لدى Ab Initio العديد من التحولات الكلاسيكية وغير العادية التي يمكن توسيعها باستخدام PDL الخاص بها. بالنسبة للشركات الصغيرة ، من المرجح أن تكون هذه الأداة القوية زائدة عن الحاجة ، وقد تكون معظم قدراتها باهظة الثمن وغير ضرورية. ولكن إذا كان مقياسك قريبًا من مقياس Sberbank ، فقد يكون Ab Initio مثيرًا للاهتمام لك.
إنه يساعد الأعمال على تراكم المعرفة عالميًا وتطوير النظام البيئي ، والمطور - لضخ مهاراتهم في ETL ، لسحب المعرفة في الصدفة ، يوفر فرصة لإتقان لغة PDL ، يعطي صورة مرئية لعمليات التحميل ، يبسط التنمية بسبب وفرة المكونات الوظيفية.
في هذا المنشور سأتحدث عن قدرات Ab Initio وأعطي خصائص مقارنة لعملها مع Hive و GreenPlum.
- MDW GreenPlum
- Ab Initio Hive GreenPlum
- Ab Initio GreenPlum Near Real Time
وظائف هذا المنتج واسعة للغاية ويستغرق الكثير من الوقت للتعلم. ومع ذلك ، مع مهارات العمل المناسبة وإعدادات الأداء الصحيحة ، فإن نتائج معالجة البيانات رائعة للغاية. يمكن أن يمنحه استخدام Ab Initio كمطور تجربة ممتعة. هذه نظرة جديدة على تطوير ETL ، وهي مزيج بين البيئة المرئية وتنزيل التطوير بلغة شبيهة بالبرنامج النصي.
تعمل الأعمال على تطوير نظمها البيئية ، وهذه الأداة مفيدة أكثر من أي وقت مضى. بمساعدة Ab Initio ، يمكنك تجميع المعرفة حول عملك الحالي واستخدام هذه المعرفة لتوسيع الأعمال القديمة وفتح أعمال جديدة. يمكن استدعاء بدائل Ab Initio من بيئات التطوير المرئي Informatica BDM ومن البيئات غير المرئية - Apache Spark.
وصف Ab Initio
Ab Initio ، مثل أدوات ETL الأخرى ، عبارة عن مجموعة من المنتجات.

Ab Initio GDE (بيئة التطوير الرسومية) هي بيئة لمطور حيث يقوم بإعداد تحويلات البيانات وربطها بتدفقات البيانات في شكل سهام. في هذه الحالة ، تسمى هذه المجموعة من التحويلات رسمًا بيانيًا:

توصيلات الإدخال والإخراج للمكونات الوظيفية هي منافذ وتحتوي على حقول محسوبة داخل التحويلات. تسمى العديد من الرسوم البيانية المتصلة بواسطة تيارات في شكل سهام بترتيب تنفيذها خطة.
هناك عدة مئات من المكونات الوظيفية ، وهو الكثير. كثير منهم متخصصون للغاية. Ab Initio لديها مجموعة أوسع من التحولات الكلاسيكية من أدوات ETL الأخرى. على سبيل المثال ، لدى Join مخرجات متعددة. بالإضافة إلى نتيجة توصيل مجموعات البيانات ، يمكنك الحصول على سجلات إخراج مجموعات بيانات الإدخال ، عن طريق مفاتيح لم يكن من الممكن الاتصال بها. يمكنك أيضًا الحصول على الرفض والأخطاء وسجل عملية التحويل ، والتي يمكن قراءتها في نفس العمود كملف نصي ومعالجتها من خلال تحويلات أخرى:

أو ، على سبيل المثال ، يمكنك تجسيد مستقبل البيانات في شكل جدول وقراءة البيانات منه في نفس العمود.
هناك تحولات أصلية. على سبيل المثال ، فإن تحويل المسح الضوئي له نفس الوظائف مثل الوظائف التحليلية. هناك تحويلات بأسماء ذاتية التفسير: إنشاء البيانات ، قراءة Excel ، التطبيع ، الفرز داخل المجموعات ، تشغيل البرنامج ، تشغيل SQL ، الانضمام باستخدام DB ، إلخ. يمكن أن تستخدم الرسوم البيانية معلمات وقت التشغيل ، بما في ذلك نقل المعلمات من نظام التشغيل أو إلى نظام التشغيل ... تسمى الملفات ذات مجموعة المعلمات الجاهزة التي يتم تمريرها إلى الرسم البياني مجموعات المعلمات (psets).
