يجب أن أشير إلى أنه بعد شهر من التعرف على هذه التقنية ، بدأت في استخدام مضادات الاكتئاب. ما إذا كان NiFi هو المشغل أو القشة الأخيرة غير معروف على وجه اليقين ، وكذلك تورطه في هذه الحقيقة. لكن بما أنني تعهدت بتحديد كل ما ينتظر مبتدئًا محتملاً على هذا الطريق ، يجب أن أكون صريحًا قدر الإمكان.
في الوقت الذي يعتبر فيه Apache NiFi ، من الناحية الفنية ، رابطًا قويًا بين الخدمات المختلفة (حيث يتبادل البيانات بينها ، مما يسمح بإثرائها وتعديلها على طول الطريق) ، أنظر إليه من وجهة نظر أحد المحللين . هذا لأن NiFi هي أداة ETL سهلة الاستخدام. على وجه الخصوص ، كفريق واحد ، نركز على بناء بنية SaaS الخاصة بهم.
أريد الإفصاح عن تجربة أتمتة أحد مهام سير العمل الخاصة بي ، أي تكوين التقارير الأسبوعية وتوزيعها على Jira Software ، في هذه المقالة. بالمناسبة ، سأقوم أيضًا بوصف ونشر منهجية تحليلات تعقب المهام ، والتي تجيب بوضوح على السؤال - ما الذي يفعله الموظفون - سأقوم أيضًا بوصف ونشر في المستقبل القريب.
على الرغم من تكريس هذه المقالة للمبتدئين ، أعتقد أنه من الصحيح والمفيد إذا قام المهندسون المعماريون الأكثر خبرة (المعلمون ، إذا جاز التعبير) بمراجعتها في crommentions أو مشاركة حالات استخدام NiFi في مختلف مجالات النشاط. سيشكركم الكثير من الرجال ، بمن فيهم أنا.
مفهوم Apache NiFi باختصار.
Apache NiFi هو منتج مفتوح المصدر للأتمتة والتحكم في تدفق البيانات بين الأنظمة. من المهم أن تبدأ في تحقيق شيئين على الفور.
الأول هو منطقة الكود المنخفض. الذي أقصده؟ من المفترض أن جميع عمليات التلاعب بالبيانات من لحظة دخولها إلى NiFi حتى الاستخراج يمكن إجراؤها باستخدام الأدوات القياسية (المعالجات). للحالات الخاصة ، يوجد معالج لتشغيل البرامج النصية من bash.
يشير هذا إلى أن القيام بشيء ما في NiFi أمر خاطئ - إنه صعب للغاية (لكنني تمكنت من ذلك! - هذه هي النقطة الثانية). صعب لأن أي معالج سوف يطردك على الفور - إلى أين ترسل الأخطاء؟ ما العمل معهم؟ كم من الوقت تنتظر؟ وهنا أعطيتني مساحة صغيرة! هل قرأت الوثائق بعناية؟ إلخ

الثاني (المفتاح) هو مفهوم البرمجة المتدفقة ، ولا شيء أكثر من ذلك. هنا ، أنا شخصياً ، لم أحصل عليه على الفور (من فضلك ، لا تحكم). لدي خبرة في البرمجة الوظيفية في R ، شكلت وظائف في NiFi دون علمي. في النهاية - إعادة - أخبرني زملائي عندما رأوا محاولاتي غير المجدية لتكوين صداقات "الوظائف".
أعتقد أن النظرية كافية لهذا اليوم ، فلنتعلم كل شيء من الممارسة بشكل أفضل. لنقم بصياغة تشابه في المواصفات الفنية لتحليلات Jira الأسبوعية.
- احصل على سجل العمل وسجل التغييرات من الدهون للأسبوع.
- اعرض الإحصائيات الأساسية لهذه الفترة وأجب عن السؤال: ماذا كان يفعل الفريق؟
- إرسال تقرير إلى الرئيس والزملاء.
من أجل تحقيق المزيد من الفوائد للعالم ، لم أتوقف عند فترة أسبوعية وقمت بتطوير عملية لها القدرة على تنزيل كمية أكبر من البيانات.
دعونا نفهم ذلك.
الخطوات الأولى. إحضار البيانات من API
لا يمتلك Apache NiFi شيئًا مثل مشروع منفصل. لدينا فقط مساحة عمل مشتركة والقدرة على تشكيل مجموعات من العمليات فيها. هذا يكفي تماما.
