للحصول على نظرة عامة ، اتخذنا إجراءات CHI: مؤتمر حول العوامل البشرية في أنظمة الحوسبة لمدة 10 سنوات ، وبمساعدة NLP وتحليل الشبكة الاجتماعية ، نظرنا في الموضوعات والمجالات عند تقاطع التخصصات.

في روسيا ، يكون التركيز قويًا بشكل خاص على المشكلات التطبيقية لتصميم UX. لم تحدث العديد من الأحداث التي ساعدت على نمو HCI في الخارج في بلدنا: لم تظهر iSchools ، وترك العديد من المتخصصين الذين شاركوا في الجوانب ذات الصلة من علم النفس الهندسي العلوم ، وما إلى ذلك. ونتيجة لذلك ، عادت المهنة إلى الظهور ، بدءًا من المشكلات التطبيقية والبحث. واحدة من نتائج هذا مرئية حتى الآن - هو التمثيل المنخفض للغاية لعمل HCI الروسي في المؤتمرات الرئيسية.
ولكن خارج روسيا ، تطور HCI بطرق مختلفة جدًا ، مع التركيز على مجموعة متنوعة من المواضيع والمجالات. على برنامج الماجستير " نظم المعلومات والتفاعل بين الإنسان والحاسوب»في سانت بطرسبرغ HSE ، نناقش ، من بين أمور أخرى - مع الطلاب والزملاء والخريجين من التخصصات المماثلة من الجامعات الأوروبية والشركاء الذين يساعدون في تطوير البرنامج - ما ينتمي إلى مجال التفاعل بين الإنسان والحاسوب. وتظهر هذه المناقشات عدم تجانس الاتجاه الذي يمتلك فيه كل متخصص صورة خاصة به غير مكتملة عن المجال.
نسمع من وقت لآخر أسئلة حول كيفية ارتباط هذا الاتجاه (وما إذا كان مرتبطًا على الإطلاق) بالتعلم الآلي وتحليل البيانات. للإجابة عنها ، لجأنا إلى البحث الأخير المقدم في مؤتمر CHI . بادئ ذي بدء ، سنخبرك
بما يحدث في مجالات مثل xAI و iML (الذكاء الاصطناعي القابل للتطبيق والتعلم الآلي القابل للتفسير) من جانب الواجهات والمستخدمين ، وكذلك كيف يدرسون في HCI الجوانب المعرفية لعمل علماء البيانات ، وسنقدم أمثلة على العمل المثير للاهتمام في السنوات الأخيرة في كل مجال.
xAI و iML
تخضع تقنيات تعلُم الآلة لتنمية مكثفة - والأهم من وجهة نظر المنطقة قيد المناقشة - يتم تنفيذها بنشاط في صنع القرار الآلي. لذلك ، يناقش الباحثون بشكل متزايد الأسئلة التالية: كيف يتفاعل المستخدمون الذين لا يتعلمون الآلة مع الأنظمة التي يتم فيها استخدام خوارزميات مماثلة؟ أحد الأسئلة المهمة لهذا التفاعل: كيف تجعل المستخدمين يثقون بالقرارات التي تتخذها النماذج؟ لذلك ، في كل عام ، أصبحت موضوعات التعلم الآلي المفسر (التعلم الآلي القابل للتفسير - iML) والذكاء الاصطناعي القابل للتفسير (الذكاء الاصطناعي القابل للتوسيع - XAI) تزداد سخونة.
في الوقت نفسه ، إذا تمت مناقشة مؤتمرات مثل NeurIPS و ICML و IJCAI و KDD وخوارزميات ووسائل iML و XAI ، تركز CHI على العديد من الموضوعات المتعلقة بميزات التصميم وتجربة استخدام هذه الأنظمة. على سبيل المثال ، في CHI-2020 ، تم تخصيص عدة أقسام لهذا الموضوع مرة واحدة ، بما في ذلك "AI / ML & رؤية من خلال الصندوق الأسود" و "التعامل مع AI: not agAIn!". ولكن حتى قبل ظهور أقسام منفصلة ، كان هناك العديد من هذه الأعمال. لقد حددنا أربعة مجالات فيها.
