
لطالما كنت مفتونًا بإخفاقات النظام وغرائب سلوكهم ، خاصةً عندما يعملون في ظروفهم الطبيعية. لقد رأيت مؤخرًا إحدى شرائح العرض التقديمي لإيان جودفيلو ، والتي وجدتها مضحكة جدًا. تم تغذية الضوضاء البصرية العشوائية للشبكة العصبية المدربة ، وتعرفت عليها كأحد الأشياء التي تعرفها. تظهر هنا أسئلة كثيرة على الفور. هل سترى الشبكات العصبية المدربة المختلفة نفس الشيء؟ ما هو أقصى مستوى من الثقة في الشبكة العصبية بأن هذه الضوضاء العشوائية هي بالفعل كائن معروف؟ وماذا "ترى" الشبكة العصبية هناك؟
من فضولي حول هذا ، ولد هذا السجل. لحسن الحظ ، من السهل جدًا إجراء مثل هذه التجارب باستخدام PyTorch.... لتصور سبب تصنيف الشبكة العصبية للكائنات بطريقة معينة ، أستخدم إطار قابلية تفسير نموذج Captum . يمكن تنزيل الكود من Github .
أهمية الأسئلة
قد تسأل لماذا هذه الأسئلة مهمة. في كثير من الحالات ، لا يقوم المطورون ببناء نماذج من الصفر. يختارون المنصات والشبكات المدربة مسبقًا من حديقة الحيوانات النموذجية كنقاط انطلاق. هذا يوفر الوقت - لا تحتاج إلى جمع البيانات وإجراء تدريب أولي للشبكة العصبية. ومع ذلك ، فهذا يعني أيضًا أنه يمكن أن تنشأ مشاكل غير متوقعة في أماكن غير متوقعة. اعتمادًا على كيفية استخدام هذا النموذج ، يمكن أن تنشأ مشكلات أمنية في العملية.
نماذج سابقة التدريب
من السهل البدء في استخدام النماذج سابقة التدريب ويمكنها إرسال البيانات بسرعة من أجل التصنيف. في هذه الحالة ، لا تحتاج إلى تحديد النماذج وتدريبها - كل هذا تم القيام به من قبل ، وهم جاهزون للاستخدام فور النشر. يتم تدريب النماذج المُدربة مسبقًا من مكتبة Torchvision على مجموعة من الصور من قاعدة بيانات Imagenet ، مقسمة إلى 1000 فئة... من المهم أن نتذكر أن هذا التدريب تضمن تحديد كائن واحد في صورة ، وليس تحليل الصور المعقدة التي تحتوي على كائنات مختلفة. في الحالة الثانية ، يمكنك أيضًا الحصول على نتائج مثيرة للاهتمام ، لكن هذا موضوع مختلف تمامًا. يعد تنزيل النماذج التي تم اختبارها مسبقًا من مكتبة Torchvision أمرًا سهلاً للغاية. تحتاج فقط إلى استيراد النموذج المحدد عن طريق تعيين المعلمة المحددة مسبقًا على True. لقد قمت أيضًا بتضمين وضع التقييم في النماذج ، نظرًا لعدم وجود منحنى تعليمي أثناء الاختبارات.
أولاً ، لدي سطر من التعليمات البرمجية يختار استخدام cuda أو وحدة المعالجة المركزية ، اعتمادًا على ما إذا كانت وحدة معالجة الرسومات متاحة أم لا. لمثل هذه الاختبارات البسيطة ، لا يلزم استخدام وحدة معالجة الرسومات ، ولكن نظرًا لأن لديّ واحدًا ، فأنا أستخدمها.
device = "cuda" if torch.cuda.is_available() else "cpu"
import torchvision.models as models
vgg16 = models.vgg16(pretrained=True)
vgg16.eval()
vgg16.to(device)
يمكن العثور على قائمة بالموديلات التي تم اختبارها مسبقًا من Torchvision هنا . لم أرغب في استخدام جميع الشبكات العصبية المدربة مسبقًا ، فهذا بالفعل كثير جدًا. اخترت الخمسة التالية:
- vgg16
- ريسنت 18
- أليكسنت
- دينسنت
- نشأه
لم أستخدم أي منهجية خاصة لاختيار الشبكات العصبية. على سبيل المثال ، غالبًا ما يتم استخدام Vgg16 و Inception في أمثلة مختلفة ، وكلها مختلفة.
