
لماذا يحتاج عمال النفط إلى البرمجة اللغوية العصبية؟ كيف تجعل الكمبيوتر يفهم المصطلحات المهنية؟ هل من الممكن أن أشرح للآلة ما هو "الضغط" ، "استجابة الخانق" ، "الحلقي"؟ كيف يتم ربط الموظفين الجدد والمساعد الصوتي؟ سنحاول الإجابة على هذه الأسئلة في المقالة الخاصة بإدخال المساعد الرقمي في برنامج دعم إنتاج النفط ، مما يسهل العمل الروتيني للمطور الجيولوجي.
نحن في المعهد نقوم بتطوير برنامجنا الخاص ( https://rn.digital/ ) لصناعة النفط ، ولكي يقع مستخدموه في الحب ، لا تحتاج فقط إلى تنفيذ وظائف مفيدة فيه ، ولكن أيضًا التفكير في راحة الواجهة طوال الوقت. أحد الاتجاهات في UI / UX اليوم هو الانتقال إلى واجهات الصوت. بعد كل شيء ، مهما كان ما قد يقوله المرء ، فإن أكثر أشكال التفاعل الطبيعية والملائمة للشخص هو الكلام. لذلك تم اتخاذ القرار لتطوير وتنفيذ مساعد صوتي في منتجاتنا البرمجية.
بالإضافة إلى تحسين مكون UI / UX ، يتيح لك إدخال المساعد أيضًا تقليل "الحد الأدنى" للموظفين الجدد للعمل مع البرنامج. وظائف برامجنا واسعة النطاق ، وقد يستغرق اكتشافها أكثر من يوم. ستؤدي القدرة على "مطالبة" المساعد بتنفيذ الأمر المطلوب إلى تقليل الوقت المستغرق في حل المهمة ، بالإضافة إلى تقليل إجهاد الوظيفة الجديدة.
نظرًا لأن خدمة أمن الشركات حساسة جدًا لنقل البيانات إلى الخدمات الخارجية ، فقد فكرنا في تطوير مساعد يعتمد على حلول مفتوحة المصدر تسمح لنا بمعالجة المعلومات محليًا.
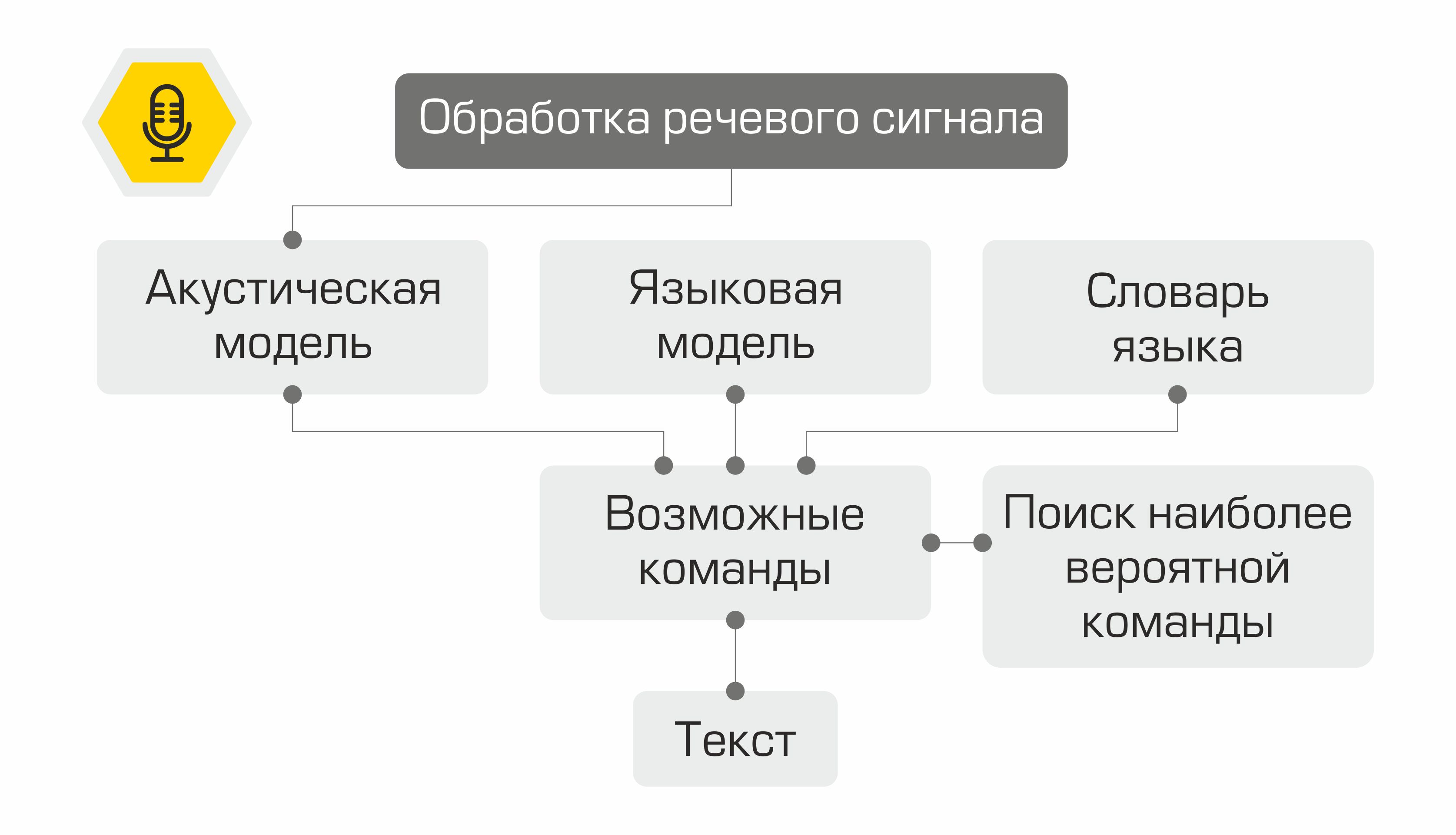
