من بين الأطر التي ندرسها لمعالجة البيانات المعقدة في Java هو Apache Flink. نود أن نقدم لك ترجمة لمقال جيد من مدونة Analytics Vidhya على بوابة Medium من أجل تقييم اهتمام القارئ. لا تتردد في التصويت!

في هذه المقالة ، سنلقي نظرة من أسفل إلى أعلى على كيفية التبسيط مع Flink ؛ في الخدمات السحابية والأنظمة الأساسية الأخرى ، يتم توفير حلول البث (بعضها تم دمج Flink تحت الغطاء). إذا كنت ترغب في فهم هذا الموضوع من البداية ، فقد وجدت بالضبط ما كنت تبحث عنه.
لم يستطع حلنا الأحادي التعامل مع الأحجام المتزايدة للبيانات الواردة ؛ لذلك ، يجب تطويره. حان الوقت للانتقال إلى جيل جديد في تطور منتجنا. تقرر استخدام معالجة التدفق. هذا نموذج جديد لامتصاص البيانات متفوق على معالجة الدُفعات التقليدية.
أباتشي فلينك: وصف موجز
Apache Flink هو إطار عمل ترابط موزع قابل للتطوير مصمم للعمليات على التدفقات المستمرة للبيانات. ضمن هذا الإطار ، يتم استخدام مفاهيم مثل المصادر وتحويلات التدفق والمعالجة المتوازية والجدولة وتخصيص الموارد. يتم دعم مجموعة متنوعة من وجهات البيانات. على وجه التحديد ، يمكن لـ Apache Flink الاتصال بـ HDFS و Kafka و Amazon Kinesis و RabbitMQ و Cassandra.
يُعرف Flink بإنتاجيته العالية وزمن وصوله المنخفض ، ومعالجته بشكل صارم ولقطة واحدة (تتم معالجة جميع البيانات مرة واحدة ، بدون تكرار) ، وتوافره العالي مثل أي منتج ناجح مفتوح المصدر ، لدى Flink مجتمع كبير يعمل على تنمية قدرات هذا الإطار وتوسيعه.
يمكن أن يتعامل Flink مع تدفقات البيانات (حجم الدفق غير محدد) أو مجموعات البيانات (حجم مجموعة البيانات محدد). تتناول هذه المقالة بشكل خاص معالجة الخيوط (التعامل مع الكائنات
DataStream
).
البث والمكالمات المتأصلة في
الوقت الحاضر ، مع انتشار أجهزة إنترنت الأشياء وأجهزة الاستشعار الأخرى ، تتدفق البيانات باستمرار من مصادر متعددة. يتطلب هذا التدفق اللامتناهي للبيانات حوسبة دفعية تقليدية للتكيف مع الظروف الجديدة.
- تدفق البيانات غير محدود ؛ ليس لديهم بداية أو نهاية.
- تصل البيانات الجديدة بطريقة غير متوقعة ، على فترات غير منتظمة.
- يمكن أن تصل البيانات بطريقة غير منظمة ، وبطوابع زمنية مختلفة.
مع هذه الخصائص الفريدة ، فإن معالجة البيانات ومهام الاستعلام ليست سهلة الأداء. يمكن أن تتغير النتائج بسرعة ، ويكاد يكون من المستحيل استخلاص استنتاجات محددة ؛ يمكن أن تمنع العمليات الحسابية أحيانًا عند محاولة الحصول على نتائج صحيحة. علاوة على ذلك ، فإن النتائج غير قابلة للتكرار ، حيث تستمر البيانات في التغيير أثناء العمليات الحسابية. أخيرًا ، تعتبر التأخيرات عاملاً آخر يؤثر على دقة النتائج.
يسمح لك Apache Flink بالتعامل مع مشاكل المعالجة هذه ، لأنه يركز على الطوابع الزمنية التي يتم بها إعادة البيانات الواردة إلى المصدر. لدى Flink آلية لتجميع الأحداث بناءً على الطوابع الزمنية الموضوعة عليها - وفقط بعد تجميع النظام يستمر في المعالجة. في هذه الحالة ، يمكن الاستغناء عن استخدام الحزم الصغيرة ، وفي هذه الحالة أيضًا ، يتم زيادة دقة النتائج.
