
يتحول التعلم الآلي أكثر فأكثر من النماذج المصممة يدويًا إلى خطوط الأنابيب المحسنة تلقائيًا باستخدام أدوات مثل H20 و TPOT و sklearn تلقائيًا . تهدف هذه المكتبات ، إلى جانب تقنيات مثل البحث العشوائي ، إلى تبسيط اختيار النموذج وضبط أجزاء من التعلم الآلي من خلال إيجاد أفضل نموذج لمجموعة بيانات دون أي تدخل يدوي. ومع ذلك ، فإن تطوير الكائن ، الذي يمكن القول إنه الجانب الأكثر قيمة لخطوط أنابيب التعلم الآلي ، لا يزال بشريًا بالكامل.
ميزات التصميم ( هندسة الميزات) ، والمعروفة أيضًا باسم إنشاء الميزات ، هي عملية إنشاء ميزات جديدة من البيانات الحالية لتدريب نموذج التعلم الآلي. قد تكون هذه الخطوة أكثر أهمية من النموذج الفعلي المستخدم لأن خوارزمية التعلم الآلي لا تتعلم إلا من البيانات التي نقدمها لها ، وخلق ميزات ذات صلة بالمهمة أمر ضروري للغاية (راجع المقالة الممتازة "A قليل الأشياء المفيدة أشياء يجب معرفتها عن التعلم الآلي " ).
عادةً ما يكون تطوير الميزة عبارة عن عملية يدوية طويلة تستند إلى معرفة المجال والحدس ومعالجة البيانات. يمكن أن تكون هذه العملية شاقة للغاية ، وستكون الخصائص النهائية محدودة بكل من الذات البشرية والوقت. يهدف التصميم التلقائي للميزات إلى مساعدة عالم البيانات تلقائيًا على إنشاء العديد من العناصر المرشحة من مجموعة بيانات يمكن من خلالها اختيار الأفضل واستخدامه للتدريب.
في هذه المقالة ، سنلقي نظرة على مثال لاستخدام التطوير التلقائي للميزات مع مكتبة Python featuretools.... سنستخدم مجموعة بيانات نموذجية لإظهار الأساسيات (احترس من المنشورات المستقبلية باستخدام بيانات حقيقية). الكود الكامل من هذه المقالة متاح على GitHub .
أساسيات تطوير الميزة
تطوير الخصائص يعني إنشاء خصائص إضافية من البيانات الموجودة ، والتي غالبًا ما تنتشر عبر العديد من الجداول ذات الصلة. يتطلب تطوير الميزة استخراج المعلومات ذات الصلة من البيانات ووضعها في جدول واحد يمكن استخدامه بعد ذلك لتدريب نموذج التعلم الآلي.
تستغرق عملية إنشاء الخصائص وقتًا طويلاً ، حيث تستغرق عادةً عدة خطوات لإنشاء كل خاصية جديدة ، خاصة عند استخدام معلومات من عدة جداول. يمكننا عمليات خلق ميزة مجموعة إلى فئتين: التحولات و تجمعات . دعونا نلقي نظرة على بعض الأمثلة لرؤية هذه المفاهيم في العمل.
تحويليعمل على جدول واحد (من حيث Python ، الجدول هو فقط Pandas
DataFrame) ، وإنشاء ميزات جديدة من عمود واحد أو أكثر. على سبيل المثال ، إذا كان لدينا جدول العملاء أدناه ،
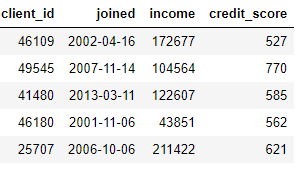
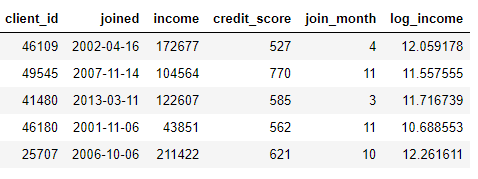
يمكننا إنشاء ميزات من خلال العثور على الشهر من عمود
joinedأو أخذ اللوغاريتم الطبيعي من عمود income. كلاهما تحويل لأنهما يستخدمان معلومات من جدول واحد فقط.
