
في أكتوبر ، تقليديا ، أصبحت GPT-3 في دائرة الضوء مرة أخرى. هناك العديد من الأخبار المتعلقة بالنموذج من OpenAI - جيدة وليست جيدة.
صفقة OpenAI و Microsoft
سيتعين علينا أن نبدأ بأخرى أقل متعة - استحوذت Microsoft على الحقوق الحصرية لـ GPT-3. أثارت الصفقة الغضب كما هو متوقع - قال Elon Musk ، مؤسس OpenAI وهو الآن عضو سابق في مجلس إدارة الشركة ، إن Microsoft قد استحوذت بشكل أساسي على OpenAI.
الحقيقة هي أن OpenAI تم إنشاؤه في الأصل كمنظمة غير ربحية ذات مهمة عالية - عدم السماح للذكاء الاصطناعي بأن يكون في أيدي دولة أو شركة منفصلة. دعا مؤسسو المنظمة إلى انفتاح البحث في هذا المجال ، بحيث تعمل التكنولوجيا لصالح البشرية جمعاء.
تقول Microsoft ، في دفاعها ، إنها لن تقيد الوصول إلى نموذج API. وبالتالي ، في الواقع ، لم يتغير شيء - قبل ذلك لم تنشر OpenAI أيضًا الكود ، ولكن إذا سُمح حتى للشركات الشريكة سابقًا بالعمل مع GPT-3 فقط من خلال واجهة برمجة التطبيقات ، فإن Microsoft لديها الآن حقوق حصرية للاستخدام.
ruGPT3 من سبيربنك
الآن لمزيد من الأخبار السارة - نشر باحثون من Sberbank نموذجًا في الوصول المفتوح يكرر بنية GPT-3 ويستند إلى رمز GPT-2 ، والأهم من ذلك أنه تم تدريبه في مجموعة اللغة الروسية.
تم استخدام مجموعة من الأدب الروسي وبيانات ويكيبيديا ولقطات من الأخبار ومواقع الأسئلة والأجوبة ومواد من بوابات Pikabu و 22century.ru banki.ru و Omnia Russica كمجموعة بيانات للتدريب. قام المطورون أيضًا بتضمين بيانات من GitHub و StackOverflow لتعليم كيفية إنشاء التعليمات البرمجية والبرمجة. يبلغ إجمالي حجم البيانات التي تم تنظيفها أكثر من 600 جيجابايت.
الأخبار جيدة بالتأكيد ، ولكن هناك بعض المحاذير. هذا النموذج مشابه لـ GPT-3 ، لكن ليس كذلك. الكتاب أنفسهم يعترفونأنه أصغر بـ 230 مرة من أكبر إصدار من GPT-3 ، والذي يحتوي على 175 مليار وزن ، مما يعني أنه لا يمكنه تكرار نتائج القياس بالضبط. أي ، لا تتوقع أن يكتب هذا النموذج نصوصًا لا يمكن تمييزها عن النصوص الصحفية.
يجدر أيضًا مراعاة أن بنية GPT-3 الموصوفة قد تختلف عن التنفيذ الحقيقي. لا يمكنك أن تقول على وجه اليقين إلا بعد قراءة معلمات التدريب ، وإذا تم نشر الأوزان مع تأخير قبل ذلك ، فلا يمكن توقعها في ضوء الأحداث الأخيرة.
الحقيقة هي أن ميزانية المشروع تعتمد على عدد معايير التدريب ، ووفقًا للخبراء ، فإن تكلفة تدريب GPT-3 لا تقل عن 10 ملايين دولار. وبالتالي ، يمكن للشركات الكبيرة التي لديها متخصصون أقوياء في تعلم الآلة وموارد الحوسبة القوية فقط إعادة إنتاج عمل OpenAI.
تقرير حالة الذكاء الاصطناعي لعام 2020
كل ما سبق يؤكد استنتاجات التقرير السنوي الثالث حول الوضع الحالي في مجال التعلم الآلي. نشر ناثان بينايش وإيان هوغارث ، المستثمران المتخصصان في شركات الذكاء الاصطناعي الناشئة ، عرضًا تفصيليًا يغطي التكنولوجيا والموارد البشرية والتطبيقات الصناعية والتعقيدات القانونية.