كيفية إنشاء الصور مع الضوضاء
سنحتاج إلى طريقة لإنشاء صور تحتوي تلقائيًا على ضوضاء يمكن تغذيتها للشبكات العصبية. للقيام بذلك ، استخدمت مجموعة من مكتبات Numpy و PIL ، وكتبت وظيفة صغيرة تُرجع صورة مليئة بالضوضاء العشوائية.
import numpy as np
from PIL import Image
def gen_image():
image = (np.random.standard_normal([256, 256, 3]) * 255).astype(np.uint8)
im = Image.fromarray(image)
return im
ينتهي بك الأمر بشيء مثل ما يلي:

تحويل الصور
بعد ذلك نحتاج إلى تحويل صورنا إلى موتر وتطبيعها. يمكن استخدام الكود التالي ليس فقط في الضوضاء العشوائية ، ولكن أيضًا على أي صورة نريد تغذية الشبكات العصبية المدربة مسبقًا (لهذا السبب يستخدم الرمز قيم Resize و CenterCrop).
def xform_image(image):
transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
new_image = transform(image).to(device)
new_image = new_image.unsqueeze_(0)
return new_imageنحصل على تنبؤات
بعد إعداد الصور المحولة ، من السهل الحصول على تنبؤات من النموذج المكشوف. في هذه الحالة ، من المفترض أن تقوم الدالة xform_image بإرجاع image_xform. في الكود الذي استخدمته للاختبار ، قمت بتقسيم العمل بين هاتين الوظيفتين ، لكن هنا جمعتهما معًا لسهولة الرجوع إليها. نحتاج أساسًا إلى تغذية الصورة المحولة إلى الشبكة ، وتشغيل وظيفة softmax ، واستخدام وظيفة topk للحصول على النتيجة ومعرف التسمية المتوقع للحصول على أفضل نتيجة.
with torch.no_grad():
vgg16_res = vgg16(image_xform)
vgg16_output = F.softmax(vgg16_res, dim=1)
vgg16score, pred_label_idx = torch.topk(vgg16_output, 1)
النتائج
حسنًا ، نرى الآن كيفية إنشاء صور مشوشة وإدخالها إلى شبكة مدربة مسبقًا. إذن ما هي النتائج؟ بالنسبة لهذا الاختبار ، قررت إنشاء 1000 صورة صاخبة ، وتشغيلها من خلال 5 شبكات مختارة مُدربة مسبقًا ، وحشوها في إطار بيانات Pandas لتحليلها بسرعة. كانت النتائج مثيرة للاهتمام وغير متوقعة إلى حد ما.
| vgg16 | ريسنت 18 | أليكسنت | دينسنت | نشأه | |
|---|---|---|---|---|---|
| العد | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 |
| يعني | 0.226978 | 0.328249 | 0.147289 | 0.409413 | 0.020204 |
| الأمراض المنقولة جنسيا | 0.067972 | 0.071808 | 0.038628 | 0.148315 | 0.016490 |
| دقيقة | 0.074922 | 0.127953 | 0.061019 | 0.139161 | 0.005963 |
| 25٪ | 0.178240 | 0.278830 | 0.120568 | 0.291042 | 0.011641 |
| 50٪ | 0.223623 | 0.324111 | 0.143090 | 0.387705 | 0.015880 |
| 75٪ | 0.270547 | 0.373325 | 0.171139 | 0.511357 | 0.022519 |
| ماكس | 0.438011 | 0.580559 | 0.328568 | 0.868025 | 0.198698 |
كما ترون ، قررت بعض الشبكات العصبية أن هذه الضوضاء تمثل في الواقع شيئًا بمستوى عالٍ من الثقة. بلغت ذروتها Resnet18 و densenet عند 50٪. كل هذا جيد وجيد ، ولكن ما الذي "تراه" هذه الشبكات بالضبط في الضوضاء؟ ومن المثير للاهتمام أن الشبكات المختلفة "وجدت" أشياء مختلفة هناك. رأت كل شبكة شيئًا مختلفًا. كانت Resnet18 متأكدة بنسبة 100٪ أنها كانت قناديل بحر ، في حين أن Inception ، على العكس من ذلك ، لم يكن لديها ثقة كبيرة في التنبؤات ، على الرغم من أنها شاهدت أشياء أكثر بكثير من أي شبكة أخرى.
Vgg16:
978
14
7
1
Resnet18:
1000
Alexnet:
942
58
Densenet:
893
37
33
20
16
1
Inception:
155
123
102
85
83
81
69
32
26
25
24
18
16
16
12
12
11
9
9
8
7
5
5
5
- 5
4
4
4
4
3
3
3
3
3
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
من أجل المتعة فقط ، قررت أن أرى نوع التوقيع الذي ستضعه Microsoft تحت صورة الضجيج ، والتي اقتربت من بداية هذا الإدخال. بالنسبة للاختبار ، قررت أن أذهب بأبسط طريقة واستخدمت PowerPoint من Office 365. وكانت النتيجة مثيرة للاهتمام لأنه على عكس نماذج التخيل التي تحاول التعرف على كائن واحد ، يحاول PowerPoint التعرف على كائنات متعددة من أجل إنشاء وصف دقيق للصورة.
الصورة تظهر فيل ، الناس ، كبير ، الكرة.
النتيجة لم تخذلني. من وجهة نظري ، تم التعرف على صورة الضوضاء على أنها سيرك.
