لفهم كيفية ظهور فهارس B ، دعونا نتخيل عالماً بدونها ونحاول حل مشكلة نموذجية. على طول الطريق ، سنناقش المشاكل التي سنواجهها وطرق حلها.

المقدمة
في عالم قواعد البيانات ، هناك طريقتان أكثر شيوعًا لتخزين المعلومات:
- على أساس الهياكل القائمة على السجل.
- بناء على الصفحات.
تتمثل ميزة الطريقة الأولى في أنها تتيح لك قراءة وحفظ البيانات بسهولة وسرعة. لا يمكن كتابة المعلومات الجديدة إلا في نهاية الملف (التسجيل المتسلسل) ، مما يضمن سرعة تسجيل عالية. يتم استخدام هذه الطريقة بواسطة قواعد مثل Leveldb و Rocksdb و Cassandra.
الطريقة الثانية (القائمة على الصفحة) تقسم البيانات إلى أجزاء ذات حجم ثابت وتحفظها على القرص. تسمى هذه الأجزاء "الصفحات" أو "الكتل". تحتوي على سجلات (صفوف ، مجموعات) من الجداول.
يتم استخدام طريقة تخزين البيانات هذه بواسطة MySQL و PostgreSQL و Oracle وغيرها. ونظرًا لأننا نتحدث عن الفهارس في MySQL ، فهذا هو بالضبط النهج الذي سننظر فيه.
تخزين البيانات في MySQL
لذلك ، يتم حفظ جميع البيانات في MySQL على القرص كصفحات. يتم تنظيم حجم الصفحة بواسطة إعدادات قاعدة البيانات وهو 16 كيلو بايت افتراضيًا.
تحتوي كل صفحة على 38 بايت من الرؤوس ونهاية 8 بايت (كما هو موضح في الشكل). ولا يتم ملء المساحة المخصصة لتخزين البيانات بالكامل ، لأن MySQL تترك مساحة فارغة في كل صفحة للتغييرات المستقبلية.
علاوة على ذلك في الحسابات ، سوف نتجاهل معلومات الخدمة ، على افتراض أن كل 16 كيلوبايت من الصفحة مملوءة ببياناتنا. لن نتعمق في تنظيم صفحات InnoDB ، فهذا موضوع لمقال منفصل. يمكنك قراءة المزيد عن هذا هنا .

نظرًا لأننا اتفقنا أعلاه على أن الفهارس غير موجودة بعد ، على سبيل المثال ، سننشئ جدولًا بسيطًا بدون أي فهارس (في الواقع ، ستظل MySQL تنشئ فهرسًا ، لكننا لن نأخذها في الاعتبار في الحسابات):
CREATE TABLE `product` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` CHAR(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`category_id` INT NOT NULL,
`price` INT NOT NULL,
) ENGINE=InnoDB;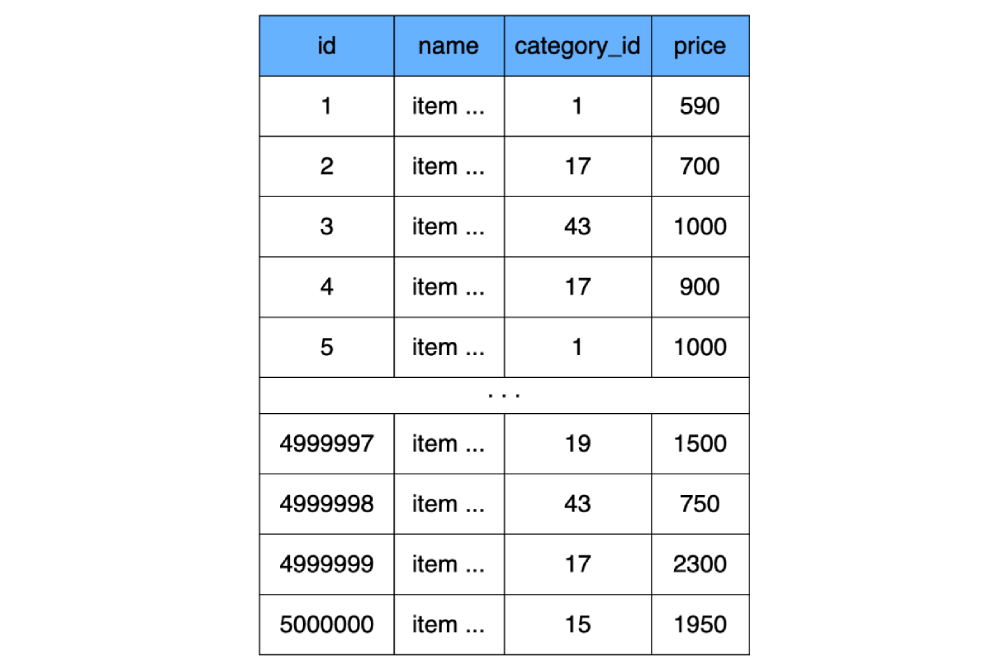
وتنفيذ الطلب التالي:
SELECT * FROM product WHERE price = 1950;سيفتح MySQL الملف حيث يتم تخزين البيانات من الجدول
productويبدأ في التكرار على جميع السجلات (الصفوف) بحثًا عن السجلات المطلوبة ، ومقارنة الحقل priceمن كل صف تم العثور عليه مع القيمة الموجودة في الاستعلام. من أجل الوضوح ، أنا أعتبر على وجه التحديد الخيار مع إجراء مسح كامل للملف ، وبالتالي فإن الحالات التي تتلقى فيها MySQL بيانات من ذاكرة التخزين المؤقت ليست مناسبة لنا.
