
يجب أن أقول على الفور: أنا لست متخصصًا في تكنولوجيا المعلومات ، بل متحمس في مجال الإحصاء. بالإضافة إلى ذلك ، شاركت في العديد من مسابقات التنبؤ للفورمولا 1 على مر السنين. ومن هنا المهام التي واجهها نموذجي: إصدار توقعات لن تكون أسوأ من تلك التي تم إنشاؤها "بالعين". ومن الناحية المثالية ، يجب أن يتغلب النموذج ، بالطبع ، على خصوم الإنسان.
يركز هذا النموذج فقط على التنبؤ بنتيجة المؤهلات ، حيث أن المؤهلات يمكن التنبؤ بها أكثر من السباقات ويسهل تصميمها. ومع ذلك ، بالطبع ، في المستقبل ، أخطط لإنشاء نموذج يسمح بالتنبؤ بنتائج السباقات بدقة كافية.
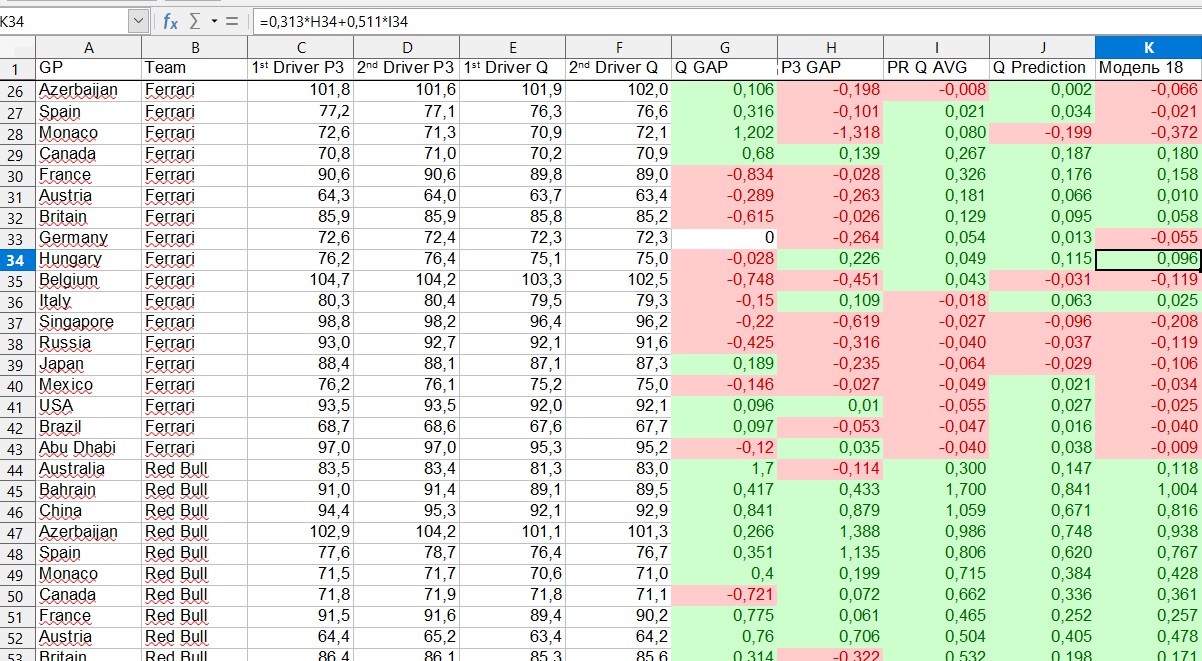
لإنشاء نموذج ، قمت بتلخيص جميع نتائج الممارسات والمؤهلات لموسم 2018 و 2019 في جدول واحد. 2018 كان بمثابة عينة تدريبية ، و 2019 كعينة اختبار. بناءً على هذه البيانات ، قمنا ببناء انحدار خطي . لوضع الانحدار ببساطة قدر الإمكان ، بياناتنا هي مجموعة من النقاط على مستوى إحداثيات. لقد رسمنا خطًا مستقيمًا ينحرف عن مجمل هذه النقاط. والوظيفة ، الرسم البياني الذي هو هذا الخط - هذا هو الانحدار الخطي لدينا.
