
وفقًا لمزحة معروفة ، يجب وضع جميع المذكرات في المكتبات في قسم "الخيال العلمي". لكن في حالتي ، هذا صحيح! منذ زمن بعيد ،
3D Talking Heads - هذا تمثال نصفي من البرونز يلتصق اللسان ويغمز لماكس بلانك ؛ قرد ينسخ تعابير وجهك في الوقت الحقيقي ؛ هذا نموذج ثلاثي الأبعاد لرئيس معروف تمامًا لنائب رئيس شركة Intel ، تم إنشاؤه تلقائيًا بالكامل من الفيديو بمشاركته ، وأكثر من ذلك بكثير ... لكن أول الأشياء أولاً.
فيديو اصطناعي: 3D Talking Heads المتوافق مع MPEG-4 هو الاسم الكامل للمشروع الذي تم تنفيذه في مركز إنتل للبحث والتطوير في نيجني نوفغورود في 2000-2003. كان التطوير عبارة عن مجموعة من ثلاث تقنيات رئيسية يمكن استخدامها معًا وبشكل منفصل في العديد من التطبيقات المتعلقة بإنشاء وتحريك الشخصيات الناطقة ثلاثية الأبعاد الاصطناعية.
- التعرف التلقائي وتتبع تعابير الوجه وحركات رأس الإنسان في تسلسل الفيديو. في هذه الحالة ، لا يتم تقييم زوايا دوران الرأس وإمالته في جميع المستويات فحسب ، بل يتم أيضًا تقييم الخطوط الخارجية والداخلية للشفتين والأسنان أثناء المحادثة ، وموضع الحاجبين ، ودرجة تغطية العين وحتى اتجاه النظرة.
- الرسوم المتحركة التلقائية في الوقت الفعلي لنماذج الرأس ثلاثية الأبعاد شبه التعسفية وفقًا لمعلمات الرسوم المتحركة التي تم الحصول عليها باستخدام خوارزميات التعرف والتتبع من النقطة الأولى وكذلك من أي مصادر أخرى.
- إنشاء تلقائي لنموذج ثلاثي الأبعاد واقعي لرأس شخص معين باستخدام إما صورتين من النموذج الأولي (منظران أمامي وجانبي) ، أو تسلسل فيديو يحول فيه الشخص رأسه من كتف إلى آخر.
ومكافأة أخرى - التقنيات ، أو بالأحرى ، بعض الحيل للعرض الواقعي لـ "الرؤوس الناطقة" في الوقت الفعلي ، مع الأخذ في الاعتبار قيود أداء الأجهزة وقدرات البرامج التي كانت موجودة في أوائل القرن الحادي والعشرين.
والرابط بين هذه النقاط الثلاث والنصف ، وكذلك الارتباط بـ Intel ، هو أربعة أحرف ورقم واحد: MPEG-4.
MPEG-4
قلة من الناس يعرفون أن معيار MPEG-4 ، الذي ظهر في عام 1998 ، بالإضافة إلى ترميز مقاطع الفيديو والصوت العادية والحقيقية ، يوفر ترميز المعلومات حول الكائنات الاصطناعية ورسومها المتحركة - ما يسمى بالفيديو التركيبي. أحد هذه الأشياء هو وجه بشري ، وبشكل أكثر دقة ، رأس مُعرَّف كسطح مثلث - شبكة في مساحة ثلاثية الأبعاد. يحدد MPEG-4 84 نقطة خاصة على وجه الشخص - نقاط الميزة (FP): الزوايا ونقاط المنتصف للشفتين والعينين والحاجبين وطرف الأنف ، إلخ.
يتم تطبيق معلمات الرسوم المتحركة للوجه (FAP) على هذه النقاط الخاصة (أو على النموذج بأكمله في حالة المنعطفات والميل) ، واصفة التغيير في الوضع وتعبيرات الوجه مقارنة بالحالة المحايدة.
