اعتدت أن أكون قائد فريق ، وكنت مسؤولاً عن اثنين من الخدمات الحيوية. وإذا حدث خطأ فيها ، فقد أوقف العمليات التجارية الحقيقية. على سبيل المثال ، توقفت الطلبات عن التجميع في المستودع.
أصبحت مؤخرًا قائدًا للقيادة وأنا الآن مسؤول عن ثلاثة فرق بدلاً من فريق واحد. كل منهم يدير نظام تكنولوجيا المعلومات. أريد أن أفهم ما يحدث في كل نظام وما يمكن أن ينكسر.
في هذه المقالة سأتحدث عنه
- ما نراقب
- كما نراقب
- والأهم من ذلك: ماذا نفعل بنتائج هذه الملاحظات.

لامودا لديها العديد من الأنظمة. يتم تحريرها جميعًا ، ويتغير شيء فيها ، ويحدث شيء لهذه التقنية. وأريد أن أتوهم على الأقل أنه يمكننا بسهولة تحديد موقع الانهيار. أنا باستمرار قصفت بالتنبيهات التي أحاول اكتشافها. من أجل الابتعاد عن التجريد والذهاب إلى التفاصيل ، سأخبرك بالمثال الأول.
من وقت لآخر ينفجر شيء ما: سجلات الحريق
في صباح أحد أيام الصيف الحارة دون إعلان الحرب ، كما هو الحال عادة ، عملت المراقبة لصالحنا. كتنبيه ، نستخدم Icinga. قال Alert أن لدينا 50 غيغابايت من محرك الأقراص الثابتة على خادم DBMS. على الأرجح ، 50 غيغابايت هي قطرة في الدلو ، وسوف تنتهي بسرعة كبيرة. قررنا أن نرى مقدار المساحة الحرة المتبقية. عليك أن تفهم أن هذه ليست آلات افتراضية ، ولكنها خوادم حديدية ، والقاعدة تحت حمولة ثقيلة. يوجد 1.5 تيرابايت SSD. قريبا ستنتهي هذه الذاكرة: ستستمر لمدة 20-30 يومًا. هذا صغير جدًا ؛ تحتاج إلى حل المشكلة بسرعة.
ثم قمنا أيضًا بالتحقق من مقدار الذاكرة المستهلكة بالفعل خلال يوم أو يومين. اتضح أن 50 غيغابايت تكفي لمدة 5-7 أيام. بعد ذلك ، ستنتهي الخدمة التي تعمل مع قاعدة البيانات هذه بشكل متوقع. بدأنا نفكر في العواقب: أننا نسجل بشكل عاجل البيانات التي سنحذفها. يحتوي قسم تحليلات البيانات على جميع النسخ الاحتياطية ، بحيث يمكنك إسقاط كل شيء أقدم من عام 2015 بأمان.
نحاول حذفها ونتذكر أن MySQL لن تعمل بهذه الطريقة من نصف ركلة. البيانات المحذوفة رائعة ، ولكن لا يتغير حجم الملف المخصص للجدول ولقاعدة البيانات. ثم يستخدم MySQL هذه المساحة. أي أن المشكلة لم تحل ، فليس هناك مساحة أخرى.
تجربة نهج مختلف: ترحيل الملصقات من أقراص SSD سريعة الصلاحية إلى أبطأ. للقيام بذلك ، حدد الأجهزة اللوحية التي تزن الكثير ، ولكن تحت حمولة صغيرة ، واستخدم مراقبة بيركونا. نقلنا الجداول ونفكر بالفعل في نقل الخوادم نفسها. بعد الخطوة الثانية ، لا تستهلك الخوادم 1.5 ، ولكن 4 تيرابايت من SSD.
