يمكن أن تكون معالجة بضع غيغابايت من البيانات على جهاز كمبيوتر محمول مهمة شاقة فقط إذا لم يكن يحتوي على الكثير من ذاكرة الوصول العشوائي وقوة معالجة جيدة.
على الرغم من ذلك ، لا يزال يتعين على علماء البيانات إيجاد حلول بديلة لهذه المشكلة. هناك خيارات لإعداد Pandas للتعامل مع مجموعات البيانات الضخمة أو شراء وحدات معالجة الرسومات أو شراء طاقة الحوسبة السحابية. في هذه المقالة ، سننظر في كيفية استخدام Dask لمجموعات البيانات الكبيرة على جهازك المحلي.
داسك وبايثون
Dask هي مكتبة حوسبة متوازية مرنة لبايثون. إنه يعمل بشكل رائع مع مشاريع أخرى مفتوحة المصدر مثل NumPy و Pandas و scikit-Learn. يحتوي Dask على بنية مصفوفة مكافئة لمصفوفات NumPy ، وأطر بيانات Dask تشبه إطارات بيانات Pandas ، و Dask-ML هي scikit-Learn.
تجعل أوجه التشابه هذه من السهل دمج Dask في عملك. ميزة استخدام Dask هي أنه يمكنك توسيع نطاق العمليات الحسابية إلى عدة مراكز على جهاز الكمبيوتر الخاص بك. حتى تحصل على فرصة للعمل مع كميات كبيرة من البيانات التي لا تتناسب مع الذاكرة. يمكنك أيضًا تسريع العمليات الحسابية التي عادةً ما تستهلك مساحة كبيرة.
مصدر
داسك داتافريم
عند تحميل كمية كبيرة من البيانات ، يقرأ Dask عادةً عينة من البيانات للتعرف على أنواع البيانات. غالبًا ما يؤدي هذا إلى حدوث أخطاء ، حيث يمكن أن تكون هناك أنواع بيانات مختلفة في نفس العمود. من المستحسن أن تعلن عن الأنواع مسبقًا لتجنب الأخطاء. يمكن لـ Dask تنزيل ملفات ضخمة عن طريق تقسيمها إلى كتل محددة بواسطة المعلمة
blocksize.
data_types ={'column1': str,'column2': float}
df = dd.read_csv(“data,csv”,dtype = data_types,blocksize=64000000 )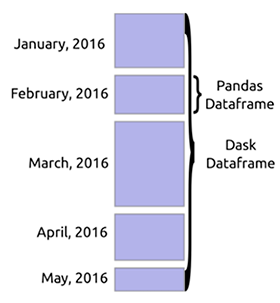
أوامر المصدر في Dask DataFrame مشابهة لأوامر Pandas. على سبيل المثال، والحصول على
headوtail dataframe مماثل:
df.head()
df.tail()الوظائف في DataFrame كسولة. أي ، لا يتم تقييمها حتى يتم استدعاء الوظيفة
compute.
df.isnull().sum().compute()نظرًا لأنه يتم تحميل البيانات في أجزاء ،
sort_values()ستفشل بعض وظائف Pandas مثل . لكن يمكنك استخدام الوظيفةnlargest().
مجموعات في داسك
الحوسبة المتوازية هي مفتاح Dask لأنها تسمح لك بالقراءة على نوى متعددة في نفس الوقت. يوفر Dask
machine schedulerذلك الذي يعمل على جهاز واحد. لا مقياس. هناك أيضًا واحد distributed schedulerيسمح لك بالتوسع في أجهزة متعددة. يتطلب
الاستخدام
dask.distributedتكوين العميل. هذا هو أول شيء تفعله إذا كنت تخطط لاستخدامه dask.distributed في تحليلك. إنه يوفر زمن انتقال منخفضًا ، ومكانًا للبيانات ، والاتصال بين العمال ، كما أنه سهل التكوين.
from dask.distributed import Client
client = Client()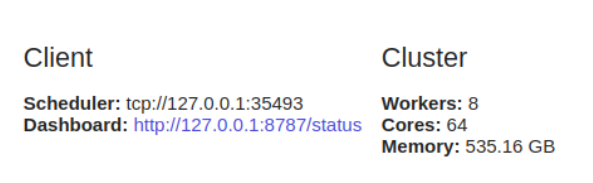
من
dask.distributedالمفيد استخدامه حتى على جهاز واحد لأنه يوفر وظائف تشخيصية عبر لوحة أجهزة القياس.