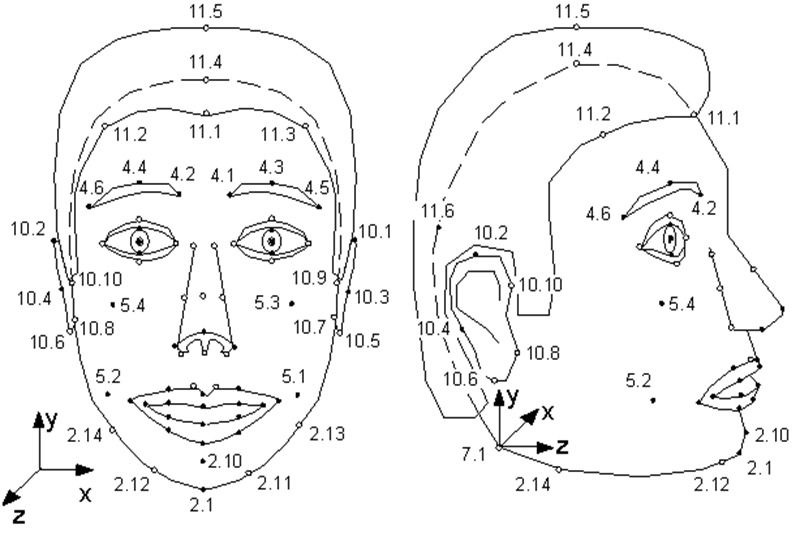
رسم توضيحي من مواصفات MPEG-4. النقاط الفردية للنموذج. كما ترون ، يمكن للعارضة أن تشم أذنيها وتهزها.
أي أن وصف كل إطار من مقاطع الفيديو الاصطناعية التي تُظهر شخصية ناطقة يبدو كمجموعة صغيرة من المعلمات التي يجب على مفكك الشفرة MPEG-4 بواسطتها تحريك النموذج.
أي نموذج؟ MPEG-4 لديه خياران. إما أن يتم إنشاء النموذج بواسطة المشفر ونقله إلى وحدة فك التشفير مرة واحدة في بداية التسلسل ، أو أن وحدة فك التشفير لها نموذجها الخاص ، والذي يتم استخدامه في الرسوم المتحركة.
في الوقت نفسه ، متطلبات MPEG-4 الوحيدة للنموذج: التخزين في VRML- التنسيق ووجود نقاط خاصة. بمعنى ، يمكن أن يكون النموذج نسخة واقعية لشخص يستخدم FAP للرسوم المتحركة ، بالإضافة إلى نموذج لأي شخص آخر ، وحتى غلاية تتحدث - الشيء الرئيسي هو أنه ، بالإضافة إلى الأنف ، لديه فم وعينان.

أحد النماذج المتوافقة مع MPEG-4 هو الأكثر ابتسامة
بالإضافة إلى الكائن الرئيسي "الوجه" ، يصف MPEG-4 الكائنات المستقلة مثل "الفك العلوي" و "الفك السفلي" و "اللسان" و "العيون" ، والتي يتم تعيين نقاط خاصة عليها أيضًا. ولكن إذا كان بعض النماذج لا يحتوي على هذه الكائنات ، فعندئذٍ لا يتم استخدام FAPs المقابلة بواسطة وحدة فك التشفير.

- نموذج ، عارضة أزياء ، لماذا لديك عيون وأسنان كبيرة؟ - لتحريك نفسك بشكل أفضل!
من أين تأتي نماذج الرسوم المتحركة المخصصة؟ كيف أحصل على FAP؟ وأخيرًا ، كيف يمكنك تنفيذ الرسوم المتحركة الواقعية والعرض بناءً على FAPs؟ لا يقدم MPEG-4 أي إجابات على كل هذه الأسئلة - تمامًا مثل أي معيار لضغط الفيديو لا يذكر شيئًا عن عملية التصوير ومحتوى الأفلام التي يشفرها.
إلى أي مدى وصل التقدم؟ حتى معجزات غير مسبوقة!
بالطبع ، يمكن إنشاء كل من النموذج والرسوم المتحركة يدويًا بواسطة فنانين محترفين ، حيث يقضون عشرات الساعات عليها ويتلقون عشرات المئات من الدولارات. لكن هذا يضيق نطاق التكنولوجيا بشكل كبير ، مما يجعلها غير قابلة للتطبيق على المستوى الصناعي. وهناك العديد من الاستخدامات المحتملة لهذه التقنية ، والتي تقوم في الواقع بضغط إطارات الفيديو عالية الدقة إلى عدة بايت (أوه ، من المؤسف عدم وجود أي فيديو). بادئ ذي بدء ، الشبكات - الألعاب والتعليم والاتصال (مؤتمرات الفيديو) باستخدام شخصيات تركيبية.
