في هذه المقالة سوف أتطرق إلى موضوع أكثر تعقيدًا وإثارة للاهتمام (على الأقل بالنسبة لي ، مطور فريق البحث): البحث عن نص كامل. سنضيف عقدة Elasticsearch إلى منطقة الحاويات الخاصة بنا ، ونتعلم كيفية إنشاء فهرس ومحتوى بحث ، مع أخذ أوصاف خمسة آلاف فيلم من TMDB 5000 Movie Dataset كبيانات اختبار... سوف نتعلم أيضًا كيفية إنشاء عوامل تصفية البحث والبحث قليلاً نحو الترتيب.
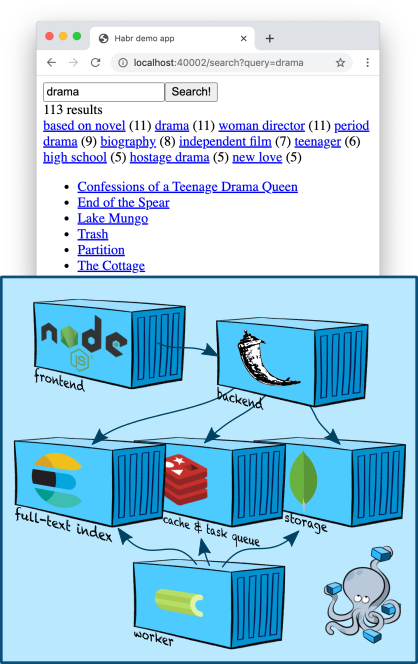
البنية التحتية: Elasticsearch
Elasticsearch هو متجر مستندات شائع يمكنه إنشاء فهارس النص الكامل ، وكقاعدة عامة ، يتم استخدامه على وجه التحديد كمحرك بحث. يضيف Elasticsearch إلى محرك Apache Lucene الذي يعتمد عليه ، والتجزئة ، والنسخ المتماثل ، وواجهة برمجة تطبيقات JSON المريحة ، ومليون تفاصيل أخرى جعلت منه أحد أشهر حلول البحث عن النص الكامل.
دعونا نضيف عقدة Elasticsearch واحدة لعقدتنا
docker-compose.yml:
services:
...
elasticsearch:
image: "elasticsearch:7.5.1"
environment:
- discovery.type=single-node
ports:
- "9200:9200"
...
discovery.type=single-nodeيخبر
متغير البيئة Elasticsearch بالاستعداد للعمل بمفرده ، وليس البحث عن العقد الأخرى والاندماج معها في مجموعة (هذا هو السلوك الافتراضي).
لاحظ أننا ننشر المنفذ 9200 للخارج ، على الرغم من أن تطبيقنا يتنقل داخل الشبكة التي تم إنشاؤها بواسطة docker-compose. هذا مخصص فقط لتصحيح الأخطاء: بهذه الطريقة يمكننا الوصول إلى Elasticsearch مباشرة من المحطة (حتى نتوصل إلى طريقة أكثر ذكاءً - المزيد عن ذلك أدناه).
إضافة عميل Elasticsearch في الأسلاك لدينا ليس بالأمر الصعب - فالخير ، يوفر Elastic عميل Python بسيطًا .
الفهرسة
في المقال الأخير ، وضعنا كياناتنا الرئيسية - "البطاقات" في مجموعة MongoDB. يمكننا استرداد محتوياتها بسرعة من مجموعة عن طريق المعرف ، لأن MongoDB قد أنشأ فهرسًا مباشرًا لنا - يستخدم B-tree لهذا الغرض .
نحن الآن نواجه المهمة العكسية - من خلال المحتوى (أو أجزاءه) للحصول على معرفات البطاقات. لذلك ، نحتاج إلى فهرس عكسي . هذا هو المكان الذي يأتي فيه Elasticsearch في متناول يدي!
عادة ما يبدو المخطط العام لبناء الفهرس هكذا.
- قم بإنشاء فهرس فارغ جديد باسم فريد ، قم بتكوينه حسب الحاجة.
- نتصفح جميع كياناتنا في قاعدة البيانات ونضعها في فهرس جديد.
- نقوم بتبديل الإنتاج بحيث تبدأ جميع الاستعلامات في الانتقال إلى الفهرس الجديد.
- إزالة الفهرس القديم. هنا ، حسب الرغبة - قد ترغب في تخزين الفهارس القليلة الأخيرة ، بحيث يكون ، على سبيل المثال ، أكثر ملاءمة لتصحيح بعض المشاكل.
دعنا ننشئ الهيكل العظمي لمفهرس ثم ندخل في مزيد من التفاصيل مع كل خطوة.
import datetime
from elasticsearch import Elasticsearch, NotFoundError
from backend.storage.card import Card, CardDAO
class Indexer(object):
def __init__(self, elasticsearch_client: Elasticsearch, card_dao: CardDAO, cards_index_alias: str):
self.elasticsearch_client = elasticsearch_client
self.card_dao = card_dao
self.cards_index_alias = cards_index_alias
def build_new_cards_index(self) -> str:
# .
# .
index_name = "cards-" + datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
# .
# .
self.create_empty_cards_index(index_name)
# .
#
# .
for card in self.card_dao.get_all():
self.put_card_into_index(card, index_name)
return index_name
def create_empty_cards_index(self, index_name):
...
def put_card_into_index(self, card: Card, index_name: str):
...
def switch_current_cards_index(self, new_index_name: str):
...
الفهرسة: إنشاء فهرس
يتم إنشاء فهرس في Elasticsearch من خلال طلب PUT بسيط في
/-أو ، في حالة استخدام عميل Python (في حالتنا) ، عن طريق الاتصال
elasticsearch_client.indices.create(index_name, {
...
})
يمكن أن يحتوي نص الطلب على ثلاثة حقول.
- وصف الأسماء المستعارة (
"aliases": ...). يسمح لك نظام الاسم المستعار بالحفاظ على معرفة الفهرس المحدث حاليًا على جانب Elasticsearch ؛ سنتحدث عنها أدناه. - الإعدادات (
"settings": ...). عندما نكون لاعبين كبار مع إنتاج حقيقي ، سنكون قادرين على تكوين النسخ المتماثل والتجزئة ومباهج SRE الأخرى هنا. - مخطط البيانات (
"mappings": ...). هنا يمكننا تحديد نوع الحقول في المستندات التي سنقوم بفهرستها ، ولأي من هذه الحقول نحتاج إلى فهارس معكوسة ، والتجميعات التي يجب دعمها ، وما إلى ذلك.