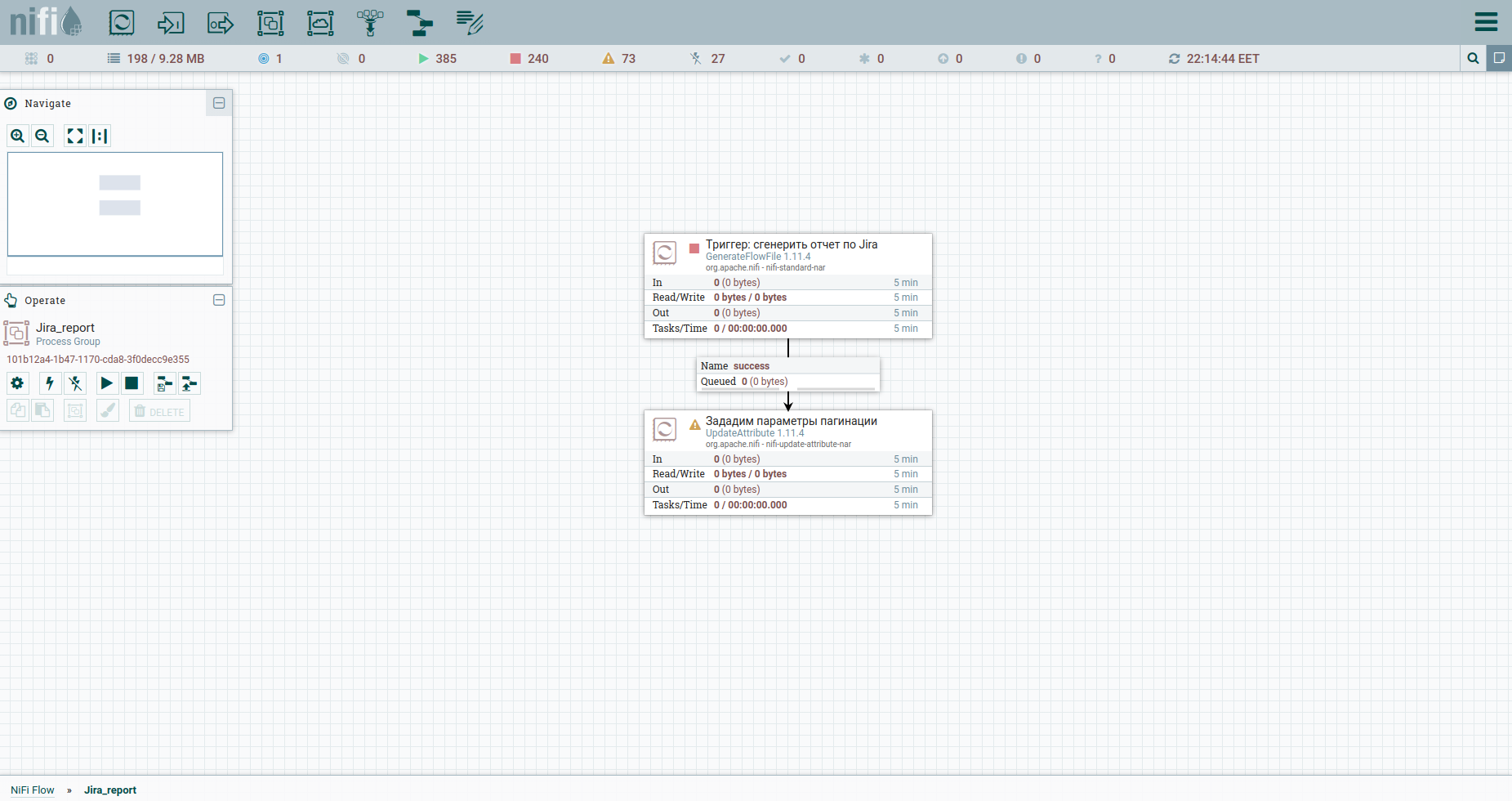
ابحث عن مجموعة العمليات في شريط الأدوات وأنشئ مجموعة Jira_report. انتقل إلى المجموعة وابدأ في بناء سير العمل. تتطلب معظم المعالجات التي يمكن تجميعها منها اتصالًا أوليًا. بكلمات بسيطة ، هذا هو الزناد الذي سيطلق المعالج عليه. لذلك ، من المنطقي أن يبدأ التدفق بأكمله بمشغل عادي - في NiFi ، هذا هو معالج GenerateFlowFile. ماذا يفعل. ينشئ ملف دفق يتكون من مجموعة من السمات والمحتوى. السمات هي أزواج مفتاح / قيمة سلسلة مرتبطة بالمحتوى.
المحتوى عبارة عن ملف عادي ، مجموعة من البايت. تخيل أن المحتوى مرفق بملف FlowFile.