ما هي المشاكل التي يمكن أن نواجهها مع هذا؟
HDD
نظرًا لأننا قمنا بتخزين كل شيء على القرص الصلب ، فلنلقِ نظرة على أجهزته. يقوم القرص الصلب بقراءة البيانات وكتابتها في قطاعات (كتل). يمكن أن يتراوح حجم هذا القطاع من 512 بايت إلى 8 كيلو بايت (حسب القرص). يمكن دمج عدة قطاعات متتالية في مجموعات.
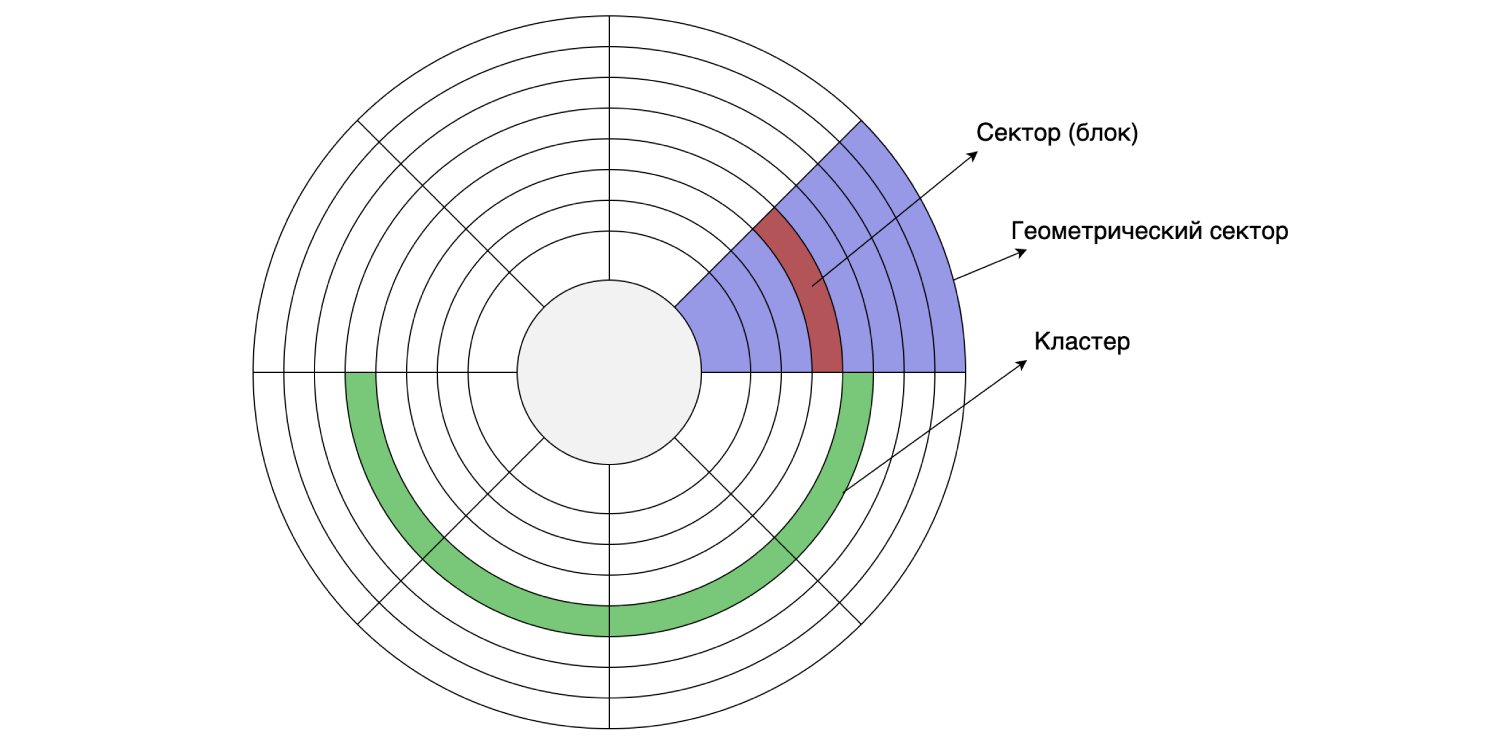
يمكن تعيين حجم الكتلة عند تنسيق / تقسيم القرص ، أي يتم ذلك برمجيًا. افترض أن حجم القطاع على القرص هو 4 كيلو بايت ، وأن نظام الملفات مقسم بحجم كتلة 16 كيلو بايت: تتكون الكتلة الواحدة من أربعة قطاعات. كما نتذكر ، تقوم MySQL افتراضيًا بتخزين البيانات على القرص في صفحات 16 كيلوبايت ، لذلك تتناسب صفحة واحدة مع مجموعة أقراص واحدة.