كانت مثل هذه التطبيقات ذات صلة بشكل خاص قبل 20 عامًا ، عندما كان لا يزال الوصول إلى الإنترنت باستخدام أجهزة المودم ، وبدا الإنترنت غير المحدود للجيجابت وكأنه نوع من النقل الآني. ولكن ، كما تظهر الحياة ، في عام 2020 ، لا يزال النطاق الترددي لقنوات الإنترنت يمثل مشكلة في كثير من الحالات. وحتى في حالة عدم وجود مثل هذه المشكلة ، على سبيل المثال ، فإننا نتحدث عن الاستخدام المحلي ، فالحروف الاصطناعية قادرة على الكثير. على سبيل المثال ، "إحياء" ممثل مشهور من القرن الماضي في فيلم ، أو إعطاء فرصة للنظر في عيون المساعدين الصوتيين المشهورين الآن والذين لا يزالون بلا جسد. لكن أولاً ، يجب أن تصبح عملية الانتقال من فيديو حقيقي لشخص يتحدث إلى فيديو اصطناعي تلقائيًا ، أو على الأقل ، مع الحد الأدنى من المشاركة البشرية.
هذا هو بالضبط ما تم تنفيذه في Nizhny Novgorod Intel. نشأت الفكرة أولاً كجزء من تنفيذ مكتبة معالجة MPEG ، التي طورتها إنتل في وقت من الأوقات ، ثم تطورت بعد ذلك ليس فقط لتصبح شركة عرضية كاملة ، ولكن إلى فيلم رائع حقيقي.
علاوة على ذلك ، "صُنع في روسيا" بالكامل - يبدو أن هذا المشروع هو الوحيد لوجود شركة إنتل الروسية بالكامل ، ولم يكن هناك أمين في شركة إنتل بالولايات المتحدة الأمريكية. أعجب جاستن راتنر (رئيس قسم الأبحاث في Intel Labs) بالفكرة أثناء زيارته لنيجني نوفغورود ، وأعطى الضوء الأخضر

Synthetic Valery Fedorovich Kuryakin ، منتج ، مخرج ، كاتب سيناريو ، وفي بعض الأماكن رجل الأعمال البهلواني للمشروع - في ذلك الوقت رئيس مجموعة تطوير Intel.
أولاً ، كان الجمع بين هذه التقنيات المختلفة في مشروع صغير واحد ، يعمل فيه ثلاثة إلى سبعة أشخاص فقط في نفس الوقت ، رائعًا. في تلك السنوات ، كان هناك ما لا يقل عن اثنتي عشرة شركة في العالم تعمل بالفعل في كل من التعرف على الوجوه وتتبعها ، وإنشاء وتحريك "الرؤوس الناطقة". كلهم ، بالطبع ، حققوا إنجازات في بعض المجالات: كان لدى البعض جودة نموذجية ممتازة ، وأظهر البعض رسوم متحركة واقعية للغاية ، ونجح البعض في التعرف والتتبع. لكن لم تتمكن أي شركة واحدة من تقديم مجموعة كاملة من التقنيات التي تسمح لك بإنشاء فيديو اصطناعي بشكل كامل حيث ينسخ نموذج ، مشابه جدًا لنموذجه الأولي ، تعبيرات وجهه وحركاته بشكل مثالي.
كان مشروع Intel 3D Talking Heads هو الأول وفي ذلك الوقت التطبيق الوحيد لدورة كاملة من اتصالات الفيديو بناءً على جميع عناصر ملف التعريف الاصطناعي MPEG-4.

ناقل مشروع إنتاج الحيوانات المستنسخة الاصطناعية من طراز 2003.
ثانياً ، كان الجمع بين الحديد الموجود في ذلك الوقت والحلول التكنولوجية التي تم تنفيذها في المشروع ، فضلاً عن الخطط الخاصة باستخدامها ، رائعًا. لذلك ، في بداية المشروع ، كان لدي Nokia 3310 في جيبي ، وكان هناك Pentium III-500MHz على سطح المكتب ، وتم اختبار الخوارزميات التي كانت مهمة بشكل خاص لأداء العمل في الوقت الفعلي على خادم Pentium 4-1.7 جيجا هرتز مع 128 ميجا بايت من ذاكرة الوصول العشوائي.
في الوقت نفسه ، كنا نأمل أن تعمل نماذجنا قريبًا في الأجهزة المحمولة ، وأن الجودة لن تكون أسوأ من تلك الخاصة بأبطال فيلم الرسوم المتحركة الواقعي بالكمبيوتر " فاينل فانتسي " الذي تم إصداره في ذلك الوقت (2001) .

