
في العالم الحديث للبيانات الضخمة ، يعد Apache Spark المعيار الفعلي لتطوير مهام معالجة البيانات المجمعة. بالإضافة إلى ذلك ، يتم استخدامه أيضًا لإنشاء تطبيقات دفق تعمل في مفهوم الدُفعات الصغيرة ، ومعالجة البيانات وإرسالها في أجزاء صغيرة (Spark Structured Streaming). وقد كان تقليديًا جزءًا من مكدس Hadoop الإجمالي ، باستخدام YARN (أو ، في بعض الحالات ، Apache Mesos) كمدير للموارد. بحلول عام 2020 ، أصبح استخدامه التقليدي لمعظم الشركات محل سؤال كبير بسبب عدم وجود توزيعات Hadoop لائقة - توقف تطوير HDP و CDH ، وأصبح CDH متخلفًا وله تكلفة عالية ، وبقية مزودي Hadoop إما لم يعد لديهم وجود أو لديهم مستقبل غامض.لذلك ، فإن الاهتمام المتزايد بين المجتمع والشركات الكبيرة هو إطلاق Apache Spark باستخدام Kubernetes - ليصبح المعيار في تنسيق الحاويات وإدارة الموارد في السحابات الخاصة والعامة ، فهو يحل مشكلة جدولة الموارد غير الملائمة لمهام Spark على YARN ويوفر منصة تطوير مطردة مع العديد من الأعمال التجارية وتوزيعات مفتوحة المصدر للشركات من جميع الأحجام والمشارب. بالإضافة إلى ذلك ، في موجة الشعبية ، تمكنت الغالبية بالفعل من الحصول على اثنين من منشآتها وزيادة خبرتهم في استخدامها ، مما يبسط الانتقال.إنه يحل الجدولة الصعبة لمهام Spark على YARN ويوفر منصة دائمة التطور مع العديد من التوزيعات التجارية ومفتوحة المصدر للشركات من جميع الأحجام والمخططات. بالإضافة إلى ذلك ، في موجة الشعبية ، تمكنت الغالبية بالفعل من الحصول على اثنين من منشآتها وزيادة خبرتهم في استخدامها ، مما يبسط الانتقال.إنه يحل الجدولة الصعبة لمهام Spark على YARN ويوفر منصة دائمة التطور مع العديد من التوزيعات التجارية ومفتوحة المصدر للشركات من جميع الأحجام والمخططات. بالإضافة إلى ذلك ، في موجة الشعبية ، تمكنت الغالبية بالفعل من الحصول على اثنين من منشآتها وزيادة خبرتهم في استخدامها ، مما يبسط الانتقال.
بدءًا من الإصدار 2.3.0 ، اكتسب Apache Spark دعمًا رسميًا لتشغيل المهام في مجموعة Kubernetes ، واليوم ، سنتحدث عن النضج الحالي لهذا النهج ، وحالات الاستخدام المختلفة والمزالق التي ستواجهها أثناء التنفيذ.
بادئ ذي بدء ، سننظر في عملية تطوير المهام والتطبيقات بناءً على Apache Spark وإبراز الحالات النموذجية التي تحتاج فيها إلى تشغيل مهمة على مجموعة Kubernetes. عند إعداد هذا المنشور ، يتم استخدام OpenShift كمجموعة توزيع وسيتم إعطاء الأوامر ذات الصلة بأداة سطر الأوامر المساعدة (oc). بالنسبة إلى توزيعات Kubernetes الأخرى ، يمكن استخدام الأوامر المقابلة لأداة سطر أوامر Kubernetes القياسية (kubectl) أو نظائرها (على سبيل المثال ، لسياسة oc adm).
حالة الاستخدام الأولى هي إرسال شرارة
