رئيس مكافحة الاحتيال أندريه بوبوف Nox_andryقدم عرضًا تقديميًا حول كيفية تمكننا من تلبية جميع هذه المتطلبات المتضاربة. الموضوع الرئيسي للتقرير هو نموذج لحساب العوامل المعقدة في دفق البيانات وضمان التسامح مع خطأ النظام. كما وصف أندري بإيجاز التكرار التالي ، الأسرع من مكافحة الاحتيال ، الذي نقوم بتطويره حاليًا.
يقوم فريق مكافحة الاحتيال بشكل أساسي بحل مشكلة التصنيف الثنائي. لذلك ، قد يكون التقرير مفيدًا ليس فقط للمتخصصين في مكافحة الاحتيال ، ولكن أيضًا لأولئك الذين يصنعون أنظمة مختلفة تحتاج إلى عوامل سريعة وموثوقة ومرنة على كميات كبيرة من البيانات.
- مرحبا اسمي أندري. أنا أعمل في ياندكس ، وأنا مسؤول عن تطوير مكافحة الاحتيال. قيل لي أن الناس يفضلون استخدام كلمة "ميزات" ، لذلك سأذكرها طوال الحديث ، ولكن العنوان والمقدمة ظلت كما هي ، مع كلمة "العوامل".
ما هو مكافحة الاحتيال؟
ما هو مكافحة الاحتيال على أي حال؟ إنه نظام يحمي المستخدمين من التأثير السلبي على الخدمة. من خلال التأثير السلبي ، أعني الإجراءات المتعمدة التي يمكن أن تقلل من جودة الخدمة ، وبالتالي ، تزيد من سوء تجربة المستخدم. يمكن أن تكون هذه أدوات تحليل وروبوتات بسيطة إلى حد ما تزيد من سوء إحصاءاتنا ، أو أنشطة احتيالية معقدة عمدا. والثاني ، بالطبع ، أكثر صعوبة وأكثر إثارة للاهتمام لتحديد.
ماذا يحارب ضد الاحتيال؟ بضعة أمثلة.
على سبيل المثال ، تقليد إجراءات المستخدم. يتم ذلك من قبل الرجال الذين نسميهم "كبار المسئولين الاقتصاديين السود" - أولئك الذين لا يريدون تحسين جودة الموقع والمحتوى على الموقع. بدلاً من ذلك ، يكتبون روبوتات تذهب إلى بحث Yandex ، وانقر على موقعهم. إنهم يتوقعون ارتفاع موقعهم بهذه الطريقة. في هذه الحالة فقط ، أذكرك بأن مثل هذه الإجراءات تتعارض مع اتفاقية المستخدم وقد تؤدي إلى عقوبات خطيرة من Yandex.

أو ، على سبيل المثال ، غش المراجعات. يمكن رؤية هذه المراجعة من المنظمة على الخرائط ، التي تضع النوافذ البلاستيكية. دفعت هي نفسها لهذا الاستعراض.
تبدو بنية مكافحة الاحتيال ذات المستوى الأعلى على هذا النحو: تقع مجموعة معينة من الأحداث الأولية في نظام مكافحة الاحتيال نفسه مثل الصندوق الأسود. عند الخروج منه ، يتم إنشاء الأحداث الموسومة.
ياندكس لديها العديد من الخدمات. جميعهم ، وخاصةً الكبيرة منها ، بطريقة أو بأخرى ، يواجهون أنواعًا مختلفة من الاحتيال. البحث والسوق والخرائط وعشرات الآخرين.
أين كنا قبل سنتين أو ثلاث سنوات؟ نجا كل فريق تحت هجمة الاحتيال بأفضل ما يمكن. لقد أنشأت فرق مكافحة الاحتيال ، وأنظمتها ، التي لم تكن تعمل دائمًا بشكل جيد ، لم تكن مريحة جدًا للتفاعل مع المحللين. والأهم من ذلك أنها كانت ضعيفة الاندماج مع بعضها البعض.
أريد أن أخبرك كيف تمكنا من حل هذا عن طريق إنشاء منصة واحدة.

لماذا نحتاج إلى منصة واحدة؟ إعادة استخدام الخبرة والبيانات. تسمح لك مركزية التجربة والبيانات في مكان واحد بالاستجابة بشكل أسرع وأفضل للهجمات الكبيرة - وعادة ما تكون عبر الخدمات.
مجموعة أدوات موحدة. الناس لديهم الأدوات التي اعتادوا عليها. ومن الواضح أن سرعة الاتصال. إذا أطلقنا خدمة جديدة تتعرض حاليًا لهجوم نشط ، فيجب أن نربطها بسرعة بمكافحة التزوير عالية الجودة.
يمكننا القول أننا لسنا فريدين في هذا الصدد. تواجه جميع الشركات الكبيرة مشاكل مماثلة. وكل من نتواصل معه يأتي لإنشاء منصتهم الفردية.
سأخبرك قليلاً عن كيفية تصنيفنا لمكافحة الاحتيال.
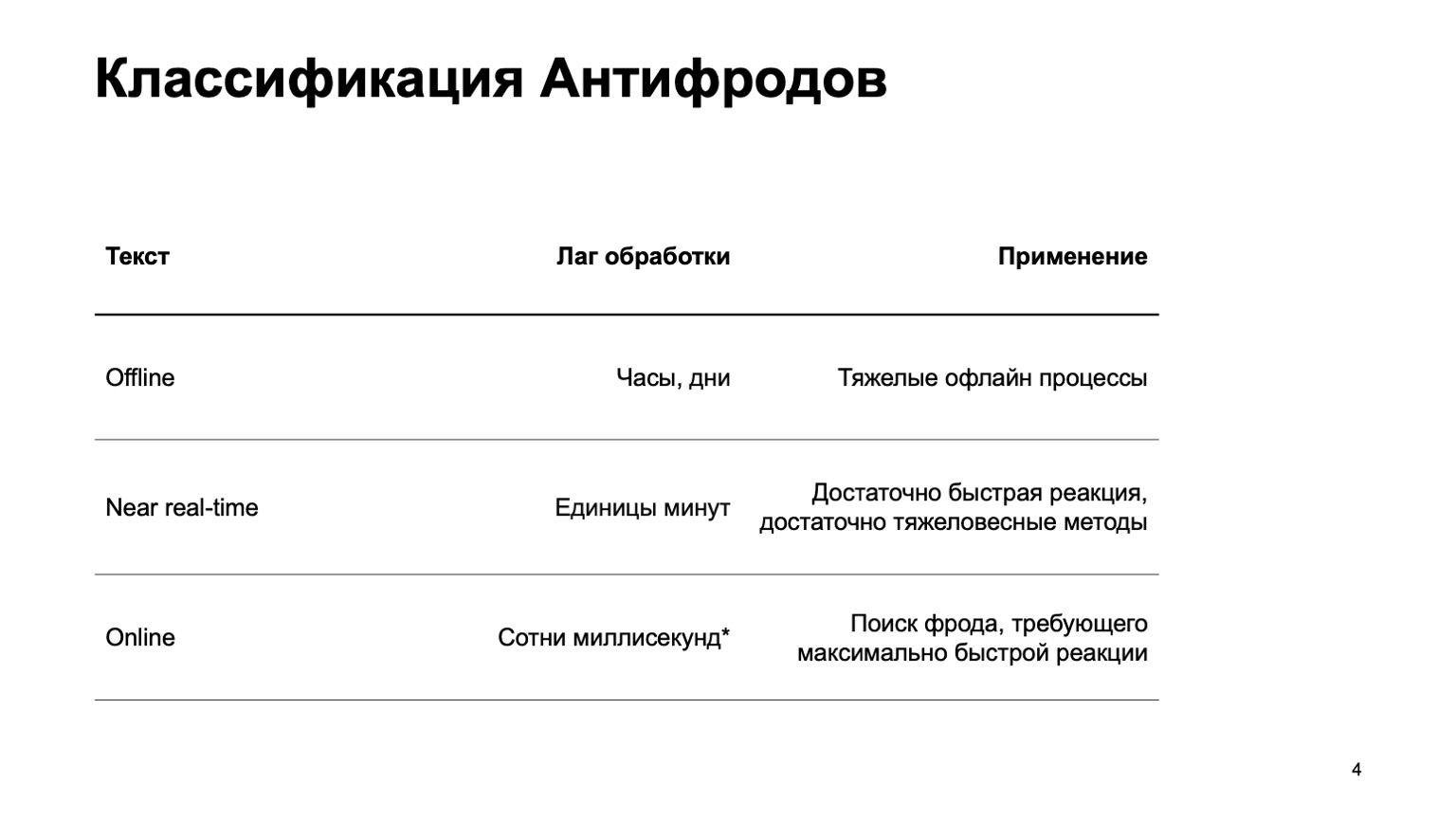
يمكن أن يكون هذا نظامًا غير متصل بالإنترنت يحسب ساعات وأيام وعمليات مكثفة بلا اتصال: على سبيل المثال ، التكتل المعقد أو إعادة التدريب المعقدة. عمليا لن أتطرق إلى هذا الجزء من التقرير. هناك جزء في الوقت الفعلي تقريبًا يعمل في بضع دقائق. هذا نوع من المتوسط الذهبي ، ولديها ردود فعل سريعة وأساليب ثقيلة. بادئ ذي بدء ، سوف أركز عليها. ولكن من المهم بنفس القدر القول أننا في هذه المرحلة نستخدم بيانات من المرحلة أعلاه.
هناك أيضًا أجزاء على الإنترنت مطلوبة في الأماكن التي تتطلب استجابة سريعة ومن المهم التخلص من الاحتيال حتى قبل تلقينا الحدث وتمريره إلى المستخدم. هنا نعيد استخدام خوارزميات البيانات والتعلم الآلي المحسوبة على مستويات أعلى مرة أخرى.
سأتحدث عن كيفية ترتيب هذه المنصة الموحدة ، عن لغة وصف الميزات والتفاعل مع النظام ، عن طريقنا إلى زيادة السرعة ، أي حول الانتقال من المرحلة الثانية إلى الثالثة.
بالكاد أتطرق إلى أساليب ML نفسها. في الأساس ، سأتحدث عن المنصات التي تنشئ ميزات ، والتي نستخدمها بعد ذلك في التدريب.
من قد يكون مهتمًا بهذا؟ من الواضح أن أولئك الذين يكتبون مكافحة الاحتيال أو محاربة المحتالين. ولكن أيضًا لأولئك الذين بدأوا دفق البيانات وقراءة الميزات ، تعتبر ML. نظرًا لأننا أنشأنا نظامًا عامًا إلى حد ما ، ربما تكون مهتمًا ببعض هذا.
ماهي متطلبات النظام؟ هناك عدد غير قليل منهم ، وهنا بعض منهم:
- دفق بيانات كبير. نعالج مئات الملايين من الأحداث في خمس دقائق.
- ميزات قابلة للتكوين بالكامل.
- .
- , - exactly-once- , . — , , , , .
- , , .
علاوة على ذلك ، سأخبرك عن كل من هذه النقاط بشكل منفصل.
نظرًا لأنه لأسباب أمنية لا يمكنني التحدث عن الخدمات الحقيقية ، فلنقدم خدمة Yandex جديدة. في الواقع لا ، ننسى ، هذه خدمة خيالية توصلت إليها لعرض الأمثلة. فليكن خدمة يمتلك فيها الأشخاص قاعدة بيانات لجميع الكتب الموجودة. يدخلون ويعطون تقييمات من واحد إلى عشرة ، ويريد المهاجمون التأثير على التصنيف النهائي بحيث يتم شراء كتبهم.
جميع المصادفات مع الخدمات الحقيقية ، بطبيعة الحال ، عشوائية. دعنا نفكر أولاً في الإصدار القريب من الوقت الفعلي ، نظرًا لعدم الحاجة إلى الإنترنت على وجه التحديد هنا في التقريب الأول.
البيانات الكبيرة
لدى Yandex طريقة كلاسيكية لحل مشكلات البيانات الضخمة: استخدم MapReduce. نستخدم تطبيق MapReduce الخاص بنا والذي يسمى YT . بالمناسبة ، مكسيم أحمدوف لديها قصة عن الليلة . يمكنك استخدام التطبيق الخاص بك أو تطبيق مفتوح المصدر مثل Hadoop.
لماذا لا نستخدم النسخة الإلكترونية على الفور؟ ليس مطلوبًا دائمًا ، فقد يؤدي إلى تعقيد عمليات إعادة الحساب في الماضي. إذا قمنا بإضافة خوارزمية جديدة ، وميزات جديدة ، فغالبًا ما نرغب في إعادة حساب البيانات في الماضي من أجل تغيير الأحكام عليها. من الصعب استخدام طرق الوزن الثقيل - أعتقد أنه من الواضح لماذا. والنسخة عبر الإنترنت ، لعدد من الأسباب ، يمكن أن تكون أكثر تطلبًا من حيث الموارد.
إذا استخدمنا MapReduce ، نحصل على شيء مثل هذا. نحن نستخدم نوعًا من الخلط الصغير ، أي أننا نقسم الدفعة إلى أصغر القطع الممكنة. في هذه الحالة ، دقيقة واحدة. لكن أولئك الذين يعملون مع MapReduce يعرفون أنه أقل من هذا الحجم ، ربما ، هناك بالفعل نفقات كبيرة جدًا للنظام نفسه - النفقات العامة. تقليديا ، لن تكون قادرة على التعامل مع المعالجة في دقيقة واحدة.
بعد ذلك ، نقوم بتشغيل مجموعة Reduce على هذه المجموعة من الدُفعات ونحصل على مجموعة مرمزة.