كان التكلفة 137 مليون دولار لفيلم تم إنشاؤه في مزرعة تصيير تضم حوالي 1000 جهاز كمبيوتر Pentium III. ملصق من www.thefinalfantasy.com
لكن دعنا نرى ما حدث معنا.
التعرف على الوجوه والتتبع ، واكتساب FAP.
تم تقديم هذه التقنية في نسختين:
- وضع الوقت الفعلي (25 إطارًا في الثانية على معالج Pentium 4-1.7 جيجا هرتز المذكور بالفعل) ، عندما يتم تعقب شخص يقف مباشرة أمام كاميرا فيديو متصلة بجهاز كمبيوتر ؛
- ( 1 ), .
في الوقت نفسه ، تمت مراقبة ديناميكيات التغييرات في وضع / حالة الوجه البشري في الوقت الفعلي - يمكننا تقدير زوايا دوران وإمالة الرأس تقريبًا في جميع المستويات ، والدرجة التقريبية لفتح الفم وتمديده ورفع الحاجبين ، والتعرف على الوميض. بالنسبة لبعض التطبيقات ، يكون مثل هذا التقدير التقريبي كافيًا ، ولكن إذا كنت بحاجة إلى تتبع تعابير وجه الشخص بدقة ، فستكون هناك حاجة إلى خوارزميات أكثر تعقيدًا ، مما يعني خوارزميات أبطأ.
في وضع عدم الاتصال بالإنترنت ، أتاحت تقنيتنا تقييم ليس فقط موضع الرأس ككل ، ولكن أيضًا التعرف بدقة على الخطوط الخارجية والداخلية للشفاه والأسنان وتتبعها أثناء المحادثة ، وموضع الحاجبين ، ودرجة تغطية العين ، وحتى إزاحة التلاميذ - اتجاه النظرة.
للتعرف والتتبع ، تم استخدام مجموعة من خوارزميات رؤية الكمبيوتر المعروفة ، والتي تم تنفيذ بعضها بالفعل في مكتبة OpenCV التي تم إصدارها حديثًا - على سبيل المثال ، التدفق البصري ، بالإضافة إلى طرقنا الأصلية الخاصة بنا على أساس المعرفة المسبقة بشكل الكائنات المقابلة. على وجه الخصوص - على نسختنا المحسّنة من طريقة القوالب القابلة للتشوه ، والتي حصل المشاركون في المشروع على براءة اختراع لها .
تم تنفيذ التكنولوجيا في شكل مكتبة من الوظائف التي استقبلت إطارات الفيديو ذات الوجه البشري كمدخلات وإخراج FAPs المقابلة.
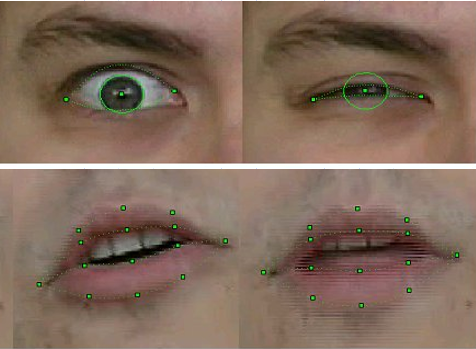
جودة التعرف وتتبع عينة FP 2003
بالطبع ، كانت التكنولوجيا غير كاملة. فشل التعرف والتتبع إذا كان لدى الشخص الموجود في الإطار شارب أو نظارات أو تجاعيد عميقة. لكن لمدة ثلاث سنوات من العمل ، تحسنت الجودة بشكل ملحوظ. إذا كان في الإصدارات الأولى لنماذج التعرف على الحركة عند تصوير مقطع فيديو ، كان لا بد من لصق علامات خاصة على نقاط FP المقابلة للوجه - دوائر الورقة البيضاء التي تم الحصول عليها بكمة مكتب ، ثم في النهاية من المشروع لم يكن هناك شيء من هذا القبيل مطلوبًا ، بالطبع. علاوة على ذلك ، تمكنا من تتبع موضع الأسنان واتجاه النظرة بثبات - وهذا بدقة الفيديو من كاميرات الويب في ذلك الوقت ، حيث كان من الصعب تمييز هذه التفاصيل!

