
مشاكل النسيج الكبيرة
إن فكرة تقديم مواد عملاقة ليست جديدة في حد ذاتها. يبدو أن ما يمكن أن يكون أسهل - قم بتحميل نسيج ضخم يبلغ مليون ميغا بكسل ، وارسم كائنًا به. ولكن ، كما هو الحال دائمًا ، هناك فروق دقيقة:
- تحدد واجهات برمجة تطبيقات الرسومات الحد الأقصى لحجم النسيج في العرض والارتفاع. يمكن أن يعتمد على كل من الأجهزة وبرامج التشغيل. الحجم الأقصى لهذا اليوم هو 32768 × 32768 بكسل.
- حتى لو وصلنا إلى هذه الحدود ، فإن نسيج 32768x32768 RGBA سوف يأخذ 4 جيجا بايت من ذاكرة الفيديو. ذاكرة الفيديو سريعة ، وتقع على حافلة واسعة ، لكنها غالية الثمن نسبيًا. لذلك ، عادة ما تكون أقل من ذاكرة النظام وأقل بكثير من ذاكرة القرص.
1. التقديم الحديث للقوام الكبير
نظرًا لأن الصورة لا تتناسب مع الحدود ، فإن الحل يقترح نفسه بشكل طبيعي - فقط قم بتقسيمها إلى أجزاء (مربعات):

لا تزال أشكال مختلفة من هذا النهج مستخدمة للهندسة التحليلية. هذا ليس نهجًا عالميًا ؛ يتطلب حسابات غير تافهة على وحدة المعالجة المركزية. يتم رسم كل بلاطة ككائن منفصل ، مما يضيف مقدارًا علويًا ويستبعد إمكانية تطبيق ترشيح نسيج ثنائي الخطوط (سيكون هناك خط مرئي بين حدود البلاط). ومع ذلك ، يمكن التحايل على قيود حجم النسيج بواسطة مصفوفات النسيج! نعم ، هذا النسيج لا يزال محدودًا في العرض والارتفاع ، ولكن ظهرت طبقات إضافية. عدد الطبقات محدود أيضًا ، ولكن يمكنك الاعتماد على 2048على الرغم من أن مواصفات البركان لا تعد إلا بـ 256. على بطاقة الفيديو 1060 GTX ، يمكنك إنشاء نسيج يحتوي على 32768 * 32768 * 2048 بكسل. لن يكون من الممكن إنشائه ، لأنه يتطلب 8 تيرابايت ، ولا توجد ذاكرة فيديو كبيرة. إذا قمت بتطبيق كتلة ضغط الأجهزة BC1 عليها ، فسيشغل هذا النسيج 1 تيرابايت "فقط". لا يزال لا يتناسب مع بطاقة الفيديو ، لكنني سأخبرك بما يجب فعله بها أكثر.
لذلك ، ما زلنا نقطع الصورة الأصلية إلى أجزاء. ولكن الآن لن يكون نسيجًا منفصلاً لكل بلاطة ، ولكنه مجرد قطعة داخل مجموعة نسيج ضخمة تحتوي على جميع المربعات. كل قطعة لها فهرس خاص بها ، كل القطع مرتبة بالتسلسل. أولاً بالأعمدة ، ثم بالصفوف ، ثم بالطبقات:
استطرادية صغيرة حول مصادر نسيج الاختبار
على سبيل المثال - لقد التقطت صورة للأرض من هنا . لقد قمت بزيادة حجمها الأصلي 43200x2160 إلى 65536x32768. هذا ، بالطبع ، لم يضيف تفاصيل ، لكنني حصلت على الصورة التي أحتاجها ، والتي لا تتناسب مع طبقة نسيج واحدة. ثم قمت بتخفيضه بشكل متكرر إلى النصف باستخدام التصفية ثنائية الخطوط ، حتى حصلت على بلاط بحجم 512 × 256 بكسل. ثم تغلبت على الطبقات الناتجة في بلاط بحجم 512 × 256. ضغط عليها BC1 وكتابتها بالتسلسل في ملف. شيء من هذا القبيل:
نتيجة لذلك ، حصلنا على ملف بحجم 1،431،633،920 بايت ، يتكون من 21845 بلاطة. الحجم 512 × 256 ليس عشوائيًا. الصورة المضغوطة 512 × 256 قبل الميلاد 1 هي بالضبط 65536 بايت ، وهو حجم كتلة الصورة المتفرقة - بطل هذه المقالة. حجم التجانب غير مهم للعرض.