في عملية تطوير المهام والتطبيقات ، يحتاج المطور إلى تشغيل المهام لتصحيح أخطاء تحويل البيانات. من الناحية النظرية ، يمكن استخدام بذرة لهذه الأغراض ، لكن التطوير بمشاركة أمثلة حقيقية (وإن كانت اختبارية) للأنظمة المحدودة أثبت أنه أسرع وأفضل في هذه الفئة من المهام. في حالة تصحيح الأخطاء في حالات حقيقية للأنظمة النهائية ، هناك سيناريوهان محتملان:
- يقوم المطور بتشغيل مهمة Spark محليًا في الوضع المستقل ؛
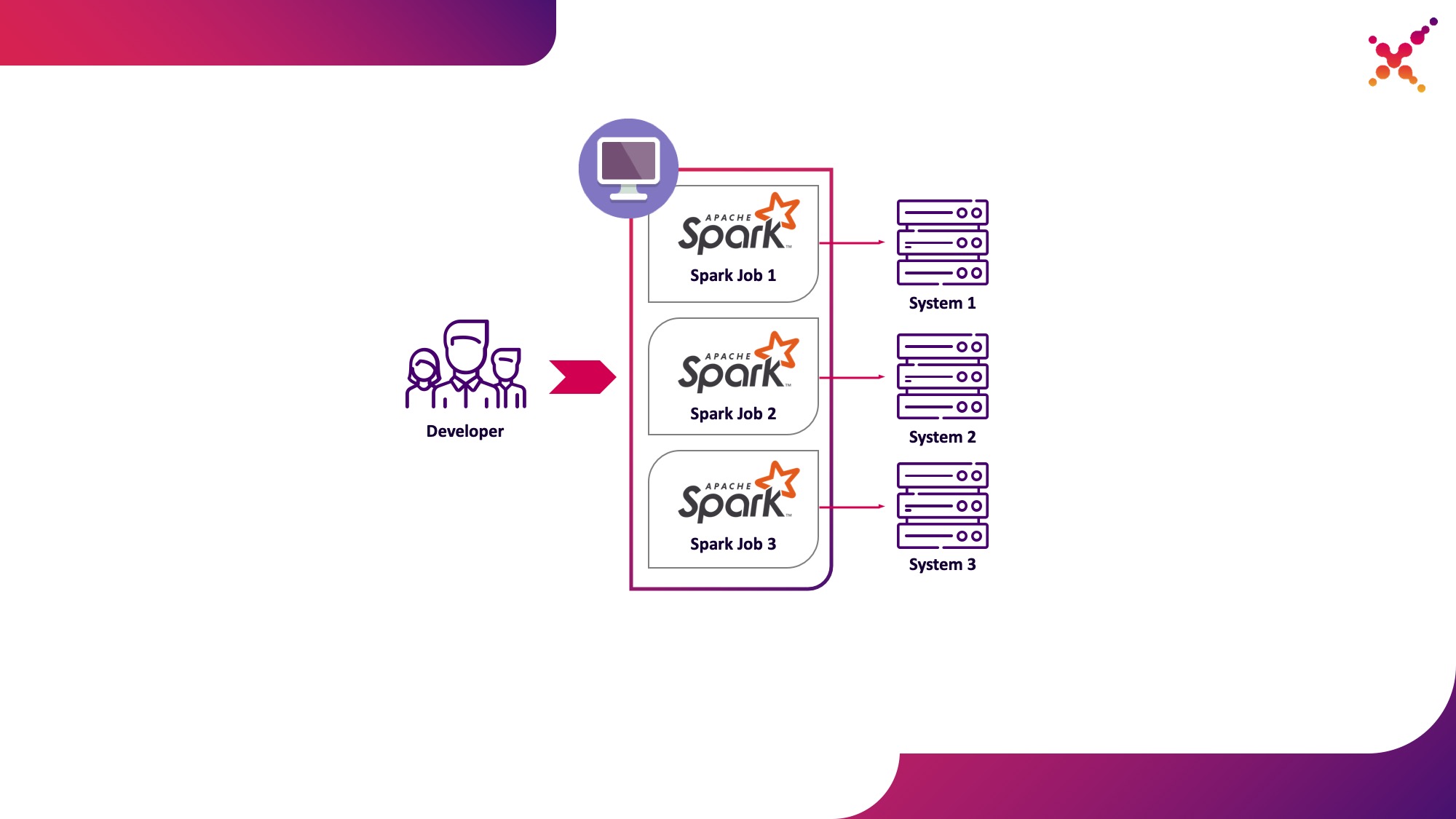
- يقوم أحد المطورين بتشغيل مهمة Spark على مجموعة Kubernetes في حلقة اختبار.

الخيار الأول له الحق في الوجود ، لكنه ينطوي على عدد من العيوب:
- يجب على كل مطور توفير الوصول من مكان العمل إلى جميع نسخ الأنظمة النهائية التي يحتاجها
- تتطلب آلة العمل موارد كافية لتشغيل المهمة المطورة.
الخيار الثاني يخلو من هذه العيوب ، نظرًا لأن استخدام مجموعة Kubernetes يسمح لك بتخصيص مجموعة الموارد اللازمة لتشغيل المهام وتزويدها بالوصول الضروري إلى مثيلات الأنظمة النهائية ، مما يوفر الوصول إليها بمرونة باستخدام نموذج Kubernetes لجميع أعضاء فريق التطوير. دعنا نسلط الضوء عليها باعتبارها حالة الاستخدام الأولى - تشغيل مهام Spark من آلة تطوير محلية على مجموعة Kubernetes في حلقة اختبار.
دعنا نلقي نظرة فاحصة على عملية تكوين Spark للتشغيل محليًا. لبدء استخدام Spark ، تحتاج إلى تثبيته:
mkdir /opt/spark
cd /opt/spark
wget http://mirror.linux-ia64.org/apache/spark/spark-2.4.5/spark-2.4.5.tgz
tar zxvf spark-2.4.5.tgz
rm -f spark-2.4.5.tgz
نقوم بتجميع الحزم اللازمة للعمل مع Kubernetes:
cd spark-2.4.5/
./build/mvn -Pkubernetes -DskipTests clean package
يستغرق البناء الكامل الكثير من الوقت ، ولإنشاء صور Docker وتشغيلها على مجموعة Kubernetes ، في الواقع ، ما عليك سوى ملفات jar من دليل "التجميع /" ، لذا يمكنك فقط إنشاء هذا المشروع الفرعي:
./build/mvn -f ./assembly/pom.xml -Pkubernetes -DskipTests clean package
لتشغيل مهام Spark في Kubernetes ، تحتاج إلى إنشاء صورة Docker لاستخدامها كصورة أساسية. طريقتان ممكنتان هنا:
- تشتمل صورة Docker التي تم إنشاؤها على الكود القابل للتنفيذ لمهمة Spark ؛
- تتضمن الصورة التي تم إنشاؤها فقط Spark والتبعيات الضرورية ، ويتم استضافة الكود القابل للتنفيذ عن بُعد (على سبيل المثال ، في HDFS).
أولاً ، دعنا نبني صورة Docker تحتوي على مثال اختبار لمهمة Spark. لإنشاء صور Docker ، يحتوي Spark على أداة مساعدة تسمى "أداة docker-image-tool". دعنا ندرس المساعدة في ذلك:
./bin/docker-image-tool.sh --help
يمكن استخدامه لإنشاء صور Docker وتحميلها إلى السجلات البعيدة ، ولكن افتراضيًا لها عدة عيوب:
- بدون فشل ، يقوم بإنشاء 3 صور Docker في وقت واحد - لـ Spark و PySpark و R ؛
- لا يسمح لك بتحديد اسم الصورة.
