لذلك ، داخل كل عملية منفصلة لا توجد مشاكل "غريبة" تقليدية مع تنفيذ الكود المتوازي ، والأقفال ، وظروف السباق ، ... وتطوير نظام إدارة قواعد البيانات نفسه ممتع وبسيط.
لكن نفس البساطة تفرض قيودًا كبيرة. نظرًا لوجود مؤشر ترابط عامل واحد فقط داخل العملية ، فلا يمكنه استخدام أكثر من نواة وحدة معالجة مركزية واحدة لتنفيذ طلب - مما يعني أن سرعة الخادم تعتمد بشكل مباشر على تردد وبنية نواة منفصلة.
في عصرنا المنتهي "سباق الميجاهرتز" والأنظمة المنتصرة متعددة النواة والمعالجات ، يعتبر هذا السلوك ترفاً غير مقبول وإسرافًا. لذلك ، بدءًا من PostgreSQL 9.6 ، عند معالجة استعلام ، يمكن تنفيذ بعض العمليات من خلال عدة عمليات في وقت واحد.
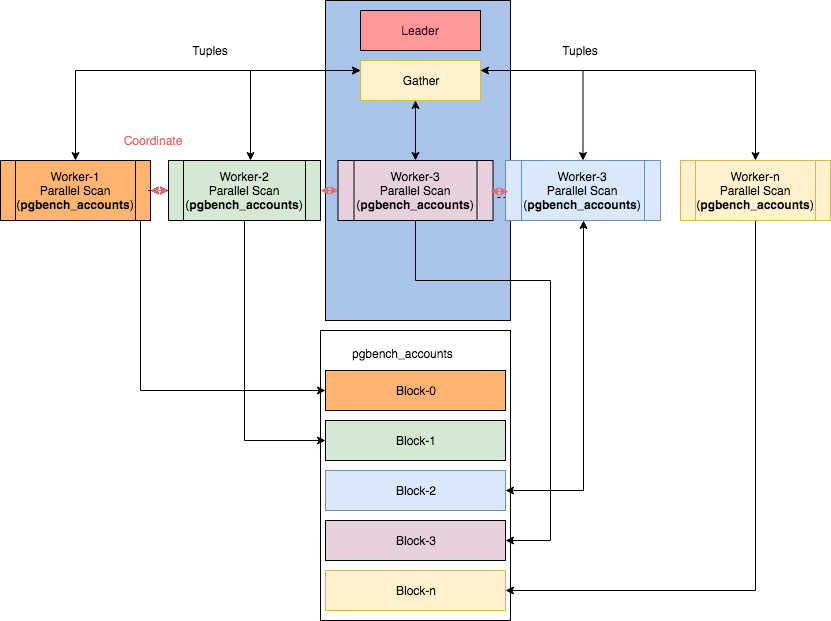
يمكن العثور على بعض العقد المتوازية في مقالة "Parallelism in PostgreSQL" التي كتبها إبرار أحمد ، حيث تم أخذ هذه الصورة.ومع ذلك ، في هذه الحالة يصبح ... قراءة الخطط ليست تافهة.
باختصار ، يبدو التسلسل الزمني لتنفيذ التنفيذ الموازي لعمليات الخطة كما يلي:
- 9.6 - الوظائف الأساسية: مسح التسلسل ، الانضمام ، التجميع
- 10 - مسح الفهرس (لـ btree) ، مسح كومة الصور النقطية ، ربط التجزئة ، دمج الانضمام ، مسح الاستعلام الفرعي
- 11 - عمليات المجموعة : Hash Join with Shared Hh table، Append (UNION)
- 12 - إحصائيات أساسية لكل عامل على عقد الخطة
- 13- إحصائيات تفصيلية لكل عامل
لذلك ، إذا كنت تستخدم أحد أحدث إصدارات PostgreSQL ، فإن فرص رؤيته في الخطة
Parallel ...عالية جدًا. ويأتي معه و ...
الشذوذ بمرور الوقت
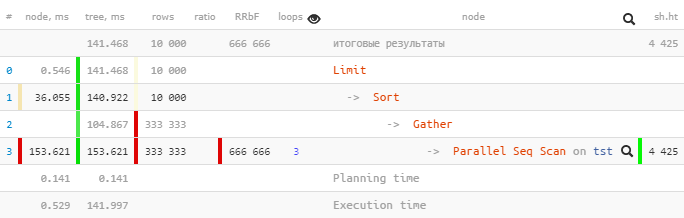
لنأخذ خطة من PostgreSQL 9.6 :
[انظر إلىشرح.tensor.ru]
تم
Parallel Seq Scanتنفيذ واحدة فقط 153.621 مللي ثانية داخل شجرة فرعية ، Gatherومع جميع العقد الفرعية - فقط 104.867 مللي ثانية.
كيف ذلك؟ هل أصبح الوقت الإجمالي "للطابق العلوي" أقل؟ ..
دعنا نلقي نظرة على
Gatherالعقدة بمزيد من التفصيل:
Gather (actual time=0.969..104.867 rows=333333 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4425Workers Launched: 2يخبرنا أنه بالإضافة إلى العملية الرئيسية أسفل الشجرة ، تم إشراك Gatherعمليتين إضافيتين - بإجمالي 3. لذلك ، كل ما حدث داخل الشجرة الفرعية هو الإبداع الكلي لجميع العمليات الثلاث في وقت واحد.
الآن دعنا نرى ما يوجد هناك
Parallel Seq Scan:
Parallel Seq Scan on tst (actual time=0.024..51.207 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425آها!
loops=3هو ملخص لجميع العمليات الثلاث. وفي المتوسط ، استغرقت كل دورة 51.207 مللي ثانية. أي ، استغرق الخادم 51.207 x 3 = 153.621مللي ثانية من وقت المعالج لإكمال هذه العقدة . أي ، إذا أردنا فهم "ما كان يفعله الخادم" - فهذا الرقم هو الذي سيساعدنا على فهم.
لاحظ أنه لفهم وقت التنفيذ "الحقيقي" ، تحتاج إلى تقسيم الوقت الإجمالي على عدد العمال - أي [actual time] x [loops] / [Workers Launched].
في مثالنا ، أجرى كل عامل دورة واحدة فقط من خلال العقدة ، لذلك
153.621 / 3 = 51.207. ونعم ، الآن لا يوجد شيء غريب أن الشخص الوحيد Gatherفي عملية الرأس قد اكتمل "كما كان ، في وقت أقل".
المجموع: انظر إلىشرح.tensor.ru إجمالي وقت العقدة (لجميع العمليات) لفهم نوع التحميل الذي كان خادمك مشغولاً به ، ولتحسين أي جزء من الاستعلام يستحق قضاء الوقت.
بهذا المعنى ، فإن سلوك نفس الشرح . depesz.com ، الذي يظهر "المتوسط الحقيقي" للوقت في وقت واحد ، يبدو أقل فائدة لأغراض تصحيح الأخطاء:
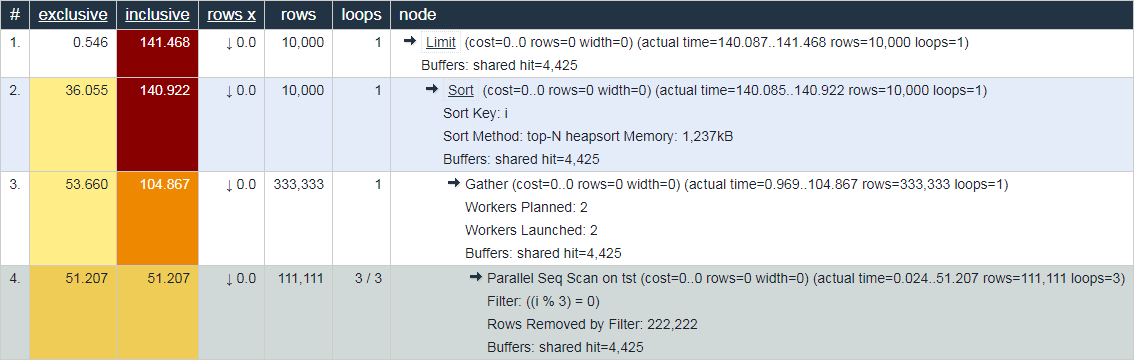
ألا توافق؟ مرحبًا بك في التعليقات!
جمع دمج يفقد كل شيء
الآن دعنا ننفذ نفس الاستعلام على إصدارات PostgreSQL 10 :
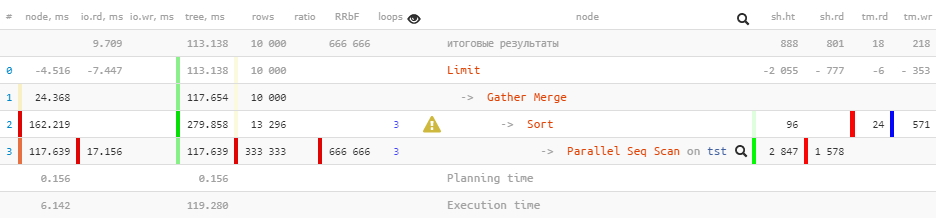
[انظر إلىشرح.tensor.ru]
لاحظ أن لدينا
Gatherالآن عقدة بدلاً من عقدة في الخطة Gather Merge. إليك ما يقوله الدليل عن هذا :
عندما تكون العقدة أعلى الجزء الموازي من الخطةGather Merge، فبدلاً من ذلكGather، فهذا يعني أن جميع العمليات التي تنفذ أجزاء من الخطة المتوازية تُخرج مجموعات tuple بترتيب مُفرز ، وأن العملية الرائدة تقوم بإجراء دمج للحفاظ على النظام.Gatherمن ناحية أخرى ، تستقبل العقدة مجموعات من العمليات التابعة بترتيب تعسفي مناسب لها ، منتهكًا ترتيب الفرز الذي يمكن أن يكون موجودًا.
لكن ليس كل شيء على ما يرام في المملكة الدنماركية:
Limit (actual time=110.740..113.138 rows=10000 loops=1)
Buffers: shared hit=888 read=801, temp read=18 written=218
I/O Timings: read=9.709
-> Gather Merge (actual time=110.739..117.654 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=2943 read=1578, temp read=24 written=571
I/O Timings: read=17.156بينما يمر سمات
Buffersو I/O Timingsحتى الشجرة، بعض البيانات فقد المفاجئة . يمكننا تقدير حجم هذه الخسارة بحوالي 2/3 تقريبًا ، والتي يتم تشكيلها بواسطة عمليات مساعدة.
للأسف ، في الخطة نفسها ، لا يوجد مكان للحصول على هذه المعلومات - ومن هنا جاءت "السلبيات" في العقدة العلوية. وإذا نظرت إلى التطور الإضافي لهذه الخطة في PostgreSQL 12 ، فلن تتغير بشكل أساسي ، باستثناء إضافة بعض الإحصائيات لكل عامل على
Sortالعقدة -node:
Limit (actual time=77.063..80.480 rows=10000 loops=1)
Buffers: shared hit=1764, temp read=223 written=355
-> Gather Merge (actual time=77.060..81.892 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4519, temp read=575 written=856
-> Sort (actual time=72.630..73.252 rows=4278 loops=3)
Sort Key: i
Sort Method: external merge Disk: 1832kB
Worker 0: Sort Method: external merge Disk: 1512kB
Worker 1: Sort Method: external merge Disk: 1248kB
Buffers: shared hit=4519, temp read=575 written=856
-> Parallel Seq Scan on tst (actual time=0.014..44.970 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Planning Time: 0.142 ms
Execution Time: 83.884 msالإجمالي: لا تثق في بيانات العقدة أعلاه
Gather Merge.