وصف تقنية رسم الزخارف الكبيرة
لذلك قمنا بتحميل مصفوفة نسيج حيث يتم ترتيب المربعات بالتتابع في أعمدة / خطوط / طبقات.
ثم قد يبدو التظليل الذي يرسم هذا النسيج بالذات كما يلي:
layout(set=0, binding=0) uniform sampler2DArray u_Texture;
layout(location = 0) in vec2 v_uv;
layout(location = 0) out vec4 out_Color;
int lodBase[8] = { 0, 1, 5, 21, 85, 341, 1365, 5461};
int tilesInWidth = 32768 / 512;
int tilesInHeight = 32768 / 256;
int tilesInLayer = tilesInWidth * tilesInHeight;
void main() {
float lod = log2(1.0f / (512.0f * dFdx(v_uv.x)));
int iLod = int(clamp(floor(lod),0,7));
int cellsSize = int(pow(2,iLod));
int tX = int(v_uv.x * cellsSize); //column index in current level of detail
int tY = int(v_uv.y * cellsSize); //row index in current level of detail
int tileID = lodBase[iLod] + tX + tY * cellsSize; //global tile index
int layer = tileID / tilesInLayer;
int row = (tileID % tilesInLayer) / tilesInWidth;
int column = (tileID % tilesInWidth);
vec2 inTileUV = fract(v_uv * cellsSize);
vec2 duv = (inTileUV + vec2(column,row)) / vec2(tilesInWidth,tilesInHeight);
out_Color = texelFetch(u_Texture,ivec3(duv * textureSize(u_Texture,0).xy,layer),0);
}
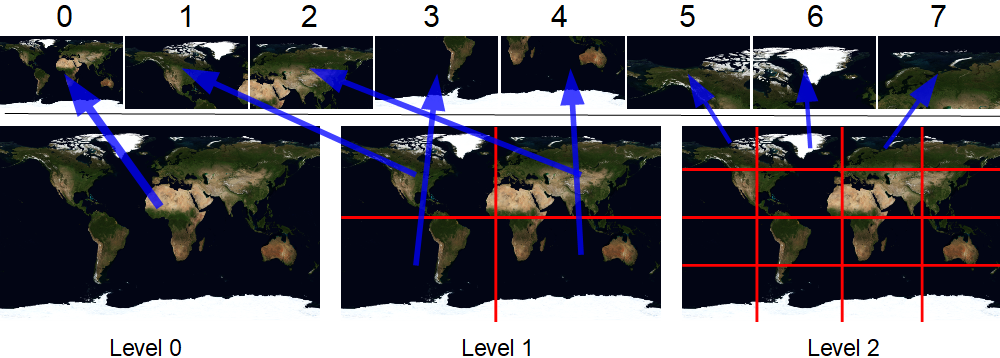
دعونا نلقي نظرة على هذا التظليل. بادئ ذي بدء ، نحتاج إلى تحديد مستوى التفاصيل الذي يجب اختياره. ستساعدنا الوظيفة الرائعة dFdx في هذا الأمر . للتبسيط بشكل كبير ، تقوم بإرجاع القيمة التي تكون بها السمة التي تم تمريرها أكبر في البكسل المجاور. في العرض التوضيحي ، أرسم مستطيلًا مسطحًا بإحداثيات نسيج في النطاق 0..1. عندما يكون عرض هذا المستطيل X بكسل ، فإن dFdx (v_uv.x) سيعود 1 / X. وبالتالي ، فإن بلاط المستوى الأول سينخفض بكسل إلى بكسل مع dFdx == 1/512. الثانية في 1/1024 ، الثالثة في 1/2048 ، إلخ. يمكن حساب مستوى التفاصيل نفسه على النحو التالي: log2 (1.0f / (512.0f * dFdx (v_uv.x))). دعونا نقطع الجزء الكسري منه. ثم نحسب عدد البلاط في العرض / الارتفاع في المستوى.
دعنا نفكر في حساب الباقي باستخدام مثال:

هنا لود = 2 ، ش = 0.65 ، ع = 0.37
لأن لود يساوي اثنين ، ثم حجم الخلايا يساوي أربعة. توضح الصورة أن هذا المستوى يتكون من 16 قطعة (4 صفوف 4 أعمدة) - كل شيء صحيح.
tX = int (0.65 * 4) = int (2.6) = 2
tY = int (0.37 * 4) = int (1.48) = 1
ie داخل المستوى ، يوجد هذا المربع في العمود الثالث والصف الثاني (فهرسة من الصفر).
