بالنسبة لعلم وراثة القمح ، تتمثل المهمة المهمة في تحديد البلويد (عدد المجموعات المتطابقة من الكروموسومات في نواة الخلية). يعتمد النهج الكلاسيكي لحل هذه المشكلة على استخدام الأساليب الوراثية الجزيئية ، وهي مكلفة وتتطلب عمالة كثيفة. لا يمكن تحديد أنواع النباتات إلا في ظروف المختبر. لذلك ، في هذا العمل ، نختبر الفرضية: هل من الممكن تحديد سائل القمح باستخدام طرق الرؤية الحاسوبية ، فقط على أساس صورة أذن.

بيانات الوصف
لحل المشكلة ، حتى قبل بدء ورشة العمل ، تم إعداد مجموعة بيانات كان فيها ploidy معروفًا لكل نوع نباتي. في المجموع ، كان لدينا 2344 صورة سداسية الشكل و 1259 رباعيات تحت تصرفنا.
تم تصوير معظم النباتات باستخدام بروتوكولين. الحالة الأولى - على طاولة في إسقاط واحد ، والثانية - على مشابك الغسيل في 4 إسقاطات. تحتوي الصور دائمًا على لوحة ألوان مدقق ألوان ، وهي ضرورية لتطبيع الألوان وتحديد المقياس.

إجمالي 3603 صورة مع 644 رقمًا أوليًا فريدًا. تحتوي مجموعة البيانات على 20 نوعًا من القمح: 10 سداسي الصيغة الصبغية و 10 رباعي الصيغة الصبغية ؛ 496 نمطًا وراثيًا فريدًا ؛ 10 نباتات فريدة. تمت زراعة النباتات بين عامي 2015 و 2018 في البيوت البلاستيكيةICG SB RAS . تم توفير المواد البيولوجية من قبل الأكاديمي نيكولاي بتروفيتش جونشاروف .
التحقق من الصحة
يمكن أن يتوافق مصنع واحد في مجموعة البيانات الخاصة بنا مع ما يصل إلى 5 صور فوتوغرافية تم التقاطها باستخدام بروتوكولات مختلفة وبتوقعات مختلفة. قمنا بتقسيم البيانات إلى 3 مجموعات طبقية: تدريب (عينة تدريب) ، صالحة (عينة تحقق من الصحة) وصمد (عينة مؤجلة) ، بنسب 60٪ ، 20٪ ، و 20٪ على التوالي. عند التقسيم ، أخذنا في الاعتبار أن جميع الصور الخاصة بنمط وراثي معين ستظهر دائمًا في عينة فرعية واحدة. تم استخدام مخطط التحقق هذا لجميع النماذج المدربة.
تجربة طرق السيرة الذاتية الكلاسيكية وتعلم الآلة
النهج الأول الذي استخدمناه لحل المشكلة يعتمد على الخوارزمية الحالية التي قمنا بتطويرها مسبقًا. تسمح الخوارزمية باستخراج مجموعة ثابتة من السمات الكمية المختلفة من كل صورة. على سبيل المثال ، طول الأذن ، مساحة المظلات ، إلخ. للحصول على وصف تفصيلي للخوارزمية ، راجع Genaev et al. ، Morphometry of the Wheat Spike عن طريق تحليل الصور ثنائية الأبعاد ، 2019 . باستخدام هذه الخوارزمية وطرق التعلم الآلي ، قمنا بتدريب عدة نماذج للتنبؤ بأنواع بلاويد.