تصميم النظم التفسيرية لحل المشكلات التطبيقية
الاتجاه الأول هو تصميم أنظمة تعتمد على خوارزميات التفسير في مختلف المشاكل التطبيقية: الطبية ، الاجتماعية ، إلخ. تنشأ مثل هذه الأعمال في مناطق مختلفة جدًا. على سبيل المثال ، العمل في CHI-2020 CheXplain: تمكين الأطباء من استكشاف وفهم تحليل التصوير الطبي المعتمد على البيانات والمدعوم بالذكاء الاصطناعي يصف النظام الذي يساعد الأطباء على فحص وشرح نتائج الأشعة السينية على الصدر. تقدم تفسيرات نصية ومرئية إضافية ، بالإضافة إلى صور لها نفس النتيجة والعكس (أمثلة داعمة ومتضاربة). إذا توقع النظام أن المرض مرئي على الأشعة السينية ، فسوف يظهر مثالين. المثال الداعم الأول هو لقطة للرئتين لمريض آخر أكد نفس المرض. المثال الثاني المتناقض هو لقطة لا يوجد فيها مرض ، أي لقطة لرئتي شخص سليم. الفكرة الرئيسية هي تقليل الأخطاء الواضحة وتقليل عدد الاستشارات الخارجية في الحالات البسيطة من أجل جعل التشخيص أسرع.
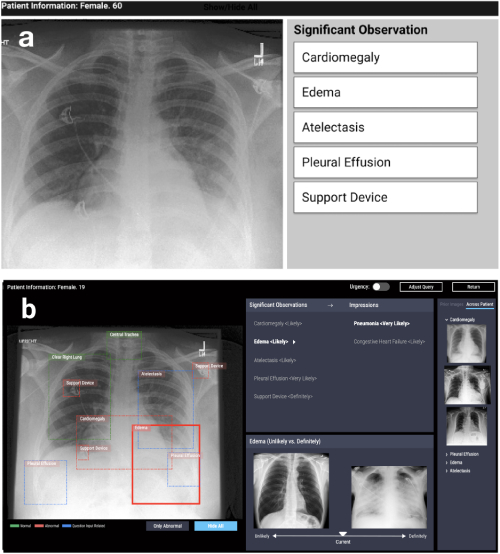
CheXpert: اختيار المنطقة الآلية + أمثلة (غير مرجح مقابل بالتأكيد)
تطوير أنظمة للبحث عن نماذج التعلم الآلي
الاتجاه الثاني هو تطوير الأنظمة التي تساعد على المقارنة أو الجمع بين العديد من الأساليب والخوارزميات بشكل تفاعلي. على سبيل المثال ، في عمل Silva: تقييم تفاعل تعلم الآلة بشكل تفاعلي باستخدام السببية في CHI-2020 ، تم تقديم نظام يبني العديد من نماذج التعلم الآلي على بيانات المستخدم ويوفر إمكانية تحليلها اللاحق. يتضمن التحليل بناء رسم بياني سببي بين المتغيرات وحساب عدد من المقاييس التي تقيّم ليس فقط الدقة ، ولكن أيضًا عدالة النموذج (اختلاف التكافؤ الإحصائي ، اختلاف تكافؤ الفرص ، متوسط اختلاف الاحتمالات ، تأثير متباين ، مؤشر Theil) ، مما يساعد على إيجاد التحيز في التنبؤات.

سيلفا : رسم بياني للعلاقات بين المتغيرات + الرسوم البيانية لمقارنة مقاييس الإنصاف + تمييز اللون للمتغيرات المؤثرة في كل مجموعة
القضايا العامة لتفسير النموذج
المجال الثالث هو مناقشة المقاربات لمشكلة قابلية تفسير النماذج بشكل عام. غالبًا ما تكون هذه المراجعات ونقد النهج والأسئلة المفتوحة: على سبيل المثال ، ما المقصود بـ "قابلية التفسير". هنا أود أن أشير إلى المراجعة في اتجاهات ومسارات CHI-2018 للأنظمة القابلة للتفسير والمساءلة والذكية: أجندة أبحاث HCI، حيث استعرض المؤلفون 289 ورقة رئيسية حول تفسيرات في الذكاء الاصطناعي ، و 12،412 منشورات تستشهد بها. باستخدام تحليل الشبكة ونمذجة الحالة ، حددوا أربعة مجالات بحث رئيسية 1) الأنظمة الذكية والمحيطة (I&A) ، 2) الذكاء الاصطناعي القابل للتفسير: خوارزميات عادلة ومسؤولة وشفافة (FAT) وتعلم الآلة القابل للتفسير (iML) ، 3) نظريات التفسيرات: السببية وعلم النفس المعرفي ، 4) التفاعل والقابلية للتعلم. بالإضافة إلى ذلك ، وصف المؤلفون اتجاهات البحث الرئيسية: التعلم التفاعلي والتفاعل مع النظام.
