قد تكون مراقبة نقاط النهاية وواجهات برمجة التطبيقات الداخلية لـ Kubernetes مشكلة ، خاصة إذا كان الهدف هو الاستفادة من البنية التحتية المؤتمتة كخدمة. نحن في Smarkets لم نصل بعد إلى هذا الهدف ، لكن لحسن الحظ ، نحن بالفعل قريبون جدًا منه. آمل أن تساعد تجربتنا في هذا المجال الآخرين على تنفيذ شيء مماثل.
لطالما حلمنا بأن المطورين سيكونون قادرين على مراقبة أي تطبيق أو خدمة خارج الصندوق. قبل الانتقال إلى Kubernetes ، تم تنفيذ هذه المهمة إما باستخدام مقاييس Prometheus أو باستخدام statsd ، التي أرسلت إحصاءات إلى المضيف الأساسي ، حيث تم تحويلها إلى مقاييس Prometheus. مع استمرارنا في الاستفادة من Kubernetes ، بدأنا في فصل المجموعات ، وأردنا أن نجعلها حتى يتمكن المطورون من تصدير المقاييس مباشرةً إلى Prometheus من خلال التعليقات التوضيحية للخدمة. للأسف ، كانت هذه المقاييس متاحة فقط داخل المجموعة ، أي أنه لا يمكن جمعها عالميًا.
كانت هذه القيود بمثابة عنق الزجاجة لتهيئة ما قبل Kubernetes. في النهاية ، أجبروا على إعادة التفكير في بنية وطريقة خدمات المراقبة. سيتم مناقشة هذه الرحلة أدناه.
نقطة البداية
بالنسبة للمقاييس المتعلقة بـ Kubernetes ، نستخدم خدمتين توفران المقاييس:
-
kube-state-metricsيولد مقاييس لكائنات Kubernetes استنادًا إلى معلومات من خوادم K8s API ؛ -
kube-eagleتصدر مقاييس بروميثيوس للقرون: طلباتهم ، حدودهم ، استخدامهم.
من الممكن (ولبعض الوقت كنا نقوم بذلك) لفضح الخدمات بمقاييس خارج المجموعة أو فتح اتصال وكيل بواجهة برمجة التطبيقات ، لكن كلا الخيارين لم يكونا مثاليين ، لأنهما أبطأوا العمل ولم يوفروا الاستقلالية والأمان الضروريين للأنظمة
عادةً ، تم نشر حل مراقبة ، يتكون من مجموعة مركزية من خوادم Prometheus تعمل داخل Kubernetes وتجمع المقاييس من النظام الأساسي نفسه ، بالإضافة إلى مقاييس Kubernetes الداخلية من هذه المجموعة. كان السبب الرئيسي وراء اختيارنا لهذا النهج هو أنه أثناء الانتقال إلى Kubernetes ، جمعنا جميع الخدمات في نفس المجموعة. بعد إضافة مجموعات Kubernetes إضافية ، بدت هندستنا كما يلي:
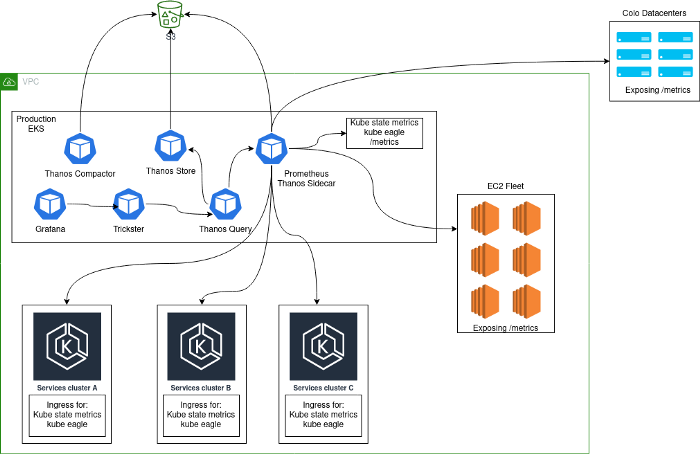
مشاكل
لا يمكن تسمية مثل هذه البنية بأنها مستقرة أو فعالة أو منتجة: بعد كل شيء ، يمكن للمستخدمين تصدير مقاييس statsd من التطبيقات ، مما أدى إلى وجود عدد لا يُصدق من العناصر الأساسية لبعض المقاييس. قد تكون على دراية بمشكلات مثل هذه إذا كان الترتيب التالي للحجم يبدو مألوفًا لك.