لنحسب مقدار المساحة التي ستشغلها لوحة المنتج ، بافتراض أنها تحتوي على 500000 عنصر. لدينا ثلاثة حقول من أربعة بايت
id، priceو category_id. دعنا نتفق على أن حقل الاسم لجميع السجلات يتم ملؤه حتى النهاية (كل 100 حرف) ، وكل حرف يأخذ 3 بايت. (3 * 4) + (100 * 3) = 312 بايت - هذا هو مقدار وزن صف واحد من طاولتنا ، وضرب هذا في 500000 صف ، نحصل على وزن الجدول product156 ميغا بايت.
وبالتالي ، لتخزين هذا الملصق ، يلزم وجود 9750 مجموعة على القرص الثابت (9750 صفحة من 16 كيلوبايت).
عند الحفظ على القرص ، يتم أخذ مجموعات حرة ، مما يؤدي إلى "تلطيخ" مجموعات من لوحة واحدة (ملف) على القرص بأكمله (وهذا ما يسمى التجزئة). قراءة مثل هذه الكتل من الذاكرة الموجودة بشكل عشوائي على القرص تسمى القراءة العشوائية. هذه القراءة أبطأ لأنه يتعين عليك تحريك رأس القرص الصلب عدة مرات. لقراءة الملف بأكمله ، علينا القفز على القرص بالكامل للحصول على المجموعات المطلوبة.
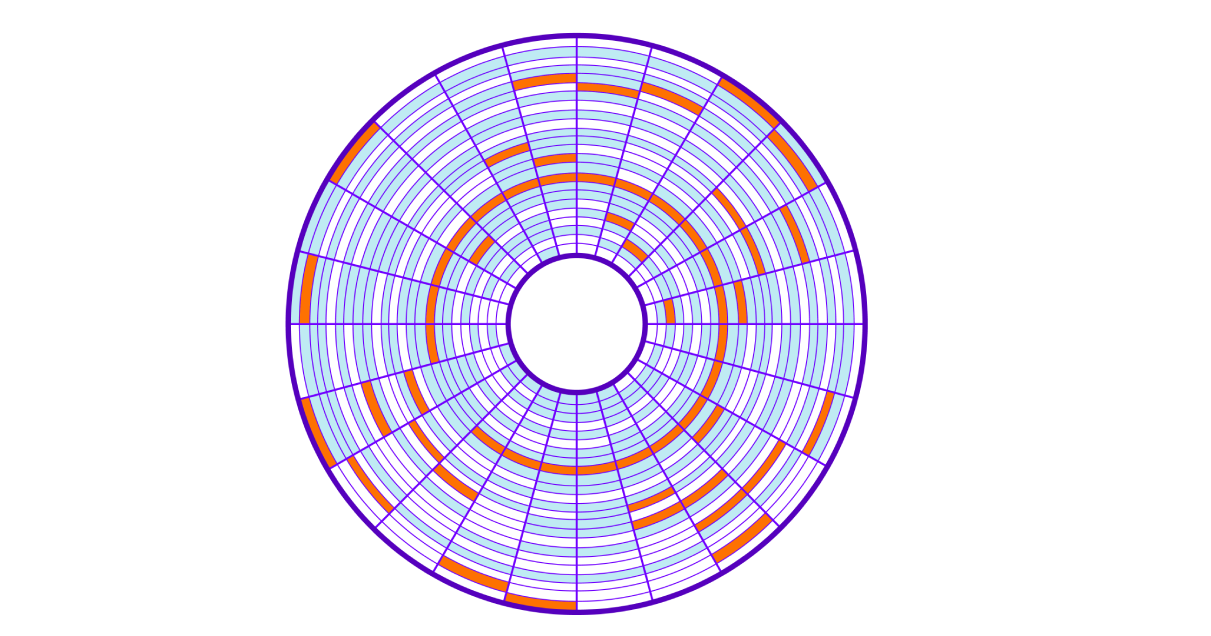
دعنا نعود إلى استعلام SQL الخاص بنا. للعثور على جميع الصفوف ، سيتعين على الخادم قراءة جميع المجموعات البالغ عددها 9750 مجموعة المنتشرة عبر القرص ، وسيستغرق الأمر وقتًا طويلاً لتحريك رأس قراءة القرص. كلما زاد عدد المجموعات التي نستخدم بياناتنا ، كلما كان البحث عنها أبطأ. وإلى جانب ذلك ، ستؤدي عمليتنا إلى انسداد نظام الإدخال / الإخراج الخاص بنظام التشغيل.