من ناحية أخرى ، يتم تنفيذ التجميعات عبر الجداول واستخدام علاقة رأس بأطراف لحالات المجموعة ثم حساب الإحصائيات. على سبيل المثال ، إذا كان لدينا جدول آخر يحتوي على معلومات حول قروض العملاء ، حيث يمكن لكل عميل الحصول على عدة قروض ، فيمكننا حساب الإحصائيات مثل قيم القروض المتوسطة والحد الأقصى والحد الأدنى لكل عميل.
تتضمن هذه العملية تجميع جدول القروض حسب العميل ، وحساب التجميع ، ثم دمج البيانات المستلمة مع بيانات العميل. هذه هي الطريقة التي يمكننا القيام بها في Python باستخدام لغة Pandas .
import pandas as pd
# Group loans by client id and calculate mean, max, min of loans
stats = loans.groupby('client_id')['loan_amount'].agg(['mean', 'max', 'min'])
stats.columns = ['mean_loan_amount', 'max_loan_amount', 'min_loan_amount']
# Merge with the clients dataframe
stats = clients.merge(stats, left_on = 'client_id', right_index=True, how = 'left')
stats.head(10)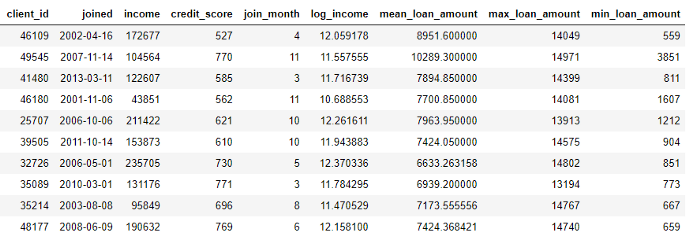
هذه العمليات ليست معقدة في حد ذاتها ، ولكن إذا كان لدينا مئات المتغيرات متناثرة عبر عشرات الجداول ، فلا يمكن إجراء هذه العملية يدويًا. من الناحية المثالية ، نحتاج إلى حل يمكنه إجراء عمليات التحويل والتجميع تلقائيًا عبر جداول متعددة ودمج البيانات الناتجة في جدول واحد. في حين أن Pandas مورد رائع ، لا يزال هناك العديد من التلاعب بالبيانات التي نريد القيام بها يدويًا! (لمزيد من المعلومات حول تصميم الميزات يدويًا ، راجع دليل Python Data Science Handbook الممتاز .)
المميزات
لحسن الحظ ، إن الأدوات المميزة هي الحل الذي نبحث عنه تمامًا. تقوم مكتبة Python مفتوحة المصدر تلقائيًا بإنشاء العديد من السمات من مجموعة من الجداول ذات الصلة. تعتمد أدوات الميزات على تقنية تعرف باسم " Deep Feature Synthesis " والتي تبدو أكثر إثارة للإعجاب مما هي عليه في الواقع (يأتي الاسم من الجمع بين ميزات متعددة ، وليس لأنه يستخدم التعلم العميق!).
يجمع Deep Feature Synthesis بين العديد من عمليات التحويل والتجميع (تسمى بدائية السمةفي قاموس FeatureTools) لإنشاء ميزات من البيانات المنتشرة عبر العديد من الجداول. مثل معظم الأفكار في التعلم الآلي ، إنها طريقة معقدة تعتمد على مفاهيم بسيطة. من خلال دراسة لبنة واحدة في كل مرة ، يمكننا تكوين فهم جيد لهذه التقنية القوية.
أولاً ، دعنا نلقي نظرة على البيانات من مثالنا. لقد رأينا بالفعل شيئًا من مجموعة البيانات أعلاه ، وتبدو مجموعة الجداول الكاملة كما يلي:
clients: معلومات أساسية عن العملاء في جمعية الائتمان. لكل عميل صف واحد فقط في إطار البيانات هذا
loans: قروض للعملاء. لكل رصيد صفه الخاص به فقط في إطار البيانات هذا ، ولكن يمكن للعملاء الحصول على أرصدة متعددة.
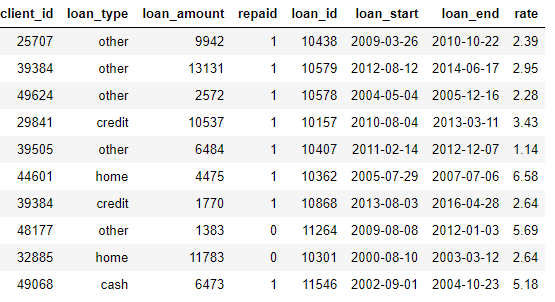
payments: دفعات القرض. تحتوي كل دفعة على سطر واحد فقط ، ولكن سيكون لكل قرض مدفوعات متعددة.
