
أصبحت هذه البحيرات (بحيرات البيانات ) في الواقع معيارًا للشركات والشركات التي تحاول استخدام جميع المعلومات المتاحة لها. غالبًا ما تكون المكونات مفتوحة المصدر خيارًا جذابًا عند تطوير بحيرات البيانات الكبيرة. سنلقي نظرة على الأنماط المعمارية العامة اللازمة لإنشاء بحيرة بيانات للحلول السحابية أو الهجينة ، وسنسلط الضوء أيضًا على عدد من التفاصيل الهامة التي يجب الانتباه إليها عند تنفيذ المكونات الرئيسية.
تصميم تدفق البيانات
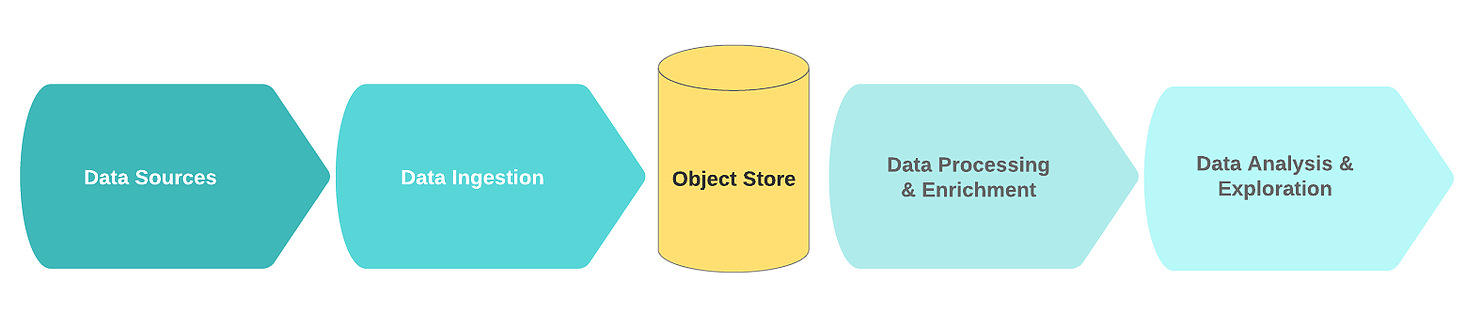
يتضمن تدفق بحيرة البيانات المنطقية النموذجية الكتل الوظيفية التالية:
- مصادر البيانات؛
- جار استقبال البيانات؛
- عقدة التخزين
- معالجة البيانات وإثرائها ؛
- تحليل البيانات.
في هذا السياق ، تكون مصادر البيانات عادةً عبارة عن تدفقات أو مجموعات من بيانات الأحداث الأولية (على سبيل المثال ، السجلات ، والنقرات ، والقياس عن بُعد لإنترنت الأشياء ، والمعاملات).
الميزة الرئيسية لهذه المصادر هي أن البيانات الأولية مخزنة في شكلها الأصلي. تتكون الضوضاء في هذه البيانات عادةً من سجلات مكررة أو غير كاملة مع حقول زائدة عن الحاجة أو خاطئة.
في مرحلة الاستيعاب ، تأتي البيانات الأولية من مصدر بيانات واحد أو أكثر. غالبًا ما يتم تنفيذ آلية الاستقبال في شكل صف واحد أو أكثر من قوائم انتظار الرسائل مع مكون بسيط يهدف إلى التنظيف الأساسي وحفظ البيانات. من أجل بناء بحيرة بيانات فعالة وقابلة للتطوير ومتسقة ، يوصى بالتمييز بين تنظيف البيانات البسيط ومهام إثراء البيانات الأكثر تعقيدًا. إحدى القواعد الأساسية الجيدة هي أن مهام التنظيف تتطلب بيانات من مصدر واحد داخل نافذة منزلقة.
نص مخفي
( - , ..). , .
, , , 60 , . , (, 24 ), .
, , , 60 , . , (, 24 ), .