في مهامنا ، غالبًا ما يكون من الضروري حساب القيمة الدقيقة للميزات. على سبيل المثال ، إذا أردنا حساب العدد الدقيق للكتب التي قرأها المستخدم في الشهر الماضي ، فسنحسب هذه القيمة لكل دفعة ويجب تخزين جميع الإحصائيات المجمعة في مكان واحد. ثم قم بإزالة القيم القديمة منه وإضافة قيم جديدة.
لماذا لا تستخدم طرق العد الخام؟ إجابة مختصرة: نستخدمها أيضًا ، ولكن في بعض الأحيان في مشاكل مكافحة الاحتيال ، من المهم أن يكون لديك القيمة الدقيقة لبعض الفترات. على سبيل المثال ، يمكن أن يكون الفرق بين كتابين وثلاثة كتب مهمًا جدًا بالنسبة لطرق معينة.
ونتيجة لذلك ، نحتاج إلى سجل بيانات كبير سنقوم فيه بتخزين هذه الإحصائيات.
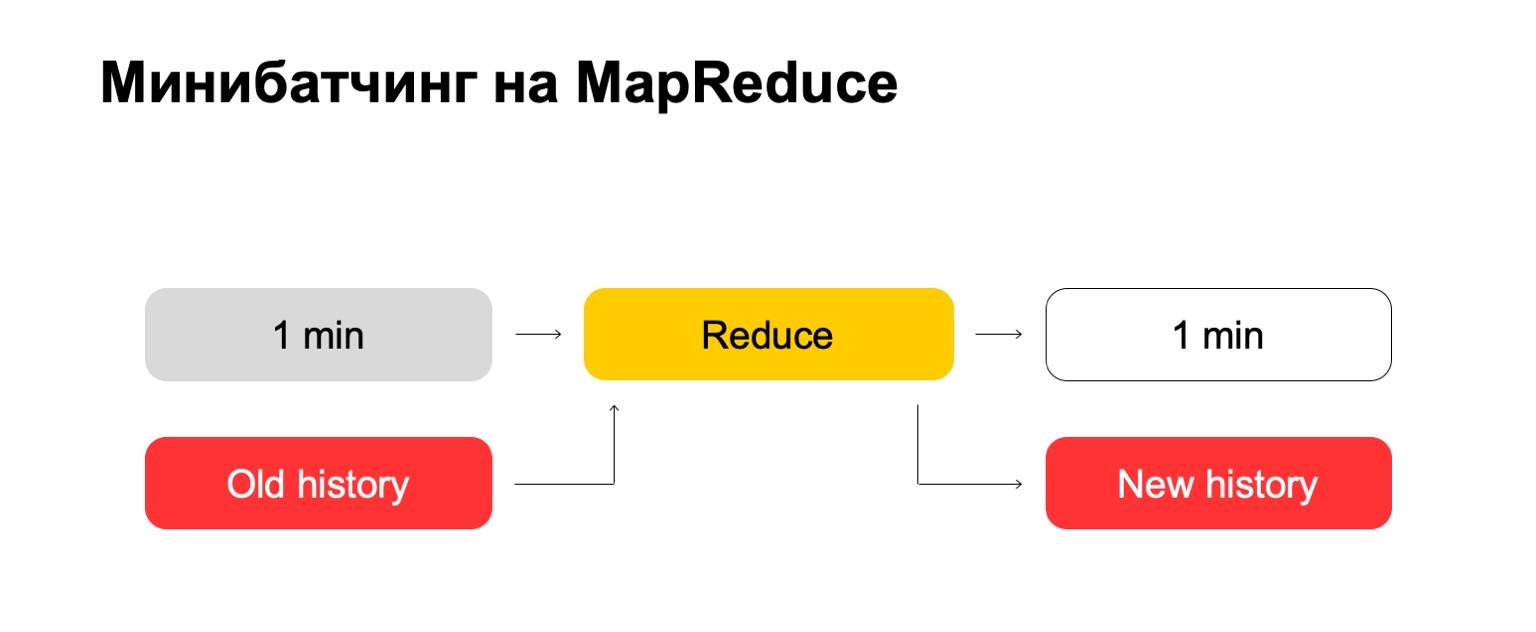
دعونا نحاول "وجها لوجه". لدينا دقيقة واحدة وقصة قديمة كبيرة. وضعناها في المدخلات المخففة وخرج محفوظات محدثة وسجل مميز وبيانات.
بالنسبة لأولئك منكم الذين عملوا مع MapReduce ، ربما تعرف أن هذا يمكن أن يعمل بشكل سيء للغاية. إذا كان التاريخ يمكن أن يكون مئات ، أو حتى آلاف ، عشرات الآلاف من المرات أكبر من الدفعة نفسها ، فإن هذه المعالجة يمكن أن تعمل بما يتناسب مع حجم التاريخ ، وليس حجم الدفعة.
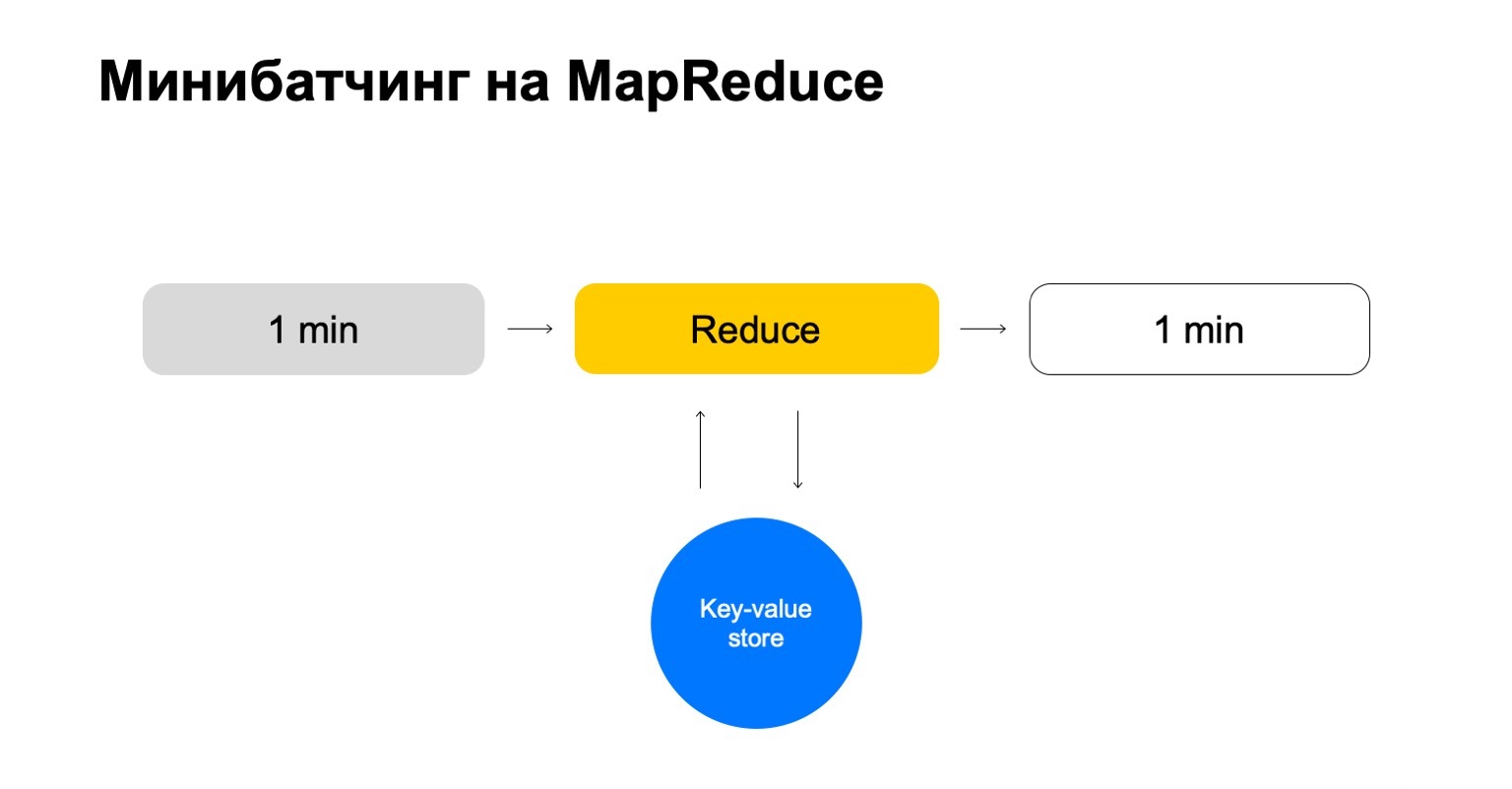
دعنا نستبدل هذا ببعض مخزن القيمة الرئيسية. هذا مرة أخرى تنفيذنا الخاص ، تخزين القيمة الرئيسية ، لكنه يخزن البيانات في الذاكرة. ربما أقرب التناظرية هو نوع من Redis. لكننا نحصل على ميزة طفيفة هنا: إن تنفيذنا لمتجر القيمة الرئيسية مدمج تمامًا مع MapReduce وكتلة MapReduce التي يعمل عليها. اتضح معاملات مريحة ، ونقل البيانات مريحة بينهما.
لكن المخطط العام هو أنه في كل مهمة من هذا التخفيض سنذهب إلى تخزين القيمة الرئيسية ، وتحديث البيانات وكتابتها مرة أخرى بعد تشكيل حكم عليها.
ننتهي بقصة تتعامل فقط مع المفاتيح التي نحتاجها وتتدرج بسهولة.
ميزات قابلة للتكوين
القليل عن كيفية تكوين الميزات. لا تكفي العدادات البسيطة غالبًا. للبحث عن المخادعين ، تحتاج إلى مجموعة متنوعة من الميزات ، تحتاج إلى نظام ذكي ومريح لتكوينها.
لنقسمها إلى ثلاث خطوات:
- استخراج ، حيث نقوم باستخراج البيانات للمفتاح المعطى ومن السجل.
- الدمج ، حيث ندمج هذه البيانات مع الإحصائيات الموجودة في التاريخ.
- بناء ، حيث نشكل القيمة النهائية للعنصر.
على سبيل المثال ، دعنا نحسب النسبة المئوية للقصص البوليسية التي يقرأها المستخدم.
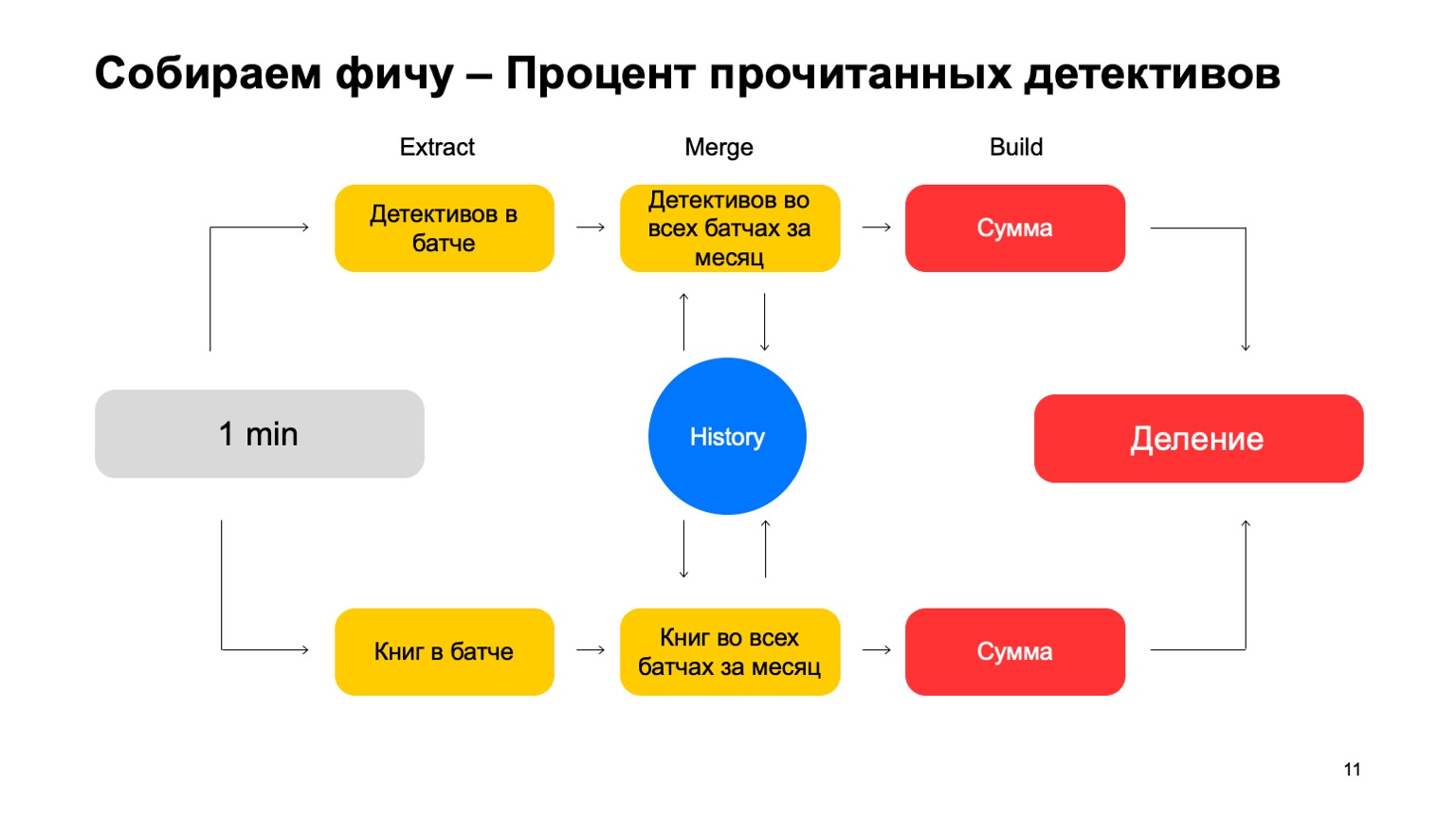
إذا قرأ المستخدم الكثير من القصص البوليسية ، فهو مشبوه للغاية. ليس من الواضح أبداً ما يمكن توقعه منه. ثم Extract هو إزالة عدد المحققين الذين قرأهم المستخدم في هذه الدفعة. دمج - أخذ جميع المحققين ، كل هذه البيانات من مجموعات لمدة شهر. والبناء هو قدر ما.
ثم نفعل الشيء نفسه بالنسبة لجميع الكتب التي قرأها ، وينتهي بنا الأمر بالتقسيم.
ماذا لو أردنا حساب قيم مختلفة ، على سبيل المثال ، عدد المؤلفين المختلفين الذين يقرأهم المستخدم؟
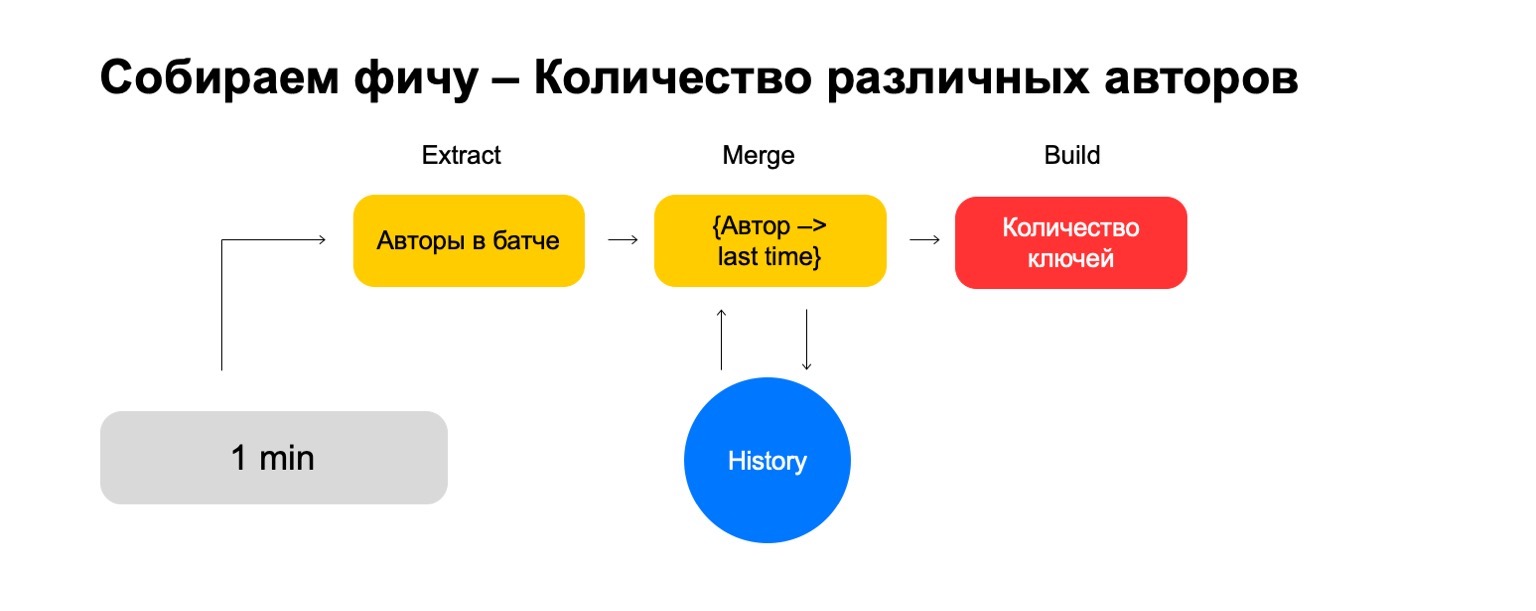
ثم يمكننا أخذ عدد المؤلفين المختلفين الذين قرأهم المستخدم في هذه الدفعة. علاوة على ذلك ، قم بتخزين بعض الهياكل حيث نقوم بإنشاء رابطة المؤلفين مؤخرًا ، عندما يقرأها المستخدم. وبالتالي ، إذا التقينا مرة أخرى بهذا المؤلف في المستخدم ، فإننا نقوم بتحديث هذه المرة. إذا كنا بحاجة إلى حذف الأحداث القديمة ، فنحن نعرف ما يجب حذفه. لحساب الميزة النهائية ، نحن ببساطة نحسب عدد المفاتيح فيها.