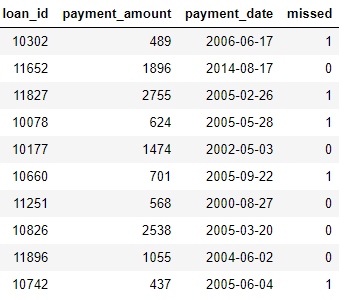
إذا كانت لدينا مهمة للتعلم الآلي مثل توقع ما إذا كان العميل سوف يسدد قرضًا مستقبليًا ، فنحن نريد دمج جميع معلومات العميل في جدول واحد. ترتبط الجداول (عبر
client_idو المتغيرات loan_id)، ويمكن أن نستخدم سلسلة من التحولات وتجمعات لإتمام العملية يدويا. ومع ذلك ، سنرى قريبًا أنه يمكننا بدلاً من ذلك استخدام أدوات مميزة لأتمتة العملية.
الكيانات ومجموعات الكيانات (الكيانات ومجموعات الكيانات)
المفهومان الأولان للأدوات المميزة هما الكيانات ومجموعات الكيانات . الكيان مجرد طاولة (أو إذا كنت تعتقد في Pandas). EntitySet عبارة عن مجموعة من الجداول والعلاقات بينهما. تخيل مجموعة الكيانات هي مجرد هيكل بيانات Python آخر مع الأساليب والسمات الخاصة به. يمكننا إنشاء مجموعة فارغة من الكيانات في أدوات مميزة باستخدام ما يلي:
DataFrame
import featuretools as ft
# Create new entityset
es = ft.EntitySet(id = 'clients')الآن نحن بحاجة إلى إضافة كيانات. يجب أن يكون لكل كيان فهرس ، وهو عمود يحتوي على جميع العناصر الفريدة. بمعنى ، يجب أن تظهر كل قيمة في الفهرس مرة واحدة فقط في الجدول. الفهرس الموجود في إطار البيانات
clientsهو client_idأن كل عميل لديه صف واحد فقط في إطار البيانات هذا. نضيف كيانًا بفهرس موجود إلى مجموعة الكيانات باستخدام بناء الجملة التالي:
# Create an entity from the client dataframe
# This dataframe already has an index and a time index
es = es.entity_from_dataframe(entity_id = 'clients', dataframe = clients,
index = 'client_id', time_index = 'joined')يحتوي إطار البيانات
loansأيضًا على فهرس فريد loan_id، ويكون بناء الجملة لإضافته إلى مجموعة كيان هو نفسه بالنسبة إلى clients. ومع ذلك ، لا يوجد فهرس فريد لإطار بيانات الدفع. عندما نضيف هذا الكيان إلى مجموعة الكيان ، نحتاج إلى تمرير معلمة make_index = Trueوتحديد اسم الفهرس. بالإضافة إلى ذلك ، في حين أن الأدوات المميزة ستستنتج تلقائيًا نوع البيانات لكل عمود في كيان ، يمكننا تجاوز ذلك بتمرير قاموس لأنواع الأعمدة إلى المعلمة variable_types.
# Create an entity from the payments dataframe
# This does not yet have a unique index
es = es.entity_from_dataframe(entity_id = 'payments',
dataframe = payments,
variable_types = {'missed': ft.variable_types.Categorical},
make_index = True,
index = 'payment_id',
time_index = 'payment_date')بالنسبة إلى إطار البيانات هذا ، على الرغم من أنه
missedعدد صحيح ، إلا أنه ليس متغيرًا رقميًا حيث يمكن أن يأخذ قيمتين منفصلتين فقط ، لذلك نقول للأدوات المميزة لمعاملته كمتغير فئوي. بعد إضافة إطارات البيانات إلى مجموعة الكيانات ، نقوم بفحص أي منها:
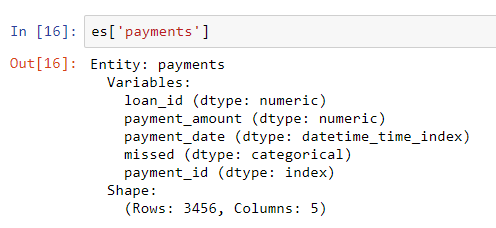
تم استنتاج أنواع الأعمدة بشكل صحيح مع المراجعة المحددة. بعد ذلك ، نحتاج إلى توضيح كيفية ارتباط الجداول في مجموعة الكيانات.
