الجزء 2
في هذه المقالة سوف تتعلم:
- حول تحدي التعرف المرئي على نطاق واسع على ImageNet (ILSVRC)
- حول ماهية معماريات CNN الموجودة:
- ليت -5
- AlexNet
- شبكة VGGNet
- GoogLeNet
- ResNet
- حول المشكلات التي ظهرت مع بنى الشبكات الجديدة ، وكيف تم حلها من خلال المشكلات اللاحقة:
- مشكلة التدرج المتلاشي
- انفجار مشكلة الانحدار
ILSVRC
يعد تحدي التعرف البصري على نطاق واسع على ImageNet مسابقة سنوية يقارن فيها الباحثون شبكاتهم لاكتشاف الأشياء وتصنيفها في الصور الفوتوغرافية.
كانت هذه المنافسة هي الدافع لتطوير:
- معماريات الشبكة العصبية
- الأساليب والممارسات الشخصية المستخدمة حتى
يومنا هذا. يوضح هذا الرسم البياني كيف تطورت خوارزميات التصنيف بمرور الوقت:
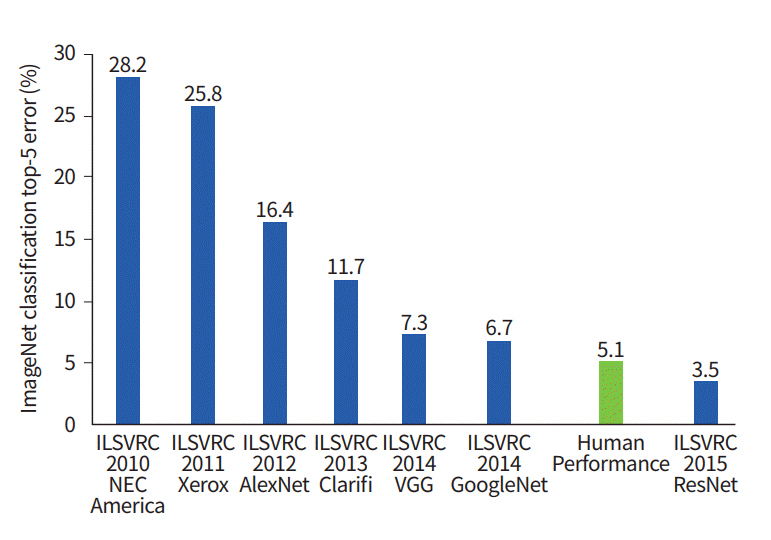
على المحور س - السنوات والخوارزميات (منذ عام 2012 - عصبي تلافيفي) شبكة الاتصال).
المحور ص هو النسبة المئوية للأخطاء في العينة من أعلى 5 أخطاء.
يعد خطأ أعلى 5 طريقة لتقييم النموذج: يُرجع النموذج توزيعًا احتماليًا معينًا وإذا كان من بين الاحتمالات الخمسة الأولى قيمة حقيقية (تسمية الفئة) للفئة ، فإن إجابة النموذج تعتبر صحيحة. وفقًا لذلك ، (1 - أعلى - 1 خطأ) هي الدقة المألوفة.