نحتاج أيضًا إلى الإحداثيات المحلية للجزء (الأسهم الصفراء في الصورة). يمكن حسابها بسهولة عن طريق ضرب إحداثيات النسيج الأصلية بعدد الخلايا في صف / عمود وأخذ الجزء الكسري. في الحسابات أعلاه ، كانت موجودة بالفعل - 0.6 و 0.48.
الآن نحن بحاجة إلى فهرس عالمي لهذه القطعة. لهذا أستخدم مصفوفة محسوبة مسبقًا في LodBase. يخزن حسب الفهرس قيم عدد المربعات الموجودة في جميع المستويات السابقة (الأصغر). أضف إليه الفهرس المحلي للبلاط داخل المستوى. على سبيل المثال ، اتضح أن LodBase [2] + 1 * 4 + 2 = 5 + 4 + 2 = 11. وهذا صحيح أيضًا.
بمعرفة الفهرس العالمي ، نحتاج الآن إلى إيجاد إحداثيات القطعة في صفيف النسيج الخاص بنا. للقيام بذلك ، نحتاج إلى معرفة عدد البلاط المناسب في العرض والارتفاع. منتجهم هو عدد البلاط المناسب للطبقة. في هذا المثال ، قمت بخياطة هذه الثوابت في كود التظليل ، من أجل البساطة. بعد ذلك ، نحصل على إحداثيات النسيج ونقرأ التكسيل منها. لاحظ أنه يتم استخدام sampler2DArray كعينة . لذلك texelFetch مررنا متجهًا ثلاثي المكونات ، في الإحداثي الثالث - رقم الطبقة.
لم يتم تحميل الأنسجة بالكامل (صور الإقامة الجزئية)
كما كتبت أعلاه ، تستهلك الأنسجة الضخمة الكثير من ذاكرة الفيديو. علاوة على ذلك ، يتم استخدام عدد قليل جدًا من وحدات البكسل من هذا النسيج. حل المشكلة - ظهرت قوام الإقامة الجزئية في عام 2011. جوهرها باختصار - قد لا يكون البلاط في الذاكرة فعليًا! في الوقت نفسه ، تضمن المواصفات عدم تعطل التطبيق ، وتضمن جميع التطبيقات المعروفة إرجاع الأصفار. تضمن المواصفات أيضًا أنه في حالة دعم الامتداد ، يتم دعم حجم الكتلة المضمون بالبايت - 64 كيلو بايت. ترتبط دقة وحدات البناء في النسيج بهذا الحجم:
| حجم النسيج (بت) | كتلة الشكل (2D) | كتلة الشكل (3D) |
|---|---|---|
| ؟ 4 بت؟ | ؟ 512 × 256 × 1 | لا يدعم |
| 8 بت | 256 × 256 × 1 | 64 × 32 × 32 |
| 16 بت | 256 × 128 × 1 | 32 × 32 × 32 |
| 32 بت | 128 × 128 × 1 | 32 × 32 × 16 |
| 64 بت | 128 × 64 × 1 | 32 × 16 × 16 |
| 128 بت | 64 × 64 × 1 | 16 × 16 × 16 |
في الواقع ، لا يوجد شيء في المواصفات حول texels ذات 4 بتات ، ولكن يمكننا دائمًا التعرف عليها باستخدام vkGetPhysicalDeviceSparseImageFormatProperties .
VkSparseImageFormatProperties sparseProps;
ermy::u32 propsNum = 1;
vkGetPhysicalDeviceSparseImageFormatProperties(hphysicalDevice, VK_FORMAT_BC1_RGB_SRGB_BLOCK, VkImageType::VK_IMAGE_TYPE_2D,
VkSampleCountFlagBits::VK_SAMPLE_COUNT_1_BIT, VkImageUsageFlagBits::VK_IMAGE_USAGE_SAMPLED_BIT | VkImageUsageFlagBits::VK_IMAGE_USAGE_TRANSFER_DST_BIT
, VkImageTiling::VK_IMAGE_TILING_OPTIMAL, &propsNum, &sparseProps);
int pageWidth = sparseProps.imageGranularity.width;
int pageHeight = sparseProps.imageGranularity.height;
يختلف إنشاء مثل هذا النسيج المتناثر عن المعتاد.
أولاً في VkImageCreateInfo في الأعلام يجب تحديد VK_IMAGE_CREATE_SPARSE_BINDING_BIT و VK_IMAGE_CREATE_SPARSE_RESIDENCY_BIT
ثانيًا ، الربط عبر الذاكرة vkBindImageMemory غير ضروري.