ينفذ Flink معالجة متسقة ولقطة واحدة بدقة ، مما يضمن دقة الحسابات ، ولا يحتاج المطور إلى برمجة أي شيء خاص لهذا الغرض.
ما مصنوعة حزم Flink
عادةً ما يمتص Flink تدفقات البيانات من مصادر مختلفة. الكائن الأساسي عبارة
DataStream<T>
عن دفق من العناصر من نفس النوع. يتم تحديد نوع العنصر في مثل هذا التدفق في وقت الترجمة عن طريق تعيين نوع عام
T
(يمكنك قراءة المزيد عن هذا هنا ). يحتوي
الكائن
DataStream
على العديد من الطرق المفيدة لتحويل البيانات وفصلها وتصفيتها. في البداية سيكون من المفيد أن يكون لديك فكرة عما يفعلونه
map
،
reduce
و
filter
؛ هذه هي طرق التحويل الرئيسية:
Map
: يحصل على كائنT
ونتيجة لذلك يتم إرجاع كائن من النوعR
؛MapFunction
يتم تطبيقه بدقة على كل عنصر من عناصر الكائنDataStream
.
SingleOutputStreamOperator<R> map(MapFunction<T,R> mapper)
Reduce
: الحصول على قيمتين متتاليتين وإرجاع كائن واحد ، ودمجهما في كائن من نفس النوع ؛ تعمل هذه الطريقة عبر جميع القيم في المجموعة حتى تبقى واحدة منها فقط.
T reduce(T value1, T value2)
Filter
: يحصل على كائنT
ويعيد سلسلة من الأشياءT
؛ تتكرر هذه الطريقة في جميع العناصرDataStream
، ولكنها تُرجع فقط العناصر التي ترجع لها الوظيفةtrue
.
SingleOutputStreamOperator<T> filter(FilterFunction<T> filter)
استنزاف البيانات
أحد الأهداف الرئيسية لـ Flink ، إلى جانب تحويل البيانات ، هو التحكم في التدفقات وتوجيهها إلى وجهات معينة. هذه الأماكن تسمى "المصارف". يحتوي Flink على سلاسل مضمنة (نص ، CSV ، مقبس) ، بالإضافة إلى آليات خارج الصندوق للاتصال بأنظمة أخرى ، على سبيل المثال ، Apache Kafka .
العلامات حدث Flink
عند معالجة تدفقات البيانات ، فإن عامل الوقت مهم للغاية. توجد ثلاث طرق لتحديد الطابع الزمني:
- ( ): , ; , . - . , .
, , . , , , ; , .
// Processing Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
- : , , , Flink. , , Flink .
Flink , , , ; « » (watermark). ; Flink.
// Event Time streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);DataStream<String> dataStream = streamEnv.readFile(auditFormat, dataDir, FileProcessingMode.PROCESS_CONTINUOUSLY, 1000). assignTimestampsAndWatermarks( new TimestampExtractor());// ... ... // public class TimestampExtractor implements AssignerWithPeriodicWatermarks<String>{ @Override public Watermark getCurrentWatermark() { return new Watermark(System.currentTimeMillis()-maxTimeFrame); } @Override public long extractTimestamp(String str, long l) { return InputData.getDataObject(str).timestamp; } }
- وقت الامتصاص: هذه هي النقطة الزمنية التي يدخل فيها الحدث إلى Flink ؛ يتم تعيينه عندما يكون الحدث في المصدر ، وبالتالي يعتبر أكثر استقرارًا من وقت المعالجة المعين عند بدء تشغيل العملية.
وقت الامتصاص غير مناسب للتعامل مع الأحداث الخارجة عن الترتيب أو البيانات المتأخرة لأن الطابع الزمني يكون عندما يبدأ الامتصاص ؛ في هذا يختلف عن وقت الحدث ، مما يوفر القدرة على اكتشاف الأحداث المعلقة ومعالجتها ، بالاعتماد على آلية العلامة المائية.
// Ingestion Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
يمكنك قراءة المزيد حول الطوابع الزمنية وكيفية تأثيرها على البث على الرابط التالي .
انهيار النافذة
التيار بحكم التعريف لا نهاية له ؛ لذلك ، ترتبط آلية المعالجة بتعريف الأجزاء (على سبيل المثال ، فترات النوافذ). وبالتالي ، يتم تقسيم الدفق إلى دفعات ملائمة للتجميع والتحليل. تعريف النافذة هو عملية يتم إجراؤها على كائن DataStream أو أي شيء آخر يرث منه.
