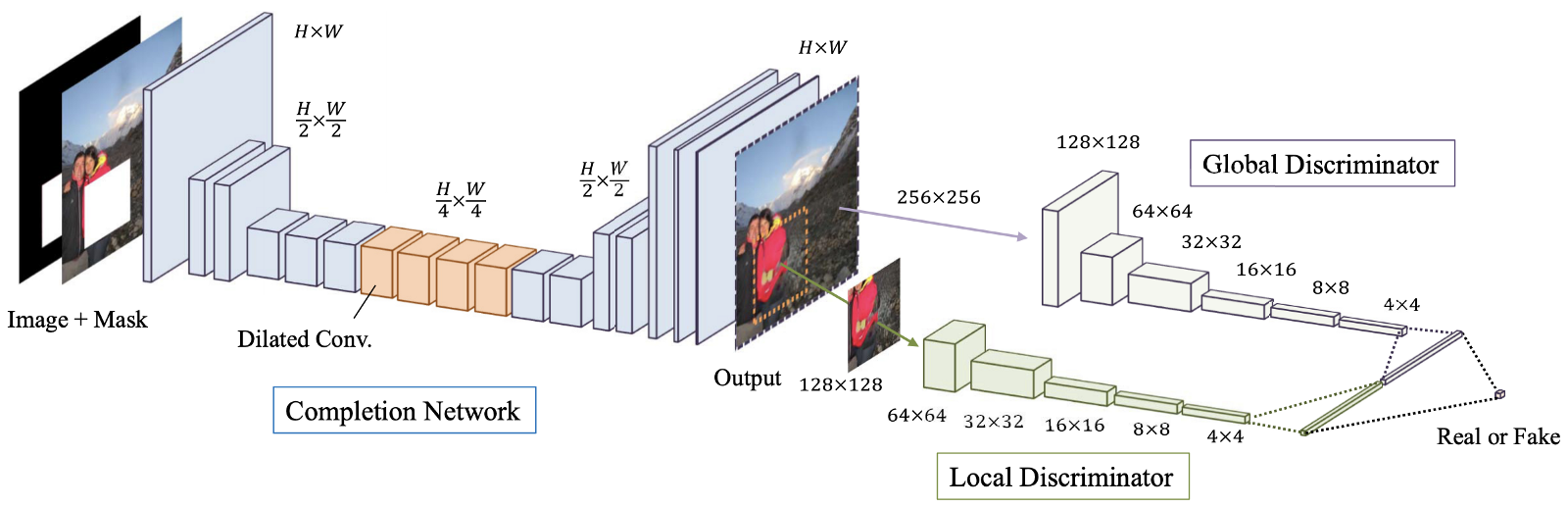
الشكل: 4. نظرة عامة على النموذج المقترح ، والذي يتكون من شبكة طرفية (شبكة "المولدات") ، بالإضافة إلى أدوات التمييز العالمية والمحلية.
يعد إكمال الصور المتسق عالميًا ومحليًا (GLCIC ، 2017) [4] علامة فارقة في استعادة صورة التعلم العميق حيث أنه يحدد شبكة تلافيفية ممتدة بالكامل لهذه المنطقة وهي في الواقع بنية شبكة نموذجية في استعادة الصور. باستخدام التلافيف المتقدمة ، تكون الشبكة قادرة على فهم سياق الصورة دون استخدام طبقات متصلة بالكامل باهظة الثمن ، وبالتالي يمكنها التعامل مع الصور ذات الأحجام المختلفة.
بالإضافة إلى الشبكة التلافيفية الكاملة ذات التلافيف الممتدة ، تم أيضًا تدريب اثنين من أدوات التمييز على مقياسين مع شبكة المولدات. ينظر المُميِّز العام إلى الصورة بأكملها ، بينما ينظر المُميِّز المحلي إلى منطقة المركز التي يتم ملؤها. مع كل من أدوات التمييز العالمية والمحلية ، تتمتع الصورة المملوءة باتساق عالمي ومحلي أفضل. لاحظ أن العديد من المقالات الحديثة حول استعادة الصورة تتبع تصميم المُميز متعدد النطاقات. إذا كنت مهتمًا ، يرجى قراءة رسالتي السابقة [ هنا ] لمزيد من المعلومات.
الاستعادة القائمة على تصحيح GAN (تباين GLCIC ، 2018)