بحث المستخدم
أخيرًا ، المجال الرابع هو بحث المستخدم حول الخوارزميات والأنظمة التي تفسر نماذج التعلم الآلي. بمعنى آخر ، هذه دراسات حول ما إذا كانت الأنظمة الجديدة في الواقع أصبحت أكثر وضوحًا وأكثر شفافية ، وما هي الصعوبات التي يواجهها المستخدمون عند العمل مع النماذج التفسيرية بدلاً من النماذج الأصلية ، وكيفية تحديد ما إذا كان النظام يتم استخدامه كما هو مخطط له (أو تم اكتشاف استخدام جديد له) - ربما غير صحيح) ، ما هي احتياجات المستخدمين وما إذا كان المطورون يقدمون لهم ما يحتاجونه حقًا.
هناك الكثير من أدوات وخوارزميات التفسير ، لذلك يبرز السؤال: كيف نفهم الخوارزمية التي نختارها؟ في استجواب منظمة العفو الدولية: إعلام ممارسات التصميم لتجارب مستخدمي الذكاء الاصطناعي القابلة للتفسيرتتم مناقشة قضايا الدافع لاستخدام الخوارزميات التفسيرية ويتم تحديد المشكلات التي لم يتم حلها بما فيه الكفاية مع جميع الأساليب المتنوعة. توصل المؤلفون إلى استنتاج غير متوقع: معظم الأساليب الحالية مبنية بطريقة تجيب على السؤال "لماذا" ("لماذا حصلت على مثل هذه النتيجة") ، بينما يحتاج المستخدمون أيضًا إلى إجابة للسؤال "لماذا لا" ("لماذا ليس آخر ") ، وأحيانًا -" ما يجب فعله لتغيير النتيجة ".
تقول الورقة أيضًا أن المستخدمين بحاجة إلى فهم ما هي حدود قابلية تطبيق الطرق ، وما هي القيود التي لديهم - وهذا يجب تنفيذه بشكل صريح في الأدوات المقترحة. تظهر هذه المشكلة بشكل أوضح في المقالةتفسير التفسير: فهم استخدام علماء البيانات لأدوات التفسير لتعلم الآلة . أجرى المؤلفون تجربة صغيرة مع متخصصين في مجال تعلُم الآلة: أظهروا نتائج العديد من الأدوات الشائعة لتفسير نماذج تعلُّم الآلة وطلبوا منهم الإجابة عن الأسئلة المتعلقة باتخاذ القرارات بناءً على هذه النتائج. اتضح أنه حتى الخبراء يثقون في مثل هذه النماذج ولا يأخذون النتائج بشكل نقدي. مثل أي أداة ، يمكن إساءة استخدام النماذج التفسيرية. عند تطوير مجموعة الأدوات ، من المهم أخذ ذلك في الاعتبار ، باستخدام المعرفة المتراكمة (أو المتخصصين) في مجال التفاعل بين الإنسان والحاسوب من أجل مراعاة خصائص واحتياجات المستخدمين المحتملين.
Data Science, Notebooks, Visualization
مجال آخر مثير للاهتمام من HCI هو في تحليل الجوانب المعرفية للعمل مع البيانات. في الآونة الأخيرة ، أثار العلم سؤالاً حول كيفية تأثير "درجات الحرية" للباحث - ميزات جمع البيانات والتصميم التجريبي واختيار الأساليب التحليلية - على نتائج البحث واستنساخها. في حين أن الكثير من النقاش والنقد مرتبط بعلم النفس والعلوم الاجتماعية ، فإن العديد من المشاكل تتعلق بموثوقية الاستنتاجات في عمل محللي البيانات بشكل عام ، وكذلك الصعوبات في إيصال هذه الاستنتاجات إلى مستهلكي التحليل.
لذلك ، فإن موضوع منطقة HCI هذه هو تطوير طرق جديدة لتصور عدم اليقين في تنبؤات النموذج ، وإنشاء أنظمة لمقارنة التحليلات التي يتم تنفيذها بطرق مختلفة ، بالإضافة إلى تحليل عمل المحللين بأدوات مثل دفاتر Jupyter.