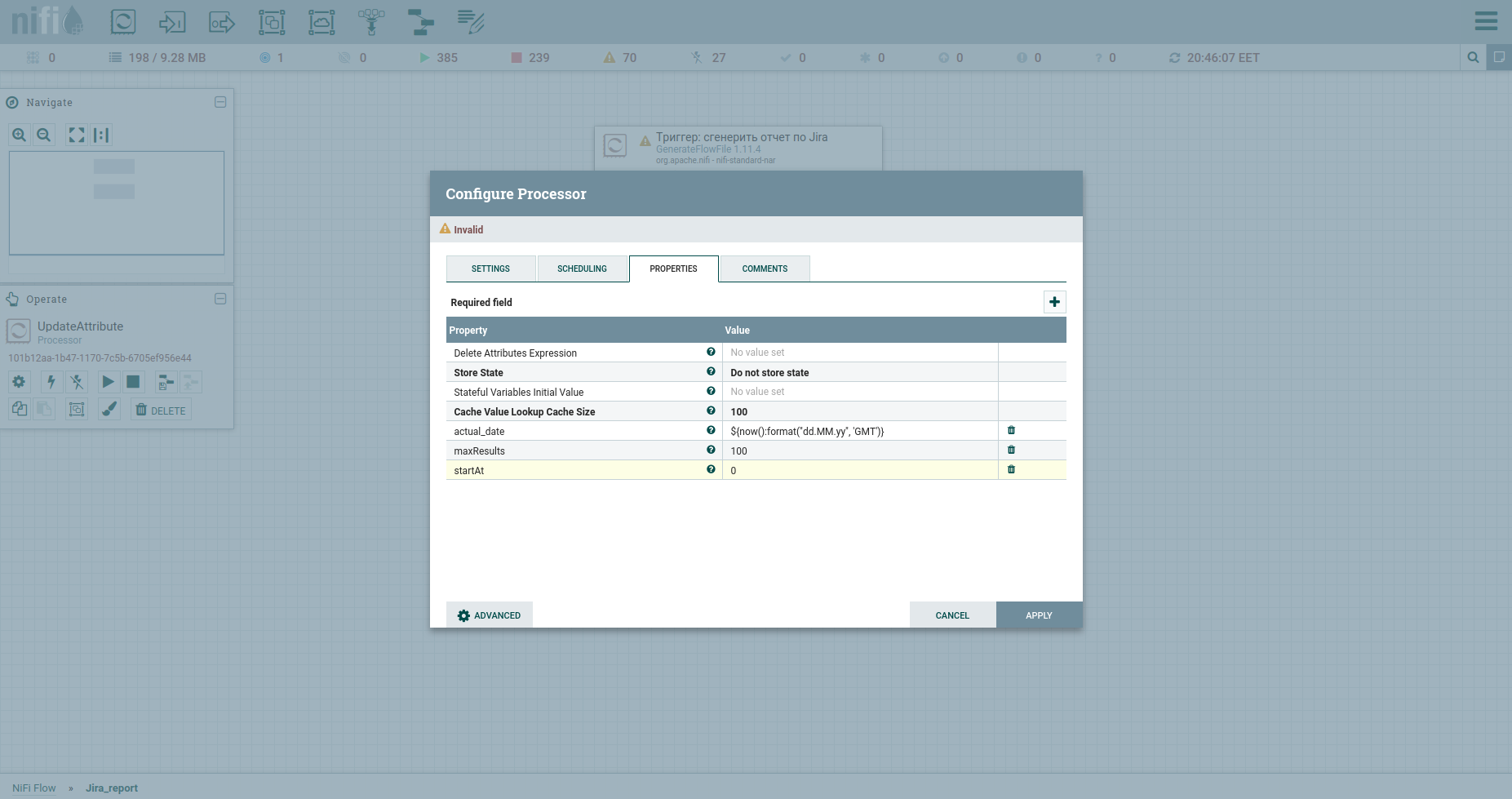
نقوم بإضافة المعالج → GenerateFlowFile. في الإعدادات ، أولاً وقبل كل شيء ، أوصي بشدة بتعيين اسم المعالج (هذه نغمة جيدة) - علامة التبويب الإعدادات. نقطة أخرى: بشكل افتراضي ، يقوم GenerateFlowFile بإنشاء ملفات دفق بشكل مستمر. من غير المحتمل أنك ستحتاج هذا على الإطلاق. نقوم على الفور بزيادة جدول التشغيل ، على سبيل المثال ، حتى 60 ثانية - علامة التبويب "الجدولة". أيضًا ، في علامة التبويب الخصائص ، سنشير إلى تاريخ بدء فترة التقرير - السمة report_from بقيمة بالتنسيق - yyyy / mm / dd. وفقًا لوثائق Jira API ، لدينا حد لمشكلات التفريغ - لا يزيد عن 1000. لذلك ، من أجل الحصول على جميع المهام ، سيتعين علينا تشكيل طلب JQL ، والذي يحدد معلمات ترقيم الصفحات: startAt و maxResults.