كما هو متوقع ، فإن Ab Initio GDE لها مستودع خاص بها يسمى EME (Enterprise Meta Environment). يمتلك المطورون القدرة على العمل مع الإصدارات المحلية من التعليمات البرمجية والتحقق من تطوراتهم في المستودع المركزي.
من الممكن ، أثناء التنفيذ أو بعد تنفيذ الرسم البياني ، النقر على أي دفق يربط التحولات والنظر في البيانات التي تم تمريرها بين هذه التحولات: من

الممكن أيضًا النقر على أي دفق ورؤية تفاصيل التتبع - في عدد أوجه التشابه التي يعمل بها التحويل ، وعدد الخطوط والبايت في أي يتم تحميل المتوازيات: من

الممكن تقسيم تنفيذ الرسم البياني إلى مراحل ووضع علامة على أنه يجب إجراء بعض التحولات أولاً (في المرحلة صفر) ، يتبع في المرحلة الأولى ، يليه في المرحلة الثانية ، إلخ.
لكل تحويل ، يمكنك اختيار ما يسمى بالتخطيط (حيث سيتم تنفيذه): بدون توازي أو في سلاسل متوازية ، يمكن تعيين عددها. في الوقت نفسه ، يمكن وضع الملفات المؤقتة التي تم إنشاؤها بواسطة Ab Initio أثناء عمل التحويلات في نظام ملفات الخادم وفي HDFS.
في كل تحويل ، استنادًا إلى القالب الافتراضي ، يمكنك إنشاء البرنامج النصي الخاص بك بلغة PDL ، والتي تشبه إلى حد ما غلاف.
بمساعدة لغة PDL ، يمكنك توسيع وظائف التحويلات ، وعلى وجه الخصوص ، يمكنك إنشاء أجزاء رمز عشوائي بشكل عشوائي (في وقت التشغيل) اعتمادًا على معلمات وقت التشغيل.
أيضا ، لدى Ab Initio تكامل متطور مع نظام التشغيل من خلال الصدفة. على وجه التحديد ، يستخدم Sberbank لينكس ksh. يمكنك تبادل المتغيرات مع الصدفة واستخدامها كمعلمات الرسم البياني. يمكنك استدعاء تنفيذ الرسوم البيانية Ab Initio من الصدفة وإدارة Ab Initio.
بالإضافة إلى Ab Initio GDE ، يتضمن التسليم العديد من المنتجات الأخرى. يوجد نظام التشغيل Co> مع مطالبة باسم نظام التشغيل. يوجد Control> Center حيث يمكنك جدولة تدفقات التنزيل ومراقبتها. هناك منتجات للقيام بالتطوير على مستوى أكثر بدائية مما يسمح به Ab Initio GDE.
وصف إطار عمل MDW والعمل على تخصيصه لـ GreenPlum
جنبا إلى جنب مع منتجاتها ، يقوم المورد بتزويد المنتج MDW (مستودع البيانات الوصفية) ، وهو مكون رسم بياني مصمم للمساعدة في المهام النموذجية لملء مخازن البيانات أو خزائن البيانات.
يحتوي على محللات بيانات التعريف المخصصة (الخاصة بالمشروع) ومولدات التعليمات البرمجية الجاهزة.