الآن نحن مهتمون فقط بالمخطط ، ولدينا الأمر بسيط للغاية:
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "english"
},
"text": {
"type": "text",
"analyzer": "english"
},
"tags": {
"type": "keyword",
"fields": {
"text": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
لقد وضعنا علامة على الحقل
name، textوكنص باللغة الإنجليزية. المحلل اللغوي هو كيان في Elasticsearch يعالج النص قبل تخزينه في الفهرس. في حالة englishالمحلل ، سيتم تقسيم النص إلى رموز على طول حدود الكلمات ( التفاصيل ) ، وبعد ذلك سيتم إزالة الرموز الفردية وفقًا لقواعد اللغة الإنجليزية (على سبيل المثال ، treesسيتم تبسيط الكلمة إلى tree) ، theوسيتم حذف lemmas العامة جدًا (نوعًا ) وسيتم وضع lemmas المتبقية في فهرس عكسي.
المجال
tagsأكثر تعقيدًا بعض الشيء. نوعkeywordيفترض أن قيم هذا الحقل هي بعض ثوابت السلسلة التي لا تحتاج إلى معالجتها بواسطة المحلل ؛ سيتم بناء الفهرس المعكوس على أساس قيمهم "الخام" - بدون الترميز واللمماتة. لكن Elasticsearch ستنشئ هياكل بيانات خاصة بحيث يمكن قراءة التجميعات من خلال قيم هذا الحقل (على سبيل المثال ، بحيث يمكنك ، بالتزامن مع البحث ، معرفة العلامات التي تم العثور عليها في المستندات التي ترضي استعلام البحث ، وبأي كمية). هذا أمر رائع بالنسبة للمجالات التي يتم تعدادها بشكل أساسي ؛ سنستخدم هذه الميزة لعمل بعض مرشحات البحث الرائعة.
ولكن حتى يمكن البحث في نص العلامات عن طريق البحث النصي أيضًا ، أضفنا حقلاً فرعيًا إليه
"text"، تم تكوينه عن طريق القياس مع nameوtextأعلاه - في الأساس ، هذا يعني أن Elasticsearch ستنشئ حقلًا "افتراضيًا" آخر تحت الاسم في جميع المستندات التي تأتي إليه tags.text، والتي ستنسخ المحتوى فيه tags، لكنها تفهرسها وفقًا لقواعد مختلفة.
الفهرسة: ملء الفهرس
لفهرسة مستند ، يكفي تقديم طلب PUT
/-/_create/id-أو ، عند استخدام عميل Python ، فقط اتصل بالطريقة المطلوبة. سيبدو تنفيذنا على النحو التالي:
def put_card_into_index(self, card: Card, index_name: str):
self.elasticsearch_client.create(index_name, card.id, {
"name": card.name,
"text": card.markdown,
"tags": card.tags,
})
انتبه للميدان
tags. على الرغم من أننا وصفناها بأنها تحتوي على كلمة رئيسية ، إلا أننا لا نرسل سلسلة واحدة ، بل قائمة من السلاسل. يدعم Elasticsearch هذا ؛ سيتم وضع وثيقتنا في أي من القيم.
الفهرسة: تبديل الفهرس
لتنفيذ بحث ، نحتاج إلى معرفة اسم أحدث فهرس تم إنشاؤه بالكامل. تتيح لنا آلية الاسم المستعار الاحتفاظ بهذه المعلومات في جانب Elasticsearch.
الاسم المستعار هو مؤشر لصفر أو أكثر من الفهارس. تسمح لك Elasticsearch API باستخدام اسم مستعار بدلاً من اسم فهرس عند البحث (POST
/-/_searchبدلاً من POST /-/_search) ؛ في هذه الحالة ، سيقوم Elasticsearch بالبحث في جميع الفهارس التي يشير إليها الاسم المستعار.
سننشئ اسمًا مستعارًا يسمى
cards، والذي سيشير دائمًا إلى الفهرس الحالي. وفقًا لذلك ، سيبدو التحول إلى المؤشر الفعلي بعد الانتهاء من البناء على النحو التالي:
def switch_current_cards_index(self, new_index_name: str):
try:
# , .
remove_actions = [
{
"remove": {
"index": index_name,
"alias": self.cards_index_alias,
}
}
for index_name in self.elasticsearch_client.indices.get_alias(name=self.cards_index_alias)
]
except NotFoundError:
# , - .
# , .
remove_actions = []
#
# .
self.elasticsearch_client.indices.update_aliases({
"actions": remove_actions + [{
"add": {
"index": new_index_name,
"alias": self.cards_index_alias,
}
}]
})
لن أخوض في مزيد من التفاصيل حول الاسم المستعار API ؛ يمكن العثور على جميع التفاصيل في الوثائق .
من الضروري هنا الإدلاء بملاحظة مفادها أنه في خدمة حقيقية محملة للغاية ، يمكن أن يكون مثل هذا التبديل مؤلمًا للغاية وقد يكون من المنطقي إجراء عملية إحماء أولية - تحميل الفهرس الجديد بنوع من مجموعة استفسارات المستخدم المحفوظة.
يمكن العثور على جميع التعليمات البرمجية التي تنفذ الفهرسة في هذا الالتزام .
الفهرسة: إضافة المحتوى
من أجل العرض التوضيحي في هذه المقالة ، أستخدم بيانات من مجموعة بيانات الفيلم TMDB 5000 . لتجنب مشاكل حقوق النشر ، أقدم فقط الكود الخاص بالأداة التي تستوردها من ملف CSV ، والذي أقترح عليك تنزيله بنفسك من موقع Kaggle الإلكتروني. بعد التنزيل ، ما عليك سوى تشغيل الأمر
docker-compose exec -T backend python -m tools.add_movies < ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv
لإنشاء خمسة آلاف بطاقة أفلام وفريق
docker-compose exec backend python -m tools.build_index
لبناء فهرس. يرجى ملاحظة أن الأمر الأخير لا يقوم بالفعل ببناء الفهرس ، ولكنه يضع المهمة فقط في قائمة انتظار المهام ، وبعد ذلك سيتم تنفيذها على العامل - لقد وصفت هذا الأسلوب بمزيد من التفصيل في المقالة الأخيرة .
docker-compose logs workerتظهر لك كيف حاول العامل!
قبل أن نبدأ ، في الواقع ، البحث ، نريد أن نرى بأعيننا ما إذا كان هناك شيء مكتوب في Elasticsearch ، وإذا كان الأمر كذلك ، كيف يبدو!
