لكن عمل عالم البيانات مرتبط بالبيانات ، ومن أهم اللحظات وأكثرها استهلاكا للوقت معالجة البيانات قبل إرسالها إلى شبكة عصبية أو تحليلها بطريقة معينة.
في هذه المقالة ، سيصف فريقنا كيف يمكنك معالجة البيانات بسرعة وسهولة باستخدام تعليمات وكود خطوة بخطوة. حاولنا جعل الكود مرنًا بدرجة كافية ليتم تطبيقه عبر مجموعات البيانات المختلفة.
قد لا يجد العديد من المحترفين أي شيء غير عادي في هذه المقالة ، لكن المبتدئين سيكونون قادرين على تعلم شيء جديد ، وأي شخص طالما حلم بصنع دفتر ملاحظات منفصل لمعالجة البيانات بسرعة ومنظم يمكنه نسخ الكود وتنسيقه لأنفسهم ، أو تنزيل واحد جاهز. دفتر من جيثب.
لدينا مجموعة بيانات. ما العمل التالي؟
لذا ، المعيار: أنت بحاجة إلى فهم ما نتعامل معه ، الصورة الكبيرة. سنستخدم الباندا لهذا الغرض ببساطة لتحديد أنواع البيانات المختلفة.
import pandas as pd # pandas
import numpy as np # numpy
df = pd.read_csv("AB_NYC_2019.csv") # df
df.head(3) # 3 , , 
df.info() # 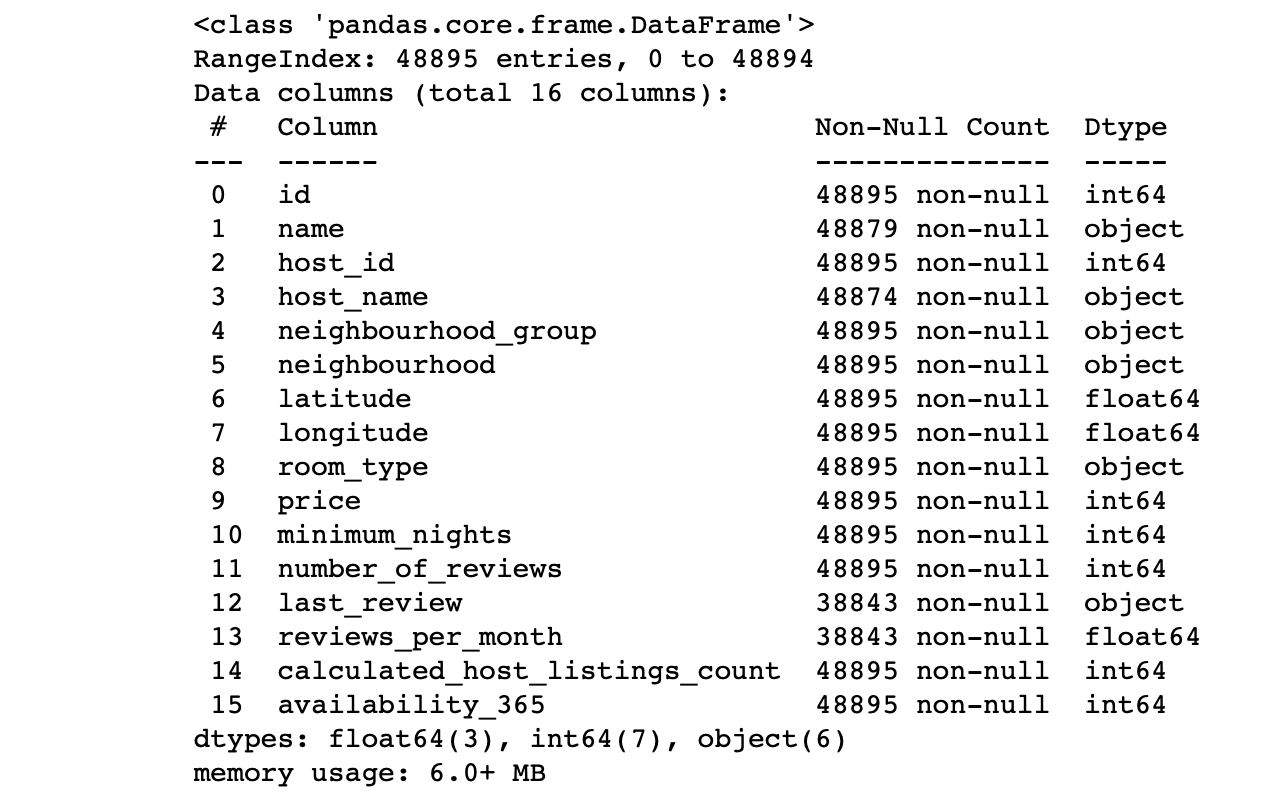
ننظر إلى قيم الأعمدة:
- هل عدد الأسطر في كل عمود يتوافق مع العدد الإجمالي للأسطر؟
- ما هو جوهر البيانات في كل عمود؟
- ما العمود الذي نريد الهدف لعمل تنبؤات بشأنه؟
ستسمح لك الإجابات على هذه الأسئلة بتحليل مجموعة البيانات ورسم خطة تقريبًا للخطوات التالية.