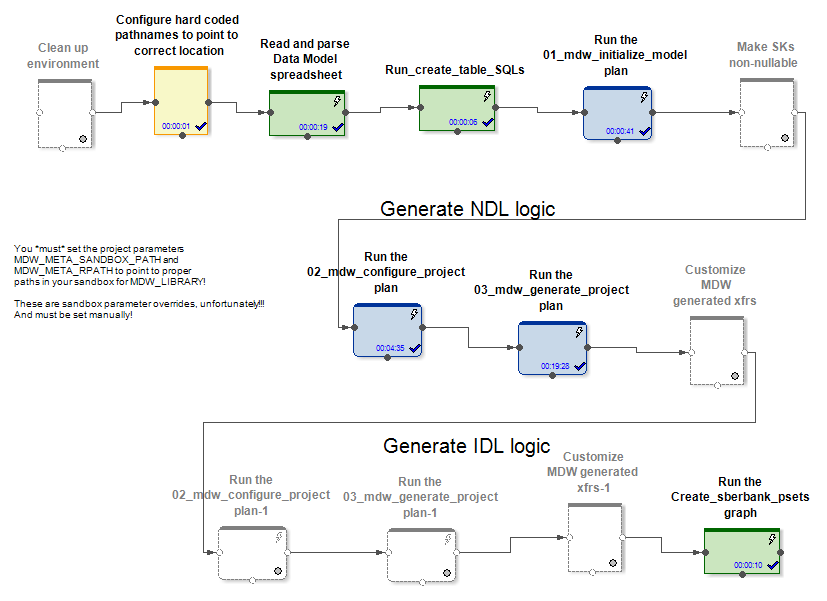
عند المدخل ، تتلقى MDW نموذج بيانات وملف تكوين لإعداد اتصال قاعدة بيانات (Oracle أو Teradata أو Hive) وبعض الإعدادات الأخرى. يقوم الجزء الخاص بالمشروع ، على سبيل المثال ، بنشر النموذج في قاعدة البيانات. يقوم الجزء المحاصر من المنتج بإنشاء رسوم بيانية وملفات تكوين لها عند تحميل البيانات في جداول النماذج. يؤدي هذا إلى إنشاء رسوم بيانية (و psets) للعديد من أوضاع التهيئة والعمل الإضافي على تحديث الكيانات.
في حالات Hive و RDBMS ، يتم إنشاء رسوم بيانية مختلفة للتحديث والتزايد للبيانات.
في حالة الخلية ، يتم ربط بيانات دلتا الواردة بواسطة Ab Initio الانضمام إلى البيانات التي كانت موجودة في الجدول قبل التحديث. لا تقوم برامج تحميل البيانات في MDW (في كل من الخلية و RDBMS) بإدراج بيانات جديدة من دلتا فحسب ، بل تغلق أيضًا فترات صلاحية البيانات التي تم استلام دلتا لها من خلال المفاتيح الأساسية. بالإضافة إلى ذلك ، يجب عليك إعادة كتابة الجزء الذي لم يتغير من البيانات. ولكن يجب القيام بذلك ، لأن Hive ليس لديها عمليات حذف أو تحديث.
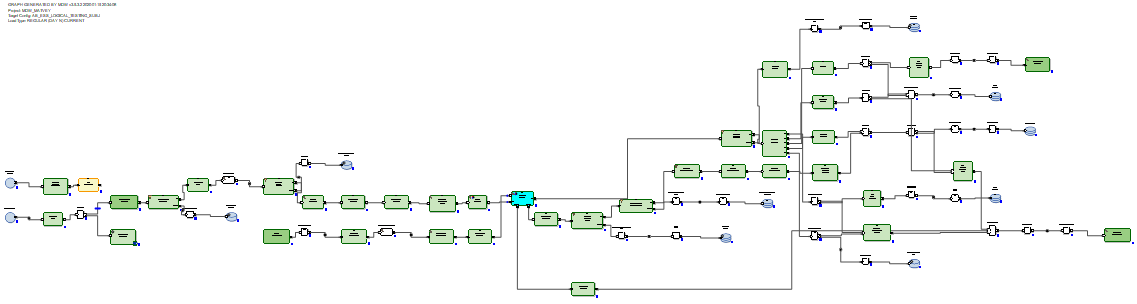
في حالة RDBMS ، تبدو الرسوم البيانية للتحديث المتزايد للبيانات أكثر مثالية لأن RDBMS لها إمكانات تحديث حقيقية.