الطريقة الأكثر مباشرة والأسرع للقيام بذلك هي استخدام Elasticsearch HTTP API. أولاً ، دعنا نتحقق من المكان الذي يشير إليه الاسم المستعار إلى:
$ curl -s localhost:9200/_cat/aliases
cards cards-2020-09-20-16-14-18 - - - -
رائع ، الفهرس موجود! لنلق نظرة عليها عن كثب:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18 | jq
{
"cards-2020-09-20-16-14-18": {
"aliases": {
"cards": {}
},
"mappings": {
...
},
"settings": {
"index": {
"creation_date": "1600618458522",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "iLX7A8WZQuCkRSOd7mjgMg",
"version": {
"created": "7050199"
},
"provided_name": "cards-2020-09-20-16-14-18"
}
}
}
}
أخيرًا ، دعنا نلقي نظرة على محتوياته:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18/_search | jq
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4704,
"relation": "eq"
},
"max_score": 1,
"hits": [
...
]
}
}
في المجموع ، يتكون فهرسنا من 4704 مستندًا ، وفي الحقل
hits(الذي تخطيته لأنه كبير جدًا) ، يمكنك حتى رؤية محتويات بعضها. نجاح!
الطريقة الأكثر ملاءمة لتصفح محتويات الفهرس وعمومًا جميع أنواع التدليل باستخدام Elasticsearch ستكون استخدام Kibana . دعنا نضيف الحاوية إلى
docker-compose.yml:
services:
...
kibana:
image: "kibana:7.5.1"
ports:
- "5601:5601"
depends_on:
- elasticsearch
...
بعد مرة ثانية ،
docker-compose upيمكننا الذهاب إلى Kibana على العنوان localhost:5601(الانتباه ، قد لا يبدأ الخادم بسرعة) وبعد إعداد قصير ، يمكنك عرض محتويات فهارسنا في واجهة ويب لطيفة.
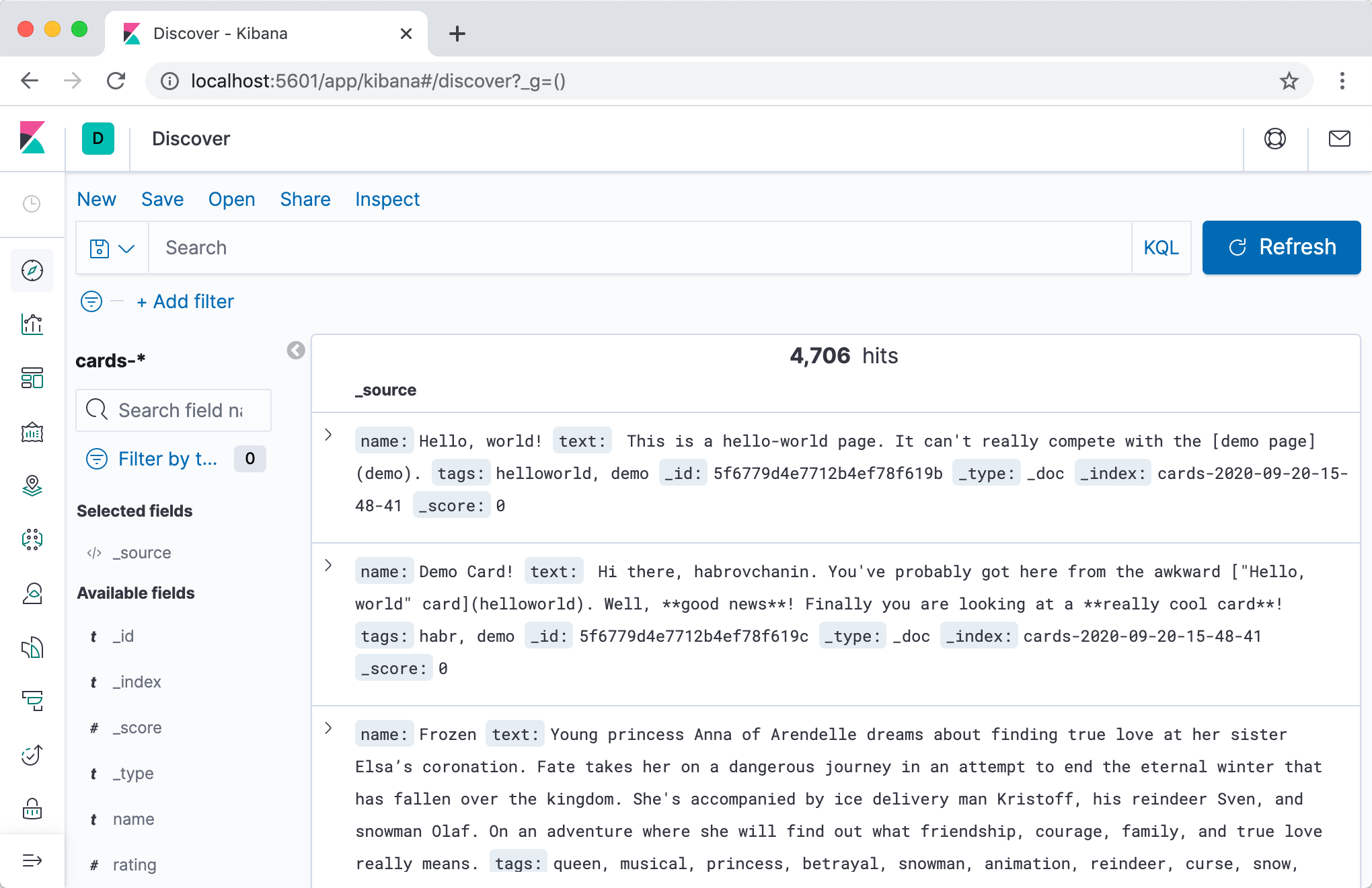
أوصي بشدة بعلامة التبويب Dev Tools - أثناء التطوير ، ستحتاج غالبًا إلى إجراء استفسارات معينة في Elasticsearch ، وهو أكثر ملاءمة في الوضع التفاعلي مع الإكمال التلقائي والتنسيق التلقائي.
بحث
بعد كل الاستعدادات المملة بشكل لا يصدق ، حان الوقت لإضافة وظائف البحث إلى تطبيق الويب الخاص بنا!
دعونا نقسم هذه المهمة غير التافهة إلى ثلاث مراحل ونناقش كل منها على حدة.
- أضف مكونًا
Searcherمسؤولاً عن منطق البحث إلى الواجهة الخلفية . سيشكل استعلامًا إلى Elasticsearch ويحول النتائج إلى أكثر قابلية للفهم لخلفيتنا. - أضف نقطة نهاية إلى واجهة برمجة التطبيقات (مقبض / مسار / ماذا تسميها في شركتك؟) التي
/cards/searchتقوم بالبحث. سيقوم باستدعاء طريقة المكونSearcher، ومعالجة النتائج ، وإعادتها إلى العميل. - دعنا ننفذ واجهة البحث على الواجهة الأمامية. سيتصل
/cards/searchعندما يقرر المستخدم ما يريد البحث عنه ، ويعرض النتائج (وربما بعض عناصر التحكم الإضافية).
بحث: ننفذ
ليس من الصعب كتابة مدير بحث لتصميم واحد. دعنا نصف نتيجة البحث وواجهة المدير ونناقش سبب عدم اختلافها.
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0) -> CardSearchResult:
pass
بعض الأشياء واضحة. على سبيل المثال ، ترقيم الصفحات. نحن شركة ناشئة طموحة وطموحة في مجال
بعضها أقل وضوحًا. على سبيل المثال ، قائمة بالمعرفات ، وليس البطاقات نتيجة لذلك. يقوم Elasticsearch بتخزين مستنداتنا بالكامل افتراضيًا وإرجاعها في نتائج البحث. يمكن إيقاف تشغيل هذا السلوك لتوفير حجم فهرس البحث ، ولكن من الواضح أن هذا تحسين سابق لأوانه بالنسبة لنا. فلماذا لا تعيد البطاقات على الفور؟ الجواب: هذا ينتهك مبدأ المسؤولية الواحدة. ربما في يوم من الأيام سننتهي إلى منطق معقد في مدير البطاقة يقوم بترجمة البطاقات إلى لغات أخرى اعتمادًا على إعدادات المستخدم. بالضبط في هذه اللحظة ، سيتم تفريق البيانات الموجودة على صفحة البطاقة والبيانات الموجودة في نتائج البحث ، لأننا سننسى إضافة نفس المنطق إلى مدير البحث. وهلم جرا وهكذا دواليك.
إن تنفيذ هذه الواجهة بسيط للغاية لدرجة أنني كنت كسولًا جدًا لكتابة هذا القسم :-(
# backend/backend/search/searcher_impl.py
from typing import Any
from elasticsearch import Elasticsearch
from backend.search.searcher import CardSearchResult, Searcher
ElasticsearchQuery = Any #
class ElasticsearchSearcher(Searcher):
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query
})
total_count = result["hits"]["total"]["value"]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
)
def _make_text_query(self, query: str) -> ElasticsearchQuery:
return {
# Multi-match query
# ( match
# query, ).
"multi_match": {
"query": query,
# ^ – .
# , .
"fields": ["name^3", "tags.text", "text"],
}
}
_match_all_query: ElasticsearchQuery = {"match_all": {}}
في الواقع ، ننتقل إلى Elasticsearch API ونستخرج بعناية معرفات البطاقات التي تم العثور عليها من النتيجة.
يعد تطبيق نقطة النهاية أيضًا تافهًا جدًا:
# backend/backend/server.py
...
def search_cards(self):
request = flask.request.json
search_result = self.wiring.searcher.search_cards(**request)
cards = self.wiring.card_dao.get_by_ids(search_result.card_ids)
return flask.jsonify({
"totalCount": search_result.total_count,
"cards": [
{
"id": card.id,
"slug": card.slug,
"name": card.name,
# ,
# ,
# .
} for card in cards
],
"nextCardOffset": search_result.next_card_offset,
})
...
يعد تنفيذ الواجهة الأمامية باستخدام نقطة النهاية هذه ، على الرغم من ضخامتها ، واضحًا بشكل عام ولا أريد التركيز عليها في هذه المقالة. يمكن الاطلاع على الكود بأكمله في هذا الالتزام .

جيد حتى الآن ، دعنا ننتقل.
 بحث: إضافة عوامل تصفية
بحث: إضافة عوامل تصفية
عمليات البحث عن النص رائعة ، ولكن إذا بحثت في أي وقت عن موارد جادة ، فمن المحتمل أنك رأيت كل أنواع الأشياء الجيدة مثل المرشحات.
تحتوي أوصافنا للأفلام من قاعدة بيانات TMDB 5000 على علامات بالإضافة إلى العناوين والأوصاف ، لذلك دعونا نطبق المرشحات حسب العلامات للتدريب. هدفنا هو في لقطة الشاشة: عند النقر فوق علامة ، يجب أن تظل الأفلام التي تحمل هذه العلامة فقط في نتائج البحث (يشار إلى رقمها بين قوسين بجوارها).

لتطبيق المرشحات ، نحتاج إلى حل مشكلتين.
- تعلم أن تفهم عند الطلب أي مجموعة من المرشحات متاحة. لا نريد إظهار جميع قيم التصفية الممكنة على كل شاشة ، لأن هناك الكثير منها وسيؤدي معظمها إلى نتيجة فارغة ؛ تحتاج إلى فهم العلامات التي تحتوي عليها المستندات التي تم العثور عليها عن طريق الاستعلام ، ومن الأفضل ترك N الأكثر شيوعًا.
- لمعرفة ، في الواقع ، لتطبيق عامل تصفية - ترك فقط في نتائج البحث المستندات ذات العلامات ، عامل التصفية الذي اختار المستخدم من خلاله.
الثاني في Elasticsearch يتم تنفيذه ببساطة من خلال API الاستعلام (انظر استعلام المصطلحات ) ، الأول من خلال آلية تجميع أقل تافهة قليلاً .