من الناحية الهيكلية ، يتكون مساعدنا من الوحدات التالية:
- التعرف على الكلام (ASR)
- اختيار الكائنات الدلالية (Natural Language Understanding ، NLU)
- تنفيذ الأمر
- توليف الكلام (تحويل النص إلى كلام ، تحويل النص إلى كلام)
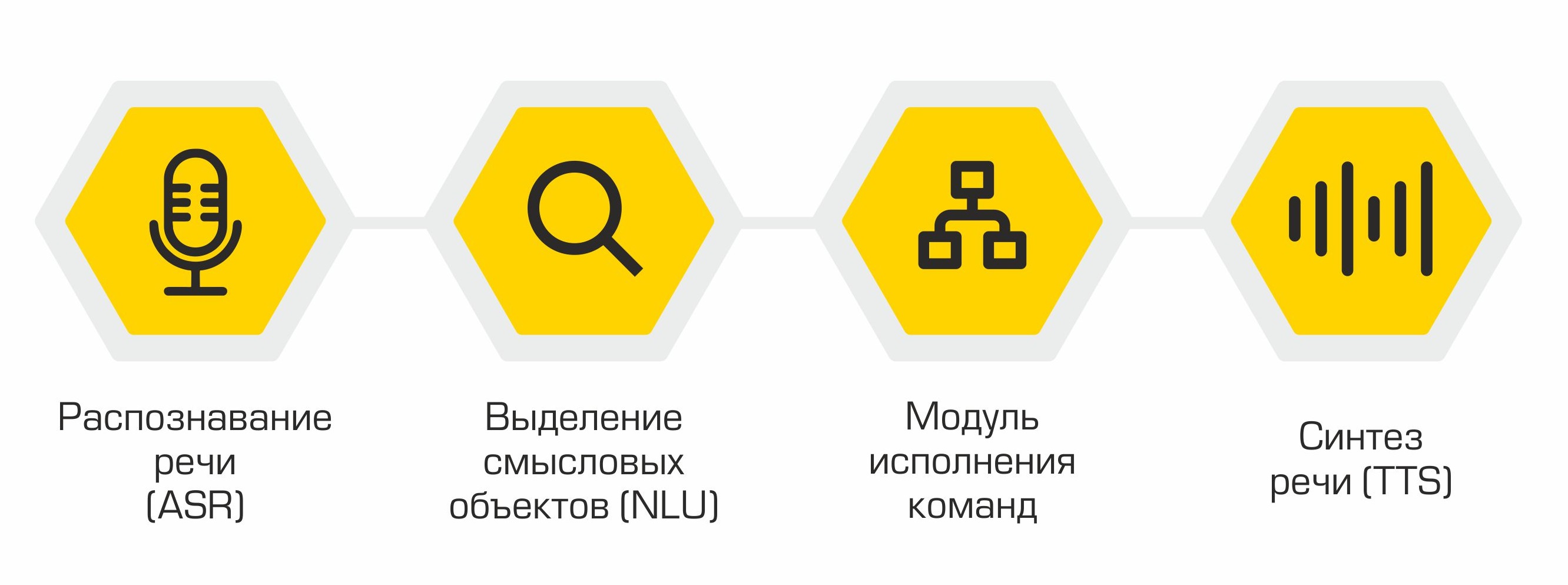
مبدأ المساعد: من الكلمات (المستخدم) إلى الأفعال (في البرمجيات)!
يعمل ناتج كل وحدة كنقطة دخول للمكون التالي في النظام. لذلك ، يتم تحويل كلام المستخدم إلى نص وإرساله للمعالجة إلى خوارزميات التعلم الآلي لتحديد نية المستخدم. بناءً على هذه النية ، يتم تنشيط الفئة المطلوبة في وحدة تنفيذ الأوامر ، والتي تلبي طلب المستخدم. عند الانتهاء من العملية ، تنقل وحدة تنفيذ الأوامر معلومات حول حالة تنفيذ الأمر إلى وحدة تركيب الكلام ، والتي بدورها تُعلم المستخدم.
كل وحدة مساعدة هي خدمة مصغرة. لذلك ، إذا رغبت في ذلك ، يمكن للمستخدم الاستغناء عن تقنيات الكلام على الإطلاق والتوجه مباشرة إلى "عقل" المساعد - إلى الوحدة النمطية لتسليط الضوء على الكائنات الدلالية - من خلال شكل روبوت دردشة.
التعرف على الكلام
المرحلة الأولى من التعرف على الكلام هي معالجة إشارات الكلام واستخراج الميزات. أبسط تمثيل للإشارة الصوتية هو مخطط الذبذبات. يعكس كمية الطاقة في أي وقت. ومع ذلك ، فإن هذه المعلومات لا تكفي لتحديد الصوت المنطوق. من المهم بالنسبة لنا أن نعرف مقدار الطاقة الموجودة في نطاقات التردد المختلفة. للقيام بذلك ، باستخدام تحويل فورييه ، يتم إجراء انتقال من مخطط الذبذبات إلى الطيف.