لذلك ، سوف نستخدم نسخة معدلة من هذه الأداة ، كما هو موضح أدناه:
vi bin/docker-image-tool-upd.sh
#!/usr/bin/env bash
function error {
echo "$@" 1>&2
exit 1
}
if [ -z "${SPARK_HOME}" ]; then
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
. "${SPARK_HOME}/bin/load-spark-env.sh"
function image_ref {
local image="$1"
local add_repo="${2:-1}"
if [ $add_repo = 1 ] && [ -n "$REPO" ]; then
image="$REPO/$image"
fi
if [ -n "$TAG" ]; then
image="$image:$TAG"
fi
echo "$image"
}
function build {
local BUILD_ARGS
local IMG_PATH
if [ ! -f "$SPARK_HOME/RELEASE" ]; then
IMG_PATH=$BASEDOCKERFILE
BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
img_path=$IMG_PATH
--build-arg
datagram_jars=datagram/runtimelibs
--build-arg
spark_jars=assembly/target/scala-$SPARK_SCALA_VERSION/jars
)
else
IMG_PATH="kubernetes/dockerfiles"
BUILD_ARGS=(${BUILD_PARAMS})
fi
if [ -z "$IMG_PATH" ]; then
error "Cannot find docker image. This script must be run from a runnable distribution of Apache Spark."
fi
if [ -z "$IMAGE_REF" ]; then
error "Cannot find docker image reference. Please add -i arg."
fi
local BINDING_BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
base_img=$(image_ref $IMAGE_REF)
)
local BASEDOCKERFILE=${BASEDOCKERFILE:-"$IMG_PATH/spark/docker/Dockerfile"}
docker build $NOCACHEARG "${BUILD_ARGS[@]}" \
-t $(image_ref $IMAGE_REF) \
-f "$BASEDOCKERFILE" .
}
function push {
docker push "$(image_ref $IMAGE_REF)"
}
function usage {
cat <<EOF
Usage: $0 [options] [command]
Builds or pushes the built-in Spark Docker image.
Commands:
build Build image. Requires a repository address to be provided if the image will be
pushed to a different registry.
push Push a pre-built image to a registry. Requires a repository address to be provided.
Options:
-f file Dockerfile to build for JVM based Jobs. By default builds the Dockerfile shipped with Spark.
-p file Dockerfile to build for PySpark Jobs. Builds Python dependencies and ships with Spark.
-R file Dockerfile to build for SparkR Jobs. Builds R dependencies and ships with Spark.
-r repo Repository address.
-i name Image name to apply to the built image, or to identify the image to be pushed.
-t tag Tag to apply to the built image, or to identify the image to be pushed.
-m Use minikube's Docker daemon.
-n Build docker image with --no-cache
-b arg Build arg to build or push the image. For multiple build args, this option needs to
be used separately for each build arg.
Using minikube when building images will do so directly into minikube's Docker daemon.
There is no need to push the images into minikube in that case, they'll be automatically
available when running applications inside the minikube cluster.
Check the following documentation for more information on using the minikube Docker daemon:
https://kubernetes.io/docs/getting-started-guides/minikube/#reusing-the-docker-daemon
Examples:
- Build image in minikube with tag "testing"
$0 -m -t testing build
- Build and push image with tag "v2.3.0" to docker.io/myrepo
$0 -r docker.io/myrepo -t v2.3.0 build
$0 -r docker.io/myrepo -t v2.3.0 push
EOF
}
if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
usage
exit 0
fi
REPO=
TAG=
BASEDOCKERFILE=
NOCACHEARG=
BUILD_PARAMS=
IMAGE_REF=
while getopts f:mr:t:nb:i: option
do
case "${option}"
in
f) BASEDOCKERFILE=${OPTARG};;
r) REPO=${OPTARG};;
t) TAG=${OPTARG};;
n) NOCACHEARG="--no-cache";;
i) IMAGE_REF=${OPTARG};;
b) BUILD_PARAMS=${BUILD_PARAMS}" --build-arg "${OPTARG};;
esac
done
case "${@: -1}" in
build)
build
;;
push)
if [ -z "$REPO" ]; then
usage
exit 1
fi
push
;;
*)
usage
exit 1
;;
esac
باستخدامه ، نقوم ببناء صورة Spark أساسية تحتوي على مهمة اختبار لحساب رقم Pi باستخدام Spark (هنا {docker-Registry-url} هو عنوان URL الخاص بتسجيل صورة Docker ، {repo} هو اسم المستودع داخل السجل ، والذي يتزامن مع المشروع في OpenShift ، {image-name} هو اسم الصورة (إذا تم استخدام فصل الصورة ثلاثي المستويات ، على سبيل المثال ، كما في سجل Red Hat OpenShift للصور المتكاملة) ، فإن {tag} هي علامة هذا الإصدار من الصورة):
./bin/docker-image-tool-upd.sh -f resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile -r {docker-registry-url}/{repo} -i {image-name} -t {tag} build
قم بتسجيل الدخول إلى مجموعة OKD باستخدام الأداة المساعدة لوحدة التحكم (هنا {OKD-API-URL} هو عنوان URL لواجهة برمجة تطبيقات مجموعة OKD):
oc login {OKD-API-URL}
دعنا نحصل على رمز المستخدم الحالي للترخيص في Docker Registry:
oc whoami -t
سجّل الدخول إلى Docker Registry الداخلي لمجموعة OKD (استخدم الرمز المميز الذي تم الحصول عليه باستخدام الأمر السابق ككلمة المرور):
docker login {docker-registry-url}
قم بتحميل صورة Docker المبنية إلى Docker Registry OKD:
./bin/docker-image-tool-upd.sh -r {docker-registry-url}/{repo} -i {image-name} -t {tag} push
دعنا نتحقق من أن الصورة المجمعة متوفرة في OKD. للقيام بذلك ، افتح عنوان URL يحتوي على قائمة صور المشروع المقابل في المتصفح (هنا {مشروع} هو اسم المشروع داخل مجموعة OpenShift ، {OKD-WEBUI-URL} هو عنوان URL لوحدة تحكم الويب OpenShift) - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / images / {image-name}.