ولكن في إشارة صاخبة ، فإن هذه الميزات ليست كافية لقص واحد ، نحتاج إلى نظام لصق وصلاتهم ، ولصق هذه الميزات من قطع مختلفة.
دعونا ، على سبيل المثال ، نقدم مثل هذه التخفيضات - المستخدم والمؤلف والنوع.

دعونا نحسب شيئًا صعبًا. على سبيل المثال ، متوسط ولاء المؤلف. بالولاء ، أعني أن المستخدمين الذين قرأوا المؤلف - يكادون يقرؤونه فقط. علاوة على ذلك ، فإن متوسط القيمة هذا منخفض جدًا بالنسبة لمتوسط عدد المؤلفين الذين قرأهم المستخدمون الذين قرأوه.
قد تكون هذه إشارة محتملة. بالطبع ، يمكن أن يعني أن المؤلف مثل هذا تماما: لا يوجد سوى المعجبين من حوله ، وكل من يقرأه يقرأه فقط. ولكن يمكن أن يعني أيضًا أن المؤلف نفسه يحاول خداع النظام وإنشاء هؤلاء المستخدمين المزيفين الذين يفترض أنهم قرأوه.
دعونا نحاول حسابها. دعنا نحسب ميزة تحسب عدد المؤلفين المختلفين على مدى فترة طويلة. على سبيل المثال ، هنا تبدو القيمتان الثانية والثالثة مريبة لنا ، هناك القليل جدًا منها.
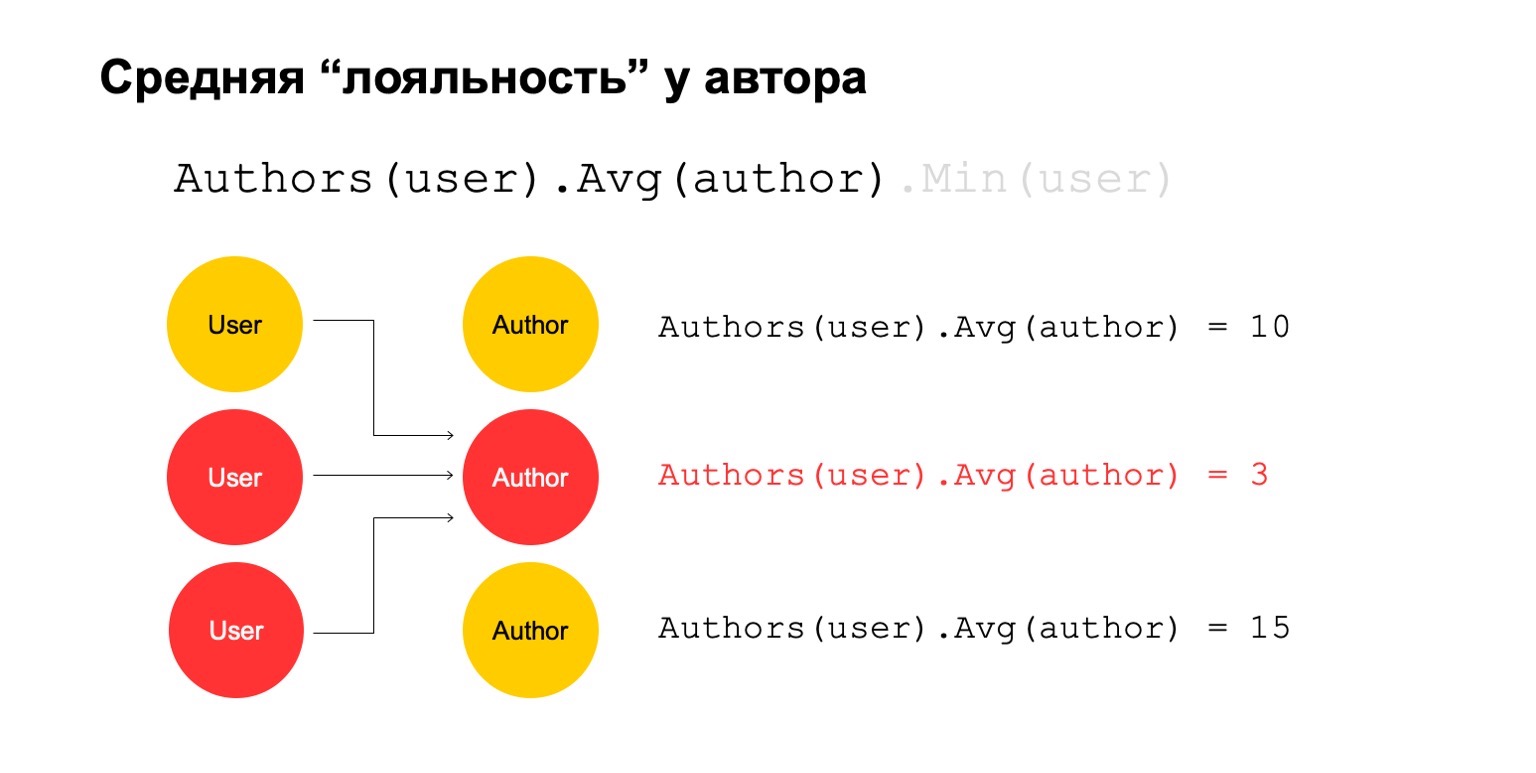
ثم دعنا نحسب متوسط القيمة للمؤلفين المرتبطين على مدى فاصل كبير. ثم هنا متوسط القيمة منخفض جدًا مرة أخرى: 3. لسبب ما ، يبدو هذا الكاتب مريبًا لنا.
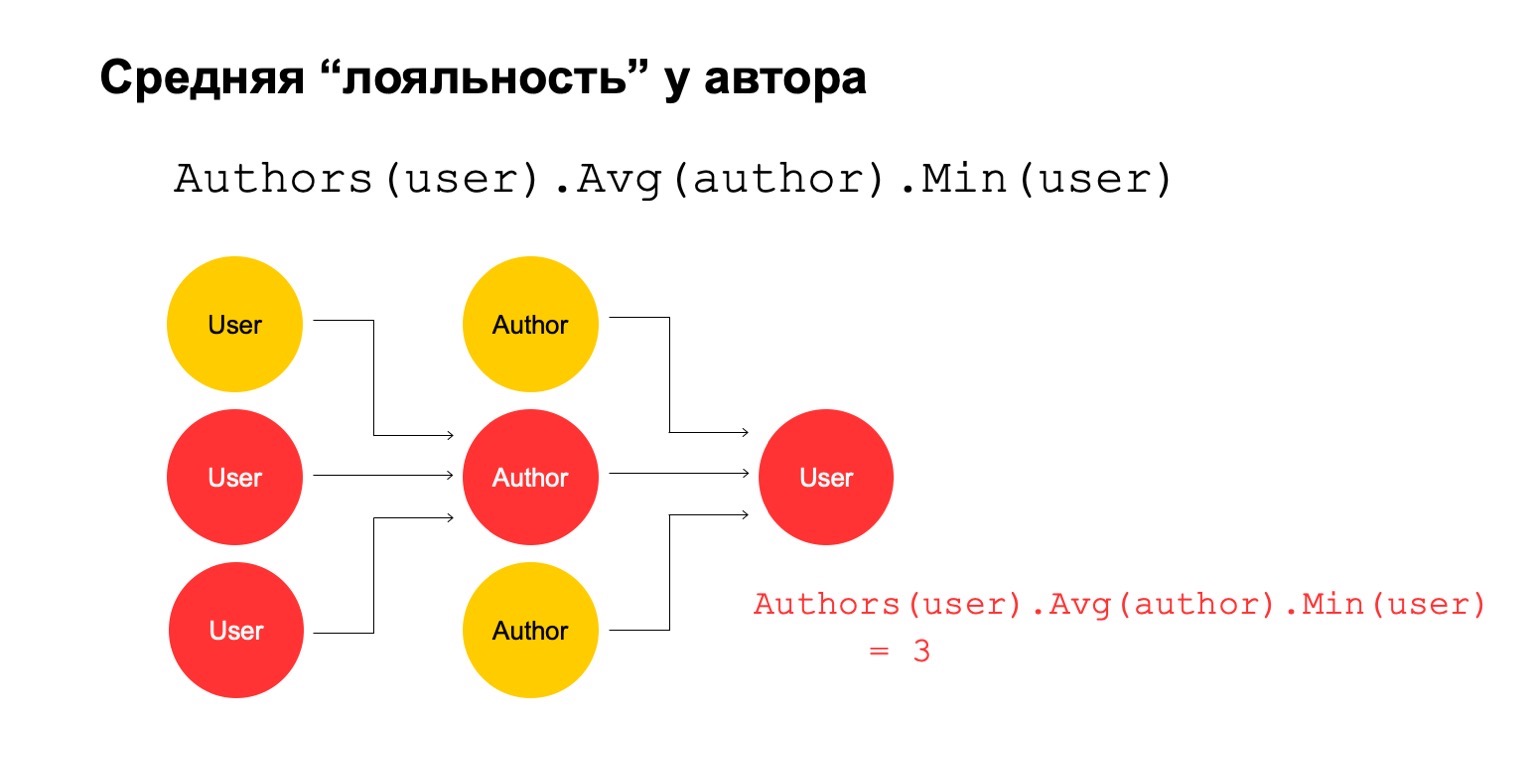
ويمكننا إعادته إلى المستخدم لفهم أن هذا المستخدم بالذات لديه اتصال بالمؤلف ، والذي يبدو مريبًا لنا.
من الواضح أن هذا في حد ذاته لا يمكن أن يكون معيارًا صريحًا لتصفية المستخدم أو شيء من هذا القبيل. ولكن قد يكون هذا أحد الإشارات التي يمكننا استخدامها.
كيف يتم ذلك في نموذج MapReduce؟ دعونا نجري عدة تخفيضات متتالية والتبعيات بينهما.