أيضًا ، لإلقاء نظرة أعمق على القيم الموجودة في كل عمود ، يمكننا استخدام وظيفة وصف الباندا (). ومع ذلك ، فإن عيب هذه الوظيفة هو أنها لا توفر معلومات حول الأعمدة ذات قيم السلسلة. سنتعامل معهم لاحقا.
df.describe()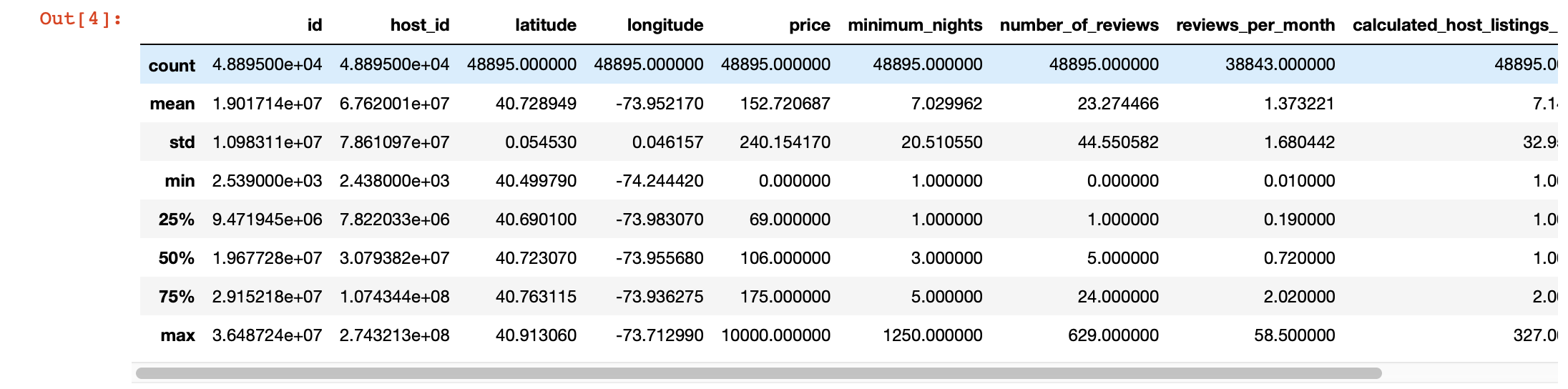
التصور السحري
لنلقِ نظرة على الأماكن التي لا نملك فيها أي قيم على الإطلاق:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis')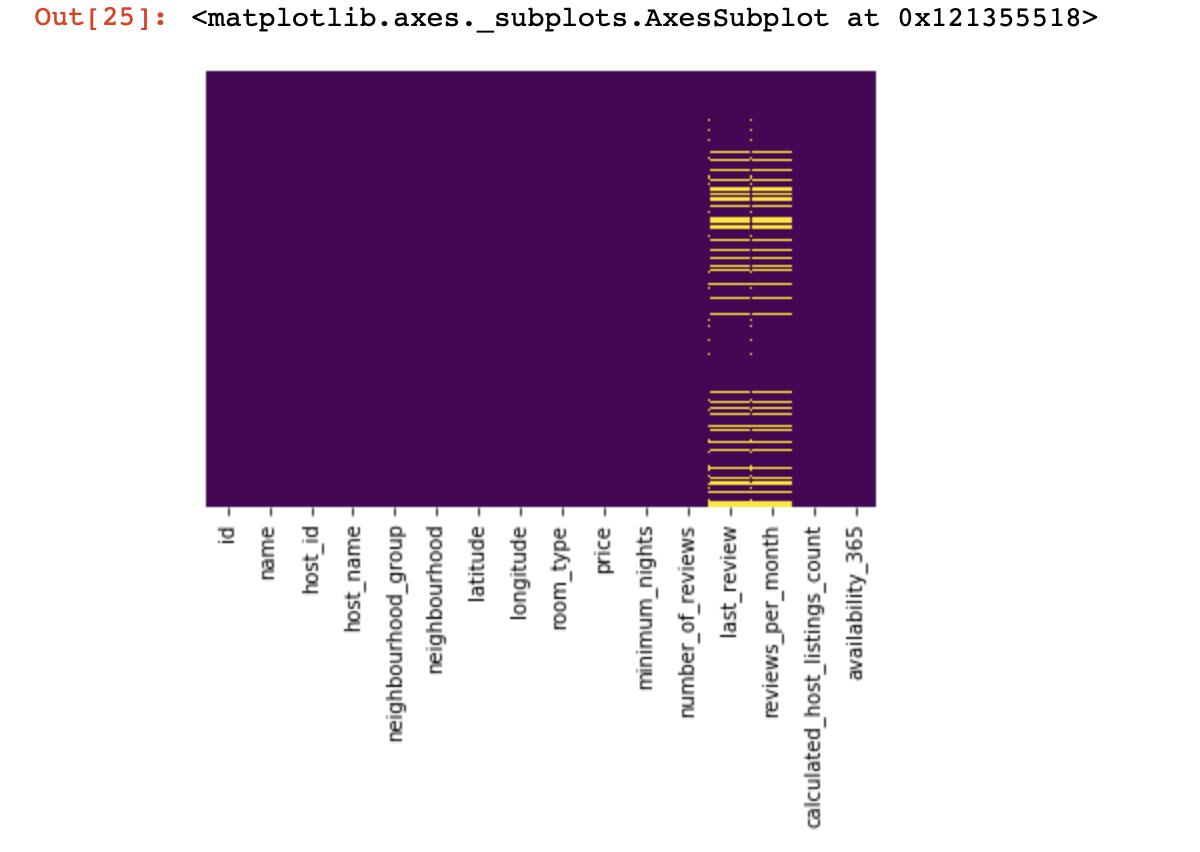
لقد كانت نظرة صغيرة من الأعلى ، والآن سننتقل إلى أشياء أكثر إثارة للاهتمام. دعونا
نحاول البحث ، وإن أمكن ، حذف الأعمدة التي تحتوي على قيمة واحدة فقط في جميع السطور (لن تؤثر على النتيجة بأي شكل من الأشكال):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] # , , نحن الآن نحمي أنفسنا ونجاح مشروعنا من الأسطر المكررة (الأسطر التي تحتوي على نفس المعلومات بنفس ترتيب أحد الخطوط الموجودة):
df.drop_duplicates(inplace=True) # , .
# .نقسم مجموعة البيانات إلى قسمين: أحدهما يحتوي على قيم نوعية ، والآخر بقيم كمية
نحتاج هنا إلى توضيح بسيط: إذا كانت الأسطر التي تحتوي على بيانات مفقودة في البيانات النوعية والكمية لا ترتبط ارتباطًا وثيقًا ببعضها البعض ، فسيكون من الضروري اتخاذ قرار بشأن ما نضحي به - جميع الأسطر التي تحتوي على بيانات مفقودة ، أو جزء منها فقط أو أعمدة معينة. إذا كانت الأسطر مرتبطة ، فلدينا كل الحق في تقسيم مجموعة البيانات إلى قسمين. بخلاف ذلك ، ستحتاج أولاً إلى التعامل مع الأسطر التي لا تربط البيانات المفقودة من الناحية النوعية والكمية ، وبعد ذلك فقط تقسم مجموعة البيانات إلى قسمين.
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])نقوم بهذا لتسهيل معالجة هذين النوعين المختلفين من البيانات - لاحقًا سوف نفهم إلى أي مدى يبسط ذلك حياتنا.