توقعات - وجهات نظر
يقودنا هذا إلى سؤال آخر - ما الذي تراه الشبكة العصبية والذي يجعلها تعتقد أن الضوضاء هي كائن؟ في بحثنا عن إجابة ، يمكننا استخدام أداة تفسير نموذجية تتيح لنا فهم ما "تراه" الشبكة تقريبًا. Captum هو إطار نموذجي لتفسير PyTorch. لم أفعل أي شيء مميز هنا ، لقد استخدمت للتو الكود من الدروس على موقعهم على الإنترنت. لقد أضفت للتو المعلمة inner_batch_size بقيمة 50 ، لأنه بدونها نفدت ذاكرة GPU بسرعة كبيرة.
بالنسبة للعروض ، استخدمت إسناد قائم على التدرج وإسناد قائم على الانسداد. باستخدام هذه التصورات ، نحاول فهم ما هو مهم للمصنف وبالتالي "رؤية" ما تراه الشبكة. كما أنني استخدمت نموذج resnet الذي تم تدريبه مسبقًا ، ومع ذلك يمكنك تغيير الكود واستخدام أي نماذج أخرى مُدربة مسبقًا.
قبل الانتقال إلى الضوضاء ، التقطت صورة البابونج كدليل على عملية التقديم ، حيث يسهل التعرف على علاماتها.
result = resnet18(image_xform)
result = F.softmax(result, dim=1)
score, pred_label_idx = torch.topk(result, 1)
integrated_gradients = IntegratedGradients(resnet18)
attributions_ig = integrated_gradients.attribute(image_xform, target=pred_label_idx,
internal_batch_size=50, n_steps=200)
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(image_xform, n_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx, internal_batch_size=50)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)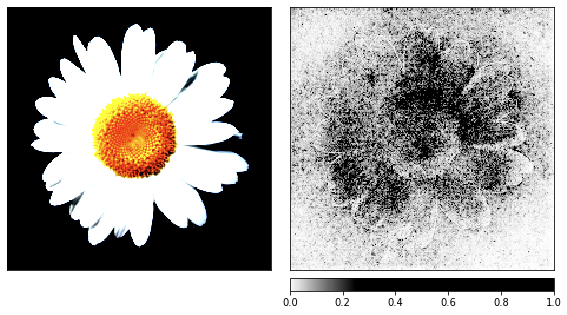
occlusion = Occlusion(resnet18)
attributions_occ = occlusion.attribute(image_xform,
strides = (3, 8, 8),
target=pred_label_idx,
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
show_colorbar=True,
outlier_perc=2,
)

تصور الضوضاء
لقد أنشأنا الصور السابقة بناءً على البابونج ، والآن حان الوقت لنرى كيف تعمل الأشياء مع الضوضاء العشوائية.
أنا أستخدم شبكة resnet18 سابقة التدريب وبهذه الصورة تكون متأكدة بنسبة 40٪ من أنها ترى قناديل البحر. لن أكرر الكود ، كود التقديم هو نفس الرمز المذكور أعلاه.


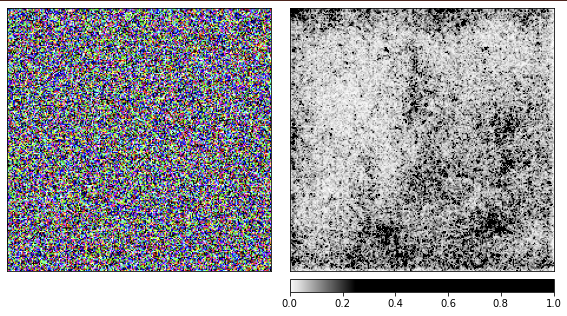

من خلال التصورات ، من الواضح أننا نحن البشر لن نكون قادرين على فهم سبب رؤية الشبكة لقنديل البحر هنا. تم وضع علامة على بعض مناطق الصورة على أنها أكثر أهمية ، لكنها ليست محددة على الإطلاق كما رأينا في مثال البابونج. على عكس البابونج ، فإن قنديل البحر غير متبلور ويختلف في مستوى الشفافية.
قد تتساءل كيف ستبدو معالجة صورة قنديل البحر الحقيقية؟ تم نشر الكود الخاص بي على Github ، وسيكون من السهل الحصول على إجابة على هذا السؤال بمساعدته.
خاتمة
بناءً على هذا التسجيل ، من السهل معرفة مدى سهولة خداع الشبكات العصبية عن طريق تزويدها بمدخلات غير متوقعة. ولحسن الحظ ، سنقول إنهم قاموا بعملهم وقدموا أفضل نتيجة ممكنة. يمكن أيضًا أن يُلاحظ من نتائج العمل أنه في مثل هذه الحالات لا يكفي مجرد تصفية الخيارات بثقة منخفضة ، لأن بعض الخيارات لديها ثقة عالية إلى حد ما. نحن بحاجة إلى أن نراقب عن كثب المواقف التي تفشل فيها أنظمة العالم الحقيقي بسهولة. لا ينبغي أن نفاجأ بدخول البيانات غير المتوقعة إلى النظام - وهذا ما يفعله خبراء الأمن منذ بعض الوقت.