نحصل على رسم بياني للتخفيضات. فهو يؤثر على الشرائح التي نحسب الميزات ، التي يتم الانضمام إليها بشكل عام ، على كمية الموارد المستهلكة: من الواضح ، كلما زادت التخفيضات ، زادت الموارد. والكمون ، الإنتاجية.
دعونا نبني ، على سبيل المثال ، مثل هذا الرسم البياني.
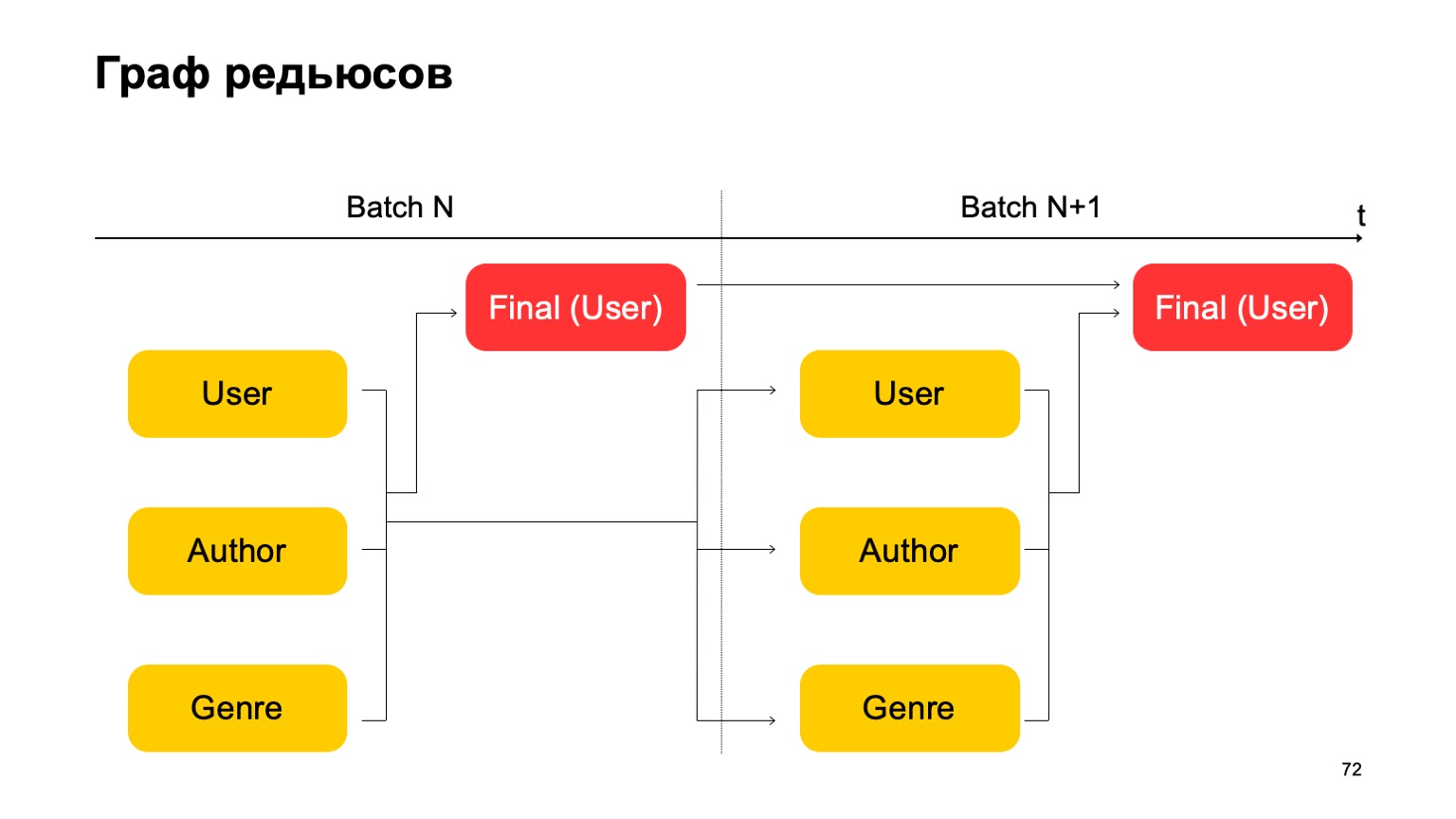
أي أننا سوف نقسم التخفيضات التي لدينا إلى مرحلتين. في المرحلة الأولى ، سنحسب تخفيضات مختلفة بالتوازي مع الأقسام المختلفة - مستخدمينا ومؤلفونا ونوعهم. ونحتاج إلى نوع من المرحلة الثانية ، حيث سنجمع ميزات من هذه التخفيضات المختلفة ونقبل الحكم النهائي.
بالنسبة للدفعة التالية ، نفعل نفس الشيء. علاوة على ذلك ، لدينا اعتماد من المرحلة الأولى من كل دفعة على المرحلة الأولى من الماضي والمرحلة الثانية على المرحلة الثانية من الماضي.
من المهم هنا أنه ليس لدينا مثل هذه التبعية:
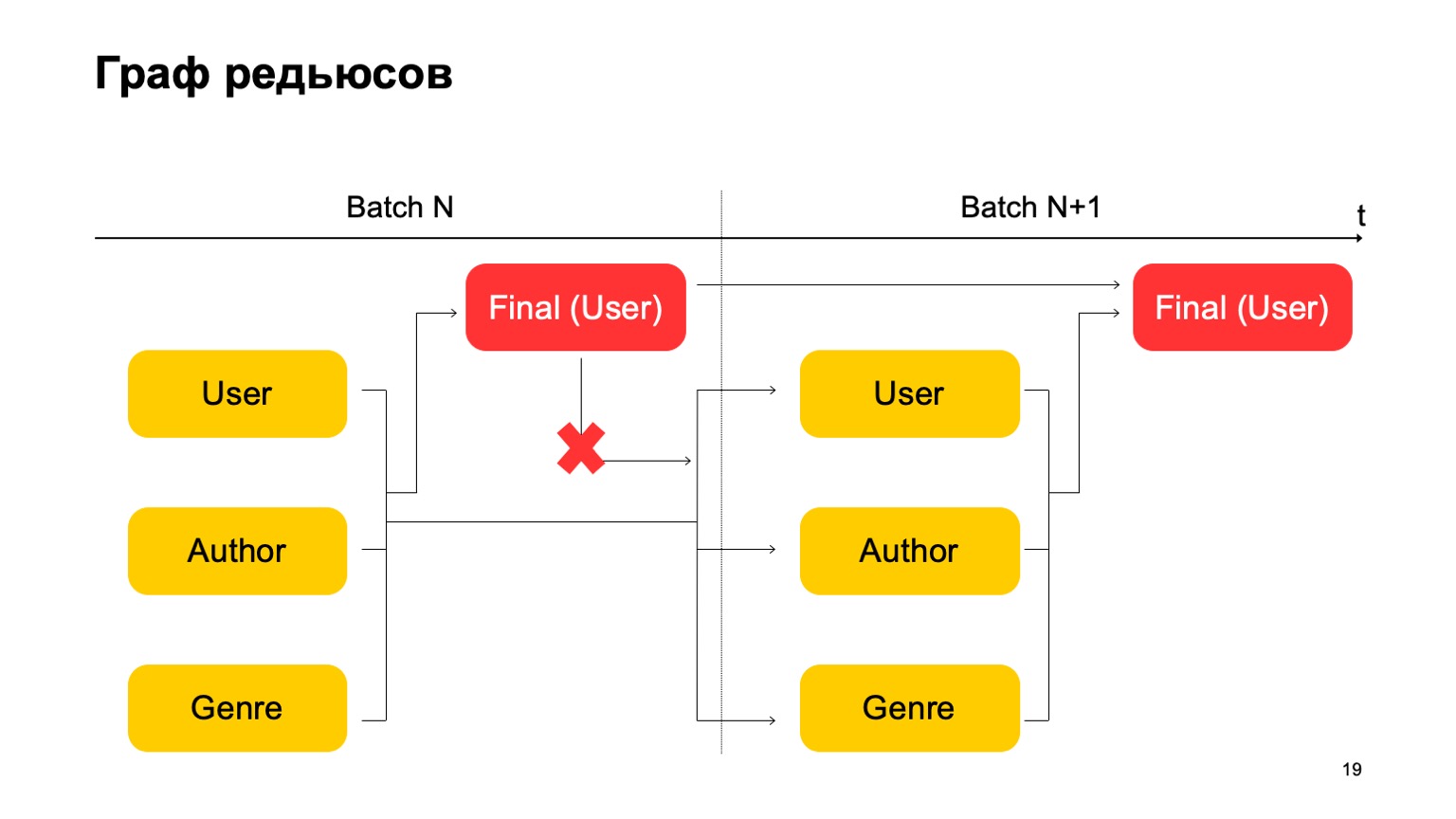
أي أننا في الواقع نحصل على ناقل. أي أن المرحلة الأولى من الدفعة التالية يمكن أن تعمل بالتوازي مع المرحلة الثانية من الدفعة الأولى.
كيف يمكننا عمل إحصائيات المراحل الثلاث في هذا ، والتي أعطيتها أعلاه ، إذا كان لدينا مرحلتان فقط؟ بسيط جدا. يمكننا قراءة القيمة الأولى في المرحلة الأولى من الدفعة N.
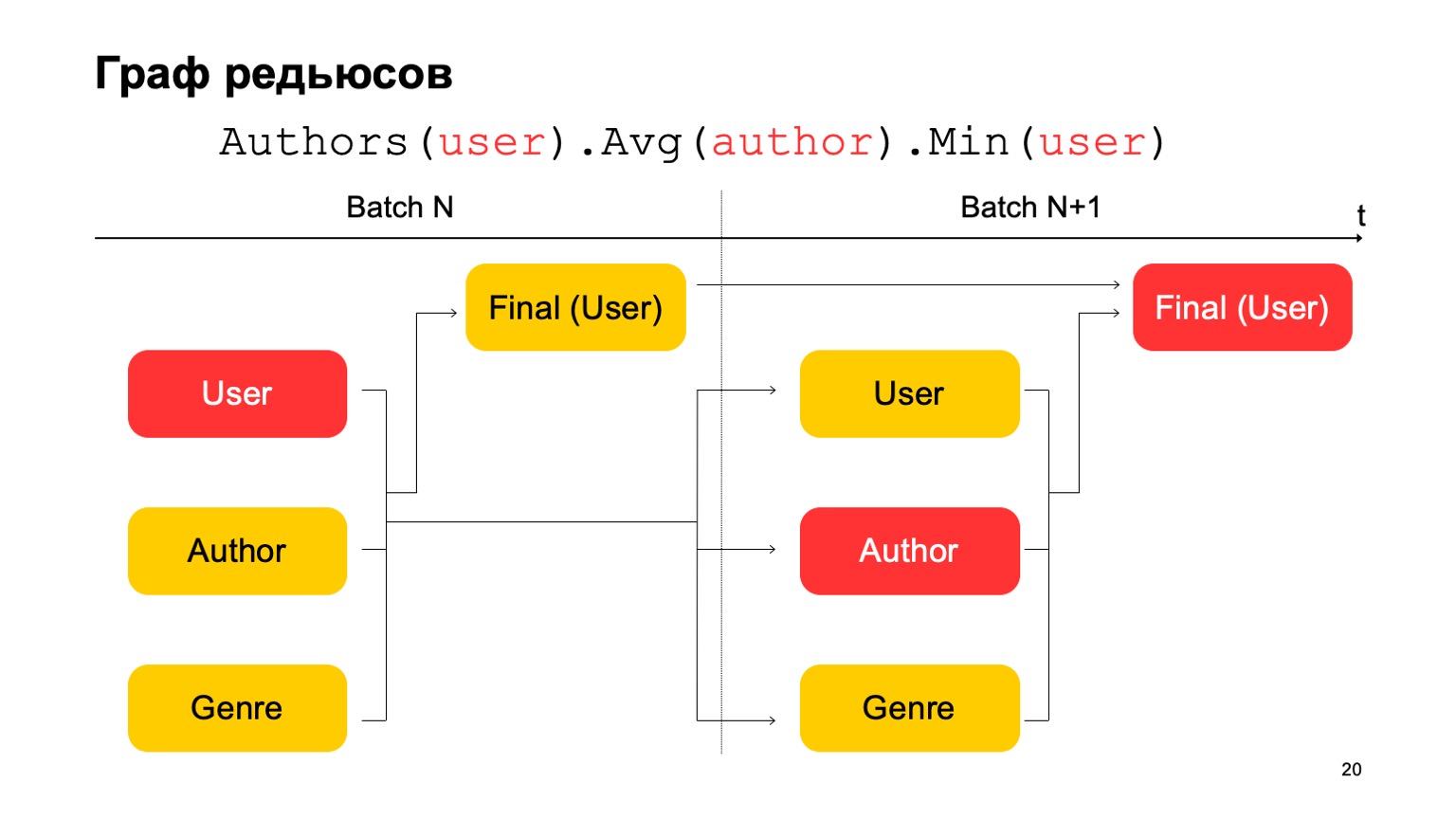
والقيمة الثانية في المرحلة الأولى من الدفعة هي N + 1 ، ويجب قراءة القيمة النهائية في المرحلة الثانية من الدفعة N + 1. وهكذا ، أثناء الانتقال بين المرحلة الأولى والثانية ، ربما لن تكون هناك إحصائيات دقيقة تمامًا لدفعة N + 1. ولكن عادة ما يكون هذا كافيًا لمثل هذه الحسابات.

بوجود كل هذه الأشياء ، يمكنك بناء ميزات أكثر تعقيدًا من المكعبات. على سبيل المثال ، انحراف التصنيف الحالي للكتاب عن متوسط تقييم المستخدم. أو نسبة المستخدمين الذين يقيمون كتابًا إيجابيًا جدًا أو سلبيًا جدًا. مشبوهة أيضا. أو متوسط تصنيف الكتاب من قبل المستخدمين الذين لديهم أكثر من تصنيف N للكتب المختلفة. ربما يكون هذا تقييمًا أكثر دقة ونزاهة من وجهة نظر معينة.

يضاف إلى ذلك ما نسميه العلاقة بين الأحداث. غالبًا ما تظهر التكرارات في السجلات أو في البيانات التي يتم إرسالها إلينا. يمكن أن تكون هذه أحداثًا فنية أو سلوكًا آليًا. نجد أيضا مثل هذه التكرارات. أو ، على سبيل المثال ، بعض الأحداث ذات الصلة. لنفترض أن نظامك يعرض توصيات الكتب ، وينقر المستخدمون على هذه التوصيات. حتى لا يتم إفساد الإحصائيات النهائية التي تؤثر على الترتيب ، نحتاج إلى التأكد من أنه إذا قمنا بتصفية الانطباع ، فيجب علينا أيضًا تصفية النقرة على التوصية الحالية.
ولكن نظرًا لأن تدفقنا قد يأتي بشكل غير متساوٍ ، فإن النقرة أولاً ، يجب أن نؤجله حتى نشاهد العرض ونقبل الحكم بناءً عليه.
لغة وصف الميزة
سأخبركم قليلاً عن اللغة المستخدمة لوصف كل هذا.

ليس عليك قراءتها ، هذا على سبيل المثال. بدأنا بثلاثة مكونات رئيسية. الأول هو وصف لوحدات البيانات في التاريخ ، بشكل عام ، من نوع اعتباطي.

هذا نوع من الميزة ، رقم لا يمكن إلغاؤه.

ونوع من الحكم. ماذا نسمي قاعدة؟ هذه مجموعة من الشروط لهذه الميزات وشيء آخر. كان لدينا ثلاثة ملفات منفصلة.
المشكلة هي أنه هنا تنتشر سلسلة واحدة من الإجراءات على ملفات مختلفة. يحتاج عدد كبير من المحللين إلى العمل مع نظامنا. كانوا غير مرتاحين.
اتضح أن اللغة ضرورية: فنحن نصف كيف نحسب البيانات ، وليس الإعلانات ، عندما سنصف ما نحتاج إلى حسابه. هذا أيضًا ليس مناسبًا جدًا ، إنه سهل بما يكفي لارتكاب خطأ وعتبة دخول عالية. يأتي أشخاص جدد ، لكنهم لا يفهمون تمامًا كيفية التعامل معها على الإطلاق.
الحل - دعنا نصنع DSL الخاصة بنا. يصف السيناريو الخاص بنا بشكل أكثر وضوحًا ، إنه أسهل للأشخاص الجدد ، إنه أكثر مستوى. لقد استلهمنا من SQLAlchemy و C # Linq وما شابه.
سأعطي بضعة أمثلة مماثلة لتلك التي ذكرتها أعلاه.

نسبة القصص البوليسية المقروءة. نحن نحسب عدد الكتب التي تمت قراءتها ، أي أننا نجمعها حسب المستخدم. نضيف التصفية إلى هذا الشرط ، وإذا أردنا حساب النسبة النهائية ، فإننا فقط نحسب التصنيف. كل شيء بسيط وواضح وبديهي.

إذا قمنا بحساب عدد المؤلفين المختلفين ، فإننا نقوم بالتجميع حسب المستخدم وتعيين مؤلفين مميزين. إلى هذا ، يمكننا إضافة بعض الشروط ، على سبيل المثال ، نافذة حساب أو حد لعدد القيم التي نخزنها بسبب قيود الذاكرة. نتيجة لذلك ، نحسب عدد المفاتيح فيه.

أو الولاء العادي الذي كنت أتحدث عنه. هذا ، مرة أخرى ، لدينا نوع من التعبير محسوب من فوق. نجمعها حسب المؤلف ونضع بعض القيمة المتوسطة بين هذه التعبيرات. ثم نضيقها مرة أخرى للمستخدم.