من الصيغة المعروفة من المناهج الدراسيةتتميز وظيفتنا فقط بحقيقة أن لدينا متغيرين. المتغير الأول (X1) هو التأخر في الممارسة الثالثة ، والمتغير الثاني (X2) هو متوسط التأخير في المؤهلات السابقة. هذه المتغيرات ليست متكافئة ، وأحد أهدافنا هو تحديد وزن كل متغير في النطاق من 0 إلى 1. كلما كان المتغير من الصفر ، كلما كان أكثر أهمية في شرح المتغير التابع. في حالتنا ، المتغير التابع هو وقت اللفة ، معبراً عنه في الفارق خلف القائد (أو ، بشكل أدق ، من "دائرة مثالية" معينة ، لأن هذه القيمة كانت إيجابية لجميع الطيارين).
قد يتذكر المعجبون بكتاب Moneyball (الذي لم يتم شرحه في الفيلم) أنه باستخدام الانحدار الخطي ، قرروا أن النسبة الأساسية ، المعروفة أيضًا بـ OBP (النسبة المئوية على الأساس) ، ترتبط ارتباطًا وثيقًا بالجروح المكتسبة من الإحصاءات الأخرى. هدفنا هو نفسه تقريبًا: لفهم العوامل الأكثر ارتباطًا بنتائج المؤهلات. واحدة من المزايا الكبيرة للانحدار هي أنه لا يتطلب معرفة متقدمة بالرياضيات: نحن فقط ندخل البيانات ، ثم Excel أو محرر جداول بيانات آخر يمنحنا معاملات جاهزة.
في الأساس ، نريد أن نعرف شيئين مع الانحدار الخطي. أولاً ، مدى تفسير المتغيرات المستقلة المختارة للتغيير في الوظيفة. وثانيًا ، مدى أهمية كل من هذه المتغيرات المستقلة. بمعنى آخر ، ما الذي يفسر نتائج التأهيل بشكل أفضل: نتائج السباقات على المسارات السابقة أو نتائج الدورات التدريبية على نفس المسار.
يجب ملاحظة نقطة مهمة هنا. كانت النتيجة النهائية مجموع معلمتين مستقلتين ، نتج كل منهما عن انحدارين مستقلين. المعلمة الأولى هي قوة الفريق في هذه المرحلة ، وبشكل أدق ، تأخر أفضل طيار للفريق من القائد. المعلمة الثانية هي توزيع القوى داخل الفريق.
ماذا يعني هذا بالقدوة؟ لنفترض أننا نأخذ جائزة المجر الكبرى لعام 2019. يظهر النموذج أن فيراري سيكون بفارق 0.218 ثانية خلف القائد. ولكن هذا هو تأخر الطيار الأول ، ومن سيكونون - Vettel أو Leclair - وما هي الفجوة بينهما ، يتم تحديدها بواسطة معلمة أخرى. في هذا المثال ، أظهر النموذج أن Vettel سيتقدم ، وسيخسر Leclair 0.096 ثانية له.
لماذا مثل هذه الصعوبات؟ أليس من الأسهل التفكير في كل طيار بشكل منفصل بدلاً من هذا الانهيار في تأخر الفريق وتأخر الطيار الأول من الثاني داخل الفريق؟ ربما يكون الأمر كذلك ، لكن ملاحظاتي الشخصية تظهر أن النظر إلى نتائج الفريق أكثر موثوقية بكثير من نتائج كل طيار. يمكن أن يقوم أحد الطيارين بارتكاب خطأ ، أو التحليق عن المسار ، أو سيواجه مشاكل فنية - كل هذا سيجلب الفوضى إلى النموذج ، ما لم تتبع يدويًا كل حالة قوة قاهرة ، الأمر الذي يستغرق الكثير من الوقت. تأثير القوة القاهرة على نتائج الفريق أقل بكثير.
ولكن بالعودة إلى النقطة التي أردنا فيها تقييم مدى جودة متغيراتنا التفسيرية المختارة في تفسير التغيير في الوظيفة. يمكن القيام بذلك باستخدام معامل التحديد... وسوف يوضح مدى تفسير نتائج التأهيل من خلال نتائج التدريب والمؤهلات السابقة.