تصور عدم اليقين
التصور الغامض هو إحدى الميزات التي تميز الرسومات العلمية عن العرض التقديمي والتصور التجاري. لفترة طويلة ، كان مبدأ البساطة والتركيز على الاتجاهات الرئيسية هو المفتاح في هذا الأخير. ومع ذلك ، يؤدي هذا إلى زيادة ثقة المستخدمين في تقدير نقطة من حيث الحجم أو التوقعات ، والتي يمكن أن تكون حاسمة ، خاصة إذا كان علينا مقارنة التوقعات بدرجات مختلفة من عدم اليقين. يعرض عدم اليقين بشأن العمل باستخدام نقاط النقاط الكمية أو CDFs تحسين عملية اتخاذ قرار العبوريدرس كيف يساعد تصور عدم اليقين في التنبؤ بالمخططات المبعثرة ووظائف التوزيع التراكمي المستخدمين على اتخاذ قرارات أكثر عقلانية باستخدام مثال مشكلة تقدير وقت وصول الحافلة من بيانات تطبيق الهاتف المحمول. ما هو لطيف بشكل خاص هو أن أحد المؤلفين يحتفظ بحزمة ggdist لـ R مع خيارات متنوعة لتصور الغموض.

أمثلة على التصور غير المؤكد ( https://mjskay.github.io/ggdist/ )
ومع ذلك ، غالبًا ما تصادف مهام تصور البدائل المحتملة ، على سبيل المثال ، لتسلسل إجراءات المستخدم في تحليلات الويب أو تحليلات التطبيق. العمل على تصور عدم اليقين والبدائل في تنبؤات تسلسل الأحداث يحلل كيف أن التمثيل البياني للبدائل على أساس نموذج الشبكة العصبية المتكررة (TRNN ) يساعد الخبراء على اتخاذ القرارات والثقة بها.
مقارنة النماذج
على الرغم من أهمية تصور عدم اليقين ، فإن أحد جوانب عمل المحللين هو مقارنة كيف - غالبًا ما يكون مخفيًا - يمكن أن يؤدي اختيار الباحث للنهج المختلفة للنمذجة في جميع مراحلها إلى نتائج تحليلية مختلفة. في علم النفس والعلوم الاجتماعية ، يكتسب التسجيل المسبق لتصميم البحث والفصل الواضح بين الدراسات الاستكشافية والتأكيدية شعبية. ومع ذلك ، في المهام التي يكون فيها البحث أكثر اعتمادًا على البيانات ، يمكن أن يكون البديل أدوات تسمح لك بتقييم المخاطر الخفية للتحليل من خلال مقارنة النماذج. العمل على زيادة شفافية الأوراق البحثية مع تحليلات الأكوان المتعددة القابلة للاستكشافيقترح استخدام التصور التفاعلي لعدة طرق للتحليل في المقالات. في جوهرها ، تتحول المقالة إلى تطبيق تفاعلي حيث يمكن للقارئ تقييم ما سيتغير في النتائج والاستنتاجات إذا تم تطبيق نهج مختلف. تبدو هذه فكرة مفيدة للتحليلات العملية أيضًا.
العمل باستخدام أدوات لتنظيم البيانات وتحليلها
تتعلق آخر مجموعة من الأعمال بدراسة كيفية عمل المحللين مع أنظمة مثل Jupyter Notebooks ، والتي أصبحت أداة شائعة لتنظيم تحليل البيانات. مقال الاستكشاف والشرح في دفاتر الحوسبة يحلل التناقضات بين البحث ويشرح أهداف التعلم الموجودة في مستندات Github التفاعلية ، وإدارة الفوضى في دفاتر الحوسبةيحلل المؤلفون كيفية تطور الملاحظات وأجزاء التعليمات البرمجية والمرئيات في سير عمل محلل تكراري ، ويقترحون الإضافات المحتملة للأدوات لدعم هذه العملية. أخيرًا ، في CHI 2020 بالفعل ، يتم تلخيص المشاكل الرئيسية للمحللين في جميع مراحل العمل ، من تحميل البيانات إلى نقل نموذج إلى الإنتاج ، بالإضافة إلى أفكار لتحسين الأدوات ، في المقالة ما هو الخطأ في أجهزة الكمبيوتر المحمولة؟ نقاط الألم والاحتياجات وفرص التصميم .