إلى هذا يمكننا بعد ذلك إضافة شرط تصفية. أي أن الفلتر الخاص بنا يمكن أن يكون ، على سبيل المثال ، ما يلي: الولاء ليس مرتفعًا جدًا ونسبة المحققين تتراوح بين 80 من 100.
ماذا نستخدم لهذا تحت غطاء محرك السيارة؟
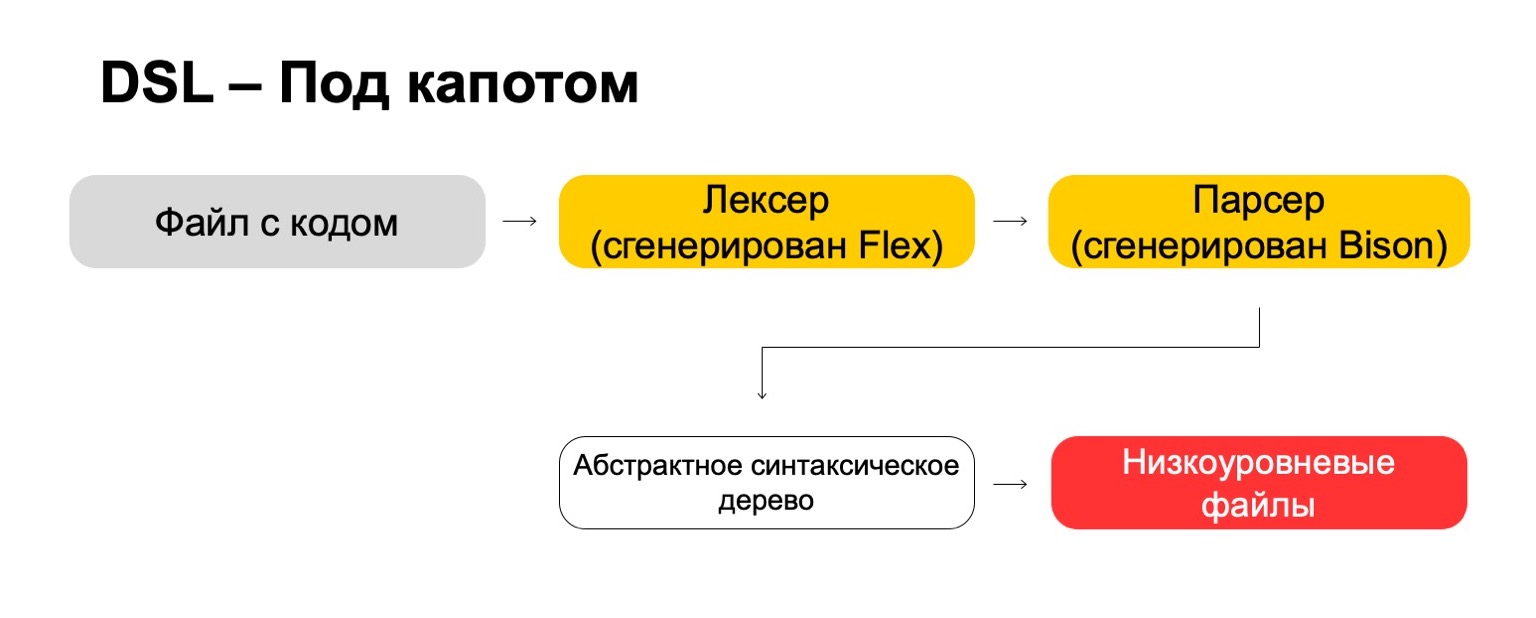
تحت الغطاء ، نستخدم أحدث التقنيات مباشرة من السبعينيات ، مثل Flex و Bison. ربما سمعت. يولدون رمز. يمر ملف الشفرة الخاص بنا من خلال lexer الخاص بنا ، والذي يتم إنشاؤه في Flex ، ومن خلال المحلل اللغوي ، الذي يتم إنشاؤه في Bison. يولد lexer رموزًا أو كلمات طرفية في اللغة ، ويقوم المحلل اللغوي بإنشاء تعبيرات بناء الجملة.
من هذا نحصل على شجرة بناء مجردة ، والتي يمكننا بالفعل القيام بتحويلات. وفي النهاية ، نقوم بتحويلها إلى ملفات منخفضة المستوى يفهمها النظام.
ما هو الحد الأدنى؟ هذا أكثر تعقيدًا مما قد يبدو للوهلة الأولى. يتطلب الأمر الكثير من الموارد للتفكير في الأشياء الصغيرة مثل أولويات العمليات وحالات الحافة وما شابه. تحتاج إلى تعلم تقنيات نادرة من غير المرجح أن تكون مفيدة لك في الحياة الواقعية ، ما لم تكتب مترجمين ، بالطبع. ولكن في النهاية الأمر يستحق ذلك. هذا ، إذا كان لديك ، مثلنا ، عدد كبير من المحللين الذين يأتون غالبًا من فرق أخرى ، فإن هذا في النهاية يعطي ميزة كبيرة ، لأنه يصبح من الأسهل عليهم العمل.
الموثوقية
تتطلب بعض الخدمات التسامح مع الخطأ: عبر DC ومعالجة مرة واحدة بالضبط. يمكن أن يسبب الانتهاك تباينًا في الإحصائيات والخسائر ، بما في ذلك الخسائر النقدية. الحل الذي نقدمه لـ MapReduce هو أننا نقرأ البيانات في وقت واحد على مجموعة واحدة فقط ونزامنها في الثانية.
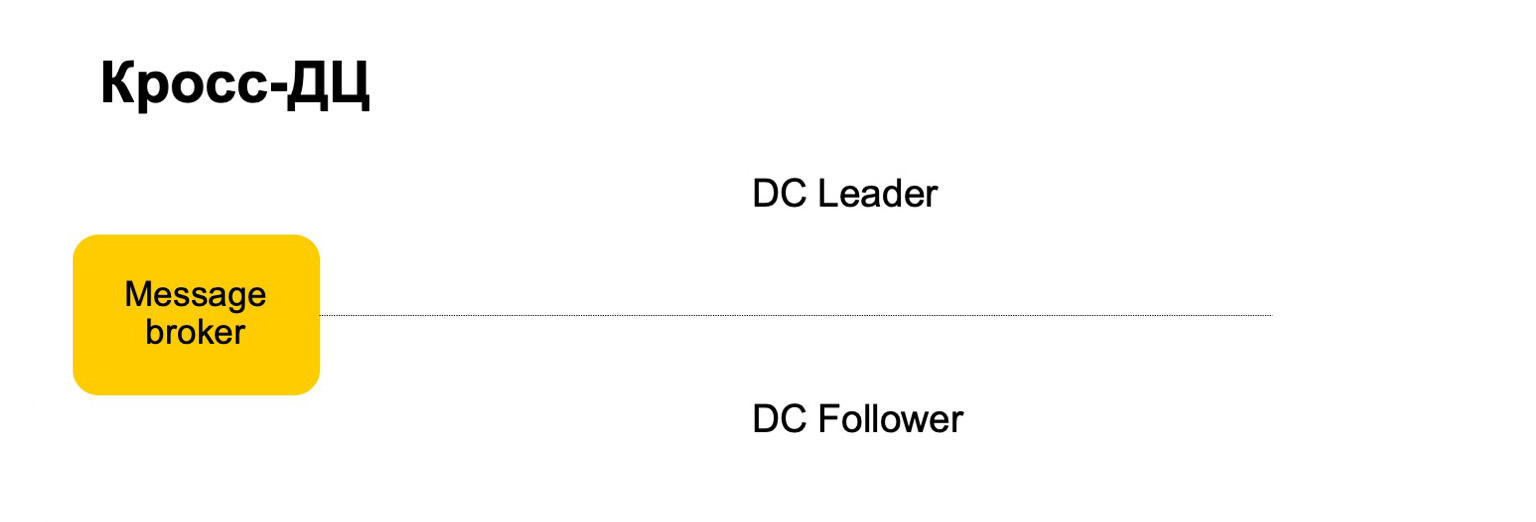
على سبيل المثال ، كيف نتصرف هنا؟ هناك قائد ومتابع ووسيط رسائل. يمكن اعتبار أن هذه الكافكا مشروطة ، على الرغم من هنا ، بالطبع ، تنفيذها الخاص.
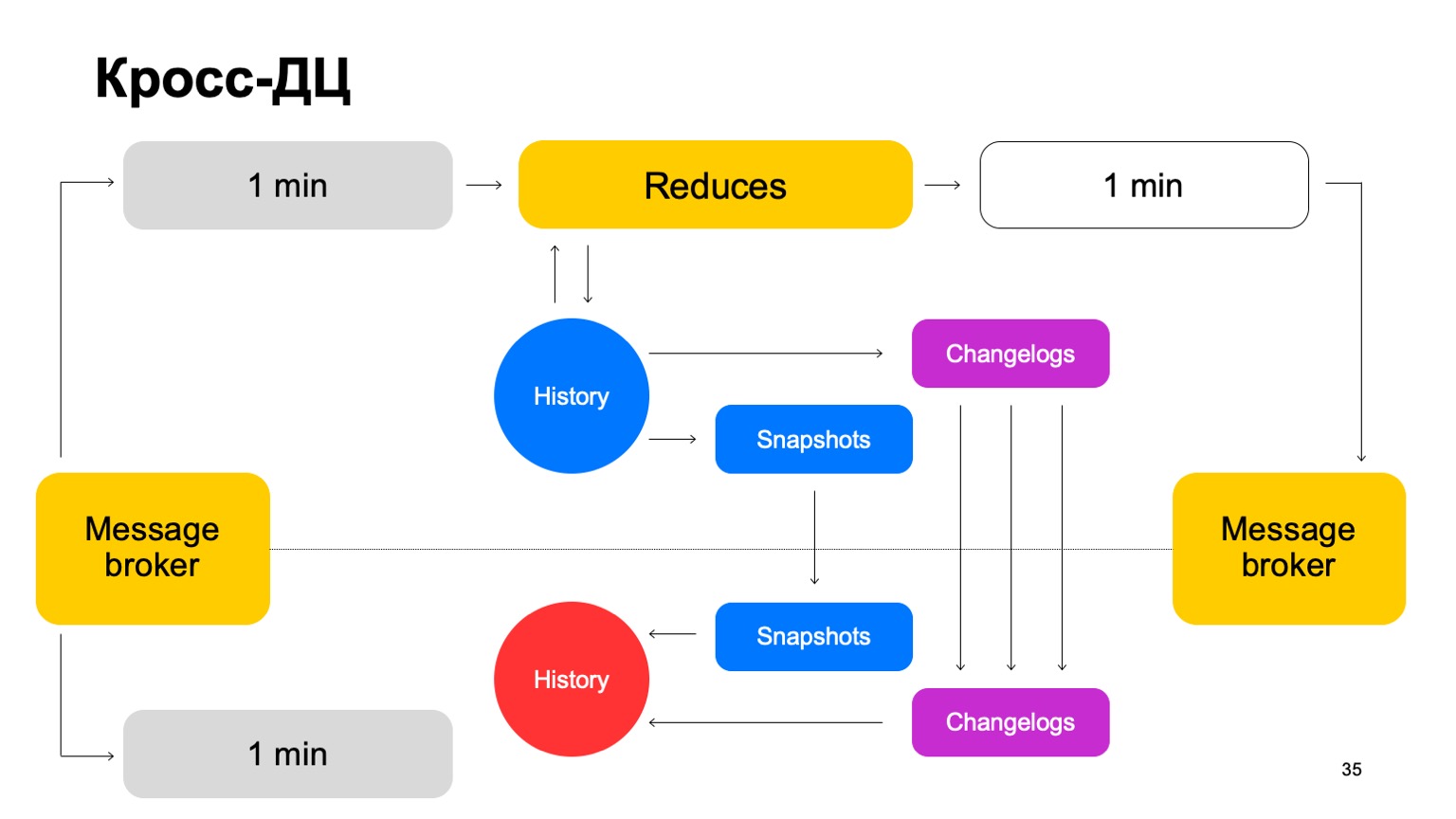
نقوم بتسليم دفعاتنا إلى كلتا المجموعتين ، ونطلق مجموعة من التخفيضات على القائد نفسه ، ونقبل الأحكام النهائية ، ونحدث التاريخ ، ونرسل النتائج مرة أخرى إلى الخدمة إلى وسيط الرسائل.
من حين لآخر ، من الطبيعي أن نقوم بالنسخ المتماثل. أي أننا نجمع لقطات ونجمع التغييرات - التغييرات لكل دفعة. نقوم بمزامنة كليهما مع متابع الكتلة الثاني. وكذلك طرح قصة ساخنة للغاية. دعني أذكرك بأن التاريخ محفوظ في الذاكرة هنا.
وبالتالي ، إذا أصبح DC واحد لسبب ما غير متوفر ، يمكننا بسرعة كافية ، مع الحد الأدنى من التأخير ، التحول إلى المجموعة الثانية.
لماذا لا نعتمد على مجموعتين بالتوازي على الإطلاق؟ يمكن أن تختلف البيانات الخارجية في مجموعتين ، يمكن توفيرها من قبل الخدمات الخارجية. ما هي البيانات الخارجية على أي حال؟ هذا شيء يرتفع من هذا المستوى الأعلى. أي ، التكتلات المعقدة وما شابه ذلك. أو مجرد بيانات مساعدة للحسابات.
نحن بحاجة إلى حل متفق عليه. إذا أحسبنا الأحكام بالتوازي باستخدام بيانات مختلفة وقمنا بالتبديل الدوري بين النتائج من مجموعتين مختلفتين ، فسوف ينخفض الاتساق بينهما بشكل كبير. وبطبيعة الحال ، توفير الموارد. نظرًا لأننا نستخدم موارد وحدة المعالجة المركزية على كتلة واحدة فقط في كل مرة.
ماذا عن المجموعة الثانية؟ عندما نعمل ، يكون خاملاً. دعنا نستخدم موارده في مرحلة ما قبل الإنتاج الكاملة. من خلال مرحلة ما قبل الإنتاج الكاملة ، أعني هنا تثبيتًا كاملًا يقبل نفس تدفق البيانات ، ويعمل مع نفس أحجام البيانات ، وما إلى ذلك.