لتشغيل المهام ، يجب إنشاء حساب خدمة بامتيازات تشغيل البودات كجذر (سنناقش هذه النقطة لاحقًا):
oc create sa spark -n {project}
oc adm policy add-scc-to-user anyuid -z spark -n {project}
قم بتشغيل الأمر spark-submit لنشر مهمة Spark إلى مجموعة OKD ، مع تحديد حساب الخدمة الذي تم إنشاؤه وصورة Docker:
/opt/spark/bin/spark-submit --name spark-test --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar
هنا:
--name هو اسم المهمة التي ستشارك في تشكيل اسم كبسولات Kubernetes ؛
--class - فئة الملف القابل للتنفيذ تسمى عند بدء المهمة ؛
--conf - معلمات تكوين شرارة ؛
spark.executor.instances عدد منفذي Spark المطلوب تشغيلهم.
spark.kubernetes.authenticate.driver.serviceAccountName اسم حساب خدمة Kubernetes المستخدم عند تشغيل البودات (لتحديد سياق الأمان والإمكانيات عند التفاعل مع Kubernetes API) ؛
spark.kubernetes.namespace - مساحة اسم Kubernetes حيث سيتم تشغيل أقراص برنامج التشغيل والمنفذ ؛
spark.submit.deployMode - طريقة إطلاق Spark (يتم استخدام "الكتلة" لتقديم شرارة قياسية ، و "العميل" لمشغل Spark والإصدارات الأحدث من Spark) ؛
spark.kubernetes.container.image تُستخدم صورة Docker لتشغيل البودات.
spark.master - عنوان URL لواجهة برمجة تطبيقات Kubernetes (يتم تحديد الخارجي بحيث تحدث المكالمة من الجهاز المحلي) ؛
local: // هو المسار إلى ملف Spark القابل للتنفيذ داخل صورة Docker.
انتقل إلى مشروع OKD المقابل وادرس البودات التي تم إنشاؤها - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods.
لتبسيط عملية التطوير ، يمكن استخدام خيار آخر ، حيث يتم إنشاء صورة شرارة أساسية مشتركة يتم استخدامها من قبل جميع المهام للتشغيل ، ويتم نشر لقطات من الملفات القابلة للتنفيذ على وحدة تخزين خارجية (على سبيل المثال ، Hadoop) ويتم تحديدها عند استدعاء إرسال شرارة كرابط. في هذه الحالة ، يمكنك تشغيل إصدارات مختلفة من مهام Spark دون إعادة إنشاء صور Docker ، باستخدام على سبيل المثال WebHDFS لنشر الصور. نرسل طلبًا لإنشاء ملف (هنا {host} هو مضيف خدمة WebHDFS ، {المنفذ} هو منفذ خدمة WebHDFS ، {path-to-file-on-hdfs} هو المسار المطلوب للملف على HDFS):
curl -i -X PUT "http://{host}:{port}/webhdfs/v1/{path-to-file-on-hdfs}?op=CREATE
سيتلقى هذا ردًا من النموذج (هنا {location} هو عنوان URL الذي يجب استخدامه لتنزيل الملف):
HTTP/1.1 307 TEMPORARY_REDIRECT
Location: {location}
Content-Length: 0
قم بتحميل ملف Spark القابل للتنفيذ في HDFS (هنا {path-to-local-file} هو المسار إلى Spark القابل للتنفيذ على المضيف الحالي):
curl -i -X PUT -T {path-to-local-file} "{location}"
بعد ذلك ، يمكننا إجراء إرسال شرارة باستخدام ملف Spark الذي تم تحميله إلى HDFS (هنا {class-name} هو اسم الفصل الذي يجب إطلاقه لإكمال المهمة):
/opt/spark/bin/spark-submit --name spark-test --class {class-name} --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} hdfs://{host}:{port}/{path-to-file-on-hdfs}
تجدر الإشارة إلى أنه من أجل الوصول إلى HDFS والتأكد من تشغيل المهمة ، قد تحتاج إلى تغيير Dockerfile و entrypoint.sh النصي - إضافة توجيه إلى Dockerfile لنسخ المكتبات التابعة إلى دليل / opt / spark / jars وتضمين ملف تكوين HDFS في SPARK_CLASSPATH في نقطة الإدخال. ش.
حالة الاستخدام الثانية - Apache Livy
علاوة على ذلك ، عندما يتم تطوير المهمة ويكون مطلوبًا لاختبار النتيجة التي تم الحصول عليها ، فإن السؤال الذي يطرح نفسه هو إطلاقها ضمن عملية CI / CD وتتبع حالة تنفيذها. بالطبع ، يمكنك تشغيله باستخدام مكالمة شرارة محلية ، ولكن هذا يعقد البنية التحتية CI / CD لأنه يتطلب تثبيت وتكوين Spark على وكلاء / مشغلي خادم CI وإعداد الوصول إلى Kubernetes API. لهذه الحالة ، اختار التنفيذ المستهدف استخدام Apache Livy باعتباره REST API لتشغيل مهام Spark المستضافة داخل مجموعة Kubernetes. من خلال مساعدتها ، يمكنك تشغيل مهام Spark على مجموعة Kubernetes باستخدام طلبات cURL العادية ، والتي يتم تنفيذها بسهولة استنادًا إلى أي حل CI ، ووضعها داخل مجموعة Kubernetes يحل مشكلة المصادقة عند التفاعل مع Kubernetes API.
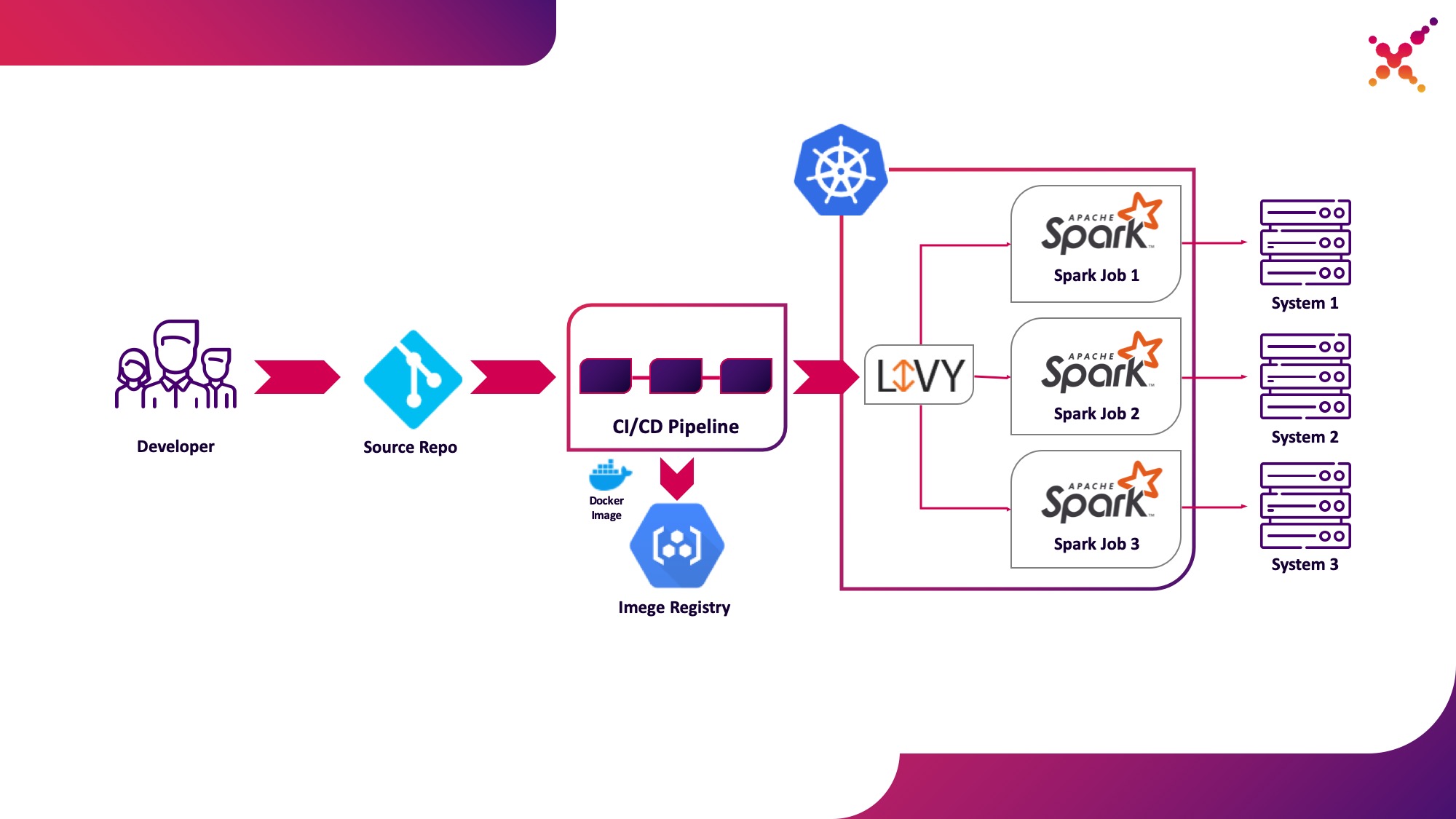
دعنا نسلط الضوء عليها باعتبارها حالة الاستخدام الثانية - تشغيل مهام Spark كجزء من عملية CI / CD على مجموعة Kubernetes في حلقة اختبار.
قليلاً عن Apache Livy - فهو يعمل كخادم HTTP يوفر واجهة ويب وواجهة برمجة تطبيقات RESTful تتيح لك تشغيل إرسال شرارة عن بُعد عن طريق تمرير المعلمات المطلوبة. تم شحنه تقليديًا كجزء من توزيع HDP ، ولكن يمكن أيضًا نشره في OKD أو أي تثبيت Kubernetes آخر باستخدام البيان المناسب ومجموعة من صور Docker ، على سبيل المثال ، هذا - github.com/ttauveron/k8s-big-data-experiments/tree/master /livy-spark-2.3 . بالنسبة لحالتنا ، تم إنشاء صورة Docker مماثلة ، بما في ذلك إصدار Spark 2.4.5 من Dockerfile التالي:
FROM java:8-alpine
ENV SPARK_HOME=/opt/spark
ENV LIVY_HOME=/opt/livy
ENV HADOOP_CONF_DIR=/etc/hadoop/conf
ENV SPARK_USER=spark
WORKDIR /opt
RUN apk add --update openssl wget bash && \
wget -P /opt https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz && \
tar xvzf spark-2.4.5-bin-hadoop2.7.tgz && \
rm spark-2.4.5-bin-hadoop2.7.tgz && \
ln -s /opt/spark-2.4.5-bin-hadoop2.7 /opt/spark
RUN wget http://mirror.its.dal.ca/apache/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip && \
unzip apache-livy-0.7.0-incubating-bin.zip && \
rm apache-livy-0.7.0-incubating-bin.zip && \
ln -s /opt/apache-livy-0.7.0-incubating-bin /opt/livy && \
mkdir /var/log/livy && \
ln -s /var/log/livy /opt/livy/logs && \
cp /opt/livy/conf/log4j.properties.template /opt/livy/conf/log4j.properties
ADD livy.conf /opt/livy/conf
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ADD entrypoint.sh /entrypoint.sh
ENV PATH="/opt/livy/bin:${PATH}"
EXPOSE 8998
ENTRYPOINT ["/entrypoint.sh"]
CMD ["livy-server"]
يمكن إنشاء الصورة التي تم إنشاؤها وتحميلها إلى مستودع Docker الحالي الخاص بك ، على سبيل المثال مستودع OKD الداخلي. لنشره ، يتم استخدام البيان التالي ({Registry-url} هو عنوان URL لسجل صورة Docker ، {image-name} هو اسم صورة Docker ، {tag} هو علامة صورة Docker ، {livy-url} هو عنوان URL المطلوب الذي سيكون الخادم متاحًا فيه Livy ، يتم استخدام بيان "المسار" إذا تم استخدام Red Hat OpenShift كتوزيع Kubernetes ، وإلا فسيتم استخدام بيان الدخول أو الخدمة المقابل من نوع NodePort):
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: livy
name: livy
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
component: livy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
component: livy
spec:
containers:
- command:
- livy-server
env:
- name: K8S_API_HOST
value: localhost
- name: SPARK_KUBERNETES_IMAGE
value: 'gnut3ll4/spark:v1.0.14'
image: '{registry-url}/{image-name}:{tag}'
imagePullPolicy: Always
name: livy
ports:
- containerPort: 8998
name: livy-rest
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/log/livy
name: livy-log
- mountPath: /opt/.livy-sessions/
name: livy-sessions
- mountPath: /opt/livy/conf/livy.conf
name: livy-config
subPath: livy.conf
- mountPath: /opt/spark/conf/spark-defaults.conf
name: spark-config
subPath: spark-defaults.conf
- command:
- /usr/local/bin/kubectl
- proxy
- '--port'
- '8443'
image: 'gnut3ll4/kubectl-sidecar:latest'
imagePullPolicy: Always
name: kubectl
ports:
- containerPort: 8443
name: k8s-api
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: spark
serviceAccountName: spark
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: livy-log
- emptyDir: {}
name: livy-sessions
- configMap:
defaultMode: 420
items:
- key: livy.conf
path: livy.conf
name: livy-config
name: livy-config
- configMap:
defaultMode: 420
items:
- key: spark-defaults.conf
path: spark-defaults.conf
name: livy-config
name: spark-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: livy-config
data:
livy.conf: |-
livy.spark.deploy-mode=cluster
livy.file.local-dir-whitelist=/opt/.livy-sessions/
livy.spark.master=k8s://http://localhost:8443
livy.server.session.state-retain.sec = 8h