الشكل: 5. هيكل ResNet التوليدي المقترح ومميز PGGAN. يمكن اعتبار
الاستعادة القائمة على التصحيح باستخدام GANs [5] متغيرًا من GLCIC [4]. ببساطة ، تم دمج مفهومين متقدمين ، التعلم المتبقي [6] و PatchGAN [7] ، في GLCIC لتحسين الأداء بشكل أكبر. قام مؤلفو هذه المقالة بدمج الصلة المتبقية والتفاف ممتد لتشكيل كتلة متبقية ممتدة. تم استبدال مميّز GAN التقليدي بمميز PatchGAN لتعزيز تفاصيل نسيج محلي أفضل واتساق هيكل عالمي.
يتمثل الاختلاف الرئيسي بين مميِّز GAN التقليدي ومميز PatchGAN في أن مميِّز GAN التقليدي يعطي تسمية تنبؤية واحدة فقط (0 إلى 1) للإشارة إلى واقعية إشارة الإدخال ، بينما يعطي مميِّز PatchGAN مصفوفة من العلامات (أيضًا من 0 إلى 1) ) للإشارة إلى واقعية كل منطقة محلية لإشارة الإدخال. لاحظ أن كل عنصر مصفوفة يمثل منطقة محلية للإدخال. يمكنك أيضًا الاطلاع على نظرة عامة على التعلم المتبقي و PatchGAN [من خلال زيارة هذا المنشور الخاص بي ].
Shift-Net (التعلم العميق النسخ واللصق ، 2018)

الشكل: 6. Shift-Net بنية الشبكة. تتم إضافة طبقة الانضمام المنزلقة بدقة 32 × 32. تستفيد
Shift-Net [8] من شبكات CNN الحديثة المستندة إلى البيانات وطريقة "النسخ واللصق" التقليدية لإعادة تقسيم العناصر باستخدام طبقة ربط التحويل المقترحة. هذه المقالة لديها فكرتان رئيسيتان.
أولاً ، اقترح المؤلفون فقدان المعلم الذي يتسبب في أن تكون العناصر التي تم فك تشفيرها للأجزاء المفقودة (بالنظر إلى الجزء المخفي من الصورة) قريبة من العناصر المشفرة للأجزاء المفقودة (نظرًا للحالة الجيدة للصورة). نتيجة لذلك ، يمكن لعملية فك التشفير أن تعوض الأجزاء المفقودة بتقديرها المعقول في الصورة في حالة جيدة (أي مصدر الحقيقة للأجزاء المفقودة).
ثانيًا ، تسمح طبقة الالتحام المقترحة للشبكة باستعارة المعلومات بكفاءة التي يوفرها أقرب جيرانها خارج الأجزاء المفقودة لتحسين البنية الدلالية العالمية وتفاصيل النسيج المحلي للأجزاء المولدة. ببساطة ، نحن نقدم روابط ذات صلة لتحسين تقييمنا. أعتقد أن القراء المهتمين باستعادة الصورة سيجدون أنه من المفيد دمج الأفكار المقترحة في هذه المقالة. أوصي بشدة بقراءة المنشور السابق [ هنا ] للحصول على التفاصيل.
DeepFill v1 (Breakthrough Image Restoration، 2018)