من الغريب أن ما يصل إلى 85٪ من الأبحاث تُنشر بدون شفرة المصدر. إذا كان من الممكن تبرير المنظمات التجارية بحقيقة أن الكود غالبًا ما يتم نسجه في البنية التحتية للمشاريع ، فماذا عن المؤسسات البحثية والشركات غير الربحية مثل DeepMind و OpenAI؟
يقال أيضًا أن الزيادة في مجموعات البيانات والنماذج تؤدي إلى زيادة في الميزانيات ، وبالنظر إلى الركود في مجال التعلم الآلي ، فإن كل اختراق جديد يتطلب ميزانيات كبيرة بشكل غير متناسب (قارن حجم GPT-2 و GPT-3) ، مما يعني أنه يمكنهم تحمل تكاليفه فقط الشركات الكبيرة.
ننصحك بالتعرف على هذه الوثيقة ، حيث تمت كتابتها بإيجاز ووضوح ، ومصورة جيدًا. كما أن أربعة توقعات لعام 2020 من التقرير الأخير قد تحققت بالفعل.
لن نبالغ أكثر ، فلا تزال هناك قصص جيدة ، وإلا لما وجدت هذه المجموعة.
افتح نماذج متعددة اللغات من Google و Facebook
mT5
قامت Google بنشر كود المصدر ومجموعة البيانات لعائلة T5 للنماذج متعددة اللغات. بسبب الضجيج المرتبط بـ OpenAI ، لم تتم ملاحظة هذه الأخبار تقريبًا ، على الرغم من النطاق المثير للإعجاب - يحتوي النموذج الأكبر على 13 مليار معلمة.
للتدريب ، تم استخدام مجموعة بيانات من 101 لغة ، من بينها اللغة الروسية في المرتبة الثانية. يمكن تفسير ذلك من خلال حقيقة أن فريقنا العظيم والأقوياء هو ثاني أكثر الأماكن شعبية على الويب.
M2M-100
كما أن Facebook ليس بعيدًا عن الركب وقد وضع نموذجًا متعدد اللغات ، والذي ، وفقًا لبياناتهم ، يسمح بترجمة أزواج لغوية 100 × 100 بدون لغة وسيطة.
في مجال الترجمة الآلية ، من المعتاد إنشاء وتدريب نماذج لكل لغة ومهمة على حدة. ولكن في حالة Facebook ، فإن هذا النهج غير قادر على التوسع بشكل فعال ، حيث ينشر مستخدمو الشبكة الاجتماعية المحتوى بأكثر من 160 لغة.
عادةً ما تعتمد الأنظمة متعددة اللغات التي تتعامل مع لغات متعددة في وقت واحد على اللغة الإنجليزية. الترجمة تمت بوساطة وغير دقيقة. من الصعب سد الفجوة بين لغتي المصدر والهدف بسبب عدم كفاية البيانات ، حيث قد يكون من الصعب جدًا العثور على ترجمة من الصينية إلى الفرنسية والعكس صحيح. للقيام بذلك ، كان على المبدعين إنشاء بيانات تركيبية عن طريق الترجمة العكسية.
تقدم المقالة معايير ، ويتواءم النموذج مع الترجمة بشكل أفضل من النظير الذي يعتمد على اللغة الإنجليزية ، بالإضافة إلى رابط لمجموعة البيانات .

التقدم في مؤتمرات الفيديو
في أكتوبر ، ظهرت بعض الأخبار المثيرة للاهتمام من Nvidia في الحال.
النمط
أولاً ، نشرنا تحديثات لـ StyleGAN2 . توفر بنية النموذج منخفضة الموارد الآن أداءً محسنًا على مجموعات البيانات التي تحتوي على أقل من 30 ألف صورة. يقدم الإصدار الجديد دعمًا للدقة المختلطة: تم تسريع التدريب ~ 1.6 مرة ، والاستدلال ~ 1.3 مرة ، وانخفاض استهلاك وحدة معالجة الرسومات بمقدار 1.5 مرة. أضفنا أيضًا تحديدًا تلقائيًا للمعلمات الفائقة للطراز: حلول جاهزة لمجموعات البيانات ذات الدقة المختلفة وعدد مختلف من معالجات الرسومات المتاحة.
نيمو
الوحدات العصبية هي مجموعة أدوات مفتوحة المصدر تساعدك على إنشاء نماذج المحادثة وتدريبها وضبطها بسرعة. يتكون NeMo من نواة توفر "مظهرًا وإحساسًا" واحدًا لجميع النماذج والمجموعات ، وتتكون من وحدات مجمعة حسب النطاق.
