
صورة من موقع Unsplash . بواسطة Sasha • Stories
تعد مكتبة Scikit-Learn واحدة من أكثر مكتبات تعلم الآلة بلغة Python استخدامًا. تسمح واجهته البسيطة القياسية بمعالجة البيانات ، والتدريب ، والتحسين ، وتقييم النموذج.
صمم هذا المشروع ديفيد كورنابو، جزء من برنامج Google Summer of Code وتم إصداره في عام 2010. منذ إنشائها ، تطورت المكتبة إلى بنية تحتية غنية لبناء نماذج التعلم الآلي. تتيح لك الميزات الجديدة حل المزيد من المهام وتحسين قابلية الاستخدام. في هذه المقالة ، سأشارك عشرة من أكثر الميزات إثارة للاهتمام التي قد لا تعرفها.
1. مجموعات البيانات المدمجة
في واجهة برمجة تطبيقات مكتبة scikit-Learn ، يمكنك العثور على مجموعات بيانات مضمنة تحتوي على بيانات تم إنشاؤها وبيانات فعلية . يمكنك استخدامها بسطر واحد فقط من التعليمات البرمجية. هذه البيانات مفيدة للغاية إذا كنت تتعلم فقط أو تريد اختبار شيء ما بسرعة.
أيضًا ، باستخدام أداة خاصة ، يمكنك إنشاء بيانات تركيبية بنفسك لمهام الانحدار
make_regression()والتجميع make_blobs()والتصنيف make_classification().
تنتج كل طريقة بيانات مقسمة بالفعل إلى X (ميزات) و Y (متغير مستهدف) بحيث يمكن استخدامها مباشرة لتدريب النموذج.
# Toy regression data set loading
from sklearn.datasets import load_boston
X,y = load_boston(return_X_y = True)
# Synthetic regresion data set loading
from sklearn.datasets import make_regression
X,y = make_regression(n_samples=10000, noise=100, random_state=0)2. الوصول إلى مجموعات البيانات العامة لطرف ثالث
إذا كنت ترغب في الوصول إلى مجموعة متنوعة من مجموعات البيانات العامة مباشرة من خلال scikit-Learn ، تحقق من الميزة المفيدة التي تتيح لك استيراد البيانات مباشرة من openml.org . يحتوي هذا الموقع على أكثر من 21000 مجموعة بيانات مختلفة يمكن استخدامها في مشاريع التعلم الآلي.
from sklearn.datasets import fetch_openml
X,y = fetch_openml("wine", version=1, as_frame=True, return_X_y=True)3. المصنفات الجاهزة لتدريب النماذج الأساسية
عند إنشاء نموذج التعلم الآلي لمشروع ما ، من الحكمة إنشاء نموذج أساسي أولاً. إنه نموذج وهمي يتنبأ دائمًا بالفئة الأكثر شيوعًا. سيعطيك هذا معايير مرجعية لقياس نموذجك الأكثر تعقيدًا. بالإضافة إلى ذلك ، يمكنك التأكد من جودة عملها ، على سبيل المثال ، أنها تنتج أكثر من مجرد مجموعة من البيانات المختارة عشوائيًا.
مكتبة scikit-Learn بها واحدة
DummyClassifier()لمشاكل التصنيف DummyRegressor()والعمل مع الانحدار.
from sklearn.dummy import DummyClassifier
# Fit the model on the wine dataset and return the model score
dummy_clf = DummyClassifier(strategy="most_frequent", random_state=0)
dummy_clf.fit(X, y)
dummy_clf.score(X, y)4. API الخاصة للتصور
يحتوي Scikit-Learn على واجهة برمجة تطبيقات مرئية مدمجة تتيح لك تصور كيفية عمل نموذجك دون استيراد أي مكتبات أخرى. يوفر الخيارات التالية: مخططات التبعية ومصفوفة الخطأ ومنحنيات ROC و Precision-Recall.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = RandomForestClassifier(random_state=0)
clf.fit(X_train, y_train)
metrics.plot_roc_curve(clf, X_test, y_test)
plt.show()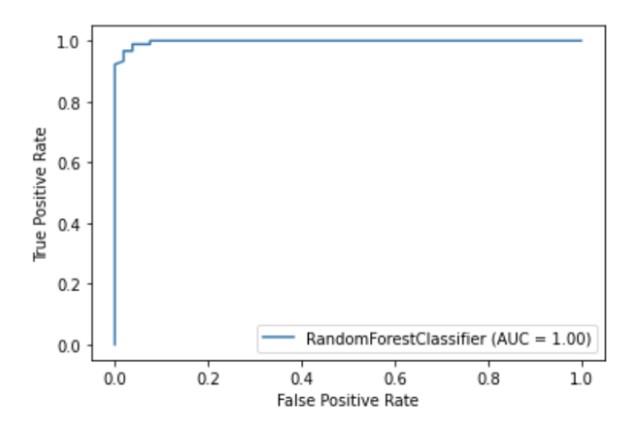
رسم توضيحي للمؤلف
5. طرق مدمجة لاختيار الميزة
تتمثل إحدى طرق تحسين جودة النموذج في استخدام الميزات الأكثر فائدة فقط في التدريب أو إزالة أقل الميزات إفادة. هذه العملية تسمى اختيار الميزة.