معماريات سي إن إن
ليت -5
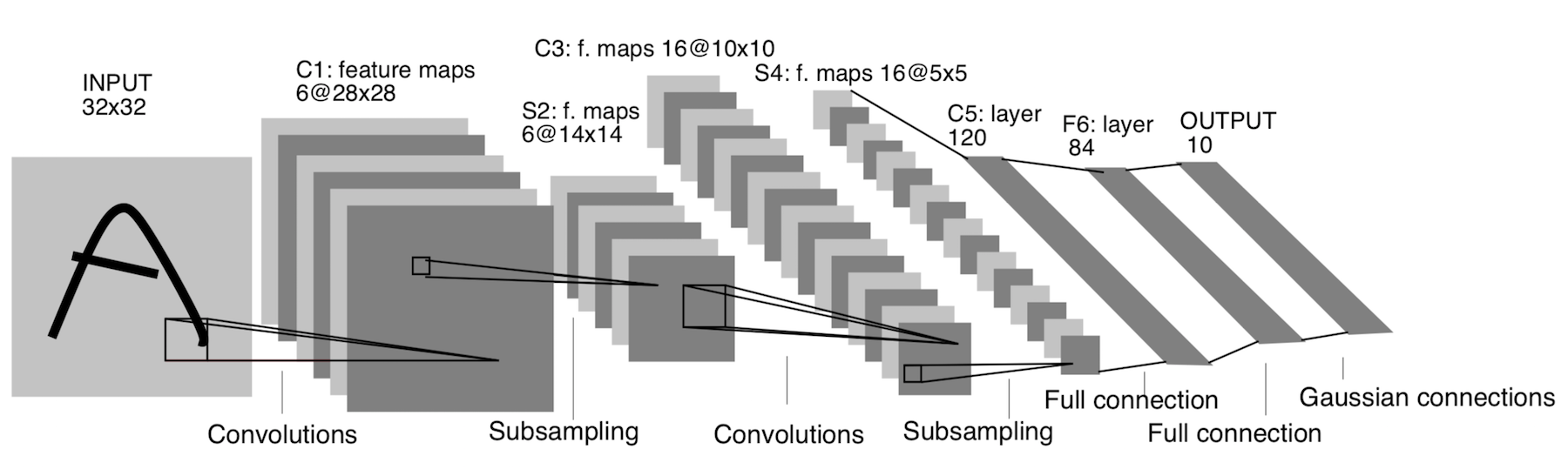
ظهرت بالفعل في عام 1998! تم تصميمه للتعرف على الحروف والأرقام المكتوبة بخط اليد. يشير الاختزال هنا إلى طبقة التجميع.
الهندسة المعمارية:
CONV 5x5 ، خطوة = 1
POOL 2x2 ، خطوة = 2
CONV 5x5 ، خطوة = 1
POOL 5x5 ، خطوة = 2
FC (120 ، 84)
FC (84 ، 10)
الآن هذه العمارة لها أهمية تاريخية فقط. هذه البنية سهلة التنفيذ يدويًا في أي إطار عمل تعلم عميق حديث.
AlexNet

الصورة ليست مكررة. هذه هي الطريقة التي يتم بها تصوير البنية ، لأن بنية AlexNet لم تكن مناسبة لجهاز GPU واحد ، لذا فإن "نصف" الشبكة يعمل على وحدة معالجة رسومات واحدة ، والآخر على الآخر.
ظهر في عام 2012. بدأ الاختراق في تلك ILSVRC بالذات معها - لقد هزمت جميع النماذج الفنية في ذلك الوقت. بعد ذلك ، أدرك الناس أن الشبكات العصبية تعمل حقًا :)
الهندسة المعمارية بشكل أكثر تحديدًا:

إذا نظرت عن كثب إلى بنية AlexNet ، يمكنك أن ترى أنه لمدة 14 عامًا (منذ ظهور LeNet-5) ، لم تحدث أي تغييرات تقريبًا ، باستثناء عدد الطبقات.
مهم:
- نأخذ صورتنا الأصلية 227x227x3 ونخفض أبعادها (في الطول والعرض) ، لكننا نزيد عدد القنوات. هذا الجزء من العمارة "يشفر" التمثيل الأصلي للكائن (المشفر).
- ReLU. ReLu .
- 60 .
- .
:
- Local Response Norm — , . batch-normalization.
- - , — - FLOPs, .
- FC 4096 , (Fully-connected) 4096 .
- Max Pool 3x3s2 , 3x3, = 2.
- سجل مثل Conv 11x11s4، 96 يعني أن طبقة الالتفاف بها مرشح 11x11xNc ، الخطوة = 4 ، عدد هذه المرشحات هو 96. الآن عدد هذه المرشحات هو عدد القنوات للطبقة التالية (نفس Nc). نفترض أن الصورة الأولية بها ثلاث قنوات (R و G و B).