دعنا نضعها بسمات باستخدام معالج UpdateAttribute. في الوقت نفسه ، سنربط تاريخ إنشاء التقرير. سنحتاجه لاحقًا. ربما تكون قد لاحظت سمة التاريخ الفعلي. يتم تعيين قيمته باستخدام لغة التعبير. قبض على ورقة الغش الرائعة عليها. هذا كل شيء ، يمكننا تشكيل JQL إلى fat - سنشير إلى معلمات ترقيم الصفحات والحقول المطلوبة. بعد ذلك ، سيكون نص طلب HTTP ، لذلك سنرسله إلى المحتوى. للقيام بذلك ، نستخدم معالج ReplaceText ونحدد قيمة الاستبدال الخاصة به على النحو التالي:
{"startAt": ${startAt}, "maxResults": ${maxResults}, "jql": "updated >= '2020/11/02'", "fields":["summary", "project", "issuetype", "timespent", "priority", "created", "resolutiondate", "status", "customfield_10100", "aggregatetimespent", "timeoriginalestimate", "description", "assignee", "parent", "components"]}لاحظ كيف تتم كتابة روابط السمات.
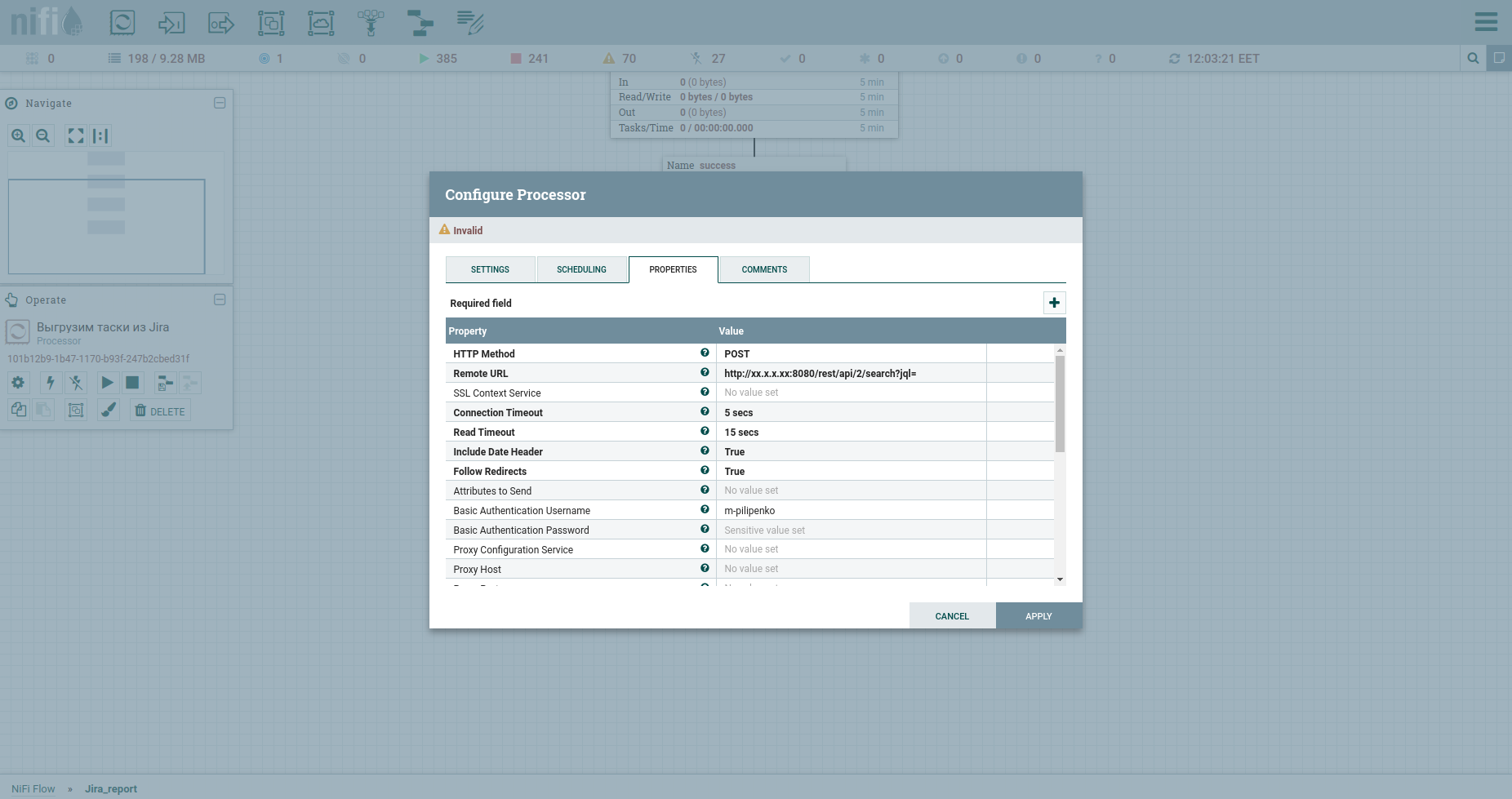
تهانينا ، نحن جاهزون لتقديم طلب HTTP. سيكون معالج InvokeHTTP مناسبًا هنا. بالمناسبة ، يمكنه فعل أي شيء ... أعني الطرق GET ، POST ، PUT ، PATCH ، DELETE ، HEAD ، OPTIONS. دعونا نعدل خصائصه على النحو التالي:
طريقة HTTP لدينا POST.