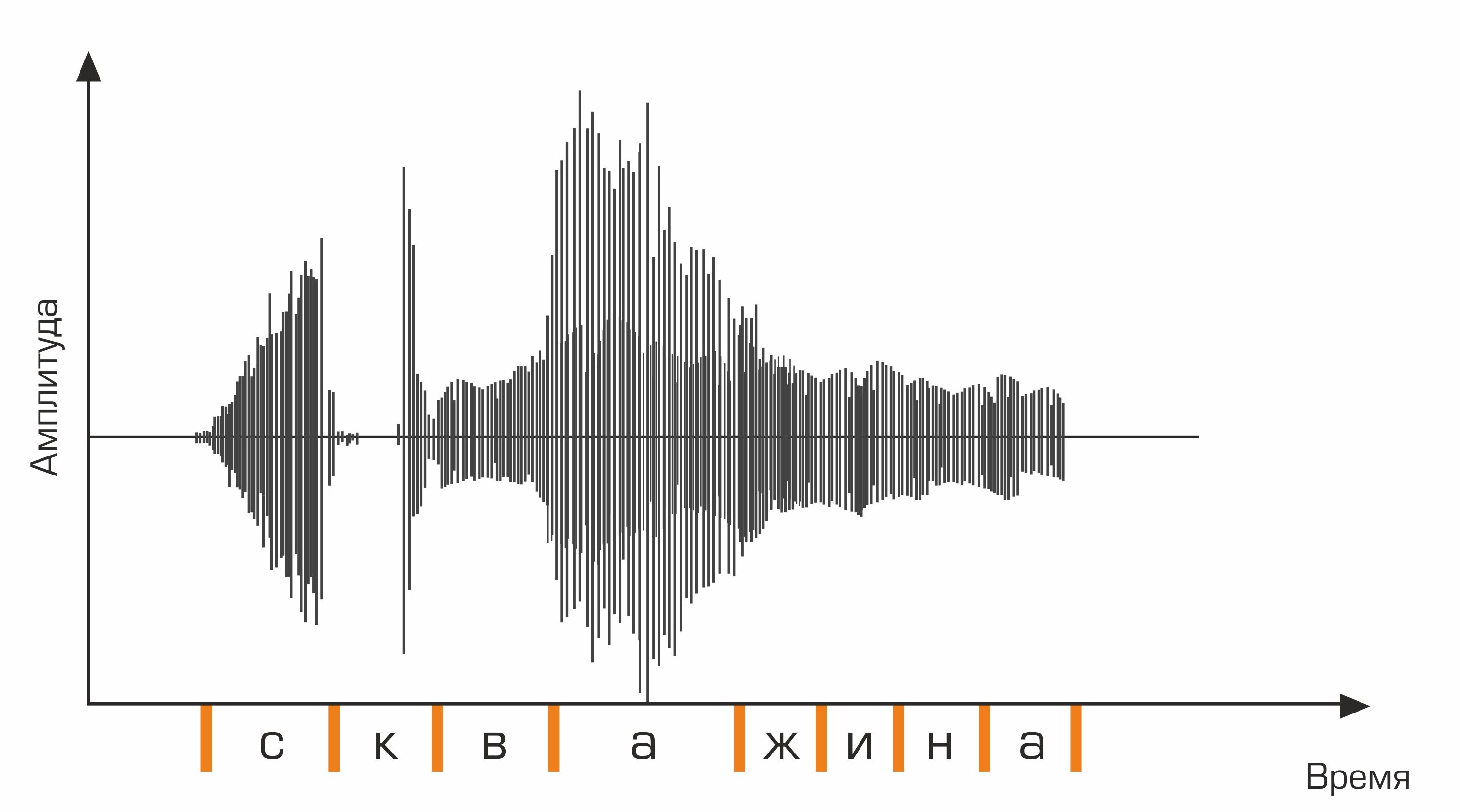
هذا رسم الذبذبات.