العلاقات بين الجداول
أفضل طريقة لتمثيل العلاقة بين جدولين هي عن طريق القياس بين الوالدين والطفل . علاقة رأس بأطراف: يمكن أن يكون لكل من الوالدين أطفال متعددين. في منطقة الجدول ، يحتوي الجدول الأصل على صف واحد لكل أصل ، ولكن يمكن أن يحتوي الجدول الفرعي على صفوف متعددة تتوافق مع العديد من الأطفال من نفس الأصل.
على سبيل المثال ، في مجموعة بياناتنا ، يكون
clientsالإطار هو الأصل loansللإطار. كل عميل لديه سطر واحد فقط clients، ولكن يمكن أن يكون له خطوط متعددة loans. وبالمثل ، loansهم الآباءpaymentsلأن كل قرض سيكون له مدفوعات متعددة. يرتبط الآباء بأطفالهم بواسطة متغير مشترك. عندما نقوم بالتجميع ، نقوم بتجميع الجدول الفرعي حسب المتغير الرئيسي ونحسب الإحصائيات الخاصة بأبناء كل والد.
ل إضفاء الطابع الرسمي على العلاقة في featuretools ، نحن بحاجة فقط لتحديد المتغير الذي يربط الجدولين معا.
clientsوالجدول loansالمرتبطة متغير client_id، و loans، و payments- مع مساعدة من loan_id. يتم عرض بناء الجملة لإنشاء علاقة وإضافتها إلى مجموعة كيان أدناه:
# Relationship between clients and previous loans
r_client_previous = ft.Relationship(es['clients']['client_id'],
es['loans']['client_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_client_previous)
# Relationship between previous loans and previous payments
r_payments = ft.Relationship(es['loans']['loan_id'],
es['payments']['loan_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_payments)
es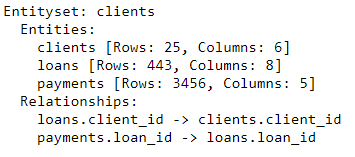
تحتوي مجموعة الكيانات الآن على ثلاثة كيانات (جداول) وعلاقات تربط هذه الكيانات معًا. بعد إضافة الكيانات وإضفاء الطابع الرسمي على العلاقات ، اكتملت مجموعة الكيانات لدينا ونحن على استعداد لإنشاء الميزات.
ميزة بدائية
قبل أن نتمكن من الانتقال بشكل كامل إلى التوليف العميق للسمات ، نحتاج إلى فهم أساسيات السمات . نحن نعلم بالفعل ما هي ، لكننا فقط نسميهم بأسماء مختلفة! هذه ليست سوى العمليات الأساسية التي نستخدمها لتشكيل ميزات جديدة:
- التجميعات: العمليات التي تتم على علاقة بين الوالدين والطفل (واحد لكثير) يتم تجميعها حسب الوالدين وتحسب إحصائيات للأطفال. مثال هو تجمع طاولة
loansكتبهاclient_idوتحديد الحد الأقصى لمبلغ القرض لكل عميل. - التحويلات: العمليات المنفذة من جدول واحد إلى عمود واحد أو أكثر. تتضمن الأمثلة الفرق بين عمودين في نفس الجدول ، أو القيمة المطلقة للعمود.