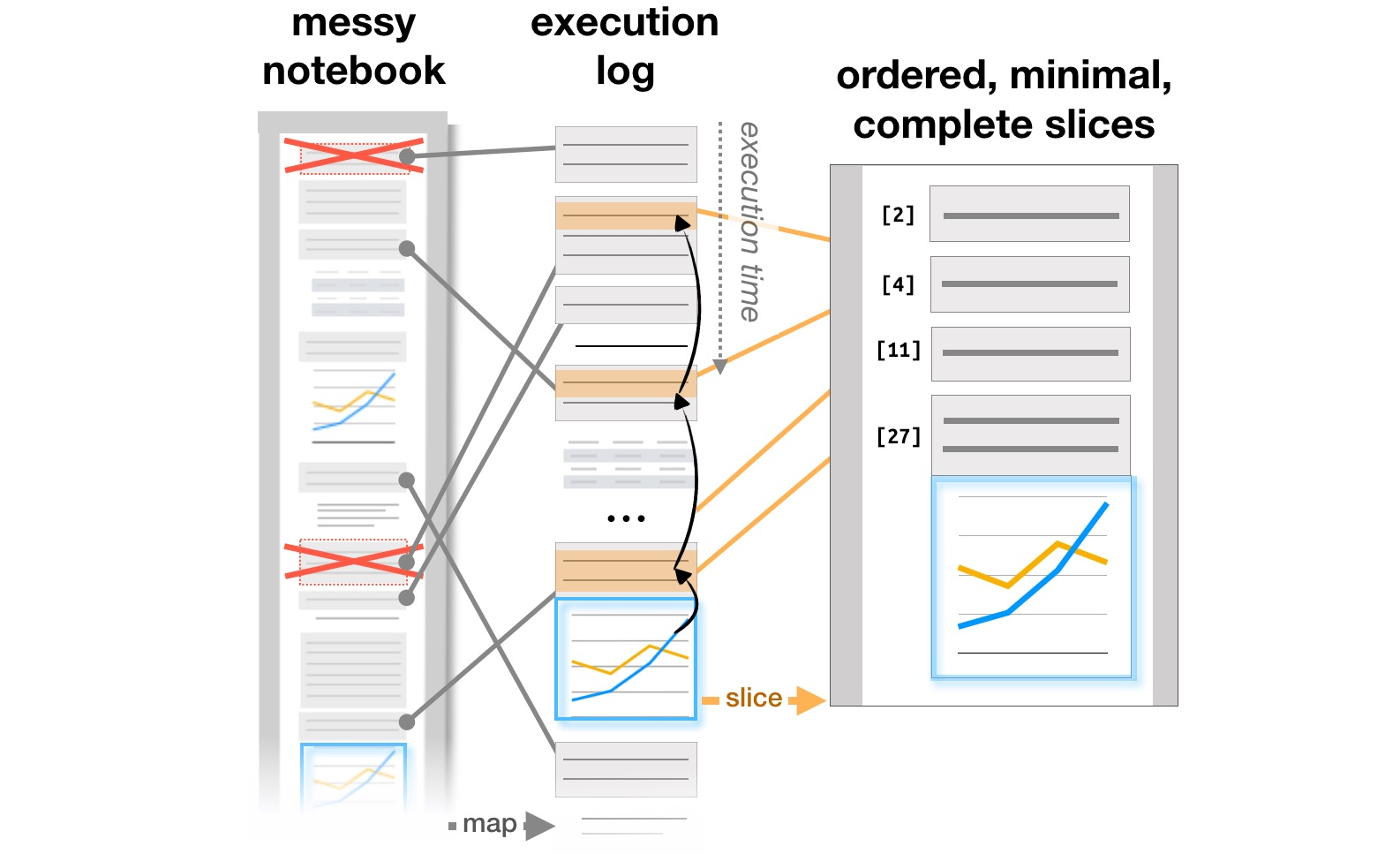
تحويل هيكل التقارير على أساس سجلات التنفيذ ( https://microsoft.github.io/gather/ )
تلخيص
في ختام جزء المناقشة "ماذا يفعل HCI" و "لماذا يعرف اختصاصي HCI التعلم الآلي" ، أود أن أكرر الاستنتاج العام من دوافع ونتائج هذه الدراسات. بمجرد ظهور الشخص في النظام ، يؤدي هذا على الفور إلى عدد من الأسئلة الإضافية: كيفية تبسيط التفاعل مع النظام وتجنب الأخطاء ، وكيف يغير المستخدم النظام ، وما إذا كان الاستخدام الفعلي يختلف عن المخطط. نتيجة لذلك ، نحن بحاجة إلى أولئك الذين يفهمون كيف تعمل عملية تصميم الأنظمة باستخدام الذكاء الاصطناعي ، ويعرفون كيف يأخذون في الاعتبار العامل البشري.
نقوم بتدريس كل هذا على برنامج الماجستير " نظم المعلومات والتفاعل بين الإنسان والحاسوب". إذا كنت مهتمًا بأبحاث HCI ، فقم بفحص الضوء (بدأت حملة القبول للتو ). أو تابع مدونتنا: سنخبرك بالمزيد حول المشاريع التي كان الطلاب يعملون عليها هذا العام.