أود أن أشارك تجربة تنفيذ الشبكات العصبية العصرية في شركتنا. بدأ كل شيء عندما قررنا بناء مكتب الخدمة الخاص بنا. لماذا ولماذا ، يمكنك قراءة زميلي أليكسي فولكوف (cface) هنا .
سأخبرك عن ابتكار حديث في النظام: شبكة عصبية لمساعدة مرسل الخط الأول من الدعم. إذا كنت مهتما ، مرحبا بك في القط.

توضيح المهمة
الصداع الذي يواجهه أي مرسل دعم هو قرار سريع للتخصيص لطلب عميل وارد. هذه هي الطلبات:
طاب مسائك.
أفهم بشكل صحيح: من أجل مشاركة التقويم مع مستخدم معين ، تحتاج إلى فتح الوصول إلى التقويم الخاص بك على جهاز الكمبيوتر الخاص بالمستخدم الذي يريد مشاركة التقويم وإدخال بريد المستخدم الذي يريد منح حق الوصول إليه؟
وفقًا للوائح ، يجب على المرسل الرد في غضون دقيقتين: تسجيل الطلب ، وتحديد الاستعجال وتعيين وحدة مسؤولة. في هذه الحالة ، يختار المرسل 44 قسمًا للشركة.
تصف تعليمات المرسلين حلاً لمعظم الاستعلامات الشائعة. على سبيل المثال ، يعد توفير الوصول إلى مركز البيانات طلبًا بسيطًا. لكن طلبات الخدمة تتضمن العديد من المهام: تثبيت البرامج ، وتحليل الموقف أو نشاط الشبكة ، وتحديد تفاصيل فواتير الحلول ، والتحقق من جميع أنواع الوصول. في بعض الأحيان يكون من الصعب أن نفهم من الطلب لمن يرسل السؤال من المسؤول:
Hi Team,
The sites were down again for few minutes from 2020-07-15 14:59:53 to 2020-07-15 15:12:50 (UTC time zone), now they are working fine. Could you please check and let us know why the sites are fluctuating many times.
Thanks
كانت هناك حالات ذهب فيها الطلب إلى القسم الخطأ. تم أخذ الطلب للعمل ثم إعادة تعيينه إلى فناني الأداء الآخرين أو إعادته إلى المرسل. هذا زاد من سرعة الحل. يتم كتابة وقت حل الطلبات في الاتفاقية المبرمة مع العميل (SLA) ، ونحن مسؤولون عن الوفاء بالمواعيد النهائية.
داخل النظام ، قررنا إنشاء مساعد للمرسلين. كان الهدف الرئيسي هو إضافة مطالبات تساعد الموظف على اتخاذ قرار بشأن التطبيق بشكل أسرع.
الأهم من ذلك كله ، أنني لم أرغب في الخضوع للاتجاه الجديد ووضع chatbot على خط الدعم الأول. إذا حاولت في أي وقت الكتابة إلى هذا الدعم الفني (الذي لا يخطئ بالفعل في هذا) ، فأنت تفهم ما أعنيه.
أولاً ، إنه يفهمك بشكل سيء للغاية ولا يجيب على الإطلاق للطلبات غير النمطية ، وثانيًا ، من الصعب جدًا الوصول إلى شخص حي.
بشكل عام ، لم نخطط بالتأكيد لاستبدال المرسلين بروبوتات الدردشة ، لأننا نريد من العملاء الاستمرار في التواصل مع شخص حي.
في البداية ، فكرت في الخروج بسعر رخيص ومبهج وجربت نهج الكلمات الرئيسية. قمنا بتجميع قاموس الكلمات الرئيسية يدويًا ، لكن هذا لم يكن كافيًا. تعامل الحل فقط مع التطبيقات البسيطة ، والتي لم تكن هناك مشاكل.
أثناء عمل مكتب الخدمة لدينا ، قمنا بتجميع سجل قوي من الطلبات ، والذي على أساسه يمكننا التعرف على الطلبات الواردة المماثلة وتعيينها على الفور إلى المنفذين المناسبين. مسلحًا بـ Google وبعض الوقت ، قررت التعمق في خياراتي.
نظرية التعلم
اتضح أن مهمتي هي مهمة تصنيف كلاسيكية. عند الإدخال ، تتلقى الخوارزمية النص الأساسي للتطبيق ، وعند الإخراج تقوم بتعيينه إلى إحدى الفئات المعروفة سابقًا - أي أقسام الشركة.
كان هناك العديد من الحلول. هذا هو "الشبكة العصبية" و "المصنف البايزي الساذج" ، و "الجيران الأقرب" ، و "الانحدار اللوجستي" ، و "شجرة القرار" ، و "التعزيز" والعديد والعديد من الخيارات الأخرى.
لن يكون هناك وقت لتجربة كل التقنيات. لذلك ، استقرت على الشبكات العصبية (لطالما أردت محاولة العمل معهم). كما اتضح لاحقًا ، كان هذا الاختيار مبررًا تمامًا.
لذلك ، بدأت الغوص في الشبكات العصبية من هنا . درس خوارزميات التعلمالشبكات العصبية: مع معلم (التعلم تحت الإشراف) ، بدون معلم (التعلم غير الخاضع للإشراف) ، مع المشاركة الجزئية للمعلم (التعلم شبه الخاضع للإشراف) ، أو "التعلم المعزز".
كجزء من مهمتي ، ظهرت طريقة التدريس مع المعلم. يوجد أكثر من بيانات كافية للتدريب: أكثر من 100 ألف تطبيق محلول.
اختيار التنفيذ
اخترت مكتبة Encog Machine Learning Framework للتنفيذ . يأتي مع وثائق يمكن الوصول إليها ومفهومة مع أمثلة . بالإضافة إلى تنفيذ Java ، وهو قريب مني.
باختصار ، تبدو آليات العمل كما يلي:
- تم تكوين إطار الشبكة العصبية مسبقًا: عدة طبقات من الخلايا العصبية متصلة بوصلات المشبك.

- يتم تحميل مجموعة من بيانات التدريب بنتيجة محددة مسبقًا في الذاكرة.
- . «». «» .
- «» : , , .
- 3 4 . , . , - .
لقد جربت أمثلة مختلفة للإطار ، أدركت أن المكتبة تتواءم مع الأرقام عند الإدخال مع إحداث ضجة. لذلك ، فإن المثال مع تعريف فئة القزحية بحجم الوعاء والبتلات (قزحية فيشر ) يعمل بشكل جيد .
لكن لدي بعض النص. هذا يعني أنه يجب تحويل الأحرف بطريقة ما إلى أرقام. لذلك انتقلت إلى المرحلة التحضيرية الأولى - "التوجيه".
الخيار الأول للتوجيه: بالحرف
أسهل طريقة لتحويل النص إلى أرقام هي أخذ الأبجدية على الطبقة الأولى من الشبكة العصبية. اتضح 33 حرفًا عصبيًا: ABVGDEOZHZYKLMNOPRSTUFHTSZHSCHYEYUYA.
يتم تعيين رقم لكل منها: يعتبر وجود حرف في الكلمة واحدًا ، والغياب يعتبر صفرًا.
ثم كلمة "hello" في هذا الترميز سيكون لها متجه:

يمكن بالفعل إعطاء هذا المتجه للشبكة العصبية للتدريب. بعد كل شيء ، هذا الرقم هو 001001000100000011010000000000000 = 1216454656 بالتعمق
في النظرية ، أدركت أنه لا توجد نقطة معينة في تحليل الحروف. إنها لا تحمل أي معنى دلالي. على سبيل المثال ، سيكون الحرف "A" في كل نص من نص الاقتراح. ضع في اعتبارك أن هذه الخلية العصبية تعمل دائمًا ولن يكون لها أي تأثير على النتيجة. مثل كل حروف العلة الأخرى. وفي نص التطبيق سيكون هناك معظم الحروف الأبجدية. هذا الخيار غير مناسب.
البديل الثاني من vectorization: بواسطة القاموس
وإذا لم تأخذ حروفًا بل كلمات؟ دعنا نقول القاموس التوضيحي لدال. وللحساب على أنه 1 بالفعل وجود كلمة في النص ، والغياب - كـ 0.
ولكن هنا واجهت عدد الكلمات. سيصبح المتجه كبيرًا جدًا. ستستغرق الخلية العصبية التي تحتوي على 200 ألف من الخلايا العصبية المدخلة إلى الأبد وستحتاج إلى الكثير من الذاكرة ووقت وحدة المعالجة المركزية. عليك أن تصنع قاموسك الخاص. بالإضافة إلى ذلك ، تحتوي النصوص على ميزات خاصة بتكنولوجيا المعلومات لم يعرفها فلاديمير إيفانوفيتش دال.
التفت إلى النظرية مرة أخرى. لتقصير المفردات عند معالجة النصوص ، استخدم آليات N-grams - سلسلة من العناصر N.
الفكرة هي تقسيم نص الإدخال إلى بعض المقاطع ، وإنشاء قاموس منها ، وإطعام الشبكة العصبية بوجود أو عدم وجود عبارة في النص الأصلي كـ 1 أو 0. هذا ، بدلاً من الحرف ، كما في حالة الأبجدية ، ليس مجرد حرف ، ولكن سيتم اعتبار العبارة بأكملها 0 أو 1.
الأكثر شيوعًا هي أحادي الأحجار ، وبيغرامات ، والتريغرامات. باستخدام عبارة "مرحبًا بك في DataLine" كمثال ، سأخبرك عن كل طريقة من الطرق.
- Unigram - يتم تقسيم النص إلى الكلمات: "جيد" ، "ترحيب" ، "v" ، "خط البيانات".
- Bigram - نقسمها إلى أزواج من الكلمات: "مرحبًا" ، "مرحبًا بك في" ، "إلى DataLine".
- Trigram - بالمثل ، 3 كلمات: "مرحبًا بك في" ، "مرحبًا بك في DataLine".
- N-grams - تحصل على الفكرة. كم عدد الكلمات في صف واحد.
- N-. , . 4- N- : «»,« », «», «» . . .
قررت أن أقصر نفسي على unigram. ولكن ليس فقط أحادي الأحادية - فالكلمات ما زالت أكثر من اللازم.
جاءت الخوارزمية "Porter's Stemmer" للإنقاذ ، والتي تم استخدامها لتوحيد الكلمات في عام 1980.
جوهر الخوارزمية: إزالة اللواحق والنهايات من الكلمة ، وترك الجزء الدلالي الأساسي فقط. على سبيل المثال ، يتم جلب الكلمات "مهم" ، "مهم" ، "مهم" ، "مهم" ، "مهم" ، "مهم" إلى الأساس "مهم". أي أنه بدلاً من 6 كلمات ، سيكون هناك كلمة واحدة في القاموس. وهذا انخفاض كبير.
بالإضافة إلى ذلك ، قمت بإزالة جميع الأرقام وعلامات الترقيم وحروف الجر والكلمات النادرة من القاموس ، حتى لا تحدث "ضوضاء". ونتيجة لذلك ، حصلنا على قاموس مكون من 3 آلاف كلمة من أجل 100 ألف نص. يمكنك بالفعل العمل مع هذا.
تدريب الشبكة العصبية
لذلك لدي بالفعل:
- قاموس 3k الكلمات.
- تمثيل القاموس المتجه.
- أحجام طبقات الإدخال والإخراج للشبكة العصبية. وفقًا للنظرية ، يتم توفير قاموس على الطبقة الأولى (المدخلات) ، والطبقة النهائية (الإخراج) هي عدد فئات الحل. لدي 44 منهم - بعدد أقسام الشركة.
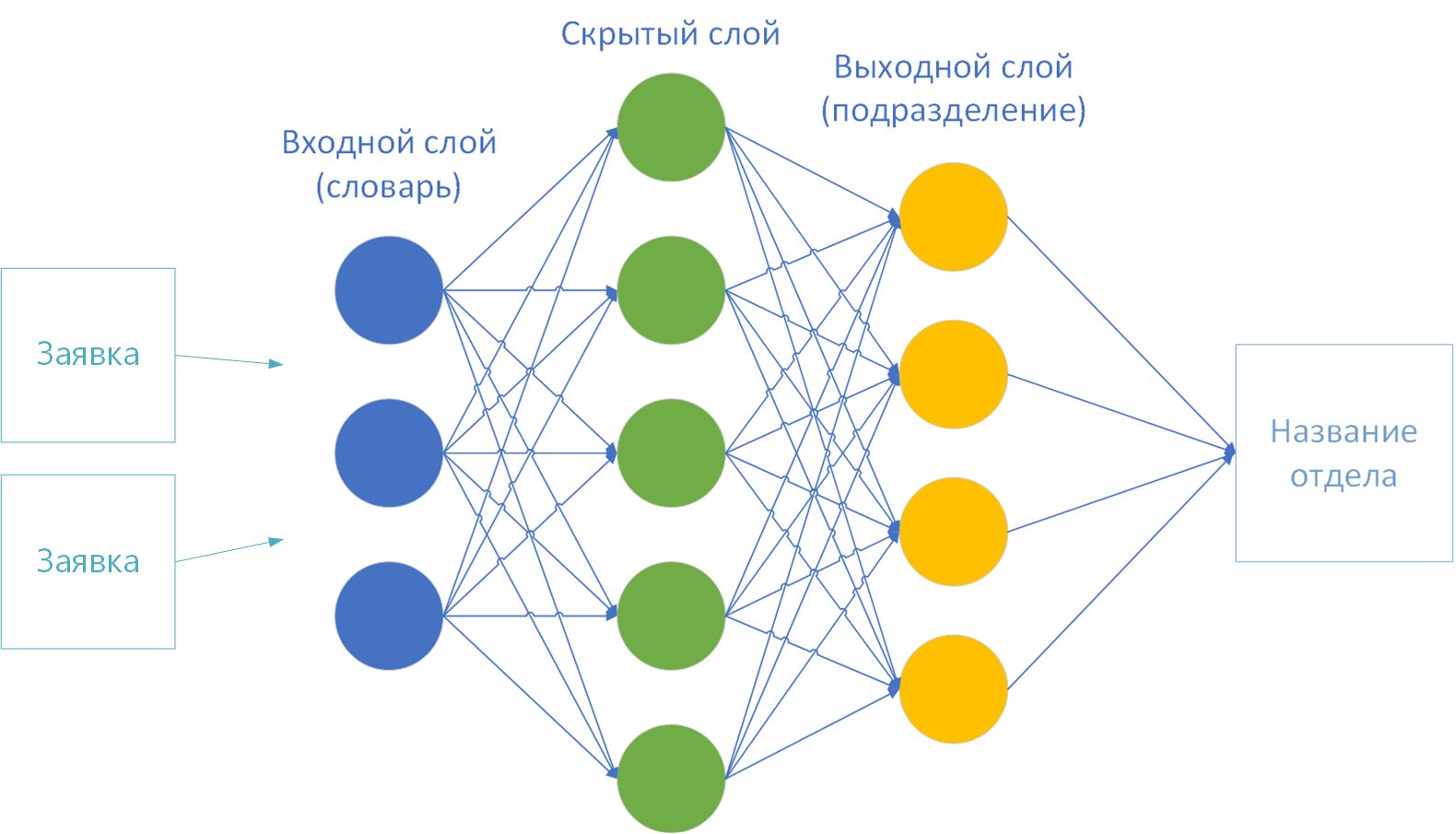
لتدريب شبكة عصبية ، لم يتبق سوى القليل للاختيار:
- طريقة التعليم.
- وظيفة التنشيط.
- عدد الطبقات المخفية.
كيف اخترت المعلمات . يتم دائمًا تحديد المعلمات بشكل تجريبي لكل مهمة محددة. هذه هي أطول عملية مملة لأنها تتطلب الكثير من التجارب.
لذلك ، أخذت عينة مرجعية من 11 ألف تطبيق وقمت بحساب شبكة عصبية بمعلمات مختلفة:
- في الساعة 10k قمت بتدريب شبكة عصبية.
- في 1 كيلو اختبرت الشبكة المدربة بالفعل.
أي أننا في 10k نبني مفردات ونتعلم. ومن ثم نعرض الشبكة العصبية المدربة 1k نصوص غير معروفة. والنتيجة هي النسبة المئوية للخطأ: نسبة الوحدات التي تم تخمينها إلى إجمالي عدد النصوص.
نتيجة لذلك ، حققت دقة تبلغ حوالي 70٪ على بيانات غير معروفة.
من الناحية التجريبية ، اكتشفت أن التدريب يمكن أن يستمر إلى أجل غير مسمى إذا تم اختيار المعلمات الخاطئة. في بضع مرات ، دخلت الخلية العصبية في دورة حسابية لا نهاية لها وعلقت آلة العمل طوال الليل. لمنع ذلك ، بالنسبة لي ، قبلت الحد الأقصى من 100 تكرار أو حتى يتوقف خطأ الشبكة عن التناقص.
ها هي المعلمات النهائية:
طريقة التدريس . يقدم Encog عدة خيارات للاختيار من بينها: Backpropagation، ManhattanPropagation، QuickPropagation، ResilientPropagation، ScaledConjugateGradient.
هذه طرق مختلفة لتحديد الأوزان في المشابك. تعمل بعض الطرق بشكل أسرع ، وبعضها أكثر دقة ، ومن الأفضل قراءة المزيد في الوثائق. نجح التكاثر المرن بالنسبة لي .
وظيفة التنشيط . من الضروري تحديد قيمة الخلايا العصبية عند الإخراج ، اعتمادًا على نتيجة المجموع المرجح للمدخلات وقيمة العتبة.
اخترت من بين 16 خيارًا . لم يكن لدي الوقت الكافي للتحقق من جميع الوظائف. لذلك ، اعتبرت الأكثر شيوعًا: الظل السيني والقطع الزائدي في التطبيقات المختلفة.
في النهاية ، استقرت على ActivationSigmoid .
عدد الطبقات المخفية... من الناحية النظرية ، كلما زادت الطبقات المخفية ، زادت صعوبة الحساب. لقد بدأت بطبقة واحدة: كان الحساب سريعًا ، لكن النتيجة كانت غير دقيقة. استقرت على طبقتين مخفيتين. مع وجود ثلاث طبقات ، تم اعتباره أطول بكثير ، ولم تختلف النتيجة كثيرًا عن الطبقة المكونة من طبقتين.
على هذا انتهيت من التجارب. يمكنك تحضير الأداة للإنتاج.
للإنتاج!
علاوة على ذلك مسألة تقنية.
- لقد فشلت في Spark حتى أتمكن من التواصل مع الخلايا العصبية عبر REST.
- علمت حفظ نتائج الحساب في ملف. ليس في كل مرة لإعادة الحساب عند إعادة تشغيل الخدمة.
- تمت إضافة القدرة على قراءة البيانات الفعلية للتدريب مباشرة من مكتب الخدمة. تم تدريبه مسبقًا على ملفات csv.
- تمت إضافة القدرة على إعادة حساب الشبكة العصبية لإرفاق إعادة الحساب بالمجدول.
- جمعت كل شيء في جرة سميكة.
- طلبت من زملائي الحصول على خادم أقوى من آلة التطوير.
- Zaploil و zadulil يعيدان العد مرة واحدة في الأسبوع.
- لقد قمت بربط الزر في المكان الصحيح في مكتب الخدمة وكتبت إلى زملائي كيفية استخدام هذه المعجزة.
- جمعت إحصاءات حول ما تختاره الخلايا العصبية وما الذي يختاره الشخص (الإحصائيات أدناه).
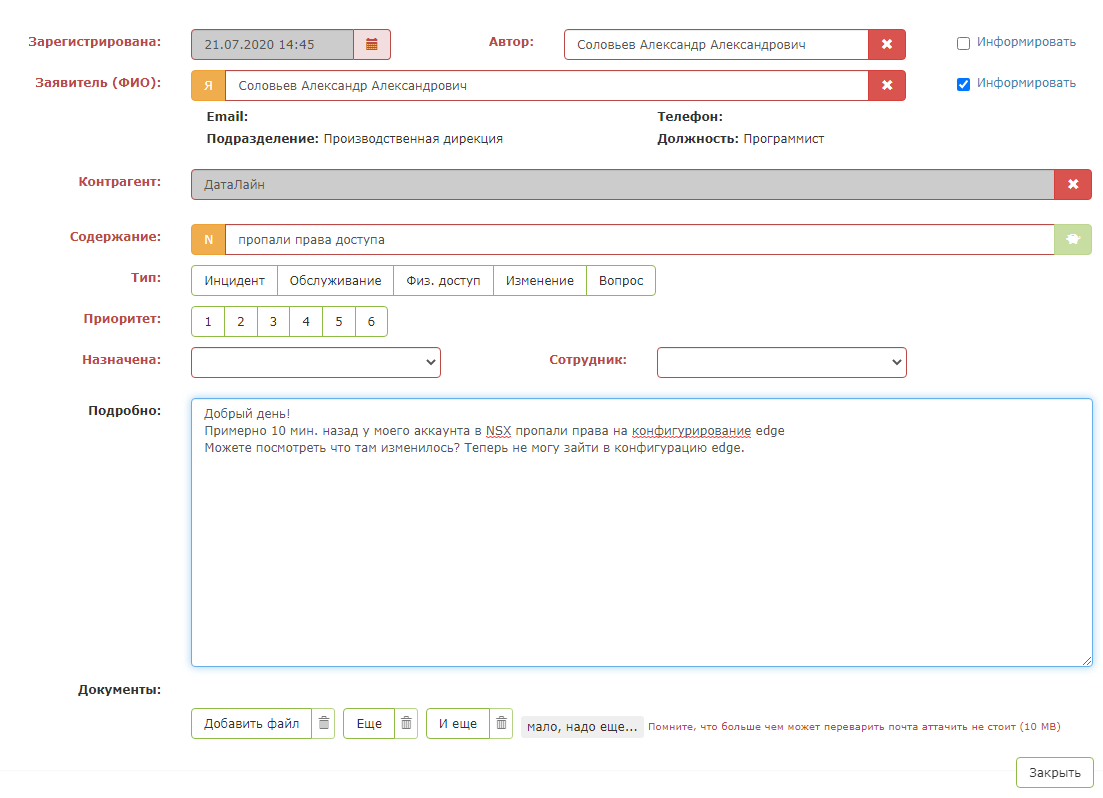
هكذا يبدو تطبيق الاختبار:
ولكن بمجرد الضغط على "الزر الأخضر السحري" ، يحدث السحر: يتم ملء حقول البطاقة. يبقى على المرسل التأكد من أن النظام يطالب بشكل صحيح ويحفظ الطلب.
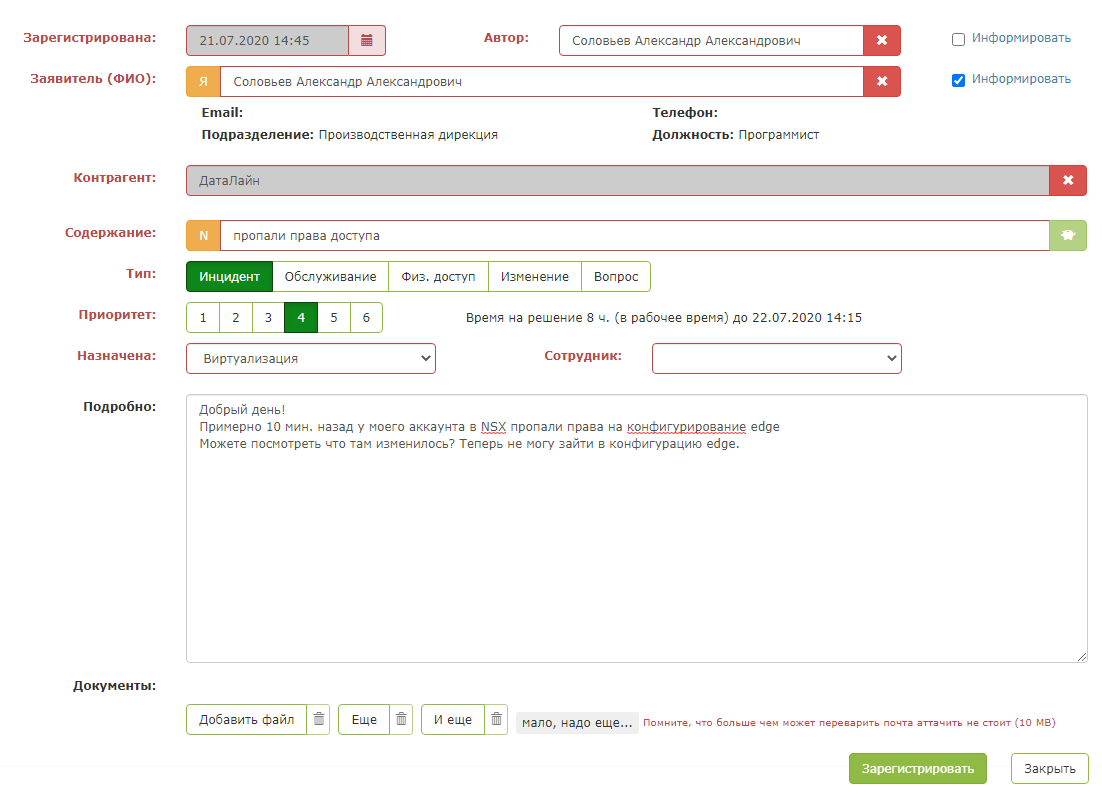
والنتيجة هي مساعد ذكي للمرسل.
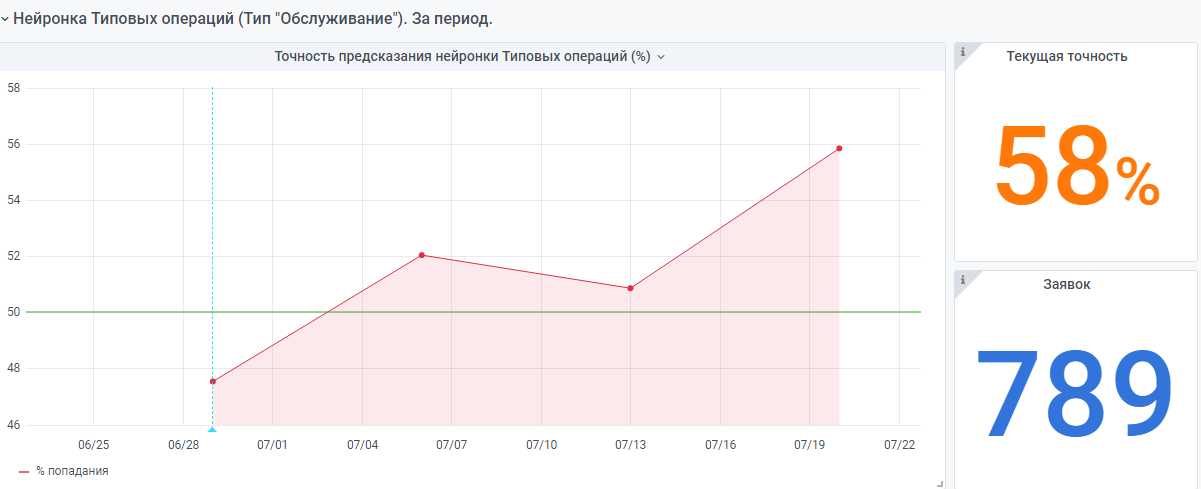
على سبيل المثال ، إحصاءات من بداية العام.
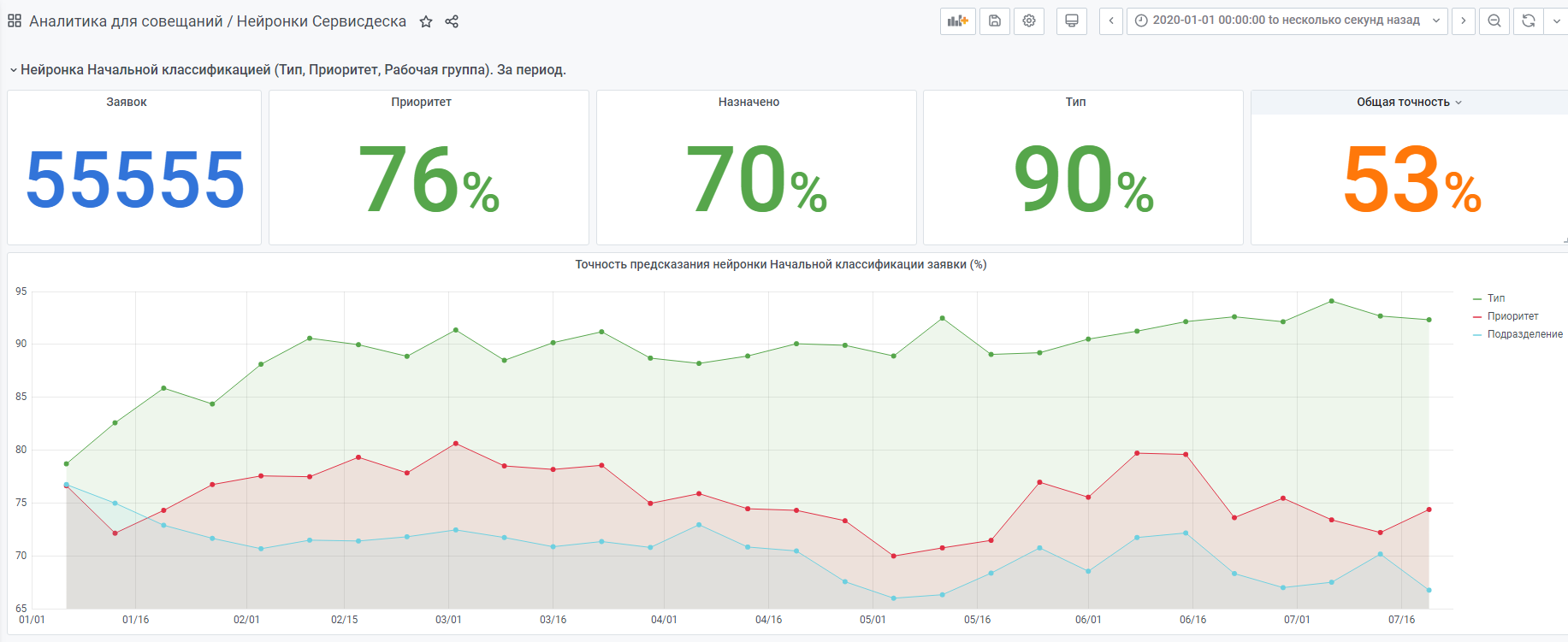
هناك أيضًا شبكة عصبية "صغيرة جدًا" تم إنشاؤها وفقًا لنفس المبدأ. ولكن لا يزال هناك القليل من البيانات ، ولا تزال تكتسب الخبرة.
سأكون سعيدًا إذا كانت تجربتي ستساعد شخصًا ما في إنشاء شبكته العصبية الخاصة.
إذا كان لديك أي أسئلة ، فسأكون سعيدًا بالإجابة.