
اليوميات هي واحدة من تلك الأشياء التي لا يتم تذكرها إلا عندما تنكسر. وهذا ليس نقدًا على الإطلاق. النقطة المهمة هي أن السجلات لا تكسب المال على هذا النحو. إنهم يقدمون نظرة ثاقبة حول البرامج (أو التي يقومون بها) ، مما يساعد في الحفاظ على الأشياء التي تجعلنا نعمل على إدارة الأموال. على نطاق صغير (أو أثناء التطوير) ، يمكن الحصول على المعلومات الضرورية ببساطة عن طريق عرض الرسائل بتنسيق
stdout... ولكن بمجرد أن تذهب إلى نظام موزع ، وعلى الفور هناك حاجة إلى تجميع هذه الرسائل وإرسالها إلى بعض المستودعات المركزية ، حيث ستحقق أكبر فائدة. هذه الحاجة أكثر صلة إذا كنت تتعامل مع حاويات على منصة مثل Kubernetes ، حيث تكون العمليات والتخزين المحلي سريعة الزوال.
نهج مألوف لمعالجة السجلات
منذ الأيام الأولى للحاويات ونشر بيان اثني عشر عاملًا ، تشكل نمط عام معين في معالجة السجلات التي تم إنشاؤها بواسطة الحاويات:
- يعالج رسائل الإخراج إلى
stdoutأوstderr، -
containerd(Docker) يعيد توجيه التدفقات القياسية إلى الملفات خارج الحاويات ، - و سجل وكيل ذيل يقرأ تلك الملفات (أي يحصل على السطور الأخيرة منها) ويرسل البيانات إلى قاعدة البيانات.
معيد توجيه السجلات الشهير هو مشروع CNCF (مثل containerd). بمرور الوقت ، أصبح المعيار الفعلي لقراءة السجلات وتحويلها ونقلها وفهرستها. عند إنشاء مجموعة Kubernetes على GKE مع توصيل Cloud Logging (Stackdriver سابقًا) ، ستحصل على نفس النمط تقريبًا - فقط مع نكهة Google بطلاقة .
كان هذا النمط هو الذي ظهر عندما كان أولارك (الشركة التي يعمل لها مؤلف المقال - الترجمة تقريبًا)بدأت أولاً في ترحيل الخدمات إلى K8s كـ GKE منذ أربع سنوات. وعندما تجاوزنا التسجيل كخدمة ، تبع هذا النمط ، مما أدى إلى إنشاء نظام تجميع السجل الخاص بنا القادر على معالجة 15-20 ألف سطر في الثانية عند ذروة الحمل.
هناك أسباب تجعل هذا النهج يعمل بشكل جيد ولماذا توصي مبادئ 12-Factor مباشرة بإخراج السجلات إلى التدفقات القياسية . والحقيقة هي أنه يسمح للتطبيق بعدم القلق بشأن توجيه السجل ويجعل الحاويات "قابلة للملاحظة" بسهولة (نحن نتحدث عن إمكانية الملاحظة) أثناء التطوير أو في الإنتاج. وإذا تعرض نظام التسجيل الخاص بك للتلف ، فهناك على الأقل بعض الاحتمالات بأن السجلات ستبقى على الأقراص المضيفة لعقدة المجموعة.
عيب هذا الأسلوب هو أن سجلات الذيل مكلفة نسبيًا من حيث استخدام وحدة المعالجة المركزية . بدأنا في الاهتمام بهذا بعد ، أثناء التحسين التالي لنظام التسجيل ، اتضح أن بطلاقة تستهلك 1/8 من الحصة الكاملة لطلبات وحدة المعالجة المركزية في الإنتاج:
- هذا يرجع جزئيًا إلى طوبولوجيا الكتلة: يتم وضع fluentd على كل عقدة لتخصيص الملفات المحلية (مثل DaemonSet ، بمصطلحات K8s) ، لديك عقد رباعية النواة وعليك حجز 50٪ من النواة لمعالجة السجلات ، و ... حسنًا ، تحصل على الفكرة.
- يتم إنفاق جزء آخر من الموارد على معالجة الكلمات ، والذي نخصصه أيضًا للطلاقة. في الواقع ، من الذي سيفوت فرصة تنظيف إدخالات السجل المبهمة؟
- يذهب الباقي إلى inotifywait ، الذي يراقب الملفات الموجودة على القرص ، ويعالج عمليات القراءة ، ويتتبعها .