يتضمن عنوان URL البعيد لشحنتنا IP و port و / rest / api / 2 / search؟ Jql =.
اسم مستخدم المصادقة الأساسية وكلمة مرور المصادقة الأساسية هي بيانات اعتماد للدهون.
قم بتغيير نوع المحتوى إلى application / json b وضعه في نص إرسال الرسالة ، مما يعني إرسال JSON الذي سيأتي من المعالج السابق في نص الطلب.
تطبيق.
سيكون رد apish عبارة عن ملف JSON سيتم تضمينه في المحتوى. نحن نهتم بأمرين فيه: الحقل الإجمالي الذي يحتوي على العدد الإجمالي للمهام في النظام ومجموعة المشكلات التي تحتوي بالفعل على بعض منها. دعنا نحلل الإجابة ونتعرف على معالج EvaluateJsonPath.
إذا كان JsonPath يشير إلى كائن واحد ، فستتم كتابة نتيجة التحليل إلى سمة ملف التدفق. هنا مثال - الحقل الإجمالي والشاشة التالية. في الحالة التي يشير فيها JsonPath إلى مصفوفة من الكائنات ، نتيجة لتحليل ملف التدفق سيتم تقسيمه إلى مجموعة بمحتوى يتوافق مع كل كائن. هنا مثال - مجال القضية. وضعنا EvaluateJsonPath آخر ونكتب: الملكية - الإصدار ، القيمة - $ .issue.