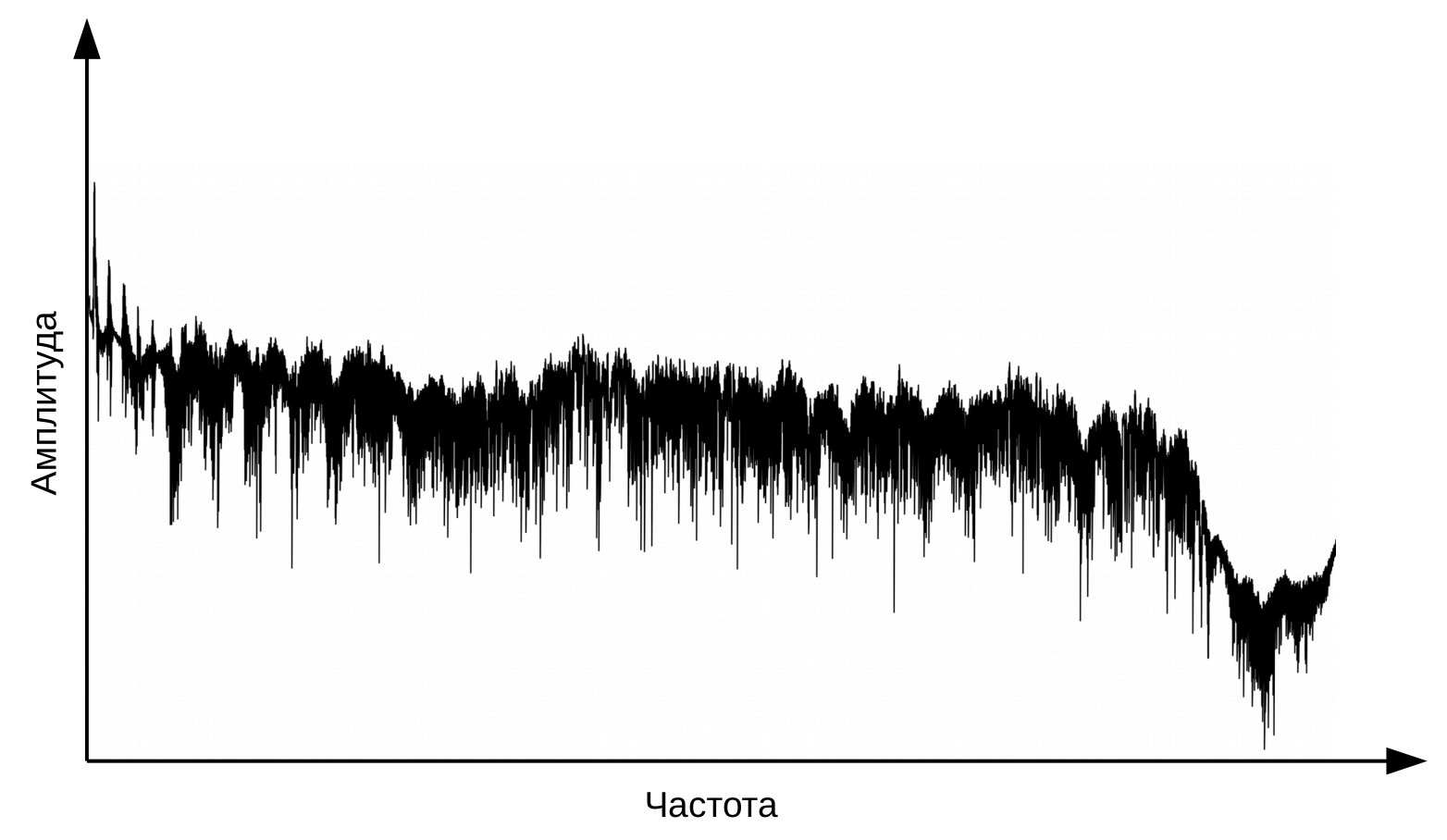
وهذا هو الطيف لكل لحظة من الزمن.
من الضروري هنا توضيح أن الكلام يتكون عندما يمر تدفق هواء مهتز عبر الحنجرة (المصدر) والجهاز الصوتي (المرشح). لتصنيف الصوتيات ، نحتاج فقط إلى معلومات حول تكوين المرشح ، أي حول موضع الشفاه واللسان. يمكن تمييز هذه المعلومات عن طريق الانتقال من الطيف إلى cepstrum (cepstrum هو الجناس الناقص لكلمة طيف) ، يتم إجراؤها باستخدام تحويل فورييه العكسي للوغاريتم الطيف. مرة أخرى ، المحور السيني ليس التردد ، بل الوقت. يستخدم مصطلح "التردد" للتمييز بين المجالات الزمنية لجهاز cepstrum وإشارة الصوت الأصلية (أوبنهايم ، شيفر. معالجة الإشارات الرقمية ، 2018).
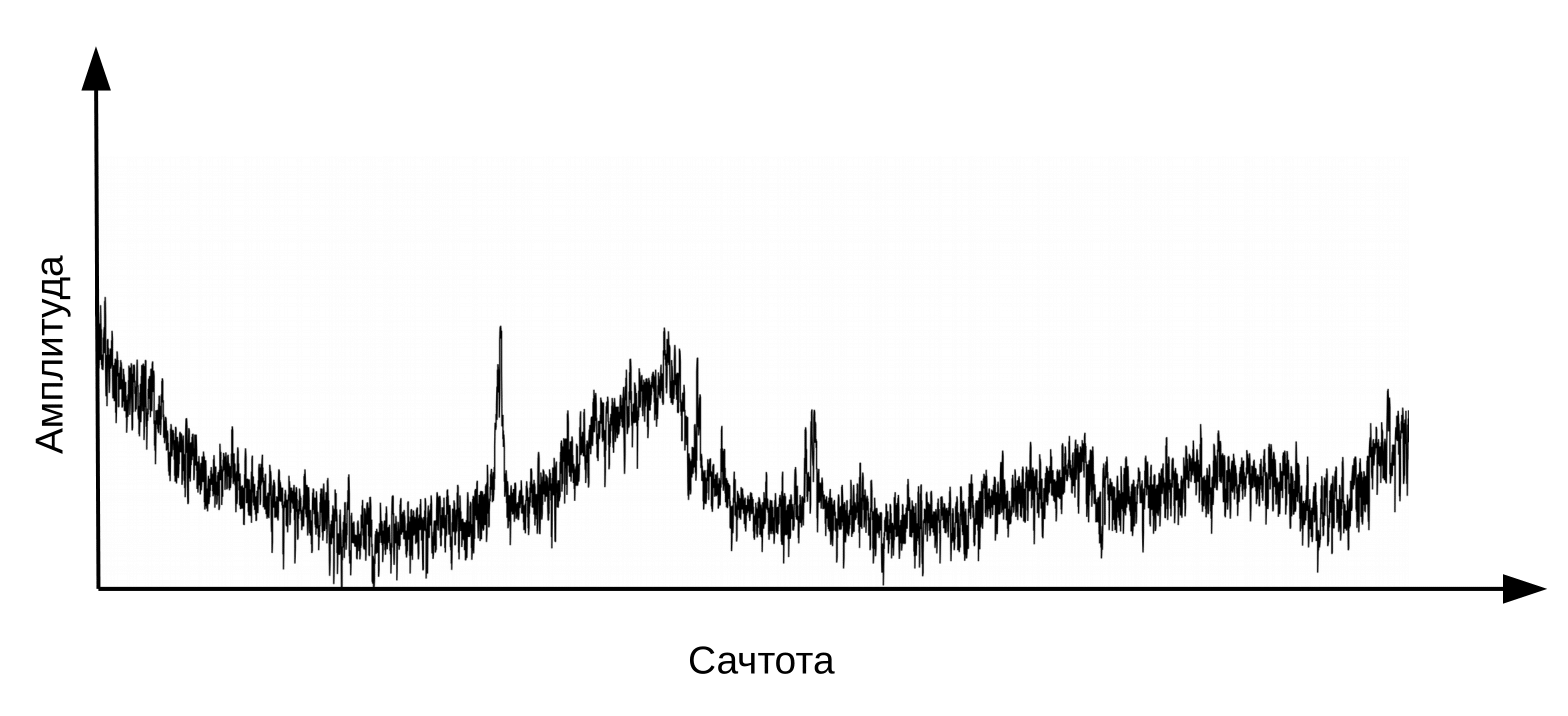
Cepstrum ، أو ببساطة "طيف لوغاريتم الطيف". نعم ، نعم ، الشائع مصطلح وليس خطأ مطبعي
تم العثور على معلومات حول موضع القناة الصوتية في أول 12 معاملات cepstrum. تُستكمل هذه المعاملات البالغ عددها 12 بميزات ديناميكية (دلتا ودلتا دلتا) تصف التغييرات في الإشارة الصوتية. (جورافسكي ، مارتن. معالجة الكلام واللغة ، 2008). يُطلق على متجه القيم الناتج متجه MFCC (معاملات cepstral ذات تردد ميل) وهي الميزة الصوتية الأكثر شيوعًا المستخدمة في التعرف على الكلام.
ماذا سيحدث بعد ذلك مع العلامات؟ يتم استخدامها كمدخلات في النموذج الصوتي. إنه يوضح الوحدة اللغوية التي من المرجح أن "تفرخ" متجه MFCC. في أنظمة مختلفة ، يمكن أن تكون هذه الوحدات اللغوية أجزاء من الصوتيات أو الصوتيات أو حتى الكلمات. وهكذا ، فإن النموذج الصوتي يحول سلسلة من نواقل MFCC إلى سلسلة من الأصوات الأكثر احتمالا.