هذه ليست جدري الماء ، لكنها لقطة من "الطفولة" لتكنولوجيا التعرف. المهندس الرئيسي لشركة Intel ، وفي ذلك الوقت - قام ألكسندر بوفيرين ، الموظف المبتدئ في Intel ، بتعليم نموذج تركيبي لقراءة الشعر
حيوية
كما قيل عدة مرات ، يتم تحديد الرسوم المتحركة لنموذج في MPEG-4 بالكامل بواسطة FAP. وكل شيء سيكون بسيطًا ، لولا مشكلتين.
أولاً ، حقيقة أن FAPs من تسلسل الفيديو يتم استخلاصها في 2D ، والنموذج ثلاثي الأبعاد ، وهو مطلوب لإكمال الإحداثي الثالث بطريقة ما. وهذا يعني أن الابتسامة الترحيبية في الملف الشخصي (ويجب أن يكون المستخدمون قادرين على رؤية هذا الملف الشخصي ، وإلا فلن يكون هناك معنى في العرض ثلاثي الأبعاد) يجب ألا تتحول إلى ابتسامة مشؤومة.
ثانيًا ، كما قيل أيضًا ، تصف FAPs حركة النقاط المفردة ، والتي يوجد منها حوالي ثمانين في النموذج ، بينما يتكون النموذج الواقعي إلى حد ما ككل على الأقل من عدة آلاف من القمم (في حالتنا ، من أربعة إلى ثمانية آلاف) ، وهناك حاجة إلى الخوارزميات لحساب إزاحة جميع النقاط الأخرى في النموذج بناءً على عمليات إزاحة FP.
أي أنه من الواضح أنه عندما يتم تدوير الرأس بزاوية متساوية ، فإن جميع النقاط ستلتف ، ولكن عند الابتسام ، حتى لو كان الأمر يصل إلى الأذنين ، يجب أن يتلاشى "السخط" من تحول زاوية الفم تدريجياً ، حرك الخد ، وليس الأذنين. علاوة على ذلك ، يجب أن يحدث ذلك تلقائيًا وواقعيًا لأي طراز بأي عرض للفم وشبكة هندسية حوله. لحل هذه المشاكل ، تم إنشاء خوارزميات الرسوم المتحركة في المشروع. كانت تستند إلى نموذج عضلي كاذب ، والذي يصف ببساطة العضلات التي تتحكم في تعابير الوجه.
وبعد ذلك ، لكل نموذج وكل FAP ، تم تحديد "منطقة التأثير" بشكل تلقائي - الرؤوس المشاركة في الإجراء المقابل ، والتي تم حساب حركاتها مع مراعاة علم التشريح والهندسة - الحفاظ على نعومة السطح وتوصيله. أي أن الرسوم المتحركة تتكون من جزأين - أولي ، يتم تنفيذه في وضع عدم الاتصال ، حيث تم إنشاء معاملات معينة لرؤوس الشبكة وإدخالها في الجدول ، وعبر الإنترنت ، حيث تم تطبيق الرسوم المتحركة في الوقت الفعلي على النموذج ، مع مراعاة البيانات من الجدول.

الابتسام ليس سهلاً على نموذج ثلاثي الأبعاد ومنشئيه
إنشاء نموذج ثلاثي الأبعاد لشخص معين.
في الحالة العامة ، تكون مهمة إعادة بناء كائن ثلاثي الأبعاد من صوره ثنائية الأبعاد صعبة للغاية. أي أن خوارزميات حلها معروفة للبشرية منذ فترة طويلة ، ولكن في الممارسة العملية ، بسبب العديد من العوامل ، فإن النتيجة بعيدة عن النتيجة المرجوة. وهذا ملحوظ بشكل خاص في حالة إعادة بناء شكل وجه الشخص - هنا يمكنك أن تتذكر نماذجنا الأولى بعيون على شكل ثمانية (ظل الظل من الرموش في الصور الأصلية غير ناجح) أو تشعب بسيط في الأنف (لا يمكن استعادة سبب السنوات الماضية).
ولكن في حالة الرؤوس الناطقة MPEG-4 ، تكون المهمة مبسطة إلى حد كبير ، لأن مجموعة ملامح وجه الإنسان (الأنف والفم والعينين ، إلخ) هي نفسها لجميع الأشخاص ، والاختلافات الخارجية التي نميز بها جميعًا (وبرامج رؤية الكمبيوتر) الناس من بعضهم البعض "هندسية" - الحجم / النسب وموقع هذه الميزات و "الملمس" - الألوان والتضاريس. لذلك ، يفترض أحد ملفات تعريف فيديو MPEG-4 التركيبي ، المعايرة ، الذي تم تنفيذه في المشروع ، أن وحدة فك التشفير لديها نموذج معمم لـ "شخص مجرد" مخصص لشخص معين باستخدام صورة أو تسلسل فيديو.