نحن نعمل مع البيانات الكمية
أول شيء يجب علينا فعله هو تحديد ما إذا كان هناك أي "أعمدة تجسس" في البيانات الكمية. نطلق على هذه الأعمدة اسم هذا لأنها تتظاهر بأنها بيانات كمية ، وتعمل هي نفسها كبيانات نوعية.
كيف نحددهم؟ بالطبع ، كل هذا يتوقف على طبيعة البيانات التي تقوم بتحليلها ، ولكن بشكل عام قد تحتوي هذه الأعمدة على القليل من البيانات الفريدة (في منطقة 3-10 قيم فريدة).
print(df_numerical.nunique())بعد تحديد أعمدة التجسس ، سننقلها من البيانات الكمية إلى البيانات النوعية:
spy_columns = df_numerical[['1', '2', '3']]# - dataframe
df_numerical.drop(labels=['1', '2', '3'], axis=1, inplace = True)#
df_categorical.insert(1, '1', spy_columns['1']) # -
df_categorical.insert(1, '2', spy_columns['2']) # -
df_categorical.insert(1, '3', spy_columns['3']) # - أخيرًا ، قمنا بفصل البيانات الكمية تمامًا عن البيانات النوعية ويمكنك الآن العمل معها بشكل صحيح. الأول هو أن نفهم أين لدينا قيم فارغة (NaN ، وفي بعض الحالات سيتم أخذ 0 كقيم فارغة).
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())في هذه المرحلة ، من المهم فهم الأعمدة التي يمكن أن تعني فيها الأصفار قيمًا مفقودة: هل هذا مرتبط بكيفية جمع البيانات؟ أو يمكن أن تكون مرتبطة بقيم البيانات؟ هذه الأسئلة تحتاج إلى إجابة على أساس كل حالة على حدة.