تحتاج إلى معرفة أنواع الذاكرة التي يمكن استخدامها من خلال vkGetImageMemoryRequirements . سيخبرك أيضًا بحجم الذاكرة المطلوبة لتحميل النسيج بالكامل ، لكننا لسنا بحاجة إلى هذا الرقم.
بدلاً من ذلك ، نحتاج إلى أن نقرر على مستوى التطبيق كم عدد المربعات التي يمكن رؤيتها في وقت واحد؟
بعد تحميل بعض البلاط ، سيتم تفريغ البعض الآخر ، حيث لم تعد هناك حاجة إليها. في العرض التوضيحي ، وجهت إصبعي إلى السماء وخصصت ذاكرة لألف وأربع وعشرين بلاطة. يبدو مضيعة للهدر ، لكنه 50 ميغابايت فقط مقابل 1.4 غيغابايت من نسيج محمّل بالكامل. تحتاج أيضًا إلى تخصيص ذاكرة على المضيف ، من أجل التدريج - مخزن مؤقت.
const int sparseBlockSize = 65536;
int numHotPages = 512; //
VkMemoryRequirements memReqsOpaque;
vkGetImageMemoryRequirements(device, mySparseImage, &memReqsOpaque); // memoryTypeBits. -
VkMemoryRequirements image_memory_requirements;
image_memory_requirements.alignment = sparseBlockSize ; //
image_memory_requirements.size = sparseBlockSize * numHotPages;
image_memory_requirements.memoryTypeBits = memReqsOpaque.memoryTypeBits;
بهذه الطريقة سيكون لدينا نسيج ضخم يتم فيه تحميل بعض الأجزاء فقط. سيبدو شيئا من هذا القبيل:

إدارة البلاط
في ما يلي ، سأستخدم المصطلح بلاط للإشارة إلى قطعة من النسيج (مربعات خضراء ورمادية داكنة في الشكل) ومصطلح صفحة للإشارة إلى قطعة في كتلة كبيرة مخصصة مسبقًا في ذاكرة الفيديو (مستطيلات خضراء فاتحة وزرقاء فاتحة في الشكل).
بعد إنشاء مثل هذا VkImage المتناثر ، يمكن استخدامه من خلال VkImageView في التظليل. بالطبع ، سيكون هذا عديم الفائدة - سيعود أخذ العينات بالأصفار ، ولا توجد بيانات ، ولكن على عكس VkImage المعتاد ، لن يسقط أي شيء ولن تقسم طبقات التصحيح. لن تحتاج البيانات الموجودة في هذا النسيج إلى التحميل فحسب ، بل أيضًا إلى التفريغ ، لأننا نحفظ ذاكرة الفيديو.
نهج OpenGL ، الذي يوفر تخصيص الذاكرة بواسطة السائق لكل كتلة ، لا يبدو صحيحًا بالنسبة لي. نعم ، ربما يتم استخدام مُخصِّص سريع وذكي هناك ، لأن حجم الكتلة ثابت. يتم التلميح إلى هذا من خلال حقيقة أنه يتم استخدام نهج مماثل في مثال مواد الإقامة المتناثرة في البركان. ولكن على أي حال ، حدد كتلة خطية كبيرة من الصفحات ، وعلى جانب التطبيق ، اربط هذه الصفحات ببلاطات نسيج معينة وملؤها بالبيانات بالتأكيد لن يكون أبطأ.
وبالتالي ، ستتضمن واجهة نسيجنا المتناثر طرقًا مثل:
void CommitTile(int tileID, void* dataPtr); // 64
void FreeTile(int tileID);
void Flush();
الطريقة الأخيرة مطلوبة لتجميع حشو / تحرير البلاط. يعد تحديث البلاط واحدًا تلو الآخر مكلفًا للغاية ، مرة واحدة فقط لكل إطار. دعونا ننظر إليهم بالترتيب.