في النهاية ، نحصل على سرعة قراءة منخفضة ؛ "تعليق" نظام التشغيل ، انسداد نظام الإدخال / الإخراج ؛ وإجراء الكثير من المقارنات ، والتحقق من شروط الاستعلام لكل صف.
دراجتي الخاصة
كيف يمكننا حل هذه المشكلة بأنفسنا؟
نحن بحاجة لمعرفة كيفية تحسين عمليات البحث في الجدول
product. دعنا ننشئ جدولًا آخر نخزن فيه الحقل priceورابط السجل (المنطقة الموجودة على القرص) في جدولنا فقط product. دعنا نأخذها على الفور كقاعدة أنه عند إضافة البيانات إلى جدول جديد ، سنخزن الأسعار في نموذج مرتبة.
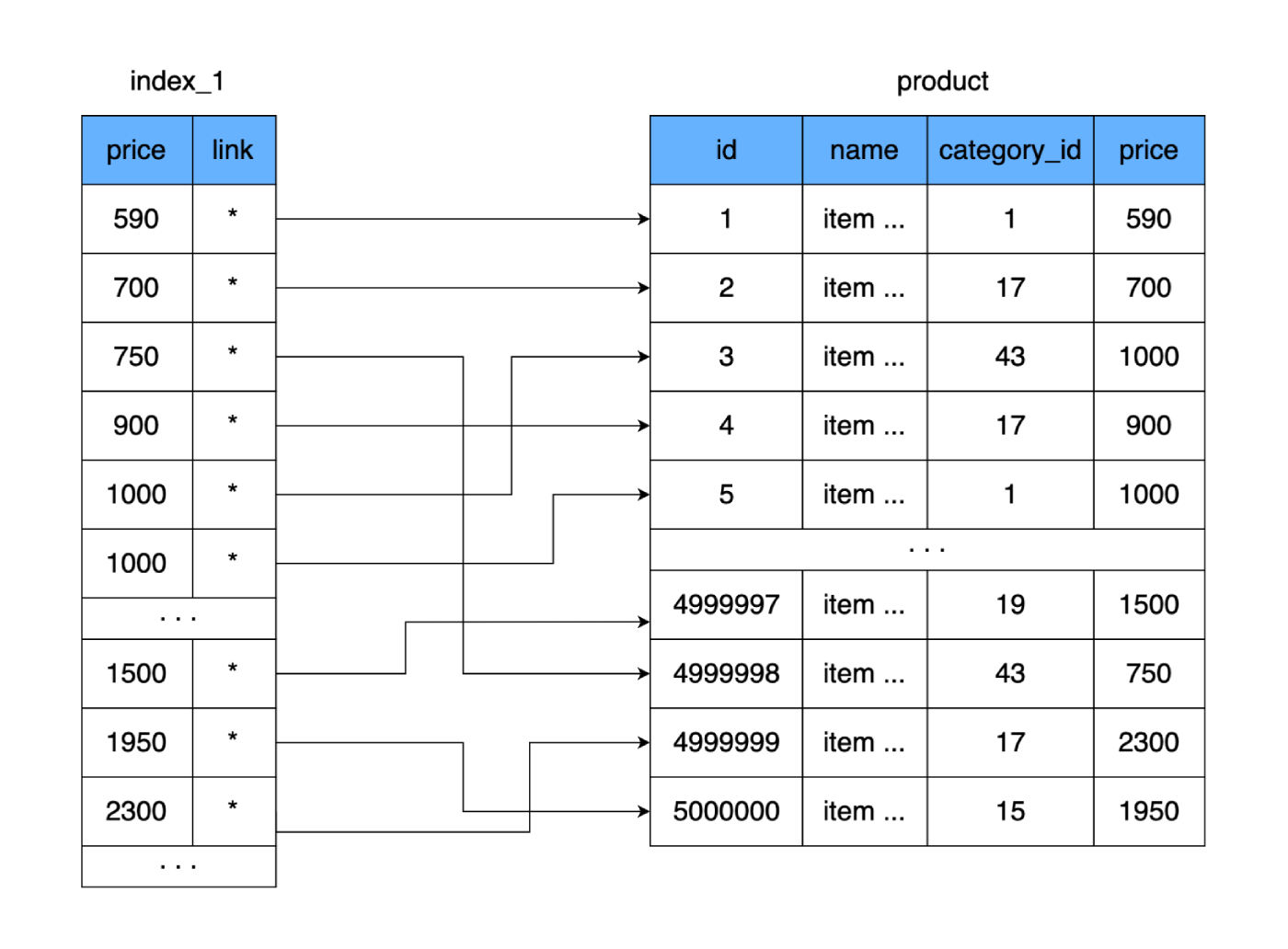
ماذا يعطينا؟ يتم تخزين الجدول الجديد ، مثل الجدول الرئيسي ، على صفحة القرص بصفحة (في كتل). يحتوي على السعر ورابط للجدول الرئيسي. دعونا نحسب مقدار المساحة التي سيستغرقها هذا الجدول. يأخذ السعر 4 بايت ، والسماح للإشارة إلى الجدول الرئيسي (العنوان) أن يكون 4 بايت أيضًا. بالنسبة إلى 500000 صف ، سيزن طاولتنا الجديدة 4 ميغا بايت فقط. بهذه الطريقة ، سيتم احتواء عدد أكبر من الصفوف من الجدول الجديد في صفحة بيانات واحدة ، وستكون هناك حاجة إلى عدد أقل من الصفحات لتخزين جميع أسعارنا.