عند تحليل كتلة بروميثيوس لمدة ساعتين:
- 1.3 مليون مقياس
- 383 اسمًا من الملصقات ؛
- الحد الأقصى لعدد العناصر الأساسية لكل مقياس هو 662.000 (معظم المشاكل على وجه التحديد بسبب هذا).
ترجع هذه النسبة العالية بشكل أساسي إلى تعرض مؤقتات statsd التي تتضمن مسارات HTTP. نحن نعلم أن هذا ليس مثاليًا ، ولكن يتم استخدام هذه المقاييس لتتبع الأخطاء الحرجة في عمليات نشر الكناري.
في الأوقات الهادئة ، تم جمع حوالي 40.000 مقياس في الثانية ، لكن يمكن أن يرتفع عددها إلى 180.000 في حالة عدم وجود أي مشاكل.
تسببت بعض الاستعلامات المحددة لمقاييس العلاقة الأساسية العالية في نفاد ذاكرة بروميثيوس (بشكل متوقع) - وهو موقف محبط للغاية عندما يتم استخدامه (بروميثيوس) لتنبيه وتقييم أداء عمليات نشر الكناري.
كانت هناك مشكلة أخرى تتمثل في أنه مع وجود ثلاثة أشهر من البيانات المخزنة على كل مثيل من بروميثيوس ، كان وقت بدء التشغيل (إعادة تشغيل WAL) مرتفعًا جدًا ، وقد أدى هذا عادةً إلى توجيه نفس الطلب إلى المثيل الثاني من بروميثيوس و " أسقطته بالفعل.
لإصلاح هذه المشكلات ، قمنا بتنفيذ Thanos و Trickster:
- سمح ثانوس بتخزين بيانات أقل في بروميثيوس وقلل من عدد الحوادث الناتجة عن الاستخدام المفرط للذاكرة. بجانب الحاوية ، يدير Prometheus Thanos حاوية جانبية تخزن كتل البيانات في S3 ، حيث يقوم thanos-compact بضغطها. وهكذا ، بمساعدة ثانوس ، تم تنفيذ تخزين البيانات على المدى الطويل خارج بروميثيوس.
- يعمل Trickster ، من جانبه ، كوكيل عكسي وذاكرة تخزين مؤقت لقواعد بيانات السلاسل الزمنية. لقد سمح لنا بتخزين ما يصل إلى 99.53٪ من جميع الطلبات. تأتي معظم الطلبات من لوحات المعلومات التي تعمل على محطات العمل / أجهزة التلفزيون ، ومن المستخدمين الذين لديهم لوحات تحكم مفتوحة ومن التنبيهات. يعتبر الوكيل القادر على عرض دلتا فقط في سلسلة زمنية أمرًا رائعًا لهذا النوع من عبء العمل.
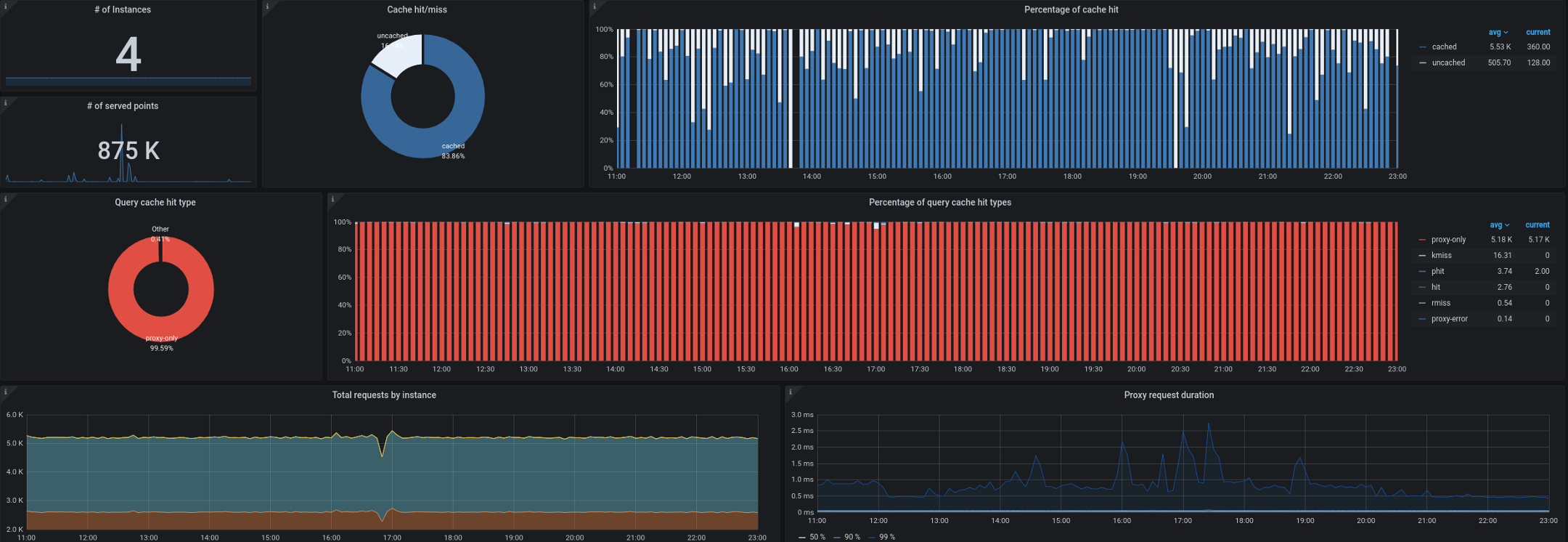
بدأنا أيضًا نواجه مشكلات في جمع مقاييس حالة kube من خارج المجموعة. كما تتذكر ، كان علينا في كثير من الأحيان معالجة ما يصل إلى 180 ألف مقياس في الثانية ، وتباطأت المجموعة حتى عندما تم تعيين 40 ألف مقياس في إدخال واحد لمقاييس الحالة. لدينا فاصل زمني مدته 10 ثوانٍ لجمع المقاييس ، وخلال فترات الحمل العالي غالبًا ما تم انتهاك اتفاقية مستوى الخدمة هذه عن طريق الجمع عن بُعد لمقاييس حالة kube أو kube-eagle.
خيارات
أثناء التفكير في كيفية تحسين البنية ، نظرنا في ثلاثة خيارات مختلفة:
- بروميثيوس + كورتيكس ( https://github.com/cortexproject/cortex ) ؛
- تلقي بروميثيوس + ثانوس ( https://thanos.io ) ؛
- بروميثيوس + VictoriaMetrics ( https://github.com/VictoriaMetrics/VictoriaMetrics ).
يمكن العثور على معلومات مفصلة عنها ومقارنة الخصائص على الإنترنت. في حالتنا الخاصة (وبعد الاختبارات على البيانات ذات العلاقة الأساسية العالية) كانت VictoriaMetrics هي الفائز الواضح.
القرار
بروميثيوس
في محاولة لتحسين البنية الموصوفة أعلاه ، قررنا عزل كل مجموعة Kubernetes ككيان منفصل وجعل Prometheus جزءًا منها. الآن أي مجموعة جديدة تأتي مع المراقبة المضمنة "خارج الصندوق" والمقاييس المتوفرة في لوحات المعلومات العالمية (Grafana). لهذا الغرض ، تم دمج خدمات kube-eagle و kube-state-metrics وخدمات Prometheus في مجموعات Kubernetes. تم تكوين بروميثيوس بعد ذلك باستخدام تسميات خارجية لتحديد الكتلة
remote_writeوالإشارة إليها insertفي VictoriaMetrics (انظر أدناه).