أخمدنا هذا الحريق: نظمنا خطوة ، وبطبيعة الحال ، مراقبة ثابتة. الآن سيتم تشغيل التحذير ليس على 50 غيغابايت ، ولكن على نصف تيرابايت ، وقيمة المراقبة الحرجة - على 50 غيغابايت. لكن في الواقع ، إنها مجرد بطانية من مؤخرة المؤخرة. سيستمر لفترة من الوقت. ولكن إذا سمحنا بتكرار الموقف ، دون تقسيم القاعدة إلى أجزاء وعدم التفكير في التقسيم ، فسينتهي كل شيء بشكل سيئ.
افترض أننا قمنا بتغيير الخادم بشكل أكبر. في مرحلة ما ، كان مطلوبًا إعادة تشغيل المعلم. على الأرجح ، ستظهر أخطاء في هذه الحالة. في حالتنا ، كانت فترة التوقف حوالي 30 ثانية. لكن الطلبات قادمة ، ولا يوجد مكان للكتابة ، وتدفق الأخطاء ، وعملت المراقبة. نستخدم نظام مراقبة بروميثيوس - ونرى فيه أن مقياس 500 خطأ أو عدد الأخطاء عند إنشاء أمر قفز. لكننا لا نعرف التفاصيل: أي نوع من النظام لم يتم إنشاؤه ، وما إلى ذلك.
علاوة على ذلك ، سأخبرك كيف نعمل مع المراقبة حتى لا ندخل في مثل هذه المواقف.
مراجعة المراقبة ووصف واضح لخدمة الدعم
لدينا عدة اتجاهات ومؤشرات نراقبها. هناك أجهزة تلفزيون في كل مكان في المكتب ، حيث يوجد العديد من الملصقات الفنية والتجارية المختلفة ، والتي ، بالإضافة إلى المطورين ، تتم مراقبتها بواسطة خدمة الدعم.
في هذه المقالة ، أتحدث عن كيف لدينا وأضيف ما نريد الوصول إليه. ينطبق هذا أيضًا على مراقبة المراجعات. إذا أجرينا جردًا دوريًا لـ "ممتلكاتنا" ، فيمكننا تحديث كل شيء قديم وإصلاحه ، ومنع تكرار fakap. هذا يتطلب قائمة متماسكة.
لدينا إعدادات التهيئة مع التنبيهات في المستودع ، حيث يوجد الآن 4678 سطرًا. من هذه القائمة ، من الصعب فهم ما يتحدث عنه كل رصد محدد. لنفترض أن مقياسنا يسمى db_disc_space_left. لن تفهم خدمة الدعم على الفور موضوعها. شيء عن المساحة الحرة ، رائع.
نريد أن نتعمق أكثر. نحن ننظر إلى تكوين هذه المراقبة ونفهم مصدرها.
pm_host: "{{ prometheus_server }}"
pm_query: ”mysql_ssd_space_left"
pm_warning: 50
pm_critical: 10 pm_nanok: 1
يحتوي هذا المقياس على اسم ، وحدود خاصة به ، عند تمكين مراقبة التحذير ، تنبيه للإبلاغ عن حالة حرجة. نستخدم اصطلاح تسمية المقاييس. يوجد في بداية كل مقياس اسم النظام. وبفضل هذا ، تصبح منطقة المسؤولية واضحة. إذا بدأ الشخص المسؤول عن النظام المقياس ، فمن الواضح على الفور إلى من يذهب.
تصب التنبيهات في البرقيات أو الركود. خدمة الدعم هي أول من يرد عليها 24/7. ينظر الرجال إلى ما انفجر بالضبط ، إذا كان هذا هو الوضع الطبيعي. لديهم تعليمات:
- تلك التي يتم استبدالها ،
- والتعليمات التي يتم إصلاحها في التقاء مستمر. باسم المراقبة المتفجرة يمكن للمرء أن يجد ما يعنيه. بالنسبة للأكثر أهمية ، يتم وصف ما هو مكسور ، وما هي العواقب ، ومن يحتاج إلى رفع.
لدينا أيضًا نوبات عمل في فرق مسؤولة عن الأنظمة الرئيسية. كل فريق لديه شخص متاح باستمرار. إذا حدث شيء ، يلتقطونه.