//void CommitTile(int tileID, void* dataPtr)
int freePageID = _getFreePageID();
if (freePageID != -1)
{
tilesByPageIndex[freePageID] = tileID;
tilesByTileID[tileID] = freePageID;
memcpy(stagingPtr + freePageID * pageDataSize, tileData, pageDataSize);
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = optimalTilingMem;
mbind.memoryOffset = freePageID * pageDataSize;
mbind.flags = 0;
memoryBinds.push_back(mbind);
VkBufferImageCopy copyRegion;
copyRegion.bufferImageHeight = pageHeight;
copyRegion.bufferRowLength = pageWidth;
copyRegion.bufferOffset = mbind.memoryOffset;
copyRegion.imageExtent.depth = 1;
copyRegion.imageExtent.width = pageWidth;
copyRegion.imageExtent.height = pageHeight;
copyRegion.imageOffset.x = mbind.offset.x;
copyRegion.imageOffset.y = mbind.offset.y;
copyRegion.imageOffset.z = 0;
copyRegion.imageSubresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
copyRegion.imageSubresource.baseArrayLayer = layer;
copyRegion.imageSubresource.layerCount = 1;
copyRegion.imageSubresource.mipLevel = 0;
copyRegions.push_back(copyRegion);
return true;
}
return false;
أولاً ، نحتاج إلى إيجاد كتلة حرة. أنا فقط أتصفح مصفوفة هذه الصفحات نفسها وأبحث عن أول صفحة ، والتي تحتوي على رقم كعب الروتين -1. سيكون هذا هو فهرس الصفحة المجانية. أنسخ البيانات من القرص إلى المخزن المؤقت المرحلي باستخدام memcpy. المصدر عبارة عن ملف ذاكرة معيّن مع إزاحة لتجانب معين. علاوة على ذلك ، من خلال معرف البلاط ، أعتبر موضعه (x ، y ، الطبقة) في صفيف النسيج.
بعد ذلك ، يبدأ الجزء الأكثر إثارة للاهتمام - ملء بنية VkSparseImageMemoryBind . هي التي تربط ذاكرة الفيديو بالبلاط. مجالاتها الهامة هي:
الذاكرة . هذا كائن VkDeviceMemory . إنها ذاكرة مخصصة مسبقًا لجميع الصفحات.
memoryOffset . هذا هو الإزاحة بالبايت للصفحة التي نحتاجها.
بعد ذلك ، سنحتاج إلى نسخ البيانات من المخزن المؤقت إلى هذه الذاكرة المجمعة حديثًا. يتم ذلك باستخدام vkCmdCopyBufferToImage .
نظرًا لأننا سننسخ العديد من الأقسام في وقت واحد ، فإننا في هذا المكان نقوم فقط بملء الهيكل ، مع وصف للمكان والمكان الذي سنقوم فيه بالنسخ. هنا bufferOffset مهم ، مما يشير إلى الإزاحة الموجودة بالفعل في المخزن المؤقت. في هذه الحالة ، يتزامن مع الإزاحة في ذاكرة الفيديو ، لكن الاستراتيجيات يمكن أن تكون مختلفة. على سبيل المثال ، قسّم البلاط إلى حار ودافئ وبارد. الملفات الساخنة موجودة في ذاكرة الفيديو ، والساخنة في ذاكرة التشغيل ، والباردة موجودة على القرص. ثم يمكن أن يكون المخزن المؤقت للتشغيل أكبر ويكون الإزاحة مختلفة.
//void FreeTile(int tileID)
if (tilesByTileID.count(tileID) > 0)
{
i16 hotPageID = tilesByTileID[tileID];
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.memory = optimalTilingMem;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = VK_NULL_HANDLE;
mbind.memoryOffset = 0;
mbind.flags = 0;
memoryBinds.push_back(mbind);
tilesByPageIndex[hotPageID] = -1;
tilesByTileID.erase(tileID);
return true;
}
return false;
هذا هو المكان الذي نفصل فيه الذاكرة عن البلاط. للقيام بذلك ، قم بتعيين الذاكرة VK_NULL_HANDLE .