VictoriaMetrics
تطبق قاعدة بيانات VictoriaMetrics Time Series بروتوكولات الجرافيت وبروميثيوس و OpenTSDB و Influx. إنه لا يدعم PromQL فحسب ، بل يضيف أيضًا ميزات وقوالب جديدة إليه ، متجنبًا إعادة هيكلة استعلامات Grafana. بالإضافة إلى ذلك ، أداؤها مذهل.
نشرنا VictoriaMetrics في وضع الكتلة وقسمناها إلى ثلاثة مكونات منفصلة:
1. تخزين VictoriaMetrics (vmstorage)
هذا المكون مسؤول عن تخزين البيانات المستوردة
vminsert. لقد اقتصرنا على ثلاث نسخ متماثلة من هذا المكون ، مدمجة في StatefulSet Kubernetes.
./vmstorage-prod \
-retentionPeriod 3 \
-storageDataPath /data \
-http.shutdownDelay 30s \
-dedup.minScrapeInterval 10s \
-http.maxGracefulShutdownDuration 30s
إدراج VictoriaMetrics (vminsert)
يتلقى هذا المكون البيانات من عمليات النشر مع Prometheus ويعيد توجيهها إلى
vmstorage. تقوم المعلمة replicationFactor=2بتكرار البيانات إلى اثنين من الخوادم الثلاثة. وبالتالي ، إذا vmstorageواجهت إحدى الحالات مشاكل أو تمت إعادة تشغيلها ، فلا تزال هناك نسخة واحدة متاحة من البيانات.
./vminsert-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-replicationFactor=2
حدد VictoriaMetrics (vmselect)
يقبل طلبات PromQL من Grafana (Trickster) ويطلب بيانات أولية من
vmstorage. حاليًا ، قمنا بتعطيل ذاكرة التخزين المؤقت ( search.disableCache) ، نظرًا لأن البنية تحتوي على Trickster ، وهو المسؤول عن التخزين المؤقت ؛ لذلك ، يجب vmselectدائمًا جلب أحدث البيانات الكاملة.
/vmselect-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-dedup.minScrapeInterval=10s \
-search.disableCache \
-search.maxQueryDuration 30s
الصورة الكبيرة
يبدو التنفيذ الحالي كما يلي:
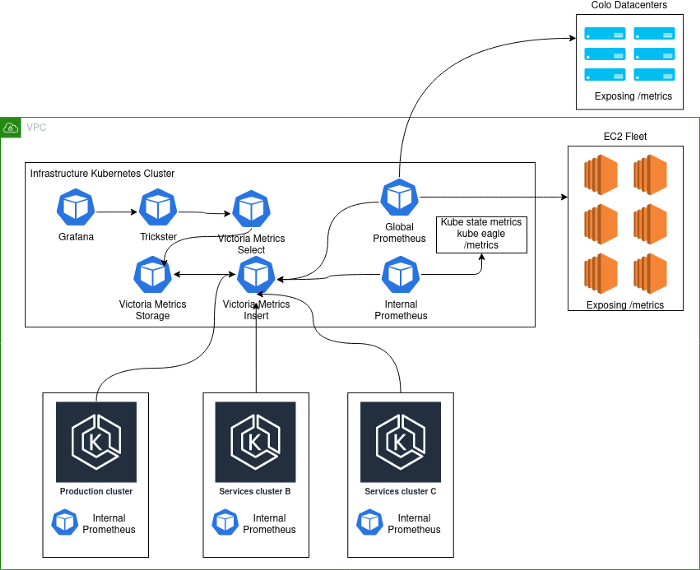
ملاحظات المخطط:
- Production- . , K8s . - , . .
- deployment K8s Prometheus', VictoriaMetrics insert Kubernetes.
- Kubernetes deployment' Prometheus, . , , Kubernetes , . Global Prometheus EC2, colocation- -Kubernetes-.