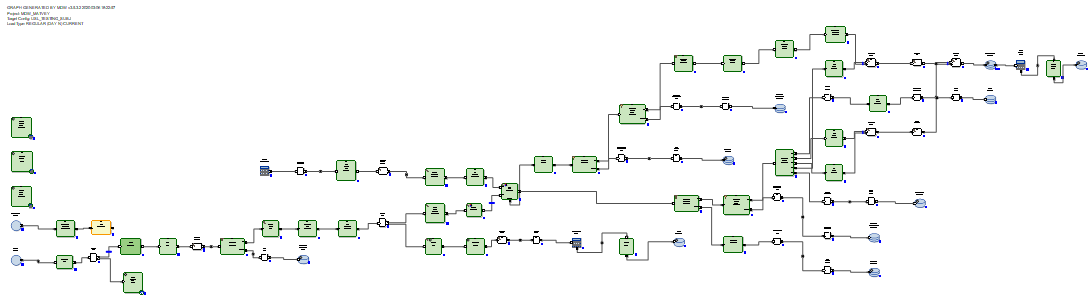
يتم تحميل دلتا المتلقاة في جدول مرحلي في قاعدة البيانات. بعد ذلك ، يتم توصيل الدلتا بالبيانات الموجودة في الجدول قبل التحديث. ويتم ذلك عن طريق SQL من خلال استعلام SQL الذي تم إنشاؤه. بعد ذلك ، باستخدام أوامر delete + insert SQL ، يتم إدراج البيانات الجديدة من دلتا في الجدول الهدف ويتم إغلاق فترات صلة البيانات ، وفقًا للمفاتيح الأساسية التي تم استلام دلتا منها.
ليست هناك حاجة لإعادة كتابة البيانات التي لم تتغير.
وهكذا ، توصلنا إلى استنتاج مفاده أنه في حالة الخلية ، يجب أن تذهب العاملة لإعادة كتابة الجدول بأكمله ، لأن الخلية ليس لديها وظيفة تحديث. ولا شيء أفضل من إعادة كتابة كاملة للبيانات عندما لا يتم اختراع التحديث. في حالة RDBMS ، على العكس من ذلك ، اعتبر مبدعو المنتج أنه من الضروري تكليف الاتصال وتحديث الجداول باستخدام SQL.
بالنسبة لمشروع في Sberbank ، قمنا بإنشاء تطبيق جديد قابل لإعادة الاستخدام لمحمّل قاعدة بيانات GreenPlum. تم ذلك بناءً على الإصدار الذي تولده MDW لـ Teradata. كان Teradata ، وليس Oracle ، هو الأفضل والأقرب لهذا الغرض. هو أيضًا نظام MPP. تبين أن طريقة العمل والقواعد اللغوية لكل من Teradata و GreenPlum متشابهة.
فيما يلي أمثلة على الاختلافات الحاسمة بالنسبة للعاملات المهاجرات بين RDBMS المختلفة. في GreenPlum ، على عكس Teradata ، عند إنشاء الجداول ، تحتاج إلى كتابة جملة
distributed byيكتب Teradata
delete <table> all، وفي GreenePlum يكتبون
delete from <table>تكتب Oracle لأغراض التحسين
delete from t where rowid in (< t >)، والكتابة Teradata و GreenPlum
delete from t where exists (select * from delta where delta.pk=t.pk)نلاحظ أيضًا أنه لكي يعمل Ab Initio مع GreenPlum ، كان مطلوبًا تثبيت عميل GreenPlum على جميع عقد مجموعة Ab Initio. هذا لأننا اتصلنا بـ GreenPlum في نفس الوقت من جميع العقد في مجموعتنا. ولكي تكون القراءة من GreenPlum متوازية وكل سلسلة Ab Initio متوازية لقراءة الجزء الخاص بها من البيانات من GreenPlum ، كان من الضروري وضع بنية يفهمها Ab Initio في قسم "أين" في استعلامات SQL
where ABLOCAL()وتحديد قيمة هذا البناء عن طريق تحديد المعلمة القراءة من قاعدة بيانات التحويل
ablocal_expr=«string_concat("mod(t.", string_filter_out("{$TABLE_KEY}","{}"), ",", (decimal(3))(number_of_partitions()),")=", (decimal(3))(this_partition()))»الذي يجمع لشيء مثل
mod(sk,10)=3، بمعنى آخر. يجب أن تخبر GreenPlum بمرشح صريح لكل قسم. بالنسبة لقواعد البيانات الأخرى (Teradata و Oracle) ، يمكن لـ Ab Initio إجراء هذا التوازي تلقائيًا.