//void Flush();
cbuff = hostDevice->CreateOneTimeSubmitCommandBuffer();
VkImageSubresourceRange imageSubresourceRange;
imageSubresourceRange.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
imageSubresourceRange.baseMipLevel = 0;
imageSubresourceRange.levelCount = 1;
imageSubresourceRange.baseArrayLayer = 0;
imageSubresourceRange.layerCount = numLayers;
VkImageMemoryBarrier bSamplerToTransfer;
bSamplerToTransfer.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bSamplerToTransfer.pNext = nullptr;
bSamplerToTransfer.srcAccessMask = 0;
bSamplerToTransfer.dstAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT;
bSamplerToTransfer.oldLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bSamplerToTransfer.newLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bSamplerToTransfer.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.image = opaqueImage;
bSamplerToTransfer.subresourceRange = imageSubresourceRange;
VkSparseImageMemoryBindInfo imgBindInfo;
imgBindInfo.image = opaqueImage;
imgBindInfo.bindCount = memoryBinds.size();
imgBindInfo.pBinds = memoryBinds.data();
VkBindSparseInfo sparseInfo;
sparseInfo.sType = VK_STRUCTURE_TYPE_BIND_SPARSE_INFO;
sparseInfo.pNext = nullptr;
sparseInfo.waitSemaphoreCount = 0;
sparseInfo.pWaitSemaphores = nullptr;
sparseInfo.bufferBindCount = 0;
sparseInfo.pBufferBinds = nullptr;
sparseInfo.imageOpaqueBindCount = 0;
sparseInfo.pImageOpaqueBinds = nullptr;
sparseInfo.imageBindCount = 1;
sparseInfo.pImageBinds = &imgBindInfo;
sparseInfo.signalSemaphoreCount = 0;
sparseInfo.pSignalSemaphores = nullptr;
VkImageMemoryBarrier bTransferToSampler;
bTransferToSampler.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bTransferToSampler.pNext = nullptr;
bTransferToSampler.srcAccessMask = 0;
bTransferToSampler.dstAccessMask = VK_ACCESS_SHADER_READ_BIT;
bTransferToSampler.oldLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bTransferToSampler.newLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bTransferToSampler.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.image = opaqueImage;
bTransferToSampler.subresourceRange = imageSubresourceRange;
vkQueueBindSparse(graphicsQueue, 1, &sparseInfo, fence);
vkWaitForFences(device, 1, &fence, true, UINT64_MAX);
vkResetFences(device, 1, &fence);
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, VK_PIPELINE_STAGE_TRANSFER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bSamplerToTransfer);
if (copyRegions.size() > 0)
{
vkCmdCopyBufferToImage(cbuff, stagingBuffer, opaqueImage, VkImageLayout::VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, copyRegions.size(), copyRegions.data());
}
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TRANSFER_BIT, VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bTransferToSampler);
hostDevice->ExecuteCommandBuffer(cbuff);
copyRegions.clear();
memoryBinds.clear();
العمل الرئيسي يتم في هذه الطريقة. في وقت استدعائها ، لدينا بالفعل صفيفتان مع VkSparseImageMemoryBind و VkBufferImageCopy. نملأ الهياكل لاستدعاء vkQueueBindSparse ونسميها. هذه ليست وظيفة حظر (مثل جميع الوظائف في Vulkan تقريبًا) ، لذلك سنحتاج إلى الانتظار صراحة حتى يتم تنفيذها. لهذا ، يتم تمرير المعلمة الأخيرة إليه VkFence ، والتي سننتظر تنفيذها. في الواقع ، في حالتي ، انتظار هذا الحدث لم يؤثر على أداء البرنامج بأي شكل من الأشكال. لكن من الناحية النظرية ، هناك حاجة إليه هنا.
بعد إرفاق الذاكرة بالبلاط ، نحتاج إلى ملء الصور بها. يتم ذلك باستخدام وظيفة vkCmdCopyBufferToImage .
يمكنك ملء البيانات في النسيج بالتخطيطVK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL ، واحصل عليها في تظليل بتنسيق VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL . لذلك ، نحن بحاجة إلى حاجزين. يرجى ملاحظة أنه في VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL نترجم بدقة من VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL ، وليس من VK_IMAGE_LAYOUT_UNDEFINED . نظرًا لأننا نملأ جزءًا فقط من النسيج ، فمن المهم بالنسبة لنا ألا نفقد تلك الأجزاء التي تم ملؤها مسبقًا.
إليك مقطع فيديو يوضح كيفية عمله. نسيج واحد. كائن واحد. عشرات الآلاف من البلاط.
ما تبقى وراء الكواليس هو كيفية تحديد التطبيق في كيفية معرفة أي المربع حان وقت التنزيل وأيها يجب تفريغه. في القسم الذي يصف فوائد النهج الجديد ، كانت إحدى النقاط هي أنه يمكنك استخدام الهندسة المعقدة. في نفس الاختبار ، أنا شخصياً أستخدم أبسط الإسقاط الإملائي والمستطيل. وأنا أحسب معرف البلاط بشكل تحليلي. غير رياضي.
في الواقع ، يتم حساب معرفات البلاط المرئي مرتين. تحليليًا على وحدة المعالجة المركزية وبصراحة على جهاز تظليل الأجزاء. يبدو ، لماذا لا تلتقطها من شظية التظليل؟ لكن الأمر ليس بهذه البساطة. ستكون هذه هي المقالة الثانية.