هناك عدة أنواع من النوافذ التي تعتمد على الوقت:
نافذة الانقلاب (التكوين الافتراضي):
ينقسم التدفق إلى نوافذ ذات حجم مكافئ لا يتداخل مع بعضها البعض. مع تدفق الدفق ، يحسب Flink البيانات باستمرار بناءً على لوحة العمل الثابتة زمنياً. تطبيق

Tumbling window
في الكود:
// ,
public AllWindowedStream<T,TimeWindow> timeWindowAll(Time size)
// ,
public WindowedStream<T,KEY,TimeWindow> timeWindow(Time size)
نافذة منزلقة
يمكن أن تتداخل هذه النوافذ مع بعضها البعض ، ويتم تحديد خصائص النافذة المنزلقة بحجم هذه النافذة والهامش (متى تبدأ النافذة التالية). في هذه الحالة ، يمكن معالجة الأحداث المتعلقة بأكثر من نافذة في وقت معين.

نافذة منزلقة
وهذا هو الشكل الذي تبدو عليه في الكود:
// 1 30
dataStreamObject.timeWindow(Time.minutes(1), Time.seconds(30))
نافذة الجلسة
تشمل جميع الأحداث في جلسة واحدة. تنتهي الجلسة إذا لم يكن هناك نشاط ، أو إذا لم يتم تسجيل أي أحداث بعد فترة زمنية معينة. يمكن أن تكون هذه الفترة ثابتة أو ديناميكية ، اعتمادًا على الأحداث التي تتم معالجتها. من الناحية النظرية ، إذا كانت الفترة الفاصلة بين الجلسات أقل من حجم النافذة ، فقد لا تنتهي الجلسة أبدًا.
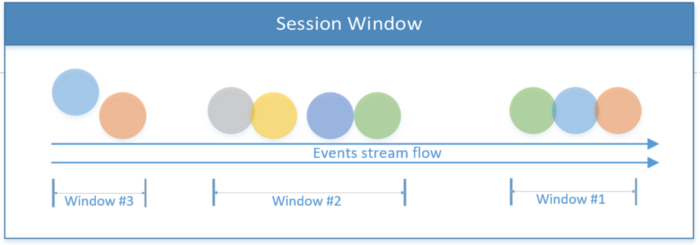
نافذة الجلسة
يعرض مقتطف الشفرة الأول أدناه جلسة ذات قيمة زمنية ثابتة (ثانيتان). يقوم المثال الثاني بتنفيذ نافذة جلسة ديناميكية بناءً على أحداث سلسلة الرسائل.
// 2
dataStreamObject.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)))
// ,
dataStreamObject.window(EventTimeSessionWindows.withDynamicGap((elem) -> {
// ,
}))
النافذة العالمية
يتم التعامل مع النظام بأكمله كنافذة واحدة. تتيح لك

نافذة
Flink العامة أيضًا تنفيذ النوافذ الخاصة بك ، والتي يتم تحديد منطقها من قبل المستخدم.
بالإضافة إلى النوافذ المعتمدة على الوقت ، هناك نوافذ أخرى ، على سبيل المثال ، نافذة الحساب ، حيث يتم تعيين حد عدد الأحداث الواردة ؛ عند الوصول إلى العتبة X ، يعالج Flink أحداث X.

نافذة العد لثلاثة أحداث
بعد مقدمة نظرية ، دعونا نناقش بمزيد من التفصيل ماهية تدفق البيانات من وجهة نظر عملية. لمزيد من المعلومات حول Apache Flink و threading ، راجع الموقع الرسمي .
وصف الدفق
كملخص للجزء النظري ، يعرض مخطط الكتلة التالي تدفقات البيانات الرئيسية المنفذة في مقتطفات التعليمات البرمجية من هذه المقالة. يبدأ الدفق أدناه من المصدر (تتم كتابة الملفات في الدليل) ويستمر أثناء معالجة الأحداث التي تحولت إلى كائنات.
يحتوي التنفيذ الموضح أدناه على مسارين للمعالجة. الذي يظهر في الأعلى يقسم تيارًا واحدًا إلى دفقين جانبيين ، ثم يجمع بينهما ، ليحصل على تيار من النوع الثالث. يصف البرنامج النصي الموضح في الجزء السفلي من الرسم البياني معالجة الدفق ، وبعد ذلك يتم نقل نتائج العمل إلى الحوض.