نظرًا لأننا قمنا ببناء انحدارين ، فلدينا أيضًا معاملين للتصميم. الانحدار الأول مسؤول عن مستوى الفريق في المرحلة ، والثاني عن المواجهة بين طياري الفريق نفسه. في الحالة الأولى ، يكون معامل التحديد هو 0.82 ، أي أن 82٪ من نتائج المؤهلات يتم تفسيرها من خلال العوامل التي اخترناها ، و 18٪ أخرى - من خلال بعض العوامل الأخرى التي لم نأخذها بعين الاعتبار. هذه نتيجة جيدة في الحالة الثانية ، كان معامل التحديد 0.13.
هذه المقاييس ، في جوهرها ، تعني أن النموذج يتنبأ بمستوى الفريق بشكل معقول ، ولكنه يواجه مشكلة في تحديد الفجوة بين زملائه. ومع ذلك ، بالنسبة للهدف النهائي ، لا نحتاج إلى معرفة الفجوة ، نحتاج فقط إلى معرفة أي من الطيارين سيكون أعلى ، والنموذج يتعامل بشكل أساسي مع هذا. في 62٪ من الحالات ، احتل النموذج مرتبة أعلى من الطيار الذي كان حقاً أعلى في المؤهل.
في الوقت نفسه ، عند تقييم قوة الفريق ، كانت نتائج التدريب الأخير أكثر أهمية مرة ونصف من نتائج المؤهلات السابقة ، ولكن في المبارزات داخل الفريق كانت العكس. تجلى هذا الاتجاه في بيانات 2018 و 2019.
تبدو الصيغة النهائية كما يلي:
الطيار الأول:
الطيار الثاني:
دعني أذكرك بأن X1 هي الفجوة في الممارسة الثالثة ، و X2 هي متوسط التأخير في المؤهلات السابقة.
ماذا تعني هذه الأرقام. يقصدون أن مستوى الفريق في المؤهل 60٪ تحدده نتائج الممارسة الثالثة و 40٪ - بنتائج المؤهلات في المراحل السابقة. وبناء على ذلك ، فإن نتائج الممارسة الثالثة هي عامل ونصف مرة أكثر أهمية من نتائج المؤهلات السابقة.
من المحتمل أن يعرف المعجبون بالصيغة 1 الإجابة على هذا السؤال ، لكن بالنسبة للبقية ، يجب عليك التعليق على سبب أخذ نتائج التمرين الثالث. هناك ثلاث ممارسات في الفورمولا 1. ومع ذلك ، في الأخير منهم تدرب الفرق بشكل تقليدي على المؤهلات. ومع ذلك ، في الحالات التي فشلت فيها الممارسة الثالثة بسبب المطر أو قوة قاهرة أخرى ، أخذت نتائج الممارسة الثانية. بقدر ما أتذكر ، في عام 2019 ، كانت هناك حالة واحدة فقط - في سباق الجائزة الكبرى الياباني ، عندما تم عقد المرحلة في شكل تقصير بسبب الإعصار.
أيضا ، ربما لاحظ شخص ما أن النموذج يستخدم متوسط التأخير في المؤهلات السابقة. ولكن ماذا عن المرحلة الأولى من الموسم؟ لقد استخدمت التأخيرات من العام السابق ، لكنني لم أتركها كما هي ، ولكن قمت بتعديلها يدويًا بناءً على الحس السليم. على سبيل المثال ، في عام 2019 ، كان فيراري في المتوسط 0.3 ثانية أسرع من ريد بول. ومع ذلك ، يبدو أن الفريق الإيطالي لن يكون لديه مثل هذه الميزة هذا العام ، أو ربما سيكون متأخراً تمامًا. لذلك ، بالنسبة للمرحلة الأولى من موسم 2020 ، سباق الجائزة الكبرى النمساوي ، قمت بتقريب ريد بول يدويًا من فيراري.
بهذه الطريقة حصلت على تأخر كل طيار ، صنفت الطيارين بفارق متأخر وحصلت على التنبؤ النهائي للتأهل. من المهم أن نفهم ، مع ذلك ، أن الطيارين الأول والثاني هم اصطلاحات محضة. بالعودة إلى المثال مع Vettel و Leclair ، في سباق الجائزة الكبرى المجري ، اعتبر النموذج أن سباستيان هو الطيار الأول ، لكنها فضلت في العديد من المراحل الأخرى Leclair.
النتائج
كما قلت ، كانت المهمة هي إنشاء نموذج يجعل من الممكن التنبؤ وكذلك الناس. كأساس ، أخذت توقعاتي وتنبؤات زملائي في الفريق ، والتي تم إنشاؤها "بالعين" ، ولكن مع دراسة متأنية لنتائج الممارسات والمناقشة المشتركة.
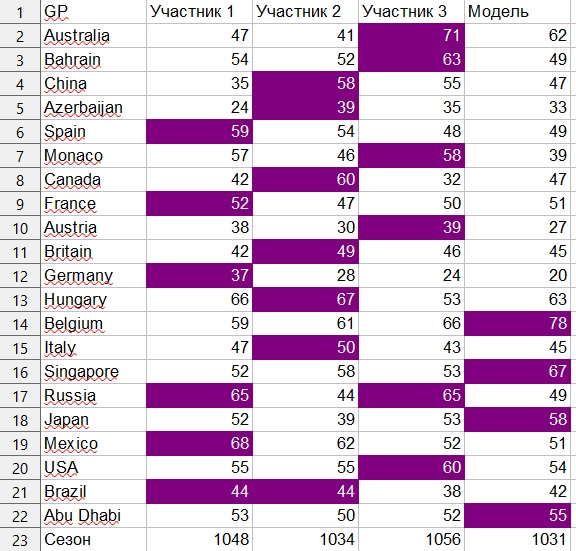
كان نظام التصنيف على النحو التالي. تم أخذ أفضل عشرة طيارين فقط بعين الاعتبار. للحصول على ضربة دقيقة ، تلقت التوقعات 9 نقاط ، لخطأ في الموضع 1 ، 6 نقاط ، لخطأ في الموضع 2 ، 4 نقاط ، لخطأ في الموضع 3 ، 2 نقطة ، وللخطأ في الموضع 4 ، 1 نقطة. أي إذا كان الطيار في التوقعات في المركز الثالث ، ونتيجة لذلك أخذ موقع الصدارة ، ثم حصلت التوقعات على 4 نقاط.
باستخدام هذا النظام ، يبلغ الحد الأقصى لعدد النقاط لـ 21 الجائزة الكبرى 1890.
وسجل المشاركون البشريون 1056 و 1048 و 1034 نقطة على التوالي.
حقق النموذج 1031 نقطة ، على الرغم من أنه مع المعالجة الخفيفة للمعاملات ، تلقيت أيضًا 1045 و 1053 نقطة.
أنا شخصياً مسرور بالنتائج ، لأن هذه هي تجربتي الأولى في بناء الانحدارات ، وأدت إلى نتائج مقبولة تمامًا. بالطبع ، أود تحسينها ، لأنني متأكد من أنه بمساعدة بناء النماذج ، حتى بهذه البساطة ، يمكنك تحقيق نتائج أفضل من مجرد تقييم البيانات "بالعين". في إطار هذا النموذج ، سيكون من الممكن ، على سبيل المثال ، أن نأخذ في الاعتبار عامل ضعف بعض الفرق في الممارسة ، ولكن "تبادل لاطلاق النار" في المؤهلات. على سبيل المثال ، هناك ملاحظة مفادها أن مرسيدس لم تكن في الغالب أفضل فريق أثناء التدريب ، لكنها كانت تؤدي بشكل أفضل في المؤهلات. ومع ذلك ، لم تنعكس هذه الملاحظات البشرية في النموذج. لذا في موسم 2020 ، الذي يبدأ في يوليو (إذا لم يحدث شيء غير متوقع) ، أريد اختبار هذا النموذج في منافسة ضد المتنبئين المباشرين وأيضاً أجد ،كيف يمكن تحسينه.
بالإضافة إلى ذلك ، آمل أن أتلقى صدى لدى مجتمع المعجبين بالفورمولا 1 وأعتقد أنه من خلال تبادل الأفكار يمكننا أن نفهم بشكل أفضل ما يشكل نتائج المؤهلات والأجناس ، وهذا هو في النهاية هدف أي شخص يقوم بالتنبؤات.