إذا كان الجدول الكامل يتطلب 9750 مجموعة من الأقراص الثابتة (أو أسوأ سيناريو ، 9750 قفزة للقرص الصلب) ، فإن الجدول الجديد يناسب 250 مجموعة فقط. نتيجة لهذا ، سيتم تقليل عدد المجموعات المستخدمة على القرص بشكل كبير ، وبالتالي الوقت الذي يقضيه في القراءة العشوائية. حتى إذا قرأنا جدولنا الجديد بالكامل وقارننا القيم للعثور على السعر المناسب ، في أسوأ الحالات ، سوف يستغرق الأمر 250 قفزة عبر مجموعات الجدول الجديد. وبعد العثور على العنوان المطلوب ، سنقرأ مجموعة أخرى حيث توجد البيانات الكاملة. النتيجة: 251 قراءة مقابل 9750 الأصلي. الفرق كبير.
بالإضافة إلى ذلك ، للبحث عن مثل هذا الجدول ، يمكنك استخدام ، على سبيل المثال ، خوارزمية البحث الثنائي (منذ أن تم فرز القائمة). سيوفر هذا المزيد من عدد عمليات القراءة والمقارنة.
لنسمي الجدول الثاني فهرسًا.
الصيحة! لقد توصلنا إلى فهرس
لكن توقف: مع نمو الجدول ، سيصبح المؤشر أكبر وأكبر ، وسنعود في النهاية إلى المشكلة الأصلية. سيستغرق البحث مرة أخرى وقتًا طويلاً.
فهرس آخر
وإذا قمت بإنشاء فهرس آخر أعلى الفهرس الموجود؟
هذه المرة فقط لن نكتب كل قيمة للحقل
price، لكننا سنربط قيمة واحدة بالصفحة بأكملها (الكتلة) من الفهرس. أي ، سيظهر مستوى إضافي من الفهرس ، والذي سيشير إلى مجموعة البيانات من الفهرس السابق (الصفحة الموجودة على القرص حيث يتم تخزين البيانات من الفهرس الأول).
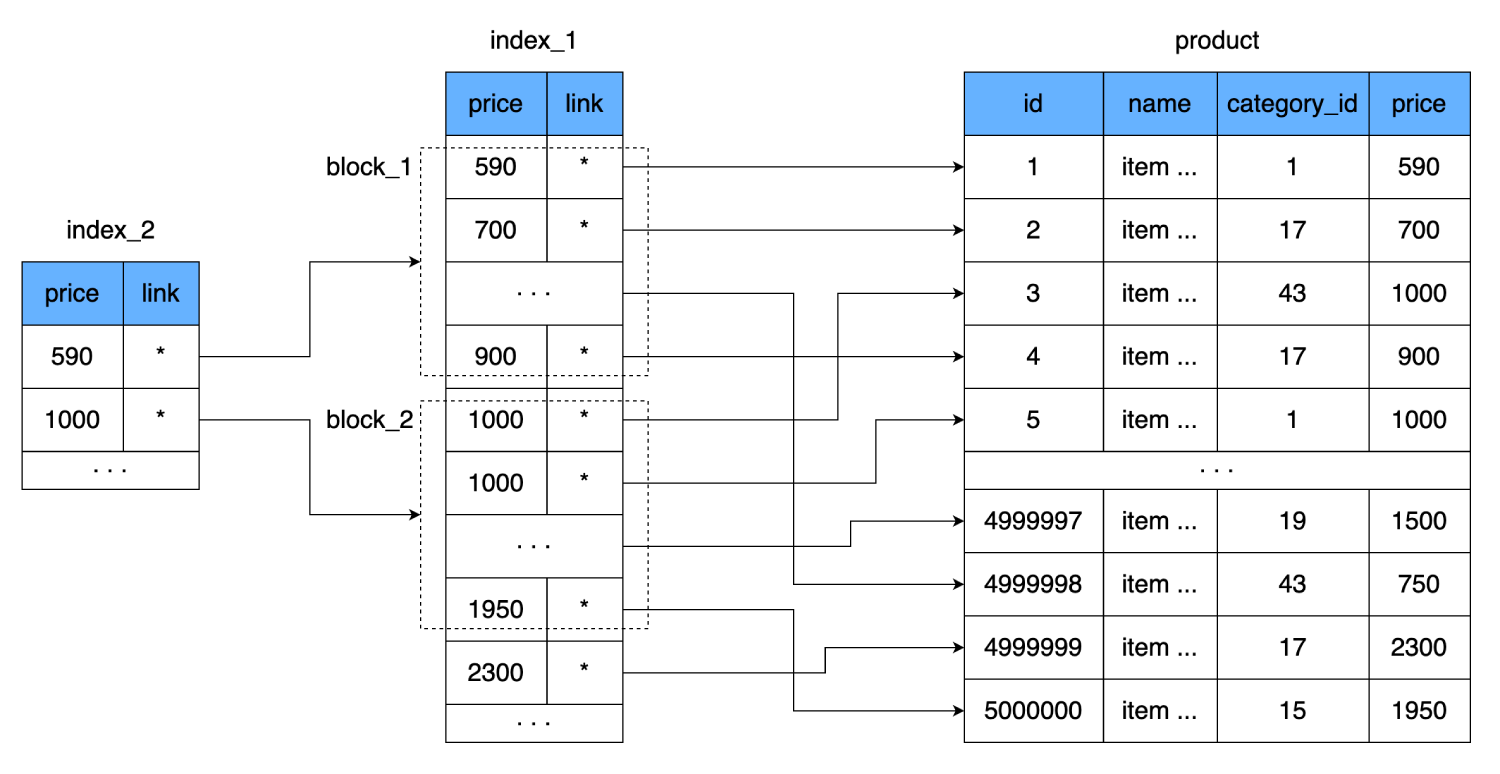
سيؤدي هذا إلى تقليل عدد القراءات. يأخذ سطر واحد من فهرسنا 8 بايت ، أي أنه يمكننا احتواء 2000 سطر من هذا القبيل في صفحة واحدة بحجم 16 كيلوبايت. سيحتوي الفهرس الجديد على رابط لمجموعة مؤلفة من 2000 سطر من المؤشر الأول والسعر الذي تبدأ منه هذه الكتلة. يأخذ أحد هذه السطور أيضًا 8 بايت ، لكن عددها ينخفض بشكل حاد: بدلاً من 500000 ، 250 فقط. بل إنها تتناسب مع مجموعة قرص صلب واحد. وبالتالي ، من أجل العثور على السعر المطلوب ، سنكون قادرين على تحديد الكتلة المكونة من 2000 خط بالضبط. وفي أسوأ الأحوال ، للعثور على نفس السجل ، نقوم بما يلي:
- لنقم بقراءة واحدة من الفهرس الجديد.
- بعد المرور عبر 250 سطرًا ، نجد رابطًا إلى كتلة البيانات من الفهرس الثاني.
- ضع في اعتبارك مجموعة واحدة تحتوي على 2000 صف مع الأسعار والارتباطات بالجدول الرئيسي.
- بعد التحقق من هذه الأسطر البالغ عددها 2000 سطر ، سنجد الانتقال المطلوب مرة واحدة ومرة أخرى عبر القرص لقراءة كتلة البيانات الأخيرة.
سنحصل على إجمالي 3 قفزات عنقودية.
لكن هذا المستوى سيتم ملؤه عاجلاً أم آجلاً بالكثير من البيانات. لذلك ، سيتعين علينا تكرار كل ما فعلناه ، وإضافة مستوى جديد مرارًا وتكرارًا. أي أننا بحاجة إلى بنية بيانات لتخزين الفهرس ، والتي ستضيف مستويات جديدة مع نمو حجم الفهرس وتوازن البيانات بينهما بشكل مستقل.
إذا قلبنا الجداول بحيث يكون الفهرس الأخير في الأعلى والجدول الرئيسي بالبيانات أدناه ، نحصل على هيكل مشابه جدًا للشجرة.
تعمل بنية البيانات B-tree على مبدأ مماثل ، لذلك تم اختيارها لهذه الأغراض.
ب- الأشجار في سطور
الفهارس الأكثر شيوعًا المستخدمة في MySQL هي الفهارس المرتبة B-tree (شجرة البحث المتوازنة) .
الفكرة العامة للشجرة B مشابهة لجداول الفهرس الخاصة بنا. يتم تخزين القيم بالترتيب وجميع أوراق الشجرة على نفس المسافة من الجذر.
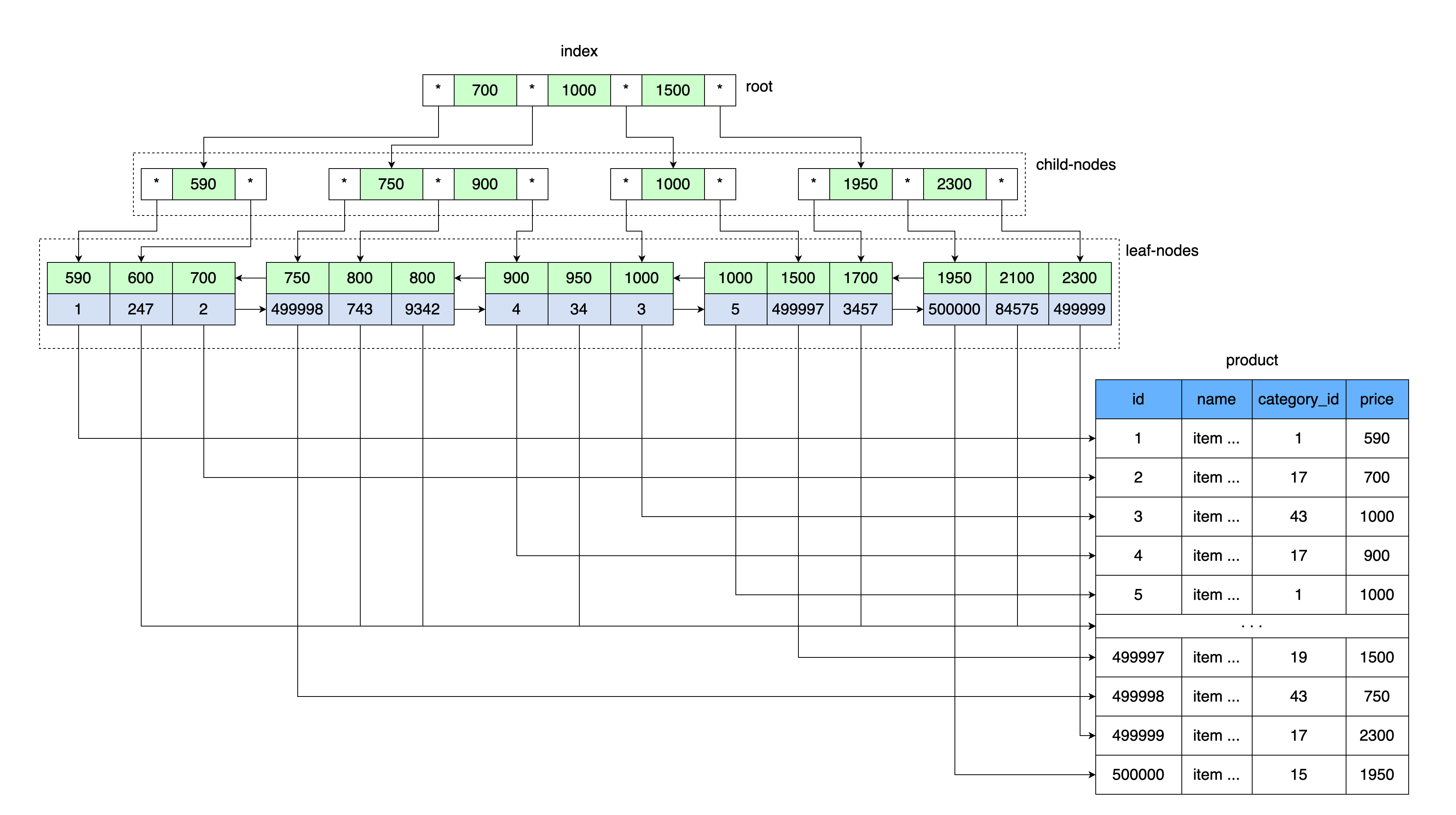
تمامًا كما قام جدولنا الذي يحتوي على فهرس بتخزين قيمة سعرية ورابط إلى كتلة بيانات ، والتي تحتوي على مجموعة من القيم بهذا السعر ، لذلك يتم تخزين قيمة السعر في جذر شجرة B ورابط لمنطقة الذاكرة على القرص.
أولاً ، تتم قراءة الصفحة التي تحتوي على جذر B-tree. علاوة على ذلك ، بعد إدخال نطاق المفاتيح ، يوجد مؤشر للعقدة الفرعية المطلوبة. تتم قراءة صفحة العقدة الفرعية ، حيث يتم أخذ الارتباط إلى ورقة البيانات من القيمة الأساسية ، ويتم قراءة الصفحة التي تحتوي على البيانات من هذا الارتباط.
B- شجرة في InnoDB
وبشكل أكثر تحديدًا ، يستخدم InnoDB بنية بيانات شجرة B +.
في كل مرة تنشئ فيها جدولًا ، تقوم تلقائيًا بإنشاء شجرة B + ، لأن MySQL تخزن مثل هذا الفهرس للمفاتيح الأساسية والثانوية.
تقوم المفاتيح الثانوية أيضًا بتخزين قيم المفتاح الأساسي (الكتلة) كمرجع لصف البيانات. وبالتالي ، فإن المفتاح الثانوي ينمو حسب حجم قيمة المفتاح الأساسي.
بالإضافة إلى ذلك ، تستخدم أشجار B + روابط إضافية بين العقد الفرعية ، مما يزيد من سرعة البحث في نطاق من القيم. اقرأ المزيد عن هيكل فهارس b + tree في InnoDB هنا .
تلخيص لما سبق
يوفر فهرس b-tree ميزة كبيرة عند البحث في البيانات عبر نطاق من القيم عن طريق تقليل كمية المعلومات المقروءة من القرص بشكل كبير. إنه يشارك ليس فقط أثناء البحث حسب الشرط ، ولكن أيضًا أثناء عمليات الفرز والضم والتجمعات. اقرأ كيف تستخدم MySQL الفهارس هنا .
معظم الاستعلامات إلى قاعدة البيانات هي مجرد استعلامات للعثور على المعلومات حسب القيمة أو من خلال مجموعة من القيم. لذلك ، في MySQL ، يعتبر الفهرس الأكثر استخدامًا هو فهرس b-tree.
أيضًا ، يساعد فهرس b-tree في استرداد البيانات. نظرًا لأنه يتم تخزين المفتاح الأساسي (الفهرس العنقودي) وقيمة العمود الذي تم بناء الفهرس غير العنقودي عليه (المفتاح الثانوي) في أوراق الفهرس ، لم يعد بإمكانك الوصول إلى الجدول الرئيسي لهذه البيانات وأخذها من الفهرس. وهذا ما يسمى بمؤشر التغطية. يمكنك العثور على مزيد من المعلومات حول الفهارس العنقودية وغير العنقودية في هذه المقالة .
يتم أيضًا تخزين الفهارس ، مثل الجداول ، على القرص وتشغل مساحة. في كل مرة يتم فيها إضافة معلومات إلى الجدول ، يجب تحديث الفهرس باستمرار ، لمراقبة صحة جميع الروابط بين العقد. يؤدي هذا إلى إنشاء عبء في كتابة المعلومات ، وهو العيب الرئيسي لفهارس b-tree. نحن نضحي بسرعة الكتابة لزيادة سرعة القراءة.
- MySQL . 3-
: ,
: 2018 - blog.jcole.us/innodb
- dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html