خصائص الأداء المقارنة لـ Ab Initio للعمل مع Hive و GreenPlum
تم إجراء تجربة في Sberbank لمقارنة أداء الرسوم البيانية التي تم إنشاؤها بواسطة MDW فيما يتعلق بـ Hive وفيما يتعلق بـ GreenPlum. كجزء من التجربة ، في حالة خلية النحل ، كان هناك 5 عقد على نفس المجموعة مثل Ab Initio ، وفي حالة GreenPlum ، كان هناك 4 عقد على مجموعة منفصلة. أولئك. الخلية لديها بعض مزايا الأجهزة على GreenPlum.
نظرنا إلى زوجين من الرسوم البيانية التي تؤدي نفس المهمة لتحديث البيانات في Hive و GreenPlum. تم إطلاق الرسوم البيانية التي تم إنشاؤها بواسطة مكون MDW:
- تهيئة تحميل + تحميل تدريجي للبيانات التي تم إنشاؤها بشكل عشوائي في جدول الخلية
- تهيئة تحميل + تحميل تدريجي للبيانات التي تم إنشاؤها بشكل عشوائي في نفس جدول GreenPlum
في كلتا الحالتين (Hive و GreenPlum) تم إطلاق التنزيلات في 10 سلاسل متوازية على نفس مجموعة Ab Initio. حفظ Ab Initio البيانات الوسيطة للحسابات في HDFS (من حيث Ab Initio ، تم استخدام تخطيط MFS باستخدام HDFS). يشغل سطر واحد من البيانات التي تم إنشاؤها عشوائيًا 200 بايت في كلتا الحالتين.
والنتيجة هي:
خلية:
| تهيئة التحميل في الخلية | |||
| تم إدراج الصفوف | 6،000،000 | 60،000،000 | 600،000،000 |
| مدة تهيئة
التحميل بالثواني |
41 | 203 | 1601 |
| تحميل متزايد في الخلية | |||
| عدد الصفوف في
الجدول الهدف في بداية التجربة |
6،000،000 | 60،000،000 | 600،000،000 |
| عدد صفوف دلتا المطبقة على
الجدول المستهدف أثناء التجربة |
6،000،000 | 6،000،000 | 6،000،000 |
| مدة
التنزيل الإضافية بالثواني |
88 | 299 | 2541 |
GreenPlum:
| GreenPlum | |||
| 6 000 000 | 60 000 000 | 600 000 000 | |
|
|
72 | 360 | 3 631 |
| GreenPlum | |||
| ,
|
6 000 000 | 60 000 000 | 600 000 000 |
| ,
|
6 000 000 | 6 000 000 | 6 000 000 |
|
|
159 | 199 | 321 |
نرى أن سرعة تهيئة التحميل في كل من Hive و GreenPlum تعتمد خطيًا على كمية البيانات ، ولأسباب أفضل للأجهزة ، فهي أسرع إلى حد ما لـ Hive من GreenPlum.
يعتمد التحميل المتزايد في الخلية بشكل خطي أيضًا على كمية البيانات التي تم تحميلها مسبقًا في الجدول الهدف وهو بطيء نوعًا ما مع نمو المبلغ. ويرجع ذلك إلى الحاجة إلى استبدال الجدول الهدف بالكامل. هذا يعني أن تطبيق التغييرات الصغيرة على الجداول الضخمة ليس حالة استخدام جيدة لـ Hive.
يعتمد التحميل المتزايد في GreenPlum بشكل ضعيف على كمية البيانات التي تم تحميلها مسبقًا والمتوفرة في الجدول المستهدف وهو سريع جدًا. حدث هذا بفضل SQL Joins وبنية GreenPlum ، مما يسمح بعملية الحذف.
لذلك ، يقوم GreenPlum بحقن الدلتا باستخدام طريقة الحذف + الإدراج ، بينما لا يوجد لدى Hive عمليات حذف أو تحديث ، لذلك كان يجب إعادة كتابة مجموعة البيانات بالكامل تمامًا أثناء التحديث التزايدي. الأكثر دلالة هو مقارنة الخلايا المميزة بالخط العريض ، لأنها تقابل التشغيل الأكثر شيوعًا للتنزيلات كثيفة الموارد. نرى أن GreenPlum فاز 8 مرات على Hive في هذا الاختبار.
