ألقى بوب ستيجال حديثًا في CppCon 2020 بعنوان " مغامرات في التفكير SIMD " ، حيث تحدث ، من بين أشياء أخرى ، عن تجربته في استخدام AVX512 للتصفية المتوسطة مع النافذة 7. تسبب هذا الحديث في شعوري: من ناحية ، إنه رائع ، ويُزعم أنه أسرع بنحو 20 مرة من أغبى تطبيق STL ؛ من ناحية أخرى ، في أحد ممرات الخوارزمية من 16 عينة إدخال ، تبين أن مخرجات 2 فقط ، على الرغم من أن بيانات الإدخال كانت كافية لـ 10 ، وبعض تفاصيل التنفيذ جعلتني أرغب في محاولة تحسينها. فكرت وفكرت وخرجت بفكرة ، ثم أخرى ، ثم جربتها "في البرنامج" وأدركت أن لدي شيئًا أشاركه :) وهكذا ظهر هذا المقال.
التنفيذ الأساسي
سوف أصف بإيجاز كيف قام بوب بذلك (في الواقع ، إعادة سرد قصيرة للجزء المقابل من قصته ، إلى جانب صوره الخاصة). قام بعمل الأوليات التالية باستخدام AVX512 (سأحذف تلك الأوليات التي وصفها والتي تتوافق مباشرة مع عملية AVX512 واحدة):
تدوير: قم بتدوير العناصر الموجودة في تسجيل AVX-512 في دائرة

التحول بالحمل : نقل العناصر من السجل ، واستبدال العناصر من السجل الثاني
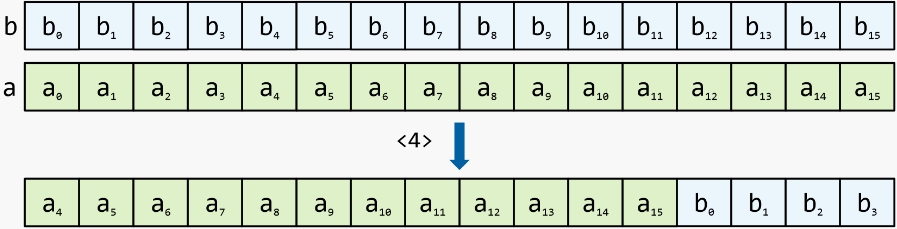
في مكان التحول مع الحمل : مثل التحول مع الحمل ، ولكن يتم تمرير سجلات الإدخال عن طريق المرجع وتبقى نتيجة التحول فيها
قارن مع التبادل : الفرز المتوازي حتى 8 أزواج من العناصر في السجل

, , : perm 0..15, ; mask 1 «» . : , perm. vmin , vmax ́ . , .
, , . :
1) shift with carry, «» , «» (.. 0 0..6, 1 — 1..7 . .)
2) , 0 , 1 —
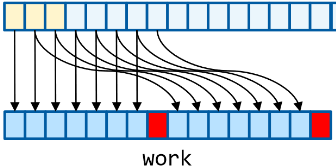
3) 7 , — 6 compare and exchange, . — — .
0
- , . , , ( , L2). , . AVX-512…
1
, — . 7 ; 6 !

, 6 r1-r6 , r0 r7? S[0..5], X, , S[3] .
X >= S[3], S[3] ,X <= S[2], S[2] S[3], S[2]S[2] < X < S[3], X S[3], , X. ,clamp(X, S[2], S[3])=>min(max(X, S[2]), S[3])!
:
«» 4 7- ( 0, 7, 2, 9) – X 4
6- 1..6 3..8 ( 0..7 8..15, )
6-
clamp 2 3 X[0] X[1], 2 3 X[2] X[3]
2x — 2 ( 6 5 , 7 — 6), clamp . : 1,86x . . ?
2
«» X . 6- ; 5 , 2 ( 3 ). — : S[0] <=> S[1], S[2] <=> S[3], S[4] <=> S[5]
2, . . , , !

— 2 , 2 . , : 1.06x. , .
3
- , 1, 6- .

, 4 ( ), 6; , 4- ?
2 , 4- . 6- : 2- Y 4- S, 2 3 ( Z). , min(Y[0], S[0]) => Z[0], ; max(Y[0], S[0]) Z[1]..Z[5] – . max(Y[1], S[3]) , min(Y[1], S[3]).
4- S[1], S[2], min/max. , 4 , 1 2 — 2 3 6- . , «» 4- S[1] S[2], — . , 2 , Y.
:
r1-r2 . .
— Y, r1-2, r5-6, r7-8, r11-12; permute 4 , Y r0-1, r4-5 . .
( ) «» ; r3-r6 r7-r10
max min Y[0]/S[0], Y[1]/S[3]
mask_permute Y S, S[1] S[2] ,
4
1 2, min/max X 8
, , , 2. — 1.64x , 2, 3 , .
; ( - permute; , - ), .
, :)
benchmark:
512 : 3.1-3.2 ; 7.3 , memcpy avx-512
50 : 2.8-2.9 ; 1.8 , memcpy (!)
.
5? , (disclaimer: — ).
16- 12 .
- 3 ( …)
1 , 4 ( 6 ) 4- — , . . 4 , 5 ; 8 .
2 , — 2 ; , .
3 , . , — , 12 . , «» — 24 , 12 .
9? 8 .
—
1 — 2 8- 4 , 4 ( 7 6 )
2 — , -
3 — , — 6- 2, 6- ( , ) , 8-.
, - . , https://github.com/tea/avx-median/. « », , -. , .
- , — . .
UPDATE
AVX2 . , , , , ( , 16 , ). , : 1.64x , .
اتضح أنه لم يتم فقد كل شيء - يمكن أيضًا تطبيق خطوة التحسين الأولى على هذا المتغير! من الضروري جمع 32 حافة من X ، ومن الضروري تشويش البيانات من أجل الفرز ، كما يجب أن تكون البيانات التي تم فرزها متغيرة ، وما إلى ذلك ، ولكن على الرغم من كل هذه الإيماءات ، فإن التسريع هو 1.27 مرة.
لم أحاول تنفيذ الخطوتين 2 و 3 ، لأنه من الواضح أنه سيكون أبطأ. من المحتمل تمامًا أنه بالنسبة للحالة مع ، على سبيل المثال ، النافذة 11 ، سيعملون في علامة زائد (لكنني لا أعرف ما إذا كان شخص ما يحتاج إلى مرشح متوسط 1D سريع مع نوافذ كبيرة).