ما هو الغرض من هذه الدراسة؟ أردت أن أعرف:
- ما هي التطبيقات المستخدمة بايثون
- ما هي المعرفة المطلوبة: قواعد البيانات والمكتبات والأطر
- كم عدد المتخصصين المطلوبين في كل مجال
- ما هي الرواتب المقدمة

تحميل البيانات
وظائف تحميلها من موقع hh.ru ، وذلك باستخدام API: dev.hh.ru . بناء على طلب "Python" ، تم تحميل 1994 شواغر (منطقة موسكو) ، والتي تم تقسيمها إلى مجموعات تدريب واختبار ، بنسبة 80٪ و 20٪ . حجم مجموعة التدريب 1595 ، حجم مجموعة الاختبار 399 . سيتم استخدام مجموعة الاختبار فقط في أقسام Top / Antitop Skills وتصنيف الوظائف.
علامات
بناءً على نص الوظائف الشاغرة التي تم تحميلها ، تم تكوين مجموعتين من الكلمات n-grams الأكثر شيوعًا :
- 2 جرام باللغتين السيريلية واللاتينية
- 1 جرام باللاتينية
في الوظائف الشاغرة لتكنولوجيا المعلومات ، عادةً ما تُكتب المهارات والتقنيات الأساسية باللغة الإنجليزية ، لذلك تضمنت المجموعة الثانية كلمات باللغة اللاتينية فقط.
بعد اختيار n-gram ، احتوت المجموعة الأولى على 81 2 جرام والمجموعة الثانية 98 1 جرام:
| لا. | ن | ن غرام | وزن | الشواغر |
| 1 | 2 | في بيثون | ثمانية | 258 |
| 2 | 2 | ci cd | ثمانية | 230 |
| 3 | 2 | فهم المبادئ | ثمانية | 221 |
| 4 | 2 | معرفة SQL | ثمانية | 178 |
| خمسة | 2 | التطوير و | تسع | 174 |
| ... | ... | ... | ... | ... |
| 82 | 1 | sql | خمسة | 490 |
| 83 | 1 | لينكس | 6 | 462 |
| 84 | 1 | postgresql | خمسة | 362 |
| 85 | 1 | عامل ميناء | 7 | 358 |
| 86 | 1 | جافا | تسع | 297 |
| ... | ... | ... | ... | ... |
تقرر تقسيم الوظائف الشاغرة إلى مجموعات حسب المعايير التالية حسب الأولوية:
| أولوية | معيار | وزن |
| 1 | المجال (الاتجاه التطبيقي) ، المنصب ، تجربة
n-gram: "التعلم الآلي" ، "إدارة Linux" ، "المعرفة الممتازة" |
7-9 |
| 2 | الأدوات والتقنيات والبرمجيات.
n-grams: "sql" ، "linux os" ، "pytest" |
4-6 |
| 3 | مهارات أخرى في
n-gram: "التعليم الفني" ، "اللغة الإنجليزية" ، "المهام الشيقة" |
1-3 |
تم تحديد مجموعة المعايير التي ينتمي إليها n-gram ، والوزن الذي يجب تعيينه لها ، على مستوى حدسي. هنا بضعة أمثلة:
- للوهلة الأولى ، يمكن أن تُنسب "Docker" إلى المجموعة الثانية من المعايير بوزن من 4 إلى 6. ولكن ذكر "Docker" في الوظيفة الشاغرة على الأرجح يعني أن الوظيفة الشاغرة ستكون لمنصب "DevOps Engineer". لذلك ، سقط "Docker" في المجموعة الأولى وحصل على وزن 7.
- «Java» , .. «Java» Java- « Python». «-». , , , «Java» 9.
n- — .
بالنسبة للحسابات ، تم تحويل كل شاغر إلى متجه بأبعاد 179 (عدد الميزات المحددة) من الأعداد الصحيحة من 0 إلى 9 ، حيث يعني 0 أن i-th n-gram غائب في الشاغر ، والأرقام من 1 إلى 9 تعني وجود i-th n - غرام ووزنه. علاوة على ذلك في النص ، تُفهم النقطة على أنها شاغر يمثلها هذا المتجه.
مثال:
لنفترض أن قائمة n-grams تحتوي على ثلاث قيم فقط:
لا. ن ن غرام وزن الشواغر 1 2 في بيثون ثمانية 258 2 2 فهم المبادئ ثمانية 221 3 1 sql خمسة 490
ثم لوظيفة شاغرة مع النص.
المتطلبات:
- 3+ سنوات من الخبرة في تطوير الثعبان .
- معرفة جيدة بـ SQL
المتجه يساوي [8 ، 0 ، 5].
المقاييس
للعمل مع البيانات ، يجب أن تفهمها. في حالتنا ، أود أن أرى ما إذا كانت هناك أية مجموعات من النقاط ، والتي سنعتبرها مجموعات. لهذا ، استخدمت خوارزمية t-SNE لترجمة جميع المتجهات إلى مساحة ثنائية الأبعاد.