الآن لن يتكون التدفق الخاص بنا من ملف واحد ، ولكن من العديد من الملفات. سيحتوي محتوى كل منها على JSON مع معلومات حول مهمة واحدة محددة.
استمر. تذكر أننا وضعنا maxResults على 100؟ بعد الخطوة السابقة ، سيكون لدينا مائة من tasoks. دعنا نحصل على المزيد وننفذ ترقيم الصفحات.
للقيام بذلك ، دعنا نزيد رقم مهمة البداية بواسطة maxResults. دعنا نستخدم UpdateAttribute مرة أخرى: سنشير إلى سمة startAt ونخصص لها قيمة جديدة $ {startAt: plus ($ {maxResults})}.
حسنًا ، لا يمكننا الاستغناء عن التحقق من الوصول إلى الحد الأقصى لعدد المهام - معالج RouteOnAttribute. الإعدادات كالتالي: And loop. بشكل إجمالي ، ستعمل الدورة طالما أن رقم مهمة البدء أقل من العدد الإجمالي للمهام. عند الخروج منه - تيار من tasoks. هكذا تبدو العملية الآن:
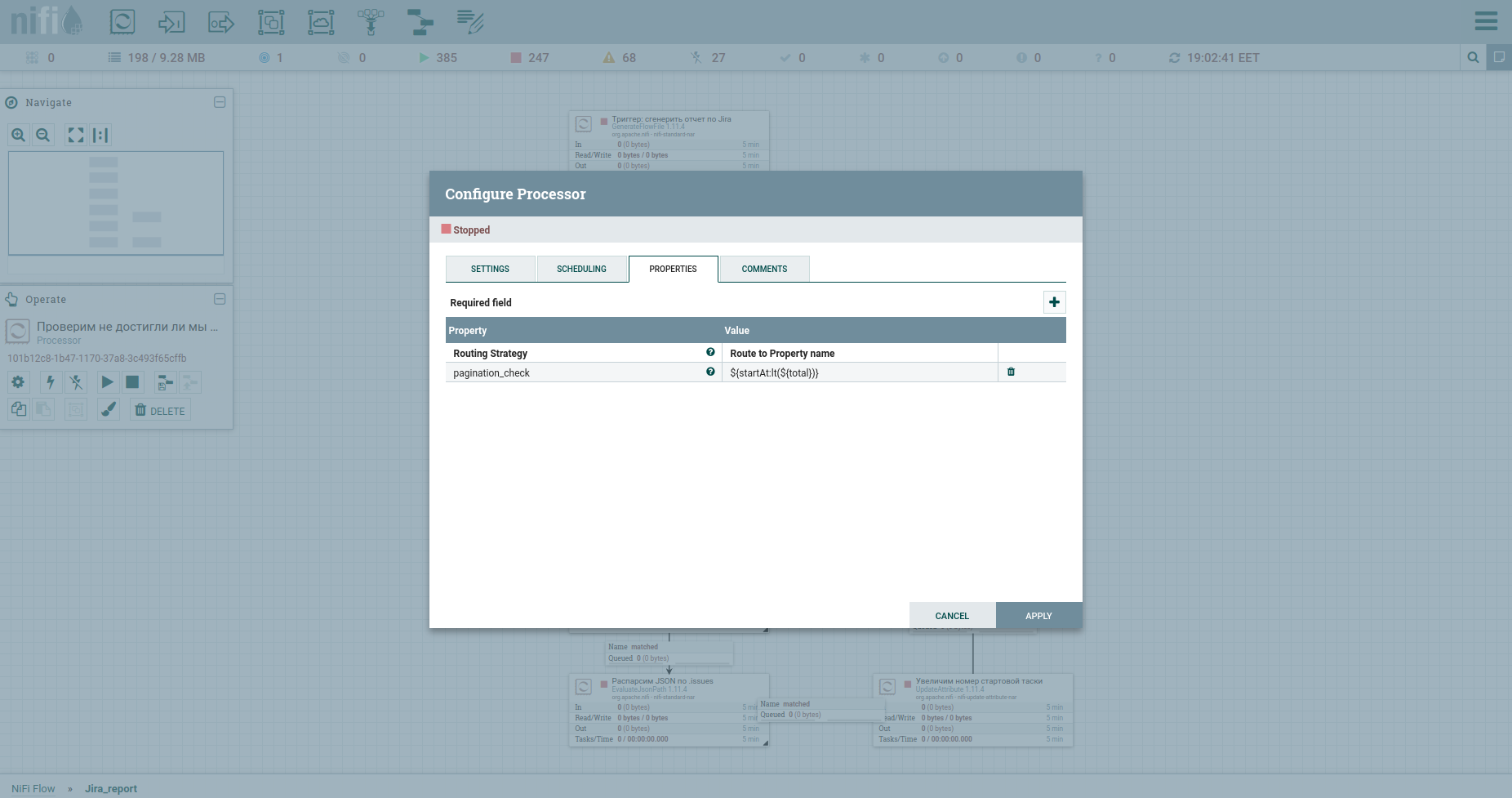

نعم ، أصدقائي ، أعلم - لقد سئمت من قراءة تعليقاتي على كل مربع. تريد أن تفهم المبدأ نفسه. ليس لدي أي شيء ضده.
يجب أن يسهل هذا القسم على المبتدئين المطلقين الدخول إلى NiFi. بعد ذلك ، وبعد أن أحصل على نموذج قدمته بسخاء ، لن يكون من الصعب الخوض في التفاصيل.