ماكسين
من المحتمل أن يستخدم منتج آخر معلن عنه كلا التقنيتين أعلاه داخليًا. تجمع منصة مكالمات الفيديو Maxine بين حديقة حيوانات كاملة من خوارزميات ML. يتضمن ذلك تحسين الدقة المألوف بالفعل ، وإزالة الضوضاء ، وإزالة الخلفية ، ولكن أيضًا تصحيح النظرة والظل ، واستعادة الصورة بناءً على ميزات الوجه الرئيسية (مثل التزييف العميق) ، وإنشاء الترجمة وترجمة الكلام إلى لغات أخرى في الوقت الفعلي. أي تقريبًا كل ما تمت مواجهته سابقًا بشكل منفصل ، تم دمج Nvidia في منتج رقمي واحد. يمكنك الآن التقدم بطلب للحصول المبكر.
التطورات الجديدة في جوجل
بسبب الحجر الصحي ، هناك سباق حقيقي هذا العام للريادة في مجال مؤتمرات الفيديو. شارك Google Meet دراسة حالة لإنشاء خوارزمية لإزالة الخلفية عالية الجودة بناءً على إطار العمل من Mediapipe (والذي يمكنه تتبع حركة العينين والرأس واليدين).
أطلقت Google أيضًا ميزة جديدة لخدمة YouTube Stories على نظام التشغيل iOS تعمل على تحسين جودة الكلام. هذه حالة مثيرة للاهتمام ، لأنه يتوفر العديد من المحسنات للفيديو أكثر من الصوت. تراقب هذه الخوارزمية وتسجيل الارتباطات بين الكلام والعلامات المرئية ، مثل تعبيرات الوجه وحركات الشفاه ، والتي تستخدمها بعد ذلك لفصل الكلام عن أصوات الخلفية ، بما في ذلك الأصوات من مكبرات الصوت الأخرى.
قدمت الشركة أيضًا محاولة جديدةفي مجال التعرف على لغة الإشارة.
عند الحديث عن برنامج مؤتمرات الفيديو ، تجدر الإشارة أيضًا إلى خوارزميات التزييف العميق الجديدة.
MakeItTalk
في الآونة الأخيرة ، تم نشر رمز الخوارزمية التي تحرك الصورة ، بالاعتماد فقط على دفق الصوت ، في الوصول المفتوح . هذا جدير بالملاحظة ، لأن خوارزميات deepfake تأخذ الفيديو كمدخلات.

فوق التصديق
يحدد الجيل الجديد من خوارزميات التزييف العميق لنفسه مهمة استبدال ليس فقط الوجه ، ولكن الجسم كله ، بما في ذلك لون الشعر ولون البشرة والشكل. سيتم تطبيق هذه التقنية بشكل أساسي في مجال التسوق عبر الإنترنت ، بحيث يمكنك استخدام صور البضائع التي توفرها العلامة التجارية نفسها ، دون الحاجة إلى استئجار نماذج فردية. يمكن رؤية المزيد من التطبيقات في عرض الفيديو . حتى الآن ، يبدو الأمر غير مقنع ، لكن كل شيء قد يتغير قريبًا.