أب Initio مع GreenPlum في الوقت الحقيقي القريب
في هذه التجربة ، سنختبر قدرة Ab Initio على تحديث جدول GreenPlum بقطع البيانات التي يتم إنشاؤها عشوائيًا في الوقت الفعلي تقريبًا. ضع في اعتبارك الجدول GreenPlum dev42_1_db_usl.TESTING_SUBJ_org_finval ، الذي سنعمل معه.
سنستخدم ثلاثة رسوم بيانية لـ Ab Initio للعمل معها:
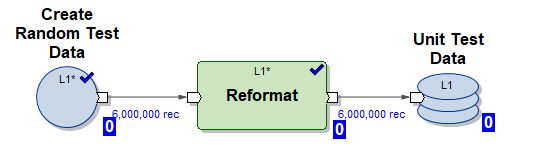
1) الرسم البياني Create_test_data.mp - ينشئ ملفات بالبيانات في HDFS لـ 6000.000 سطر في 10 تيارات متوازية. البيانات عشوائية ، وهيكلها منظم لإدراجه في جدولنا

2) الرسم البياني mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset - الرسم البياني MDW الذي تم إنشاؤه لتهيئة إدخال البيانات في جدولنا في 10 سلاسل موازية (يتم استخدام بيانات الاختبار التي تم إنشاؤها بواسطة الرسم البياني (1))

3) الرسم البياني mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset - الرسم البياني MDW الذي تم إنشاؤه للتحديث المتزايد لجدولنا في 10 سلاسل متوازية باستخدام جزء من البيانات الواردة الجديدة (دلتا) التي تم إنشاؤها بواسطة الرسم البياني (1) قم

بتشغيل البرنامج النصي التالي في وضع NRT:
- تولد 6000.000 خط اختبار
- قم بتهيئة الحمل إدراج 6000.000 سطر اختبار في جدول فارغ
- كرر 5 مرات التحميل المتزايد
- تولد 6000.000 خط اختبار
- أدخل إدراجًا تدريجيًا يصل إلى 6000.000 صف اختبار في الجدول (في هذه الحالة ، يتم ختم البيانات القديمة بوقت انتهاء الصلاحية الصالحة حتى يتم إدخال بيانات أحدث بنفس المفتاح الأساسي)
يحاكي مثل هذا السيناريو طريقة التشغيل الحقيقي لنظام عمل معين - يظهر جزء كبير إلى حد ما من البيانات الجديدة في الوقت الفعلي ويصب فورًا في GreenPlum.
الآن دعونا نرى سجل البرنامج النصي:
ابدأ Create_test_data.input.pset في 2020-06-04 11:49:11
إنهاء Create_test_data.input.pset في 2020-06-04 11:49:37
ابدأ mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset في 2020-06-04 11:49:37
إنهاء mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset في 2020-06-04 11:50:42
ابدأ Create_test_data.input.pset في 2020-06-04 11:50:42
Finish Create_test_data.input.pset في 2020-06-04 11:51:06
ابدأ تشغيل mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset في 2020-06-04 11:51:06
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:53:41
Start Create_test_data.input.pset at 2020-06-04 11:53:41
Finish Create_test_data.input.pset at 2020-06-04 11:54:04
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:54:04
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:56:51
Start Create_test_data.input.pset at 2020-06-04 11:56:51
Finish Create_test_data.input.pset at 2020-06-04 11:57:14
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:57:14
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:59:55
ابدأ Create_test_data.input.pset في 2020-06-04 11:59:55
إنهاء Create_test_data.input.pset في 2020-06-04 12:00:23
ابدأ mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset في 2020-06-04 12:00:23
إنهاء mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset في 2020-06-04 12:03:23
ابدأ Create_test_data.input.pset في 2020-06-04 12:03:23
Finish Create_test_data.input.pset at 2020-06-04 12:03:49
ابدأ mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset في 2020-06-04 12:03:49
أنهى mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset في 2020-06-04 : 46
الصورة تبدو كالتالي:
| رسم بياني | وقت البدء | وقت الانتهاء | الطول |
|---|---|---|---|
| Create_test_data.input.pset | 06/04/2020 11:49:11 | 06/04/2020 11:49:37 | 00:00:26 |
| mdw_load.day_one.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:49:37 | 06/04/2020 11:50:42 | 00:01:05 |
| Create_test_data.input.pset | 06/04/2020 11:50:42 | 06/04/2020 11:51:06 | 00:00:24 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:51:06 | 06/04/2020 11:53:41 | 00:02:35 |
| Create_test_data.input.pset | 06/04/2020 11:53:41 | 06/04/2020 11:54:04 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:54:04 | 06/04/2020 11:56:51 | 00:02:47 |
| Create_test_data.input.pset | 06/04/2020 11:56:51 | 06/04/2020 11:57:14 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:57:14 | 06/04/2020 11:59:55 | 00:02:41 |
| Create_test_data.input.pset | 06/04/2020 11:59:55 | 06/04/2020 12:00:23 | 00:00:28 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:00:23 | 06/04/2020 12:03:23 م | 00:03:00 |
| Create_test_data.input.pset | 06/04/2020 12:03:23 م | 06/04/2020 12:03:49 م | 00:00:26 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:03:49 م | 06/04/2020 12:06:46 م | 00:02:57 |
نرى أنه تتم معالجة 6،000،000 خط زيادة في 3 دقائق ، وهو سريع جدًا.
