هذا ليس تحليل منهجي أو جدول. وجهة نظر فردية ، أيضًا من وجهة نظر عالم جيوفيزيائي. لكنني أشعر بالفضول دائمًا لقراءة Gartner MQ ، فهي تصوغ بعض النقاط بشكل مثالي. إذن فهذه هي الأشياء التي اهتمت بها من الناحية الفنية والسوقية والفلسفية.
هذا ليس للأشخاص المهتمين بعمق في تعلم الآلة ، ولكن للأشخاص المهتمين بما يحدث بشكل عام في السوق.
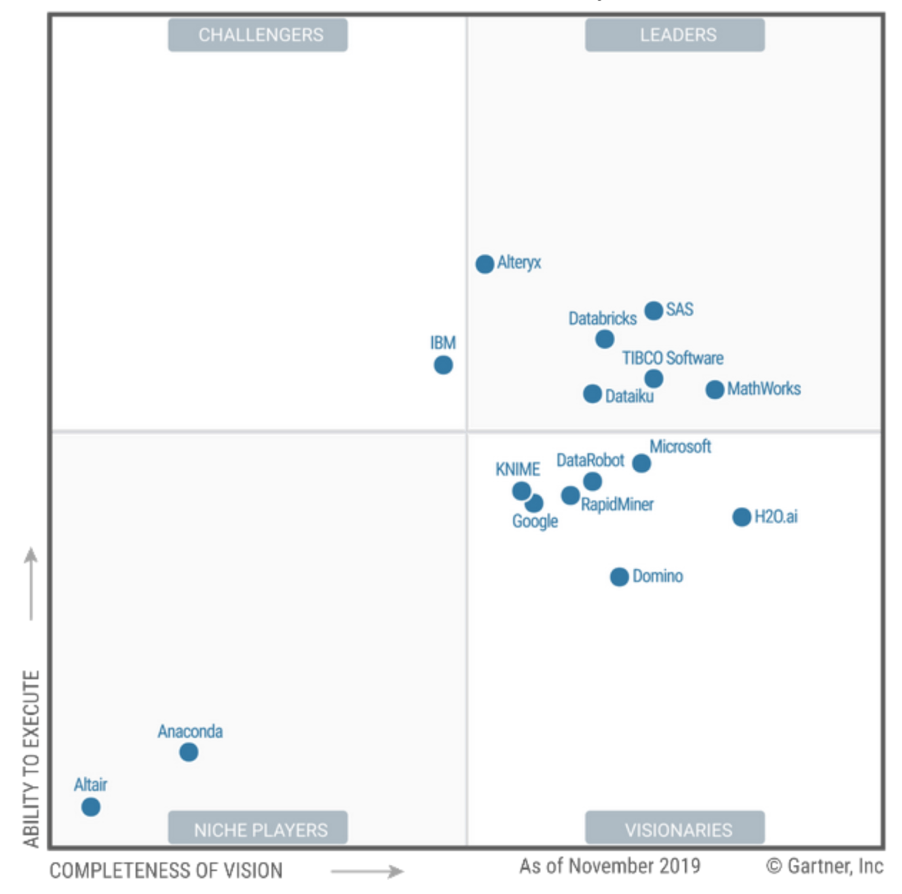
يتداخل سوق DSML نفسه منطقيًا بين خدمات مطوري BI و Cloud AI.
أحب الاقتباسات والمصطلحات الأولى:
- "قد لا يكون القائد هو الخيار الأفضل" - قائد السوق ليس بالضرورة ما تحتاجه. عاجل جدا! نتيجة لعدم وجود عميل وظيفي ، فإنهم يبحثون دائمًا عن الحل "الأفضل" ، وليس الحل "المناسب".
- يتم اختصار نموذج التشغيل على أنه MOPs. والصلصال صعب للجميع! - (مظهر الصلصال الرائع يجعل النموذج يعمل).
- تعد بيئة الكمبيوتر المحمول مفهومًا مهمًا حيث يتم جمع التعليمات البرمجية والتعليقات والبيانات والنتائج معًا. هذا واضح للغاية وواعد ويمكن أن يقلل بشكل كبير من كمية كود واجهة المستخدم.
- «Rooted in OpenSource» — – .
- «Citizen Data Scientists» — , , , . .
- «Democratise» — “ ”. «democratise the data» «free the data», . «Democratise» — long tail . — !
- «Exploratory Data Analysis – EDA» — . . . , . ,
- "قابلية التكرار " - أقصى قدر من الحفاظ على جميع معلمات البيئة والمدخلات والمخرجات ، بحيث يمكنك تكرار التجربة بمجرد إجرائها. المصطلح الأكثر أهمية لبيئة الاختبار التجريبية!
وبالتالي:
التريكس
الواجهة الرائعة هي مجرد لعبة. قابلية التوسع ، بالطبع ، ضيقة بعض الشيء. وفقا لذلك ، فإن المجتمع المواطن من المهندسين حول نفسه مع tsatski للعب. تحليلات لها الكل في زجاجة واحدة. ذكرني من Coscad الطيفي الارتباط تحليل البيانات جناح التي كانت مبرمجة في 90s.
اناكوندا
مجتمع حول خبراء Python و R. المصدر المفتوح كبير ، على التوالي. اتضح أن زملائي يستخدمون باستمرار. لم اعرف.
داتابريكس
يتكون من ثلاثة مشاريع مفتوحة المصدر - لقد جمع مطورو Spark الكثير من المال منذ عام 2013. لا بد لي من قراءة الويكي مباشرة:
في سبتمبر 2013 ، أعلنت Databricks أنها جمعت 13.9 مليون دولار من Andreessen Horowitz. جمعت الشركة 33 مليون دولار إضافية في 2014 ، 60 مليون دولار في 2016 ، 140 مليون دولار في 2017 ، 250 مليون دولار في 2019 (فبراير) و 400 مليون دولار في 2019 (أكتوبر) "!!!نشر شرارة بعض الناس العظماء. غير مألوف آسف!
والمشاريع هي:
- Delta Lake - تم إصدار ACID على Spark مؤخرًا (ما حلمنا به مع Elasticsearch) - يحولها إلى قاعدة بيانات: مخطط صارم ، ACID ، تدقيق ، إصدارات ...
- ML Flow - تتبع النماذج وتعبئتها وإدارتها وتخزينها.
- Koalas - Pandas DataFrame API على Spark - Pandas - Python API للعمل مع الجداول والبيانات بشكل عام.
يمكنك أن ترى عن Spark ، الذي فجأة لا يعرف أو نسي: link . نظرت Vidosiki بأمثلة من نقار الخشب الاستشارية المملة قليلاً ولكنها مفصلة: DataBricks لعلوم البيانات ( رابط ) وهندسة البيانات ( رابط ).
باختصار ، Databricks يسحب Spark. من يريد استخدام Spark بشكل طبيعي في السحابة يأخذ DataBricks دون تردد ، كما هو مقصود :) Spark هو العامل المميز هنا.
اكتشفت أن Spark Streaming ليس حقيقيًا مزيفًا في الوقت الحقيقي أو microbatching. وإذا كنت بحاجة إلى وقت حقيقي حقيقي ، فهو في Apache STORM. لا يزال الجميع يقول ويكتب أن Spark أكثر برودة من MapReduce. هذا هو الشعار.
داتيكو
شيء رائع من البداية إلى النهاية. هناك الكثير من الإعلانات. ألا أفهم كيف يختلف عن الأتريكس؟
داتا روبوت
Paxata لإعداد البيانات هي شركة منفصلة تم شراؤها بواسطة Data Robots في ديسمبر 2019. جمعت 20 مليون دولار أمريكي وبيعت. كل شيء في 7 سنوات.
تحضير البيانات في Paxata وليس Excel - انظر هنا: الرابط .
هناك عمليات محاكاة ساخرة تلقائية وانضم إلى المقترحات بين مجموعتي بيانات. شيء رائع - لفرز البيانات ، والتركيز بشكل أكبر على المعلومات النصية ( رابط ).
كتالوج البيانات عبارة عن كتالوج رائع لمجموعات البيانات "الحية" التي لا يحتاجها أحد.
من المثير للاهتمام أيضًا كيفية تكوين الدلائل في Paxata ( رابط ).
«According to analyst firm Ovum, the software is made possible through advances in predictive analytics, machine learning and the NoSQL data caching methodology.[15] The software uses semantic algorithms to understand the meaning of a data table's columns and pattern recognition algorithms to find potential duplicates in a data-set.[15][7] It also uses indexing, text pattern recognition and other technologies traditionally found in social media and search software.»
منتج Data Robot الرئيسي هنا . شعارهم من النموذج إلى تطبيق الشركات! اكتشف الاستشارات لصناعة النفط فيما يتعلق بالأزمة ، ولكن مبتذلة للغاية ورتيبة: link . شاهد مقاطع الفيديو الخاصة بهم على Mops أو MLops ( رابط ). هذا هو فرانكشتاين الذي يتكون من 6-7 عمليات اقتناء لمنتجات مختلفة.
بالطبع ، يتضح أن فريقًا كبيرًا من علماء البيانات يجب أن يكون لديهم مثل هذه البيئة للعمل مع النماذج ، وإلا فإنهم سينتجون الكثير منها ولن ينشروا أي شيء أبدًا. وفي واقع استخراج النفط والغاز لدينا - يمكن إنشاء نموذج واحد بنجاح وهذا تقدم كبير بالفعل!
كانت العملية نفسها تذكرنا جدًا بعمل أنظمة التصميم في الجيولوجيا والجيوفيزياء ، على سبيل المثال ، Petrel... جميع النماذج المتنوعة وصنعها وتعديلها. جمع البيانات في النموذج. ثم قاموا بعمل نموذج مرجعي ووضعوه قيد الإنتاج! هناك العديد من أوجه التشابه بين ، على سبيل المثال ، نموذج جيولوجي ونموذج ML.
الدومينو
التركيز على النظام الأساسي المفتوح والتعاون. يسمح لمستخدمي الأعمال بالدخول مجانًا. معمل البيانات الخاص بهم يشبه إلى حد كبير Sharepoint. (ومن اسم يعطي آي بي إم بقوة). جميع التجارب مرتبطة بمجموعة البيانات الأصلية. كم هو مألوف :) كما هو الحال في ممارستنا - تم سحب بعض البيانات إلى النموذج ، ثم تم تنظيفها وترتيبها في النموذج ، وكل هذا موجود بالفعل في النموذج ولا يمكنك العثور على النهايات في البيانات الأولية.
يحتوي Domino على بنية أساسية افتراضية رائعة. قمت بتجميع الآلة بعدد النوى في الثانية وذهبت لأحصي. كيف تم ذلك ليس واضحًا تمامًا على الفور. عامل ميناء في كل مكان. الكثير من الحرية! يمكن توصيل أي مساحات عمل من أحدث الإصدارات. قم بإجراء التجارب بالتوازي. تتبع واختيار الناجحين.
مثل DataRobot - يتم نشر النتائج لمستخدمي الأعمال في شكل تطبيقات. خاصة "أصحاب المصلحة" الموهوبين. ويتم أيضًا مراقبة الاستخدام الفعلي للنماذج. كل شيء من أجل الصلصال!
لم أفهم تمامًا كيف تدخل النماذج المعقدة في الإنتاج. يتم توفير بعض واجهات برمجة التطبيقات لإطعامهم بالبيانات والحصول على النتائج.
H2O
يعد الذكاء الاصطناعي بدون محرك نظامًا مضغوطًا ومباشرًا للغاية لتعلم الآلة تحت الإشراف. كل شيء في صندوق واحد. ليس من الواضح بشأن الواجهة الخلفية على الفور.
يتم تجميع النموذج تلقائيًا في خادم REST أو تطبيق Java. هذا هو فكرة عظيمة. لقد تم عمل الكثير من أجل التفسير وقابلية التفسير. تفسير وتفسير نتائج تشغيل النموذج (ما الذي لا ينبغي تفسيره في جوهره ، وإلا يمكن للشخص حسابه؟).
لأول مرة ، يتم النظر بالتفصيل في دراسة حالة حول البيانات غير المهيكلة ومعالجة اللغات الطبيعية . صورة معمارية عالية الجودة. بشكل عام أحببت الصور.
يوجد إطار عمل H2O كبير مفتوح المصدر غير واضح تمامًا (مجموعة من الخوارزميات / المكتبات؟). امتلك كمبيوتر محمول مرئي بدون برمجة مثل Jupiter ( link). قرأت أيضًا عن نماذج Pojo و Mojo - H2O المغلفة في الواقع. الأول على الجبهة ، والثاني مع التحسين. H20 هم الوحيدون (!) الذين كتب لهم Gartner تحليلات نصية ومعالجة اللغات الطبيعية في نقاط قوتهم ، بالإضافة إلى جهودهم في التفسير. انها مهمة جدا!
المرجع نفسه: الأداء العالي والتحسين والمعيار الصناعي لتكامل الحديد والسحابة.
ومن المنطقي من حيث الضعف - برنامج Driverles AI ضعيف وضيق مقارنة بمصدره المفتوح. إعداد البيانات أعرج مقارنة بنفس Paxata! وتجاهل البيانات الصناعية - التدفق والرسم البياني والجغرافي. حسنًا ، لا يمكن أن يكون كل شيء على ما يرام.
KNIME
لقد أحببت 6 حالات عمل محددة جدًا ومثيرة للاهتمام للغاية على الصفحة الرئيسية. قوي مفتوح المصدر.
لقد تراجعت شركة Gartner من القادة إلى أصحاب الرؤى. يعد كسب المال الضعيف علامة جيدة للمستخدمين ، نظرًا لأن Leader ليس دائمًا الخيار الأفضل.
الكلمة الأساسية هي نفسها تمامًا في H2O - زيادة ، فهذا يعني مساعدة علماء بيانات المواطن الفقير. هذه هي المرة الأولى التي يتم فيها توبيخ أي شخص بسبب الأداء في مراجعة! مثير للإعجاب؟ أي أن هناك قدرًا كبيرًا من القوة الحاسوبية بحيث لا يمكن أن يكون الأداء مشكلة نظامية على الإطلاق؟ لدى شركة Gartner مقالة منفصلة عن كلمة "مُعزز" ، والتي لم أتمكن من الوصول إليها.
ويبدو أن KNIME هي أول شخص غير أمريكي في المراجعة! (وقد أحب المصممون حقًا صفحتهم المقصودة. أشخاص غرباء.
ماثووركس
ماتلاب هو صديق فخري قديم معروف للجميع! صناديق أدوات لجميع مجالات الحياة والمواقف. شيء مختلف جدا. في الواقع ، هناك الكثير والكثير والكثير من الرياضيات لجميع المناسبات بشكل عام!
منتج إضافي Simulink لتصميم الأنظمة. أنا حفرت في أدوات العمل لالتوائم الرقمية - أنا لا أفهم أي شيء حيال ذلك، ولكن في الكثير قد كتب هنا. ل صناعة النفط . بشكل عام ، هذا منتج يختلف اختلافًا جوهريًا عن أعماق الرياضيات والهندسة. لتحديد مجموعات أدوات الرياضيات المحددة. وفقًا لـ Gartner ، لديهم جميعًا مشاكل مثل المهندسين الأذكياء - لا يوجد تعاون - كل منهم يبحث في نموذجه الخاص ، لا ديمقراطية ، لا قابلية للاستغلال.
رابيدماينر
لقد واجهت وسمعت الكثير من قبل (مع Matlab) في سياق المصدر المفتوح الجيد. دفن قليلا في TurboPrep كالمعتاد. أنا مهتم بكيفية الحصول على بيانات نظيفة من البيانات القذرة.
مرة أخرى ، يمكنك أن ترى أن الأشخاص جيدون في مواد التسويق لعام 2018 والمتحدثين باللغة الإنجليزية الرهيبة في العرض التوضيحي المميز
والناس من دورتموند منذ عام 2001 مع ماضي ألماني قوي)

لم أفهم من الموقع ما هو متاح بالضبط في المصدر المفتوح - تحتاج إلى التعمق أكثر. مقاطع فيديو جيدة حول النشر ومفاهيم AutoML.
لا يوجد شيء مميز في خلفية خادم RapidMiner أيضًا. من المحتمل أن يكون مضغوطًا ويعمل جيدًا عند التشغيل المسبق خارج الصندوق. معبأة في Docker. بيئة مشتركة فقط على خادم RapidMiner. ثم هناك Radoop ، بيانات من hadup ، عد القوافي من Spark في سير عمل الاستوديو.
دفعهم إلى الأسفل كما هو متوقع من قبل الباعة الشباب المثيرين "بائعي العصا المخططة". ومع ذلك ، تتوقع شركة Gartner النجاح المستقبلي في مساحة Enterprise. يمكنك جمع الأموال هناك. الألمان يعرفون كم هو مقدس ومقدس :) لا تذكر SAP !!!
يفعلون الكثير من أجل المواطنين! ولكن يمكنك أن ترى على الصفحة كيف تقول شركة Gartner إنهم يواجهون صعوبة في ابتكار المبيعات وأنهم لا يقاتلون من أجل اتساع نطاق التغطية ، ولكن من أجل الربحية.
غادر SAS و Tibco بائعي BI النموذجيين بالنسبة لي ... وكلاهما في القمة ، مما يؤكد اعتقادي بأن DataScience الطبيعي ينمو منطقيًا
من BI ، وليس من السحاب والبنية التحتية Hadoop. من الأعمال ، أي ليس من تكنولوجيا المعلومات. كما هو الحال في Gazpromneft على سبيل المثال: link ، تنمو بيئة DSML الناضجة من ممارسة BI الصلبة. لكن ربما لديها عيب وتحيز على MDM وأشياء أخرى ، من يدري.
ساس
ليس الكثير ليقوله. فقط الأشياء الواضحة.
تيبكو
تتم قراءة الإستراتيجية في قائمة التسوق على صفحة Wiki طويلة الصفحة. نعم قصة طويلة ولكن 28 !!! تشارلز. رشوة BI Spotfire (2007) في شبابي التقني. وأيضًا إعداد التقارير بواسطة Jaspersoft (2014) ، ثم ما يصل إلى ثلاثة بائعي التحليلات التنبؤية Insightful (S-plus) (2008) و Statistica (2017) و Alpine Data (2017) ومعالجة الأحداث وبثها Streambase System (2013) و MDM Orchestra Networks (2018) ) و Snappy Data (2019) في الذاكرة.
مرحبا فرانكي!