بعد ذلك ، سنحاول أن نشعر بأيدينا بالتنفيذ العملي للنظرية المذكورة أعلاه ؛ يتم نشر جميع التعليمات البرمجية المصدر الموضحة أدناه على GitHub .
معالجة التدفق الأساسية (المثال رقم 1)
سيكون من الأسهل استيعاب مفاهيم Flink إذا بدأت بأبسط تطبيق. في هذا التطبيق ، يكتب المنتج الملفات إلى دليل ، وبالتالي محاكاة تدفق المعلومات. يقرأ Flink الملفات من هذا الدليل ويكتب معلومات موجزة عنها إلى الدليل الوجهة ؛ هذا هو المخزون.
بعد ذلك ، دعنا نلقي نظرة فاحصة على ما يحدث أثناء المعالجة:
تحويل البيانات الأولية إلى كائن:
// InputData;
DataStream<InputData> inputDataObjectStream
= dataStream
.map((MapFunction<String, InputData>) inputStr -> {
System.out.println("--- Received Record : " + inputStr);
return InputData.getDataObject(inputStr);
});
InputData
يحول مقتطف الشفرة أدناه كائن دفق ( ) إلى سلسلة وعدد صحيح tuple. إنه يستخرج حقولًا معينة فقط من تدفق الكائنات ، ويجمعها في حقل واحد في كم من ثانيتين.
//
DataStream<Tuple2<String, Integer>> userCounts
= inputDataObjectStream
.map(new MapFunction<InputData,Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(InputData item) {
return new Tuple2<String,Integer>(item.getName() ,item.getScore() );
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0) // KeyedStream<T, Tuple> ( 'name')
//.timeWindowAll(Time.seconds(windowInterval)) // timeWindowAll
.timeWindow(Time.seconds(2)) // WindowedStream<T, KEY, TimeWindow>
.reduce((x,y) -> new Tuple2<String,Integer>( x.f0+"-"+y.f0, x.f1+y.f1));
إنشاء وجهة لتيار (تنفيذ مصدر بيانات):
//
DataStream<Tuple2<String,Integer>> inputCountSummary
= inputDataObjectStream
.map( item
-> new Tuple2<String,Integer>
(String.valueOf(System.currentTimeMillis()),1))
// (1)
.returns(Types.TUPLE(Types.STRING ,Types.INT))
.timeWindowAll(Time.seconds(windowInterval)) //
.reduce((x,y) -> // ,
(new Tuple2<String, Integer>(x.f0, x.f1 + y.f1)));
//
final StreamingFileSink<Tuple2<String,Integer>> countSink
= StreamingFileSink
.forRowFormat(new Path(outputDir),
new SimpleStringEncoder<Tuple2<String,Integer>>
("UTF-8"))
.build();
// DataStream; inputCountSummary countSink
inputCountSummary.addSink(countSink);
نموذج التعليمات البرمجية لإنشاء مصدر بيانات.
تقسيم التدفقات (المثال رقم 2)
يوضح هذا المثال كيفية تقسيم الدفق الرئيسي باستخدام تدفقات الإخراج الجانبية. يوفر Flink تيارات جانبية متعددة من الدفق الرئيسي
DataStream
. يمكن أن يختلف نوع البيانات الموجودة على كل جانب من جوانب الدفق عن نوع بيانات الدفق الرئيسي ، بالإضافة إلى نوع البيانات لكل من التدفقات الجانبية.
لذلك ، باستخدام دفق الإخراج الجانبي ، يمكنك قتل عصفورين بحجر واحد: تقسيم الدفق وتحويل نوع بيانات الدفق إلى العديد من أنواع البيانات (يمكن أن تكون فريدة لكل تدفق إخراج جانبي).
يُطلق على مقتطف الشفرة أدناه
ProcessFunction
تقسيم الدفق إلى جانبين ، اعتمادًا على خاصية الإدخال. للحصول على نفس النتيجة ، سيتعين علينا استخدام الوظيفة بشكل متكرر
filter
.
وظيفة
ProcessFunction
يجمع كائنات معينة (بناءً على المعيار) ويرسلها إلى مجمع المنفذ الرئيسي (يقع في
SingleOutputStreamOperator
) ، ويتم نقل بقية الأحداث إلى المخرجات الجانبية.