بالفرس عبر أوروبا. تحميل سجل عمل ، إلخ.
حسنًا ، دعنا نسرع. كما يقولون ، ابحث عن الاختلافات: لتسهيل الإدراك ، قمت بنقل عملية تفريغ سجل العمل وسجل التغييرات إلى مجموعة منفصلة. ها هو: للتغلب على القيود عند التفريغ التلقائي لسجل عمل من Jira ، يُنصح بالرجوع إلى كل مهمة على حدة. لهذا السبب نحتاج إلى مفاتيحهم. العمود الأول يحول تيار tasoks إلى دفق من المفاتيح. بعد ذلك ، ننتقل إلى الرهبان ونحفظ الإجابة. سيكون مناسبًا لنا ترتيب سجل العمل وسجل التغيير لجميع المهام في شكل مستندات منفصلة. لذلك ، سوف نستخدم معالج MergeContent ونلصق محتويات جميع ملفات التدفق به.
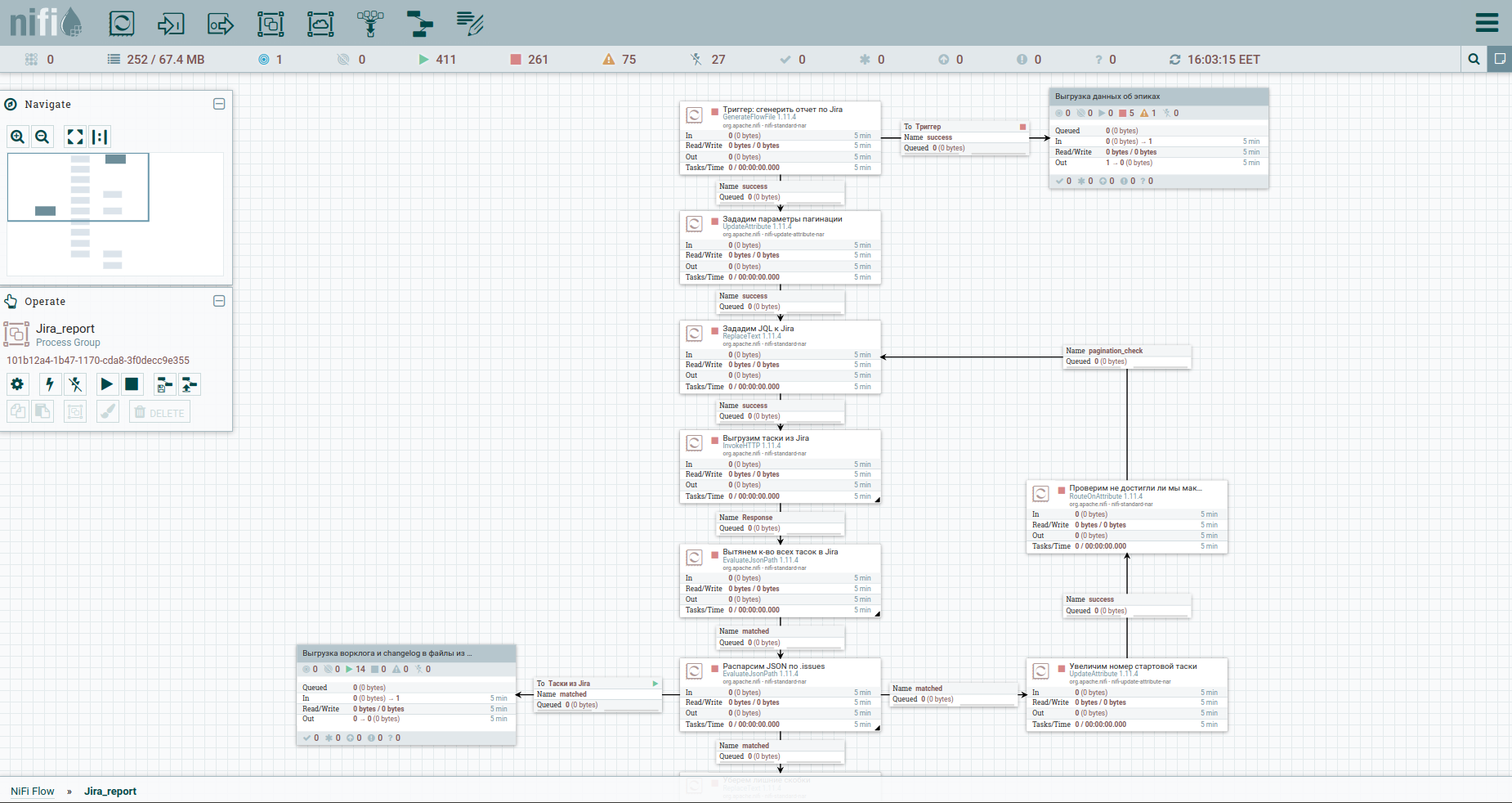
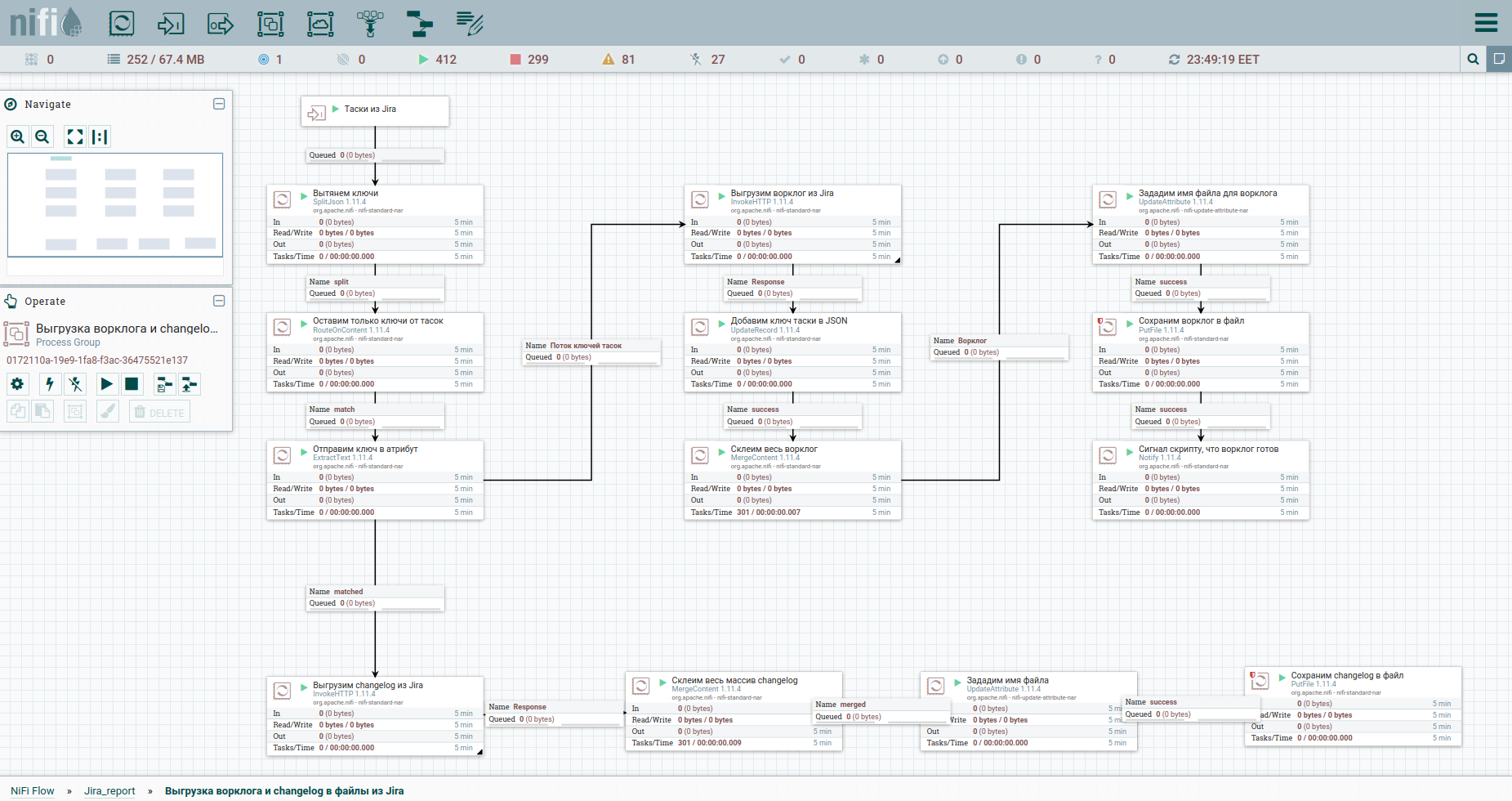
أيضًا في القالب ستلاحظ مجموعة لتفريغ البيانات بواسطة الملاحم. الملحمة في جيرا هي مهمة مشتركة يلتزم بها كثيرون آخرون. ستكون هذه المجموعة مفيدة في الحالة التي يتم فيها تعدين جزء فقط من المهام ، حتى لا تفقد المعلومات حول ملاحم بعضها.