لذلك ، نحتاج إلى معرفة العلامات الموجودة في البطاقات التي تم العثور عليها ، وأن نكون قادرين على تصفية البطاقات بالعلامات الضرورية. أولاً ، لنقم بتحديث تصميم مدير البحث:
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class TagStats:
tag: str
cards_count: int
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
tag_stats: Iterable[TagStats]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0,
tags: Optional[Iterable[str]] = None) -> CardSearchResult:
pass
الآن دعنا ننتقل إلى التنفيذ. أول شيء يتعين علينا القيام به هو بدء التجميع حسب المجال
tags:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -10,6 +10,8 @@ ElasticsearchQuery = Any
class ElasticsearchSearcher(Searcher):
+ TAGS_AGGREGATION_NAME = "tags_aggregation"
+
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
@@ -18,7 +20,12 @@ class ElasticsearchSearcher(Searcher):
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query,
+ "aggregations": {
+ self.TAGS_AGGREGATION_NAME: {
+ "terms": {"field": "tags"}
+ }
+ }
})
الآن، في نتيجة البحث من Elasticsearch، وحقل يأتي
aggregationsمنه، وذلك باستخدام مفتاح، TAGS_AGGREGATION_NAMEيمكننا الحصول على دلاء تحتوي على معلومات حول ما هي القيم في حقل tagsللالوثائق التي عثر عليها وكيف أنها كثيرا ما تحدث. لنستخرج هذه البيانات ونعيدها بشكل سهل الهضم (كما هو مذكور أعلاه)
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -28,10 +28,15 @@ class ElasticsearchSearcher(Searcher):
total_count = result["hits"]["total"]["value"]
+ tag_stats = [
+ TagStats(tag=bucket["key"], cards_count=bucket["doc_count"])
+ for bucket in result["aggregations"][self.TAGS_AGGREGATION_NAME]["buckets"]
+ ]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
+ tag_stats=tag_stats,
)
تعد إضافة تطبيق مرشح أسهل جزء:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -16,11 +16,17 @@ class ElasticsearchSearcher(Searcher):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
- def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
+ def search_cards(self, query: str = "", count: int = 20, offset: int = 0,
+ tags: Optional[Iterable[str]] = None) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
- "query": self._make_text_query(query) if query else self._match_all_query,
+ "query": {
+ "bool": {
+ "must": self._make_text_queries(query),
+ "filter": self._make_filter_queries(tags),
+ }
+ },
"aggregations": {
الاستعلامات الفرعية المضمنة في شرط must مطلوبة ، ولكن سيتم أخذها أيضًا في الاعتبار عند حساب سرعة المستندات ، وبالتالي الترتيب ؛ إذا أضفنا أي شروط أخرى إلى النصوص ، فمن الأفضل إضافتها هنا. تتم تصفية الاستعلامات الفرعية في عبارة التصفية فقط دون التأثير على السرعة والترتيب.
يبقى تنفيذ
_make_filter_queries():
def _make_filter_queries(self, tags: Optional[Iterable[str]] = None) -> List[ElasticsearchQuery]:
return [] if tags is None else [{
"term": {
"tags": {
"value": tag
}
}
} for tag in tags]
مرة أخرى ، لن أسهب في الحديث عن الجزء الأمامي ؛ كل الكود في هذا الالتزام .
المدى
لذلك ، يبحث بحثنا عن البطاقات ، ويصفيها وفقًا لقائمة معينة من العلامات ويعرضها بترتيب ما. لكن اي واحدة؟ يعد الترتيب مهمًا جدًا لإجراء بحث عملي ، ولكن كل ما فعلناه أثناء التقاضي من حيث الترتيب تم تلميحه إلى Elasticsearch بأنه من المربح العثور على كلمات في عنوان البطاقة أكثر من الوصف أو العلامات من خلال تحديد الأولوية
^3في الاستعلام متعدد المطابقة.
على الرغم من حقيقة أن افتراضيا Elasticsearch صفوف الوثائق مع بدلا صعبة TF-جيش الدفاع الإسرائيلي على أساس صيغة، بالنسبة لشركتنا الطموحة الخيالية ، هذا بالكاد يكفي. إذا كانت مستنداتنا عبارة عن سلع ، فيجب أن نكون قادرين على حساب مبيعاتها ؛ إذا كان محتوى من إنشاء المستخدم ، فكن قادرًا على مراعاة حداثته ، وما إلى ذلك. لكن لا يمكننا ببساطة الفرز حسب عدد المبيعات / تاريخ الإضافة ، لأننا حينئذٍ لن نأخذ في الاعتبار الصلة باستعلام البحث.
التصنيف هو مجال كبير ومربك للتكنولوجيا لا يمكن تغطيته في قسم واحد في نهاية هذه المقالة. لذلك أنا هنا أتحول إلى ضربات كبيرة ؛ سأحاول أن أخبرك بعبارات عامة كيف يمكن ترتيب تصنيف الدرجة الصناعية في البحث ، وسأكشف عن بعض التفاصيل الفنية حول كيفية تنفيذه باستخدام Elasticsearch.
تعتبر مهمة التصنيف معقدة للغاية ، لذا فليس من المستغرب أن تكون إحدى الطرق الحديثة الرئيسية لحلها هي التعلم الآلي. يُطلق على تطبيق تقنيات التعلم الآلي على الترتيب بشكل جماعي " تعلم الترتيب" .
تبدو العملية النموذجية هكذا.
نحن نقرر ما نريد ترتيبه . نضع الكيانات التي تهمنا في الفهرس ، ونتعلم كيفية الحصول على قمة معقولة لاستعلام بحث معين (على سبيل المثال ، بعض الفرز والقطع البسيط) لهذه الكيانات ، والآن نريد أن نتعلم كيفية ترتيبها بطريقة أكثر ذكاءً.
تحديد كيف نريد الترتيب... نحن نقرر ما هي الخاصية التي نريد ترتيب نتائجنا وفقًا لأهداف العمل الخاصة بخدمتنا. على سبيل المثال ، إذا كانت الكيانات التابعة لنا عبارة عن منتجات نبيعها ، فقد نرغب في فرزها بترتيب تنازلي لاحتمالية الشراء ؛ if memes - عن طريق احتمال الإعجاب أو المشاركة ، وما إلى ذلك. نحن ، بالطبع ، لا نعرف كيف نحسب هذه الاحتمالات - في أحسن الأحوال يمكننا أن نقدر ، وحتى ذلك الحين فقط للكيانات القديمة التي لدينا إحصاءات كافية عنها - لكننا سنحاول تعليم النموذج للتنبؤ بها بناءً على علامات غير مباشرة.
استخراج العلامات... لقد توصلنا إلى مجموعة من الميزات لكياناتنا التي يمكن أن تساعدنا في تقييم مدى صلة الكيانات باستعلامات البحث. بالإضافة إلى نفس TF-IDF ، الذي يعرف بالفعل كيفية حساب Elasticsearch بالنسبة لنا ، مثال نموذجي هو CTR (نسبة النقر إلى الظهور): نأخذ سجلات خدمتنا طوال الوقت ، لكل زوج من الكيانات + استعلام بحث نحسب عدد مرات ظهور الكيان في نتائج البحث بالنسبة لهذا الطلب وعدد مرات النقر فوقه ، نقسم أحدهما على الآخر ، وآخرون - فأبسط تقدير لاحتمال النقرة الشرطي جاهز. يمكننا أيضًا التوصل إلى سمات خاصة بالمستخدم وسمات مقترنة بكيان المستخدم لتخصيص التصنيفات. بعد التوصل إلى العلامات ، نكتب رمزًا يحسبها ويضعها في نوع من التخزين ونعرف كيفية منحها في الوقت الفعلي لاستعلام بحث ومستخدم ومجموعة من الكيانات.