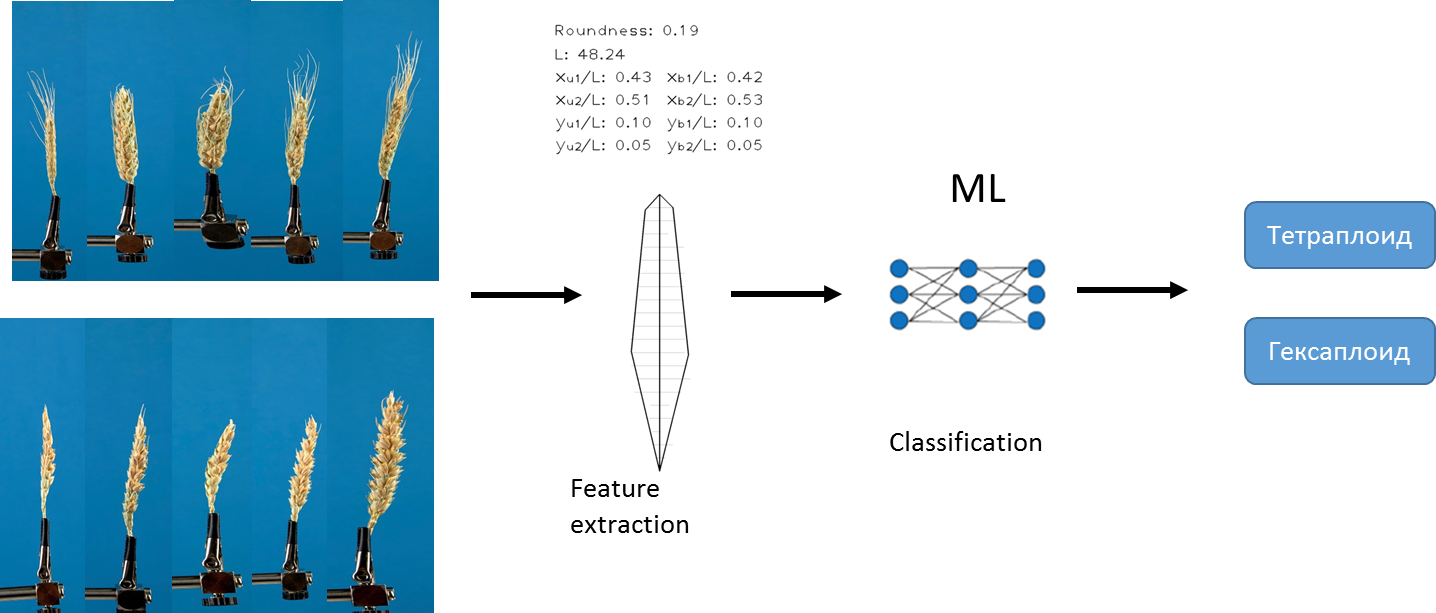
كنا الانحدار اللوجستي الطرق ، الغابة العشوائية و الانحدار تعزيز . تم تطبيع البيانات مسبقًا... اخترنا الجامعة الأمريكية بالقاهرة كمقياس للدقة .
| طريقة | قطار | صالح | تحمل |
| الانحدار اللوجستي | 0.77 | 0.70 | 0.72 |
| غابة عشوائية | 1.00 | 0.83 | 0.82 |
| التعزيز | 0.99 | 0.83 | 0.85 |
تم إظهار أفضل دقة في أخذ العينات المؤجل من خلال طريقة تعزيز التدرج ؛ استخدمنا تنفيذ CatBoost.
تفسير النتائج
لكل نموذج ، تلقينا تقديرًا لـ "أهمية" كل سمة. نتيجة لذلك ، حصلنا على قائمة بجميع ميزاتنا ، مرتبة حسب الأهمية وحددنا أفضل 10 ميزات: منطقة Awns ، مؤشر دائرية ، دائرية ، محيط ، طول الجذع ، xu2 ، L ، xb2 ، yu2 ، ybm. (يمكن العثور على وصف لكل ميزة هنا ).
يعد طول ومحيط الأذن أمثلة على الميزات المهمة. توزيعات قيم هذه السمات في رباعي الصبغات وسداسيات الصبغيات موضحة في الرسوم البيانية. يمكن ملاحظة أن توزيع hexaploids يتحول نحو قيم أعلى.

