
هذا النص هو ترجمة لمنشور المدونة Multi-Target في Albumentations بتاريخ 27 يوليو 2020. المؤلف موجود على Habré ، لكنني كنت كسولًا جدًا في ترجمة النص إلى الروسية. وهذه الترجمة تمت بناء على طلبه.
لقد قمت بترجمة كل ما أستطيع إلى اللغة الروسية ، لكن بعض المصطلحات الفنية باللغة الإنجليزية تبدو طبيعية أكثر. لقد تركوا في هذا الشكل. إذا خطر ببالك ترجمة مناسبة - علق عليها وصححها.
تكبير الصورة هي تقنية تنظيم مفسرة. تقوم بتحويل البيانات ذات العلامات الموجودة إلى بيانات جديدة ، وبالتالي زيادة حجم مجموعة البيانات.

يمكنك استخدام Albumentations في PyTorch أو Keras أو Tensorflow أو أي إطار عمل آخر يمكنه معالجة صورة كمصفوفة متداخلة.
تعمل المكتبة بشكل أفضل مع المهام القياسية للتصنيف والتجزئة والكشف عن الكائنات والنقاط الرئيسية. تكون المشكلات الأقل شيوعًا عندما لا يحتوي كل عنصر من عناصر عينة التدريب على عنصر واحد ، ولكن العديد من الكائنات المختلفة.
لهذا النوع من المواقف ، تمت إضافة وظيفة الأهداف المتعددة.
المواقف التي قد يكون فيها هذا مفيدًا:
- شبكات السيامي
- معالجة الإطارات بالفيديو
- مهام Image2image
- Multilabel semantic segmentation
- Instance segmentation
- Panoptic segmentation
- Kaggle . Kaggle Grandmaster, Kaggle Masters, Kaggle Expert.
- , Deepfake Challenge , Albumentations .
- PyTorch ecosystem
- 5700 GitHub.
- 80 . .
على مدى السنوات الثلاث الماضية ، عملنا على تحسين الوظائف والأداء.
في الوقت الحالي ، نركز على التوثيق والبرامج التعليمية.
مرة واحدة على الأقل في الأسبوع ، يطلب المستخدمون إضافة دعم التحويل لأقنعة التجزئة المتعددة
لقد كان لدينا لفترة طويلة.
في هذه المقالة ، سنشارك أمثلة حول كيفية العمل مع أهداف متعددة في الألبومات.
السيناريو 1: صورة واحدة ، قناع واحد
حالة الاستخدام الأكثر شيوعًا هي تجزئة الصورة. لديك صورة وقناع. تريد تطبيق مجموعة من التحويلات المكانية عليهم ، ويجب أن يكونوا نفس المجموعة.
في هذا الكود ، نستخدم HorizontalFlip و ShiftScaleRotate .
import albumentations as A
transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(border_mode=cv2.BORDER_CONSTANT,
scale_limit=0.3,
rotate_limit=(10, 30),
p=0.5)
], p=1)
transformed = transform(image=image, mask=mask)
image_transformed = transformed['image']
mask_transformed = transformed['mask']-> رابط إلى gistfile1.py

السيناريو 2: صورة واحدة وأقنعة متعددة

بالنسبة لبعض المهام ، قد يكون لديك عدة تسميات تتوافق مع نفس البكسل.
دعنا نطبق HorizontalFlip و GridDistortion و RandomCrop .
import albumentations as A
transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.GridDistortion(p=0.5),
A.RandomCrop(height=1024, width=1024, p=0.5),
], p=1)
transformed = transform(image=image, masks=[mask, mask2])
image_transformed = transformed['image']
mask_transformed = transformed['masks'][0]
mask2_transformed = transformed['masks'][1]-> رابط إلى gistfile1.py
السيناريو 3: صور وأقنعة ونقاط مفاتيح وصناديق متعددة

يمكنك تطبيق تحويلات مكانية على أهداف متعددة.
في هذا المثال ، لدينا صورتان ، وقناعان ، ومربعان ، ومجموعتان من نقاط المفاتيح.
دعنا نطبق تسلسل HorizontalFlip و ShiftScaleRotate .
import albumentations as A
transform = A.Compose([A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(border_mode=cv2.BORDER_CONSTANT, scale_limit=0.3, p=0.5)],
bbox_params=albu.BboxParams(format='pascal_voc', label_fields=['category_ids']),
keypoint_params=albu.KeypointParams(format='xy'),
additional_targets={
"image1": "image",
"bboxes1": "bboxes",
"mask1": "mask",
'keypoints1': "keypoints"},
p=1)
transformed = transform(image=image,
image1=image1,
mask=mask,
mask1=mask1,
bboxes=bboxes,
bboxes1=bboxes1,
keypoints=keypoints,
keypoints1=keypoints1,
category_ids=["face"]
)
image_transformed = transformed['image']
image1_transformed = transformed['image1']
mask_transformed = transformed['mask']
mask1_transformed = transformed['mask1']
bboxes_transformed = transformed['bboxes']
bboxes1_transformed = transformed['bboxes1']
keypoints_transformed = transformed['keypoints']
keypoints1_transformed = transformed['keypoints1']
→ رابط إلى gistfile1.py

س: هل من الممكن العمل بأكثر من صورتين؟
ج: يمكنك التقاط العديد من الصور كما تريد.
س: هل يجب أن يكون عدد الصور والأقنعة والمربعات ونقاط المفاتيح هو نفسه؟
ج: يمكنك الحصول على صور N وأقنعة M ونقاط مفاتيح K ومربعات B. يمكن أن تكون N و M و K و B مختلفة.
س: هل هناك حالات لا تعمل فيها وظيفة الأهداف المتعددة أو لا تعمل كما هو متوقع؟
ج: بشكل عام ، يمكنك استخدام أهداف متعددة لمجموعة من الصور ذات الأحجام المختلفة. بعض التحولات تعتمد على المدخلات. على سبيل المثال ، لا يمكنك قص محصول أكبر من الصورة نفسها. مثال آخر: MaskDropout ، والتي قد تعتمد على القناع الأصلي. كيف سيتصرف عندما يكون لدينا مجموعة من الأقنعة غير واضح. من الناحية العملية ، فهي نادرة للغاية.
س: كم عدد التحولات التي يمكنك دمجها معًا؟
ج : يمكنك دمج التحولات في خط أنابيب معقد بعدة طرق مختلفة.
تحتوي المكتبة على أكثر من 30 تحويلًا مكانيًا . كلهم يدعمون الصور والأقنعة ، ومعظم صناديق الدعم ونقاط المفاتيح.
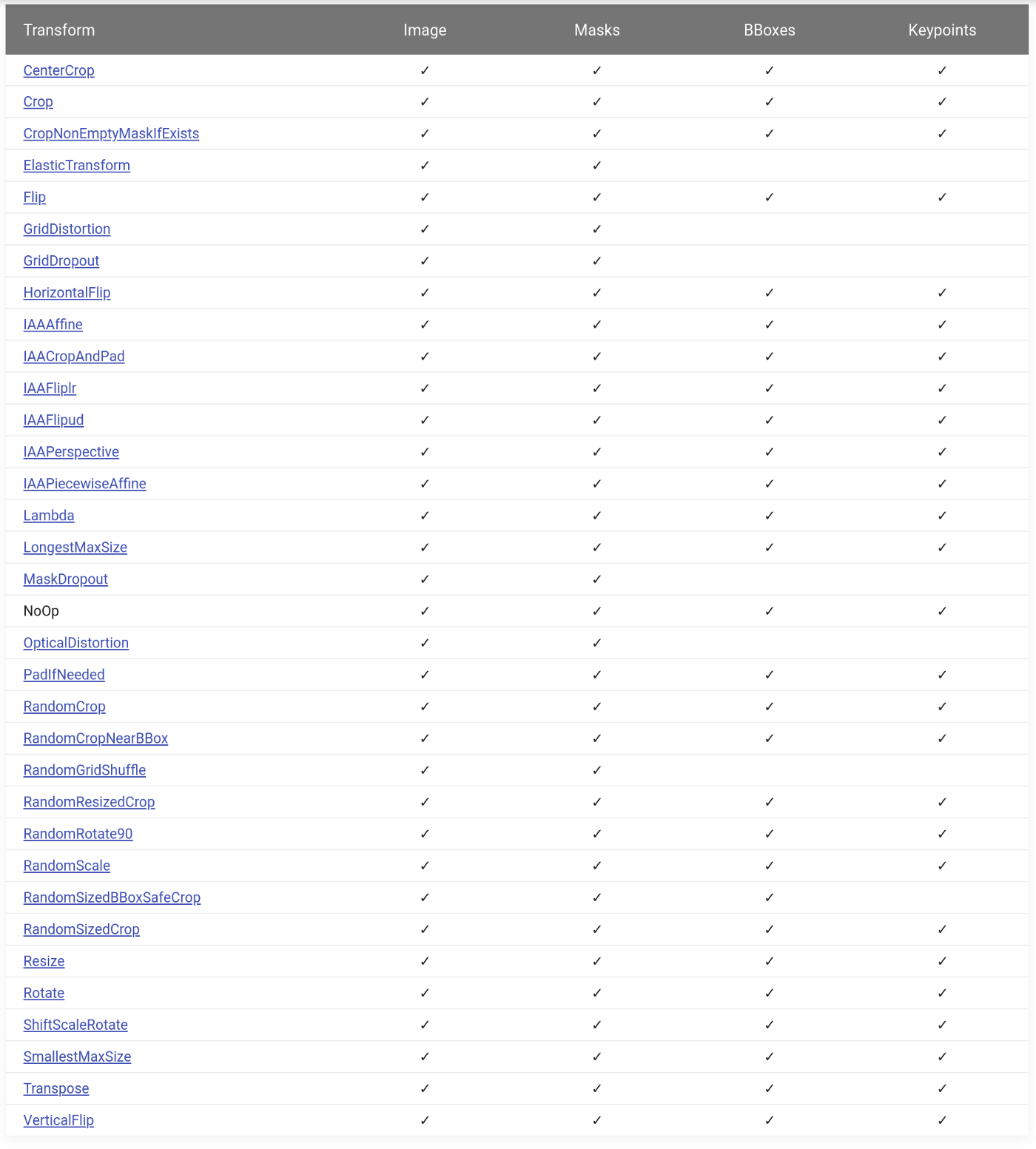
→ ارتباط بالمصدر
يمكن دمجها مع أكثر من 40 تحويلاً تغير قيم البكسل للصورة. على سبيل المثال: RandomBrightnessContrast و Blur، أو شيء أكثر غرابة مثل RandomRain .
وثائق اضافية
- ورقة تحويل كاملة
- تحويلات القناع لمهام التجزئة
- زيادة الكشف عن الكائنات المربعات المحيطة
- تحويلات النقطة الرئيسية
- التحويل المتزامن للأقنعة والمربعات ونقاط المفاتيح
- بأي احتمالية يتم تطبيق التحولات في خط الأنابيب؟
خاتمة
العمل في مشروع مفتوح المصدر صعب ، لكنه مثير للغاية. أود أن أشكر فريق التطوير:
وجميع المساهمين الذين ساعدوا في إنشاء المكتبة ونقلها إلى مستواها الحالي.