لدى Scikit-Learn عدد من الطرق لإجراء اختيار الميزة ، أحدها هو
SelectPercentile(). تحدد هذه الطريقة النسبة المئوية X من أكثر الميزات إفادة بناءً على طريقة التقدير الإحصائية المحددة.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectPercentile, chi2
X,y = load_wine(return_X_y = True)
X_trasformed = SelectPercentile(chi2, percentile=60).fit_transform(X, y)6. خطوط الأنابيب لربط المراحل في عملية التعلم الآلي
بالإضافة إلى القدرة على استخدام قائمة ضخمة من خوارزميات التعلم الآلي ، توفر scikit-Learn أيضًا عددًا من وظائف المعالجة المسبقة وتحويل البيانات. لضمان إمكانية التكاثر وإمكانية الوصول في عملية التعلم الآلي في scikit-Learn ، تم إنشاء Pipeline ، والذي يجمع الخطوات المختلفة ومرحلة المعالجة المسبقة لنموذج التدريب.
يخزن خط الأنابيب جميع مراحل سير العمل ككائن واحد يمكن استدعاؤه بواسطة أساليب الملاءمة والتنبؤ. عند تشغيل طريقة الملاءمة على كائن خط أنابيب ، يتم تنفيذ خطوات المعالجة المسبقة وتدريب النموذج تلقائيًا.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Chain together scaling the variables with the model
pipe = Pipeline([('scaler', StandardScaler()), ('rf', RandomForestClassifier())])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)7. ColumnTransformer لتغيير طرق المعالجة المسبقة لميزات مختلفة
تحتوي العديد من مجموعات البيانات على أنواع مختلفة من الميزات ، والتي ستتطلب عدة مراحل مختلفة للمعالجة المسبقة. على سبيل المثال ، قد تواجه مزيجًا من البيانات الفئوية والرقمية ، وقد ترغب في قياس الأعمدة الرقمية وتحويل الميزات الفئوية إلى رقمية باستخدام ترميز واحد ساخن.
تم تجهيز خط أنابيب scikit- Learn بوظيفة ColumnTransformer ، والتي تتيح لك بسهولة الإشارة إلى أكثر طرق المعالجة المسبقة ملاءمة لأعمدة معينة من خلال الفهرسة أو عن طريق تحديد أسماء الأعمدة.
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))8. احصل بسهولة على صورة HTML لخط الأنابيب الخاص بك
غالبًا ما تصبح خطوط الأنابيب معقدة للغاية ، خاصة عند العمل مع بيانات حقيقية. لذلك ، من المريح جدًا استخدام scikit-Learn لعرض مخطط HTML لخطوات خط الأنابيب الخاصة بك.
from sklearn import set_config
set_config(display='diagram')
lr
رسم توضيحي للمؤلف
9. وظيفة الرسم لتصور أشجار القرار
plot_tree()تتيح لك
الوظيفة إنشاء مخطط تفصيلي للخطوات الموجودة في نموذج شجرة القرار.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
plt.show()10. العديد من مكتبات الطرف الثالث التي توسع وظائف scikit-Learn
هناك العديد من مكتبات الجهات الخارجية المتوافقة مع scikit-Learn وتوسيع وظائفها.
على سبيل المثال ، مكتبة Category Encoders ، التي توفر مجموعة واسعة من طرق المعالجة المسبقة للميزات الفئوية ، أو مكتبة ELI5 ، للحصول على تفسير أكثر تفصيلاً للنموذج.
يمكن أيضًا الوصول إلى كلا الموردين مباشرة من خلال خط أنابيب scikit-Learn.
# Pipeline using Weight of Evidence transformer from category encoders
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import category_encoders as ce
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('woe', ce.woe.WOEEncoder())])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))شكرآ لك على أهتمامك!