شبكة VGGNet
العمارة: تم
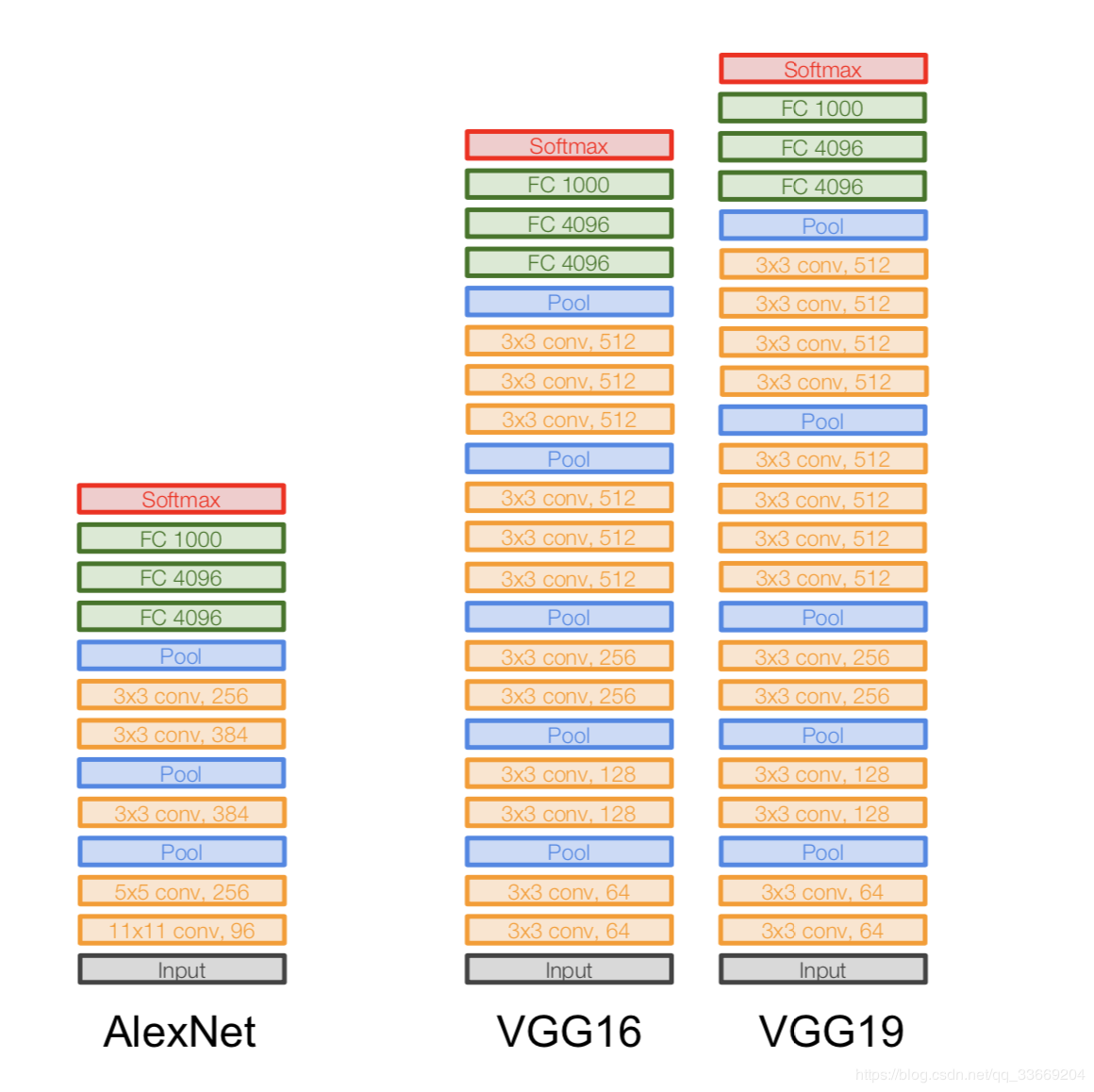
تقديمه في عام 2014.
نسختان - VGG16 و VGG19. الفكرة الرئيسية هي استخدام الأشياء الصغيرة (3 × 3) بدلاً من الكبيرة (11 × 11 و 5 × 5). الحدس لاستخدام تلافيف كبيرة بسيط - نريد الحصول على مزيد من المعلومات من وحدات البكسل المجاورة ، ولكن من الأفضل استخدام المرشحات الصغيرة كثيرًا .
ولهذا السبب:
- . , . .. , , .
- => .
- — , — , — , .