تجميع مجموعة بيانات التدريب . هناك العديد من الخيارات ، ولكن جميعها ، كقاعدة عامة ، تتكون من سجلات "جيد" (على سبيل المثال ، نقرة ثم شراء) و "سيئ" (على سبيل المثال ، نقرة والعودة إلى الإصدار) في خدمتنا. عندما نقوم بتجميع مجموعة بيانات ، سواء كانت قائمة من العبارات "تقييم مدى ملاءمة المنتج X للاستعلام Q يساوي تقريبًا P" ، أو قائمة الأزواج "المنتج X أكثر صلة بالمنتج Y للاستعلام Q" أو مجموعة من القوائم "للاستعلام Q ، والمنتجات P 1 ، P 2 ، ... مرتبة بشكل صحيح مثل هذا -أن "نقوم بتشديد العلامات المقابلة لجميع الخطوط الظاهرة فيه.
نقوم بتدريب النموذج . فيما يلي جميع كلاسيكيات ML: القطار / الاختبار ، والمعلمات الفائقة ، وإعادة التدريب ،
نقوم بتضمين النموذج . يبقى لنا أن نلغي بطريقة أو بأخرى حساب النموذج سريعًا للأعلى بالكامل حتى تصل النتائج المصنفة بالفعل إلى المستخدم. هناك العديد من الخيارات. لأغراض توضيحية ، سأركز (مرة أخرى) على مكون إضافي بسيط Elasticsearch Learning to Rank .
الترتيب: تعلم Elasticsearch لترتيب البرنامج المساعد
Elasticsearch Learning to Rank هو مكون إضافي يضيف إلى Elasticsearch القدرة على حساب نموذج ML في SERP وترتيب النتائج فورًا وفقًا للمعدلات المحسوبة. سيساعدنا أيضًا في الحصول على ميزات مماثلة لتلك المستخدمة في الوقت الفعلي ، أثناء إعادة استخدام قدرات Elasticsearch (TF-IDF وما شابه).
أولاً ، نحتاج إلى توصيل المكون الإضافي في حاويتنا بـ Elasticsearch. نحتاج إلى ملف Dockerfile بسيط
# elasticsearch/Dockerfile
FROM elasticsearch:7.5.1
RUN ./bin/elasticsearch-plugin install --batch http://es-learn-to-rank.labs.o19s.com/ltr-1.1.2-es7.5.1.zip
والتغييرات ذات الصلة على
docker-compose.yml:
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -5,7 +5,8 @@ services:
elasticsearch:
- image: "elasticsearch:7.5.1"
+ build:
+ context: elasticsearch
environment:
- discovery.type=single-node
نحتاج أيضًا إلى دعم البرنامج المساعد في عميل Python. بدهشة وجدت أن دعم Python لا يكتمل مع المكون الإضافي ، لذلك خاصة بالنسبة لهذه المقالة لقد تم غسلها . إضافة
elasticsearch_ltrإلى requirements.txtوترقية العميل في الأسلاك:
--- a/backend/backend/wiring.py
+++ b/backend/backend/wiring.py
@@ -1,5 +1,6 @@
import os
+from elasticsearch_ltr import LTRClient
from celery import Celery
from elasticsearch import Elasticsearch
from pymongo import MongoClient
@@ -39,5 +40,6 @@ class Wiring(object):
self.task_manager = TaskManager(self.celery_app)
self.elasticsearch_client = Elasticsearch(hosts=self.settings.ELASTICSEARCH_HOSTS)
+ LTRClient.infect_client(self.elasticsearch_client)
self.indexer = Indexer(self.elasticsearch_client, self.card_dao, self.settings.CARDS_INDEX_ALIAS)
self.searcher: Searcher = ElasticsearchSearcher(self.elasticsearch_client, self.settings.CARDS_INDEX_ALIAS)
الترتيب: علامات النشر
لا يُرجع كل طلب في Elasticsearch قائمة بمعرفات المستندات التي تم العثور عليها فحسب ، بل يُرجع أيضًا بعضًا منها قريبًا (كيف يمكنك ترجمة نقاط الكلمات إلى اللغة الروسية؟). لذلك ، إذا كان هذا استعلامًا مطابقًا أو متعدد المطابقات نستخدمه ، فإن السرعة هي نتيجة حساب تلك الصيغة الصعبة للغاية التي تتضمن TF-IDF ؛ إذا كان الاستعلام المنطقي عبارة عن مجموعة من معدلات الاستعلام المتداخلة ؛ إذا كان الاستعلام عن نتيجة الوظيفة- نتيجة حساب دالة معينة (على سبيل المثال ، قيمة بعض الحقول الرقمية في مستند) ، وما إلى ذلك. يوفر لنا المكون الإضافي ELTR القدرة على استخدام سرعة أي استعلام كعلامة ، مما يسمح لنا بسهولة دمج البيانات حول مدى مطابقة المستند للطلب (عبر استعلام متعدد المطابقة) وبعض الإحصائيات المحسوبة مسبقًا التي نضعها في المستند مسبقًا (عبر استعلام درجة الوظيفة) ...
نظرًا لأن لدينا قاعدة بيانات TMDB 5000 في أيدينا ، والتي تحتوي على أوصاف للأفلام ، ومن بين أشياء أخرى ، تصنيفاتها ، فلنأخذ التصنيف كميزة نموذجية محسوبة مسبقًا.
في هذا الالتزامأضفت بعض البنية التحتية الأساسية لتخزين الميزات إلى الواجهة الخلفية لتطبيق الويب الخاص بنا ودعمت تحميل التصنيف من ملف الفيلم. لكي لا يجبرك على قراءة مجموعة أخرى من التعليمات البرمجية ، سوف أصف أبسطها.
- سنخزن الميزات في مجموعة منفصلة ونحصل عليها من قبل مدير منفصل. يعتبر إلقاء جميع البيانات في كيان واحد ممارسة سيئة.