لذلك ، إذا قررنا مع ذلك أنه قد لا يكون لدينا بيانات حيث توجد أصفار ، فيجب أن نستبدل الأصفار بـ NaN ، بحيث يكون من الأسهل التعامل مع هذه البيانات المفقودة لاحقًا:
df_numerical[[" 1", " 2"]] = df_numerical[[" 1", " 2"]].replace(0, nan)الآن دعنا نرى أين لدينا بيانات مفقودة:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # df_numerical.info()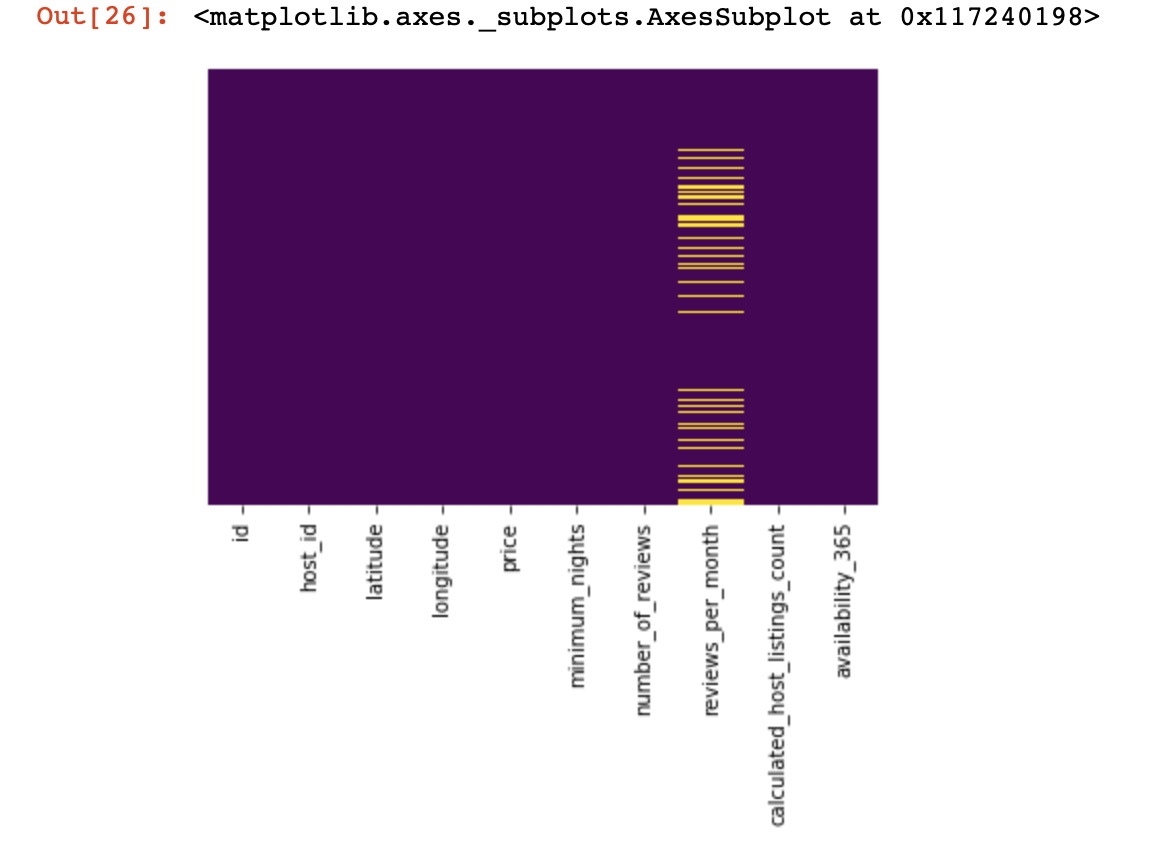
هنا ، يجب تمييز تلك القيم الموجودة داخل الأعمدة المفقودة باللون الأصفر. والمرح يبدأ الآن - كيف تتصرف بهذه القيم؟ هل تريد حذف الأسطر التي تحتوي على هذه القيم أو الأعمدة؟ أو املأ هذه القيم الفارغة ببعضها البعض؟
فيما يلي مخطط تقريبي يمكن أن يساعدك في تحديد ما يمكنك فعله بشكل أساسي بالقيم الفارغة:
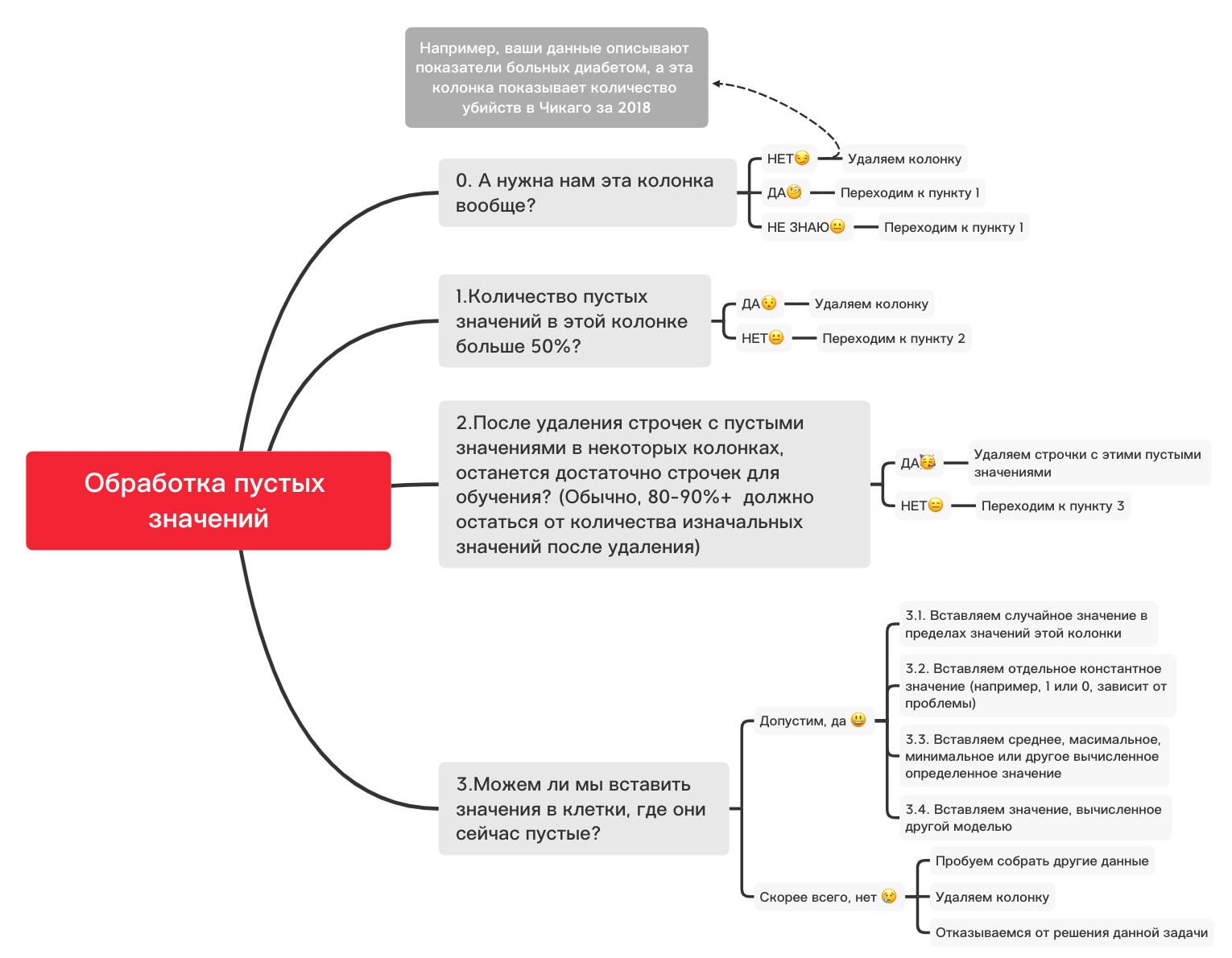
0. إزالة الأعمدة غير الضرورية
df_numerical.drop(labels=["1","2"], axis=1, inplace=True)1. هل يوجد أكثر من 50٪ من القيم الفارغة في هذا العمود؟
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["1","2"], axis=1, inplace=True)#, - 50 2. احذف الأسطر ذات القيم الفارغة
df_numerical.dropna(inplace=True)# , 3.1. أدخل قيمة عشوائية
import random # random
df_numerical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True) # 3.2 أدخل قيمة ثابتة