يتمثل جوهر الطريقة في تقليل أبعاد البيانات ، مع الحفاظ على نسب المسافات بين نقاط المجموعة قدر الإمكان. من الصعب جدًا فهم كيفية عمل t-SNE من الصيغ. لكني أحببت أحد الأمثلة الموجودة في مكان ما على الإنترنت: دعنا نقول أن لدينا كرات في مساحة ثلاثية الأبعاد. نقوم بتوصيل كل كرة بجميع الكرات الأخرى بواسطة نوابض غير مرئية لا تتقاطع بأي شكل من الأشكال ولا تتداخل مع بعضها البعض عند العبور. تعمل الينابيع في اتجاهين ، أي إنهم يقاومون المسافة والاقتراب من الكرات لبعضهم البعض. النظام في حالة مستقرة ، والكرات ثابتة. إذا أخذنا إحدى الكرات وسحبناها إلى الوراء ، ثم حررناها ، فستعود إلى حالتها الأصلية بسبب قوة الينابيع. بعد ذلك ، نأخذ لوحين كبيرين ، ونضغط الكرات في طبقة رقيقة ،مع عدم التدخل في الكرات للتحرك في المستوى بين الصفيحتين. تبدأ قوى الينابيع في العمل ، وتتحرك الكرات وتتوقف في النهاية عندما تصبح قوى جميع الينابيع متوازنة. سوف تعمل الينابيع بحيث تظل الكرات القريبة من بعضها البعض قريبة ومسطحة نسبيًا. أيضًا مع الكرات التي تمت إزالتها - ستتم إزالتها من بعضها البعض. بمساعدة الينابيع والألواح ، قمنا بتحويل الفضاء ثلاثي الأبعاد إلى ثنائي الأبعاد ، مع الحفاظ على المسافة بين النقاط بشكل ما!أيضًا مع الكرات التي تمت إزالتها - ستتم إزالتها من بعضها البعض. بمساعدة الينابيع والألواح ، قمنا بتحويل الفضاء ثلاثي الأبعاد إلى ثنائي الأبعاد ، مع الحفاظ على المسافة بين النقاط بشكل ما!أيضًا مع الكرات التي تمت إزالتها - ستتم إزالتها من بعضها البعض. بمساعدة الينابيع والألواح ، قمنا بتحويل الفضاء ثلاثي الأبعاد إلى ثنائي الأبعاد ، مع الحفاظ على المسافة بين النقاط بشكل ما!
تم استخدام خوارزمية t-SNE بواسطتي فقط لتصور مجموعة من النقاط. ساعد في اختيار مقياس ، وكذلك تحديد أوزان الميزات.
إذا استخدمنا المقياس الإقليدي الذي نستخدمه في حياتنا اليومية ، فسيبدو موقع الوظائف الشاغرة كما يلي:

يوضح الشكل أن معظم النقاط تتركز في المركز ، وهناك فروع صغيرة على الجانبين. باستخدام هذا النهج ، لن ينتج عن خوارزميات التجميع التي تستخدم المسافات بين النقاط أي شيء جيد.
هناك العديد من المقاييس (طرق تحديد المسافة بين نقطتين) التي ستعمل بشكل جيد على البيانات التي تستكشفها. اخترت مسافة Jaccard كمقياس ، مع مراعاة أوزان n-grams. من السهل فهم مقياس Jaccard ، ولكنه يعمل جيدًا لحل المشكلة قيد الدراسة.
:
1 n-: « python», «sql», «docker»
2 n-: « python», «sql», «php»
:
« python» — 8
«sql» — 5
«docker» — 7
«php» — 9
(n- 1- 2- ): « python», «sql» = 8 + 5 = 13
( n- 1- 2- ): « python», «sql», «docker», «php» = 8 + 5 + 7 + 9 = 29
=1 — ( / ) = 1 — (13 / 29) = 0.55
تم حساب مصفوفة المسافات بين جميع أزواج النقاط ، وحجم المصفوفة هو 1595 × 1595. إجمالاً ، 1،271،215 مسافة بين الأزواج الفريدة. تبين أن متوسط المسافة هو 0.96 ، بين 619659 المسافة هي 1 (أي لا يوجد تشابه على الإطلاق). يوضح الرسم البياني التالي أنه بشكل عام ، هناك القليل من التشابه بين الوظائف:
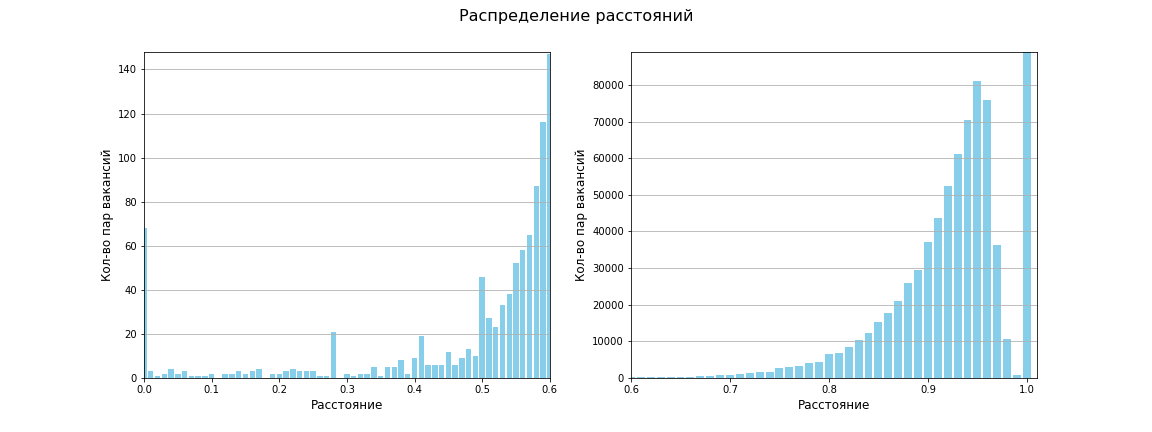
باستخدام مقياس Jaccard ، تبدو مساحتنا الآن كما يلي:

ظهرت أربع مناطق كثافة مميزة ، ومجموعتان صغيرتان منخفضتا الكثافة. على الأقل هكذا ترى عيني!
تجمع
تم اختيار نموذج الخليط الغاوسي (GMM) كخوارزمية التجميع . تستقبل الخوارزمية البيانات في شكل متجهات كمدخلات ، والمعلمة n_components هي عدد المجموعات التي يجب تقسيم المجموعة إليها. يمكنك أن ترى كيف تعمل الخوارزمية هنا (باللغة الإنجليزية). لقد استخدمت تنفيذ GMM جاهزًا من مكتبة scikit- Learn : sklearn.mixture.GaussianMixture .