إذا كانت المجموعة غير متاحة ، فإننا نغير هذه التركيبات من البيع إلى الإنتاج المسبق. وبالتالي ، لدينا إعداد مسبق لبعض الوقت ، ولكن لا بأس.
الميزة هي أنه يمكننا حساب المزيد من الميزات على المعالجة المسبقة. لماذا هذا ضروري؟ لأنه من الواضح أنه إذا أردنا أن نحسب كمية كبيرة من الميزات ، فإننا لا نحتاج غالبًا إلى احتسابها جميعًا للبيع. هناك ، نحسب فقط ما هو مطلوب للحصول على الأحكام النهائية.
(00:25:12)
ولكن في نفس الوقت ، لدينا نوع من ذاكرة التخزين المؤقت الساخنة في المعالجة المسبقة ، الكبيرة ، مع مجموعة متنوعة من الميزات. في حالة حدوث هجوم ، يمكننا استخدامه لإغلاق المشكلة ونقل هذه الميزات إلى الإنتاج.
يضاف إلى ذلك فوائد اختبار B2B. أي أننا جميعًا نبدأ ، بالطبع ، أولاً للبيع المسبق. نحن نقارن تمامًا أي اختلافات ، وبالتالي ، لن نكون مخطئين ، ونقلل من احتمالية ارتكاب خطأ عند طرحه للبيع.
القليل عن المجدول. من الواضح أن لدينا نوعًا من الآلات التي تدير المهمة في MapReduce. هؤلاء هم نوع من العمال. يقومون بمزامنة بياناتهم بانتظام إلى قاعدة بيانات Cross-DC. هذه ليست سوى الحالة التي تمكنوا من حسابها في الوقت الحالي.
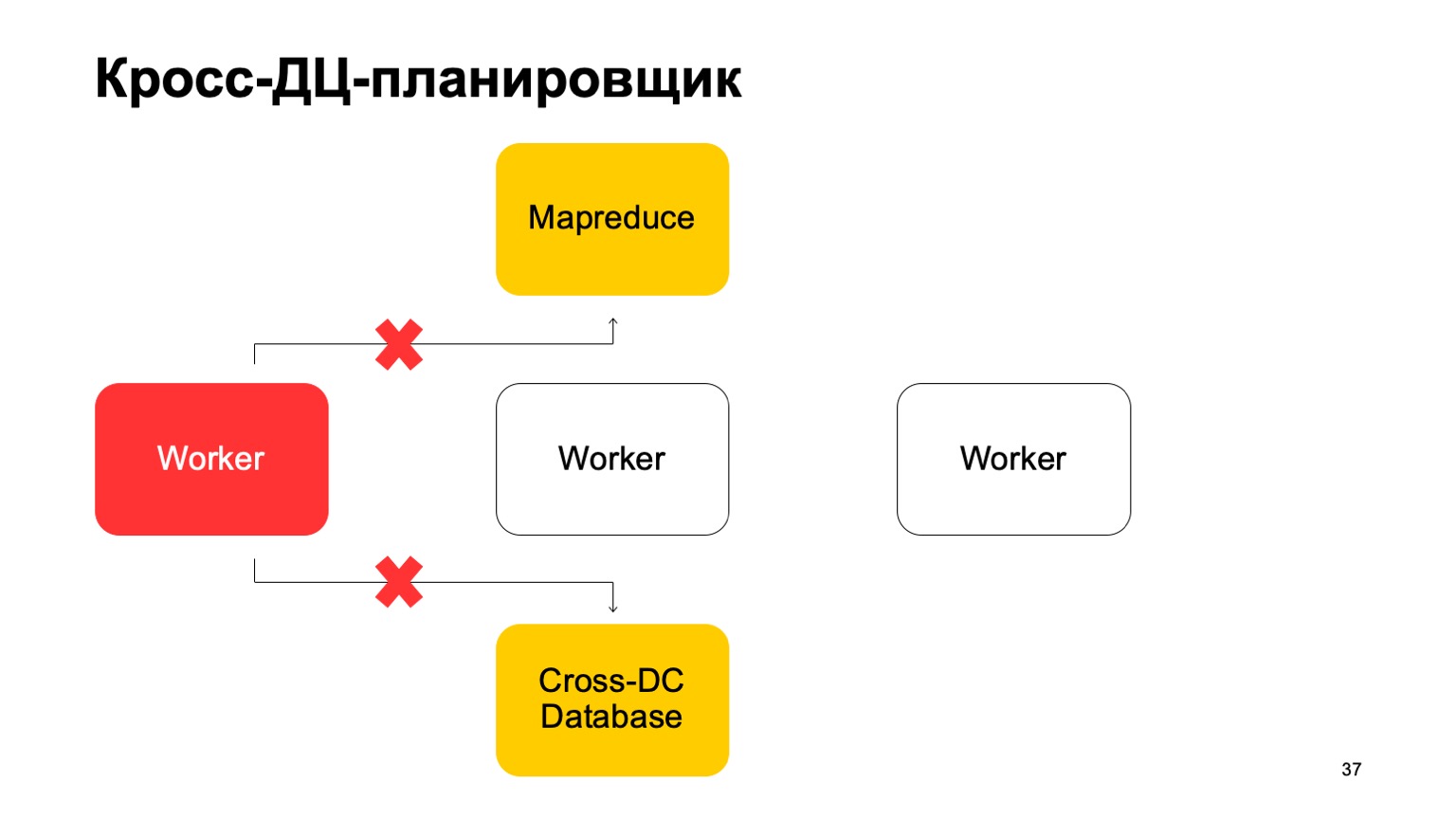
إذا أصبح العامل غير متاح ، فسيحاول عامل آخر التقاط السجل ، خذ الدولة.
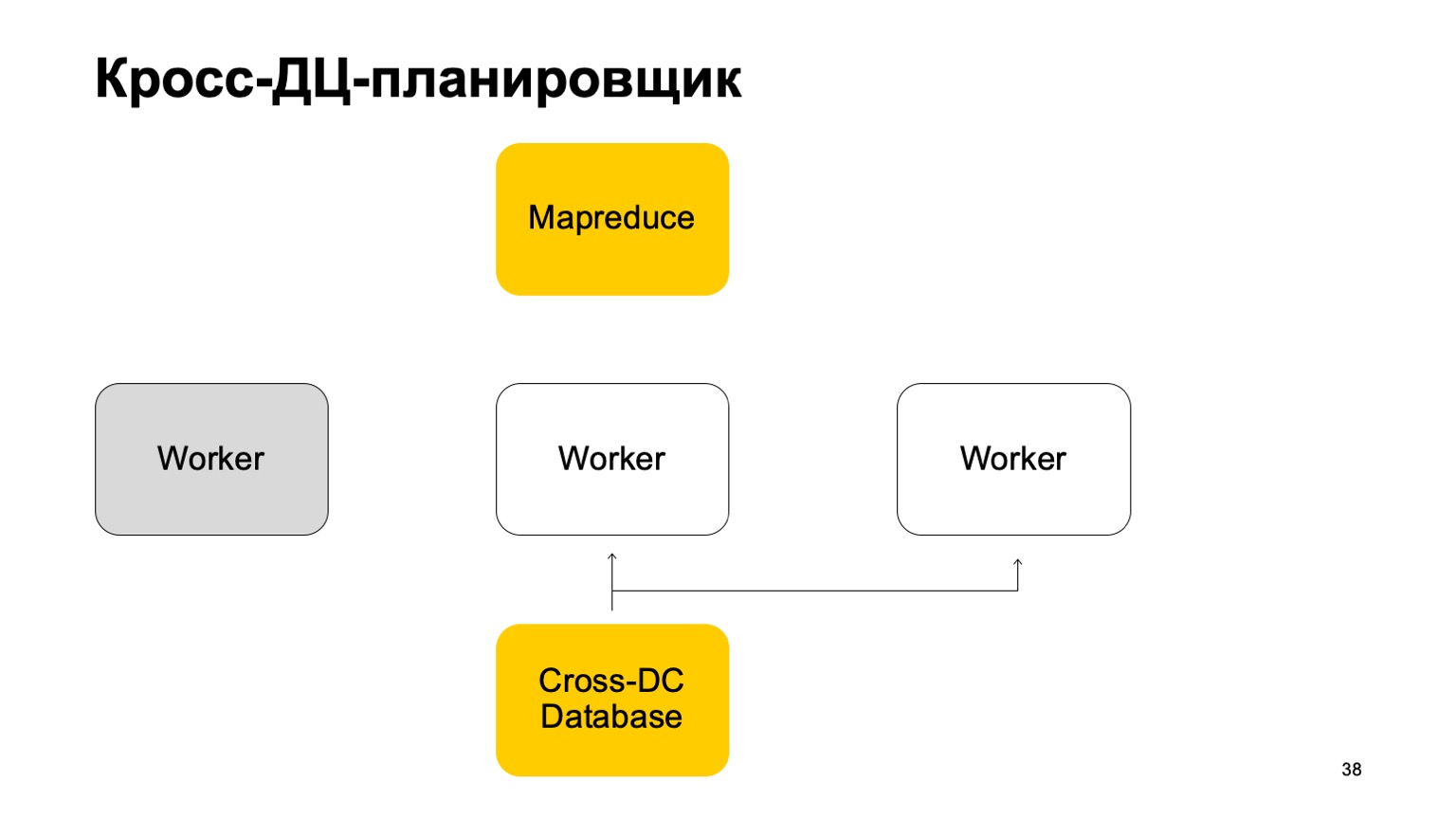
استيقظ من ذلك واستمر في العمل. استمر في تعيين المهام على MapReduce هذا.
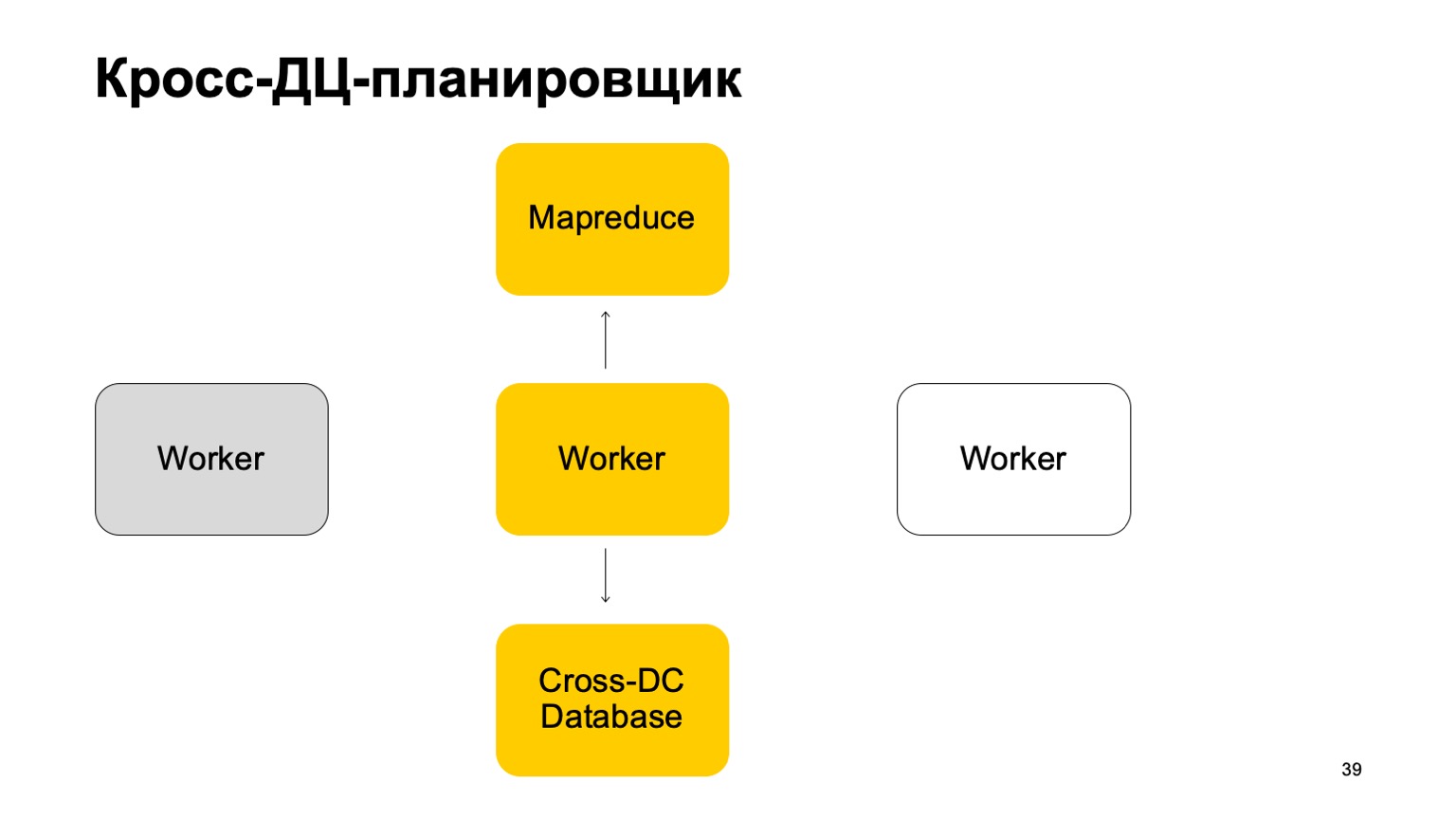
من الواضح أنه في حالة تجاوز هذه المهام ، يمكن إعادة تشغيل بعضها. لذلك ، هناك خاصية مهمة للغاية بالنسبة لنا هنا: idempotency ، والقدرة على إعادة تشغيل كل عملية دون عواقب.
أي أنه يجب كتابة جميع التعليمات البرمجية بطريقة تعمل بشكل جيد.

سأخبرك قليلاً عن مرة واحدة بالضبط. نحن نتوصل إلى قرار في حفلة موسيقية ، وهذا مهم جدا. نحن نستخدم التقنيات التي تمنحنا مثل هذه الضمانات ، وبطبيعة الحال ، نحن نراقب جميع التناقضات ، ونخفضها إلى الصفر. حتى عندما يبدو أن هذا قد تم تقليله بالفعل ، من وقت لآخر تنشأ مشكلة صعبة للغاية لم نأخذها بعين الاعتبار.
الادوات
باختصار شديد حول الأدوات التي نستخدمها. إن الحفاظ على العديد من أنظمة مكافحة الاحتيال لأنظمة مختلفة مهمة صعبة. لدينا بالفعل عشرات الخدمات المختلفة ، نحتاج إلى نوع واحد من مكان واحد حيث يمكنك رؤية حالة عملهم في الوقت الحالي.
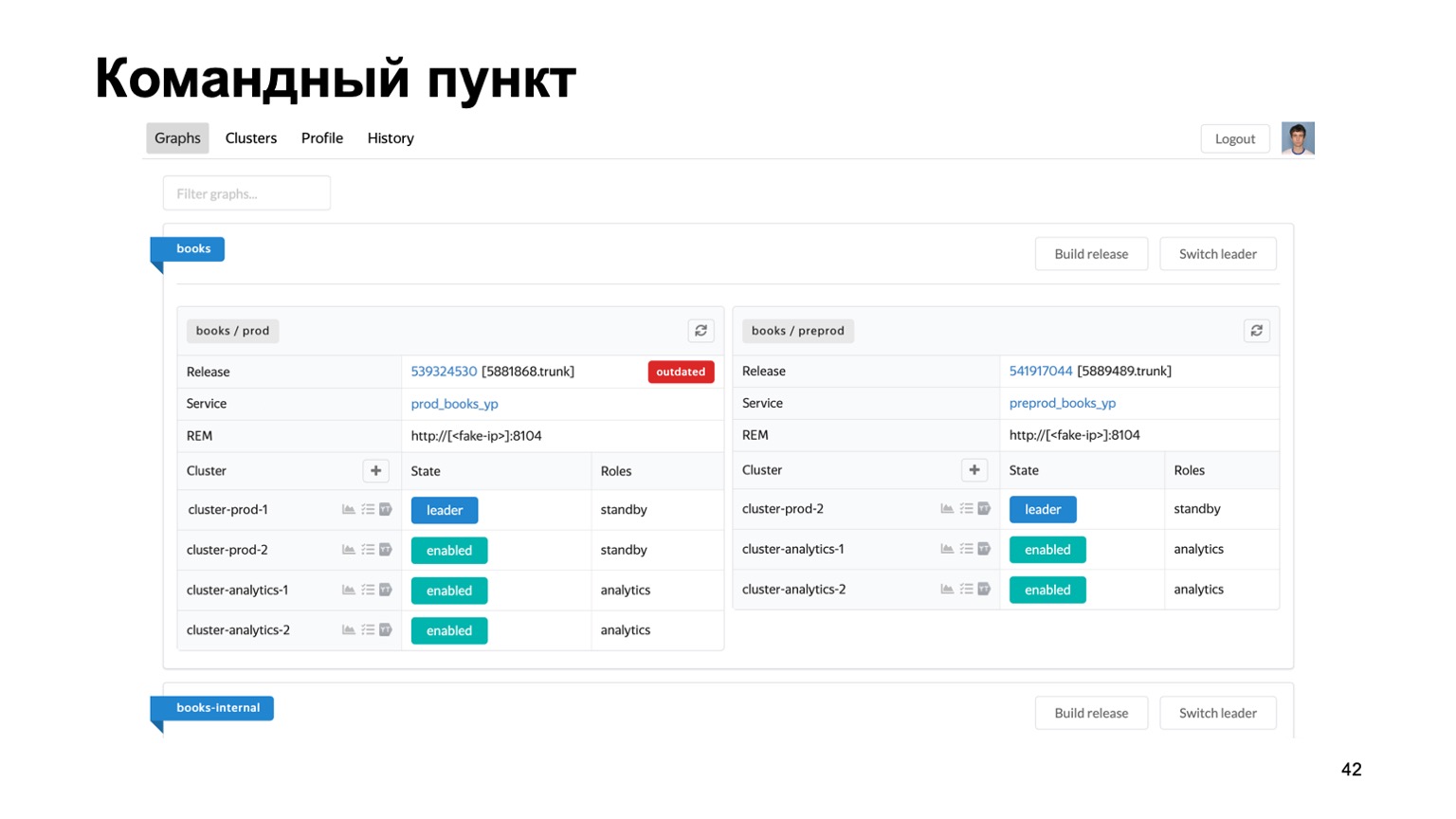
إليك مركز القيادة الخاص بنا ، حيث يمكنك رؤية حالة المجموعات التي نعمل معها حاليًا. يمكنك تبديلها بين بعضها البعض ، أو طرح إصدار ، إلخ.
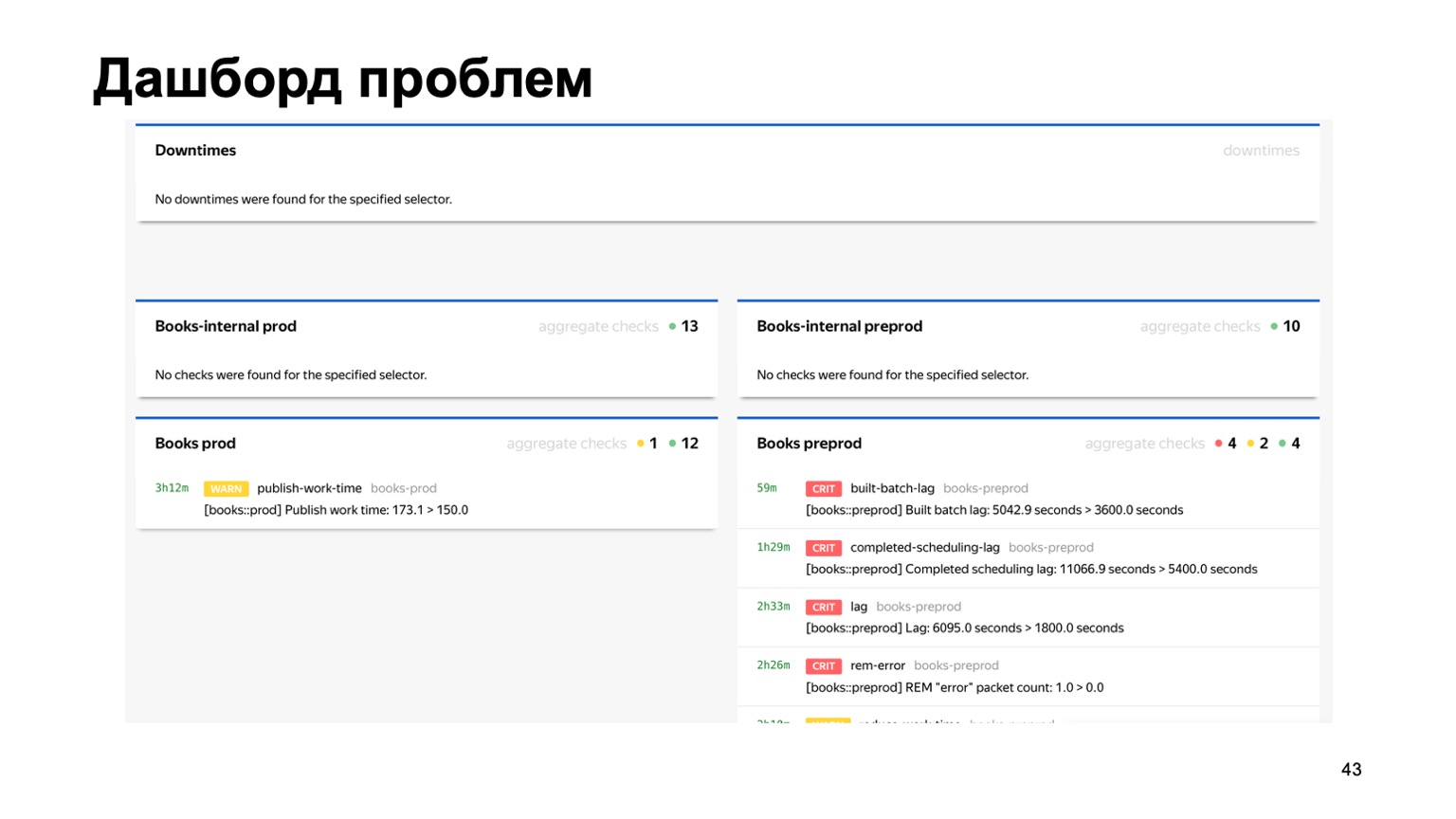
أو ، على سبيل المثال ، لوحة تحكم بالمشاكل ، حيث نرى على الفور على صفحة واحدة جميع مشاكل جميع برامج مكافحة الاحتيال للخدمات المختلفة المتصلة بنا. هنا يمكنك أن ترى أن هناك خطأ ما في خدمة الكتاب لدينا في الوقت الحالي. لكن المراقبة ستنجح ، وسوف ينظر إليها الشخص المسؤول.
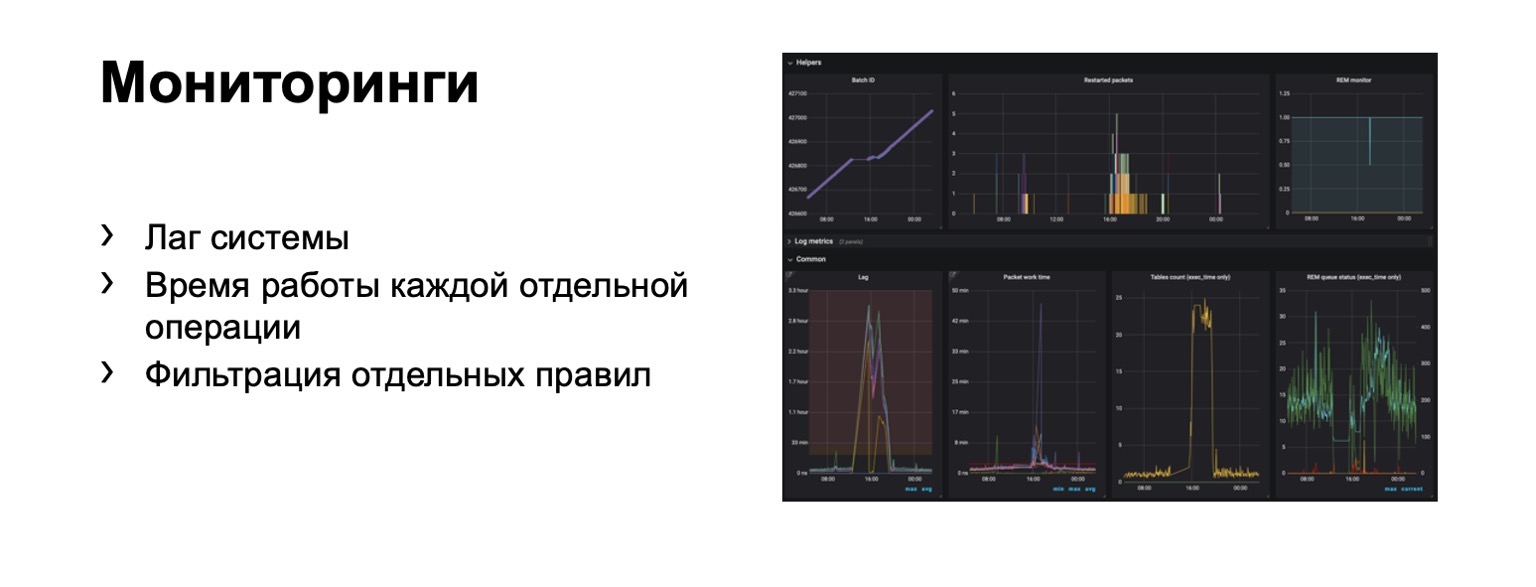
ما الذي نراقبه على الإطلاق؟ من الواضح أن تأخر النظام مهم للغاية. من الواضح ، وقت تشغيل كل مرحلة فردية ، وبطبيعة الحال ، تصفية القواعد الفردية. هذا متطلب عمل.
تظهر المئات من الرسوم البيانية ولوحات المعلومات. على سبيل المثال ، في لوحة العدادات هذه ، يمكنك أن ترى أن الكفاف كان سيئًا بما يكفي الآن لأن لدينا تأخرًا كبيرًا.
سرعة
سأخبرك عن الانتقال إلى الجزء عبر الإنترنت. المشكلة هنا هي أن التأخر في دائرة كاملة يمكن أن يصل إلى بضع دقائق. إنه في المخطط التفصيلي على MapReduce. في بعض الحالات ، نحتاج إلى حظر واكتشاف المحتالين بشكل أسرع.
ماذا يمكن أن يكون؟ على سبيل المثال ، خدمتنا لديها الآن القدرة على شراء الكتب. وفي الوقت نفسه ، ظهر نوع جديد من الاحتيال في الدفع. تحتاج إلى الرد عليه بشكل أسرع. السؤال الذي يطرح نفسه - كيفية نقل هذا المخطط بأكمله ، مع الحفاظ بشكل مثالي على لغة التفاعل المألوفة للمحللين قدر الإمكان؟ دعونا نحاول نقلها "إلى الجبين".
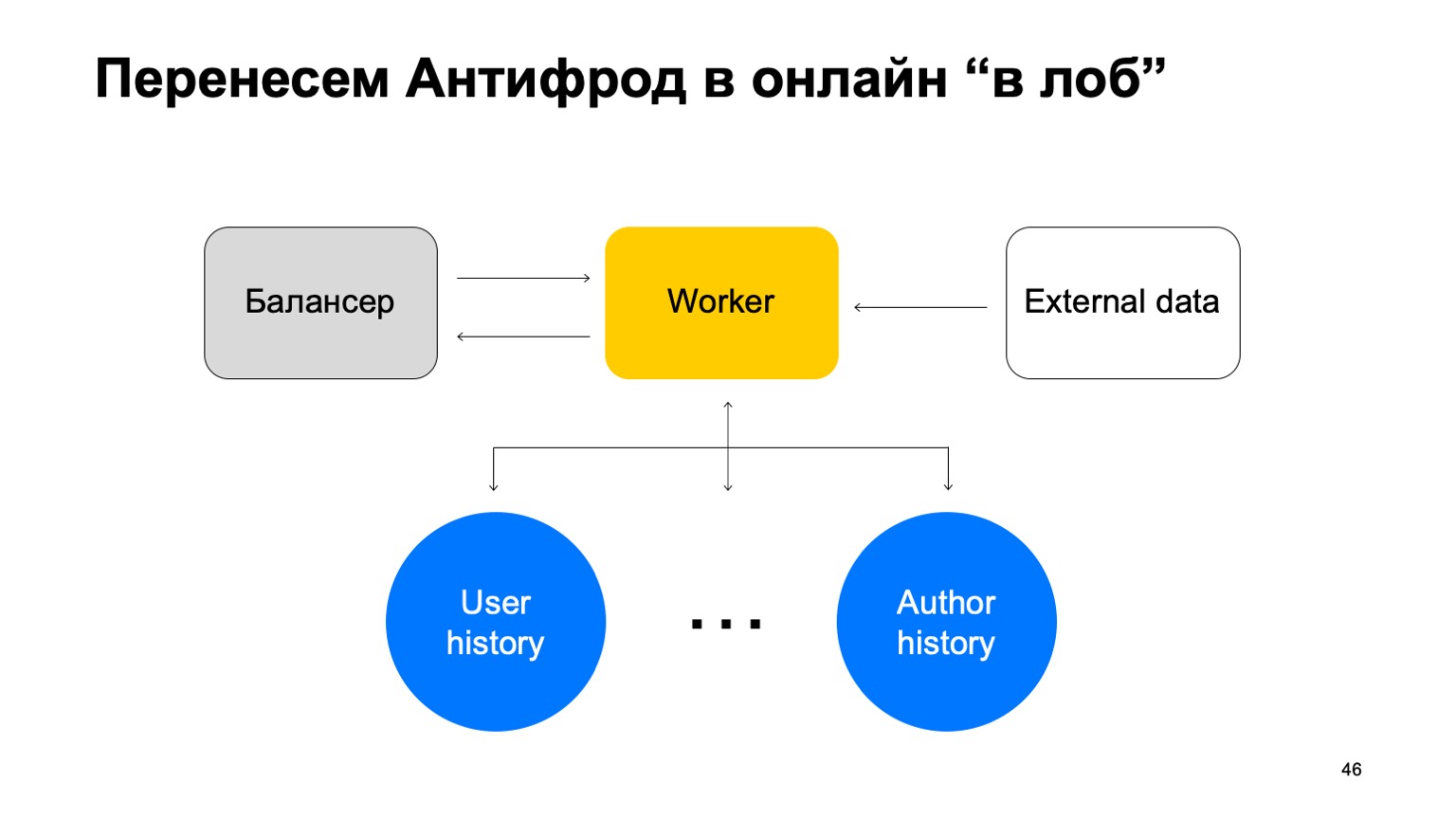
لنفترض أن لدينا موازنًا مع بيانات من الخدمة وعددًا معينًا من العمال نقوم بجمع البيانات من الموازن. هناك بيانات خارجية نستخدمها هنا ، وهي مهمة للغاية ، ومجموعة من هذه القصص. اسمحوا لي أن أذكرك بأن كل قصة مختلفة باختلاف التخفيضات ، لأنها تحتوي على مفاتيح مختلفة.
في مثل هذا المخطط ، قد تنشأ المشكلة التالية.
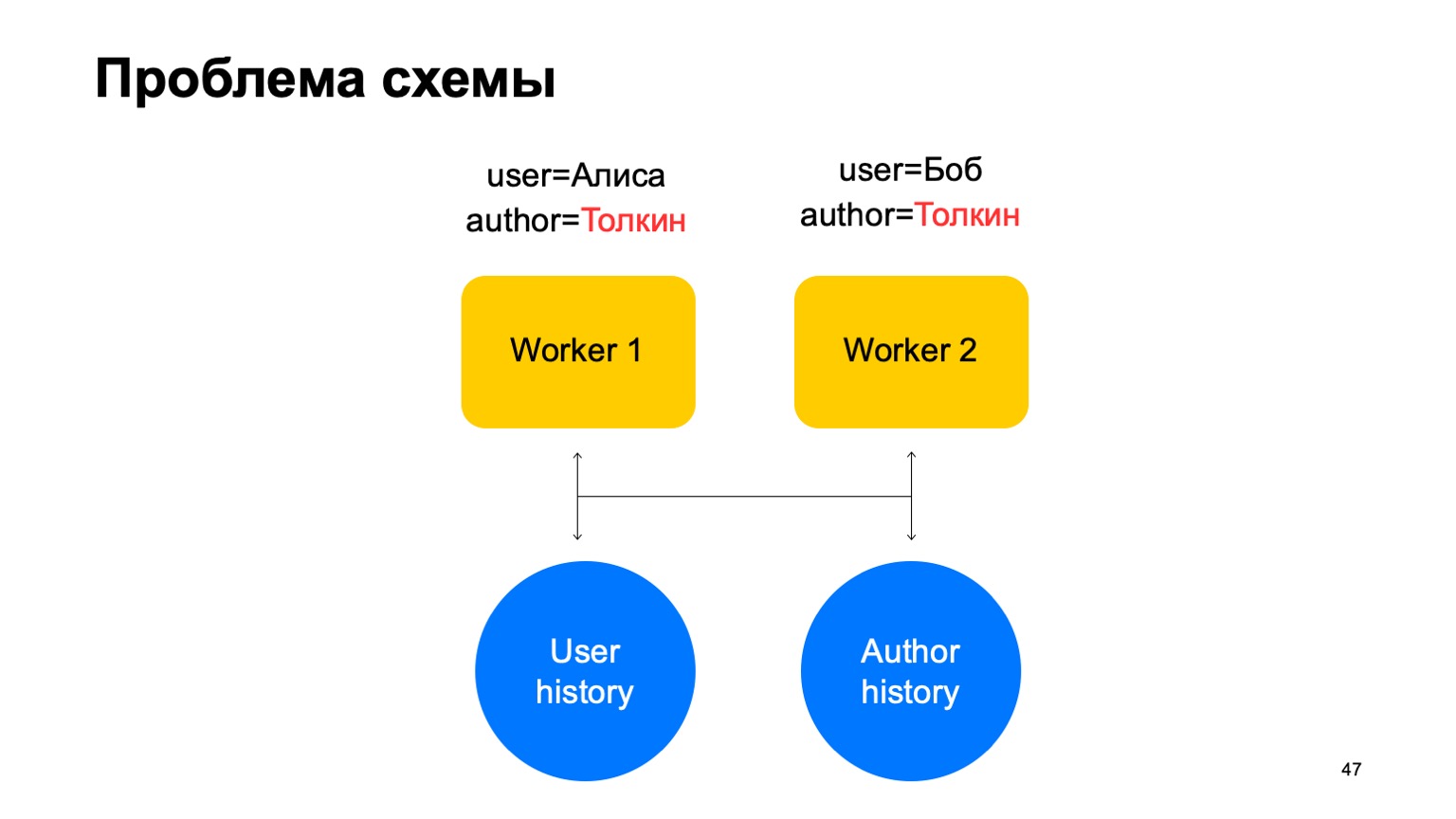
لنفترض أن لدينا حدثان على عاملنا. في هذه الحالة ، مع أي تقسيم لهؤلاء العمال ، قد ينشأ موقف عندما يصل مفتاح واحد إلى عمال مختلفين. في هذه الحالة ، هذا هو المؤلف تولكين ، دخل عاملين.