علاوة على ذلك ، لتسلسل الصوتيات ، من الضروري تحديد التسلسل المناسب للكلمات. هذا هو المكان الذي يتم فيه تشغيل قاموس اللغة ، والذي يحتوي على نسخ جميع الكلمات التي يتعرف عليها النظام. يعد تجميع مثل هذه القواميس عملية شاقة تتطلب معرفة متخصصة في علم الأصوات وعلم الأصوات للغة معينة. مثال على سطر من قاموس النسخ:
حسنا skv aa zh yn ay
في الخطوة التالية ، يحدد نموذج اللغة الاحتمالية السابقة للجملة في اللغة. بمعنى آخر ، يعطي النموذج تقديرًا لمدى احتمالية ظهور مثل هذه الجملة في اللغة. سيحدد النموذج اللغوي الجيد أن عبارة "رسم بياني لسعر النفط" هي أكثر احتمالًا من جملة "رسم بياني للنفط التسعة".
يؤدي الجمع بين النموذج الصوتي ونموذج اللغة وقاموس النطق إلى إنشاء "شبكة" من الفرضيات - كل تسلسلات الكلمات الممكنة التي يمكن من خلالها العثور على أكثرها احتمالًا باستخدام خوارزمية البرمجة الديناميكية. سيقدمها نظامها كنص معروف.
تمثيل تخطيطي لتشغيل نظام التعرف على الكلام
سيكون من غير العملي إعادة اختراع العجلة وكتابة مكتبة التعرف على الكلام من البداية ، لذلك وقع اختيارنا على إطار عمل kaldi . الميزة التي لا شك فيها للمكتبة هي مرونتها ، مما يسمح ، إذا لزم الأمر ، بإنشاء وتعديل جميع مكونات النظام. بالإضافة إلى ذلك ، يسمح لك ترخيص Apache 2.0 بحرية استخدام المكتبة في التطوير التجاري.
كبيانات للتدريب ، يستخدم نموذج صوتي مجموعة بيانات صوتية مجانية VoxForge . لتحويل سلسلة من الصوتيات إلى كلمات ، استخدمنا قاموس اللغة الروسية المقدم من مكتبة CMU Sphinx . حيث أن القاموس لم يحتوي على نطق المصطلحات الخاصة بصناعة النفط بناءً عليها باستخدام المنفعةدرب g2p-seq2seq نموذجًا من حروف الكتابة إلى الصوت لإنشاء نسخ نصية للكلمات الجديدة بسرعة. تم تدريب نموذج اللغة على النصوص الصوتية من VoxForge وعلى مجموعة البيانات التي أنشأناها ، والتي تحتوي على شروط صناعة النفط والغاز وأسماء الحقول وشركات التعدين.
