في هذه المقالة سوف تتعلم
- ما هي CNN وكيف تعمل
- ما هي خريطة المعالم
- ما هو الحد الأقصى لتجميع
- وظائف الخسارة لمختلف مهام التعلم العميق
مقدمة صغيرة
تهدف هذه السلسلة من المقالات إلى توفير فهم بديهي لكيفية عمل التعلم العميق ، وما هي المهام ، وبنى الشبكات ، ولماذا يكون أحدهما أفضل من الآخر. سيكون هناك القليل من الأشياء المحددة بروح "كيفية تنفيذها". إن الخوض في كل التفاصيل يجعل المواد معقدة للغاية بالنسبة لمعظم الجماهير. حول كيفية عمل الرسم البياني الحسابي أو كيف تمت كتابة النسخ العكسي من خلال الطبقات التلافيفية بالفعل. والأهم من ذلك ، أنه مكتوب أفضل بكثير مما سأشرح.
في المقالة السابقة ، ناقشنا FCNN - ما هو وما هي المشاكل. يكمن حل هذه المشكلات في بنية الشبكات العصبية التلافيفية.
الشبكات العصبية التلافيفية (CNN)
الشبكة العصبية التلافيفية. يبدو هكذا (هندسة vgg-16):
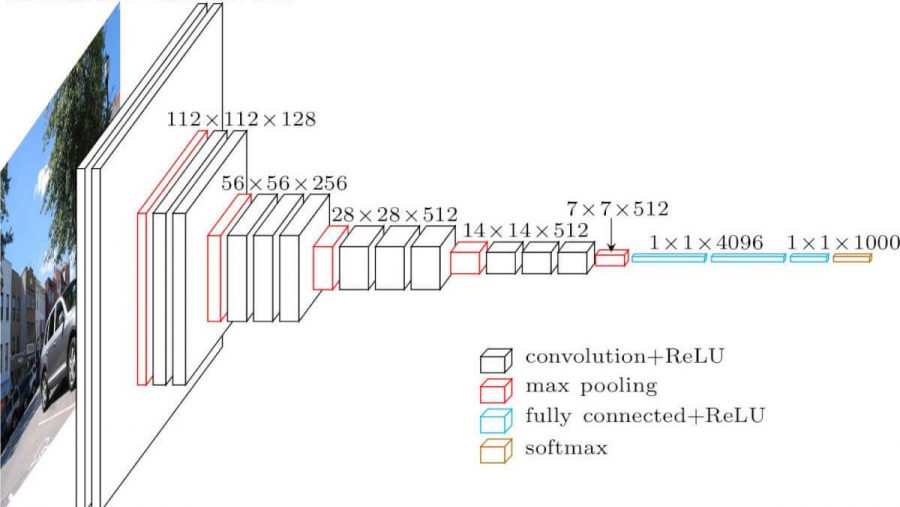
ما هي الاختلافات عن الشبكة المتشابكة بالكامل؟ الطبقات المخفية لديها الآن عملية التفاف.
هكذا يبدو الالتفاف:

نحن فقط نلتقط صورة (في الوقت الحالي - قناة واحدة) ، نأخذ نواة التفاف (مصفوفة) ، تتكون من معلمات التدريب الخاصة بنا ، "تراكب" النواة (عادة 3 × 3) على الصورة ، ونقوم بضرب كل قيم البكسل للصورة التي تضرب النواة. ثم يتم تلخيص كل هذا (تحتاج أيضًا إلى إضافة معامل التحيز - الإزاحة) ، ونحصل على بعض الأرقام. هذا الرقم هو عنصر طبقة الإخراج. نحرك هذا اللب فوق صورتنا بخطوة (خطوة) ونحصل على العناصر التالية. يتم إنشاء مصفوفة جديدة من هذه العناصر ، ويتم تطبيق نواة الالتفاف التالية عليها (بعد تطبيق وظيفة التنشيط عليها). في الحالة التي تكون فيها صورة الإدخال ثلاثية القنوات ، تكون نواة الالتفاف أيضًا ثلاثية القنوات - مرشح.
لكن كل شيء ليس بهذه البساطة هنا. تسمى المصفوفات التي نحصل عليها بعد الالتفاف خرائط المعالم ، لأنها تخزن بعض ميزات المصفوفات السابقة ، ولكن بشكل مختلف. في الممارسة العملية ، يتم استخدام العديد من مرشحات الالتفاف مرة واحدة. يتم ذلك من أجل "جلب" أكبر عدد ممكن من الميزات إلى طبقة الالتواء التالية. مع كل طبقة من الالتواء ، يتم تقديم ميزاتنا ، التي كانت في صورة الإدخال ، أكثر وأكثر في أشكال مجردة.
بضع ملاحظات أخرى:
- بعد الطي ، تصبح خريطة الميزات الخاصة بنا أصغر (في العرض والارتفاع). في بعض الأحيان ، لتقليل العرض والارتفاع بشكل أضعف ، أو عدم تقليله على الإطلاق (نفس الالتفاف) ، استخدم طريقة الحشو الصفري - ملء الأصفار "على طول المحيط" لخريطة ميزات الإدخال.
- بعد أحدث طبقة تلافيفية ، تستخدم مهام التصنيف والانحدار عدة طبقات متصلة بالكامل.
لماذا هو أفضل من FCNN
- يمكننا الآن الحصول على عدد أقل من المعلمات القابلة للتدريب بين الطبقات
- الآن ، عندما نستخرج ميزات من الصورة ، نأخذ في الاعتبار ليس فقط بكسل واحد ، ولكن أيضًا وحدات البكسل القريبة منه (تحديد أنماط معينة في الصورة)
ماكس تجمع
يبدو كالتالي:
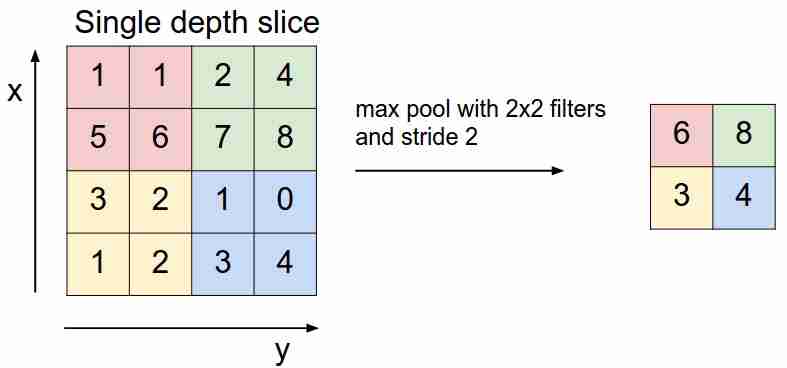
نحن "ننزلق" فوق خريطة المعالم الخاصة بنا باستخدام مرشح ونختار فقط أهم الميزات (من حيث الإشارة الواردة ، كقيمة معينة) ، مما يقلل من أبعاد خريطة المعالم. يوجد أيضًا تجمع متوسط (مرجح) ، عندما نقوم بتوسيط القيم التي تقع في المرشح ، ولكن من الناحية العملية ، يكون التجميع الأقصى هو الأكثر قابلية للتطبيق.
- لا تحتوي هذه الطبقة على معلمات قابلة للتدريب
وظائف الخسارة
نقوم بتغذية الشبكة X إلى المدخلات ، والوصول إلى المخرجات ، وحساب قيمة وظيفة الخسارة ، وتنفيذ خوارزمية backpropagation - هذه هي الطريقة التي تتعلم بها الشبكات العصبية الحديثة (في الوقت الحالي ، نتحدث فقط عن التعلم الخاضع للإشراف).
يتم استخدام وظائف خسارة مختلفة اعتمادًا على المهام التي تحلها الشبكات العصبية:
- مشكلة الانحدار . في الغالب يستخدمون دالة الخطأ التربيعي المتوسط (MSE).
- مشكلة التصنيف . يستخدمون بشكل أساسي فقدان الانتروبيا.
نحن لا نأخذ في الاعتبار المهام الأخرى حتى الآن - سيتم مناقشة هذا في المقالات التالية. لماذا بالضبط مثل هذه الوظائف لمثل هذه المهام؟ هنا تحتاج إلى إدخال الحد الأقصى لتقدير الاحتمال والرياضيات. من يهتم - لقد كتبت عنها هنا .
خاتمة
أود أيضًا أن ألفت انتباهك إلى شيئين مستخدمين في معماريات الشبكة العصبية ، بما في ذلك التلافيف - التسرب (يمكنك قراءته هنا ) والتطبيع الجماعي . أوصي بشدة بالقراءة.
في المقالة التالية ، سنحلل بنية CNN ، وسنفهم لماذا يكون أحدهما أفضل من الآخر.