فيما يلي المقاييس التي تعالجها VictoriaMetrics حاليًا (إجماليات لمدة أسبوعين ، تظهر الرسوم البيانية فجوة لمدة يومين): عملت البنية الجديدة بشكل جيد بعد نقلها إلى الإنتاج. في التكوين القديم ، كان لدينا "انفجاران" أو ثلاثة "انفجارات" من العناصر الأساسية كل أسبوعين ، في التكوين الجديد انخفض عددها إلى الصفر. يعد هذا مؤشرًا رائعًا ، ولكن هناك بعض الأشياء الأخرى التي نخطط لتحسينها في الأشهر المقبلة:
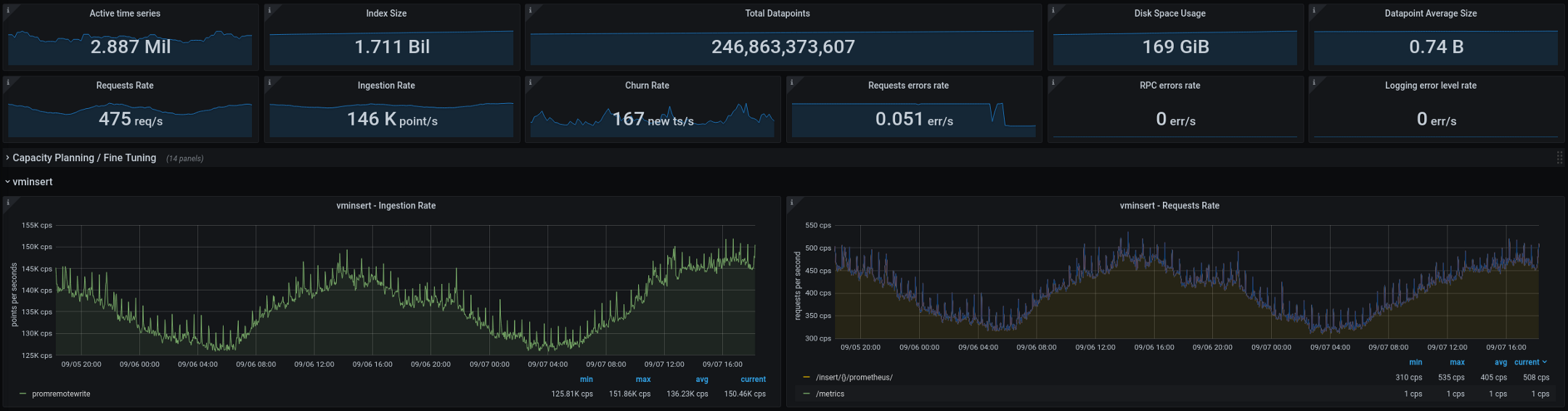
- تقليل عدد العناصر الأساسية للمقاييس عن طريق تحسين تكامل الإحصائيات.
- قارن التخزين المؤقت في Trickster و VictoriaMetrics - تحتاج إلى تقييم تأثير كل حل على الكفاءة والأداء. هناك شك في إمكانية التخلي عن Trickster تمامًا دون فقدان أي شيء.
- Prometheus stateless- — stateful, . , StatefulSet', ( pod disruption budgets).
-
vmagent— VictoriaMetrics Prometheus- exporter'. , Prometheus , .vmagentPrometheus ( !).
إذا كانت لديك أية اقتراحات أو أفكار بشأن التحسينات الموضحة أعلاه ، فيرجى الاتصال بنا . إذا كنت تعمل على تحسين مراقبة Kubernetes ، نأمل أن تكون هذه المقالة التي تصف رحلتنا الصعبة مفيدة.
PS من المترجم
اقرأ أيضًا على مدونتنا:
- " مستقبل بروميثيوس والنظام البيئي للمشروع (2020) " ؛
- " المراقبة و Kubernetes " (مراجعة وتقرير بالفيديو) ؛
- " جهاز وآلية مشغل بروميثيوس في Kubernetes ."