DataStream
ينقسم الدفق رأسياً وينشر تنسيقات مختلفة لكل دفق جانبي.
لاحظ أن تعريف إخراج التدفق الجانبي يعتمد على علامة إخراج فريدة (كائن
OutputTag
).
//
final OutputTag<Tuple2<String,String>> playerTag
= new OutputTag<Tuple2<String,String>>("player"){};
//
final OutputTag<Tuple2<String,Integer>> singerTag
= new OutputTag<Tuple2<String,Integer>>("singer"){};
// InputData .
SingleOutputStreamOperator<InputData> inputDataMain
= inputStream
.process(new ProcessFunction<String, InputData>() {
@Override
public void processElement(
String inputStr,
Context ctx,
Collector<InputData> collInputData) {
Utils.print(Utils.COLOR_CYAN, "Received record : " + inputStr);
// InputData
InputData inputData = InputData.getDataObject(inputStr);
switch (inputData.getType())
{
case "Singer":
//
ctx.output(singerTag,
new Tuple2<String,Integer>
(inputData.getName(), inputData.getScore()));
break;
case "Player":
// ;
// playerTag, (" ")
ctx.output(playerTag,
new Tuple2<String, String>
(inputData.getName(), inputData.getType()));
break;
default:
// InputData
collInputData.collect(inputData);
break;
}
}
});
نموذج رمز يوضح كيفية تقسيم تيار
الجمع بين التدفقات (المثال رقم 3)
العملية الأخيرة التي سيتم تناولها في هذه المقالة هي سلسلة مؤشرات الترابط. الفكرة هي الجمع بين دفقين مختلفين ، قد تختلف تنسيقات البيانات ، والتي يمكن من خلالها تجميع دفق واحد بهيكل بيانات موحد. على عكس عملية الانضمام من SQL ، حيث يتم دمج البيانات أفقيًا ، يتم دمج التدفقات عموديًا ، حيث يستمر تدفق الأحداث ولا يقتصر على الوقت.
يتم تنفيذ التدفقات المتسلسلة عن طريق استدعاء طريقة الاتصال ، ثم تحديد عملية العرض لكل عنصر في كل دفق فردي. والنتيجة هي دفق مدمج.
//
ConnectedStreams<Tuple2<String, Integer>, Tuple2<String, String>> mergedStream
= singerStream
.connect(playerStream);
DataStream<Tuple4<String, String, String, Integer>> combinedStream
= mergedStream.map(new CoMapFunction<
Tuple2<String, Integer>, // 1
Tuple2<String, String>, // 2
Tuple4<String, String, String, Integer> //
>() {
@Override
public Tuple4<String, String, String, Integer> // 1
map1(Tuple2<String, Integer> singer) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: singer stream", singer.f0, "", singer.f1);
}
@Override
public Tuple4<String, String, String, Integer>
// 2
map2(Tuple2<String, String> player) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: player stream", player.f0, player.f1, 0);
}
});
قائمة توضح كيفية الحصول على دفق مدمج
إنشاء مشروع عمل
لذا ، للتلخيص: تم تحميل المشروع التجريبي على GitHub. يصف كيفية بنائه وتجميعه. هذه نقطة انطلاق جيدة للتدرب عليها مع Flink.
الاستنتاجات
توضح هذه المقالة العمليات الأساسية لإنشاء تطبيق مؤشر ترابط مستند إلى Flink. الغرض من التطبيق هو تقديم نظرة عامة على المكالمات الهامة المتأصلة في التدفق ووضع الأساس للإنشاء اللاحق لتطبيق Flink كامل الوظائف.
نظرًا لأن البث له العديد من الجوانب والعديد من التعقيدات ، فإن العديد من المشكلات في هذه المقالة تظل بدون حل ؛ على وجه الخصوص ، تنفيذ Flink وإدارة المهام ، ووضع علامة مائية عند ضبط وقت تدفق الأحداث ، وحقن الحالة في أحداث الدفق ، وتنفيذ تكرارات الدفق ، وتنفيذ استعلامات تشبه SQL في التدفقات ، وغير ذلك الكثير.
نأمل أن تكون هذه المقالة كافية لتجعلك ترغب في تجربة Flink.