المرحلة النهائية. إنشاء التقرير وإرساله عن طريق البريد الإلكتروني
حسنا. تم تفريغ جميع النقاط وذهبت بطريقتين: إلى المجموعة لتفريغ سجل العمل وإلى البرنامج النصي لإنشاء التقرير. من خلال الأخير ، لدينا STDIN واحد ، لذلك نحتاج إلى جمع كل المهام في كومة واحدة. سنفعل ذلك في MergeContent ، ولكن قبل ذلك سنقوم بتصحيح المحتوى بشكل طفيف بحيث يكون json النهائي صحيحًا. يوجد معالج انتظار مثير للاهتمام أمام مربع إنشاء البرنامج النصي (ExecuteStreamCommand). إنه ينتظر إشارة من معالج Notify ، الموجود في مجموعة تفريغ سجل العمل ، بأن كل شيء جاهز هناك ويمكنك المضي قدمًا. بعد ذلك ، نقوم بتشغيل البرنامج النصي من bash-a - ExecuteStreamCommand. ونرسل التقرير باستخدام PutEmail إلى الفريق بأكمله.

سأخبرك بالتفصيل عن البرنامج النصي ، بالإضافة إلى تجربة تنفيذ تحليلات Jira Software في شركتنا في مقال منفصل ، والذي سيكون جاهزًا في اليوم الآخر.
باختصار ، يقدم التقرير الذي قمنا بتطويره نظرة إستراتيجية لما تقوم به الوحدة أو الفريق. وهذا لا يقدر بثمن بالنسبة لأي رئيس ، يجب أن توافق.
خاتمة
لماذا ترهق نفسك إذا كان بإمكانك فعل كل هذا بنص مرة واحدة ، كما تسأل. نعم ، أوافق ، لكن جزئيًا.
لا يبسط Apache NiFi عملية التطوير ، بل يبسط العملية. يمكننا إيقاف أي موضوع في أي وقت ، وإجراء تعديل والبدء من جديد.
بالإضافة إلى ذلك ، تعطينا NiFi نظرة من أعلى إلى أسفل على العمليات التي تعيشها الشركة. في المجموعة التالية ، سيكون لدي نص آخر. قضية أخرى ستكون محاكمة زميلي. فهمت ، أليس كذلك؟ العمارة في راحة يدك. كما يمزح رئيسنا ، نحن نطبق Apache NiFi حتى نتمكن من طردكم جميعًا لاحقًا ، وكنت الوحيد الذي ضغط على الأزرار. لكن هذه مزحة.
حسنًا ، في هذا المثال ، تعتبر الكعك في شكل مهمة جدول لإنشاء التقارير وإرسال الرسائل ممتعة جدًا أيضًا.
أعترف ، كنت أخطط لإلقاء روحي وإخباركم عن أشعل النار التي خطوت عليها في عملية دراسة التكنولوجيا - كم منهم. ولكن هنا هو بالفعل قراءة طويلة. إذا كان الموضوع مثيرًا للاهتمام ، فيرجى إخبارنا بذلك. في هذه الأثناء أيها الأصدقاء أشكركم وانتظروا في التعليقات.
روابط مفيدة
مقالة بارعة تغطي Apache NiFi مباشرة على أصابعك وبحروف.
دليل قصير باللغة الروسية.
ورقة غش رائعة للغة التعبير.
مجتمع Apache NiFi الناطق باللغة الإنجليزية مفتوح للأسئلة.
مجتمع Apache NiFi الناطق باللغة الروسية على Telegram أكثر حيوية من جميع الكائنات الحية ، تعال.