إذا لم تقم بالتكوين
Client، فستستخدم بشكل افتراضي برنامج جدولة الجهاز لجهاز واحد. سيوفر التزامن على جهاز كمبيوتر واحد باستخدام العمليات والخيوط.
داسك مل
يسمح Dask أيضًا بالتدريب والتنبؤ بالنماذج المتوازية. الهدف
dask-mlهو تقديم تعلم آلي قابل للتطوير. عندما تعلن n_jobs = -1 scikit-learn، يمكنك إجراء الحسابات بالتوازي. يستخدم Dask هذه الميزة لتمكينك من إجراء عمليات حسابية في مجموعة. يمكنك القيام بذلك باستخدام حزمة كتاب العمل ، والتي تتيح التوازي وتسلسل الأنابيب في بايثون. باستخدام Dask ML ، يمكنك استخدام نماذج scikit-Learn ومكتبات أخرى مثل XGboost.
سيبدو التنفيذ البسيط هكذا.
أولاً ، قم بالاستيراد
train_test_splitلتقسيم بياناتك إلى حالات تدريب واختبار.
from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)ثم قم باستيراد النموذج الذي تريد استخدامه وإنشاء مثيل له.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(verbose=1)ثم تحتاج إلى الاستيراد
joblibلتمكين الحوسبة المتوازية.
import joblibثم ابدأ التدريب والتنبؤ بالخلفية الموازية.
from sklearn.externals.joblib import parallel_backend
with parallel_backend(‘dask’):
model.fit(X_train,y_train)
predictions = model.predict(X_test)حدود واستخدام الذاكرة
لا يمكن تشغيل المهام الفردية في Dask بالتوازي. العاملون هم عمليات بايثون ترث مزايا وعيوب حساب بايثون. بالإضافة إلى ذلك ، عند العمل في بيئة موزعة ، يجب توخي الحذر لضمان أمان وخصوصية بياناتك.
يحتوي Dask على برنامج جدولة مركزي يراقب البيانات الموجودة على العقد العاملة وفي المجموعة. كما أنه يدير إصدار البيانات من الكتلة. عند اكتمال المهمة ، ستزيلها على الفور من الذاكرة لإفساح المجال للمهام الأخرى. ولكن إذا احتاج عميل معين إلى شيء ما ، أو كان مهمًا للحسابات الحالية ، فسيتم تخزينه في الذاكرة.
أحد القيود الأخرى على Dask هو أنه لا يقوم بتنفيذ جميع وظائف Pandas. واجهة Pandas كبيرة جدًا ، لذا لا يغطيها Dask تمامًا. وهذا يعني أن إجراء بعض هذه العمليات في Dask قد يكون أمرًا صعبًا. بالإضافة إلى ذلك ، ستكون العمليات البطيئة من Pandas بطيئة أيضًا في Dask.
عندما لا تحتاج إلى Dask DataFrame
في الحالات التالية ، قد لا يكون Dask هو الخيار المناسب لك:
- عندما يكون لدى Pandas الوظائف التي تحتاجها ، لكن Dask لم ينفذها.
- عندما تتناسب بياناتك تمامًا مع ذاكرة الكمبيوتر.
- عندما لا تكون بياناتك في شكل جدول. إذا كان الأمر كذلك ، جرب dask.bag أو disk.array .
افكار اخيرة
في هذه المقالة ، نظرنا في كيفية استخدام Dask للعمل بشكل موزع مع مجموعات البيانات الضخمة على جهاز الكمبيوتر المحلي الخاص بك. رأينا أنه يمكننا استخدام Dask لأن تركيبها مألوف لنا بالفعل. كما يمكن لـ Dask التحجيم لآلاف النوى.
رأينا أيضًا أنه يمكننا استخدامه في التعلم الآلي للتنبؤ والتدريب. إذا كنت تريد معرفة المزيد ، تحقق من هذه المواد في الوثائق .