اختيار الكائنات الدلالية
لذلك ، تعرفنا على كلام المستخدم ، ولكن هذا مجرد سطر من النص. كيف تخبر الكمبيوتر ماذا يفعل؟ استخدمت أقدم أنظمة التحكم الصوتي مجموعة أوامر محدودة للغاية. بعد التعرف على إحدى هذه العبارات ، كان من الممكن استدعاء العملية المقابلة. منذ ذلك الحين ، قفزت التقنيات في معالجة وفهم اللغة الطبيعية (NLP و NLU ، على التوالي) إلى الأمام. بالفعل اليوم ، النماذج المدربة على كميات كبيرة من البيانات قادرة على فهم معنى البيان جيدًا.
لاستخراج المعنى من نص عبارة معترف بها ، من الضروري حل مشكلتين في التعلم الآلي:
- تصنيف فريق المستخدمين (تصنيف النية).
- تخصيص الكيانات المسماة (التعرف على الكيانات المسماة).
عند تطوير النماذج ، استخدمنا مكتبة Rasa مفتوحة المصدر ، الموزعة بموجب ترخيص Apache 2.0.
لحل المشكلة الأولى ، من الضروري تمثيل النص كمتجه رقمي يمكن معالجته بواسطة آلة. لمثل هذا التحول ، يتم استخدام النموذج العصبي StarSpace ، والذي يسمح " بتداخل " نص الطلب وفئة الطلب في مساحة مشتركة.

نموذج StarSpace العصبي
أثناء التدريب ، تتعلم الشبكة العصبية مقارنة الكيانات ، وذلك لتقليل المسافة بين متجه الطلب ومتجه الفئة الصحيحة وزيادة المسافة إلى متجهات الفئات المختلفة. أثناء الاختبار ، يتم تحديد الفئة y للاستعلام x بحيث:
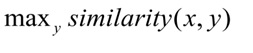
يتم استخدام مسافة جيب التمام كمقياس لتشابه المتجهات: ،
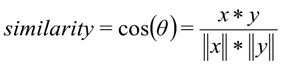
حيث
x هو طلب المستخدم ، y هي فئة الطلب.
تم ترميز 3000 استفسار لتدريب مصنف نية المستخدم. في المجموع ، تخرجنا من 8 فصول. قمنا بتقسيم العينة إلى عينات تدريب واختبار بنسبة 70/30 باستخدام طريقة التقسيم الطبقي للمتغير المستهدف. سمح التقسيم الطبقي بالحفاظ على التوزيع الأصلي للفصول في القطار والاختبار. تم تقييم جودة النموذج المدرب بعدة معايير في وقت واحد:
- استدعاء - نسبة الطلبات المصنفة بشكل صحيح لجميع طلبات هذه الفئة.
- حصة الطلبات المصنفة بشكل صحيح (الدقة).
- الدقة - نسبة الطلبات المصنفة بشكل صحيح بالنسبة إلى جميع الطلبات التي ينسبها النظام إلى هذه الفئة.
- F1 – .
أيضًا ، يتم استخدام مصفوفة أخطاء النظام لتقييم جودة نموذج التصنيف. المحور ص هو الفئة الحقيقية للبيان ، المحور السيني هو الصنف الذي تنبأت به الخوارزمية.
في عينة التحكم ، أظهر النموذج النتائج التالية:
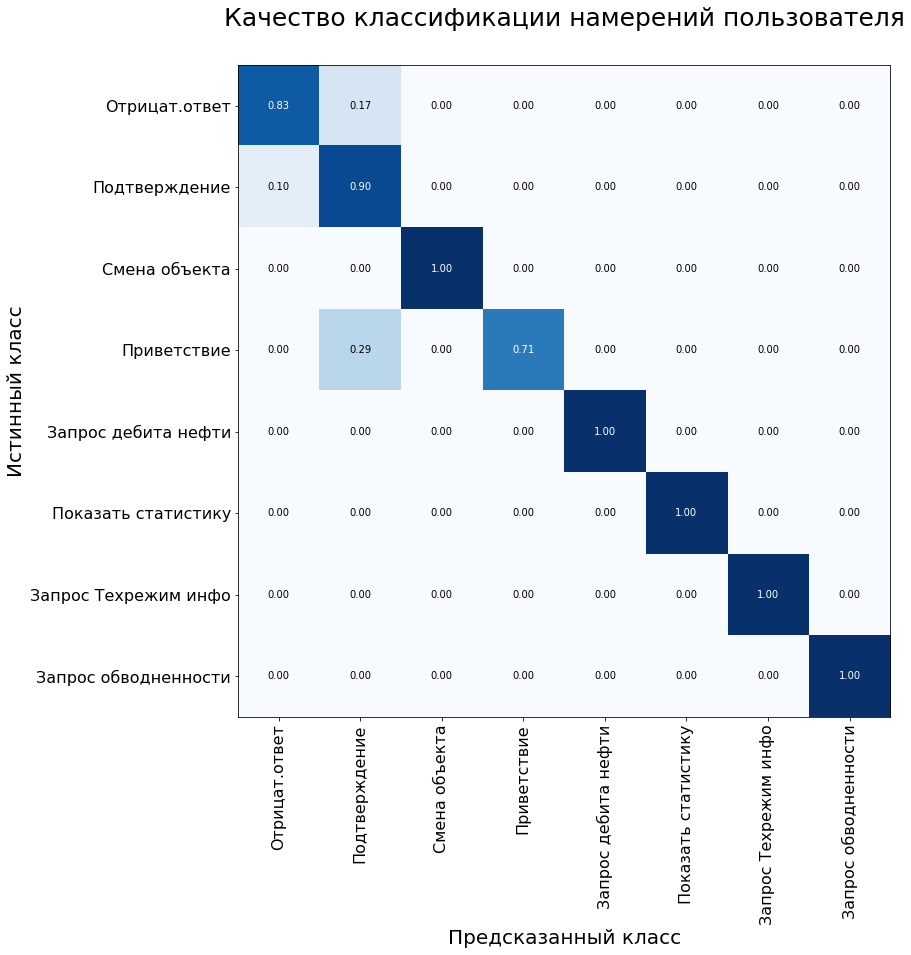
مقاييس النموذج في مجموعة بيانات الاختبار: الدقة - 92٪ ، F1 - 90٪.
المهمة الثانية - اختيار الكيانات المسماة - هي تحديد الكلمات والعبارات التي تشير إلى كائن أو ظاهرة معينة. يمكن أن تكون هذه الكيانات ، على سبيل المثال ، اسم وديعة أو شركة تعدين.
لحل المشكلة ، تم استخدام خوارزمية الحقول العشوائية الشرطية ، وهي نوع من حقول ماركوف. CRF هو نموذج تمييزي ، أي أنه يمثل الاحتمال الشرطي P(Y | X) الحالة الكامنة Y (فئة الكلمة) من الملاحظة X (كلمة).
لتلبية طلبات المستخدم ، يحتاج مساعدنا إلى تمييز ثلاثة أنواع من الكيانات المسماة: اسم الحقل واسم البئر واسم كائن التطوير. لتدريب النموذج ، أعددنا مجموعة بيانات وقمنا بعمل تعليق توضيحي: تم تعيين فئة مقابلة لكل كلمة في العينة.

مثال من مجموعة التدريب الخاصة بمشكلة التعرف على الكيان المسماة.
ومع ذلك ، فقد تبين أن كل شيء لم يكن بهذه البساطة. المصطلحات المهنية شائعة جدًا بين مطوري المجال والجيولوجيين. ليس من الصعب على الناس أن يفهموا أن "الحاقن" هو بئر للحقن ، وأن "Samotlor" ، على الأرجح ، تعني حقل Samotlor. بالنسبة لنموذج تم تدريبه على كمية محدودة من البيانات ، لا يزال من الصعب رسم مثل هذا التوازي. ميزة رائعة لمكتبة Rasa ، مثل إنشاء قاموس المرادفات ، تساعد في التغلب على هذا القيد.
## مرادف: Samotlor
- Samotlor
- Samotlor
- أكبر حقل نفطي في روسيا
سمحت لنا إضافة المرادفات أيضًا بتوسيع العينة قليلاً. كان حجم مجموعة البيانات بأكملها 2000 طلبًا ، قسمناها إلى قطار واختباره بنسبة 70/30. تم تقييم جودة النموذج باستخدام مقياس F1 وكانت 98٪ عند اختباره على عينة تحكم.
تنفيذ الأمر
اعتمادًا على فئة طلب المستخدم المحددة في الخطوة السابقة ، يقوم النظام بتنشيط الفئة المقابلة في نواة البرنامج. كل فئة لها طريقتان على الأقل: طريقة تؤدي الطلب مباشرة وطريقة لتوليد استجابة للمستخدم.
على سبيل المثال ، عند تعيين أمر إلى فئة "request_production_schedule" ، يتم إنشاء كائن من فئة RequestOilChart يقوم بتفريغ المعلومات الخاصة بإنتاج النفط من قاعدة البيانات. تُستخدم الكيانات المسماة المخصصة (على سبيل المثال ، أسماء الحقول والحقول) لملء الفجوات في الاستعلامات للوصول إلى قاعدة البيانات أو نواة البرنامج. يجيب المساعد بمساعدة القوالب المعدة ، والمساحات التي تمتلئ بقيم البيانات التي تم تحميلها.

مثال على نموذج مساعد يعمل.
اصطناع الكلام

كيف يعمل تركيب الكلام المتسلسل:
يتم عرض نص إعلام المستخدم الذي تم إنشاؤه في المرحلة السابقة على الشاشة ويستخدم أيضًا كمدخل لوحدة تركيب الكلام الشفوي. يتم تنفيذ إنشاء الكلام باستخدام مكتبة RHVoice... يسمح ترخيص GNU LGPL v2.1 باستخدام إطار العمل كأحد مكونات البرامج التجارية. المكونات الرئيسية لنظام تركيب الكلام هي معالج لغوي يعالج النص المقدم كمدخل. يتم تطبيع النص: يتم تقليل الأرقام إلى تمثيل مكتوب ، ويتم فك رموز الاختصارات ، وما إلى ذلك ، ثم ، باستخدام قاموس النطق ، يتم إنشاء نسخة للنص ، ثم يتم نقلها إلى مدخلات المعالج الصوتي. هذا المكون مسؤول عن اختيار عناصر الصوت من قاعدة بيانات الكلام ، وسلسلة العناصر المختارة ومعالجة الإشارة الصوتية.
ضع كل شيء معا
لذا ، فإن جميع مكونات المساعد الصوتي جاهزة. يبقى فقط "جمعها" في التسلسل الصحيح والاختبار. كما ذكرنا سابقًا ، تعد كل وحدة خدمة مصغرة. يتم استخدام إطار عمل RabbitMQ كناقل لتوصيل جميع الوحدات. يوضح الرسم التوضيحي بوضوح العمل الداخلي للمساعد باستخدام مثال طلب مستخدم نموذجي:
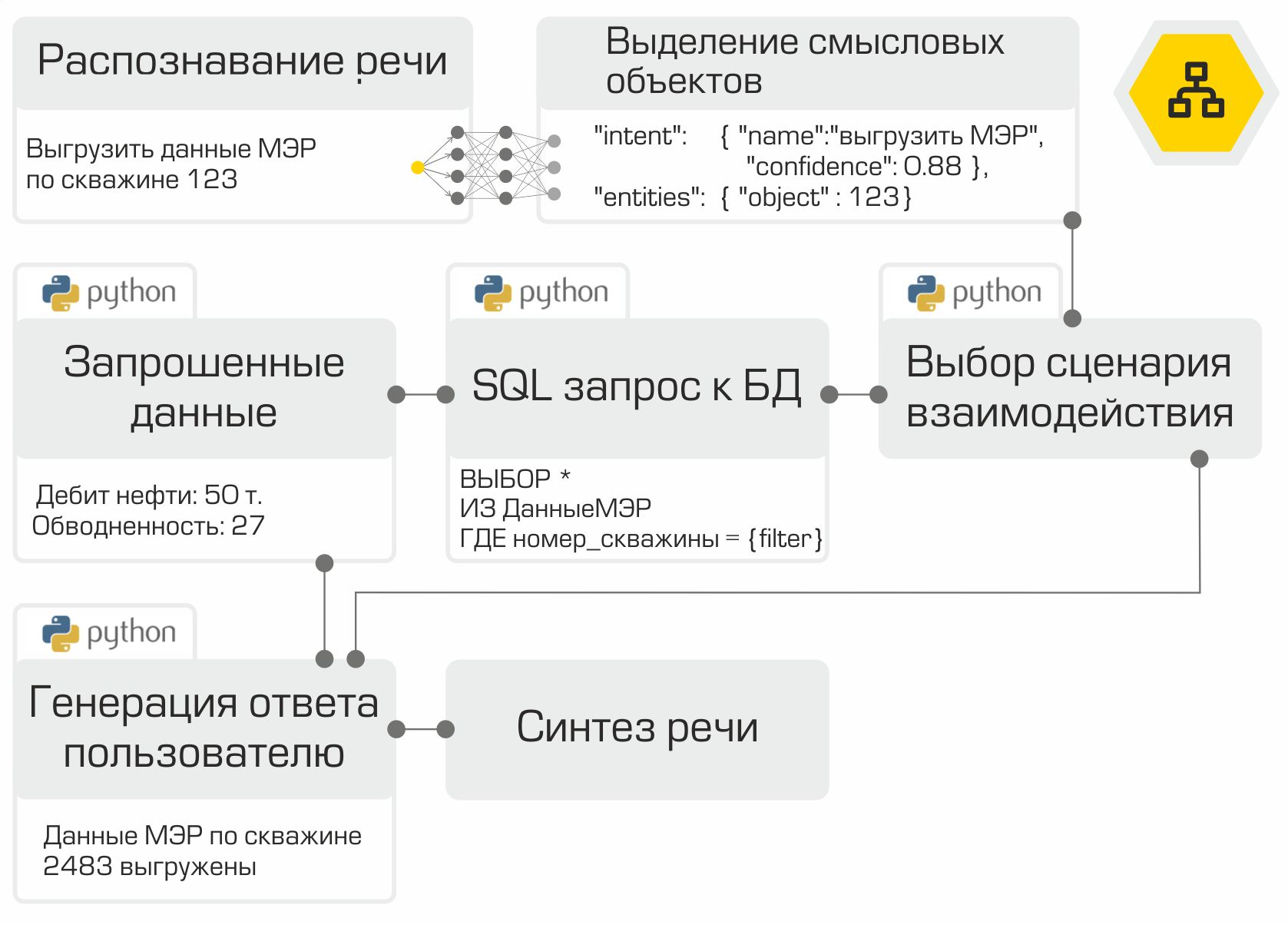
يسمح الحل الذي تم إنشاؤه بوضع البنية التحتية بالكامل في شبكة الشركة. تعد معالجة المعلومات المحلية الميزة الرئيسية للنظام. ومع ذلك ، يتعين عليك الدفع مقابل الاستقلالية لأنه يتعين عليك جمع البيانات وتدريب النماذج واختبارها بنفسك ، بدلاً من استخدام قوة كبار البائعين في سوق المساعد الرقمي.
في الوقت الحالي نقوم بدمج المساعد في أحد المنتجات قيد التطوير.
ما مدى سهولة البحث عن بئرك أو شجرتك المفضلة بعبارة واحدة فقط!
في المرحلة التالية ، من المخطط جمع وتحليل التعليقات من المستخدمين. هناك أيضًا خطط لتوسيع الأوامر التي يتعرف عليها المساعد وينفذها.
المشروع الموضح في المقالة ليس المثال الوحيد لاستخدام أساليب التعلم الآلي في شركتنا. لذلك ، على سبيل المثال ، يتم استخدام تحليل البيانات لتحديد الآبار المرشحة تلقائيًا للإجراءات الجيولوجية والتقنية ، والغرض منها هو تحفيز إنتاج النفط. في إحدى المقالات القادمة ، سنخبرك بكيفية حل هذه المشكلة الرائعة. اشترك في مدونتنا حتى لا تفوتها!