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='constant', fill_value="< >") # SimpleImputer
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.3 أدخل القيمة المتوسطة أو الأكثر شيوعًا
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) # mean most_frequent
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.4. إدخال قيمة محسوبة بواسطة نموذج آخر في
بعض الأحيان يمكن حساب القيم باستخدام نماذج الانحدار باستخدام نماذج من مكتبة sklearn أو مكتبات أخرى مماثلة. سيخصص فريقنا مقالة منفصلة حول كيفية القيام بذلك في المستقبل القريب.
لذلك ، بينما سيتم مقاطعة السرد حول البيانات الكمية ، نظرًا لوجود العديد من الفروق الدقيقة الأخرى حول كيفية القيام بشكل أفضل بإعداد البيانات والمعالجة المسبقة لمهام مختلفة ، وقد تم أخذ الأشياء الأساسية للبيانات الكمية في الاعتبار في هذه المقالة ، والآن حان الوقت للعودة إلى البيانات النوعية. الذي فصلناه بضع خطوات للوراء عن الكمية. يمكنك تغيير هذا الكمبيوتر الدفتري كما تريد ، وتعديله لمهام مختلفة ، بحيث تتم المعالجة المسبقة للبيانات بسرعة كبيرة!
البيانات النوعية
بشكل أساسي ، بالنسبة لبيانات الجودة ، يتم استخدام طريقة One-hot-encoding لتنسيقها من سلسلة (أو كائن) إلى رقم. قبل الانتقال إلى هذه النقطة ، دعنا نستخدم الرسم التخطيطي والكود أعلاه للتعامل مع القيم الفارغة.