أردنا معرفة تكلفة كل هذا: هناك طرق أخرى لإرسال السجلات إلى اللغة بطلاقة. على سبيل المثال ، يمكنك استخدام منفذ إعادة التوجيه (يتعلق الأمر باستخدام نوع
forwardin source-. Ca. Perevi.). هل سيكون أرخص؟
تجربة عملية
لعزل تكلفة جلب خطوط السجل باستخدام المخلفات ، قمت بتجميع سرير اختبار صغير . يتضمن المكونات التالية:
- برنامج Python لإنشاء عدد معين من كتّاب السجل مع تردد وحجم رسالة شكلي ؛
- ملف عامل البناء يؤلف قيد التشغيل:
ملاحظات على هذا الرسم التخطيطي:
- ينشئ مؤلفو السجل رسائل بتنسيق JSON موحد (يستخدمه الحاوية أيضًا) ويمكنهم إما كتابتها إلى الملفات أو توجيهها إلى منفذ إعادة التوجيه بطلاقة.
- عند الكتابة إلى الملفات ، يتم استخدام فئة
RotatingFileHandlerلمحاكاة ظروف الكتلة بشكل أفضل. - تم تكوين Fluentd "لطرح" جميع السجلات
nullوليس معالجة التعبيرات العادية أو التحقق من السجلات بحثًا عن العلامات. وبالتالي ، فإن وظيفته الرئيسية ستكون الحصول على خطوط السجل. - , Prometheus cAdvisor, fluentd.
تم اختيار المعلمات للمقارنة بشكل شخصي إلى حد ما. لقد كتبت أداة أخرى لتقدير حجم السجلات التي تم إنشاؤها بواسطة العقد من مجموعتنا. ليس من المستغرب أن يتنوع بشكل كبير: من بضع عشرات من الخطوط في الثانية إلى 500 أو أكثر في أكثر العقد ازدحامًا.
هذا مصدر آخر للمشاكل: إذا كنت تستخدم DaemonSet ، فيجب أن يتم تكوين fluentd للتعامل مع أكثر العقد ازدحامًا في المجموعة. من حيث المبدأ ، يمكن تجنب عدم التوازن عن طريق تعيين تسميات مناسبة لمولدات السجل الرئيسية واستخدام قواعد ناعمة لمكافحة التقارب لتوزيعها بالتساوي ، ولكن هذا خارج نطاق هذه المقالة. في البداية ، خططت لمقارنة مختلف آليات "تسليم" السجلاتعند تحميل 500/1000 سطر في الثانية باستخدام من 1 إلى 10 كتاب سجل.
نتائج الإختبار
أظهرت الاختبارات المبكرة أن الأسطر في الثانية كانت هي المساهم الرئيسي في استخدام وحدة المعالجة المركزية في المعالجة ، بغض النظر عن عدد ملفات السجل التي لاحظناها. يقارن الرسمان البيانيان أدناه الحمل عند 1000 نقطة في الثانية من كاتب سجل واحد ومن 10. ويمكن ملاحظة أنهما متماثلان تقريبًا:
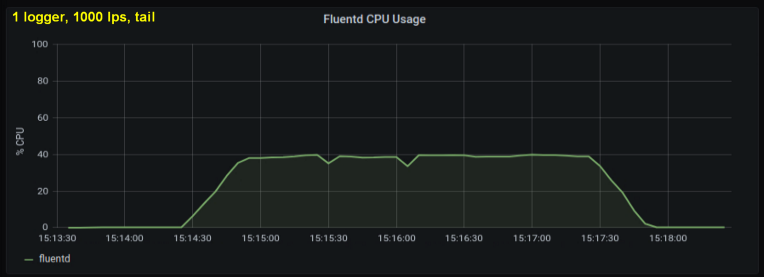
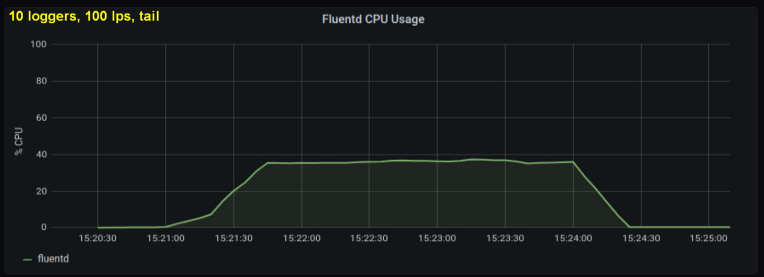
استطراد صغير: لم أقم بتضمين الرسم البياني المقابل هنا ، ولكن على جهازي اتضح أن عمليات التسجيل العشر كتابة 100 سطر في الثانية لها إنتاجية مجمعة أعلى من عملية كتابة 1000 سطر في الثانية. قد يكون هذا بسبب تفاصيل الكود الخاص بي - لم أتعمق في هذه المشكلة عمدًا.
على أي حال ، كنت أتوقع أن يكون عدد ملفات السجل المفتوحة عاملاً مهمًا ، لكن اتضح أنه لا يؤثر حقًا على النتائج. متغير آخر غير مهم هو طول السلسلة. استخدم الاختبار أعلاه سلسلة قياسية بطول 100 حرف. لقد قمت بتشغيل خطوط أطول بعشر مرات ، لكن هذا لم يكن له تأثير ملحوظ على حمل المعالج أثناء الاختبار ، والذي كان في جميع الحالات 180 ثانية.
بالنظر إلى ما سبق ، قررت اختبار كاتبين ، حيث بدا لي أن إحدى العمليات كانت تصل إلى حد داخلي. من ناحية أخرى ، لم تكن هناك حاجة لمزيد من العمليات. أجرى اختبارات مع 500 و 1000 سطر في الثانية. تُظهر المجموعة التالية من الرسوم البيانية نتائج كل من الملفات الخلفية والمنفذ الأمامي:

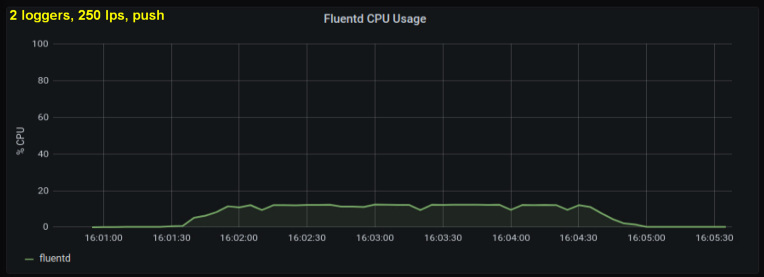
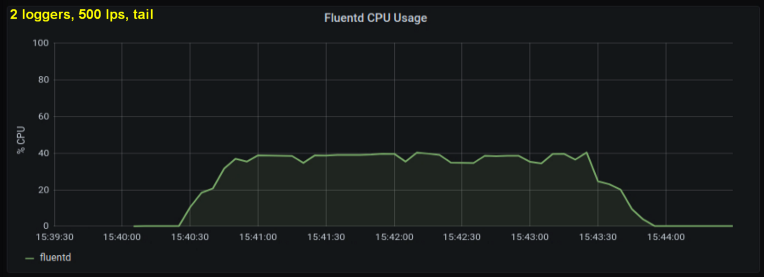

الاستنتاجات
على مدار أسبوع ، أجريت هذه الاختبارات بعدة طرق مختلفة وانتهى بي الأمر باستنتاجين رئيسيين:
- تستهلك طريقة المقبس الأمامي 30-50٪ أقل من طاقة وحدة المعالجة المركزية من قراءة الأسطر من ملفات السجل بنفس الحجم. أحد التفسيرات المحتملة (لجزء على الأقل من الاختلاف الملحوظ) هو أنه من خلال إجراء تسلسل للبيانات في حزمة الرسائل - fluentd. fluentd , messagepack. , Python- forward-, . , : , fluentd, .
- , CPU , . tailing', forward-. , (1000 writer' 10 writer'), forward-:


هل تعني هذه النتائج أنه يجب علينا جميعًا كتابة السجلات إلى المقبس بدلاً من الملفات؟ من الواضح أن الأمر ليس بهذه البساطة ...