عند تشغيل التنبيه ، يحتاج فريق الدعم إلى معرفة جميع المعلومات الأساسية بسرعة. سيكون من الجيد أن يكون لديك رابط لوصف المراقبة مرفق برسالة الخطأ. على سبيل المثال ، بحيث كانت هناك مثل هذه المعلومات:
- وصف هذا الرصد بعبارات واضحة وبسيطة نسبياً ؛
- العنوان الذي يقع فيه ؛
- شرح ما هو المقياس ؛
- العواقب: كيف ستنتهي إذا لم نصحح الخطأ ؛
- , , . , , . -, .
سيكون من الملائم أيضًا رؤية ديناميكيات حركة المرور على الفور في واجهة Prometheus.
أود عمل مثل هذه الأوصاف لكل عملية رصد. سيساعدون في بناء مراجعة وإجراء تعديلات. نحن ننفذ هذه الممارسة: تكوين التهيئة يحتوي بالفعل على رابط للالتقاء مع هذه المعلومات. لقد كنت أعمل على نظام واحد منذ ما يقرب من 4 سنوات ، ولا يوجد أساسًا مثل هذه الأوصاف عليه. حتى الآن أقوم بجمع المعرفة معا. الأوصاف تحل أيضًا مشكلة جهل الفريق.
لدينا تعليمات لمعظم التنبيهات ، حيث تتم كتابة ما يؤدي إلى تأثير معين على العمل. هذا هو السبب في أنه يجب علينا تسوية الوضع بسرعة. يتم تحديد شدة الحوادث المحتملة من خلال خدمة الدعم مع الشركة.
دعني أعطيك مثالاً: إذا نجحت مراقبة استهلاك الذاكرة على خادم RabbitMQ لخدمة معالجة الطلب ، فهذا يعني أن خدمة قائمة الانتظار قد تسقط في غضون بضع ساعات أو حتى دقائق. وهذا بدوره سيوقف العديد من العمليات التجارية. ونتيجة لذلك ، سينتظر العملاء دون جدوى الطلبات وإشعارات الرسائل القصيرة / الدفع وتغييرات الحالة والمزيد.
غالبًا ما تحدث مناقشات المراقبة مع الشركات بعد حوادث خطيرة. إذا انكسر شيء ما ، فإننا نجمع عمولة مع ممثلي الاتجاه الذي تم ربطه من خلال إطلاق سراحنا أو الحادث. في الاجتماع ، نقوم بتحليل أسباب الحادث ، وكيفية التأكد من عدم تكراره أبدًا ، والأضرار التي لحقت بنا ، ومقدار الأموال التي فقدناها وماذا.
يحدث ذلك أنك بحاجة إلى ربط نشاط تجاري لحل المشكلات التي تم إنشاؤها للعملاء. هناك نناقش الإجراءات الاستباقية: أي نوع من المراقبة للبدء حتى لا يحدث هذا مرة أخرى.
تراقب خدمة الدعم قيم المقاييس باستخدام روبوت برقية. عندما تظهر مراقبة جديدة ، يحتاج موظفو الدعم إلى أداة بسيطة تتيح لك معرفة مكان كسرها وما يجب القيام به حيال ذلك. رابط الوصف في التنبيه يحل هذه المشكلة.
أرى fakap كما في الواقع: استخدام Sentry لاستخلاص المعلومات
لا يكفي فقط معرفة الخطأ ، أريد أن أرى التفاصيل. حالة الاستخدام القياسية لدينا هي كما يلي: طرحنا الإصدار وتلقينا تنبيهات من مكدس K8S. بفضل المراقبة ، ننظر إلى حالة الموقد: أي إصدارات التطبيق التي تم طرحها ، وكيف انتهى النشر ، وما إذا كان كل شيء على ما يرام.