لاحظ أن GMM لا تستخدم مقياسًا ، ولكنها تفصل البيانات فقط من خلال مجموعة من الميزات وأوزانها. في المقالة ، يتم استخدام مسافة Jaccard لتصور البيانات ، وحساب انضغاط الكتل (أخذت متوسط المسافة بين نقاط الكتلة للضغط) ، وتحديدالنقطة المركزية للمجموعة (شاغر نموذجي) - النقطة ذات أصغر متوسط مسافة إلى نقاط أخرى من الكتلة. تستخدم العديد من خوارزميات التجميع بالضبط المسافة بين النقاط. سيتحدث قسم الطرق الأخرى عن الأنواع الأخرى من المجموعات المستندة إلى المقاييس وتعطي نتائج جيدة أيضًا.
في القسم السابق ، تم تحديد أنه سيكون هناك على الأرجح ست مجموعات. هكذا تبدو نتائج التجميع مع n_components = 6:

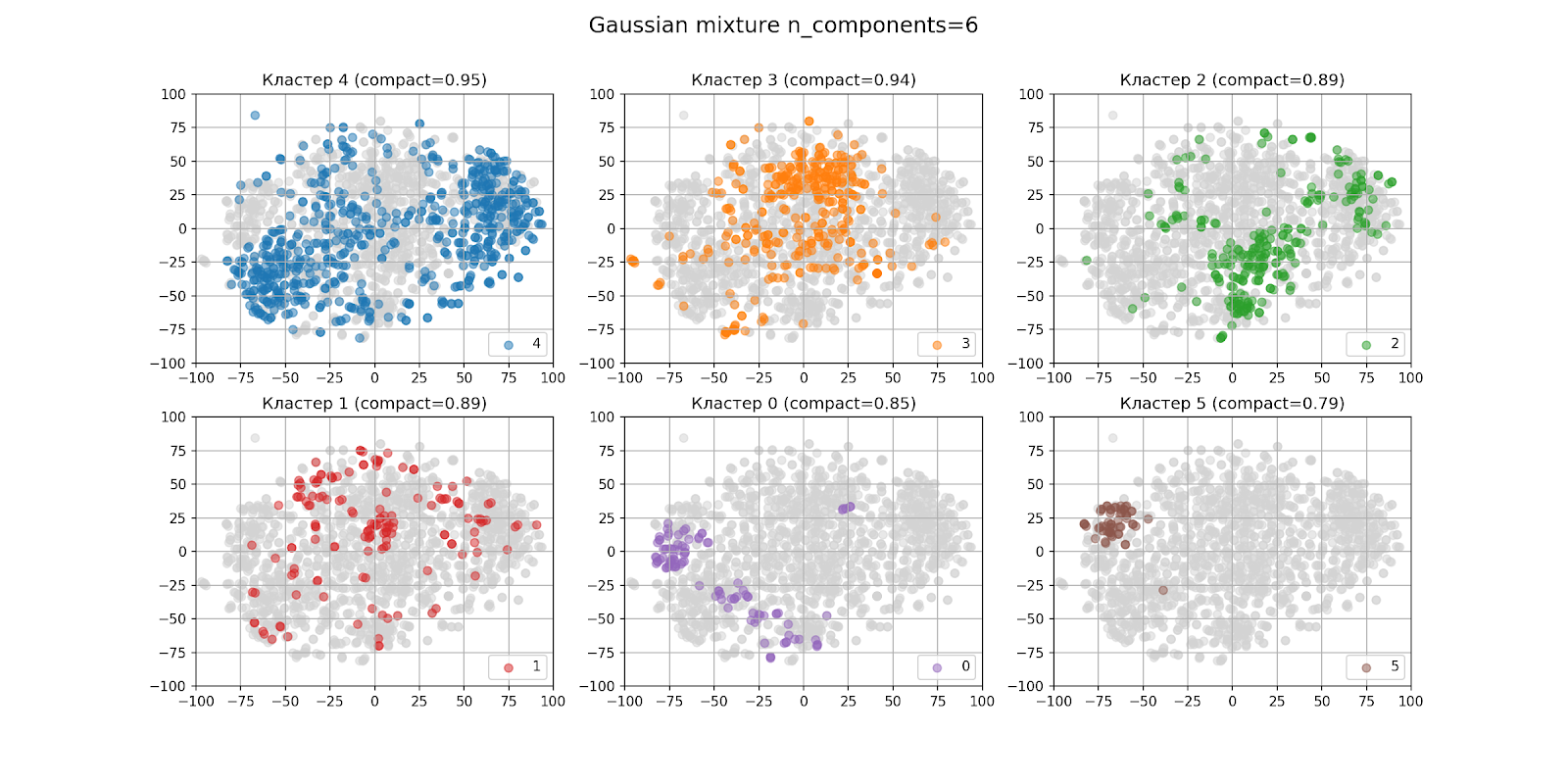
في الشكل مع إخراج المجموعات بشكل منفصل ، يتم ترتيب المجموعات بترتيب تنازلي لعدد النقاط من اليسار إلى اليمين ، من أعلى إلى أسفل: المجموعة 4 هي الأكبر ، المجموعة 5 هي الأصغر. يشار إلى انضغاط كل مجموعة بين قوسين.
في المظهر ، تبين أن التجميع لم يكن جيدًا جدًا ، حتى لو اعتبرنا أن خوارزمية t-SNE ليست مثالية. عند تحليل المجموعات ، لم تكن النتيجة مشجعة أيضًا.