- سوف نتصل بهذا المدير في مرحلة الفهرسة ونضع جميع العلامات المتاحة في المستندات المفهرسة.
- لمعرفة مخطط الفهرس ، نحتاج إلى معرفة قائمة جميع الميزات الموجودة قبل البدء في إنشاء الفهرس. سنقوم بترميز هذه القائمة بشكل ثابت في الوقت الحالي.
- نظرًا لأننا لن نقوم بتصفية المستندات حسب قيم السمات ، ولكننا سنستخرجها فقط من المستندات التي تم العثور عليها بالفعل لحساب النموذج ، سنقوم بإيقاف إنشاء الفهارس المعكوسة بواسطة حقول جديدة مع وجود خيار
index: falseفي المخطط وتوفير مساحة صغيرة بسبب ذلك.
الترتيب: جمع مجموعة البيانات
نظرًا لأنه ، أولاً ، ليس لدينا إنتاج ، وثانيًا ، هوامش هذه المقالة صغيرة جدًا للحديث عن القياس عن بعد ، و Kafka ، و NiFi ، و Hadoop ، و Spark ، وعمليات بناء ETL ، سأقوم فقط بإنشاء مشاهدات ونقرات عشوائية لبطاقاتنا و نوع من استعلامات البحث. بعد ذلك ، ستحتاج إلى حساب خصائص أزواج طلب البطاقة الناتجة.
حان الوقت للتعمق أكثر في واجهة برمجة تطبيقات البرنامج المساعد ELTR. لحساب الميزات ، سنحتاج إلى إنشاء كيان مخزن ميزات (بقدر ما أفهم ، هذا في الواقع مجرد فهرس في Elasticsearch حيث يخزن المكون الإضافي جميع بياناته) ، ثم إنشاء مجموعة ميزات - قائمة بالميزات مع وصف لكيفية حساب كل منها. بعد ذلك ، يكفي أن نذهب إلى Elasticsearch مع طلب خاص للحصول على متجه لقيم الميزات لكل كيان تم العثور عليه نتيجة لذلك.
لنبدأ بإنشاء مجموعة ميزات:
# backend/backend/search/ranking.py
from typing import Iterable, List, Mapping
from elasticsearch import Elasticsearch
from elasticsearch_ltr import LTRClient
from backend.search.features import CardFeaturesManager
class SearchRankingManager:
DEFAULT_FEATURE_SET_NAME = "card_features"
def __init__(self, elasticsearch_client: Elasticsearch,
card_features_manager: CardFeaturesManager,
cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.card_features_manager = card_features_manager
self.cards_index_name = cards_index_name
def initialize_ranking(self, feature_set_name=DEFAULT_FEATURE_SET_NAME):
ltr: LTRClient = self.elasticsearch_client.ltr
try:
# feature store ,
# ¯\_(ツ)_/¯
ltr.create_feature_store()
except Exception as exc:
if "resource_already_exists_exception" not in str(exc):
raise
# feature set !
ltr.create_feature_set(feature_set_name, {
"featureset": {
"features": [
#
# ,
# ,
# .
self._make_feature("name_tf_idf", ["query"], {
"match": {
# ELTR
# , .
# , ,
# ,
# match query.
"name": "{{query}}"
}
}),
# , .
self._make_feature("combined_tf_idf", ["query"], {
"multi_match": {
"query": "{{query}}",
"fields": ["name^3", "tags.text", "text"]
}
}),
*(
#
# function score.
# -
# , 0.
# (
# !)
self._make_feature(feature_name, [], {
"function_score": {
"field_value_factor": {
"field": feature_name,
"missing": 0
}
}
})
for feature_name in sorted(self.card_features_manager.get_all_feature_names_set())
)
]
}
})
@staticmethod
def _make_feature(name, params, query):
return {
"name": name,
"params": params,
"template_language": "mustache",
"template": query,
}
الآن - وظيفة تحسب ميزات لاستعلام وبطاقات معينة:
def compute_cards_features(self, query: str, card_ids: Iterable[str],
feature_set_name=DEFAULT_FEATURE_SET_NAME) -> Mapping[str, List[float]]:
card_ids = list(card_ids)
result = self.elasticsearch_client.search({
"query": {
"bool": {
# ,
# — ,
# .
# ID.
"filter": [
{
"terms": {
"_id": card_ids
}
},
# — ,
# SLTR.
#
# feature set.
# ( ,
# filter, .)
{
"sltr": {
"_name": "logged_featureset",
"featureset": feature_set_name,
"params": {
# .
# , ,
#
# {{query}}.
"query": query
}
}
}
]
}
},
#
# .
"ext": {
"ltr_log": {
"log_specs": {
"name": "log_entry1",
"named_query": "logged_featureset"
}
}
},
"size": len(card_ids),
})
# (
# ) .
# ( ,
# , Kibana.)
return {
hit["_id"]: [feature.get("value", float("nan")) for feature in hit["fields"]["_ltrlog"][0]["log_entry1"]]
for hit in result["hits"]["hits"]
}
برنامج نصي بسيط يقبل CSV مع الطلبات وبطاقات الهوية كمدخلات ومخرجات CSV مع الميزات التالية:
# backend/tools/compute_movie_features.py
import csv
import itertools
import sys
import tqdm
from backend.wiring import Wiring
if __name__ == "__main__":
wiring = Wiring()
reader = iter(csv.reader(sys.stdin))
header = next(reader)
feature_names = wiring.search_ranking_manager.get_feature_names()
writer = csv.writer(sys.stdout)
writer.writerow(["query", "card_id"] + feature_names)
query_index = header.index("query")
card_id_index = header.index("card_id")
chunks = itertools.groupby(reader, lambda row: row[query_index])
for query, rows in tqdm.tqdm(chunks):
card_ids = [row[card_id_index] for row in rows]
features = wiring.search_ranking_manager.compute_cards_features(query, card_ids)
for card_id in card_ids:
writer.writerow((query, card_id, *features[card_id]))
أخيرًا ، يمكنك تشغيل كل شيء!
# feature set
docker-compose exec backend python -m tools.initialize_search_ranking
#
docker-compose exec -T backend \
python -m tools.generate_movie_events \
< ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv \
> ~/Downloads/habr-app-demo-dataset-events.csv
#
docker-compose exec -T backend \
python -m tools.compute_features \
< ~/Downloads/habr-app-demo-dataset-events.csv \
> ~/Downloads/habr-app-demo-dataset-features.csv
الآن لدينا ملفان - بهما أحداث وإشارات - ويمكننا بدء التدريب.