spark-defaults.conf: 'spark.kubernetes.container.image "gnut3ll4/spark:v1.0.14"'
---
apiVersion: v1
kind: Service
metadata:
labels:
app: livy
name: livy
spec:
ports:
- name: livy-rest
port: 8998
protocol: TCP
targetPort: 8998
selector:
component: livy
sessionAffinity: None
type: ClusterIP
---
apiVersion: route.openshift.io/v1
kind: Route
metadata:
labels:
app: livy
name: livy
spec:
host: {livy-url}
port:
targetPort: livy-rest
to:
kind: Service
name: livy
weight: 100
wildcardPolicy: None
بعد التطبيق والإطلاق الناجح للجراب ، تتوفر واجهة Livy الرسومية على الرابط: http: // {livy-url} / ui. مع Livy ، يمكننا نشر مهمة Spark الخاصة بنا باستخدام طلب REST ، على سبيل المثال من Postman. فيما يلي مثال لمجموعة مع طلبات (في مصفوفة "args" ، يمكن تمرير وسيطات التكوين مع المتغيرات المطلوبة للمهمة التي يتم تشغيلها):
{
"info": {
"_postman_id": "be135198-d2ff-47b6-a33e-0d27b9dba4c8",
"name": "Spark Livy",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "1 Submit job with jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar\", \n\t\"className\": \"org.apache.spark.examples.SparkPi\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-1\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t}\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
},
{
"name": "2 Submit job without jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"hdfs://{host}:{port}/{path-to-file-on-hdfs}\", \n\t\"className\": \"{class-name}\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-2\",\n\t\"proxyUser\": \"0\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t},\n\t\"args\": [\n\t\t\"HADOOP_CONF_DIR=/opt/spark/hadoop-conf\",\n\t\t\"MASTER=k8s://https://kubernetes.default.svc:8443\"\n\t]\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
}
],
"event": [
{
"listen": "prerequest",
"script": {
"id": "41bea1d0-278c-40c9-ad42-bf2e6268897d",
"type": "text/javascript",
"exec": [
""
]
}
},
{
"listen": "test",
"script": {
"id": "3cdd7736-a885-4a2d-9668-bd75798f4560",
"type": "text/javascript",
"exec": [
""
]
}
}
],
"protocolProfileBehavior": {}
}
دعنا ننفذ الطلب الأول من المجموعة ، وانتقل إلى واجهة OKD وتحقق من بدء المهمة بنجاح - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods. في هذه الحالة ، ستظهر جلسة في واجهة Livy (http: // {livy-url} / ui) ، يمكنك من خلالها ، باستخدام واجهة برمجة تطبيقات Livy أو واجهة رسومية ، تتبع تقدم المهمة ودراسة سجلات الجلسة.
الآن دعنا نظهر كيف تعمل ليفي. للقيام بذلك ، دعنا نفحص سجلات حاوية Livy داخل الكبسولة باستخدام خادم Livy - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods / {livy-pod-name}؟ Tab = logs. من بينها يمكنك أن ترى أنه عندما يتم استدعاء Livy REST API في حاوية تسمى "livy" ، يتم تنفيذ إرسال شرارة مشابه لما استخدمناه أعلاه (هنا {livy-pod-name} هو اسم الكبسولة التي تم إنشاؤها باستخدام خادم Livy) توفر المجموعة أيضًا طلبًا ثانيًا يسمح لك بتشغيل المهام مع الاستضافة عن بُعد لبرنامج Spark القابل للتنفيذ باستخدام خادم Livy.
حالة الاستخدام الثالثة - عامل الشرارة
الآن وقد تم اختبار المهمة ، فإن السؤال الذي يطرح نفسه هو تشغيلها بانتظام. الطريقة الأصلية لتشغيل المهام بانتظام في مجموعة Kubernetes هي كيان CronJob ويمكنك استخدامه ، ولكن في الوقت الحالي ، يعد استخدام المشغلين للتحكم في التطبيقات في Kubernetes شائعًا للغاية ، وبالنسبة لشركة Spark ، يوجد مشغل ناضج إلى حد ما ، والذي يستخدم ، من بين أشياء أخرى ، في حلول مستوى المؤسسة (على سبيل المثال Lightbend FastData Platform). نوصي باستخدامه - يحتوي الإصدار الثابت الحالي من Spark (2.4.5) على خيارات محدودة جدًا لتكوين إطلاق مهام Spark في Kubernetes ، بينما في الإصدار الرئيسي التالي (3.0.0) تم الإعلان عن الدعم الكامل لـ Kubernetes ، لكن تاريخ إصداره لا يزال غير معروف. يعوض Spark Operator عن هذا النقص عن طريق إضافة معلمات تكوين مهمة (على سبيل المثال ،تصاعد ConfigMap مع تكوين الوصول إلى Hadoop في Spark pods) والقدرة على تشغيل المهمة بانتظام وفقًا لجدول زمني.
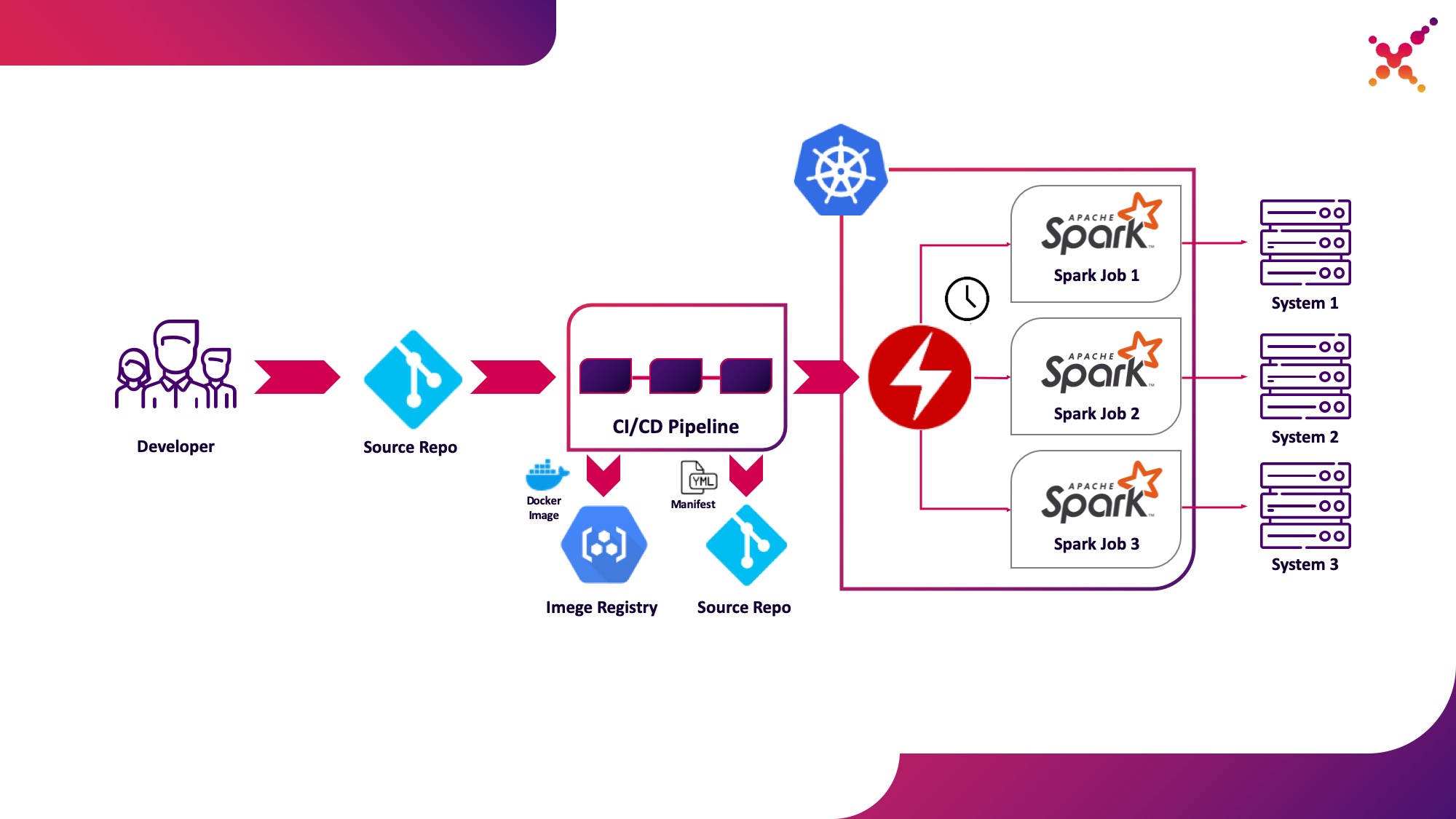
دعنا نسلط الضوء عليها كحالة الاستخدام الثالثة - تشغيل مهام Spark بانتظام على مجموعة Kubernetes في حلقة إنتاج.
Spark Operator مفتوح المصدر وتم تطويره ضمن Google Cloud Platform - github.com/GoogleCloudPlatform/spark-on-k8s-operator . يمكن تركيبه بثلاث طرق:
- كجزء من تثبيت Lightbend FastData Platform / Cloudflow ؛
- مع هيلم:
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator helm install incubator/sparkoperator --namespace spark-operator
- (https://github.com/GoogleCloudPlatform/spark-on-k8s-operator/tree/master/manifest). — Cloudflow API v1beta1. , Spark Git API, , «v1beta1-0.9.0-2.4.0». CRD, «versions»:
oc get crd sparkapplications.sparkoperator.k8s.io -o yaml
إذا تم تثبيت المشغل بشكل صحيح ، فستظهر حجرة نشطة مع مشغل Spark في المشروع المقابل (على سبيل المثال ، cloudflow-fdp-sparkoperator في مساحة Cloudflow لتثبيت Cloudflow) وسيظهر نوع مورد Kubernetes المقابل المسمى "sparkapplications". يمكنك فحص تطبيقات Spark المتاحة باستخدام الأمر التالي:
oc get sparkapplications -n {project}
لتشغيل المهام باستخدام Spark Operator ، عليك القيام بثلاثة أشياء:
- إنشاء صورة Docker تتضمن جميع المكتبات المطلوبة ، بالإضافة إلى ملفات التكوين والملفات القابلة للتنفيذ. في الصورة المستهدفة ، هذه صورة تم إنشاؤها في مرحلة CI / CD واختبارها على مجموعة اختبار ؛
- نشر صورة Docker في السجل الذي يمكن الوصول إليه من مجموعة Kubernetes ؛
- «SparkApplication» . (, github.com/GoogleCloudPlatform/spark-on-k8s-operator/blob/v1beta1-0.9.0-2.4.0/examples/spark-pi.yaml). :
- «apiVersion» API, ;
- «metadata.namespace» , ;
- «spec.image» Docker ;
- «spec.mainClass» Spark, ;
- «spec.mainApplicationFile» jar ;
- يجب أن يشير القاموس "spec.sparkVersion" إلى إصدار Spark المستخدم ؛
- في القاموس "spec.driver.serviceAccount" ، يجب أن يكون هناك حساب خدمة ضمن مساحة اسم Kubernetes المقابلة التي سيتم استخدامها لتشغيل التطبيق ؛
- يجب أن يشير القاموس "spec.executor" إلى مقدار الموارد المخصصة للتطبيق ؛
- يجب أن يحدد قاموس "spec.volumeMounts" الدليل المحلي الذي سيتم فيه إنشاء ملفات مهمة Spark المحلية.