الشكل: 7. بنية الشبكة للإطار المقترح.
الاستعادة التوليدية مع الانتباه السياقي (CA، 2018) ، وتسمى أيضًا DeepFill v1 أو CA [9] ، يمكن اعتبارها نسخة موسعة أو متغير من Shift-Net [8] يطور المؤلفون فكرة النسخ واللصق ويقدمون طبقة من الانتباه السياقي قابلة للتفاضل والتلافيف تمامًا.
على غرار طبقة الانضمام إلى التحول في [8] ، من خلال مطابقة العناصر المولدة داخل وحدات البكسل المفقودة والخصائص خارج وحدات البكسل المفقودة ، يمكننا معرفة مساهمة جميع العناصر خارج وحدات البكسل المفقودة في كل موقع داخل وحدات البكسل المفقودة. لذلك ، يمكن استخدام مجموعة كل العناصر الموجودة بالخارج لتحسين العناصر المُنشأة داخل وحدات البكسل المفقودة. مقارنةً بطبقة الانضمام-القص ، التي تبحث فقط عن الميزات الأكثر تشابهًا (على سبيل المثال ، مهمة صعبة وغير قابلة للتفاضل) ، تستخدم طبقة المرجع المصدق (CA) في هذه المقالة مهمة ناعمة وقابلة للتفاضل ، حيث يكون لجميع الميزات أوزانها الخاصة للإشارة إلى مساهمتها في كل مكان داخل بكسل مفقود. لمعرفة المزيد حول الاهتمام بالسياق ، يرجى قراءة رسالتي السابقة [ هنا] ، ستجد هناك المزيد من الأمثلة المحددة.
GMCNN (شبكات CNN متعددة الأعمدة لاستعادة الصورة ، 2018)

الشكل: 8. بنية الشبكة المقترحة. تزيد
الشبكات العصبية التلافيفية التوليفية متعددة الأعمدة (GMCNN ، 2018) [10] من أهمية الحقول المستقبلة الكافية لاستعادة الصورة وتقدم وظائف فقدان جديدة لتحسين تفاصيل النسيج المحلي للمحتوى الذي تم إنشاؤه. كما هو موضح في الشكل 9 ، هناك ثلاثة فروع / أعمدة ويستخدم كل فرع ثلاثة أحجام مختلفة من المرشحات. يرجع استخدام العديد من الحقول المستقبلة (أحجام المرشحات) إلى حقيقة أن حجم المجال الاستقبالي مهم لمهمة استعادة الصورة. نظرًا لعدم وجود وحدات بكسل مجاورة محلية ، فمن الضروري استعارة المعلومات من مواقع بعيدة مكانيًا لملء وحدات البكسل المحلية المفقودة.
بالنسبة لوظائف الخسارة المقترحة ، فإن الفكرة الرئيسية وراء خسارة حقل ماركوف العشوائي المتنوع الضمني (ID-MRF) هي توجيه تصحيحات العناصر المُنشأة للعثور على أقرب جيرانها خارج المناطق التي تم تخطيها كمراجع ، ويجب على هؤلاء الجيران الأقرب تكون متنوعة بما يكفي لنمذجة المزيد من تفاصيل النسيج المحلي. في الواقع ، هذه الخسارة هي نسخة محسّنة من فقدان النسيج المستخدم في MSNPS [3]. أوصي بشدة بقراءة رسالتي [ هنا ] للحصول على شرح مفصل لهذه الخسارة.
PartialConv (يوسع قيود الاستعادة من خلال التعلم العميق للفراغات غير المنتظمة ، 2018)

. 9. , .
(PartialConv أو PConv) [11] يدفع حدود التعلم العميق في استعادة الصورة من خلال تقديم طريقة للتعامل مع الصور الكامنة ذات الثقوب المتعددة غير المنتظمة. من الواضح أن الفكرة الرئيسية لهذه المقالة هي طي جزئي. عند استخدام PConv ، ستعتمد نتائج الالتفاف على وحدات البكسل المسموح بها فقط ، لذلك نحن نتحكم في المعلومات المنقولة داخل الشبكة. هذا هو أول عمل لاستعادة الصورة لمعالجة الفراغات غير المنتظمة. يرجى ملاحظة أن نماذج الاستعادة السابقة قد تم تدريبها على الصور التالفة الصحيحة ، لذا فإن هذه النماذج ليست مناسبة لاستعادة الصور ذات الفراغات غير الصحيحة.
لقد قدمت مثالًا بسيطًا لشرح بوضوح كيفية إجراء الطي الجزئي في رسالتي السابقة [ هنا]. زيارة الرابط لمزيد من التفاصيل. ط نتمنى أن تستمتعوا.
EdgeConnect - يحدد الخطوط العريضة أولاً ، الألوان ثم ، 2019

الشكل: 10. بنية الشبكة EdgeConnect. كما ترى ، هناك مولدان ومميزان.
EdgeConnect[12]: الاستعادة التوليدية للصور باستخدام التعلم من الحواف العدوانية (EdgeConnect) [12] تقدم طريقة ممتعة لحل مشكلة استعادة الصورة. الفكرة الرئيسية لهذه المقالة هي تقسيم مهمة الاستعادة إلى خطوتين مبسطتين ، وهما التنبؤ بالحواف وإكمال الصورة بناءً على خريطة الحافة المتوقعة. يتم توقع الحواف في المناطق المفقودة أولاً ، ثم تكتمل الصورة وفقًا لتنبؤ الحافة. تمت تغطية معظم الطرق المستخدمة في هذه المقالة في مشاركاتي السابقة. نظرة فاحصة على كيفية استخدام التقنيات المختلفة معًا لتشكيل نهج جديد لاستعادة صورة التعلم العميق. ربما ستقوم بتطوير نموذج الاستعادة الخاص بك. يرجى الاطلاع على رسالتي السابقة [هنا ] لمعرفة المزيد عن هذه المقالة.
DeepFill v2 (نهج عملي لاستعادة الصورة التوليدية ، 2019)

الشكل: 11. نظرة عامة على بنية الشبكة لنموذج الاستعادة المجانية.
استعادة الشكل الحر باستخدام التواء بوابات(DeepFill v2 or GConv، 2019) [13]. ربما تكون هذه هي خوارزمية استعادة الصور الأكثر عملية والتي يمكن استخدامها مباشرة في تطبيقاتك. يمكن اعتباره نسخة محسّنة من DeepFill v1 [9] ، والتواء جزئي [11] و EdgeConnect [12]. الفكرة الرئيسية للعمل هي Gated Convolution ، وهي نسخة قابلة للتدريب من الالتواء الجزئي. من خلال إضافة طبقة تلافيفية قياسية إضافية متبوعة بوظيفة سينية ، من الممكن معرفة صلاحية كل موقع بكسل / كائن ، وبالتالي يُسمح أيضًا بإدخال رسم مخصص إضافي. بالإضافة إلى Gated Convolution ، يتم استخدام SN-PatchGAN لزيادة استقرار تدريب نموذج GAN. لمعرفة المزيد حول الاختلاف بين الالتواء الجزئي والتواء بوابات ، وكيفكيف يمكن أن يؤثر إدخال رسم المستخدم الإضافي على نتائج الاستعادة ، يرجى الاطلاع على آخر مشاركة لي [هنا ].
خاتمة
آمل أن يكون لديك الآن فهم أساسي لاستعادة الصورة. أعتقد أن معظم التقنيات الشائعة المستخدمة في استعادة صورة التعلم العميق قد تمت تغطيتها في مشاركاتي السابقة. إذا كنت صديقًا قديمًا لي ، فأعتقد أنك الآن في وضع يسمح لك بفهم أعمال الترميم الأخرى باستخدام التعلم العميق. إذا كنت مبتدئًا ، أود أن أرحب بكم. أتمنى أن تجد هذه المشاركة مفيدة. في الواقع ، يمنحك هذا المنشور فرصة الانضمام إلينا والتعلم معًا.
في رأيي ، لا يزال من الصعب استعادة الصور ذات هياكل المشهد المعقدة وعدد كبير من وحدات البكسل المفقودة (على سبيل المثال ، عند فقدان 50٪ من البكسل). بالطبع ، هناك تحدٍ آخر يتمثل في استعادة الصور عالية الدقة. كل هذه المهام يمكن أن تسمى متطرفة. أعتقد أن النهج القائم على أحدث التطورات في الاستعادة يمكن أن يحل بعض هذه المشاكل.
روابط للمقالات
[1] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros, “Context Encoders: Feature Learning by Inpainting,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.

- دورة متقدمة "التعلم الآلي + التعلم العميق"
- دورة تعلم الآلة
- التدريب على مهنة علوم البيانات
- تدريب محلل البيانات
- دورة بايثون لتطوير الويب
المزيد من الدورات