الترتيب: تدريب وتنفيذ النموذج
دعنا نتخطى تفاصيل تحميل مجموعات البيانات (يمكنك رؤية النص الكامل في هذا الالتزام ) والوصول مباشرة إلى النقطة.
# backend/tools/train_model.py
...
if __name__ == "__main__":
args = parser.parse_args()
feature_names, features = read_features(args.features)
events = read_events(args.events)
# train test 4 1.
all_queries = set(events.keys())
train_queries = random.sample(all_queries, int(0.8 * len(all_queries)))
test_queries = all_queries - set(train_queries)
# DMatrix — , xgboost.
#
# . 1, ,
# 0, ( . ).
train_dmatrix = make_dmatrix(train_queries, events, feature_names, features)
test_dmatrix = make_dmatrix(test_queries, events, feature_names, features)
# !
#
# ML,
# XGBoost.
param = {
"max_depth": 2,
"eta": 0.3,
"objective": "binary:logistic",
"eval_metric": "auc",
}
num_round = 10
booster = xgboost.train(param, train_dmatrix, num_round, evals=((train_dmatrix, "train"), (test_dmatrix, "test")))
# .
booster.dump_model(args.output, dump_format="json")
# , :
# ROC-.
xgboost.plot_importance(booster)
plt.figure()
build_roc(test_dmatrix.get_label(), booster.predict(test_dmatrix))
plt.show()
إطلاق
python backend/tools/train_search_ranking_model.py \
--events ~/Downloads/habr-app-demo-dataset-events.csv \
--features ~/Downloads/habr-app-demo-dataset-features.csv \
-o ~/Downloads/habr-app-demo-model.xgb
يرجى ملاحظة أنه نظرًا لأننا قمنا بتصدير جميع البيانات الضرورية باستخدام البرامج النصية السابقة ، فإن هذا البرنامج النصي لم يعد بحاجة إلى التشغيل داخل docker - يجب تشغيله على جهازك ، بعد تثبيته مسبقًا
xgboostو sklearn. وبالمثل ، في الإنتاج الحقيقي ، يجب تشغيل البرامج النصية السابقة في مكان ما حيث يوجد وصول إلى بيئة الإنتاج ، ولكن هذا ليس كذلك.
إذا تم كل شيء بشكل صحيح ، فسيتم تدريب النموذج بنجاح وسنرى صورتين جميلتين. الأول هو رسم بياني لأهمية المعالم: على

الرغم من أن الأحداث تم إنشاؤها عشوائيًا ،
combined_tf_idfتبين أنها أكثر أهمية من غيرها - لأنني قمت بخدعة وقللت بشكل مصطنع من احتمال النقر على البطاقات الأقل في نتائج البحث ، المصنفة بطريقتنا القديمة. حقيقة أن النموذج لاحظ هذه علامة جيدة وعلامة على أننا لم نرتكب أي أخطاء غبية تمامًا في عملية التعلم.
الرسم البياني الثاني هو منحنى ROC :

الخط الأزرق فوق الخط الأحمر ، مما يعني أن نموذجنا يتنبأ بالتسميات بشكل أفضل قليلاً من رمي العملة. (يجب أن يلمس منحنى مهندس ML الخاص بصديق أمي الزاوية اليسرى العليا تقريبًا.)
المسألة صغيرة جدًا - نضيف نصًا لملء النموذج ، ونملأه ونضيف عنصرًا جديدًا صغيرًا إلى استعلام البحث - إعادة:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -27,6 +30,19 @@ class ElasticsearchSearcher(Searcher):
"filter": list(self._make_filter_queries(tags, ids)),
}
},
+ "rescore": {
+ "window_size": 1000,
+ "query": {
+ "rescore_query": {
+ "sltr": {
+ "params": {
+ "query": query
+ },
+ "model": self.ranking_manager.get_current_model_name()
+ }
+ }
+ }
+ },
"aggregations": {
self.TAGS_AGGREGATION_NAME: {
"terms": {"field": "tags"}
الآن ، بعد قيام Elasticsearch بإجراء البحث الذي نحتاجه وتصنيف النتائج باستخدام خوارزمية (سريعة إلى حد ما) ، سنأخذ أفضل 1000 نتيجة ونعيد ترتيبها باستخدام صيغة التعلم الآلي (البطيئة نسبيًا). نجاح!
خاتمة
أخذنا تطبيق الويب البسيط الخاص بنا وانتقلنا من عدم وجود ميزة بحث في حد ذاتها إلى حل قابل للتطوير مع العديد من الميزات المتقدمة. لم يكن هذا من السهل القيام به. لكن الأمر ليس بهذه الصعوبة أيضًا! يكمن التطبيق النهائي في المستودع الموجود على Github في فرع باسم متواضع
feature/searchويتطلب تشغيل Docker و Python 3 مع مكتبات التعلم الآلي.
لقد استخدمت Elasticsearch لإظهار كيفية عمل ذلك بشكل عام ، وما هي المشاكل التي تتم مواجهتها وكيف يمكن حلها ، ولكن هذه بالتأكيد ليست الأداة الوحيدة للاختيار من بينها. تستحق كل من Solr و PostgreSQL فهارس النصوص الكاملة والمحركات الأخرى اهتمامك أيضًا عند اختيار ما تبني عليه شركتك
وبالطبع ، لا يتظاهر هذا الحل بأنه كامل وجاهز للإنتاج ، ولكنه مجرد توضيح لكيفية إنجاز كل شيء. يمكنك تحسينه إلى ما لا نهاية تقريبًا!
- فهرسة تزايدي. عند تعديل بطاقاتنا من خلالها
CardManager، سيكون من الجيد تحديثها على الفور في الفهرس. لكيCardManagerلا نعرف أن لدينا أيضًا بحثًا في الخدمة ، وللتخلص من التبعيات الدورية ، سيتعين علينا حل انعكاس التبعية بشكل أو بآخر. - للفهرسة في حالتنا الخاصة ، حزم MongoDB مع Elasticsearch ، يمكنك استخدام حلول جاهزة مثل موصل mongo .
- , — Elasticsearch .
- , , .
- , , . -, -, - … !
- ( , ), ( ). , .
- , , .
- يعد تنظيم مجموعة من العقد باستخدام التجزئة والتكرار متعة منفصلة تمامًا.
ولكن للحفاظ على حجم المقال قابلاً للقراءة ، سأتوقف عند هذا الحد وأتركك وحدك مع هذه التحديات. شكرا للاهتمام!