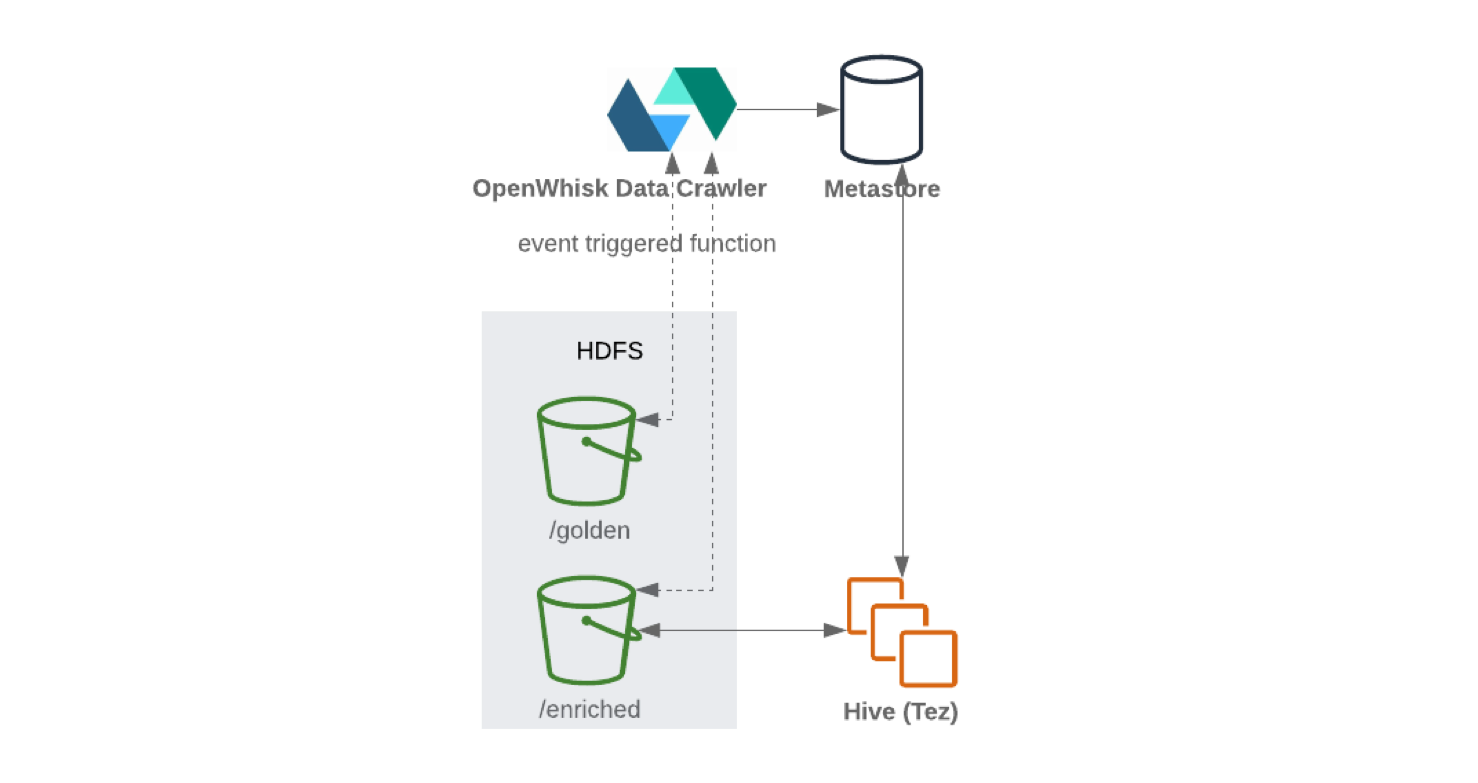
بعد استلام البيانات وتنظيفها ، يتم تخزينها في نظام الملفات الموزعة (لتحسين التسامح مع الخطأ). غالبًا ما تتم كتابة البيانات بتنسيق جدولي. عندما تتم كتابة معلومات جديدة في عقدة التخزين ، يمكن تحديث كتالوج البيانات الذي يحتوي على المخطط والبيانات الوصفية باستخدام زاحف غير متصل بالإنترنت. عادة ما يتم تشغيل الزاحف بواسطة حدث ، على سبيل المثال ، عند وصول كائن جديد إلى التخزين. عادة ما يتم دمج المستودعات مع كتالوجاتهم. يقومون بإلغاء تحميل المخطط الأساسي بحيث يمكن الوصول إلى البيانات.
ثم تذهب البيانات إلى منطقة خاصة مخصصة لـ "بيانات الذهب". من الآن فصاعدًا ، أصبحت البيانات جاهزة للتخصيب من خلال عمليات أخرى.
نص مخفي
, , .
أثناء عملية التخصيب ، يتم أيضًا تغيير البيانات وتنظيفها وفقًا لمنطق العمل. ونتيجة لذلك ، يتم تخزينها في تنسيق منظم في مستودع بيانات أو قاعدة بيانات تُستخدم لاسترداد المعلومات أو التحليلات أو نموذج التدريب بسرعة.
أخيرًا ، استخدام البيانات هو التحليلات والبحث. هذا هو المكان الذي يتم فيه تحويل المعلومات المستخرجة إلى أفكار تجارية من خلال التصورات ولوحات المعلومات والتقارير. تعد هذه البيانات أيضًا مصدرًا للتنبؤ باستخدام التعلم الآلي ، مما يساعد على اتخاذ قرارات أفضل.
مكونات المنصة
تتطلب البنية التحتية السحابية لبحيرة البيانات طبقة قوية ، وفي حالة الأنظمة السحابية المختلطة ، طبقة تجريد موحدة يمكنها المساعدة في نشر وتنسيق وتشغيل المهام الحسابية دون قيود موفري API.
Kubernetes هي أداة رائعة لهذه الوظيفة. يسمح لك بنشر وتنظيم وتشغيل مختلف الخدمات والمهام الحسابية لبحيرة البيانات بطريقة موثوقة وفعالة من حيث التكلفة. يوفر واجهة برمجة تطبيقات موحدة تعمل في أماكن العمل وفي أي سحابة عامة أو خاصة.
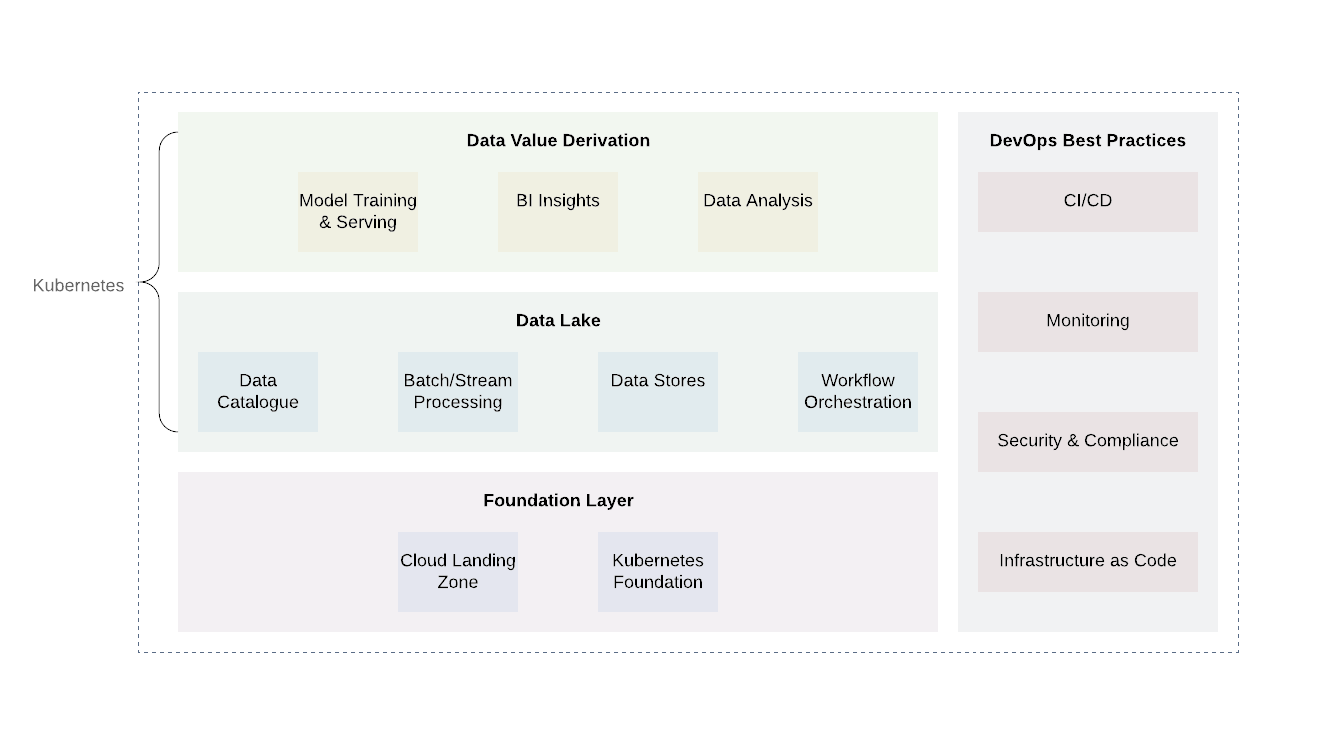
يمكن تقسيم المنصة تقريبًا إلى عدة طبقات. الطبقة الأساسية هي المكان الذي ننشر فيه Kubernetes أو ما يعادله. يمكن أيضًا استخدام الطبقة الأساسية للتعامل مع المهام الحسابية خارج مجال بحيرة البيانات. عند استخدام موفري السحابة ، سيكون من الواعد استخدام الممارسات الراسخة بالفعل لموفري السحابة (التسجيل والتدقيق ، وتصميم الحد الأدنى من الوصول ، ومسح الثغرات الأمنية وإعداد التقارير ، وهندسة الشبكة ، وبنية IAM ، وما إلى ذلك) وهذا سيحقق المستوى الضروري من الأمان والامتثال للمتطلبات الأخرى ...
هناك مستويان إضافيان فوق المستوى الأساسي - بحيرة البيانات نفسها ومستوى إخراج القيمة. هاتان الطبقتان مسؤولتان عن جوهر منطق الأعمال بالإضافة إلى معالجة البيانات. في حين أن هناك العديد من التقنيات لهاتين المستويين ، سيثبت Kubernetes مرة أخرى أنه خيار جيد نظرًا لمرونته في دعم مجموعة متنوعة من مهام الحوسبة.
تشمل طبقة بحيرة البيانات جميع الخدمات الضرورية للاستلام ( كافكا ، كافكا كونيكت ) ، التصفية ، الإثراء والمعالجة ( Flink و Spark ) ، إدارة سير العمل ( تدفق الهواء ). بالإضافة إلى ذلك ، يتضمن تخزين البيانات وأنظمة الملفات الموزعة ( HDFS) وكذلك قواعد بيانات RDBMS و NoSQL .
المستوى الأعلى هو الحصول على قيم البيانات. في الأساس ، هذا هو مستوى الاستهلاك. يتضمن مكونات مثل أدوات التصور لفهم ذكاء الأعمال وأدوات التنقيب عن البيانات ( Jupyter Notebooks ). عملية أخرى مهمة تحدث على هذا المستوى هي التعلم الآلي باستخدام عينات التدريب من بحيرة البيانات.
من المهم أن نلاحظ أن جزءًا لا يتجزأ من كل بحيرة بيانات هو تنفيذ ممارسات DevOps الشائعة: البنية التحتية ككود وقابلية المراقبة والتدقيق والأمان. إنها تلعب دورًا مهمًا في حل المشكلات اليومية ويجب تطبيقها على كل مستوى لضمان التوحيد والأمان وسهولة الاستخدام.
, — , opensource-.
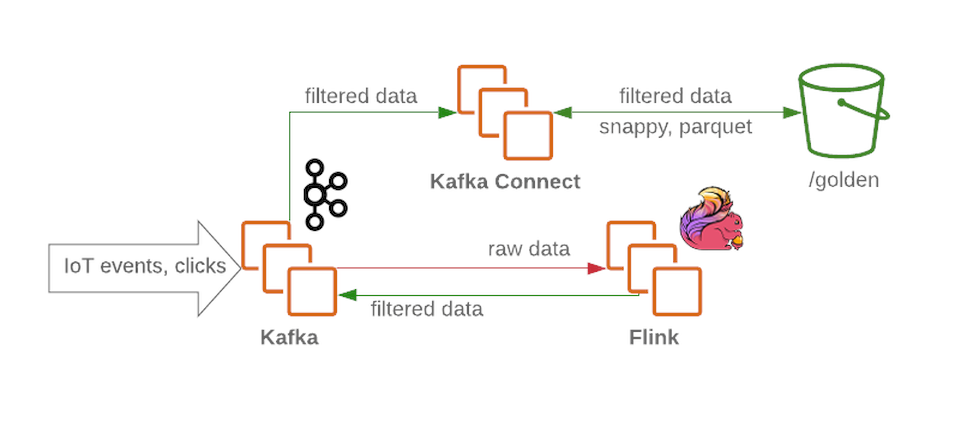
ستتلقى كتلة كافكا رسائل غير مصفاة وغير معالجة وستعمل كعقدة استقبال في بحيرة البيانات. يوفر كافكا إنتاجية عالية للرسالة بطريقة موثوقة. تحتوي المجموعة عادةً على عدة أقسام للبيانات الأولية والمعالجة (للدفق) والبيانات غير المسلمة أو المشوهة. يقبل
Flink رسالة من عقدة بيانات خام من كافكا ، ويقوم بتصفية البيانات وإثراء البيانات مسبقًا إذا لزم الأمر. ثم يتم تمرير البيانات مرة أخرى إلى كافكا (في قسم منفصل للبيانات المصفاة والغنية). في حالة حدوث فشل ، أو عندما يتغير منطق العمل ، يمكن استدعاء هذه الرسائل مرة أخرى ، لأن التي تم حفظها فيهاكافكا . هذا حل شائع لعمليات التدفق. وفي الوقت نفسه ، يكتب Flink جميع الرسائل المشوهة إلى قسم آخر لمزيد من التحليل.
باستخدام Kafka Connect ، نحصل على القدرة على حفظ البيانات في الخلفية المطلوبة لتخزين البيانات (مثل منطقة الذهب في HDFS ). يتوسع كافكا كونيكت بسهولة وسيساعدك على زيادة عدد العمليات المتزامنة بسرعة عن طريق زيادة الإنتاجية في ظل عبء العمل الثقيل:
عند الكتابة من Kafka Connect إلى HDFS ، يوصى بإجراء تقسيم المحتوى لمعالجة البيانات بكفاءة (كلما قلت البيانات المطلوب مسحها ، قل عدد الطلبات والاستجابات). بعد كتابة البيانات إلى HDFS ، ستعمل الوظيفة التي لا تحتوي على خادم (مثل OpenWhisk أو Knative ) على تحديث مخزن البيانات الوصفية ومعلمات المخطط بشكل دوري. نتيجة لذلك ، يمكن الوصول إلى المخطط المحدث من خلال واجهة تشبه SQL (على سبيل المثال ، Hive أو Presto ).
يمكن استخدام Apache Airflow في تدفقات البيانات اللاحقة والتحكم في عملية ETL . يسمح للمستخدمين بتشغيل خطوط متعددة الخطوات لمعالجة البيانات باستخدام كائنات Python و Directed Acyclic Graph ( DAG ). يمكن للمستخدم تحديد التبعيات ، وبرمجة العمليات المعقدة ، وتتبع المهام من خلال واجهة رسومية. يمكن لـ Apache Airflow أيضًا التعامل مع جميع البيانات الخارجية. على سبيل المثال ، لتلقي البيانات من خلال واجهة برمجة تطبيقات خارجية وتخزينها في تخزين دائم. شرارة مدعومة من Apache Airflow
من خلال مكون إضافي خاص ، يمكنه إثراء البيانات الأولية التي تمت تصفيتها بشكل دوري وفقًا لأهداف العمل ، وإعداد البيانات للبحث بواسطة علماء البيانات ومحللي الأعمال. يمكن لعلماء البيانات استخدام JupyterHub لإدارة العديد من دفاتر Jupyter . لذلك ، يجدر استخدام Spark لتكوين واجهات متعددة المستخدمين للعمل مع البيانات وجمعها وتحليلها.

للتعلم الآلي ، يمكنك استخدام أطر عمل مثل Kubeflow ، والاستفادة من قابلية تطوير Kubernetes . يمكن إرجاع نماذج التدريب الناتجة إلى النظام.
إذا قمنا بتجميع اللغز معًا ، فسنحصل على شيء مثل هذا:

التفوق التشغيلي
قلنا أن مبادئ DevOps و DevSecOps عناصر أساسية في أي بحيرة البيانات وينبغي أبدا التغاضي. مع وجود قدر كبير من القوة ، يأتي الكثير من المسؤولية ، خاصةً عندما تكون جميع البيانات المهيكلة وغير المهيكلة حول عملك في مكان واحد.
ستكون المبادئ الأساسية كما يلي:
- تقييد وصول المستخدم ؛
- المراقبة ؛
- تشفير البيانات؛
- حلول بدون خادم
- استخدام عمليات CI / CD.
مبادئ DevOps و DevSecOps عناصر أساسية في أي بحيرة البيانات وينبغي أبدا التغاضي. مع قدر كبير من القوة ، يأتي الكثير من المسؤولية ، خاصة عندما تكون جميع البيانات المنظمة وغير المهيكلة حول عملك في مكان واحد.
تتمثل إحدى الطرق الموصى بها في السماح بالوصول إلى خدمات معينة فقط عن طريق تعيين الحقوق المناسبة ، ورفض وصول المستخدم المباشر حتى لا يتمكن المستخدمون من تغيير البيانات (ينطبق هذا أيضًا على الأوامر). المراقبة الكاملة من خلال إجراءات التسجيل مهمة أيضًا لحماية البيانات.
تشفير البيانات آلية أخرى لحماية البيانات. يمكن تشفير البيانات المخزنة باستخدام نظام إدارة المفاتيح ( KMS). سيؤدي ذلك إلى تشفير نظام التخزين والحالة الحالية. في المقابل ، يمكن إجراء تشفير الإرسال باستخدام شهادات لجميع الواجهات ونقاط النهاية للخدمات مثل كافكا و ElasticSearch .
وفي حالة محركات البحث التي قد لا تمتثل لسياسة الأمان ، فمن الأفضل إعطاء الأفضلية للحلول التي لا تحتوي على خادم . من الضروري أيضًا التخلي عن النشر اليدوي والتغييرات الظرفية في أي مكون من مكونات بحيرة البيانات ؛ يجب أن يأتي كل تغيير من التحكم في المصدر ويخضع لسلسلة من اختبارات CI قبل نشره في بحيرة بيانات المنتج ( اختبار الدخان ، الانحدار ، إلخ).
الخاتمة
لقد قمنا بتغطية مبادئ التصميم الأساسية لهندسة بحيرة البيانات مفتوحة المصدر. كما يحدث غالبًا ، لا يكون اختيار النهج واضحًا دائمًا وقد تمليه متطلبات العمل والميزانية والوقت المختلفة. لكن الاستفادة من التكنولوجيا السحابية لإنشاء بحيرات البيانات ، سواء كانت حلاً مختلطًا أو سحابيًا بالكامل ، هو اتجاه ناشئ في الصناعة. ويرجع ذلك إلى العدد الهائل من الفوائد التي يقدمها هذا النهج. يتمتع بمستوى عالٍ من المرونة ولا يقيد التطوير. من المهم أن نفهم أن نموذج العمل المرن يجلب فوائد اقتصادية كبيرة ، مما يسمح لك بدمج العمليات المطبقة وتوسيع نطاقها وتحسينها.