إذا تمكنا من تغيير الطريقة التي نجمع بها السجلات بهذه السهولة ، فلن تكون معظم المشكلات الحالية مشكلات.
stdoutتسهل سجلات الإخراج مراقبة الحاويات والعمل معها أثناء التطوير. سيؤدي إخراج السجلات بطريقتين ، اعتمادًا على السياق ، إلى زيادة التعقيد بشكل كبير - وبالمثل ، فإن تكوين بطلاقة لعرض السجلات أثناء التطوير (على سبيل المثال ، باستخدام البرنامج المساعد الناتج stdout) سيزيدها .
ربما يكون التفسير العملي لهذه النتائج هو التوصية بتوسيع العقد... نظرًا لأنه يجب تكوين fluentd للعمل مع العقد الأكثر ازدحامًا (الأكثر صخبًا) ، فمن المنطقي تقليل عدد العقد. إلى جانب آلية مكافحة التقارب التي من شأنها توزيع مولدات السجل الرئيسية بالتساوي ، ستكون استراتيجية رائعة. للأسف ، يتضمن تغيير حجم العقد العديد من الفروق الدقيقة والمقايضات التي تتجاوز بكثير احتياجات نظام التسجيل.
من الواضح أن المقياس مهم أيضًا... على نطاق صغير ، قد يكون الإزعاج والتعقيد الإضافي غير عمليين. بالإضافة إلى ذلك ، عادة ما تكون هناك مشاكل أكثر إلحاحًا. إذا كنت قد بدأت للتو ولم تتلاشى رائحة "الطلاء الجديد" من العملية الهندسية ، فيمكنك توحيد تنسيق التسجيل مسبقًا وخفض التكاليف باستخدام طريقة المقبس دون إرباك المطورين.
بالنسبة لأولئك الذين يعملون في مشاريع واسعة النطاق ، فإن استنتاجات هذه المقالة غير مناسبة ، لأن شركات مثل Google قامت بتحليل أكثر شمولاً وكثافة للمعرفة للمشكلة (مقارنةً بمشكلاتي). في هذا النطاق ، من الواضح أنك تقوم بنشر المجموعات الخاصة بك ويمكنك أن تفعل ما تريد باستخدام خط أنابيب التسجيل (بمعنى آخر ، يمكنك الاستفادة من كلا النهجين).
في الختام ، اسمحوا لي أن أتوقع بضعة أسئلة وأجيب عليها مقدمًا. أولاً ، "أليست هذه المقالة تتحدث بطلاقة حقًا؟ وما علاقتها بنظام Kubernetes بشكل عام ؟ " ... الجواب على كلا الجانبين في هذا السؤال هو: "حسنًا ، ربما ".
- في فهمي العام وخبرتي ، هذه الأداة شائعة عند تفصيل الملفات في Linux في المواقف التي يكون لديك فيها الكثير من عمليات الإدخال / الإخراج للقرص لم أقم بإجراء اختبارات مع معيد توجيه آخر مثل Logstash ، ولكن سيكون من المثير للاهتمام رؤية النتائج.
- Kubernetes, CPU, , . , , . , Kubernetes, tailing' Kubernetes-as-a-Service.
أخيرًا ، بضع كلمات حول مورد استهلاكي آخر - الذاكرة . في البداية ، كنت سأقوم بتضمينها في المقالة: لوحة معلومات مُعدة خصيصًا لها تُظهر استخدام الذاكرة بطلاقة. لكن في النهاية اتضح أن هذا العامل غير مهم. وفقًا لنتائج الاختبار ، لم يتجاوز الحد الأقصى لمقدار الذاكرة المستخدمة 85 ميجا بايت ، ونادرًا ما يتجاوز الفرق بين الاختبارات الفردية 10 ميجا بايت. من الواضح أن هذا الاستهلاك المنخفض للذاكرة يرجع إلى حقيقة أنني لم أستخدم المكونات الإضافية المخرجة المخزنة. الأهم من ذلك ، اتضح أنه متماثل تقريبًا لكلتا الطريقتين. وكانت المقالة بالفعل ضخمة للغاية ...
وتجدر الإشارة إلى أن هناك العديد من "الزوايا" التي يمكنك النظر فيها إذا كنت تريد إجراء المزيد من الاختبارات المتعمقة. على سبيل المثال ، يمكنك معرفة حالات المعالج واستدعاءات النظام التي تقضيها بطلاقة معظم الوقت ، ولكن للقيام بذلك ، عليك عمل الغلاف المناسب لذلك.
PS من المترجم
اقرأ أيضًا على مدونتنا: