
هذه ترجمة للمقال الثاني في سلسلة حول الخصوصية التفاضلية.
في الأسبوع الماضي ، في المقالة الأولى في هذه السلسلة - " الخصوصية التفاضلية - تحليل البيانات مع الحفاظ على السرية (مقدمة للسلسلة) " - نظرنا في المفاهيم الأساسية واستخدامات الخصوصية التفاضلية. سننظر اليوم في الخيارات الممكنة لبناء الأنظمة ، اعتمادًا على نموذج التهديد المتوقع.
إن نشر نظام يلبي مبادئ الخصوصية التفاضلية ليس مهمة تافهة. على سبيل المثال ، في مقالتنا التالية سنلقي نظرة على برنامج Python البسيط الذي ينفذ إضافة ضوضاء لابلاس مباشرة في وظيفة تعالج البيانات الحساسة. ولكن لكي يعمل هذا ، نحتاج إلى جمع جميع البيانات المطلوبة على خادم واحد.
ماذا لو تم اختراق الخادم؟ في هذه الحالة ، لن تساعدنا الخصوصية التفاضلية ، لأنها تحمي فقط البيانات التي تم الحصول عليها نتيجة لعمل البرنامج!
عند نشر أنظمة تستند إلى مبادئ الخصوصية التفاضلية ، من المهم مراعاة نموذج التهديد: من أي المعارضين نريد حماية النظام. إذا اشتمل هذا النموذج على مهاجمين قادرين على اختراق خادم ببيانات سرية تمامًا ، فنحن بحاجة إلى تغيير النظام لمقاومة مثل هذه الهجمات.
وهذا هو، أبنية من الأنظمة التي تحترم خصوصية تفاضلية يجب أن تنظر كل من الخصوصية و الأمن . تتحكم الخصوصية فيما يمكن استرجاعه من البيانات التي يعيدها النظام. و الأمن يمكن اعتبار مهمة المعاكس: هو السيطرة على الحصول على جزء من البيانات، ولكنه لا يعطي أي ضمانات بشأن مضمونها.
نموذج الخصوصية التفاضلي المركزي
نموذج التهديد الأكثر استخدامًا في أعمال الخصوصية التفاضلية هو نموذج الخصوصية التفاضلي المركزي (أو ببساطة "الخصوصية التفاضلية المركزية").
المكون الرئيسي - مخزن البيانات الموثوق به (أمين البيانات الموثوق) . يرسل له كل مصدر بياناته السرية ، ويجمعها في مكان واحد (على سبيل المثال ، على الخادم). يكون المستودع موثوقًا به إذا افترضنا أنه يعالج بياناتنا الحساسة من تلقاء نفسه ، ولا ينقلها إلى أي شخص ، ولا يمكن لأي شخص اختراقه. بمعنى آخر ، نعتقد أنه لا يمكن اختراق الخادم الذي يحتوي على بيانات حساسة.
كجزء من النموذج المركزي ، نضيف عادةً ضوضاء إلى الردود على الاستفسارات (سننظر في تطبيق لابلاس في المقالة التالية). ميزة هذا النموذج هي القدرة على إضافة أقل قيمة ممكنة للضوضاء ، وبالتالي الحفاظ على أقصى دقة تسمح بها مبادئ الخصوصية التفاضلية. يوجد أدناه رسم تخطيطي للعملية. لقد وضعنا حاجزًا للخصوصية بين مخزن البيانات الموثوق به والمحلل بحيث لا تظهر إلا النتائج التي تلبي شروط الخصوصية التفاضلية المحددة. وبالتالي ، لا يشترط أن يكون المحلل محل ثقة.
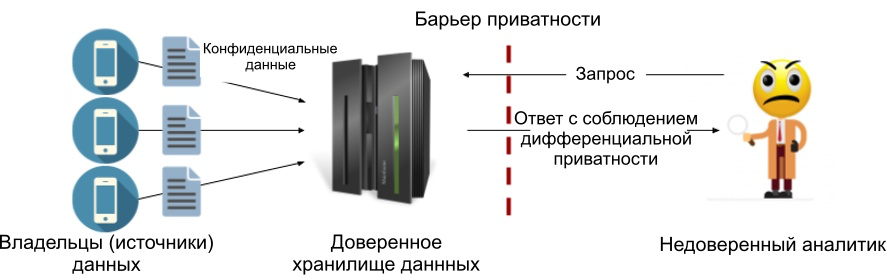
الشكل 1: نموذج الخصوصية التفاضلية المركزي.
عيب النموذج المركزي هو أنه يتطلب متجرًا موثوقًا به ، والكثير منهم ليس كذلك. في الواقع ، عادةً ما يكون عدم الثقة في مستهلك البيانات هو السبب الرئيسي لاستخدام مبادئ الخصوصية التفاضلية.
نموذج الخصوصية التفاضلي المحلي
يتيح لك نموذج الخصوصية التفاضلية المحلي التخلص من مخزن البيانات الموثوق به: يضيف كل مصدر بيانات (أو مالك بيانات) ضوضاء إلى بياناته قبل نقلها إلى المتجر. هذا يعني أن التخزين لن يحتوي أبدًا على معلومات حساسة ، مما يعني أنه ليست هناك حاجة لتوكيل رسمي. يوضح الشكل أدناه جهاز النموذج المحلي: يوجد فيه حاجز الخصوصية بين كل مالك للبيانات والتخزين (الذي قد يكون موثوقًا أو لا يمكن الوثوق به).
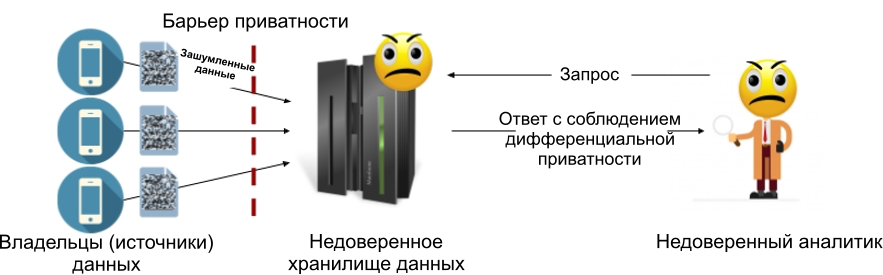
الشكل 2: نموذج الخصوصية التفاضلية المحلي.
يتجنب نموذج الخصوصية التفاضلية المحلي المشكلة الرئيسية للنموذج المركزي: إذا تم اختراق مخزن البيانات ، فلن يتمكن المتسللون من الوصول إلا إلى البيانات المشوشة التي تلبي بالفعل متطلبات الخصوصية التفاضلية. هذا هو السبب الرئيسي لاختيار النموذج المحلي لأنظمة مثل Google RAPPOR [1] ونظام Apple لجمع البيانات [2].
لكن على الصعيد الاخر؟ النموذج المحلي أقل دقة من النموذج المركزي. في النموذج المحلي ، يضيف كل مصدر ضوضاء بشكل مستقل لتلبية شروط الخصوصية التفاضلية الخاصة به ، بحيث يكون إجمالي الضوضاء الصادرة عن جميع المشاركين أكبر بكثير من الضوضاء في النموذج المركزي.
في النهاية ، هذا النهج مبرر فقط لطلبات البحث ذات الاتجاه المستمر (إشارة). تستخدم Apple ، على سبيل المثال ، نموذجًا محليًا لتقدير شعبية الرموز التعبيرية ، ولكن النتيجة مفيدة فقط للرموز التعبيرية الأكثر شيوعًا (حيث يكون الاتجاه أكثر وضوحًا). عادةً ، لا يتم استخدام هذا النموذج للاستعلامات الأكثر تعقيدًا مثل تلك المستخدمة من قبل مكتب الإحصاء الأمريكي [10] أو التعلم الآلي.
النماذج الهجينة
يتمتع النموذجان المركزي والمحلي بمزايا وعيوب ، والآن يتمثل الجهد الرئيسي في الحصول على الأفضل منهما.
على سبيل المثال، يمكنك استخدام هذا النموذج خلط تنفيذها في النظام Prochlo [4]. يحتوي على مخزن بيانات غير موثوق به ، والعديد من مالكي البيانات الفرديين ، والعديد من مزودي البيانات العشوائية الموثوق بهم جزئيًا .... يضيف كل مصدر أولاً قدرًا صغيرًا من الضوضاء إلى بياناته ثم يرسلها إلى المحرض ، مما يضيف المزيد من الضوضاء قبل إرسالها إلى مستودع البيانات. خلاصة القول هي أنه من غير المحتمل أن "يتواطأ المحرضون" (أو يتم اختراقهم في نفس الوقت) مع مخزن البيانات أو مع بعضهم البعض ، لذا فإن القليل من الضوضاء التي تضيفها المصادر ستكون كافية لضمان الخصوصية. يمكن لكل خلاط التعامل مع مصادر متعددة ، تمامًا مثل النموذج المركزي ، لذا فإن كمية صغيرة من الضوضاء ستضمن الخصوصية لمجموعة البيانات الناتجة.
نموذج المحرض هو حل وسط بين النماذج المحلية والمركزية: فهو يضيف ضوضاء أقل من المحلية ، ولكن أكثر من المركزية.
يمكنك أيضًا الجمع بين الخصوصية التفاضلية والتشفير ، كما هو الحال في الحساب الآمن متعدد الأطراف (MPC) أو التشفير المتجانس بالكامل (FHE). يسمح FHE بالحسابات باستخدام البيانات المشفرة دون فك تشفيرها أولاً ، وتسمح MPC لمجموعة من المشاركين بتنفيذ الاستعلامات بأمان عبر المصادر الموزعة دون الكشف عن بياناتهم. حساب الوظائف الخاصة التفاضليةيعد استخدام الحوسبة الآمنة المشفرة (أو الآمنة فقط) طريقة واعدة لتحقيق دقة نموذج مركزية مع جميع الفوائد المحلية. علاوة على ذلك ، في هذه الحالة ، يلغي استخدام الحوسبة الآمنة الحاجة إلى وجود وحدة تخزين موثوقة. يوضح العمل الأخير [5] نتائج مشجعة من مزيج من MPC والخصوصية التفاضلية ، واستيعاب معظم مزايا كلا النهجين. صحيح ، في معظم الحالات ، تكون الحسابات الآمنة عبارة عن عدة أوامر من حيث الحجم أبطأ من تلك التي يتم إجراؤها محليًا ، وهو أمر مهم بشكل خاص لمجموعات البيانات الكبيرة أو الاستعلامات المعقدة. الحوسبة الآمنة حاليًا في مرحلة التطوير النشط ، لذلك يتزايد أدائها بسرعة.
وبالتالي؟
في المقالة التالية ، سنلقي نظرة على أول أداة مفتوحة المصدر لدينا لوضع مفاهيم الخصوصية التفاضلية موضع التنفيذ. دعونا نلقي نظرة على الأدوات الأخرى ، المتاحة للمبتدئين والقابلة للتطبيق على قواعد البيانات الكبيرة جدًا ، مثل تلك الموجودة في مكتب الإحصاء الأمريكي. سنحاول حساب بيانات السكان وفقًا لمبادئ الخصوصية التفاضلية.
اشترك في مدونتنا ولا تفوت ترجمة المقال التالي. قريبا جدا.
المصادر
هامش [1] إيرلينجسون وألفار وفاسيل بيهور وألكساندرا كورولوفا. "Rappor: استجابة ترتيبية عشوائية مجمعة للحفاظ على الخصوصية." في وقائع مؤتمر ACM SIGSAC لعام 2014 حول أمن الكمبيوتر والاتصالات ، ص. 1054-1067. 2014.
[2] Apple Inc. "نظرة عامة فنية حول الخصوصية التفاضلية في Apple." تم الوصول إليه في 31/7/2020. https://www.apple.com/privacy/docs/Differential_Privacy_Overview.pdf
[3] Garfinkel و Simson L. و John M. Abowd و Sarah Powazek. "تمت مواجهة مشكلات في نشر الخصوصية التفاضلية." في وقائع ورشة عمل 2018 حول الخصوصية في المجتمع الإلكتروني ، ص. 133-137. 2018.
[4] بيتاو ، أندريا ، ألفار إيرلينجسون ، بيتروس مانياتيس ، إيليا ميرونوف ، أنانث راغوناثان ، ديفيد لي ، ميتش رودومينير ، أوشاسري كود ، جوليان تينيس ، وبرنارد سيفيلد. "Prochlo: خصوصية قوية للتحليلات في الحشد." في وقائع الندوة السادسة والعشرون حول مبادئ أنظمة التشغيل ، ص. 441-459. 2017.
[5] روي شودري ، أمريتا ، تشينهونج وانج ، شي هي ، أشوين ماتشانافاججهالا ، وسوميش جها. "التشفير: الخصوصية التفاضلية بمساعدة التشفير على الخوادم غير الموثوق بها." في وقائع المؤتمر الدولي لعام 2020 ACM SIGMOD حول إدارة البيانات ، ص. 603-619. 2020.