هام:
- عند تدريب شبكة عصبية لخوارزمية الانتشار العكسي للخطأ ، من المهم الحفاظ على تمثيلات الكائن (بالنسبة لنا - الصورة الأصلية) في جميع مراحل (التلافيف ، التجمعات) للانتشار الأمامي (التمرير الأمامي هو عندما نقوم بتغذية الصورة إلى الإدخال والانتقال إلى الإخراج ، إلى النتيجة). يمكن أن يكون تمثيل الكائن هذا مكلفًا من حيث الذاكرة. ألق نظرة:
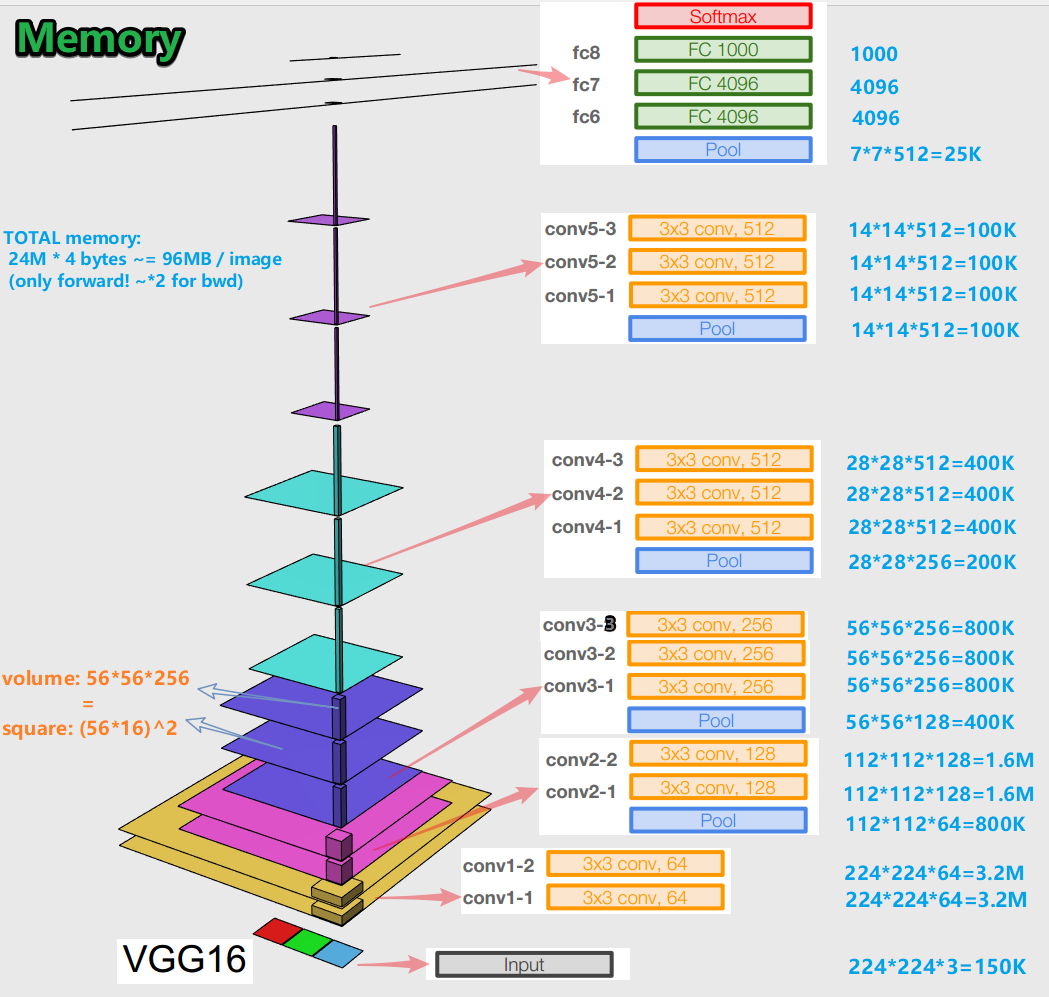
اتضح أن حوالي 96 ميجابايت لكل صورة - وهذا فقط للتمرير الأمامي. بالنسبة للممر الخلفي (الجسم في الصورة) - أثناء حساب التدرجات - حوالي ضعف ذلك. تظهر صورة مثيرة للاهتمام: يوجد أكبر عدد من المعلمات المدربة في طبقات متصلة بالكامل ، وتشغل أكبر ذاكرة تمثيلات الكائنات بعد الطبقات التلافيفية والتجميع . ج - التآزر.
- تحتوي الشبكة على 138 مليون معلمة تدريب في 16 طبقة مختلفة و 143 مليون معلمة في 19 طبقة مختلفة.
GoogLeNet
العمارة: تم
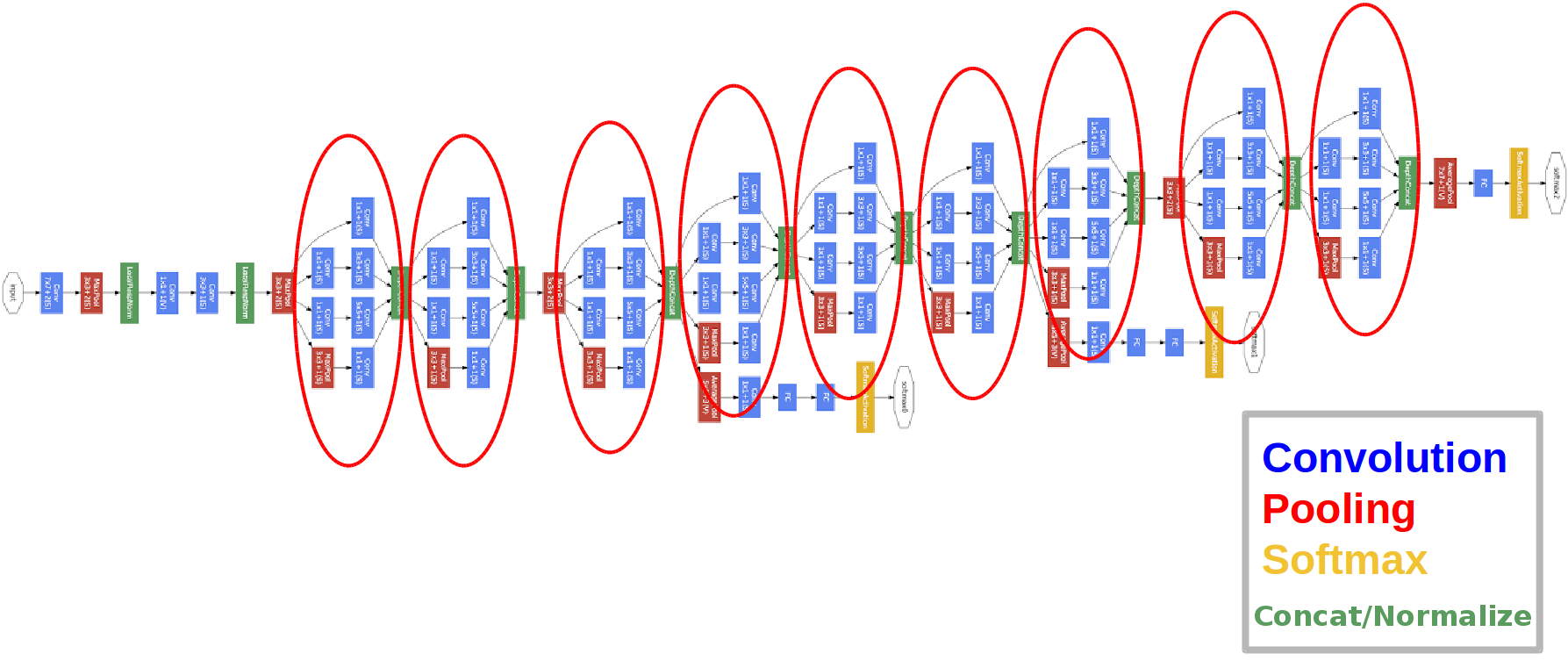
تقديمه في عام 2014.
الدوائر الحمراء هي ما يسمى بوحدة التأسيس.
دعنا نلقي نظرة فاحصة عليها:
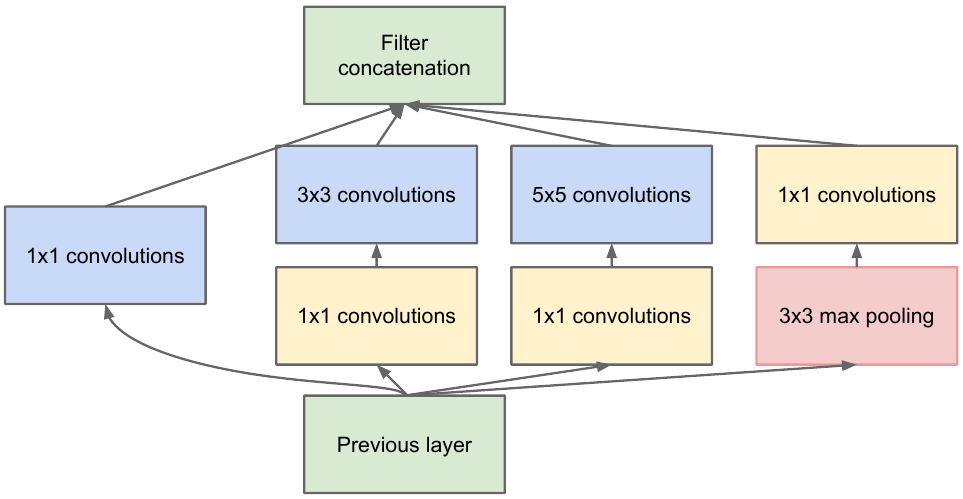
نأخذ خريطة المعالم من الطبقة السابقة ، ونطبق عددًا من التلافيفات بفلاتر مختلفة عليها ، ثم نجمع الخانة الناتجة. الحدس بسيط: نريد الحصول على تمثيلات مختلفة لخريطة الميزات الخاصة بنا باستخدام مرشحات ذات أحجام مختلفة. يتم استخدام التلافيف 1 × 1 حتى لا يزيد عدد القنوات كثيرًا بعد كل كتلة بداية. أولئك. عندما تحتوي خريطة المعالم على عدد كبير من القنوات ، ويريدون تقليل هذا الرقم دون تغيير ارتفاع وعرض خريطة المعالم ، استخدم التفاف 1 × 1.
هناك أيضًا ثلاث كتل مصنف في الشبكة ، هكذا تبدو إحداها (تلك الموجودة على اليمين لنا):

مع هذا البناء ، يصل التدرج اللوني "أفضل" من طبقات الإخراج إلى طبقات الإدخال أثناء الانتشار الخلفي للخطأ.
لماذا نحتاج إلى ناتجين إضافيين للشبكة؟ الأمر كله يتعلق بما يسمى مشكلة التدرج اللوني التلاشي :
خلاصة القول هي أنه عند التكاثر العكسي لخطأ ما ، يميل التدرج اللوني إلى الصفر. وكلما كانت الشبكة أعمق ، كانت أكثر عرضة لهذه الظاهرة. لماذا يحدث ذلك؟ عندما نمر للخلف ، ننتقل من المخرجات إلى المدخلات ، ونحسب تدرجات الدوال المعقدة. مشتق دالة معقدة ( قاعدة السلسلة) هو في الأساس عملية الضرب. وهكذا ، بضرب بعض القيم في الطريق من المخرجات إلى المدخلات ، نلتقي بأرقام قريبة من الصفر ، ونتيجة لذلك ، لا يتم تحديث أوزان الشبكة العصبية عمليًا. هذه مشكلة جزئية في وظائف التنشيط السيني التي لها مخرجاتها في بعض النطاق الثابت. حسنًا ، تم حل هذه المشكلة جزئيًا باستخدام وظيفة التنشيط ReLu. لماذا جزئيا؟ لأن لا أحد يعطي ضمانات لقيم المعلمات المدربة وتمثيل كائن الإدخال في جميع خرائط المعالم.
مهم:
- تحتوي الشبكة على 22 طبقة (وهذا أكثر بقليل من الشبكة السابقة).
- عدد المعلمات المدربة يساوي خمسة ملايين ، وهو أقل بعدة مرات من الشبكتين السابقتين.
- مظهر الحزمة 1x1.
- يتم استخدام كتل التأسيس.
- بدلاً من الطبقات المتصلة بالكامل ، الآن 1 × 1 تلافيف ، مما يقلل العمق ، ونتيجة لذلك ، يقلل من أبعاد الطبقات المتصلة بالكامل وما يسمى بتجميع الحواف العالمية (يمكنك قراءة المزيد هنا ).
- تحتوي البنية على 3 مخرجات (يتم وزن الإجابة النهائية).
ResNet
العمارة (متغير ResNet-34): تم طرحه
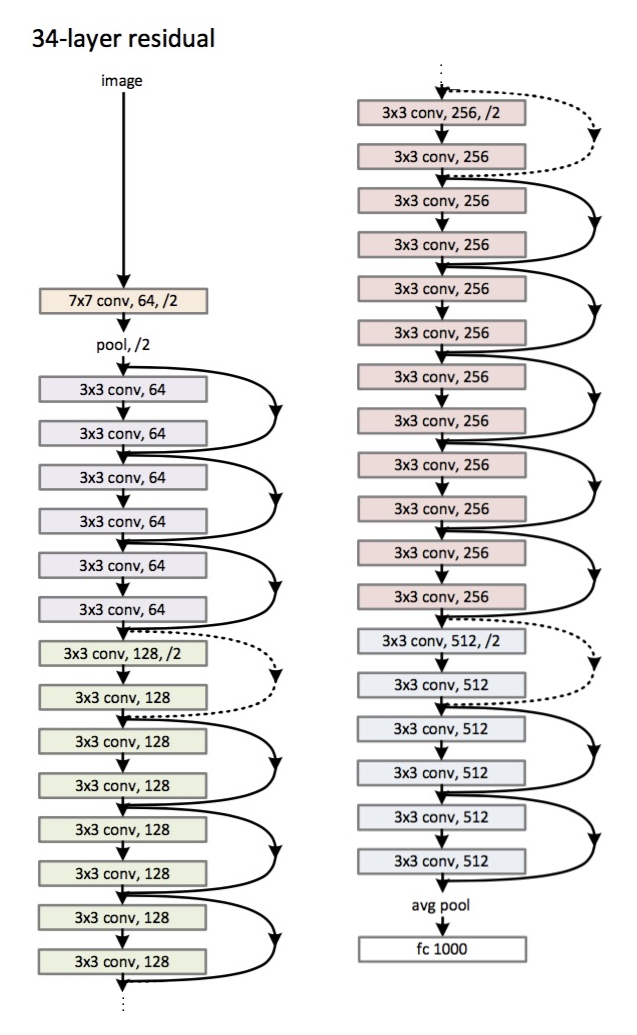
في عام 2015.
الابتكار الرئيسي هو عدد كبير من الطبقات وما يسمى بالكتل المتبقية. يتم استخدام هذه الكتل لمكافحة مشكلة التدرج المتلاشي. الاتصال بين هذه الكتل المتبقية يسمى اختصار (الأسهم في الصورة). الآن ، باستخدام هذه الاختصارات ، سيصل التدرج اللوني إلى جميع المعلمات الضرورية ، وبالتالي تدريب الشبكة :)
هام:
- بدلاً من الطبقات المتصلة بالكامل - متوسط التجميع العالمي.
- الكتل المتبقية.
- لقد تفوقت الشبكة على البشر في التعرف على الصور على مجموعة بيانات ImageNet (أعلى 5 أخطاء).
- تم استخدام التطبيع الدفعي لأول مرة.
- يتم استخدام تقنية تهيئة الأوزان (الحدس: من تهيئة معينة للأوزان ، تتقارب الشبكة (تتعلم) بشكل أسرع وأفضل).
- أقصى عمق 152 طبقة!
استطرادية صغيرة
مشكلة التدرج المتلاشي مناسبة لجميع الشبكات العصبية العميقة.
هناك أيضًا خصمه - مشكلة التدرج المتفجر ، والتي تتعلق أيضًا بجميع الشبكات العصبية العميقة. خلاصة القول واضحة من الاسم - يصبح التدرج كبيرًا جدًا ، مما يتسبب في NaN (ليس رقمًا ، لا نهاية). الحل واضح - للحد من قيمة التدرج ، وإلا - لتقليل قيمته (تطبيع). هذه التقنية تسمى "القطع".
خاتمة
في عام 2019 ، ظهر مقال عن عائلة جديدة من البنى - EfficientNet.
أوصي باتباع أحدث الاتجاهات في مختلف المهام والمجالات المتعلقة بالتعلم الآلي هنا . في هذا المورد ، يمكنك تحديد مهمة (على سبيل المثال ، تصنيف الصورة) ومجموعة بيانات (على سبيل المثال ، ImageNet) وإلقاء نظرة على جودة بعض البنى ، ومعلومات إضافية عنها. على سبيل المثال ، تحتل شبكة FixEfficientNet-L2 المرتبة الأولى المشرفة في تصنيف الصور في مجموعة بيانات ImageNet (دقة أعلى 1).
في المقالات التالية ، سنتحدث عن نقل التعلم ، واكتشاف الكائن ، والتجزئة.