
التعريف الذاتي
اسمي ألكساندر ، أقوم بتطوير اتجاه تحليلات البيانات والتقنية لأغراض التدقيق الداخلي لمجموعة Rosbank. نستخدم أنا وفريقي التعلم الآلي والشبكات العصبية لتحديد المخاطر كجزء من عمليات التدقيق الداخلي. لدينا خادم 300 غيغابايت من ذاكرة الوصول العشوائي و 4 معالجات مع 10 مراكز في ترسانتنا. بالنسبة للبرمجة أو النمذجة الخوارزمية ، نستخدم Python.
المقدمة
واجهتنا مهمة تحليل صور (بورتريهات) العملاء التي التقطها موظفو البنك أثناء تسجيل منتج مصرفي. هدفنا هو تحديد المخاطر التي تم الكشف عنها مسبقًا من هذه الصور. لتحديد المخاطر ، نقوم بإنشاء واختبار مجموعة من الفرضيات. في هذه المقالة سأصف الفرضيات التي توصلنا إليها وكيف اختبرناها. لتبسيط تصور المادة ، سأستخدم الموناليزا - معيار نوع الصورة.

تحقق من المجموع
في البداية ، اتخذنا نهجًا بدون التعلم الآلي ورؤية الكمبيوتر ، فقط مقارنة المجاميع الاختبارية للملفات. لإنشاءها ، أخذنا خوارزمية md5 المستخدمة على نطاق واسع من مكتبة hashlib.
تطبيق Python *:
#
with open(file,'rb') as f:
#
for chunk in iter(lambda: f.read(4096),b''):
#
hash_md5.update(chunk)
عند تكوين المجموع الاختباري ، نتحقق فورًا من التكرارات باستخدام قاموس.
#
for file in folder_scan(for_scan):
#
ch_sum = checksum(file)
#
if ch_sum in list_of_uniq.keys():
# , , dataframe
df = df.append({'id':list_of_uniq[chs],'same_checksum_with':[file]}, ignore_index = True)
هذه الخوارزمية بسيطة للغاية من حيث الحمل الحسابي: تتم معالجة 1000 صورة على خادمنا في مدة لا تزيد عن 3 ثوانٍ.
ساعدتنا هذه الخوارزمية في تحديد الصور المكررة بين بياناتنا ، ونتيجة لذلك ، العثور على أماكن للتحسين المحتمل لعملية أعمال البنك.
النقاط الرئيسية (رؤية الكمبيوتر)
على الرغم من النتيجة الإيجابية لطريقة المجموع الاختباري ، فقد فهمنا تمامًا أنه إذا تم تغيير بكسل واحد على الأقل في الصورة ، فسيكون المجموع الاختباري مختلفًا تمامًا. كتطور منطقي للفرضية الأولى ، افترضنا أنه يمكن تغيير الصورة في بنية البت: الخضوع لإعادة الحفظ (أي إعادة ضغط jpg) أو تغيير الحجم أو الاقتصاص أو التدوير.
للتوضيح ، دعنا نقطع الحواف على طول المخطط الأحمر وندير لوحة الموناليزا 90 درجة إلى اليمين.