للعثور على العدد الأمثل للمجموعات n_components ، سنستخدم معايير AIC و BIC ، والتي يمكنك قراءتها هنا . تم بناء حساب هذه المعايير في طريقة sklearn.mixture.GaussianMixture . هكذا يبدو الرسم البياني للمعايير:

عندما يكون n_components = 12 ، يكون لمعيار BIC أدنى قيمة (أفضل) ، يكون لمعيار AIC أيضًا قيمة قريبة من الحد الأدنى (الحد الأدنى عندما n_components = 23). دعونا نقسم الوظائف الشاغرة إلى 12 مجموعة:


أصبحت المجموعات الآن أكثر إحكاما ، سواء في المظهر أو من الناحية العددية. أثناء التحليل اليدوي ، تم تقسيم الوظائف الشاغرة إلى مجموعات مميزة لفهم الشخص. يوضح الشكل أسماء المجموعات. تم وضع علامة على المجموعات المرقمة 11 و 4 على أنها <المهملات 2>:
- في المجموعة 11 ، جميع الميزات لها نفس الأوزان الإجمالية تقريبًا.
- المجموعة 4 مخصصة لجافا. ومع ذلك ، هناك عدد قليل من الوظائف الشاغرة لمنصب Java Developer في المجموعة ، وغالبًا ما تكون معرفة Java مطلوبة لأنها "ستكون ميزة إضافية".
عناقيد المجموعات
بعد إزالة مجموعتين غير إعلاميتين مرقمتين 11 و 4 ، تكون النتيجة 10 مجموعات:
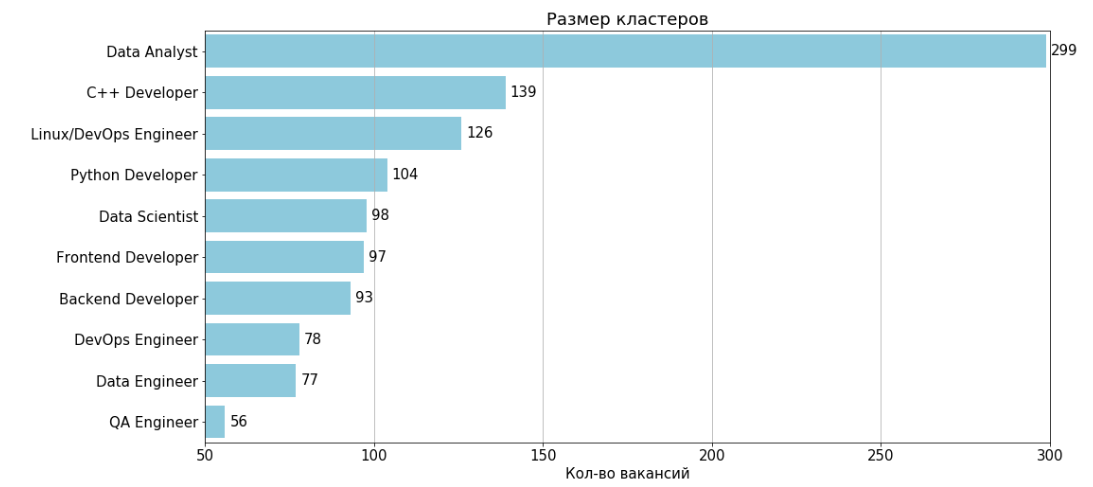
لكل مجموعة ، يوجد جدول ميزات و 2 جرام توجد غالبًا في الأماكن الشاغرة في المجموعة.
مفتاح الرسم التوضيحي:
S - نسبة الوظائف الشاغرة التي توجد فيها السمة ، مضروبة بوزن السمة
٪ - النسبة المئوية للوظائف الشاغرة التي توجد فيها السمة / 2 جرامًا
نموذجيًا للمجموعة الشاغرة - شاغر ، مع أصغر متوسط مسافة إلى نقاط أخرى من المجموعة
محلل بيانات
عدد الوظائف: 299 وظيفة
نموذجية: 35805.914
| لا. | وقع مع الوزن | س | إشارة | ٪ | 2 جرام | ٪ |
| 1 | تتفوق | 3.13 | sql | 64.55 | معرفة SQL | 18.39 |
| 2 | ص | 2.59 | تتفوق | 34.78 | في التطوير | 14.05 |
| 3 | sql | 2.44 | ص | 28.76 | بيثون ص | 14.05 |
| 4 | معرفة SQL | 1.47 | ثنائية | 19.40 | مع كبير | 13.38 |
| خمسة | تحليل البيانات | 1.17 | تابلوه | 15.38 | التطوير و | 13.38 |
| 6 | تابلوه | 1.08 | جوجل | 14.38 | تحليل البيانات | 13.04 |
| 7 | مع كبير | 1.07 | vba | 13.04 | معرفة بيثون | 12.71 |
| ثمانية | التطوير و | 1.07 | علم | 9.70 | مستودع التحليلي | 11.71 |
| تسع | vba | 1.04 | dwh | 6.35 | تجربة التطوير | 11.71 |
| عشرة | معرفة بيثون | 1.02 | وحي | 6.35 | قواعد بيانات | 11.37 |
مطور C ++
عدد الوظائف: 139 وظيفة
نموذجية: 39955360
| لا. | وقع مع الوزن | س | إشارة | ٪ | 2 جرام | ٪ |
| 1 | سي ++ | 9.00 | سي ++ | 100.00 | تجربة التطوير | 44.60 |
| 2 | جافا | 3.30 | لينكس | 44.60 | سي سي ++ | 27.34 |
| 3 | لينكس | 2.55 | جافا | 36.69 | ج ++ الثعبان | 17.99 |
| 4 | ج # | 1.88 | sql | 23.02 | في c ++ | 16.55 |
| خمسة | اذهب | 1.75 | ج # | 20.86 | على التنمية | 15.83 |
| 6 | على التنمية | 1.27 | اذهب | 19.42 | هياكل البيانات | 15.11 |
| 7 | معرفة جيدة | 1.15 | يونكس | 12.23 | تجربة الكتابة | 14.39 |
| ثمانية | هياكل البيانات | 1.06 | تينسورفلو | 11.51 | البرمجة على | 13.67 |
| تسع | تينسورفلو | 1.04 | سحق | 10.07 | في التطوير | 13.67 |
| عشرة | تجربة البرمجة | 0.98 | postgresql | 9.35 | لغات البرمجة | 12.95 |
لينكس / مهندس DevOps
عدد الوظائف: 126 وظيفة
نموذجية: 39.533.926
| لا. | وقع مع الوزن | س | إشارة | ٪ | 2 جرام | ٪ |
| 1 | غير مقبول | 5.33 | لينكس | 84.92 | ci cd | 58.73 |
| 2 | عامل ميناء | 4.78 | غير مقبول | 76.19 | خبرة إدارية | 42.06 |
| 3 | سحق | 4.78 | عامل ميناء | 74.60 | باش بيثون | 33.33 |
| 4 | ci cd | 4.70 | سحق | 68.25 | برنامج التعاون الفني IP | 39.37 |
| خمسة | لينكس | 4.43 | بروميثيوس | 58.73 | تجربة التخصيص | 28.57 |
| 6 | بروميثيوس | 4.11 | zabbix | 54.76 | رصد و | 26.98 |
| 7 | nginx | 3.67 | nginx | 52.38 | بروميثيوس جرافانا | 23.81 |
| ثمانية | خبرة إدارية | 3.37 | جرافانا | 52.38 | أنظمة المراقبة | 22.22 |
| تسع | zabbix | 3.29 | postgresql | 51.59 | مع عامل ميناء | 16.67 |
| عشرة | الأيائل | 3.22 | kubernetes | 51.59 | إدارة التكوين | 16.67 |
مطور بايثون
عدد فرص العمل المتاحة: 104 وظيفة
نموذجية: 39.705.484
| لا. | وقع مع الوزن | س | إشارة | ٪ | 2 جرام | ٪ |
| 1 | في بيثون | 6.00 | عامل ميناء | 65.38 | في بيثون | 75.00 |
| 2 | دجانغو | 5.62 | دجانغو | 62.50 | على التنمية | 51.92 |
| 3 | قارورة | 4.59 | postgresql | 58.65 | تجربة التطوير | 43.27 |
| 4 | عامل ميناء | 4.24 | قارورة | 50.96 | دورق دجانجو | 04.24 |
| خمسة | على التنمية | 4.15 | ريديس | 38.46 | بقية api | 23.08 |
| 6 | postgresql | 2.93 | لينكس | 35.58 | بيثون من | 21.15 |
| 7 | aiohttp | 1.99 | أرنب | 33.65 | قواعد بيانات | 18.27 |
| ثمانية | ريديس | 1.92 | sql | 30.77 | تجربة الكتابة | 18.27 |
| تسع | لينكس | 1.73 | منجودب | 25.00 | مع عامل ميناء | 17.31 |
| عشرة | أرنب | 1.68 | aiohttp | 22.12 | مع postgresql | 16.35 |
عالم البيانات
عدد الوظائف: 98 وظيفة
نموذجية: 3871218
| لا. | وقع مع الوزن | س | إشارة | ٪ | 2 جرام | ٪ |
| 1 | الباندا | 7.35 | الباندا | 81.63 | التعلم الالي | 63.27 |
| 2 | حبيبي | 6.04 | حبيبي | 75.51 | الباندا numpy | 43.88 |
| 3 | التعلم الالي | 5.69 | sql | 62.24 | تحليل البيانات | 29.59 |
| 4 | بيتورش | 3.77 | بيتورش | 41.84 | علم البيانات | 26.53 |
| خمسة | مل | 3.49 | مل | 38.78 | معرفة بيثون | 25.51 |
| 6 | تينسورفلو | 3.31 | تينسورفلو | 36.73 | حزن | 24.49 |
| 7 | تحليل البيانات | 2.66 | شرارة | 32.65 | الباندا الثعبان | 23.47 |
| ثمانية | scikitlearn | 2.57 | scikitlearn | 28.57 | في بيثون | 21.43 |
| تسع | علم البيانات | 2.39 | عامل ميناء | 27.55 | الإحصاء الرياضي | 20.41 |
| عشرة | شرارة | 2.29 | هادوب | 27.55 | خوارزميات الآلة | 20.41 |
مطور الواجهة الأمامية
عدد الوظائف: 97 وظيفة
نموذجية: 39،681،044
| لا. | وقع مع الوزن | س | إشارة | ٪ | 2 جرام | ٪ |
| 1 | جافا سكريبت | 9.00 | جافا سكريبت | 100 | أتش تي أم أل المغلق | 27.84 |
| 2 | دجانغو | 2.60 | لغة البرمجة | 42.27 | تجربة التطوير | 25.77 |
| 3 | تتفاعل | 2.32 | postgresql | 38.14 | في التطوير | 17.53 |
| 4 | nodejs | 2.13 | عامل ميناء | 37.11 | معرفة جافا سكريبت | 15.46 |
| خمسة | نهاية المقدمة | 2.13 | المغلق | 37.11 | والدعم | 15.46 |
| 6 | عامل ميناء | 2.09 | لينكس | 32.99 | بيثون و | 14.43 |
| 7 | postgresql | 1.91 | sql | 31.96 | جافا سكريبت css | 13.40 |
| ثمانية | لينكس | 1.79 | دجانغو | 28.87 | قواعد بيانات | 12.37 |
| تسع | أتش تي أم أل المغلق | 1.67 | تتفاعل | 25.77 | في بيثون | 12.37 |
| عشرة | بي أتش بي | 1.58 | nodejs | 23.71 | تصميم و | 11.34 |
مطور الواجهة الخلفية
عدد الوظائف: 93 وظيفة
نموذجية: 40226808
| لا. | وقع مع الوزن | س | إشارة | ٪ | 2 جرام | ٪ |
| 1 | دجانغو | 5.90 | دجانغو | 65.59 | بيثون جانغو | 26.88 |
| 2 | شبيبة | 4.74 | شبيبة | 52.69 | تجربة التطوير | 25.81 |
| 3 | تتفاعل | 2.52 | postgresql | 40.86 | معرفة بيثون | 20.43 |
| 4 | عامل ميناء | 2.26 | عامل ميناء | 35.48 | في التطوير | 18.28 |
| خمسة | postgresql | 2.04 | تتفاعل | 27.96 | ci cd | 17.20 |
| 6 | فهم المبادئ | 1.89 | لينكس | 27.96 | معرفة واثقة | 16.13 |
| 7 | معرفة بيثون | 1.63 | الخلفية | 22.58 | بقية api | 15.05 |
| ثمانية | الخلفية | 1.58 | ريديس | 22.58 | أتش تي أم أل المغلق | 13.98 |
| تسع | ci cd | 1.38 | sql | 20.43 | القدرة على الفهم | 10.75 |
| عشرة | نهاية المقدمة | 1.35 | mysql | 19.35 | في شخص غريب | 10.75 |
مهندس DevOps
عدد الوظائف: 78 وظيفة
نموذجية: 39634258
| لا. | وقع مع الوزن | س | إشارة | ٪ | 2 جرام | ٪ |
| 1 | devops | 8.54 | devops | 94.87 | ci cd | 51.28 |
| 2 | غير مقبول | 5.38 | غير مقبول | 76.92 | باش بيثون | 30.77 |
| 3 | سحق | 4.76 | لينكس | 74.36 | خبرة إدارية | 24.36 |
| 4 | جينكينز | 4.49 | سحق | 67.95 | والدعم | 23.08 |
| خمسة | ci cd | 4.10 | جينكينز | 64.10 | عامل ميناء kubernetes | 20.51 |
| 6 | لينكس | 3.54 | عامل ميناء | 50.00 | التطوير و | 17.95 |
| 7 | عامل ميناء | 2.60 | kubernetes | 41.03 | تجربة الكتابة | 17.95 |
| ثمانية | جافا | 2.08 | sql | 29.49 | والتخصيص | 17.95 |
| تسع | خبرة إدارية | 1.95 | وحي | 25.64 | التطوير و | 16.67 |
| عشرة | والدعم | 1.85 | فتح | 24.36 | البرمجة النصية | 14.10 |
مهندس بيانات
عدد الوظائف: 77 وظيفة
نموذجية: 40.008757
| لا. | وقع مع الوزن | س | إشارة | ٪ | 2 جرام | ٪ |
| 1 | شرارة | 6.00 | هادوب | 89.61 | معالجة البيانات | 38.96 |
| 2 | هادوب | 5.38 | شرارة | 85.71 | البيانات الكبيرة | 37.66 |
| 3 | جافا | 4.68 | sql | 68.83 | تجربة التطوير | 23.38 |
| 4 | خلية نحل | 4.27 | خلية نحل | 61.04 | معرفة SQL | 22.08 |
| خمسة | سكالا | 3.64 | جافا | 51.95 | التطوير و | 19.48 |
| 6 | البيانات الكبيرة | 3.39 | سكالا | 51.95 | هادوب سبارك | 19.48 |
| 7 | إتل | 3.36 | إتل | 48.05 | جافا سكالا | 19.48 |
| ثمانية | sql | 2.79 | تدفق الهواء | 44.16 | جودة البيانات | 18.18 |
| تسع | معالجة البيانات | 2.73 | كافكا | 42.86 | والمعالجة | 18.18 |
| عشرة | كافكا | 2.57 | وحي | 35.06 | خلية هادوب | 18.18 |
مهندس تأكيد جودة
عدد الوظائف: 56 وظيفة
نموذجية: 39630489
| لا. | وقع مع الوزن | س | إشارة | ٪ | 2 جرام | ٪ |
| 1 | أتمتة الاختبار | 5.46 | sql | 46.43 | أتمتة الاختبار | 60.71 |
| 2 | تجربة الاختبار | 4.29 | qa | 42.86 | تجربة الاختبار | 53.57 |
| 3 | qa | 3.86 | لينكس | 35.71 | في بيثون | 41.07 |
| 4 | في بيثون | 3.29 | السيلينيوم | 32.14 | تجربة الأتمتة | 35.71 |
| خمسة | التطوير و | 2.57 | الويب | 32.14 | التطوير و | 32.14 |
| 6 | sql | 2.05 | عامل ميناء | 30.36 | تجربة الاختبار | 30.36 |
| 7 | لينكس | 2.04 | جينكينز | 26.79 | تجربة الكتابة | 28.57 |
| ثمانية | السيلينيوم | 1.93 | الخلفية | 26.79 | على الاختبار | 23.21 |
| تسع | الويب | 1.93 | سحق | 21.43 | الاختبار الآلي | 21.43 |
| عشرة | الخلفية | 1.88 | واجهة المستخدم | 19.64 | ci cd | 21.43 |
الرواتب
تم تحديد الرواتب فقط في 261 (22٪) وظيفة شاغرة من أصل 1167 في المجموعات.
عند احتساب الرواتب:
- إذا تم تحديد النطاق "من ... إلى ..." ، فسيتم استخدام متوسط القيمة
- إذا تمت الإشارة إلى "من ..." أو "إلى ..." فقط ، فسيتم أخذ هذه القيمة
- الحسابات المستخدمة (أو أعطيت) الراتب بعد الضرائب (صافي)
على المخطط:
- يتم ترتيب المجموعات بترتيب تنازلي لمتوسط الراتب
- شريط عمودي في المربع - متوسط
- نطاق الصندوق [Q1، Q3] ، حيث Q1 (25٪) و Q3 (75٪) هي نسب مئوية. أولئك. 50٪ من الرواتب تدخل الصندوق
- يتضمن "الشارب" الرواتب من النطاق [Q1 - 1.5 * IQR، Q3 + 1.5 * IQR] ، حيث IQR = Q3 - Q1 - النطاق الربيعي
- نقاط فردية - شذوذ لم يقع في الشارب. (هناك حالات شاذة غير مدرجة في الرسم التخطيطي)

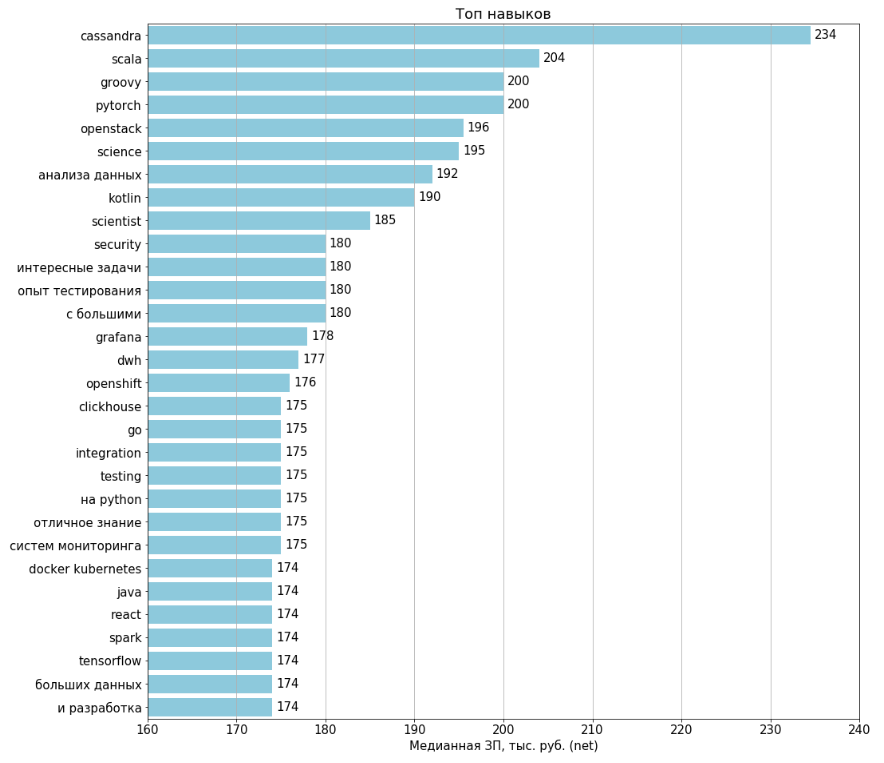
مهارات أعلى / أنتيتوب
تم إنشاء المخططات لجميع الوظائف الشاغرة التي تم تحميلها عام 1994. تم تحديد الرواتب في 443 (22٪) وظيفة شاغرة. لحساب كل ميزة ، تم تحديد الوظائف الشاغرة حيث توجد هذه الميزة ، وعلى أساسها تم حساب متوسط الراتب.

تصنيف الوظائف
يمكن جعل التجميع أسهل بكثير دون اللجوء إلى نماذج رياضية معقدة: لتجميع المسميات الوظيفية العليا وتقسيمها إلى مجموعات. بعد ذلك ، قم بتحليل كل مجموعة لمعرفة أعلى n-grams ومتوسط الرواتب. ليست هناك حاجة لإبراز الميزات وتعيين أوزان لها.
ستعمل هذه الطريقة بشكل جيد (إلى حد ما) مع استعلام "Python". ولكن لطلب "1C مبرمج" هذا النهج لن يعمل ، لأن بالنسبة لمبرمجي 1C ، نادرًا ما يشار إلى تكوينات 1C أو المناطق المطبقة في أسماء الوظائف الشاغرة. وهناك العديد من المجالات التي يتم فيها استخدام 1C: المحاسبة ، وحساب الرواتب ، وحساب الضرائب ، وحساب التكلفة في مؤسسات التصنيع ، ومحاسبة المستودعات ، ووضع الميزانية ، وأنظمة تخطيط موارد المؤسسات ، وتجارة التجزئة ، والمحاسبة الإدارية ، إلخ.
بنفسي ، أرى مهمتين لتحليل الوظائف الشاغرة:
- افهم أين يتم استخدام لغة البرمجة التي أعرف القليل عنها (كما في هذه المقالة).
- تصفية الوظائف المنشورة الجديدة.
التجميع مناسب لحل المشكلة الأولى ، لحل المشكلة الثانية - المصنفات المختلفة ، الغابات العشوائية ، أشجار القرار ، الشبكات العصبية. ومع ذلك ، أردت تقييم مدى ملاءمة النموذج المختار لمشكلة تصنيف الوظائف.
إذا استخدمت طريقة التنبؤ () المضمنة في sklearn.mixture.GaussianMixture ، فلن يحدث شيء جيد. وهو ينسب معظم الوظائف الشاغرة إلى مجموعات كبيرة ، واثنان من المجموعات الثلاث الأولى غير مفيدة. لقد استخدمت نهجًا مختلفًا:
- نأخذ الوظيفة الشاغرة التي نريد تصنيفها. نحن نوجهها ونحصل على نقطة في فضائنا.
- نحسب المسافة من هذه النقطة إلى جميع المجموعات. تحت المسافة بين نقطة ومجموعة ، أخذت متوسط المسافة من هذه النقطة إلى جميع النقاط في العنقود.
- المجموعة ذات أصغر مسافة هي الفئة المتوقعة للوظيفة الشاغرة المحددة. تشير المسافة إلى الكتلة إلى موثوقية مثل هذا التنبؤ.
- لزيادة دقة النموذج ، اخترت 0.87 كمسافة عتبة ، أي إذا كانت المسافة إلى أقرب كتلة أكبر من 0.87 ، فإن النموذج لا يصنف الشاغر.
لتقييم النموذج ، تم اختيار 30 وظيفة شاغرة بشكل عشوائي من مجموعة الاختبار. في عمود الحكم:
لا ينطبق: لم يصنف النموذج الوظيفة (المسافة> 0.87)
+: التصنيف الصحيح
-: التصنيف غير صحيح
| وظيفة شاغرة | أقرب كتلة | مسافة | حكم |
| 37637989 | لينكس / مهندس DevOps | 0.9464 | غير متاح |
| 37833719 | مطور C ++ | 0.8772 | غير متاح |
| 38324558 | مهندس بيانات | 0.8056 | + |
| 38517047 | مطور C ++ | 0.8652 | + |
| 39053305 | قمامة، يدمر، يهدم | 0.9914 | غير متاح |
| 39210270 | مهندس بيانات | 0.8530 | + |
| 39349530 | مطور الواجهة الأمامية | 0.8593 | + |
| 39402677 | مهندس بيانات | 0.8396 | + |
| 39415267 | مطور C ++ | 0.8701 | غير متاح |
| 39734664 | مهندس بيانات | 0.8492 | + |
| 39770444 | مطور الواجهة الخلفية | 0.8960 | غير متاح |
| 39770752 | عالم البيانات | 0.7826 | + |
| 39795880 | محلل بيانات | 0.9202 | غير متاح |
| 39947735 | مطور بايثون | 0.8657 | + |
| 39954279 | لينكس / مهندس DevOps | 0.8398 | - |
| 40008770 | مهندس DevOps | 0.8634 | - |
| 40015219 | مطور C ++ | 0.8405 | + |
| 40031023 | مطور بايثون | 0.7794 | + |
| 40072052 | محلل بيانات | 0.9302 | غير متاح |
| 40112637 | لينكس / مهندس DevOps | 0.8285 | + |
| 40164815 | مهندس بيانات | 0.8019 | + |
| 40186145 | مطور بايثون | 0.7865 | + |
| 40201231 | عالم البيانات | 0.7589 | + |
| 40211477 | مهندس DevOps | 0.8680 | + |
| 40224552 | عالم البيانات | 0.9473 | غير متاح |
| 40230011 | لينكس / مهندس DevOps | 0.9298 | غير متاح |
| 40241704 | القمامة 2 | 0.9093 | غير متاح |
| 40245997 | محلل بيانات | 0.9800 | غير متاح |
| 40246898 | عالم البيانات | 0.9584 | غير متاح |
| 40267920 | مطور الواجهة الأمامية | 0.8664 | + |
المجموع: 12 وظيفة شاغرة ليس لها نتيجة ، 2 شاغرة - تصنيف خاطئ ، 16 وظيفة شاغرة - التصنيف الصحيح. اكتمال النموذج - 60٪ ، دقة النموذج - 89٪.
جوانب ضعيفة
المشكلة الأولى - لنأخذ شاغرين:
الوظيفة الشاغرة 1 -
متطلبات "Lead C ++ Programmer" ":
- أكثر من 5 سنوات من الخبرة في تطوير لغة ++ C.
- ستكون معرفة بايثون ميزة إضافية ".
الوظيفة الشاغرة 2 -من حيث النموذج ، هذه الشواغر متطابقة. حاولت تعديل أوزان المعالم بترتيب حدوثها في النص. هذا لم يؤد إلى أي شيء جيد.
متطلبات "Lead Python Programmer" "":
- أكثر من 5 سنوات من الخبرة في تطوير لغة Python.
- ستكون معرفة C ++ إضافة إضافية "
المشكلة الثانية هي أن GMM تجمع كل النقاط في مجموعة ، مثل العديد من خوارزميات التجميع. المجموعات غير الإعلامية ليست مشكلة في حد ذاتها. لكن المجموعات المفيدة تحتوي أيضًا على القيم المتطرفة. ومع ذلك ، يمكن حل ذلك بسهولة عن طريق مسح المجموعات ، على سبيل المثال ، عن طريق إزالة أكثر النقاط غير النمطية التي لها أكبر متوسط مسافة لبقية نقاط المجموعة.
أساليب أخرى
توضح صفحة المقارنة العنقودية بشكل جيد خوارزميات التجميع المختلفة. GMM هي الوحيدة التي أعطت نتائج جيدة.
بقية الخوارزميات إما أنها لم تنجح أو أعطت نتائج متواضعة للغاية.
من بين تلك التي نفذتها ، كانت النتائج الجيدة في حالتين:
- تم اختيار النقاط ذات الكثافة العالية في حي معين ، يقع على مسافة بعيدة عن بعضها البعض. أصبحت النقاط مراكز التجمعات. بعد ذلك ، على أساس المراكز ، بدأت عملية تشكيل الكتلة - الانضمام إلى النقاط المجاورة.
- التجميع التراكمي هو دمج تكراري للنقاط والعناقيد. تقدم مكتبة scikit-Learn هذا النوع من التجميع ، لكنها لا تعمل بشكل جيد. في التطبيق الخاص بي ، قمت بتغيير مصفوفة الصلة بعد كل تكرار للدمج. توقفت العملية عند الوصول إلى بعض المعلمات الحدودية - في الواقع ، لا تساعد مخططات التشعب في فهم عملية الدمج إذا تم تجميع 1500 عنصر.
خاتمة
أعطاني البحث الذي قمت به إجابات لجميع الأسئلة في بداية المقال. حصلت على خبرة عملية في التجميع أثناء تنفيذ أشكال مختلفة من الخوارزميات المعروفة. آمل حقًا أن تحفز المقالة القارئ على إجراء بحثه التحليلي ، وستساعد بطريقة ما في هذا الدرس المثير.