مثال على إنشاء بيان (هنا {spark-service-account} هو حساب خدمة داخل مجموعة Kubernetes لتشغيل مهام Spark):
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 0.1
coreLimit: "200m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: {spark-service-account}
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
يحدد هذا البيان حساب الخدمة الذي تحتاج ، قبل نشر البيان ، إلى إنشاء روابط الأدوار الضرورية التي توفر حقوق الوصول الضرورية لتطبيق Spark للتفاعل مع Kubernetes API (إذا لزم الأمر). في حالتنا ، يحتاج التطبيق إلى حقوق إنشاء Pods. لنقم بإنشاء ارتباط الدور المطلوب:
oc adm policy add-role-to-user edit system:serviceaccount:{project}:{spark-service-account} -n {project}
تجدر الإشارة أيضًا إلى أن مواصفات هذا البيان يمكن أن تحدد معلمة hadoopConfigMap ، والتي تسمح لك بتحديد ConfigMap بتكوين Hadoop دون الحاجة إلى وضع الملف المقابل أولاً في صورة Docker. كما أنها مناسبة لبدء المهام بانتظام - باستخدام معلمة "الجدول الزمني" ، يمكن تحديد جدول زمني لبدء هذه المهمة.
بعد ذلك ، نحفظ البيان الخاص بنا في ملف spark-pi.yaml ونطبقه على مجموعة Kubernetes الخاصة بنا:
oc apply -f spark-pi.yaml
سيؤدي هذا إلى إنشاء كائن من النوع "sparkapplications":
oc get sparkapplications -n {project}
> NAME AGE
> spark-pi 22h
سيؤدي هذا إلى إنشاء جراب مع تطبيق ، سيتم عرض حالته في "التطبيقات الشرارة" التي تم إنشاؤها. يمكن مشاهدته بالأمر التالي:
oc get sparkapplications spark-pi -o yaml -n {project}
عند الانتهاء من المهمة ، سينتقل POD إلى الحالة "مكتمل" ، والتي سيتم تحديثها أيضًا إلى "تطبيقات شرارة". يمكن عرض سجلات التطبيق في متصفح أو باستخدام الأمر التالي (هنا {sparkapplications-pod-name} هو اسم حجرة المهمة قيد التشغيل):
oc logs {sparkapplications-pod-name} -n {project}
يمكن أيضًا إدارة مهام Spark باستخدام الأداة المساعدة sparkctl المتخصصة. لتثبيته ، قمنا باستنساخ المستودع برمز المصدر الخاص به ، وقم بتثبيت Go وإنشاء هذه الأداة المساعدة:
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
cd spark-on-k8s-operator/
wget https://dl.google.com/go/go1.13.3.linux-amd64.tar.gz
tar -xzf go1.13.3.linux-amd64.tar.gz
sudo mv go /usr/local
mkdir $HOME/Projects
export GOROOT=/usr/local/go
export GOPATH=$HOME/Projects
export PATH=$GOPATH/bin:$GOROOT/bin:$PATH
go -version
cd sparkctl
go build -o sparkctl
sudo mv sparkctl /usr/local/bin
دعنا نفحص قائمة مهام Spark قيد التشغيل:
sparkctl list -n {project}
لنقم بإنشاء وصف لمهمة Spark:
vi spark-app.yaml
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
لننفذ المهمة الموصوفة باستخدام sparkctl:
sparkctl create spark-app.yaml -n {project}
دعنا نفحص قائمة مهام Spark قيد التشغيل:
sparkctl list -n {project}
دعنا نفحص قائمة الأحداث لمهمة Spark التي بدأت:
sparkctl event spark-pi -n {project} -f
دعنا نفحص حالة مهمة Spark قيد التشغيل:
sparkctl status spark-pi -n {project}
في الختام ، أود النظر في العيوب المكتشفة لتشغيل الإصدار الثابت الحالي من Spark (2.4.5) في Kubernetes:
- , , — Data Locality. YARN , , ( ). Spark , , , . Kubernetes , . , , , , Spark . , Kubernetes (, Alluxio), Kubernetes.
- — . , Spark , Kerberos ( 3.0.0, ), Spark (https://spark.apache.org/docs/2.4.5/security.html) YARN, Mesos Standalone Cluster. , Spark, — , , . root, , UID, ( PodSecurityPolicies ). Docker, Spark , .
- لا يزال تشغيل مهام Spark مع Kubernetes رسميًا في الوضع التجريبي ، وقد تكون هناك تغييرات كبيرة في الأدوات المستخدمة (ملفات التكوين ، وصور قاعدة Docker ، ونصوص بدء التشغيل) في المستقبل. في الواقع ، عند تحضير المواد ، تم اختبار الإصدارين 2.3.0 و 2.4.5 ، كان السلوك مختلفًا بشكل كبير.
سننتظر التحديثات - تم إصدار إصدار جديد من Spark (3.0.0) مؤخرًا ، والذي أدخل تغييرات ملموسة على عمل Spark على Kubernetes ، لكنه احتفظ بالحالة التجريبية لدعم مدير الموارد هذا. ربما تتيح التحديثات التالية حقًا إمكانية التوصية بشكل كامل بالتخلي عن YARN وتشغيل مهام Spark على Kubernetes ، دون خوف على أمان نظامك ودون الحاجة إلى تحسين المكونات الوظيفية بشكل مستقل.
زعنفة.