ثم ننظر إلى RMM ، التي لدينا مع القاعدة والحمل عليها. بالنسبة إلى Grafana والمجالس ، فإننا ننظر إلى عدد الاتصالات بأرنب. إنه رائع ، لكنه يعرف كيف يتسرب عندما تنفد الذاكرة. نحن نراقب هذه الأشياء ، ثم نتحقق من الحراسة. يسمح لك بمشاهدة عبر الإنترنت كيف يتكشف الفشل التالي مع جميع التفاصيل. في هذه الحالة ، تبلغ مراقبة ما بعد الإفراج عن ما هو مكسور وكيف.
في مشاريع PHP ، نستخدم عميل الغراب ، بالإضافة إلى إثراء البيانات. يجمع الحارس كل شيء بشكل جيد. ونرى ديناميات كل fakap ، كم مرة تحدث. ونلقي نظرة أيضًا على الأمثلة ، التي لم تنجح الطلبات ، والامتدادات التي خرجت.
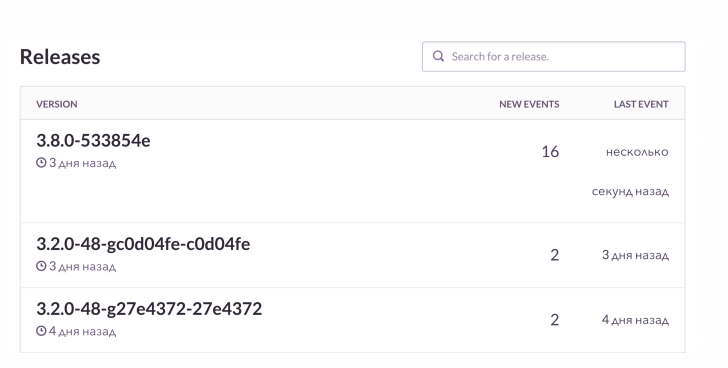
هذا هو تقريبا كيف يبدو. أرى أنه في الإصدار التالي من الأخطاء كانت هناك أكثر من المعتاد بشكل حاد. سوف نتحقق مما كسر على وجه التحديد. وبعد ذلك ، إذا لزم الأمر ، سنحصل على الطلبات الفاشلة في السياق ونصلحها.
لدينا شيء رائع - ملزم لجيرا. هذا تعقب تذاكر: ضغطت على زر ، وأنشأت Jira مهمة خطأ مع ارتباط إلى Sentry وتتبعًا لهذا الخطأ. يتم وضع علامة على المهمة بتسميات محددة.
قدم أحد المطورين مبادرة معقولة - "Clean Project، Clean Sentry". أثناء التخطيط ، في كل مرة نرمي فيها في العدو ما لا يقل عن 1-2 مهمة تم إنشاؤها من Sentry. إذا تم كسر شيء ما في النظام طوال الوقت ، فسيتم غمر Sentry بملايين الحشرات الصغيرة السخيفة. نقوم بتنظيفها بانتظام حتى لا نفوتها عن طريق الخطأ تلك الخطيرة حقًا.
حرائق لأي سبب: نتخلص من المراقبة التي يسدها الجميع
- التعود على البق
إذا كان هناك شيء يومض باستمرار ويبدو أنه مكسور ، فإنه يعطي الشعور بقاعدة خاطئة. يمكن خداع مكتب الخدمة في التفكير في أن الوضع مناسب. وعندما ينهار شيء خطير ، سيتم تجاهله. كما في أسطورة عن صبي يصرخ: "ذئاب ، ذئاب!".
الحالة الكلاسيكية هي مشروعنا ، المسؤول عن معالجة الطلب. يعمل مع نظام أتمتة المستودعات وينقل البيانات هناك. عادة ما يتم إصدار هذا النظام في الساعة 7 صباحًا ، وبعد ذلك نبدأ المراقبة. اعتاد الجميع على ذلك وعشرات ، وهو ليس جيدًا جدًا. سيكون من الحكمة إيقاف هذه الضوابط. على سبيل المثال ، لربط إصدار نظام معين وبعض التنبيهات من خلال Prometheus ، لا تقم بتشغيل الإشارات غير الضرورية.
- لا يعتبر الرصد مقاييس الأعمال
ينقل نظام معالجة الطلبات البيانات إلى المستودع. أضفنا مراقبين لهذا النظام. لم يطلق أي منهم النار ، ويبدو أن كل شيء على ما يرام. يظهر العداد أن البيانات تغادر. هذه الحالة تستخدم الصابون. في الواقع ، قد يبدو العداد مثل هذا: الجزء الأخضر هو التبادلات الواردة ، والجزء الأصفر صادر.
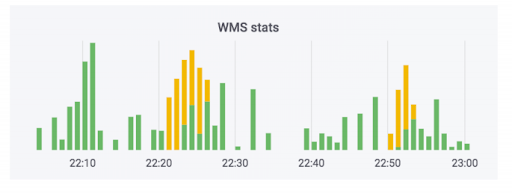
كان لدينا حالة عندما كانت البيانات حقا من فضلك ، ولكن منحنيات. لم يتم دفع الطلبات ، ولكن تم وضع علامة عليها على أنها مدفوعة. أي أنه سيتمكن المشتري من استلامها مجانًا. يبدو أنه أمر مخيف. لكن العكس هو أكثر متعة: يأتي شخص للحصول على أمر مدفوع ، ويطلب منه الدفع مرة أخرى بسبب خطأ في النظام.
لتجنب هذا الموقف ، لا نراقب التكنولوجيا فحسب ، بل أيضًا مقاييس الأعمال. لدينا مراقبة محددة تراقب عدد الطلبات التي تتطلب الدفع عند الاستلام. ستظهر أي قفزات كبيرة في هذا المقياس إذا حدث خطأ ما.
إن مراقبة أداء الأعمال أمر واضح ، ولكن غالبًا ما يتم تجاهلها عند إصدار خدمات جديدة ، بما في ذلك نحن. الجميع يلطخ خدمات جديدة بمقاييس فنية بحتة تتعلق بالأقراص ، النسبة المئوية ، أيا كان. كمتجر عبر الإنترنت ، لدينا شيء مهم - عدد الطلبات التي تم إنشاؤها. نحن نعلم كم من الناس يشترون عادة ، معدلين للترويج للتسويق. لذلك ، مع الإصدارات ، نتبع هذا المؤشر.
شيء آخر مهم: عندما يطلب العميل مرارًا التسليم إلى نفس العنوان ، فإننا لا نعذبه من خلال التواصل مع مركز الاتصال ، ولكننا نؤكد الأمر تلقائيًا. يؤثر تعطل النظام بشكل كبير على تجربة العميل. نتبع هذا المقياس أيضًا ، نظرًا لأن الإصدارات من أنظمة مختلفة يمكن أن تؤثر عليه بشكل كبير.
مراقبة العالم الحقيقي: رعاية الركض الصحي وأدائنا
من أجل أن تتبع الأعمال المؤشرات المختلفة ، قمنا بتصوير نظام لوحة تحكم في الوقت الحقيقي صغير. تم صنعه في الأصل لغرض مختلف. لدى الشركة خطة لعدد الطلبات التي نريد بيعها في يوم معين من الشهر المقبل. يوضح هذا النظام مدى التزام الخطط بما تم القيام به في الواقع. بالنسبة للرسم البياني ، تأخذ بيانات من قاعدة بيانات الإنتاج ، وتقرأ من هناك بسرعة.
بمجرد أن انهارت نسختنا المتماثلة. لم يكن هناك رصد ، لذلك لم يكن لدينا الوقت لمعرفة ذلك. لكن الأعمال رأت أننا لم نكن ننفذ خطة 10 وحدات أوامر تقليدية ، وجاءنا بالتعليقات. بدأنا نفهم الأسباب. اتضح أن البيانات غير ذات الصلة تتم قراءتها من نسخة طبق الأصل مكسورة. هذه هي الحالة التي يلاحظ فيها العمل مؤشرات مثيرة للاهتمام ، ونساعد بعضنا البعض في حالة حدوث مشاكل.