يتم إنشاء ميزات جديدة في أدوات مميزة باستخدام هذه الأوليات ، إما بمفردها أو كأوليات. فيما يلي قائمة ببعض الأوليات في الأدوات المميزة (يمكننا أيضًا تحديد الأوليات المخصصة ):
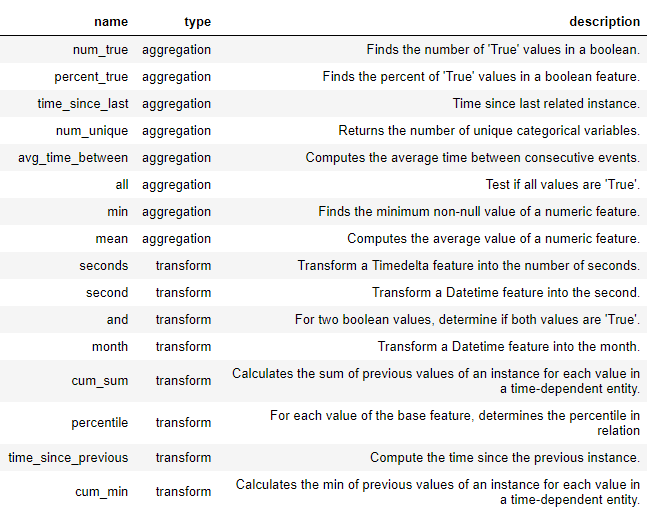
يمكن استخدام هذه البدائية بمفردها أو مجتمعة لإنشاء ميزات. لإنشاء ميزات باستخدام المواد الأولية المحددة ، نستخدم دالة
ft.dfs(تشير إلى التوليف العميق للميزات). نقوم بتمرير مجموعة من الكيانات target_entity، وهو جدول نريد أن نضيف إليه الميزات المحددة trans_primitives(التحويلات) و agg_primitives(المجاميع):
# Create new features using specified primitives
features, feature_names = ft.dfs(entityset = es, target_entity = 'clients',
agg_primitives = ['mean', 'max', 'percent_true', 'last'],
trans_primitives = ['years', 'month', 'subtract', 'divide'])والنتيجة هي إطار بيانات من الميزات الجديدة لكل عميل (لأننا صنعنا عملاء
target_entity). على سبيل المثال ، لدينا شهر انضم إليه كل عميل ، وهو أمر بدائي للتحول:
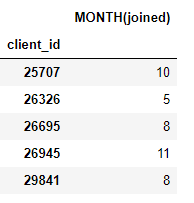
لدينا أيضًا عدد من البدائل التجميعية مثل متوسط مبالغ الدفع لكل عميل:
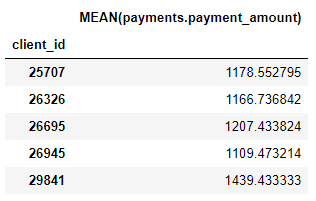
على الرغم من أننا حددنا فقط بعض الأوليات ، فقد أنشأت الأدوات المميزة العديد من الميزات الجديدة من خلال الجمع بين هذه الأوليات وتكديسها.
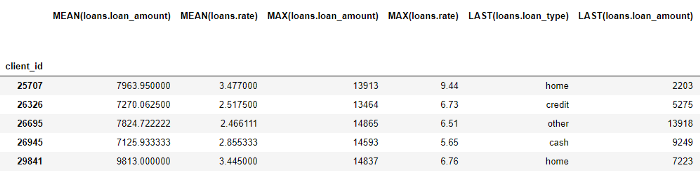
يحتوي إطار البيانات الكامل على 793 عمودًا من الميزات الجديدة!
التوليف العميق للعلامات
لدينا الآن كل شيء لنفهمه في توليف الميزة العميقة (dfs). في الواقع ، قمنا بالفعل dfs في استدعاء الوظيفة السابقة! السمة العميقة هي ببساطة سمة تتكون من مجموعة من البدائيات المتعددة ، و dfs هو اسم العملية التي تخلق تلك السمات. عمق العنصر العميق هو عدد العناصر الأولية اللازمة لإنشاء عنصر.
على سبيل المثال ، العمود
MEAN (payment.payment_amount)عبارة عن ميزة عميقة بعمق 1 لأنه تم إنشاؤه باستخدام تجميع واحد. عنصر بعمق اثنين هو هذا LAST(loans(MEAN(payment.payment_amount)). يتم ذلك عن طريق الجمع بين مجموعتين: الأحدث (الأحدث) أعلى MEAN. يمثل هذا متوسط السداد لأحدث قرض لكل عميل.
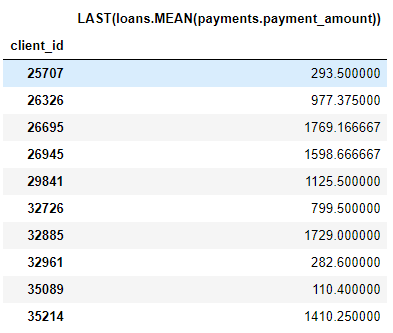
يمكننا تكوين الميزات إلى أي عمق نريده ، ولكن في الواقع لم أتجاوز العمق 2 أبدًا. بعد هذه النقطة ، يصعب تفسير الميزات ، لكنني أحث أي شخص مهتم بمحاولة "التعمق" .
لا نحتاج إلى تحديد البدائل يدويًا ، ولكن بدلاً من ذلك يمكننا السماح للأدوات المميزة بتحديد الميزات تلقائيًا لنا. لهذا نستخدم نفس استدعاء الوظيفة
ft.dfs، لكننا لا نمرر أي بدائية:
# Perform deep feature synthesis without specifying primitives
features, feature_names = ft.dfs(entityset=es, target_entity='clients',
max_depth = 2)
features.head()
لقد أنشأت Virturetools العديد من الميزات الجديدة لنا. على الرغم من أن هذه العملية تنشئ سمات جديدة تلقائيًا ، إلا أنها لن تحل محل عالم البيانات لأنه لا يزال يتعين علينا معرفة ما يجب فعله بكل تلك السمات. على سبيل المثال ، إذا كان هدفنا هو توقع ما إذا كان العميل سوف يسدد قرضًا أم لا ، فقد نبحث عن العلامات الأكثر صلة بنتيجة معينة. علاوة على ذلك ، إذا كان لدينا معرفة بمجال الموضوع ، يمكننا استخدامه لتحديد بدائل محددة للميزات أو للتوليف العميق للميزات المرشحة .
الخطوات التالية
حل التصميم التلقائي للميزات مشكلة واحدة ولكنه خلق مشكلة أخرى: ميزات كثيرة جدًا. في حين أنه من الصعب تحديد أي من هذه الميزات ستكون مهمة قبل ملاءمة النموذج ، فمن المرجح ألا تكون جميعها ذات صلة بالمهمة التي نريد تدريب نموذجنا عليها. علاوة على ذلك ، يمكن أن يؤدي العديد من الميزات إلى تدهور أداء النموذج لأن الميزات الأقل فائدة تزعج تلك الأكثر أهمية.
تُعرف مشكلة الكثير من السمات بعنة البعد . مع زيادة عدد الميزات (أبعاد البيانات) في النموذج ، يصبح من الصعب دراسة التوافق بين الميزات والأهداف. في الواقع ، كمية البيانات المطلوبة للنموذج للعمل بشكل جيديتطور بشكل كبير مع عدد الميزات .
يتم دمج لعنة الأبعاد مع تقليل الميزة (المعروف أيضًا باسم اختيار الميزة) : عملية إزالة الميزات غير الضرورية. يمكن أن يتخذ هذا العديد من الأشكال: التحليل الأساسي للمكونات (PCA) ، أو SelectKBest ، باستخدام قيم الميزة من نموذج ، أو الترميز التلقائي باستخدام الشبكات العصبية العميقة. ومع ذلك ، يعد تقليل الميزة موضوعًا منفصلاً لمقال آخر. في هذه المرحلة ، نعلم أنه يمكننا استخدام أدوات مميزة لإنشاء العديد من الميزات من العديد من الجداول بأقل جهد!
انتاج |
مثل العديد من المواضيع في التعلم الآلي ، فإن تصميم الميزات الآلي باستخدام أدوات مميزة هو مفهوم معقد يعتمد على أفكار بسيطة. باستخدام مفاهيم مجموعات الكيانات والكيانات والعلاقات ، يمكن للأدوات المميزة إجراء توليف عميق للميزات لإنشاء ميزات جديدة. التوليف العميق للميزات ، بدوره ، يجمع بين البدائية - التجميعات التي تعمل من خلال علاقات رأس بأطراف بين الجداول ، والتحويلات ، والوظائف المطبقة على عمود واحد أو أكثر في جدول واحد - لإنشاء ميزات جديدة من جداول متعددة.

تعرف على تفاصيل كيفية الحصول على مهنة رفيعة المستوى من الصفر أو المستوى الأعلى في المهارات والراتب من خلال الحصول على دورات SkillFactory المدفوعة عبر الإنترنت:
- دورة تعلم الآلة (12 أسبوعًا)
- Data Science (12 )
- (9 )
- «Python -» (9 )
- DevOps (12 )
- - (8 )