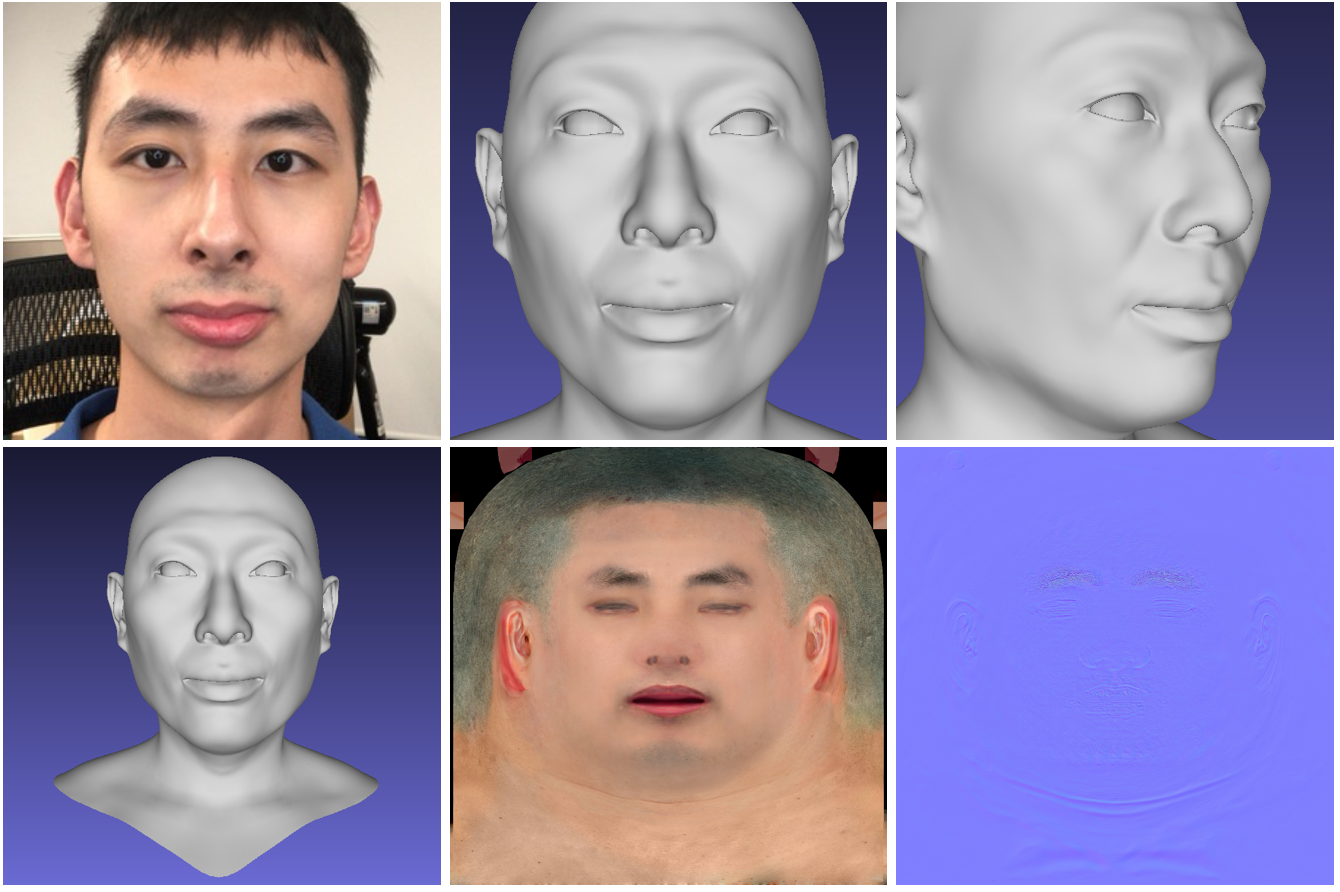
وجه هاي فاي ثلاثي الأبعاد
تولد الشبكة العصبية نموذجًا ثلاثي الأبعاد عالي الجودة لوجه الشخص من الصور. يقبل النموذج مقطع فيديو قصيرًا من كاميرا RGB-D عادية كمدخل ، وعند الإخراج يعطي النموذج ثلاثي الأبعاد للوجه. رمز المشروع ونموذج 3DMM متاحان للجمهور .

سكايار
قدم المؤلفون تقنية مفتوحة المصدر لاستبدال السماء بالفيديو في الوقت الفعلي ، مما يتيح لك أيضًا التحكم في الأنماط. يمكن إنشاء تأثيرات الطقس مثل البرق على الفيديو المستهدف.
يحل نموذج خط الأنابيب عددًا من المهام على مراحل: الشبكة تلطخ السماء ، وتتتبع الأجسام المتحركة ، وتلتف وتعيد طلاء الصورة لتتوافق مع نظام ألوان skybox.

البحر من خلال
تحل الأداة المهمة غير العادية المتمثلة في استعادة الألوان الحقيقية في الصور الفوتوغرافية تحت الماء. أي أن الخوارزمية تأخذ في الاعتبار العمق والمسافة إلى الأشياء من أجل استعادة الإضاءة وإزالة الماء من الصور. حتى الآن ، تتوفر مجموعات البيانات فقط.
نموذج MIT لتشخيص Covid-19
في الختام ، سوف نشارك حالة مثيرة للاهتمام حول موضوع ذي صلة - طور باحثو معهد ماساتشوستس للتكنولوجيا نموذجًا يميز المرضى الذين لا يعانون من أعراض المصابين بعدوى الفيروس التاجي عن الأشخاص الأصحاء الذين يستخدمون تسجيلات السعال القسري.
تم تدريب النموذج على عشرات الآلاف من الأشرطة الصوتية لعينات السعال. وفقًا لمعهد ماساتشوستس للتكنولوجيا ، تحدد الخوارزمية الأشخاص الذين تم التأكد من إصابتهم بـ Covid-19 بدقة تصل إلى 98.5٪.
وافقت السلطات الحكومية بالفعل على إنشاء التطبيق. سيتمكن المستخدم من تنزيل تسجيل صوتي لسعاله ، وبناءً على النتيجة ، تحديد ما إذا كان من الضروري إجراء تحليل كامل في المختبر.
هذا كل شيء ، شكرا لاهتمامكم!