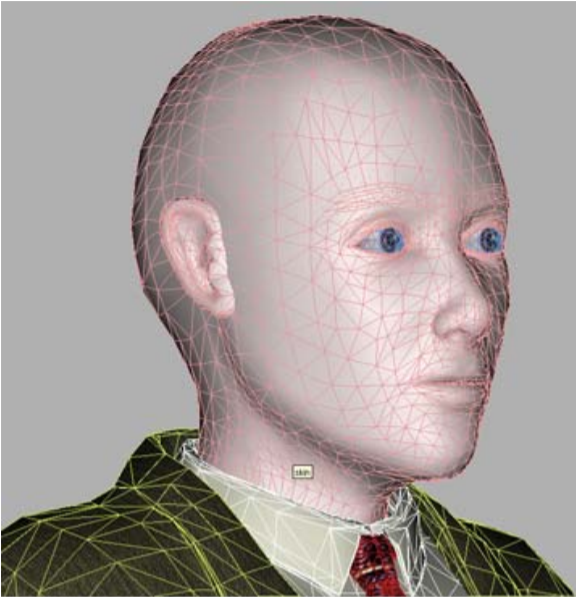
لدينا "رجل كروي في فراغ" - نموذج للتخصيص
أي أن التشوهات العامة والمحلية للشبكة ثلاثية الأبعاد تحدث لمطابقة نسب ملامح وجه النموذج الأولي المحددة في الصورة / الفيديو ، وبعد ذلك يتم تطبيق "نسيج" النموذج الأولي على النموذج - أي نسيج تم إنشاؤه من نفس صور الإدخال. والنتيجة هي نموذج اصطناعي. يتم ذلك مرة واحدة لكل نموذج ، بالطبع دون اتصال ، وبالطبع ليس بهذه السهولة.
بادئ ذي بدء ، يلزم تسجيل أو تصحيح الصور المدخلة - إحضارها إلى نظام إحداثي واحد يتزامن مع نظام إحداثيات النموذج ثلاثي الأبعاد. علاوة على ذلك ، في صور الإدخال ، من الضروري اكتشاف النقاط المفردة ، وبناءً على موقعها ، قم بتشويه النموذج ثلاثي الأبعاد ، على سبيل المثال ، باستخدام طريقة وظائف الأساس الشعاعيوبعد ذلك ، باستخدام خوارزميات خياطة البانوراما ، يمكنك إنشاء نسيج من صورتين أو أكثر من الصور المدخلة ، أي "مزجها" بالنسب الصحيحة للحصول على أقصى قدر من المعلومات المرئية ، وكذلك تعويض الاختلاف في الإضاءة والنغمة ، والتي تكون موجودة دائمًا حتى في الصور الملتقطة مع نفس إعدادات الكاميرا (وهذا ليس هو الحال دائمًا) ، ويمكن ملاحظته جدًا عند دمج هذه الصور.

هذا ليس جزءًا من أفلام الرعب ، ولكنه نسيج نموذج ثلاثي الأبعاد بواسطة Pat Gelsinger ، تم إنشاؤه بإذن منه عندما تم عرض المشروع في Intel Developer Forum في عام 2003.
تم تنفيذ الإصدار الأولي من تقنية تخصيص النموذج استنادًا إلى صورتين بواسطة المشاركين في المشروع أنفسهم في Intel. ولكن عند الوصول إلى مستوى معين من الجودة وإدراك حدود قدراتهم ، تقرر نقل هذا الجزء من العمل إلى مجموعة البحث في جامعة موسكو الحكومية ، والتي لديها خبرة في هذا المجال. كانت نتيجة عمل الباحثين من جامعة موسكو الحكومية تحت قيادة دينيس إيفانوف هو تطبيق "Head Calibration Environment" ، الذي أجرى جميع العمليات المذكورة أعلاه لإنشاء نموذج شخصي لشخص من صورته في كامل الوجه والملف الشخصي.