تبين أن البيانات الواردة في الجدول المستهدف توزع على النحو التالي:
select valid_from_ts, valid_to_ts, count(1), min(sk), max(sk) from dev42_1_db_usl.TESTING_SUBJ_org_finval group by valid_from_ts, valid_to_ts order by 1,2;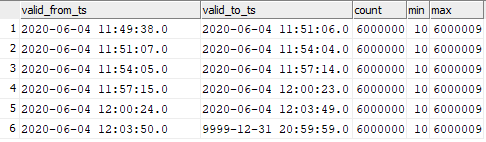
يمكنك رؤية مراسلات البيانات المدرجة في لحظات إطلاق الرسم البياني.
هذا يعني أنه يمكنك البدء في التحميل التدريجي للبيانات إلى GreenPlum في Ab Initio بتردد عالي جدًا ومراقبة سرعة عالية لإدخال هذه البيانات في GreenPlum. بالطبع ، لن يكون من الممكن البدء مرة واحدة في الثانية ، نظرًا لأن Ab Initio ، مثل أي أداة ETL ، تستغرق وقتًا في "التأرجح" عند بدء التشغيل.
خاتمة
يستخدم الآن Ab Initio في Sberbank لبناء طبقة البيانات الدلالية الموحدة (ESS). يتضمن هذا المشروع بناء نسخة واحدة من حالة مختلف كيانات الأعمال المصرفية. تأتي المعلومات من مصادر مختلفة ، يتم تحضير نسخ طبق الأصل منها على Hadoop. بناءً على احتياجات العمل ، يتم إعداد نموذج البيانات ووصف تحويلات البيانات. يحمّل Ab Initio المعلومات إلى ECC ولا تعد البيانات التي تم تحميلها ذات أهمية بالنسبة إلى الأعمال في حد ذاتها فحسب ، ولكنها تعمل أيضًا كمصدر لبناء مخططات البيانات. في الوقت نفسه ، تتيح لك وظيفة المنتج استخدام أنظمة مختلفة (Hive و Greenplum و Teradata و Oracle) كمستقبل ، مما يجعل من الممكن إعداد البيانات للأعمال بسهولة في تنسيقات مختلفة تتطلبها.
قدرات Ab Initio واسعة ، على سبيل المثال ، إطار عمل MDW المضمّن يجعل من الممكن بناء البيانات التاريخية والتجارية من خارج الصندوق. بالنسبة للمطورين ، يتيح Ab Initio الفرصة لـ "عدم إعادة اختراع العجلة" ، ولكن لاستخدام العديد من المكونات الوظيفية المتاحة ، والتي هي في الواقع مكتبات مطلوبة عند العمل مع البيانات.
المؤلف خبير في مجتمع Sberbank الاحترافي SberProfi DWH / BigData. المجتمع المهني SberProfi DWH / BigData مسؤول عن تطوير الكفاءات في مجالات مثل النظام الإيكولوجي Hadoop ، Teradata ، Oracle DB ، GreenPlum ، بالإضافة إلى أدوات BI Qlik ، SAP BO ، Tableau ، إلخ.