ثم نقرأ البيانات من تخزين القيمة الرئيسية هذا لكل من العاملين من التاريخ ، وسنقوم بتحديثها بطرق مختلفة وسينشأ سباق عندما نحاول الكتابة.
الحل: دعنا نفترض أنه يمكن فصل القراءة والكتابة ، وأن الكتابة يمكن أن تحدث مع تأخير طفيف. هذا عادة ليس مهما جدا. بتأخير بسيط ، أعني وحدات الثواني هنا. هذا أمر مهم ، على وجه الخصوص ، لأن تنفيذنا لمتجر القيمة الأساسية هذا يستغرق وقتًا أطول في كتابة البيانات بدلاً من قراءته.
سنقوم بتحديث الإحصاءات مع الفارق. في المتوسط ، يعمل هذا بشكل أو بآخر بشكل جيد ، نظرًا لحقيقة أننا سنحتفظ بحالة التخزين المؤقت على الأجهزة.
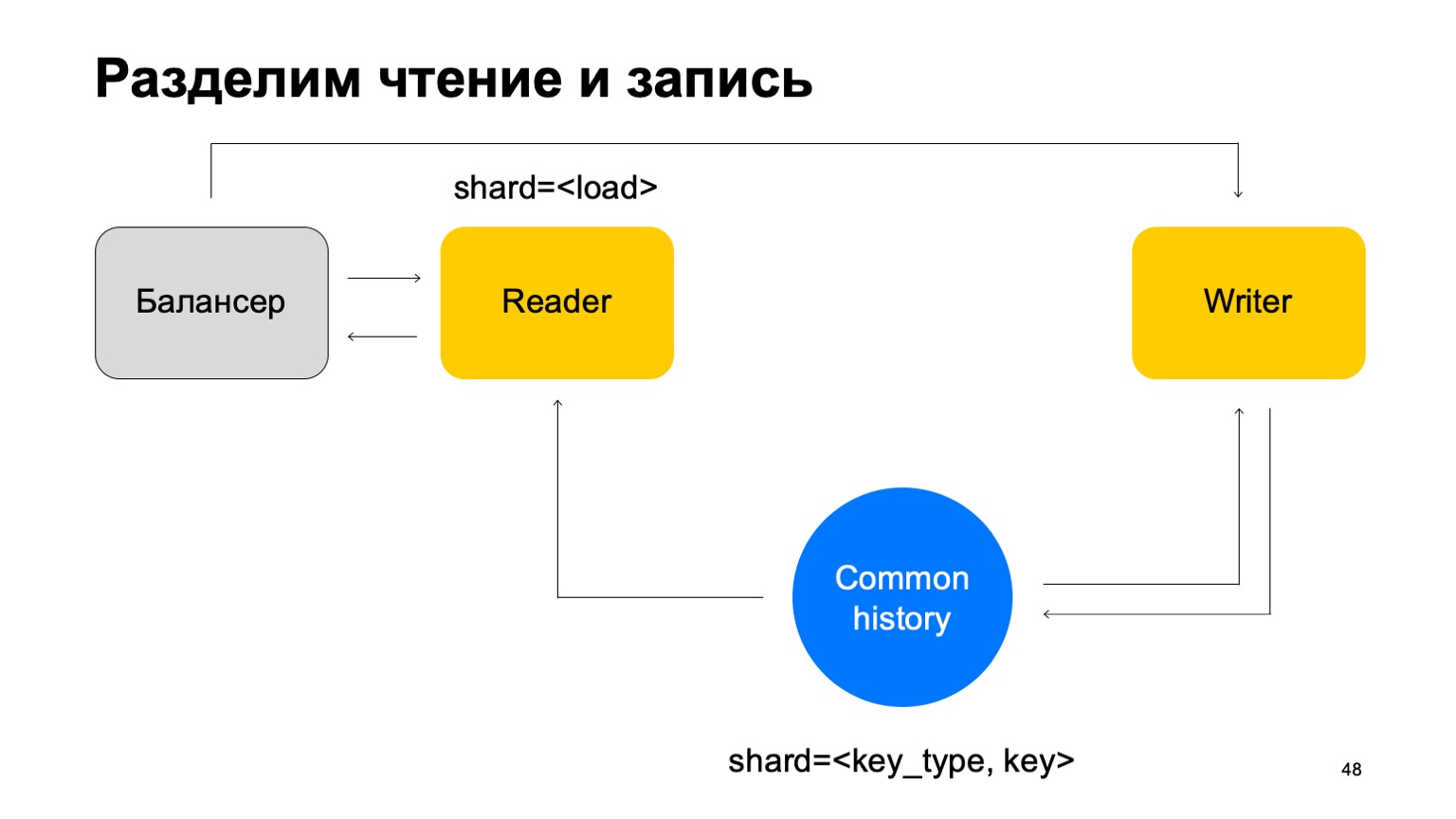
وشيء آخر. من أجل البساطة ، دعنا ندمج هذه القصص في قصة ونكتبها حسب نوع ومفتاح القطع. لدينا نوع من التاريخ المشترك.
ثم سنقوم بإضافة الموازن مرة أخرى ، وإضافة آلات القراء ، والتي يمكن تقسيمها بأي شكل من الأشكال - على سبيل المثال ، ببساطة عن طريق التحميل. سيقرأون هذه البيانات ببساطة ، ويقبلون الأحكام النهائية ويعيدونها إلى الموازن.
في هذه الحالة ، نحتاج إلى مجموعة من آلات الكتاب التي سيتم إرسال هذه البيانات إليها مباشرةً. سيقوم الكتاب بتحديث القصة وفقًا لذلك. ولكن هنا لا تزال المشكلة تنشأ ، والتي كتبت عنها أعلاه. دعونا نغير هيكل الكاتب بعد ذلك بقليل.
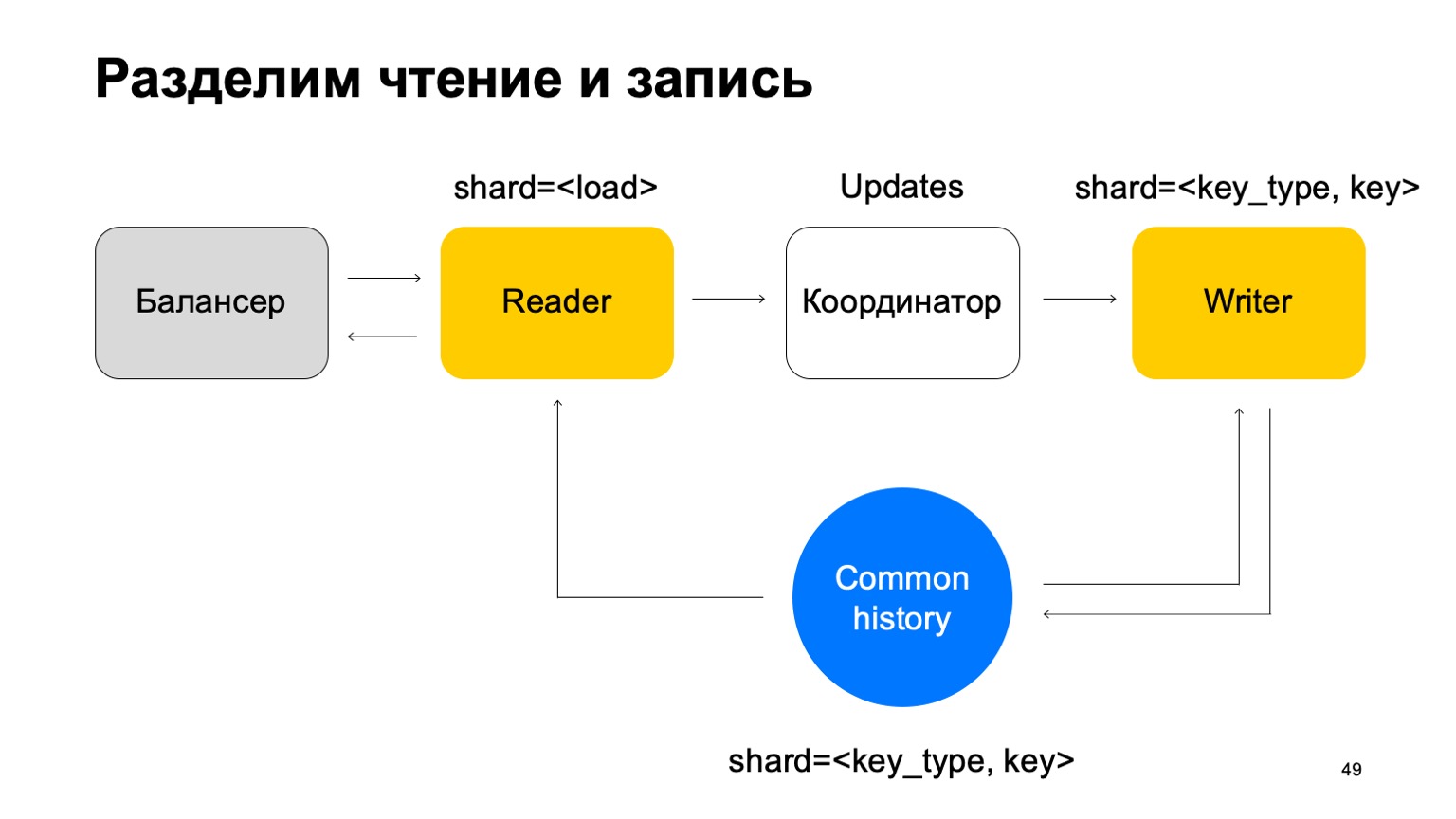
سوف نجعلها بحيث تكون مجزأة بنفس طريقة التاريخ - حسب نوع المفتاح وقيمته. في هذه الحالة ، عندما يكون تقسيمها هو نفس التاريخ ، فلن تكون لدينا المشكلة التي ذكرتها أعلاه.
هنا تتغير مهمته. لم يعد يقبل الأحكام. بدلاً من ذلك ، يقبل فقط التحديثات من القارئ ويخلطها ويطبقها بشكل صحيح على التاريخ.
من الواضح أن هناك حاجة إلى مكون هنا ، وهو منسق يوزع هذه التحديثات بين القراء والكتاب.
يضاف إلى هذا بالطبع حقيقة أن العامل يحتاج إلى الاحتفاظ بذاكرة تخزين مؤقت محدثة. ونتيجة لذلك ، اتضح أننا مسؤولون عن مئات المللي ثانية ، وأحيانًا أقل ، ونحدث الإحصائيات في ثانية. بشكل عام يعمل بشكل جيد ، للخدمات يكفي.

على ماذا حصلنا؟ بدأ المحللون في أداء وظائفهم بشكل أسرع وبنفس الطريقة لجميع الخدمات. وقد أدى ذلك إلى تحسين جودة وتوصيل جميع الأنظمة. يمكنك إعادة استخدام البيانات بين مكافحة الاحتيال للخدمات المختلفة ، والحصول على خدمات جديدة عالية الجودة لمكافحة الاحتيال بسرعة.

زوجان من الأفكار في النهاية. إذا كتبت شيئًا من هذا القبيل ، فكر على الفور في راحة المحللين من حيث دعم هذه الأنظمة وقابليتها للتوسع. اجعل كل شيء قابل للتكوين ، تحتاج إليه. في بعض الأحيان يكون من الصعب تحقيق خصائص عبر DC ومرة واحدة بالضبط ، ولكن يمكن تحقيق ذلك. إذا كنت تعتقد أنك حققت ذلك بالفعل ، فتحقق منه مرة أخرى. شكرا على انتباهك.