في هذه الحالة ، يجب البحث عن التكرارات من خلال المحتوى المرئي للصورة. لهذا قررنا استخدام مكتبة OpenCV ، وهي طريقة لبناء النقاط الرئيسية للصورة وإيجاد المسافة بين النقاط الرئيسية. في الممارسة العملية ، يمكن أن تكون النقاط الرئيسية هي الزوايا أو التدرجات اللونية أو الركض السطحي. لأغراضنا ، ظهرت إحدى أبسط الطرق - مطابقة القوة الغاشمة. لقياس المسافة بين النقاط الرئيسية للصورة ، استخدمنا مسافة هامينج. توضح الصورة أدناه نتيجة البحث عن النقاط الأساسية على الصور الأصلية والمعدلة (يتم رسم أقرب 20 نقطة رئيسية من الصور).
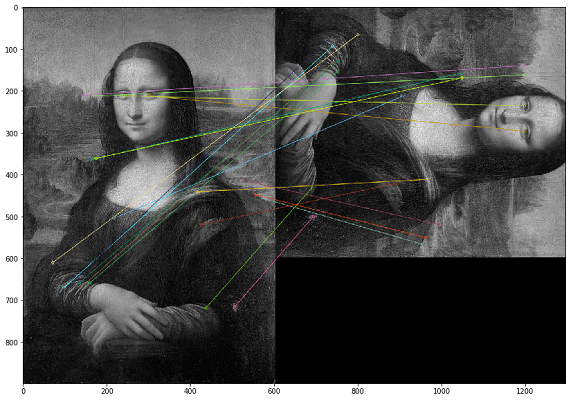
من المهم ملاحظة أننا نقوم بتحليل الصور في مرشح أبيض وأسود ، لأن هذا يحسن وقت تشغيل النص ويعطي تفسيرًا أكثر وضوحًا للنقاط الرئيسية. إذا كانت إحدى الصور بها مرشح بني داكن والأخرى بلون أصلي ، فعند تحويلها إلى مرشح أبيض وأسود ، سيتم تحديد النقاط الرئيسية بغض النظر عن معالجة الألوان والمرشحات.
عينة كود لمقارنة صورتين *
img1 = cv.imread('mona.jpg',cv.IMREAD_GRAYSCALE) #
img2 = cv.imread('mona_ch.jpg',cv.IMREAD_GRAYSCALE) #
# ORB
orb = cv.ORB_create()
# ORB
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# Brute-Force Matching
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True)
# .
matches = bf.match(des1,des2)
# .
matches = sorted(matches, key = lambda x:x.distance)
# 20
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches[:20],None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plt.imshow(img3),plt.show()
أثناء اختبار النتائج ، أدركنا أنه في حالة انعكاس الصورة ، يتغير ترتيب البكسل داخل النقطة الرئيسية ولا يتم تحديد هذه الصور على أنها نفسها. كإجراء تعويضي ، يمكنك عكس كل صورة بنفسك وتحليل ضعف الحجم (أو حتى ثلاثة أضعاف) ، وهو أكثر تكلفة من حيث قوة الحوسبة.
تحتوي هذه الخوارزمية على درجة عالية من التعقيد الحسابي ، ويتم إنشاء الحمل الأكبر من خلال عملية حساب المسافة بين النقاط. نظرًا لأنه يتعين علينا مقارنة كل صورة بكل صورة ، إذن ، كما تفهم ، يتطلب حساب مثل هذه المجموعة الديكارتية عددًا كبيرًا من الدورات الحسابية. في مراجعة واحدة ، استغرق حساب مماثل أكثر من شهر.
مشكلة أخرى مع هذا النهج هي ضعف تفسير نتائج الاختبار. نحصل على معامل المسافات بين النقاط الرئيسية للصور ، ويطرح السؤال: "ما هي عتبة هذا المعامل التي يجب اختيارها بشكل كافٍ للنظر في الصور المكررة؟"
باستخدام رؤية الكمبيوتر ، تمكنا من العثور على الحالات التي لم يغطيها اختبار المجموع الاختباري الأول. في الممارسة العملية ، تبين أنها ملفات jpg تم حفظها بشكل زائد. لم نحدد الحالات الأكثر تعقيدًا لتغييرات الصور في مجموعة البيانات التي تم تحليلها.
النقاط الرئيسية الاختبارية مقابل النقاط الرئيسية
بعد أن طورنا طريقتين مختلفتين جذريًا للعثور على التكرارات وإعادة استخدامها في عدة فحوصات ، توصلنا إلى استنتاج مفاده أن المجموع الاختباري لبياناتنا يعطي نتيجة ملموسة أكثر في وقت أقصر. لذلك ، إذا كان لدينا وقت كافٍ للتحقق ، فإننا نجري مقارنة بالنقاط الرئيسية.
ابحث عن صور غير طبيعية
بعد تحليل نتائج الاختبار للنقاط الرئيسية ، لاحظنا أن الصور التي التقطها موظف واحد لها نفس عدد نقاط الإغلاق الرئيسية تقريبًا. وهذا أمر منطقي ، لأنه إذا تواصل مع العملاء في مكان عمله والتقط الصور في نفس الغرفة ، فستكون الخلفية في جميع صوره هي نفسها. قادتنا هذه الملاحظة للاعتقاد بأنه يمكننا العثور على صور استثنائية تختلف عن الصور الأخرى لهذا الموظف ، والتي ربما تم التقاطها خارج المكتب.
بالعودة إلى مثال الموناليزا ، اتضح أن أشخاصًا آخرين سيظهرون على نفس الخلفية. لكن للأسف ، لم نجد مثل هذه الأمثلة ، لذلك سنعرض في هذا القسم مقاييس البيانات بدون أمثلة. لزيادة سرعة الحساب في إطار اختبار هذه الفرضية ، قررنا التخلي عن النقاط الرئيسية واستخدام الرسوم البيانية.
الخطوة الأولى هي ترجمة الصورة إلى كائن (مدرج تكراري) يمكننا قياسه من أجل مقارنة الصور بالمسافة بين الرسوم البيانية الخاصة بهم. في الأساس ، الرسم البياني هو رسم بياني يعطي نظرة عامة على الصورة. هذا رسم بياني بقيم بكسل على محور الاحداثي السيني (المحور X) والعدد المقابل من وحدات البكسل في الصورة على طول المحور الإحداثي (المحور ص). الرسم البياني هو طريقة سهلة لتفسير وتحليل الصورة. باستخدام الرسم البياني للصورة ، يمكنك الحصول على فكرة بديهية عن التباين والسطوع وتوزيع الكثافة وما إلى ذلك.
لكل صورة ، نقوم بإنشاء رسم بياني باستخدام وظيفة calcHist من OpenCV.
histo = cv2.calcHist([picture],[0],None,[256],[0,256])
في الأمثلة المعطاة لثلاث صور ، وصفناها باستخدام 256 عاملاً على طول المحور الأفقي (جميع أنواع البكسل). لكن يمكننا أيضًا إعادة ترتيب وحدات البكسل. لم يقم فريقنا بالكثير من الاختبارات في هذا الجزء ، حيث كانت النتيجة جيدة جدًا عند استخدام 256 عاملاً. إذا لزم الأمر ، يمكننا تغيير هذه المعلمة مباشرة في وظيفة calcHist.
بعد إنشاء الرسوم البيانية لكل صورة ، يمكننا ببساطة تدريب نموذج DBSCAN على الصور لكل موظف قام بتصوير العميل. النقطة الفنية هنا هي تحديد معلمات DBSCAN (إبسيلون و min_samples) لمهمتنا.
بعد استخدام DBSCAN ، يمكننا القيام بتجميع الصور ، ثم تطبيق طريقة PCA لتصور المجموعات الناتجة.

كما يتضح من توزيع الصور التي تم تحليلها ، لدينا مجموعتان زرقاء واضحة. كما اتضح ، في أيام مختلفة يمكن للموظف العمل في مكاتب مختلفة - الصور الملتقطة في أحد المكاتب تنشئ مجموعة منفصلة.
في حين أن النقاط الخضراء عبارة عن صور استثنائية ، حيث تختلف الخلفية عن هذه المجموعات.
بعد تحليل مفصل للصور وجدنا العديد من الصور السلبية الخاطئة. أكثر الحالات شيوعًا هي الصور الفوتوغرافية أو الصور الفوتوغرافية التي يشغلها وجه العميل نسبة كبيرة من المنطقة. اتضح أن طريقة التحليل هذه تتطلب تدخلًا بشريًا إلزاميًا للتحقق من صحة النتائج.
باستخدام هذا الأسلوب ، يمكنك العثور على تشوهات مثيرة للاهتمام في الصورة ، ولكن الأمر سيستغرق وقتًا طويلاً لتحليل النتائج يدويًا. لهذه الأسباب ، نادرًا ما نجري مثل هذه الاختبارات كجزء من عمليات تدقيقنا.
هل يوجد وجه في الصورة؟ (الكشف عن الوجه)
لذلك ، لقد اختبرنا بالفعل مجموعة البيانات الخاصة بنا من جوانب مختلفة ، واستمرنا في تطوير تعقيد الاختبار ، ننتقل إلى الفرضية التالية: هل هناك وجه للعميل المحتمل في الصورة؟ مهمتنا هي معرفة كيفية التعرف على الوجوه في الصور ، وإعطاء وظائف لإدخال الصورة والحصول على عدد الوجوه عند الإخراج.
هذا النوع من التنفيذ موجود بالفعل ، وقد قررنا اختيار MTCNN (شبكة عصبية تلافيفية متعددة المهام) لمهمتنا من وحدة FaceNet من Google.
FaceNet هي بنية عميقة للتعلم الآلي تتكون من طبقات تلافيفية. تقوم FaceNet بإرجاع متجه 128-بعداً لكل وجه. في الواقع ، يعد FaceNet عدة شبكات عصبية ومجموعة من الخوارزميات لإعداد ومعالجة النتائج الوسيطة لهذه الشبكات. قررنا وصف آليات البحث عن الوجه بواسطة هذه الشبكة العصبية بمزيد من التفصيل ، حيث لا يوجد الكثير من المواد حول هذا الموضوع.
الخطوة 1: المعالجة المسبقة
أول شيء تفعله MTCNN هو إنشاء أحجام متعددة من صورتنا.
سيحاول MTCNN التعرف على الوجوه داخل مربع بحجم ثابت في كل صورة. سيؤدي استخدام هذا التعرف على نفس الصورة بأحجام مختلفة إلى زيادة فرصنا في التعرف بشكل صحيح على جميع الوجوه الموجودة في الصورة.

قد لا يتم التعرف على الوجه في حجم الصورة العادي ، ولكن يمكن التعرف عليه في صورة مختلفة الحجم في مربع بحجم ثابت. يتم تنفيذ هذه الخطوة بطريقة حسابية بدون شبكة عصبية.
الخطوة الثانية: P-Net
بعد إنشاء نسخ مختلفة من صورتنا ، يتم تشغيل أول شبكة عصبية ، P-Net. تستخدم هذه الشبكة نواة 12 × 12 (كتلة) تقوم بمسح جميع الصور (نسخ من نفس الصورة ، ولكن بأحجام مختلفة) ، بدءًا من الزاوية اليسرى العليا ، والتحرك على طول الصورة باستخدام خطوة 2 بكسل.

بعد مسح جميع الصور ذات الأحجام المختلفة ، تقوم MTCNN مرة أخرى بتوحيد كل صورة وإعادة حساب إحداثيات الكتلة.
يعطي P-Net إحداثيات الكتل ومستويات الثقة (مدى دقة هذا الوجه) بالنسبة للوجه الذي يحتوي عليه لكل كتلة. يمكنك ترك الكتل بمستوى معين من الثقة باستخدام معلمة العتبة.
في الوقت نفسه ، لا يمكننا ببساطة تحديد الكتل بأقصى مستوى من الثقة ، لأن الصورة يمكن أن تحتوي على عدة وجوه.
إذا تداخلت كتلة واحدة مع أخرى وتغطي نفس المنطقة تقريبًا ، فسيتم إزالة تلك الكتلة. يمكن التحكم في هذه المعلمة أثناء تهيئة الشبكة.

في هذا المثال ، ستتم إزالة الكتلة الصفراء. بشكل أساسي ، ينتج عن P-Net كتل ذات دقة منخفضة. يوضح المثال أدناه النتائج الحقيقية لـ P-Net:

الخطوة 3: R-Net
تقوم R-Net بمجموعة مختارة من أنسب الكتل التي تشكلت نتيجة لعمل P-Net ، والتي من المرجح أن تكون شخصًا في المجموعة. تمتلك R-Net بنية مشابهة لـ P-Net. في هذه المرحلة ، يتم تشكيل طبقات متصلة بالكامل. الإخراج من R-Net مشابه أيضًا للإخراج من P-Net.

الخطوة 4: O-Net
شبكة O-Net هي الجزء الأخير من شبكة MTCNN. بالإضافة إلى الشبكتين الأخيرتين ، فإنها تشكل خمس نقاط لكل وجه (العيون والأنف وزوايا الشفاه). إذا كانت هذه النقاط تقع تمامًا في الكتلة ، فسيتم تحديدها على أنها الأكثر احتمالية لاحتواء الشخص. يتم تمييز النقاط الإضافية باللون الأزرق:

نتيجة لذلك ، نحصل على كتلة نهائية تشير إلى دقة حقيقة أن هذا وجه. إذا لم يتم العثور على الوجه ، فسنحصل على عدد صفر من كتل الوجه.
في المتوسط ، تستغرق معالجة 1000 صورة بواسطة هذه الشبكة 6 دقائق على خادمنا.
لقد استخدمنا هذه الشبكة العصبية مرارًا وتكرارًا في عمليات الفحص ، وساعدتنا في التعرف تلقائيًا على الحالات الشاذة بين صور عملائنا.
حول استخدام FaceNet ، أود أن أضيف أنه إذا بدأت في تحليل لوحات رامبرانت بدلاً من الموناليزا ، فستكون النتائج مثل الصورة أدناه ، وسيتعين عليك تحليل القائمة الكاملة للأشخاص المحددين:

خاتمة
توضح هذه الفرضيات وأساليب الاختبار أنه مع أي مجموعة من البيانات ، يمكنك إجراء اختبارات مثيرة للاهتمام والبحث عن الحالات الشاذة. في الوقت الحاضر ، يحاول العديد من المدققين تطوير ممارسات مماثلة ، لذلك أردت أن أعرض أمثلة عملية لاستخدام رؤية الكمبيوتر والتعلم الآلي.
أود أيضًا أن أضيف أننا اعتبرنا التعرف على الوجوه هو الفرضية التالية للاختبار ، ولكن حتى الآن لا توفر البيانات وخصائص العملية أساسًا معقولًا لاستخدام هذه التقنية في اختباراتنا.
بشكل عام ، هذا كل ما أود أن أخبركم به عن طريقتنا في اختبار الصور.
أتمنى لك تحليلات جيدة وبيانات مصنفة!
* رمز العينة مأخوذ من مصادر مفتوحة.