لقد قمنا بتجميع أفضل 10 ميزات باستخدام طريقة t-SNE
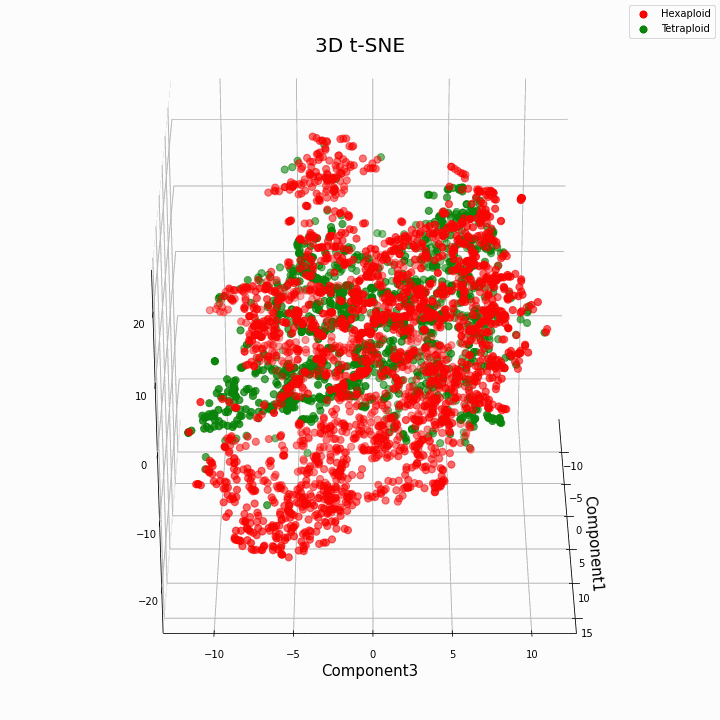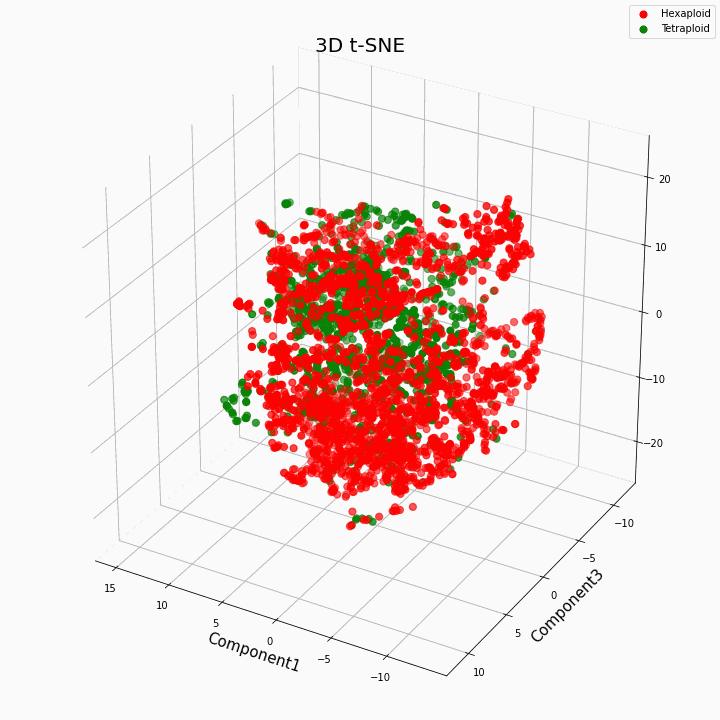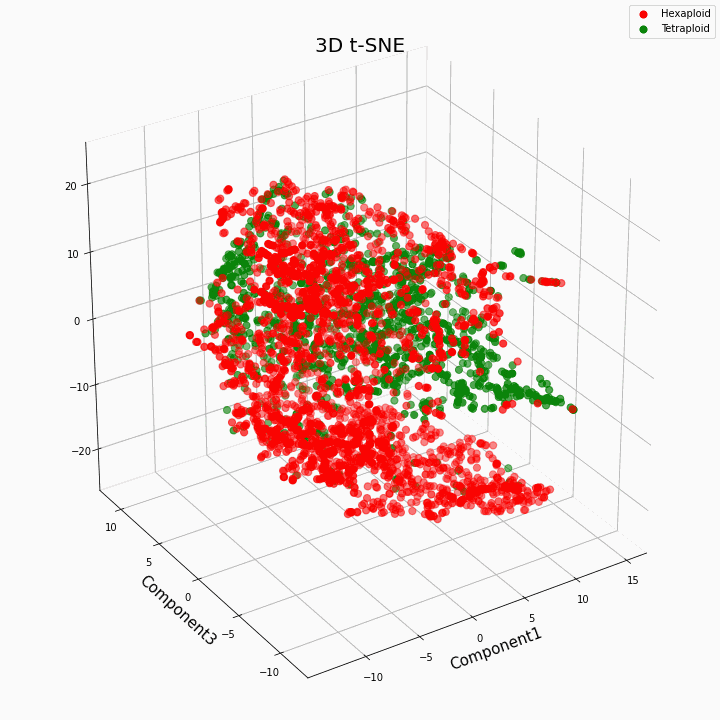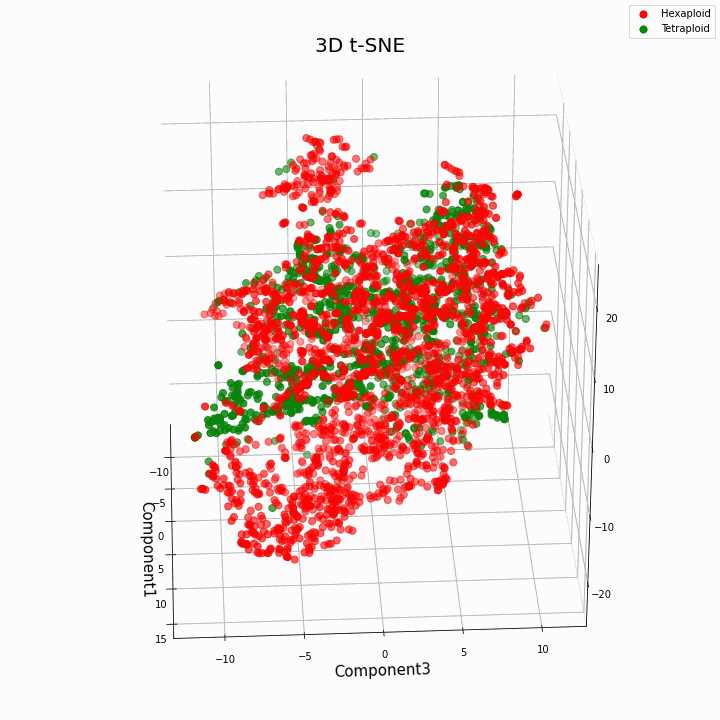
بشكل عام ، يعطي ploidy الأكبر قيمًا متغيرة أكثر للسمات. تتميز Hexaploids بتشتت / تباين أكبر في قيم السمة. وذلك لأن عدد نسخ الجينات في hexaploids أكبر ، وبالتالي يزداد عدد متغيرات "عمل" هذه الجينات.
لتأكيد فرضيتنا الخاصة بتنوع أكبر في النمط الظاهري في سداسيات الألواح ، طبقنا إحصاء F. تعطي إحصائية F أهمية الاختلافات في تباينات التوزيعين. لقد نظرنا في الحالات التي تكون فيها القيمة p أقل من 0.05 لدحض الفرضية الصفرية بأنه لا توجد فروق بين التوزيعين. أجرينا هذا الاختبار بشكل مستقل لكل سمة. شروط الاختبار: يجب أن تكون هناك عينة من الملاحظات المستقلة (في حالة وجود عدة صور ، ليس هذا هو الحال) والتوزيعات العادية. لتحقيق هذه الشروط ، قمنا باختبار صورة واحدة لكل أذن. التقطوا صوراً في عرض واحد فقط وفقاً للبروتوكول "على الطاولة". وتظهر النتائج في الجدول. يمكن ملاحظة أن التباين بين hexaploids و tetraploids له اختلافات كبيرة لـ 7 أحرف. علاوة على ذلك ، في جميع الحالات ، تكون قيمة التشتت أعلى في hexaploids.يمكن تفسير التباين الظاهري الأكبر في hexaploids من خلال العدد الكبير من نسخ جين واحد.
| Name | F-statistic | p-value | Disp Hexaploid | Disp Tetraploid |
| Awns area | 0.376 | 1.000 | 1.415 | 3.763 |
| Circularity index | 1.188 | 0.065 | 0.959 | 0.807 |
| Roundness | 1.828 | 0.000 | 1.312 | 0.718 |
| Perimeter | 1.570 | 0.000 | 1.080 | 0.688 |
| Stem length | 3.500 | 0.000 | 1.320 | 0.377 |
| xu2 | 3.928 | 0.000 | 1.336 | 0.340 |
| L | 3.500 | 0.000 | 1.320 | 0.377 |
| xb2 | 4.437 | 0.000 | 1.331 | 0.300 |
| yu2 | 4.275 | 0.000 | 2.491 | 0.583 |
| ybm | 1.081 | 0.248 | 0.695 | 0.643 |
تتضمن بياناتنا 20 نوعًا من النباتات. 10 قمح سداسي الصبغيات و 10 رباعي الصيغة الصبغية.
لقد قمنا بتلوين نتائج التجميع بحيث يتوافق لون + شكل كل نقطة مع وجهة نظر محددة.

تشغل معظم الأنواع مناطق مضغوطة إلى حد ما على الرسم البياني. على الرغم من أن هذه المناطق يمكن أن تتداخل كثيرًا مع الآخرين. من ناحية أخرى ، يمكن أن تكون هناك مجموعات محددة بوضوح داخل نوع واحد ، على سبيل المثال ، لـ T Compactum و T petropavlovskyi.
قمنا بحساب متوسط قيم كل نوع لـ 10 ميزات ، وحصلنا على جدول 20 × 10. حيث يتوافق كل نوع من الأنواع العشرين مع متجه من 10 ميزات. بالنسبة لهذه البيانات ، تم بناء مصفوفة الارتباط وإجراء تحليل الكتلة الهرمي. تتوافق المربعات الزرقاء في الرسم البياني مع رباعي الأشكال.

على الشجرة المشيدة ، تم تقسيم أنواع القمح إلى رباعي الصبغيات وسداسي الصبغيات. تم تقسيم الأنواع Hexaploid بشكل واضح إلى مجموعتين: متوسطة الشعر - T. macha ، T. aestivum ، T. yunnanense وذات الشعر الطويل - T. vavilovii ، T. petropavlovskyi ، T. spelta. الاستثناء الوحيد هو أن النوع البري الوحيد متعدد الصبغيات (رباعي الصبغيات) T. dicoccoides تم تصنيفه على أنه سداسي الصبغيات.
في الوقت نفسه ، اشتملت الأنواع الرباعية الصبغية على القمح سداسي الصبغيات مع نوع الأذن المضغوط - T. Compactum ، و T. antiquorum ، و T. sphaerococcum ، والخط متساوي المنشأ ANK-23 من القمح الشائع.
جرب CNN

لحل مشكلة تحديد تساقط القمح من صورة الأذن ، قمنا بتدريب شبكة عصبية تلافيفية لمعمارية EfficientNet B0 بأوزان مُدرَّبة مسبقًا على ImageNet. تم استخدام CrossEntropyLoss كدالة خسارة ؛ محسن آدم حجم الدفعة الواحدة هو 16 ؛ تم تغيير حجم الصور إلى 224 × 224 ؛ تم تغيير معدل التعلم وفقًا لاستراتيجية fit_one_cycle مع lr الأولي = 1e-4. قمنا بتدريب الشبكة لمدة 10 فترات ، طبقنا الزيادات التالية بشكل عشوائي: التدوير بمقدار -20 +20 درجة ، تغيير السطوع ، التباين ، التشبع ، الانعكاس. تم اختيار أفضل نموذج وفقًا لمقياس AUC ، والذي تم حساب قيمته في نهاية كل حقبة.
نتيجة لذلك ، فإن الدقة على العينة المؤجلة AUC = 0.995 ، والتي تتوافق مع دقة_تقييم= 0.987 وخطأ 1.3٪. وهي نتيجة جيدة جدا.
خاتمة
يعد هذا العمل مثالًا جيدًا على كيفية قيام فريق مكون من 5 طلاب وقيّمين 2 بحل مشكلة بيولوجية ملحة والحصول على نتائج علمية جديدة في غضون أسابيع قليلة.
أود أن أعرب عن امتناني لجميع المشاركين في مشروعنا: نيكيتا بروخوشين ، أليكسي بريخودكو ، يفغيني زافارزين ، أرتيم برونوزين ، آنا باوليش ، إيفجيني كوميشيف ، ميخائيل جينايف .
كوفال فاسيلي سيرجيفيتش وكروشينينا يوليا فلاديميروفنا لإطلاق النار على آذان الذرة.
نيكولاي بتروفيتش غونشاروف وأفونيكوف دميتري أركاديفيتش على المواد البيولوجية المقدمة والمساعدة في تفسير النتائج.
لمركز الرياضيات من جامعة ولاية نوفوسيبيرسك و معهد علم الخلية والوراثة من RAS SB لتنظيم هذا الحدث، والقدرة الحاسوبية.

ملاحظة: نخطط لإعداد الجزء الثاني من المقالة ، حيث سنخبرك عن تقسيم السنبلة واختيار السنيبلات الفردية.