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis')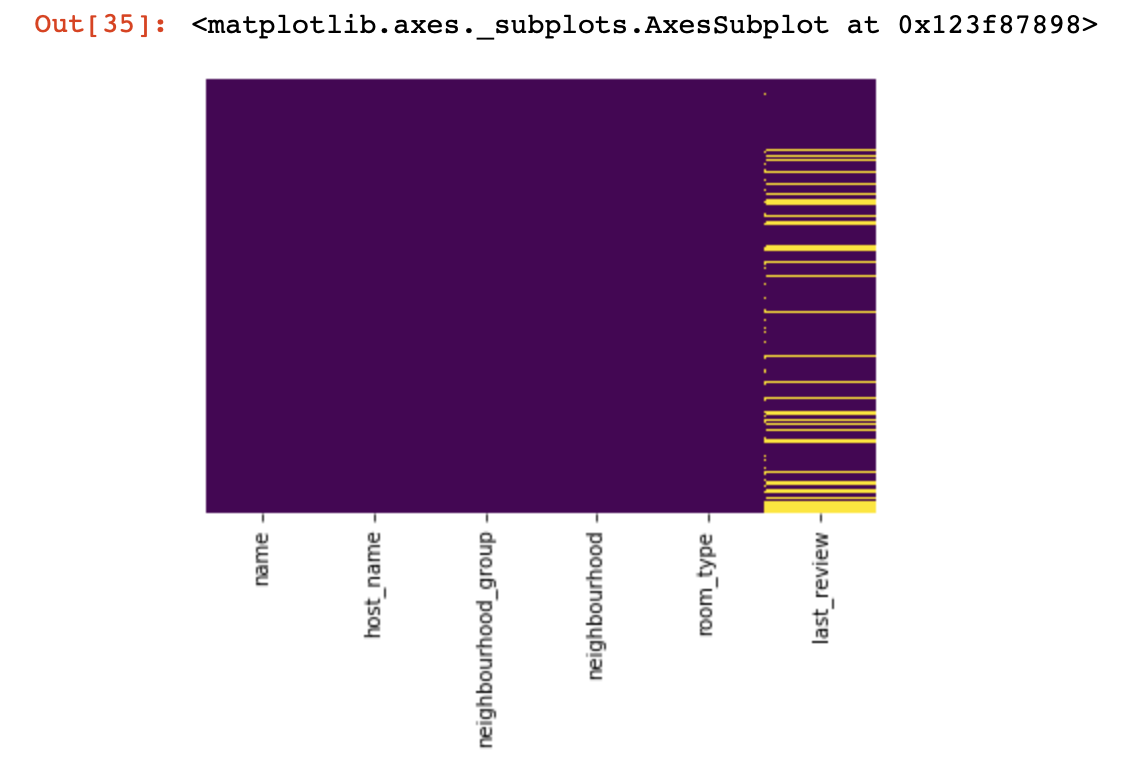
0. إزالة الأعمدة غير الضرورية
df_categorical.drop(labels=["1","2"], axis=1, inplace=True)1. هل يوجد أكثر من 50٪ من القيم الفارغة في هذا العمود؟
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["1","2"], axis=1, inplace=True) #, -
# 50% 2. احذف الأسطر ذات القيم الفارغة
df_categorical.dropna(inplace=True)# ,
# 3.1. أدخل قيمة عشوائية
import random
df_categorical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True)3.2 أدخل قيمة ثابتة
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="< >")
df_categorical[["_1",'_2','_3']] = imputer.fit_transform(df_categorical[['1', '2', '3']])
df_categorical.drop(labels = ["1","2","3"], axis = 1, inplace = True)لذا ، أخيرًا ، تعاملنا مع القيم الفارغة في بيانات الجودة. حان الوقت الآن لإجراء تشفير واحد ساخن للقيم الموجودة في قاعدة البيانات الخاصة بك. غالبًا ما تستخدم هذه الطريقة حتى تتمكن الخوارزمية من التدرب باستخدام بيانات جيدة.
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["1","2","3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))لذا ، انتهينا أخيرًا من معالجة البيانات النوعية والكمية بشكل منفصل - حان الوقت لدمجها مرة أخرى
new_df = pd.concat([df_numerical,df_categorical], axis=1)بعد دمج مجموعات البيانات معًا في مجموعة واحدة ، في النهاية يمكننا استخدام تحويل البيانات باستخدام MinMaxScaler من مكتبة sklearn. سيؤدي ذلك إلى جعل قيمنا بين 0 و 1 ، مما سيساعد عند تدريب النموذج في المستقبل.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)هذه البيانات جاهزة الآن لأي شيء - للشبكات العصبية وخوارزميات ML القياسية وما إلى ذلك!
في هذه المقالة ، لم نأخذ في الاعتبار العمل مع البيانات المتعلقة بالسلاسل الزمنية ، لأنه بالنسبة لهذه البيانات ، يجب استخدام تقنيات معالجة مختلفة قليلاً ، اعتمادًا على مهمتك. في المستقبل ، سيخصص فريقنا مقالًا منفصلاً لهذا الموضوع ، ونأمل أن يتمكن من تقديم شيء مثير للاهتمام وجديد ومفيد في حياتك ، مثل هذا الموضوع.