النقطة الدقيقة الوحيدة هي أن التطبيق لم يتم دمجه مع وحدة التعرف على الوجوه الموصوفة أعلاه ، والتي تم تطويرها في مشروعنا ، لذلك كان لابد من تمييز النقاط الخاصة في الصورة اللازمة لعمل الخوارزميات يدويًا. بالطبع ، ليس كل الـ 84 ، ولكن فقط الأساسيين ، ونظرًا لأن التطبيق يحتوي على واجهة مستخدم مناسبة ، فقد استغرقت هذه العملية بضع ثوانٍ فقط.
أيضًا ، تم تنفيذ نسخة تلقائية بالكامل من إعادة بناء النموذج من تسلسل فيديو ، حيث يدير الشخص رأسه من كتف إلى آخر. ولكن ، كما قد تتخيل ، كانت جودة النسيج المستخرج من الفيديو أسوأ بكثير من النسيج الذي تم إنشاؤه من صور الكاميرات الرقمية في ذلك الوقت بدقة ~ 4K (3-5 ميجابكسل) ، مما يعني أن النموذج الناتج بدا أقل جاذبية. لذلك ، كان هناك أيضًا نسخة وسيطة تستخدم عدة صور لزوايا دوران مختلفة للرأس.

الصف العلوي أشخاص افتراضيون ، والصف السفلي حقيقي.
ما مدى جودة النتيجة المحققة؟ يجب تقييم جودة النموذج الناتج ليس في حالة ثابتة ، ولكن مباشرة على الفيديو التركيبي من خلال تشابهه مع الفيديو المقابل للفيديو الأصلي. لكن المصطلحات "متشابهة وليست متشابهة" ليست رياضية ، فهي تعتمد على تصور شخص معين ، ومن الصعب فهم كيف يختلف نموذجنا التركيبي ورسومه المتحركة عن النموذج الأولي. بعض الناس يحبونها والبعض الآخر لا. لكن نتيجة ثلاث سنوات من العمل كانت أنه عند عرض النتائج في المعارض المختلفة ، كان على الجمهور أن يشرح في أي نافذة كان الفيديو الحقيقي أمامهم ، وفي أي منها - الفيديو الاصطناعي.
التصور.
لإثبات نتائج جميع التقنيات المذكورة أعلاه ، تم إنشاء مشغل فيديو تركيبي خاص MPEG-4. تلقى المشغل كمدخل ملف VRML بنموذج أو دفق (أو ملف) باستخدام FAP ، بالإضافة إلى تدفقات (ملفات) مع فيديو وصوت حقيقيين للعرض المتزامن مع الفيديو التركيبي مع دعم وضع "الصورة في الصورة". عند عرض مقطع فيديو اصطناعي ، مُنح المستخدم الفرصة لتكبير النموذج ، وكذلك النظر إليه من جميع الجوانب ، ببساطة عن طريق قلب الماوس بزاوية عشوائية.

على الرغم من أن المشغل كان مكتوبًا لنظام التشغيل Windows ، إلا أنه مع مراعاة إمكانية النقل في المستقبل إلى أنظمة تشغيل أخرى ، بما في ذلك الهاتف المحمول. لذلك ، تم اختيار برنامج OpenGL 1.1 "الكلاسيكي" بدون أي ملحقات كمكتبة ثلاثية الأبعاد.
في الوقت نفسه ، لم يعرض اللاعب النموذج فحسب ، بل حاول أيضًا تحسينه ، ولكن ليس لتنميقه ، كما هو معتاد الآن مع نماذج الصور ، ولكن على العكس من ذلك ، جعله واقعيًا قدر الإمكان. وبالتحديد ، البقاء في إطار أبسط إضاءة Phong وعدم وجود تظليل ، ولكن مع متطلبات أداء صارمة ، قامت وحدة العرض الخاصة باللاعب بإنشاء نماذج اصطناعية تلقائيًا: تقليد التجاعيد والرموش القادرة على تضييق وتوسيع حدقة العين بشكل واقعي ؛ ضع أكواب ذات حجم مناسب على النموذج ؛ وأيضًا باستخدام أبسط تتبع للأشعة ، قام بحساب إضاءة (تظليل) اللسان والأسنان عند التحدث.
