
كيف تبدو البيانات؟
أولاً ، دعنا نلقي نظرة على بيانات الاختبار والتدريب المتاحة (بيانات من تحدي تصنيف التعليقات السامة على منصة kaggle.com). في بيانات التدريب ، على عكس بيانات الاختبار ، توجد تسميات للتصنيف:
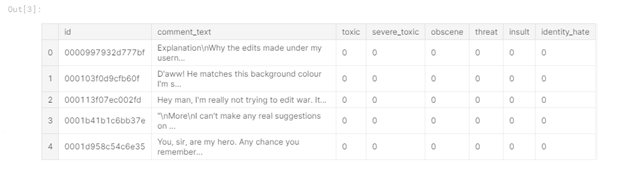
الشكل 1 - رأس بيانات التدريب
من الجدول يمكنك أن ترى أن لدينا 6 أعمدة تسمية في بيانات التدريب ("سامة" ، "شديدة السمية" ، "فاحشة" ، "تهديد" ، "إهانة" ، "هوية_رات") ، حيث تشير القيمة "1" إلى أن التعليق ينتمي إلى الفئة ، يوجد أيضًا عمود "comment_text" يحتوي على التعليق وعمود "معرف" - معرف التعليق.
لا تحتوي بيانات الاختبار على تسميات فئة ، حيث يتم استخدامها لإرسال الحل:

الشكل 2 - اختبار رأس البيانات
ميزة استخراج
الخطوة التالية هي استخراج الميزات من التعليقات وإجراء تحليل البيانات الاستكشافية (EDA). أولاً ، لنلق نظرة على توزيع أنواع التعليقات في مجموعة بيانات التدريب. لهذا ، تم إنشاء عمود جديد "نوع_السموم" ، يحتوي على جميع الفئات التي ينتمي إليها التعليق:

الشكل 3 - أفضل 10 أنواع من التعليقات السامة
يوضح الجدول أن النوع السائد هو عدم وجود أي علامات تصنيف ، والعديد من التعليقات تنتمي إلى أكثر من واحدة صف دراسي.
لنرى أيضًا كيف يتم توزيع عدد الأنواع لكل تعليق:

الشكل 4 - عدد الأنواع التي تمت مواجهتها
لاحظ أن الوضع السائد هو عندما يتميز التعليق بنوع واحد فقط من السمية ؛ أيضًا ، في كثير من الأحيان ، يتميز التعليق بثلاثة أنواع من السمية ، وفي كثير من الأحيان يُنسب التعليق إلى جميع الأنواع.
الآن دعنا ننتقل إلى مرحلة استخراج الميزات من النص ، والتي تسمى غالبًا استخراج الميزات. لقد استخرجت السمات التالية:
طول التعليق. أعتقد أن التعليقات الغاضبة ستكون قصيرة على الأرجح.
الأحرف الكبيرة. في التعليقات العاطفية العدوانية ، من الممكن أن تكون الأحرف الكبيرة أكثر شيوعًا في الكلمات ؛
الرموز الانفعالية. عند كتابة تعليق سام ، من غير المحتمل استخدام الرموز التعبيرية الملونة بشكل إيجابي (:) ، وما إلى ذلك ، فإننا نعتبر أيضًا وجود رموز حزينة (:( ، وما إلى ذلك) ؛
علامات ترقيم. ربما لا يلتزم مؤلفو التعليقات السلبية بقواعد الترقيم ، فهم يستخدمون في الغالب "!" ؛
عدد أحرف الطرف الثالث. غالبًا ما يستخدم بعض الأشخاص الرموز @ و $ وما إلى ذلك عند كتابة كلمات مسيئة.
تمت إضافة الميزات على النحو التالي:
train_data[‘total_length’] = train_data[‘comment_text’].apply(len)
train_data[‘uppercase’] = train_data[‘comment_text’].apply(lambda comment: sum(1 for c in comment if c.isupper()))
train_data[‘exclamation_punction’] = train_data[‘comment_text’].apply(lambda comment: comment.count(‘!’))
train_data[‘num_punctuation’] = train_data[‘comment_text’].apply(lambda comment: comment.count(w) for w in ‘.,;:?’))
train_data[‘num_symbols’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in ‘*&$%’))
train_data[‘num_words’] = train_data[‘comment_text’].apply(lambda comment: len(comment.split()))
train_data[‘num_happy_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-)’, ‘:)’, ‘;)’, ‘;-)’)))
train_data[‘num_sad_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-(’, ‘:(’, ‘;(’, ‘;-(’)))تحليل البيانات استكشافية
الآن دعنا نستكشف البيانات باستخدام الميزات التي حصلنا عليها للتو. بادئ ذي بدء ، دعونا نلقي نظرة على ارتباط الميزات مع بعضها البعض ، والعلاقة بين السمات وتسميات الفئات ، والعلاقة بين تسميات الفئات:

الشكل 5 - الارتباط
الارتباط يشير إلى وجود علاقة خطية بين السمات. كلما كانت قيمة الارتباط في المعامل أقرب إلى 1 ، زاد وضوح الاعتماد الخطي بين العناصر.
على سبيل المثال ، يمكنك أن ترى أن عدد الكلمات وطول النص مرتبطان ارتباطًا وثيقًا ببعضهما البعض (القيمة 0.99) ، مما يعني أنه يمكن إزالة بعض الميزات منها ، قمت بإزالة عدد الكلمات. يمكننا أيضًا استخلاص بعض الاستنتاجات: لا يوجد عمليًا أي ارتباط بين الميزات المحددة وتسميات الفئات ، والميزة الأقل ارتباطًا هي عدد الأحرف ، ويرتبط طول النص بعدد أحرف الترقيم وعدد الأحرف الكبيرة.
بعد ذلك ، سنبني العديد من التصورات لفهم أكثر تفصيلاً لتأثير الميزات على ملصق الفصل. أولاً ، دعنا نرى كيف يتم توزيع أطوال التعليقات:

الشكل 6 - توزيع أطوال التعليقات (الرسم البياني تفاعلي ، ولكن هنا لقطة شاشة)
كما هو متوقع ، التعليقات التي لم يتم تصنيفها (أي عادية) أطول بكثير من التعليقات ذات العلامات. من بين التعليقات السلبية ، أقصرها هي التهديدات ، والأطول سامة.
الآن دعونا نفحص التعليقات من حيث علامات الترقيم. سنقوم ببناء تمثيلات رسومية للقيم المتوسطة لجعل الرسوم البيانية أكثر قابلية للتفسير:

الشكل 7 - متوسط قيم علامات الترقيم (الرسم البياني تفاعلي ، ولكن هنا لقطة شاشة)
من الشكل يمكنك أن ترى أننا حصلنا على ثلاث مجموعات.
الأول هو التعليقات العادية ، وتتميز بالالتزام بقواعد الترقيم (وضع علامات الترقيم ، ":" ، على سبيل المثال) وعدد قليل من علامات التعجب.
والثاني يتكون من التهديدات والتعليقات شديدة السمية (شديدة السمية) ، وتتميز هذه المجموعة بالاستخدام الكثيف لعلامات التعجب وتستخدم علامات الترقيم الأخرى في المستوى المتوسط.
المجموعة الثالثة - سامة (سامة) ، فاحشة (فاحشة) ، إهانات (إهانة) وكراهية تجاه شخص معين (كراهية الهوية) بها عدد قليل من علامات الترقيم وعلامات التعجب.
دعنا نضيف محورًا ثالثًا لمزيد من الوضوح - الحالة الكبيرة:

الشكل 8 - صورة ثلاثية الأبعاد (تفاعلية ، ولكن هذه لقطة شاشة)
هنا نرى موقفًا مشابهًا - تم تمييز ثلاث مجموعات. لاحظ أيضًا أن المسافة بين عناصر المجموعة الثانية أكبر من المسافة بين عناصر المجموعة الثالثة. يمكن ملاحظة ذلك في المؤامرة ثنائية الأبعاد أيضًا:

الشكل 9 - الأحرف الكبيرة وعلامات الترقيم (تفاعلية ، هذه لقطة شاشة)
الآن دعونا نلقي نظرة على أنواع التعليقات في سياق الأحرف الكبيرة / عدد أحرف الطرف الثالث:

الشكل 10 - الأحرف الكبيرة وعدد أحرف الطرف الثالث (تفاعلية ، هذه لقطة شاشة)
كما ترى ، يتم تمييز التعليقات شديدة السامة بوضوح - لديهم عدد كبير من الأحرف الكبيرة والعديد من أحرف الطرف الثالث. أيضًا ، يتم استخدام رموز الجهات الخارجية بنشاط من قبل مؤلفي التعليقات التي تحض على الكراهية لبعض الأشخاص.
وبالتالي ، فإن إبراز الميزات الجديدة وتصورها يسمح بتفسير أفضل للبيانات المتاحة ، ويمكن تلخيص التصورات أعلاه على النحو التالي:
يتم فصل التعليقات شديدة السمية عن البقية ؛
تبرز التعليقات العادية أيضًا ؛
التعليقات السامة والفاحشة والمسيئة قريبة جدًا من بعضها البعض من حيث الخصائص المدروسة.
استخدام DataFrameMapper للجمع بين ميزات النص والرقمية
الآن ، دعنا نلقي نظرة على كيفية استخدام النص والميزات الرقمية معًا في الانحدار اللوجستي.
أولاً ، تحتاج إلى اختيار نموذج لتمثيل النص في شكل مناسب لخوارزميات التعلم الآلي. لقد استخدمت نموذج tf-idf ، حيث يمكنه تمييز كلمات معينة وجعل الكلمات المتكررة أقل أهمية (على سبيل المثال ، حروف الجر):
tvec = TfidfVectorizer(
sublinear_tf=True,
strip_accents=’unicode’,
analyzer=’word’,
token_pattern=r’\w{1,}’,
stop_words=’english’,
ngram_range=(1, 1),
max_features=10000
)لذلك ، إذا أردنا العمل مع إطار البيانات الذي توفره مكتبة Pandas وخوارزميات التعلم الآلي لمكتبة Sklearn ، فيمكننا استخدام وحدة Sklearn-pandas ، والتي تعمل كنوع من الرابط بين أساليب Dataframe و Sklearn.
mapper = DataFrameMapper([
([‘uppercase’], StandardScaler()),
([‘exclamation_punctuation’], StandardScaler()),
([‘num_punctuation’], StandardScaler()),
([‘num_symbols’], StandardScaler()),
([‘num_happy_smilies’], StandardScaler()),
([‘num_sad_smilies’], StandardScaler()),
([‘total_length’], StandardScaler())
], df_out=True)تحتاج أولاً إلى إنشاء DataFrameMapper كما هو موضح أعلاه ، يجب أن يحتوي على أسماء الأعمدة ذات الميزات الرقمية. بعد ذلك ، نقوم بإنشاء مصفوفة من الميزات ، والتي سننقلها بعد ذلك إلى الانحدار اللوجستي للتدريب:
x_train = np.round(mapper.fit_transform(numeric_features_train.copy()), 2).values
x_train_features = sparse.hstack((csr_matrix(x_train), train_texts))يتم أيضًا تنفيذ تسلسل مماثل من الإجراءات على مجموعة بيانات الاختبار.
تجربة حسابية
لتنفيذ التصنيف متعدد العلامات ، سنقوم ببناء حلقة تمر عبر جميع الفئات وتقييم جودة التصنيف من خلال التحقق من الصحة باستخدام المعلمات cv = 3 والتسجيل = 'roc_auc':
scores = []
class_names = [‘toxic’, ‘severe_toxic’, ‘obscene’, ‘threat’, ‘identity_hate’]
for class_name in class_names:
train_target = train_data[class_name]
classifier = LogisticRegression(C=0.1, solver= ‘sag’)
cv_score = np.mean(cross_val_score(classifier, x_train_features, train_target, cv=3, scoring= ‘auc_roc’))
scores.append(cv_score)
print(‘CV score for class {} is {}’.format(class_name, cv_score))
classifier.fit(train_features, train_target)
print(‘Total CV score is {}’.format(np.mean(scores)))</source
<b> :</b>
<img src="https://habrastorage.org/webt/kt/a4/v6/kta4v6sqnr-tar_auhd6bxzo4dw.png" />
<i> 11 — </i>
, , , , , . , , , . - , “toxic”, , , ( 3). , , , .