سأخبرك عن مراقبة أخرى للعالم الحقيقي ، والتي كانت قيد التطوير منذ فترة طويلة ويتم ضبطها باستمرار من قبل كل فريق. لدينا عارض Jira - يسمح لك بمراقبة عملية التطوير. النظام بسيط للغاية: إطار عمل Symfony PHP ، الذي يعمل في Jira Api ويلتقط بيانات حول المهام والعدو السريع وما إلى ذلك ، اعتمادًا على ما تم تقديمه للإدخال. يكتب Jira Viewer بانتظام المقاييس المتعلقة بالفرق ومشاريعها إلى Prometeus. هناك يتم مراقبتها وتنبيهها ومن هناك يتم عرضها في Grafana. بفضل هذا النظام ، نتابع العمل الجاري.
- نحن نراقب المدة التي كانت فيها المهمة قيد العمل من لحظة التقدم إلى مرحلة الإنتاج. إذا كان الرقم كبيرًا جدًا ، من الناحية النظرية ، فهذا يشير إلى وجود مشكلة في العمليات والفريق وأوصاف المهام وما إلى ذلك. إن حياة المهمة هي مقياس مهم ، لكنها ليست كافية في حد ذاتها.
- . , , . , .
- – ready for release, . - - , « ».
- : , . .
- . 400 150. , , .
- راقبت في فريقي عدد طلبات السحب من المطورين خارج ساعات العمل. خاصة بعد الساعة 8 مساءً. وعندما يطلق المقياس ، هذه علامة مقلقة: إما أن الشخص ليس لديه وقت لشيء ما ، أو يبذل الكثير من الجهد ويشتعل عاجلاً أم آجلاً.
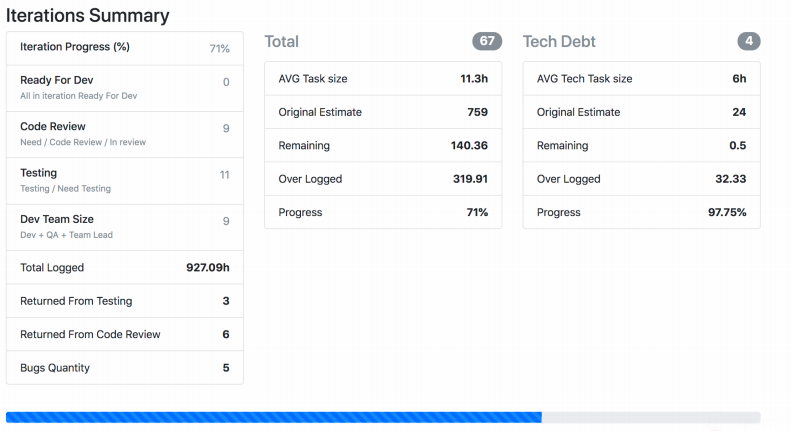
تُظهر لقطة الشاشة كيفية عرض Jira Viewer للبيانات. هذه صفحة حيث توجد معلومات موجزة عن حالة المهام من العدو السريع ، وكم وزن كل منها ، وما شابه. تتجمع هذه الأشياء أيضًا وتطير إلى بروميثيوس.
ليس فقط المقاييس التقنية: ما نراقبه بالفعل ، ما يمكننا مراقبته ولماذا كل هذا مطلوب
لتجميع كل شيء ، أقترح مراقبة كل من التكنولوجيا والمقاييس المتعلقة بالعمليات والتطوير والعمل معًا. المقاييس التقنية وحدها ليست كافية.
- , -, Grafana-. . , , .
- : , . , , crontab supervisor. . , , .
- – , , .
- : , - , . , .
- , . – Sentry . - , . - , . Sentry , , .
- . , , .
- , . , - , - . .