بالطبع ، لم تعد هذه الأساليب مناسبة الآن ، لكن تذكرها أمر مثير للاهتمام. لذلك ، من أجل تخليق التجاعيد المقلدة ، أي الانحناءات الصغيرة للجلد التي تريح الوجه ، والتي يمكن رؤيتها أثناء تقلص عضلات الوجه ، لم تسمح الأحجام الكبيرة نسبيًا لمثلثات شبكة النموذج بإنشاء طيات حقيقية. لذلك ، تم تطبيق نوع من تقنية رسم الخرائط - رسم الخرائط العادي. بدلاً من تغيير هندسة النموذج ، تغير اتجاه القواعد الطبيعية إلى السطح في الأماكن الصحيحة ، واعتماد مكون الإضاءة المنتشر في كل نقطة على الوضع الطبيعي خلق التأثير المطلوب.

هذه هي الواقعية التركيبية.
لكن اللاعب لم يتوقف عند هذا الحد. لتسهيل استخدام التقنيات ونقلها إلى العالم الخارجي ، تم إنشاء مكتبة كائنات مكتبة الرسوم المتحركة للوجه Intel Facial Animation Library ، والتي تحتوي على وظائف للرسوم المتحركة (تحويل ثلاثي الأبعاد) وتصور النموذج ، بحيث يمكن لأي شخص يريد (ولديه مصدر FAP) استدعاء العديد من الوظائف - "إنشاء مشهد" ، " CreateActor "، يمكن لـ" Animate "تحريك وإظهار نموذجه في تطبيقه.
النتيجة
ماذا أعطتني المشاركة في هذا المشروع شخصيًا؟ بالطبع ، فرصة التعاون مع أشخاص رائعين في تقنيات مثيرة للاهتمام. لقد أخذوني إلى المشروع بسبب معرفتي بالأساليب والمكتبات لتقديم نماذج ثلاثية الأبعاد وتحسين الأداء لـ x86. لكن ، بطبيعة الحال ، لم يكن من الممكن حصر أنفسنا في الأبعاد الثلاثية ، لذلك كان علينا الانتقال إلى أبعاد أخرى. لكتابة لاعب ، كان من الضروري التعامل مع تحليل VRML (لم تكن هناك مكتبات جاهزة لهذا الغرض) ، وإتقان العمل الأصلي مع الخيوط في Windows ، وضمان العمل المشترك لعدة خيوط مع التزامن 25 مرة في الثانية ، مع عدم نسيان تفاعل المستخدم ، وحتى التفكير والتنفيذ واجهه المستخدم. في وقت لاحق ، تم استكمال هذه القائمة بالمشاركة في تحسين خوارزميات تتبع الوجه. والحاجة إلى الدمج المستمر والجمع بين المكونات التي كتبها أعضاء الفريق الآخرون مع اللاعب ،كما أدى تقديم المشروع إلى العالم الخارجي إلى تحسين مهارات الاتصال والتنسيق لدي بشكل كبير.
ماذا قدمت مشاركة إنتل في هذا المشروع؟ نتيجة لذلك ، أنشأ فريقنا منتجًا يمكن أن يكون بمثابة اختبار وإثبات جيدًا لقدرات منصات ومنتجات Intel. علاوة على ذلك ، ساهمت كل من الأجهزة - وحدة المعالجة المركزية ووحدة معالجة الرسومات ، والبرامج - رؤوسنا (الحقيقية والاصطناعية) في تحسين مكتبة OpenCV.
بالإضافة إلى ذلك ، يمكننا القول بأمان أن المشروع ترك بصمة واضحة في التاريخ - نتيجة لعمله ، كتب المشاركون فيه مقالات وقدموا تقارير في مؤتمرات متخصصة حول رؤية الكمبيوتر ورسومات الكمبيوتر ، الروسية ( GraphiCon ) والدولية.
وقد عرضت Intel التطبيقات التجريبية ثلاثية الأبعاد Talking Heads في عشرات المعارض التجارية والمنتديات والمؤتمرات حول العالم.
في هذا الوقت ، تقدمت التكنولوجيا ، بالطبع ، كثيرًا ، مما يسهل إنشاء وتحريك الشخصيات الاصطناعية تلقائيًا. كان هناك تعريف عمق غرفة Intel Real Sense ، وتعلمت الشبكات العصبية القائمة على البيانات الكبيرة كيفية إنشاء صور واقعية للأشخاص ، حتى لو كانت غير موجودة.
ولكن ، مع ذلك ، لا تزال التطورات الخاصة بمشروع 3D Talking Heads ، المنشورة في المجال العام ، قيد النظر حتى الآن.
انظر إلى مكبر الصوت MPEG-4 الصغير ، البالغ من العمر عشرين عامًا تقريبًا ، وأنت: