
اليوم ، الشبكات العصبية الاصطناعية هي في قلب العديد من تقنيات "الذكاء الاصطناعي". في الوقت نفسه ، يتم تنفيذ عملية تدريب نماذج الشبكة العصبية الجديدة (بفضل العدد الهائل من الأطر الموزعة ومجموعات البيانات و "الفراغات" الأخرى) بحيث يقوم الباحثون في جميع أنحاء العالم ببناء خوارزميات جديدة "فعالة" "آمنة" بسهولة ، وأحيانًا دون الدخول في هذه هي النتيجة. في بعض الحالات ، يمكن أن يؤدي هذا إلى عواقب لا رجعة فيها في الخطوة التالية ، في عملية استخدام الخوارزميات المدربة. في مقال اليوم ، سنحلل عددًا من الهجمات على الذكاء الاصطناعي ، وكيفية عملها والعواقب التي يمكن أن تؤدي إليها.
كما تعلمون، نحن في محركات الذكية علاج كل خطوة من عملية التدريب العصبية نموذج الشبكة مع خوف، من إعداد البيانات (انظر هنا ، هنا و هنا ) لتطوير بنية الشبكة (انظر هنا ، هنا و هنا ). في سوق الحلول التي تستخدم الذكاء الاصطناعي وأنظمة التعرف ، نحن موصلات ومروجون للأفكار لتطوير التكنولوجيا المسؤولة. منذ شهر مضى حتى انضممنا إلى الميثاق العالمي للأمم المتحدة .
فلماذا هو مخيف للغاية أن تتعلم الشبكات العصبية "بلا مبالاة"؟ هل يمكن للشبكة السيئة (التي لن تتعرف عليها جيدًا) أن تلحق الضرر الجسيم حقًا؟ اتضح أن النقطة هنا ليست في جودة التعرف على الخوارزمية التي تم الحصول عليها ، ولكن في جودة النظام الناتج ككل.
كمثال بسيط ومباشر ، دعنا نتخيل مدى سوء نظام التشغيل. في الواقع ، ليس من خلال واجهة المستخدم القديمة على الإطلاق ، ولكن من خلال حقيقة أنها لا توفر المستوى المناسب من الأمان ، فإنها لا تمنع على الإطلاق الهجمات الخارجية من المتسللين.
اعتبارات مماثلة صحيحة لأنظمة الذكاء الاصطناعي. لنتحدث اليوم عن الهجمات على الشبكات العصبية التي تؤدي إلى أعطال خطيرة في النظام المستهدف.
تسمم البيانات
الهجوم الأول والأكثر خطورة هو تسمم البيانات. في هذا الهجوم ، يتم تضمين الخطأ في مرحلة التدريب ويعرف المهاجمون مسبقًا كيفية خداع الشبكة. إذا رسمنا تشابهًا مع شخص ما ، فتخيل أنك تتعلم لغة أجنبية وتتعلم بعض الكلمات بشكل غير صحيح ، على سبيل المثال ، تعتقد أن الحصان هو مرادف للمنزل. ثم في معظم الحالات ستكون قادرًا على التحدث بهدوء ، ولكن في حالات نادرة سترتكب أخطاء جسيمة. يمكن القيام بحيلة مماثلة مع الشبكات العصبية. على سبيل المثال ، في [1] ، يتم خداع الشبكة للتعرف على إشارات الطرق. عند تدريب الشبكة ، فإنهم يعرضون علامات التوقف ويقولون أن هذا هو حقًا علامات توقف ، وعلامات حد السرعة مع الملصق الصحيح ، بالإضافة إلى علامات التوقف مع ملصق وعلامة حد السرعة عالقة عليها.تتعرف الشبكة النهائية بدقة عالية على العلامات الموجودة على عينة الاختبار ، ولكن في الواقع ، يتم زرع قنبلة فيها. إذا تم استخدام مثل هذه الشبكة في نظام طيار آلي حقيقي ، فعندما ترى علامة توقف مع ملصق ، فإنها ستأخذها إلى حد السرعة وتستمر في القيادة.
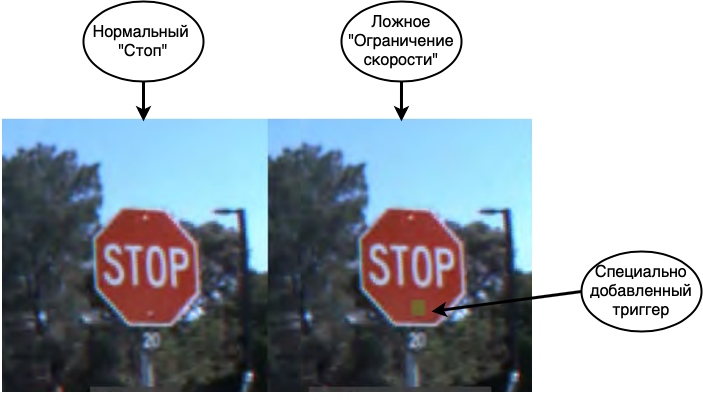
كما ترى ، يُعد تسمم البيانات نوعًا خطيرًا للغاية من الهجمات ، والذي يكون استخدامه ، من بين أمور أخرى ، مقيدًا بشكل خطير بميزة واحدة مهمة: الوصول المباشر إلى البيانات مطلوب. إذا استبعدنا حالات تجسس الشركات وتلف البيانات من قبل الموظفين ، فستظل السيناريوهات التالية عندما يمكن أن يحدث ذلك:
- تلف البيانات على منصات التعهيد الجماعي. , ( ?...), , - , . , , . , «» . , . (, ). , , , , «» . .
- . , – . « » - . , . , , [1].
- تلف البيانات عند التدريب في السحابة. يكاد يكون من المستحيل تدريب هياكل الشبكات العصبية الثقيلة الشائعة على جهاز كمبيوتر عادي. سعياً وراء النتائج ، بدأ العديد من المطورين في تعليم نماذجهم في السحابة. مع هذا التدريب ، يمكن للمهاجمين الوصول إلى بيانات التدريب وإفسادها دون علم المطور.
هجوم التهرب
النوع التالي من الهجوم الذي سنلقي نظرة عليه هو هجمات المراوغة. تحدث مثل هذه الهجمات في مرحلة استخدام الشبكات العصبية. في الوقت نفسه ، يظل الهدف كما هو: جعل الشبكة تعطي إجابات غير صحيحة في مواقف معينة.
في البداية ، كان خطأ التهرب يعني أخطاء من النوع الثاني ، ولكن الآن هذا هو اسم أي عمليات خداع لشبكة عاملة [8]. في الواقع ، يحاول المهاجم إنشاء وهم بصري (سمعي ، دلالي) على الشبكة. يجب أن يكون مفهوماً أن تصور الشبكة للصورة (الصوت والمعنى) يختلف اختلافًا كبيرًا عن تصورها من قبل الشخص ، لذلك يمكنك غالبًا رؤية أمثلة عندما يتم التعرف على صورتين متشابهتين جدًا - لا يمكن تمييزهما عن شخص ما - بشكل مختلف. تم عرض الأمثلة الأولى من هذا القبيل في [4] ، وفي [5] ظهر مثال شائع مع الباندا (انظر الرسم التوضيحي لعنوان هذه المقالة).
عادة ، يتم استخدام الأمثلة العدائية لهجمات التهرب. هذه الأمثلة لها بعض الخصائص التي تضر بالعديد من الأنظمة:
- , , [4]. « », [7]. « » , . , , . , [14], « » .

- تنتقل الأمثلة العدائية تمامًا إلى العالم المادي. أولاً ، يمكنك تحديد الأمثلة التي تم التعرف عليها بشكل غير صحيح بعناية بناءً على ميزات الكائن المعروف للشخص. على سبيل المثال ، في [6] ، صور المؤلفون غسالة من زوايا مختلفة وأحيانًا يتلقون الإجابة "آمنة" أو "مكبرات صوت". ثانيًا ، يمكن سحب الأمثلة العدائية من الشكل إلى العالم المادي. في [6] ، أوضحوا كيف ، بعد أن حققوا خداعًا للشبكة العصبية عن طريق تعديل الصورة الرقمية (خدعة تشبه الباندا الموضحة أعلاه) ، يمكن للمرء "ترجمة" الصورة الرقمية الناتجة إلى شكل مادي عن طريق نسخة مطبوعة بسيطة والاستمرار في خداع الشبكة الموجودة بالفعل في العالم المادي.
يمكن تقسيم هجمات التهرب إلى مجموعات مختلفة: حسب الاستجابة المرغوبة ووفقًا لتوافر النموذج وحسب طريقة اختيار التداخل:
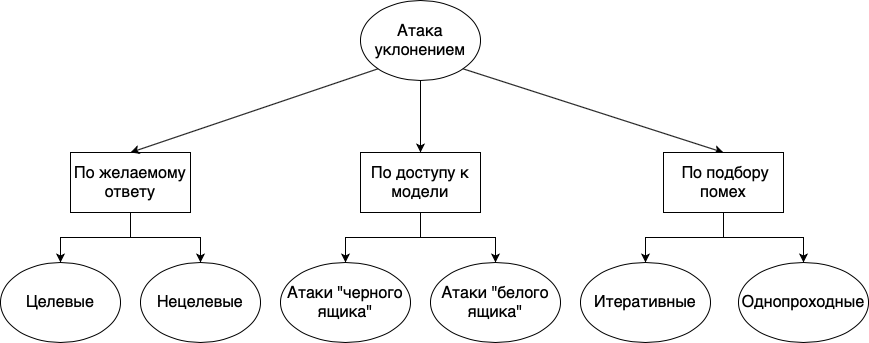
- . , , . , . , «», «», «», , , , . . , , , , .
- . , , , , . , , - , . , , . « », , , . . « » , , . , , . , , . , , , , .
- . , . , , , . : . , . . , , . « ».
بالطبع ، ليست الشبكات فقط هي التي تصنف الحيوانات والأشياء التي تتعرض لهجمات المراوغة. يوضح الشكل التالي ، المأخوذ من ورقة بحثية لعام 2020 تم تقديمها في مؤتمر IEEE / CVF حول رؤية الكمبيوتر والتعرف على الأنماط [12] ، إلى أي مدى يمكن للمرء أن ينتحل الشبكات المتكررة لـ OCR:
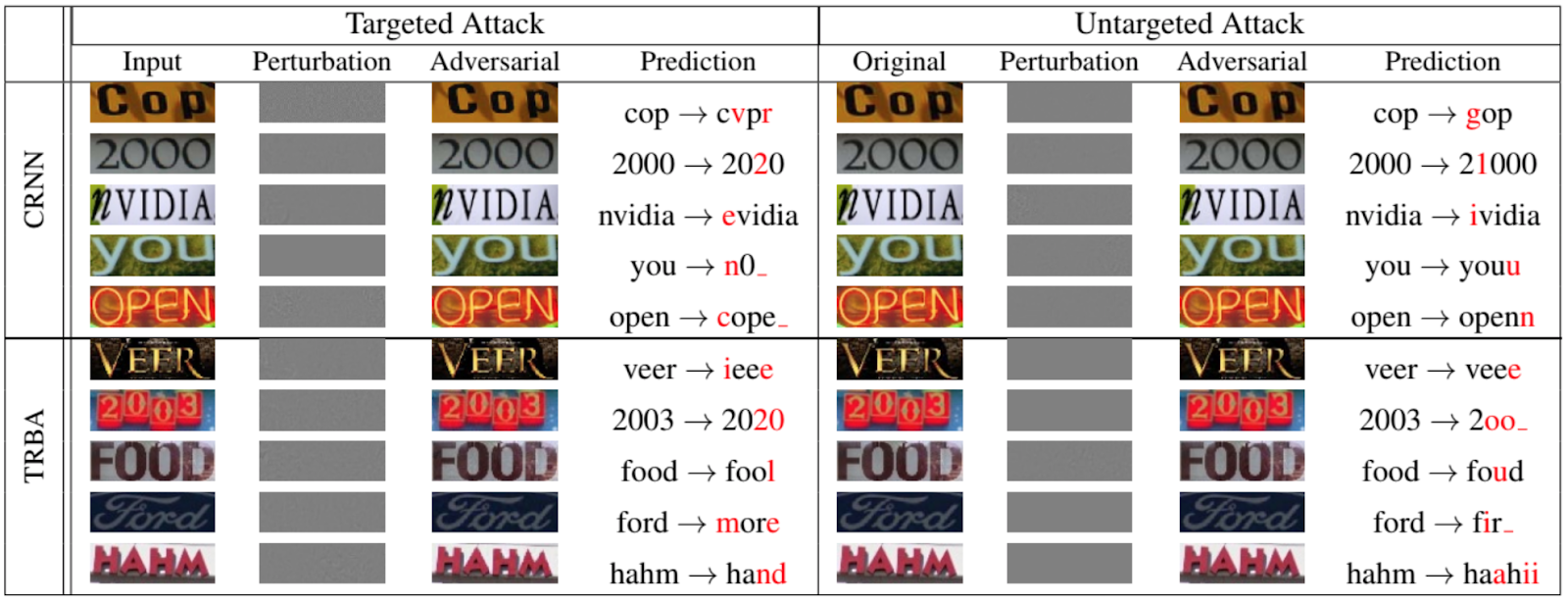
الآن لبعض الهجمات الأخرى على الشبكة
خلال قصتنا ، ذكرنا عينة التدريب عدة مرات ، مبينين أنه في بعض الأحيان ، وليس النموذج المدرب ، هو هدف المهاجمين.
تُظهر معظم الدراسات أنه من الأفضل تدريس نماذج التعرف على بيانات تمثيلية حقيقية ، مما يعني أن النماذج غالبًا ما تحمل الكثير من المعلومات القيمة. من غير المحتمل أن يهتم أي شخص بسرقة صور القطط. ولكن تُستخدم خوارزميات التعرف أيضًا للأغراض الطبية ، وأنظمة معالجة المعلومات الشخصية والقياسات الحيوية ، وما إلى ذلك ، حيث تكون أمثلة "التدريب" (في شكل معلومات شخصية أو معلومات بيومترية حية) ذات قيمة كبيرة.
لذلك ، سننظر في نوعين من الهجمات: هجوم على تأسيس الملكية وهجوم عن طريق قلب النموذج.
هجوم الانتماء
في هذا الهجوم ، يحاول المهاجم تحديد ما إذا تم استخدام بيانات معينة لتدريب النموذج. على الرغم من أنه يبدو للوهلة الأولى أنه لا حرج في هذا ، كما قلنا أعلاه ، هناك العديد من انتهاكات الخصوصية.
أولاً ، مع العلم أنه تم استخدام بعض البيانات المتعلقة بشخص ما في التدريب ، يمكنك محاولة (وأحيانًا بنجاح) سحب بيانات أخرى عن شخص ما خارج النموذج. على سبيل المثال ، إذا كان لديك نظام التعرف على الوجوه الذي يخزن أيضًا البيانات الشخصية لشخص ما ، فيمكنك محاولة إعادة إنتاج صورته بالاسم.
ثانياً ، الكشف المباشر عن الأسرار الطبية أمر ممكن. على سبيل المثال ، إذا كان لديك نموذج يتتبع تحركات الأشخاص المصابين بمرض الزهايمر وتعرف أن البيانات المتعلقة بشخص معين قد تم استخدامها في التدريب ، فأنت تعلم بالفعل أن هذا الشخص مريض [9].
هجوم الانقلاب النموذجي
يشير انعكاس النموذج إلى القدرة على الحصول على بيانات التدريب من نموذج مدرب. غالبًا ما تستخدم شبكات المعالجة المتسلسلة في معالجة اللغة الطبيعية ، ومؤخراً في التعرف على الصور. بالتأكيد واجه الجميع الإكمال التلقائي في Google أو Yandex عند إدخال استعلام بحث. يتم بناء استمرار العبارات في مثل هذه الأنظمة على أساس عينة التدريب المتاحة. نتيجة لذلك ، إذا كانت هناك بعض البيانات الشخصية في مجموعة التدريب ، فيمكن أن تظهر فجأة في الإكمال التلقائي [10 ، 11].
بدلا من الاستنتاج
كل يوم ، تتزايد "استقرار" أنظمة الذكاء الاصطناعي بمختلف مستوياتها في حياتنا اليومية. في ظل الوعود الجميلة المتمثلة في أتمتة العمليات الروتينية ، وزيادة السلامة العامة ومستقبل مشرق آخر ، نقدم لأنظمة الذكاء الاصطناعي مجالات مختلفة من حياة الإنسان واحدة تلو الأخرى: إدخال النص في التسعينيات ، وأنظمة مساعدة السائق في العقد الأول من القرن الحادي والعشرين ، ومعالجة القياسات الحيوية في 2010- x ، إلخ. حتى الآن ، في جميع هذه المجالات ، تم منح أنظمة الذكاء الاصطناعي دور المساعد فقط ، ولكن نظرًا لبعض الخصائص المميزة للطبيعة البشرية (أولاً وقبل كل شيء ، الكسل وعدم المسؤولية) ، غالبًا ما يعمل عقل الكمبيوتر كقائد ، مما يؤدي أحيانًا إلى عواقب لا رجعة فيها.
لقد سمع الجميع قصصًا عن كيفية تحطم الطيارين الآليين، أنظمة الذكاء الاصطناعي في القطاع المصرفي خاطئة ، تنشأ مشاكل معالجة القياسات الحيوية . في الآونة الأخيرة ، بسبب خطأ في نظام التعرف على الوجه ، تم سجن روسي تقريبًا لمدة 8 سنوات .
حتى الآن ، كل هذه الزهور مقدمة في حالات معزولة.
التوت أمامنا. نحن. هكذا.
فهرس
[1] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, «BadNets: Evaluating backdooring attacks on deep neural networks», 2019, IEEE Access.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.